
У поисковиков не очень с логикой, это факт. Но они стараются. А SEO-специалисты стараются в ответ — пытаются добиться предельной релевантности страниц, опираясь на догадки и эксперименты.
Недавно Гугл порадовал новым фактором ранжирования — Neural Matching. Мы почитали, что об этом пишут эксперты, и собрали некоторые приемы, которые помогут писать более релевантные тексты под запросы.
И кстати, NM — это вам не LSI, все немного сложнее.
В сентябре 2018 года Danny Sullivan твитнул о том, что в последние несколько месяцев Google использует AI-метод нейронного сопоставления (Neural Matching) для лучшего связывания слов с понятиями. Этот алгоритм повлиял на результаты выдачи по 30% запросов по всему миру.

Мы не спешили писать о новом алгоритме, ждали разъяснений со стороны Google и исследований в этой сфере. Но воз и ныне там — в основном комментаторы показывают одни и те же скрины и рассказывают о переходе от поиска по словам к поиску по интенту. А также отсылают к Deep Relevance Matching Model (DRMM).
Попробуем разобраться, что за зверь этот Neural Matching и как адаптировать под него контент на сайте.
Примеры работы Neural Matching
Danny Sullivan в общих чертах пояснил, что такое Neural Matching. Он привел пример выдачи по запросу «why does my TV look strange». Пользователь вводит такой запрос, когда еще не знает, что такое «soap opera effect». Но Google благодаря новому алгоритму знает, что именно нужно:

На русском языке похожая история:

Еще пример. Вы встретили в квартире «прекрасное» насекомое и понятия не имеете, как его зовут:

Идем в Google, вводим набор признаков и на первой же позиции получаем релевантный ответ:

Внедрение Neural Matching обусловлено тем, что пользователи не всегда знают, что именно ищут, и не всегда правильно формулируют запросы. Danny Sullivan показал несколько таких «неправильных» запросов:

Задача Neural Matching — определять истинный поисковый интент (намерение) и выдавать правильные результаты.

Для определения интента используются не отдельные слова, а сущности и связи между ними. Смотрите, как это работает — на примере запросов «нажрался что делать» и «нажрался на ночь».
Каждый запрос содержит одну и ту же сущность — «нажрался». Но объединение ее с сущностью «на ночь» сигнализирует поисковику о том, что пользователь имеет в виду переедание. А с сущностью «что делать» скорее всего связано опьянение.

Как Google определяет интент — семантика ведь схожа? Поисковик сопоставляет, насколько часто сущности, объединенные в запросе, встречаются рядом на страницах. Кроме того, учитывается статистика по запросам (пользователи при вводе запроса «нажрался на ночь» чаще кликают по статьям именно о переедании).
Другой пример. Пользователь вводит фразу «поставить окна». Это как раз «неправильный» запрос, о котором говорит Danny Sullivan. Google понимает, что человек под «поставить» подразумевает что-то другое, нежели простую установку окон, и выводит в ТОПе правильные с его точки зрения результаты:

При этом только одна страница из ТОП-6 содержит слово «поставить» (в значении «поставщик окон», а не «установить окна самому»). На остальных страницах ТОП-6 нет ни слова «поставить», ни даже однокоренных слов. Хотя ниже уже подмешиваются результаты вроде «Как поставить окна самому» и т. п.
Из этого следует парадоксальный на первый взгляд вывод: чтобы занять высокие позиции по многим словам, не обязательно насыщать тексты схожей с поисковым запросом семантикой. Релевантность контента оценивается по набору сущностей (маркерных фраз), которые с высокой вероятностью удовлетворят поисковый интент.
Это меняет подход к написанию SEO-текстов: раньше опорной точкой были ключи, теперь — потребности аудитории.
Document Relevance Ranking и Neural Matching — как это отразится на SEO?
Roger Montti в статье для Search Engine Journal предположил, что алгоритм Neural Matching может работать на основе метода Document Relevance Ranking (DRR). Описан метод в статье «Deep Relevance Ranking using Enhanced Document-Query Interactions», опубликованной на сайте Google AI.
Суть метода DRR в том, что при определении релевантности документа используется исключительно его текст. Прочие факторы — ссылки, анкоры, упоминания, on-page SEO — значения не имеют.
Это что же, ссылки больше не нужны вообще? Не совсем так. Ранжирование по описанному методу DRR является частью общего алгоритма ранжирования. На первом этапе выдача формируется с учетом всех факторов ранжирования (ссылки, ключи, «мобильность», геолокация и т. д.). Так поисковик отсеивает низкопробный контент и определяет авторитетные сайты. На втором этапе в работу вступает DRR — среди лучших результатов он выбирает наиболее релевантные (но учитывает только текст).
На практике это может выглядеть так. Есть два сайта: очень авторитетный и молодой. Молодой сайт содержит супер-контент, аналогов которому в нише нет, насыщенный деталями и конкретикой. Но поскольку на авторитетный сайт ведет больше ссылок, его страница занимает первую позицию, а страница молодого сайта — десятую. И тут в работу вступает DRR — поисковик сканирует тексты и понимает, что контент молодого сайта содержательнее, чем у авторитетного. Следствие — перемещение молодого сайта на более высокую позицию.
Как делать контент под Neural Matching
Точно ли Neural Matching работает на основе DRR или нет, — не столь важно. Важно, что здесь «рулит» поисковый интент. Не длинные «портянки», не плотность ключевиков, не синонимайзинг.

Прежде чем создать контент, определитесь:
- для кого он (лучше всего провести исследования, составить портреты пользователей и писать для них);
- зачем он нужен (какую задачу закрывает);
- что в нем такого, чего нет у конкурентов (какую ценность вносит).
Для повышения релевантности текстов помимо основных запросов используйте тесно связанные сущности. Если текст пишет эксперт, то такие сущности наверняка будут в тексте. Другое дело, когда ставится ТЗ копирайтеру — в этом случае необходимо определить сущности и указать их в задании.
Рассмотрим способы сбора сущностей на примере категории интернет-магазина «Генераторы бензиновые».
1. Поиск по вопросам/ответам
Выявлять потребности пользователей можно с помощью форумов, комментариев к статьям в блогах, обсуждений в соцсетях. Все это работает. Но проще зайти на Ответы@Mail.ru (или западный аналог — Quora), ввести запрос в поиске, пройтись по вопросам и выделить сущности, связанные с основными ключами.
По запросу «генераторы бензиновые» mail.ru выдает 1624 вопроса. Идем по списку и выбираем сущности, которые характеризуют потребности целевой аудитории.


После подбора сущностей думаем, какой контент подойдет для них. Например, расход бензина за 1 час и способы применения генератора (для сварки, для котла, для освещения и т. п.) стоит указать в описании конкретных товаров. В описании рубрики «Бензиновые генераторы» можно вкратце рассказать, чем бензиновые отличаются от газовых, инверторных и т. п. А проблемы с работой генераторов — описать в статье для блога.
Обработка вопросов в QA-сервисах кропотливая, но она позволяет выделить реальные потребности аудитории, о которых вы могли не догадываться.
Попробовать упростить работу можно с помощью сервиса Answer The Public. Он собирает вопросы, сравнения и различные формулировки, которые встречаются в сети с вхождением заданной фразы.

Единственный недостаток — сервис англоязычный. Перевод искомой фразы частично решает проблему. Но в коммерческом сегменте стоит помнить об особенностях рынков (то, что волнует индусов, россиянам может быть бесполезно).
2. Парсинг фраз-ассоциаций
Под результатами поиска выводится блок «Вместе с … часто ищут» — здесь собраны фразы, которые сам поисковик связывает с исходной фразой («генераторы бензиновые»).

Анализ фраз-ассоциаций позволяет выделить связанные сущности: 5 кВт, 3 кВт, 10 кВт, инверторный, 1 кВт.
Остается продумать, как их включить в контент. Например, в описании рубрики «генераторы бензиновые» стоит рассказать, для каких целей подходят генераторы разной мощности (1, 3, 5, 10 кВт) и типа (инверторные, обычные и др.).
Если у вас исходных запросов много, вручную собирать ассоциации долго — используйте парсер.
3. Парсинг поисковых подсказок
Подсказки — это еще один источник подбора связанных сущностей.

Пополняем список сущностей, собранных из ассоциаций: с автозапуском, дизельные, 380 вольт, бесшумные. Это слова, которые хорошо характеризуют проблемы пользователей.
Для сбора подсказок тоже есть парсер.
В принципе, рассмотренных способов достаточно, чтобы получить представление о потребностях аудитории. Но если вы еще глубже хотите проработать семантику, вот два опциональных способа.
4. Подбор квази-синонимов
Квази-синонимами (семантическими ассоциатами) называют слова, близкие по значению, но не взаимозаменяемые в различных контекстах. Например, слова «генератор» и «автогенератор» являются синонимами в тексте об автомобильных запчастях, но в тексте о видах генераторов они таковыми не будут.
Квази-синонимы определяют на основании частоты их встречаемости в текстах. Для решения этой задачи есть сервис RusVectōrēs (раздел «Похожие слова»). Введите интересующее слово, отметьте все доступные модели и части речи и запустите поиск.
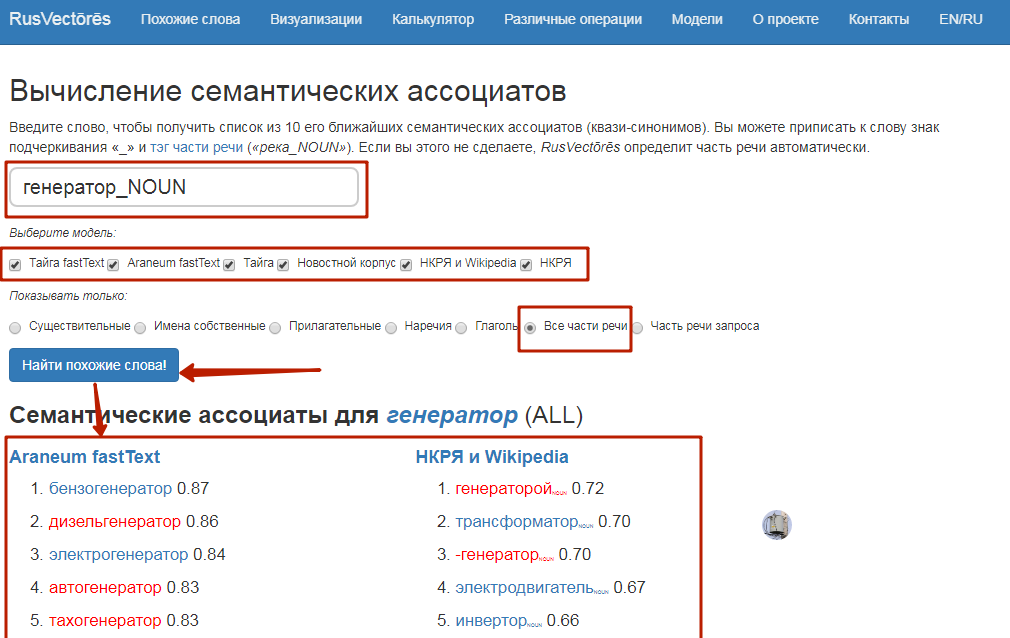
В итоге вы получите по 10 наиболее значимых ассоциатов для каждой модели поиска. Слепо использовать их при формировании ТЗ не стоит — здесь будет немало «мусора» (парсинг ассоциаций на основе данных поисковых систем все же более предпочтителен). Тем не менее выявить интересные слова можно. Например, видим, что со словом «генератор» связаны слова «бензогенератор», «инвертор», «газогенератор», «контактор» и др.
5. Парсинг текстов конкурентов
Для выявления потребностей аудитории этот способ не самый лучший. Во-первых, неизвестно, когда был создан контент на сайтах конкурентов (за это время поисковые предпочтения могли сместиться). Во-вторых, нет гарантии, что конкуренты тщательно проанализировали проблемы аудитории и создали на их основе тексты.
С другой стороны, если использовать этот способ в качестве вспомогательного, то появляется шанс выявить сущности, которые вы могли упустить.
Итак, вводим в поиске основной запрос «генераторы бензиновые», копируем релевантные тексты с сайтов в ТОП-10 и выделяем семантику с помощью Адвего:

Дополняем список релевантных сущностей: 4-тактный, аварийный, автономный, бесперебойный, для дачи, на природу и т. п.
Сводим все воедино и получаем ТЗ, оптимизированное под Neural Matching.
ТЗ на тексты: make Neural Matching, not LSI
После того как релевантные сущности собраны, необходимо написать текст. Но недостаточно просто указать в ТЗ ключи и перечень синонимов и связанных слов, как это обычно делают при заказе LSI-текстов.

Пример ТЗ на LSI-текст
На основе таких ТЗ — просто с перечнем слов — порой получаются довольно странные тексты.
Распространенная практика у копирайтеров — написать текст, и только потом вписывать в него заданные слова. Это проще, так как не нужно прерываться на подбор и вставку слов в процессе сочинения текста. Но такие вставки задним числом могут сломать — и нередко ломают — логику и стиль текста.
Текст под Neural Matching — о пользователях и их потребностях, а не о ключах и плюс-словах. Поэтому в ТЗ появляются чисто маркетинговые фишки: описания потребителей и их мотивы. Ключи и плюс-слова отходят на второй план — они используются как маркеры, а не как обязательные элементы. Их место занимают информационные потребности аудитории.

Пример ТЗ под Neural Matching
Такое ТЗ позволяет автору четко понимать, для кого текст, зачем и при каких обстоятельствах его будут читать. Такое ТЗ не просто набрасывает слова, которые надо употребить, но дает направления — о чем писать, чтобы употребить эти слова.
Neural Matching при оптимизации страниц для поиска смещает акцент с чисто сеошных механик в сторону маркетинга. На самом деле, подобная тенденция наблюдается не первый год. Просто Neural Matching — еще один шаг на пути к поисковой оптимизации с человеческим лицом.
Оптимизация контента под Neural Matching требует времени и работы головой. Намного проще забросить в ТЗ ключи из СЯ, спарсить плюс-слова и сказать копирайтеру: «Напиши для людей». Но в условиях развития AI-поиска такой подход будет все менее эффективен.

