Всем привет! Уже в следующий понедельник начинаются занятия в новой группе курса «Разработчик Python», а это значит, что у нас есть время для публикации еще одного интересного материала, чем мы сейчас и займемся. Приятного прочтения.

В далеком 2003 году Intel выпустил новый процессор Pentium 4 “HT”. Этот процессор разгонялся до 3ГГц и поддерживал технологию гиперпоточности.

В последующие годы Intel и AMD боролись за достижение наибольшей производительности настольных компьютеров, увеличивая скорость шины, размер кэша L2 и уменьшая размер матрицы для минимизации задержки. В 2004 году на смену модели HT с частотой 3ГГц пришла 580 модель “Prescott” с разгоном до 4ГГц.
Казалось, чтобы идти вперед нужно было просто повышать тактовую частоту, однако новые процессоры страдали от высокого энергопотребления и тепловыделения.
Процессор вашего настольного ПК сегодня выдает 4ГГц? Маловероятно, поскольку путь к повышению производительности в конечном итоге лежал через повышение скорости шины и увеличение количества ядер. В 2006 году Intel Core 2 заменил Pentium 4 и имел гораздо более низкую тактовую частоту.
Помимо выпуска многоядерных процессоров для широкой пользовательской аудитории в 2006 году произошло кое-что еще. Python 2.5 наконец увидел свет! Он поставлялся уже с бета версией ключевого слова with, которое вы все знаете и любите.
У Python 2.5 имелось одно серьезное ограничение, когда речь заходила об использовании Intel Core 2 или AMD Athlon X2.
Это был GIL.
GIL (Global Interpreter Lock – глобальная блокировка интерпретатора) – это булевое значение в интерпретаторе Python, защищенное мьютексом. Блокировка используется в основном цикле вычисления байткода CPython, чтобы установить, какой поток в данный момент времени выполняет инструкции.
CPython поддерживает использование нескольких потоков в одном интерпретаторе, но потоки должны запрашивать доступ к GIL, чтобы выполнять низкоуровневые операции. В свою очередь, это означает, что Python-разработчики могут использовать асинхронный код, многопоточность и больше не беспокоиться о блокировке каких-либо переменных или сбоях на уровне процессора при дедлоках.
GIL упрощает многопоточное программирование на Python.

GIL также говорит нам о том, что в то время, как CPython может быть многопоточным, только один поток в любой момент времени может выполняться. Это означает, что ваш четырехъядерный процессор делает примерно это (за исключением синего экрана, надеюсь).
Текущая версия GIL была написана в 2009 году для поддержки асинхронных функций и осталась нетронутой даже после множества попыток убрать ее в принципе или изменить требования к ней.
Любое предложение убрать GIL было обосновано тем, что глобальная блокировка интерпретатора не должна ухудшать производительность однопоточного кода. Тот, кто пробовал включать гиперпоточность в 2003 году, поймет, о чем я говорю.
Если вы хотите действительно распараллелить код на CPython, вам придется использовать несколько процессов.
В CPython 2.6 модуль multiprocessing был добавлен в стандартную библиотеку. Мультипроцессная обработка (multiprocessing) маскировала собой порождение процессов в CPython (каждый процесс со своей собственной GIL).
Процессы создаются, в них отправляются команды с помощью скомпилированных модулей и функций Python, а затем они снова присоединяются к главному процессу.
Мультипроцессная обработка также поддерживает использование переменных через очередь или канал. У нее есть объект блокировки, который используется для блокировки объектов в главном процессе и записи из других процессов.
У мультипроцессной обработки есть один главный недостаток. Она несет значительную вычислительную нагрузку, которая отражается как на времени обработки, так и на использовании памяти. Время запуска CPython даже без no-site составляет 100-200 мс (загляните на https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b, чтобы узнать больше).
В итоге у вас может быть параллельный код на CPython, но вам все еще нужно тщательно распланировать работу длительных процессов, которые совместно используют несколько объектов.
Другой альтернативой может являться использование стороннего пакета, такого как Twisted.
Итак, напомню, что многопоточность в CPython – это просто, но в действительности это не является распараллеливанием, а вот мультипроцессная обработка параллельна, но влечет за собой значительные накладные расходы.
Что если есть путь лучше?
Ключ к обходу GIL кроется в имени, глобальная блокировка интерпретатора является частью глобального состояния интерпретатора. Процессы CPython могут иметь несколько интерпретаторов и, следовательно, несколько блокировок, однако эта функция используется редко, поскольку доступ к ней есть только через C-API.
Одной из особенностей CPython 3.8, является PEP554, реализация субинтерпретаторов и API с новым модулем
Это позволяет создавать несколько интерпретаторов из Python в рамках одного процесса. Еще одно нововведение Python 3.8 заключается в том, что все интерпретаторы будут иметь свои собственные GIL.
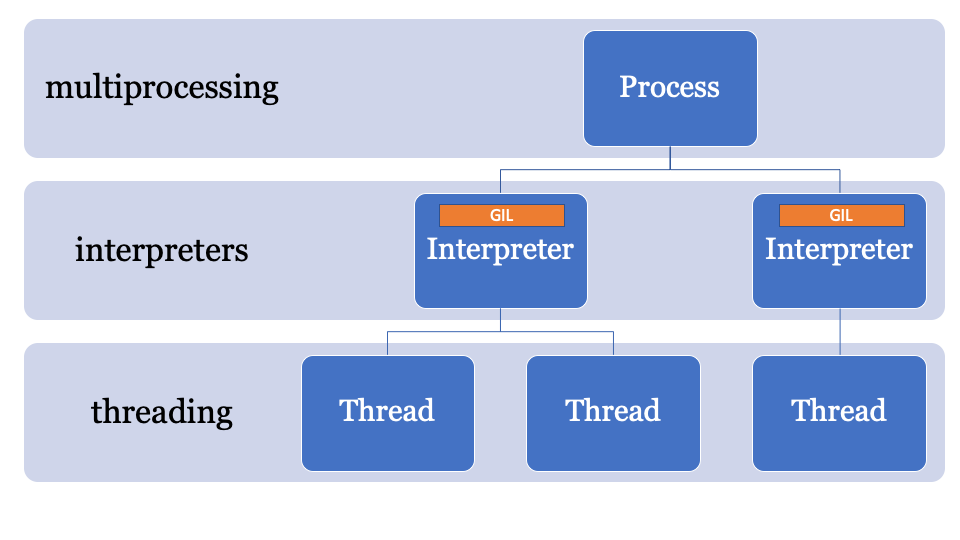
Поскольку состояние интерпретатора содержит область аллоцированную в памяти, коллекцию всех указателей на объекты Python (локальные и глобальные), субинтерпретаторы в PEP554 не могут получить доступ к глобальным переменным других интерпретаторов.
Подобно мультипроцессной обработке, совместное использование интерпретаторами объектов заключается в их сериализации и использовании формы IPC (сеть, диск или общая память). Существует много способов сериализации объектов в Python, например, модуль
Лучше всего было бы иметь общее пространство в памяти, которое можно изменять и контролировать определенным процессом. Таким образом, объекты могут быть отправлены главным интерпретатором и получены другим интерпретатором. Это будет пространство управляемой памяти для поиска указателей PyObject, к которому может получить доступ каждый интерпретатор, при этом основной процесс будет управлять блокировками.
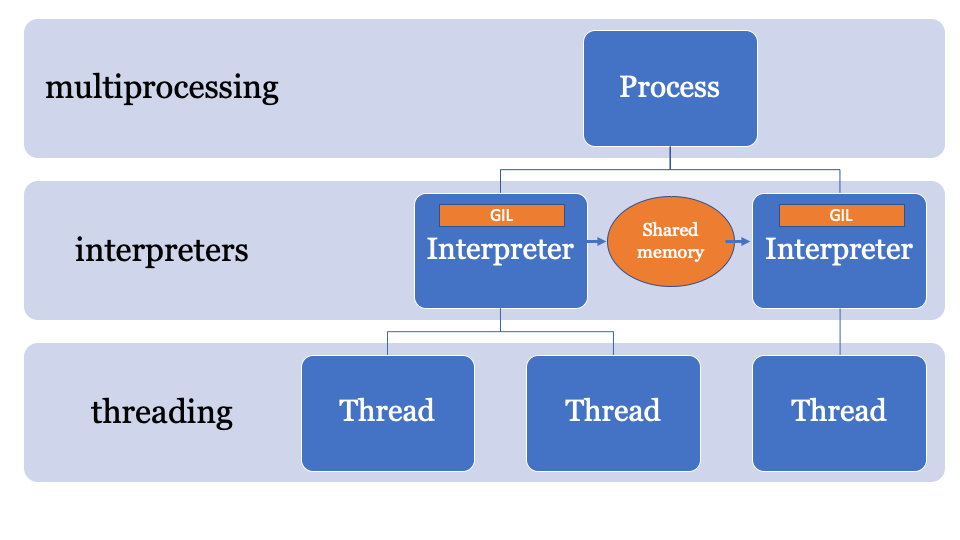
API для этого все еще разрабатывается, но оно, вероятно, будет выглядеть примерно так:
В этом примере используется NumPy. Массив numpy отправляется по каналу, он сериализуется с помощью модуля
Модуль
В PEP574 представлен новый протокол pickle (v5), который поддерживает возможность обработки буферов памяти отдельно от остальной части потока pickle. Что касается больших объектов данных, то сериализация их всех на одном дыхании и десериализация из субинтерпретатора добавит большое количество накладных расходов.
Новый API может быть реализован (чисто гипотетически) следующим образом —
По сути, этот пример построен на использовании API низкоуровневых субинтерпретаторов. Если вы не использовали библиотеку
Как только этот PEP объединится с другими, я думаю, мы увидим несколько новых API в PyPi.
Короткий ответ: Больше, чем поток, меньше, чем процесс.
Длинный ответ: Интерпретатор имеет свое собственное состояние, потому ему нужно будет клонировать и инициализовать следующее, несмотря на то, что PEP554 упрощает создание субинтерпретаторов:
Конфигурацию ядра можно легко клонировать из памяти, но с импортированными модулями все не так просто. Импорт модулей в Python дело медленное, поэтому если создание субинтерпретатора означает импорт модулей в другое пространство имен каждый раз, преимущества уменьшаются.
Существующая реализация цикла событий
После объединения PEP554, вероятно уже в Python 3.9, может быть использована альтернативная реализация цикла событий (хотя этого еще никто и не сделал), которая параллельно запускает асинхронные методы в субинтерпретаторах.
Ну, не совсем.
Поскольку CPython так долго работал на одном интерпретаторе, многие части базы кода используют “Runtime State” вместо “Interpreter State”, поэтому если бы PEP554 был введен уже сейчас, проблем все равно было бы много.
Например, состояние сборщика мусора (в версиях 3.7<) принадлежит среде выполнения.
В изменениях во время спринтов PyCon, состояние сборщика мусора начало перемещаться в интерпретатор, так что каждый субинтерпретатор будет иметь свой собственный сборщик мусора (как и должно было быть).
Другая проблема заключается в том, что есть некоторые «глобальные» переменные, которые порядком задержались в базе кода CPython наряду с множеством расширений на С. Поэтому, когда люди внезапно начали правильно распараллеливать свой код, мы разглядели некоторые проблемы.
Еще одна проблема заключается в том, что дескрипторы файлов принадлежат процессу, поэтому если у вас есть файл, открытый для записи в одном интерпретаторе, субинтерпретатор не сможет получить доступ к этому файлу (без дальнейших изменений CPython).
Короче говоря, есть еще много проблем, которые надо решить.
GIL по-прежнему будет использоваться для однопоточных приложений. Поэтому даже при следовании PEP554 ваш однопоточный код внезапно не станет параллельным.
Если вы хотите писать параллельный код в Python 3.8, у вас будут проблемы распараллеливания, связанные с процессором, но это и билет в будущее!
Pickle v5 и совместное использование памяти для мультипроцессной обработки скорее всего будут в Python 3.8 (Октябрь 2019 года), а субинтерпретаторы появятся между версиями 3.8 и 3.9.
Если у вас есть желания поиграться с представленными примерами, то я создал отдельную ветку со всем необходимым кодом: https://github.com/tonybaloney/cpython/tree/subinterpreters.
А что вы думаете по этому поводу? Пишите свои комментарии и до встречи на курсе.
В далеком 2003 году Intel выпустил новый процессор Pentium 4 “HT”. Этот процессор разгонялся до 3ГГц и поддерживал технологию гиперпоточности.
В последующие годы Intel и AMD боролись за достижение наибольшей производительности настольных компьютеров, увеличивая скорость шины, размер кэша L2 и уменьшая размер матрицы для минимизации задержки. В 2004 году на смену модели HT с частотой 3ГГц пришла 580 модель “Prescott” с разгоном до 4ГГц.
Казалось, чтобы идти вперед нужно было просто повышать тактовую частоту, однако новые процессоры страдали от высокого энергопотребления и тепловыделения.
Процессор вашего настольного ПК сегодня выдает 4ГГц? Маловероятно, поскольку путь к повышению производительности в конечном итоге лежал через повышение скорости шины и увеличение количества ядер. В 2006 году Intel Core 2 заменил Pentium 4 и имел гораздо более низкую тактовую частоту.
Помимо выпуска многоядерных процессоров для широкой пользовательской аудитории в 2006 году произошло кое-что еще. Python 2.5 наконец увидел свет! Он поставлялся уже с бета версией ключевого слова with, которое вы все знаете и любите.
У Python 2.5 имелось одно серьезное ограничение, когда речь заходила об использовании Intel Core 2 или AMD Athlon X2.
Это был GIL.
Что такое GIL?
GIL (Global Interpreter Lock – глобальная блокировка интерпретатора) – это булевое значение в интерпретаторе Python, защищенное мьютексом. Блокировка используется в основном цикле вычисления байткода CPython, чтобы установить, какой поток в данный момент времени выполняет инструкции.
CPython поддерживает использование нескольких потоков в одном интерпретаторе, но потоки должны запрашивать доступ к GIL, чтобы выполнять низкоуровневые операции. В свою очередь, это означает, что Python-разработчики могут использовать асинхронный код, многопоточность и больше не беспокоиться о блокировке каких-либо переменных или сбоях на уровне процессора при дедлоках.
GIL упрощает многопоточное программирование на Python.
GIL также говорит нам о том, что в то время, как CPython может быть многопоточным, только один поток в любой момент времени может выполняться. Это означает, что ваш четырехъядерный процессор делает примерно это (за исключением синего экрана, надеюсь).
Текущая версия GIL была написана в 2009 году для поддержки асинхронных функций и осталась нетронутой даже после множества попыток убрать ее в принципе или изменить требования к ней.
Любое предложение убрать GIL было обосновано тем, что глобальная блокировка интерпретатора не должна ухудшать производительность однопоточного кода. Тот, кто пробовал включать гиперпоточность в 2003 году, поймет, о чем я говорю.
Отказ от GIL в CPython
Если вы хотите действительно распараллелить код на CPython, вам придется использовать несколько процессов.
В CPython 2.6 модуль multiprocessing был добавлен в стандартную библиотеку. Мультипроцессная обработка (multiprocessing) маскировала собой порождение процессов в CPython (каждый процесс со своей собственной GIL).
from multiprocessing import Process def f(name): print 'hello', name if __name__ == '__main__': p = Process(target=f, args=('bob',)) p.start() p.join()
Процессы создаются, в них отправляются команды с помощью скомпилированных модулей и функций Python, а затем они снова присоединяются к главному процессу.
Мультипроцессная обработка также поддерживает использование переменных через очередь или канал. У нее есть объект блокировки, который используется для блокировки объектов в главном процессе и записи из других процессов.
У мультипроцессной обработки есть один главный недостаток. Она несет значительную вычислительную нагрузку, которая отражается как на времени обработки, так и на использовании памяти. Время запуска CPython даже без no-site составляет 100-200 мс (загляните на https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b, чтобы узнать больше).
В итоге у вас может быть параллельный код на CPython, но вам все еще нужно тщательно распланировать работу длительных процессов, которые совместно используют несколько объектов.
Другой альтернативой может являться использование стороннего пакета, такого как Twisted.
PEP554 и смерть GIL?
Итак, напомню, что многопоточность в CPython – это просто, но в действительности это не является распараллеливанием, а вот мультипроцессная обработка параллельна, но влечет за собой значительные накладные расходы.
Что если есть путь лучше?
Ключ к обходу GIL кроется в имени, глобальная блокировка интерпретатора является частью глобального состояния интерпретатора. Процессы CPython могут иметь несколько интерпретаторов и, следовательно, несколько блокировок, однако эта функция используется редко, поскольку доступ к ней есть только через C-API.
Одной из особенностей CPython 3.8, является PEP554, реализация субинтерпретаторов и API с новым модулем
interpreters в стандартной библиотеке.Это позволяет создавать несколько интерпретаторов из Python в рамках одного процесса. Еще одно нововведение Python 3.8 заключается в том, что все интерпретаторы будут иметь свои собственные GIL.
Поскольку состояние интерпретатора содержит область аллоцированную в памяти, коллекцию всех указателей на объекты Python (локальные и глобальные), субинтерпретаторы в PEP554 не могут получить доступ к глобальным переменным других интерпретаторов.
Подобно мультипроцессной обработке, совместное использование интерпретаторами объектов заключается в их сериализации и использовании формы IPC (сеть, диск или общая память). Существует много способов сериализации объектов в Python, например, модуль
marshal, модуль pickle или более стандартизированные методы, такие как json или simplexml. Каждый из них имеет свои плюсы и минусы, и все они дают вычислительную нагрузку. Лучше всего было бы иметь общее пространство в памяти, которое можно изменять и контролировать определенным процессом. Таким образом, объекты могут быть отправлены главным интерпретатором и получены другим интерпретатором. Это будет пространство управляемой памяти для поиска указателей PyObject, к которому может получить доступ каждый интерпретатор, при этом основной процесс будет управлять блокировками.
API для этого все еще разрабатывается, но оно, вероятно, будет выглядеть примерно так:
import _xxsubinterpreters as interpreters import threading import textwrap as tw import marshal # Create a sub-interpreter interpid = interpreters.create() # If you had a function that generated some data arry = list(range(0,100)) # Create a channel channel_id = interpreters.channel_create() # Pre-populate the interpreter with a module interpreters.run_string(interpid, "import marshal; import _xxsubinterpreters as interpreters") # Define a def run(interpid, channel_id): interpreters.run_string(interpid, tw.dedent(""" arry_raw = interpreters.channel_recv(channel_id) arry = marshal.loads(arry_raw) result = [1,2,3,4,5] # where you would do some calculating result_raw = marshal.dumps(result) interpreters.channel_send(channel_id, result_raw) """), shared=dict( channel_id=channel_id ), ) inp = marshal.dumps(arry) interpreters.channel_send(channel_id, inp) # Run inside a thread t = threading.Thread(target=run, args=(interpid, channel_id)) t.start() # Sub interpreter will process. Feel free to do anything else now. output = interpreters.channel_recv(channel_id) interpreters.channel_release(channel_id) output_arry = marshal.loads(output) print(output_arry)
В этом примере используется NumPy. Массив numpy отправляется по каналу, он сериализуется с помощью модуля
marshal, затем субинтерпретатор обрабатывает данные (на отдельном GIL), поэтому здесь может возникнуть проблема распараллеливания, связанная с ЦП, что идеально подойдет для субинтерпретаторов. Это выглядит неэффективно
Модуль
marshal работает действительно быстро, однако не так быстро, как совместное использование объектов непосредственно из памяти. В PEP574 представлен новый протокол pickle (v5), который поддерживает возможность обработки буферов памяти отдельно от остальной части потока pickle. Что касается больших объектов данных, то сериализация их всех на одном дыхании и десериализация из субинтерпретатора добавит большое количество накладных расходов.
Новый API может быть реализован (чисто гипотетически) следующим образом —
import _xxsubinterpreters as interpreters import threading import textwrap as tw import pickle # Create a sub-interpreter interpid = interpreters.create() # If you had a function that generated a numpy array arry = [5,4,3,2,1] # Create a channel channel_id = interpreters.channel_create() # Pre-populate the interpreter with a module interpreters.run_string(interpid, "import pickle; import _xxsubinterpreters as interpreters") buffers=[] # Define a def run(interpid, channel_id): interpreters.run_string(interpid, tw.dedent(""" arry_raw = interpreters.channel_recv(channel_id) arry = pickle.loads(arry_raw) print(f"Got: {arry}") result = arry[::-1] result_raw = pickle.dumps(result, protocol=5) interpreters.channel_send(channel_id, result_raw) """), shared=dict( channel_id=channel_id, ), ) input = pickle.dumps(arry, protocol=5, buffer_callback=buffers.append) interpreters.channel_send(channel_id, input) # Run inside a thread t = threading.Thread(target=run, args=(interpid, channel_id)) t.start() # Sub interpreter will process. Feel free to do anything else now. output = interpreters.channel_recv(channel_id) interpreters.channel_release(channel_id) output_arry = pickle.loads(output) print(f"Got back: {output_arry}")
Это выглядит шаблонно
По сути, этот пример построен на использовании API низкоуровневых субинтерпретаторов. Если вы не использовали библиотеку
multiprocessing, некоторые проблемы покажутся вам знакомыми. Это не так просто, как потоковая обработка, вы не можете просто, скажем, запустить эту функцию с таким списком входных данных в отдельных интерпретаторах (пока). Как только этот PEP объединится с другими, я думаю, мы увидим несколько новых API в PyPi.
Сколько накладных расходов имеет субинтерпретатор?
Короткий ответ: Больше, чем поток, меньше, чем процесс.
Длинный ответ: Интерпретатор имеет свое собственное состояние, потому ему нужно будет клонировать и инициализовать следующее, несмотря на то, что PEP554 упрощает создание субинтерпретаторов:
- Модули в пространстве имен
__main__иimportlib; - Содержимое словаря
sys; - Встроенные функции (
print(),assertи т.д.); - Потоки;
- Конфигурацию ядра.
Конфигурацию ядра можно легко клонировать из памяти, но с импортированными модулями все не так просто. Импорт модулей в Python дело медленное, поэтому если создание субинтерпретатора означает импорт модулей в другое пространство имен каждый раз, преимущества уменьшаются.
Как насчет asyncio?
Существующая реализация цикла событий
asyncio в стандартной библиотеке создает кадры стека для оценки, а также совместно использует состояние в главном интерпретаторе (и, следовательно, совместно использует GIL).После объединения PEP554, вероятно уже в Python 3.9, может быть использована альтернативная реализация цикла событий (хотя этого еще никто и не сделал), которая параллельно запускает асинхронные методы в субинтерпретаторах.
Звучит круто, заверните и мне!
Ну, не совсем.
Поскольку CPython так долго работал на одном интерпретаторе, многие части базы кода используют “Runtime State” вместо “Interpreter State”, поэтому если бы PEP554 был введен уже сейчас, проблем все равно было бы много.
Например, состояние сборщика мусора (в версиях 3.7<) принадлежит среде выполнения.
В изменениях во время спринтов PyCon, состояние сборщика мусора начало перемещаться в интерпретатор, так что каждый субинтерпретатор будет иметь свой собственный сборщик мусора (как и должно было быть).
Другая проблема заключается в том, что есть некоторые «глобальные» переменные, которые порядком задержались в базе кода CPython наряду с множеством расширений на С. Поэтому, когда люди внезапно начали правильно распараллеливать свой код, мы разглядели некоторые проблемы.
Еще одна проблема заключается в том, что дескрипторы файлов принадлежат процессу, поэтому если у вас есть файл, открытый для записи в одном интерпретаторе, субинтерпретатор не сможет получить доступ к этому файлу (без дальнейших изменений CPython).
Короче говоря, есть еще много проблем, которые надо решить.
Заключение: GIL правда уже не актуален?
GIL по-прежнему будет использоваться для однопоточных приложений. Поэтому даже при следовании PEP554 ваш однопоточный код внезапно не станет параллельным.
Если вы хотите писать параллельный код в Python 3.8, у вас будут проблемы распараллеливания, связанные с процессором, но это и билет в будущее!
Когда?
Pickle v5 и совместное использование памяти для мультипроцессной обработки скорее всего будут в Python 3.8 (Октябрь 2019 года), а субинтерпретаторы появятся между версиями 3.8 и 3.9.
Если у вас есть желания поиграться с представленными примерами, то я создал отдельную ветку со всем необходимым кодом: https://github.com/tonybaloney/cpython/tree/subinterpreters.
А что вы думаете по этому поводу? Пишите свои комментарии и до встречи на курсе.

