Если вы недавно начали свой путь в машинном обучении, вы можете запутаться между LabelEncoder и OneHotEncoder. Оба кодировщика — часть библиотеки SciKit Learn в Python и оба используются для преобразования категориальных или текстовых данных в числа, которые наши предсказательные модели понимают лучше. Давайте выясним отличия между кодировщиками на простеньком примере.
Кодирование признаков
Прежде всего, документацию SciKit Learn для LabelEncoder можно найти здесь. Теперь рассмотрим такие данные:
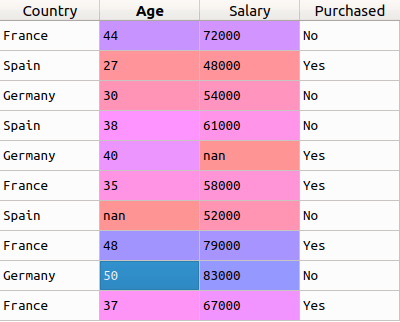
В этом примере первый столбец (страна) является полностью текстовым. Как вы, возможно, уже знаете, мы не можем использовать текст в данных для обучения модели. Поэтому, прежде чем мы сможем начать процесс, нам нужно эти данные подготовить.
И для преобразования подобных категорий в понятные модели числовые данные мы и используем класс LabelEncoder. Таким образом, всё что нам нужно сделать, чтобы получить признак для первого столбца, это импортировать класс из библиотеки sklearn, обработать колонку функцией fit_transform и заменить существующие текстовые данные новыми закодированными. Давайте посмотрим код.
from sklearn.preprocessing import LabelEncoder labelencoder = LabelEncoder() x[:, 0] = labelencoder.fit_transform(x[:, 0])
Предполагается, что данные находятся в переменной x. После запуска кода выше, если вы проверите значение x, то увидите, что три страны в первом столбце были заменены числами 0, 1 и 2.

В целом, это и есть кодирование признаков. Но в зависимости от данных это преобразование создаёт новую проблему. Мы перевели набор стран в набор чисел. Но это всего лишь категориальные данные, и между числами на самом деле нет никакой связи.
Проблема здесь в том, что, поскольку разные числа в одном столбце, модель неправильно подумает, что данные находятся в каком-то особом порядке — 0 < 1 < 2 Хотя это, конечно, совсем не так. Для решения проблемы мы используем OneHotEncoder.
OneHotEncoder
Если вам интересно почитать документацию, найти её можно здесь. Теперь, как мы уже обсуждали, в зависимости от имеющихся у нас данных мы можем столкнуться с ситуацией, когда после кодирования признаков наша модель запутается, ложно предположив, что данные связаны порядком или иерархией, которого на самом деле нет. Чтобы этого избежать мы воспользуемся OneHotEncoder.
Этот кодировщик берёт столбец с категориальными данными, который был предварительно закодирован в признак, и создаёт для него несколько новых столбцов. Числа заменяются на единицы и нули, в зависимости от того, какому столбцу какое значение присуще. В нашем примере мы получим три новых столбца, по одному для каждой страны — Франции, Германии и Испании.
Для строк, у которых первый столбец — Франция, столбец «Франция» будет установлен в «1», а два других столбца в «0». Аналогично для строк, у которых первый столбец — Германия, столбец «Германия» будет иметь «1», а два других столбца будут иметь «0».
Делается это весьма просто:
from sklearn.preprocessing import OneHotEncoder onehotencoder = OneHotEncoder(categorical_features = [0]) x = onehotencoder.fit_transform(x).toarray()
В конструкторе мы указываем, какой столбец должен быть обработан OneHotEncoder, в нашем случае — [0]. Затем преобразуем массив x с помощью функции fit_transform объекта кодировщика, который только что создали. Вот и всё, теперь у нас три новых столбца в наборе данных:
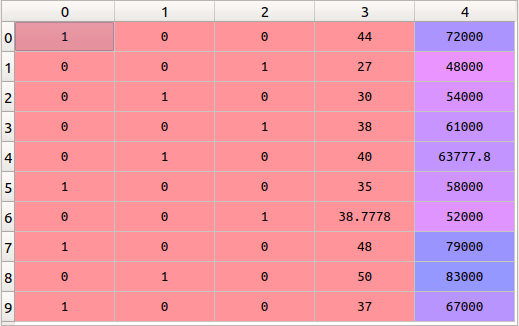
Как видите вместо одной колонки со страной мы получили три новых, кодирующих эту страну.
В этом и есть отличие от LabelEncoder и OneHotEncoder.

