В этой статье мы рассмотрим, как построить программу на Go, такую, как компилятор или статический анализатор, которая взаимодействует с фреймворком компиляции LLVM, используя язык ассемблера LLVM IR.
TL;DR мы написали библиотеку для взаимодействия с LLVM IR на чистом Go, см. ссылки на код и на пример проекта.
(Те из вас, кто знаком с LLVM IR, могут перейти к следующему разделу).
LLVM IR — это низкоуровневое промежуточное представление, используемое фреймворком компиляции LLVM. Вы можете думать об LLVM IR как о платформенно-независимом ассемблере с бесконечным количеством локальных регистров.
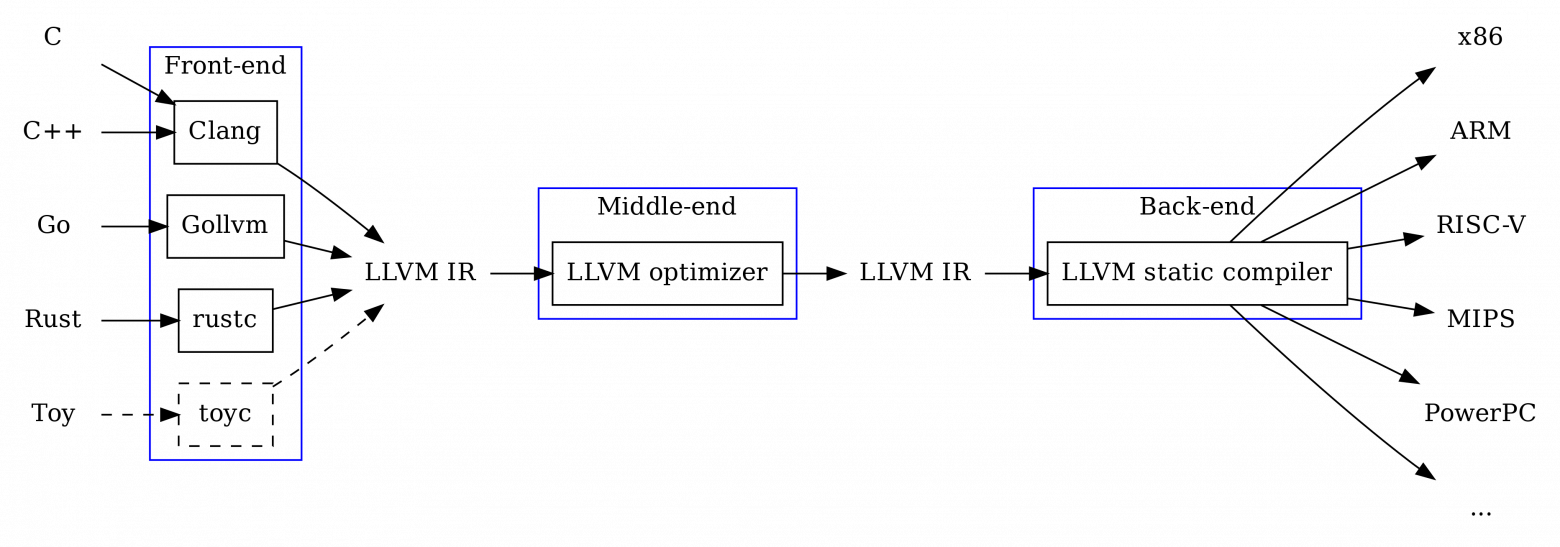
При проектировании компилятора существует огромное преимущество в компиляции исходного языка в промежуточное представление (IR, intermediate representation) вместо компиляции в целевую архитектуру (например, x86).
Так как много техник оптимизации являются общими (например, удаление неиспользуемого кода, распространение констант), эти проходы оптимизации могут быть выполнены напрямую на уровне IR и использоваться всеми целевыми платформами.
Таким образом, компиляторы часто состоят из трёх частей: фронтенд, миддленд и бэкенд, каждая из них выполняет свою задачу, принимая на входе и/или отдавая на выходе IR.
Для того, чтобы получить представление, на что похож ассемблер LLVM IR, рассмотрим следующую программу.
Используем Clang, и скомпилируем приведённый выше код C в ассемблер LLVM IR.
Посмотрев на ассемблерный код LLVM IR выше, мы можем заметить несколько примечательных особенностей LLVM IR, а именно:
LLVM IR статически типизированный (т.е. 32-битные целые посечены типом i32).
Локальные переменные имеют область видимости в пределах функции (т.е. %1 в функции main отличается от %1 в функции @f).
Неименованные (временные регистры) получают локальные идентификаторы (например, %1, %2), в порядке возрастания, в каждой из функций. Каждая функция может использовать бесконечное число регистров (не ограничиваясь 32 регистрами общего назначения). Глобальные идентификаторы (например, @f) и локальные идентификаторы (например, %a, %1) различаются префиксом (@ и %, соответственно).
Большинство команд выполняют то, что вы ожидаете, так, mul выполняет умножение, add сложение, и т.д.
Комментарии начинаются с ;, как это принято в языках ассемблера.
Содержание ассемблерного файла LLVM IR является модулем. Модуль содержит объявления высокого уровня, такие, как глобальные переменные и функции.
Декларация функции не содержит базовых блоков, определение функции содержит один или более базовых блоков (т.е. тело функции).
Более подробный пример модуля LLVM IR приведён ниже. включая определение глобальной переменной @foo и определение функции @f, содержащей три базовых блока (%entry, %block_1 и %block_2).
Базовый блок, это последовательность команд, не являющихся командами перехода (терминирующих команд). Ключевая идея базового блока состоит в том, что если одна команда базового блока выполняется, то выполняются все остальные команды базового блока. Это упрощает анализ потока исполнения.
Команда, не являющаяся командой перехода, обычно выполняет вычисления или доступ к памяти (например, add, load), но не изменяет поток управления программы.
Терминирующая команда находится в конце каждого базового блока, и определяет, куда будет выполнен переход в конце базового блока. Например, терминирующая команда ret возвращает поток управления вызывающей функции, а br выполняет переход, условный или безусловный.
Одно очень важное свойство LLVM IR состоит в том, что он записан в SSA-форме (Static Single Assignment), что, по сути, означает, что каждому регистру выполняется присваивание только один раз. Это свойство упрощает статический анализ потока данных.
Для обработки переменных, которые в оригинальном исходном коде присваиваются более одного раза, в LLVM IR используется команда phi. Команда phi, по существу, возвращает одно значение из набора входных значений, в зависимости от того, по какому пути исполнения была достигнута эта команда. Каждое входное значение, таким образом, ассоциируется с предшествующим входным блоком.
В качестве примера, рассмотрим следующую функцию LLVM IR:
Команда phi (также называемая иногда phi-узлом) в приведённом выше примере моделирует с помощью набора возможных входных значений различные присваивания, по одному на каждый возможный путь в потоке исполнения, ведущий к присваиванию переменной. Например, один из соответствующих путей в потоке данных таков:
В целом, когда разрабатывают компилятор, преобразующий исходный код в LLVM IR, все локальные переменные исходного кода могут быть преобразованы в форму SSA, за исключением переменных, для которых берётся их адрес.
Для упрощения реализации фронтенда LLVM, рекомендуется моделировать локальные переменные в исходном языке как аллоцируемые в памяти переменные (используя alloca), моделируя присваивания локальным переменным как записи в память, а использования локальной переменной — как чтения из памяти. Причина состоит в том, что может оказаться нетривиальной задачей напрямую транслировать исходный язык в LLVM IR в SSA-форме. До тех пор, пока доступы к памяти следуют определённым паттернам, мы можем положиться на проход оптимизации mem2reg в составе LLVM для преобразования аллоцированных в памяти локальных переменных в регистры в SSA-форме (с использованием phi-узлов там, где это необходимо).
Есть две главные библиотеки для работы с LLVM IR в Go:
https://godoc.org/llvm.org/llvm/bindings/go/llvm: официальные биндинги LLVM для языка Go.
github.com/llir/llvm: чистая библиотека Go для взаимодействия с LLVM IR.
Официальные биндинги LLVM для языка Go используют Cgo для того, чтобы предоставить доступ к богатому и мощному API фреймворка компилятора LLVM, в то время, как проект llir/llvm полностью написан на Go и использует LLVM IR для взаимодействия с фреймворком LLVM.
Эта статья сфокусирована на llir/llvm, но может быть обобщена для работы и с другими библиотеками.
Главной мотивацией для разработки чистой библиотеки на Go для взаимодействия с LLVM IR было сделать более весёлым занятием написание компиляторов и инструментов статического анализа, которые основаны на фреймворке компиляции LLVM IR. Также повлияло то, что время компиляции проекта, основанного на официальных биндингах LLVM с Go может быть существенным (благодаря @aykevl, автору TinyGo, сейчас возможно ускорение компиляции за счёт динамической линковки, в противовес стандартной версии LLVM 4).
Другой большой мотивацией было попробовать разработать Go API с нуля. Главным различием между API LLVM биндингов для Go и llir/llvm состоит в том, как моделируются значения LLVM. В LLVM биндингах для Go значения LLVM моделируются как конкретный структурный тип, который, по сути, содержит все возможные методы для всех возможных значений LLVM. Мой личный опыт с использованием этого API говорит о том, что трудно узнать, какое подмножество методов разрешено вызывать для данного значения. Например, для получения опкода инструкции, вы вызываете метод InstructionOpcode, что интуитивно понятно. Однако, если вы вызовете вместо этого метод Opcode, который предназначен для получения опкода константного выражения, вы получите runtime error: “cast() argument of incompatible type!” (преобразование аргумента к несовместимому типу).
Библиотека llir/llvm была разработана так, что проверяет типы в compile-time и гарантирует их правильное использование с системой типов Go. LLVM-значения в llir/llvm моделируются как интерфейсные типы. Такой подход делает доступными только минимальный набор методов, разделяемых всеми значениями, и если вы хотите получить доступ к специфичным методам или полям, используйте переключение типов (как показано в примере ниже).
Сейчас давайте рассмотрим несколько примеров конкретного использования. пусть у нас есть библиотека, но что мы должны делать с LLVM IR?
Во-первых, мы можем захотеть распарсить LLVM IR, сгенерированный другим инструментом, таким, как Clang и оптимизатором LLVM opt (см. пример входного кода ниже).
Во-вторых, мы можем захотеть обрабатывать LLVM IR и производить над ним свой собственный анализ, или делать собственные проходы оптимизации, или реализовать интерпретатор, или JIT-компилятор (см. пример анализа ниже).
В-третьих, мы можем захотеть генерировать LLVM IR, который будет входным для других инструметов. Такой подход можно избрать, если мы разрабатываем фронтенд для нового языка программирования (см. пример выходного кода ниже).
Пример входного кода — парсинг LLVM IR
Пример анализа — обрабатываем LLVM IR
Пример выходного кода — генерация LLVM IR
Разработка и реализация llir/llvm производилась и направлялась сообществом контрибьюторов, которые не только писали код, но также вели обсуждения, сессии парного программирования, производили отладку, профилирование, и проявляли любознательность в процессе обучения.
Одна из самых сложных частей проекта llir/llvm было конструирование грамматики EBNF для LLVM IR, покрывающей весь язык LLVM IR до версии LLVM 7.0. Сложность здесь не в самом по себе процессе, а в том, что не существует официально опубликованной грамматики, покрывающей весь язык. Некоторые опенсорсные сообщества пытались определить формальную грамматику для ассемблера LLVM, но они покрывают, насколько мы знаем, только подмножества языка.
Грамматика LLVM IR открывает путь интересным проектам. Например, генерация синтаксически валидного ассемблера LLVM IR, может быть использована для различных инструментов и библиотек, использующих LLVM IR, сходный подход использован в GoSmith. Это может быть использовано для кроссвалидации проектов LLVM, реализованных в других языках, и также проверок на уязвимости и баги реализации.
Будущее прекрасно, счастливого хакинга!
1. Очень хорошо написанная глава про LLVM, написанная Крисом Латтнером – автором начального проекта LLVM, в книге «Architecture of Open Source Applications».
2. The Implement a language with LLVM tutorial – часто именуемая также руководством по языку Калейдоскоп – описывает в деталях, как реализовать простой язык программирования, компилируемый в LLVM IR. Статья описывает все главные стадии написания фронтенда, включая лексический анализатор, парсер и генерацию кода.
3. Для тех, кто заинтересован в написании компилятора из входного языка в LLVM IR, рекомендуется книга "Mapping High Level Constructs to LLVM IR".
Хороший набор слайдов — LLVM, in Great Detail, который описывает важные концепции LLVM IR, даётся введение в LLVM C++ API, и описываются очень полезные проходы оптимизации LLVM.
Официальные биндинги Go для LLVM подходят для множества проектов, представляют LLVM C API, мощный и стабильный.
Хорошим дополнением к посту является статья An introduction to LLVM in Go.
TL;DR мы написали библиотеку для взаимодействия с LLVM IR на чистом Go, см. ссылки на код и на пример проекта.
Простой пример на LLVM IR
(Те из вас, кто знаком с LLVM IR, могут перейти к следующему разделу).
LLVM IR — это низкоуровневое промежуточное представление, используемое фреймворком компиляции LLVM. Вы можете думать об LLVM IR как о платформенно-независимом ассемблере с бесконечным количеством локальных регистров.
При проектировании компилятора существует огромное преимущество в компиляции исходного языка в промежуточное представление (IR, intermediate representation) вместо компиляции в целевую архитектуру (например, x86).
Спойлер
Идея использования промежуточного языка в компиляторах широко распространена. GCC использует GIMPLE, Roslyn использует CIL, LLVM использует LLVM IR.
Так как много техник оптимизации являются общими (например, удаление неиспользуемого кода, распространение констант), эти проходы оптимизации могут быть выполнены напрямую на уровне IR и использоваться всеми целевыми платформами.
Спойлер
Использование промежуточного языка (IR), таким образом, уменьшает количество комбинаций, требуемых для n исходных языков и m целевых архитектур (бэкендов) с n * m до n + m.
Таким образом, компиляторы часто состоят из трёх частей: фронтенд, миддленд и бэкенд, каждая из них выполняет свою задачу, принимая на входе и/или отдавая на выходе IR.
- Фронтенд: компилирует исходный язык в IR
- Миддленд: оптимизирует IR
- Бэкенд: компилирует IR в машинный код
Пример программы на ассемблере LLVM IR
Для того, чтобы получить представление, на что похож ассемблер LLVM IR, рассмотрим следующую программу.
int f(int a, int b) { return a + 2*b; } int main() { return f(10, 20); }
Используем Clang, и скомпилируем приведённый выше код C в ассемблер LLVM IR.
Clang
clang -S -emit-llvm -o foo.ll foo.c.
define i32 @f(i32 %a, i32 %b) { ; <label>:0 %1 = mul i32 2, %b %2 = add i32 %a, %1 ret i32 %2 } define i32 @main() { ; <label>:0 %1 = call i32 @f(i32 10, i32 20) ret i32 %1 }
Посмотрев на ассемблерный код LLVM IR выше, мы можем заметить несколько примечательных особенностей LLVM IR, а именно:
LLVM IR статически типизированный (т.е. 32-битные целые посечены типом i32).
Локальные переменные имеют область видимости в пределах функции (т.е. %1 в функции main отличается от %1 в функции @f).
Неименованные (временные регистры) получают локальные идентификаторы (например, %1, %2), в порядке возрастания, в каждой из функций. Каждая функция может использовать бесконечное число регистров (не ограничиваясь 32 регистрами общего назначения). Глобальные идентификаторы (например, @f) и локальные идентификаторы (например, %a, %1) различаются префиксом (@ и %, соответственно).
Большинство команд выполняют то, что вы ожидаете, так, mul выполняет умножение, add сложение, и т.д.
Комментарии начинаются с ;, как это принято в языках ассемблера.
Структура ассемблера LLMV IR
Содержание ассемблерного файла LLVM IR является модулем. Модуль содержит объявления высокого уровня, такие, как глобальные переменные и функции.
Декларация функции не содержит базовых блоков, определение функции содержит один или более базовых блоков (т.е. тело функции).
Более подробный пример модуля LLVM IR приведён ниже. включая определение глобальной переменной @foo и определение функции @f, содержащей три базовых блока (%entry, %block_1 и %block_2).
; Глобальная переменная, инициализированная 32-битным значением 21 @foo = global i32 21 ; f возвращает 42, если условие cond истинно, и 0 в другом случае define i32 @f(i1 %cond) { ; Входной базовый блок функции не содержит команд, не являющихся командами перехода ; и заканчивается командой условного перехода entry: ; терминирующая команда условного перехода br передаёт управление в block_1, если %cond ; истинно, и в block_2 в ином случае. br i1 %cond, label %block_1, label %block_2 ; Базовый блок содержит две команды, не являющиеся командами перехода, и заканчивается командой возврата block_1: %tmp = load i32, i32* @foo %result = mul i32 %tmp, 2 ret i32 %result ; Базовый блок не содержит команд, не являющихся командами условного перехода, и заканчивается командой возврата block_2: ret i32 0 }
Базовый блок
Базовый блок, это последовательность команд, не являющихся командами перехода (терминирующих команд). Ключевая идея базового блока состоит в том, что если одна команда базового блока выполняется, то выполняются все остальные команды базового блока. Это упрощает анализ потока исполнения.
Команда
Команда, не являющаяся командой перехода, обычно выполняет вычисления или доступ к памяти (например, add, load), но не изменяет поток управления программы.
Терминирующая команда
Терминирующая команда находится в конце каждого базового блока, и определяет, куда будет выполнен переход в конце базового блока. Например, терминирующая команда ret возвращает поток управления вызывающей функции, а br выполняет переход, условный или безусловный.
SSA-форма
Одно очень важное свойство LLVM IR состоит в том, что он записан в SSA-форме (Static Single Assignment), что, по сути, означает, что каждому регистру выполняется присваивание только один раз. Это свойство упрощает статический анализ потока данных.
Для обработки переменных, которые в оригинальном исходном коде присваиваются более одного раза, в LLVM IR используется команда phi. Команда phi, по существу, возвращает одно значение из набора входных значений, в зависимости от того, по какому пути исполнения была достигнута эта команда. Каждое входное значение, таким образом, ассоциируется с предшествующим входным блоком.
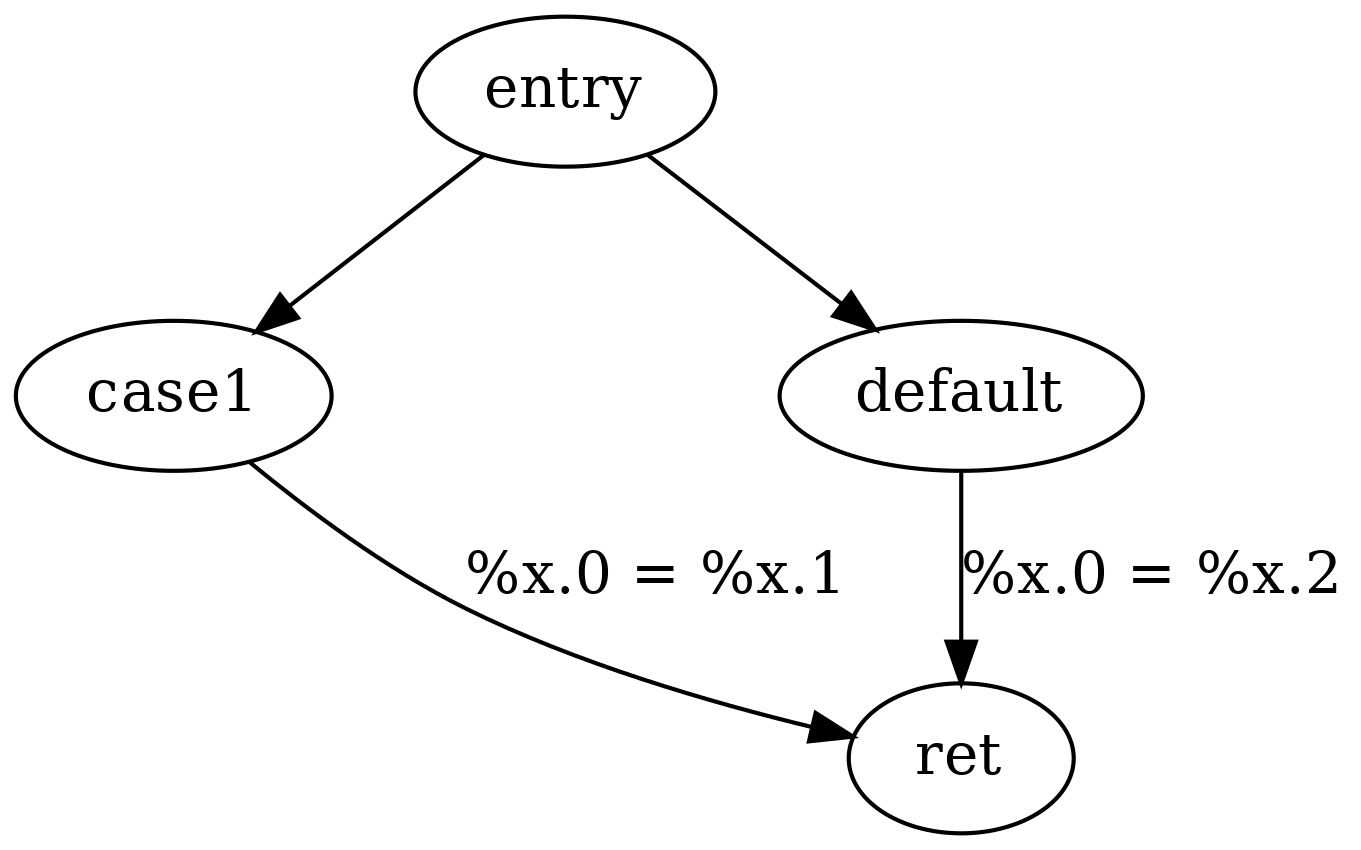
В качестве примера, рассмотрим следующую функцию LLVM IR:
define i32 @f(i32 %a) { ; <label>:0 switch i32 %a, label %default [ i32 42, label %case1 ] case1: %x.1 = mul i32 %a, 2 br label %ret default: %x.2 = mul i32 %a, 3 br label %ret ret: %x.0 = phi i32 [ %x.2, %default ], [ %x.1, %case1 ] ret i32 %x.0 }
Команда phi (также называемая иногда phi-узлом) в приведённом выше примере моделирует с помощью набора возможных входных значений различные присваивания, по одному на каждый возможный путь в потоке исполнения, ведущий к присваиванию переменной. Например, один из соответствующих путей в потоке данных таков:
В целом, когда разрабатывают компилятор, преобразующий исходный код в LLVM IR, все локальные переменные исходного кода могут быть преобразованы в форму SSA, за исключением переменных, для которых берётся их адрес.
Для упрощения реализации фронтенда LLVM, рекомендуется моделировать локальные переменные в исходном языке как аллоцируемые в памяти переменные (используя alloca), моделируя присваивания локальным переменным как записи в память, а использования локальной переменной — как чтения из памяти. Причина состоит в том, что может оказаться нетривиальной задачей напрямую транслировать исходный язык в LLVM IR в SSA-форме. До тех пор, пока доступы к памяти следуют определённым паттернам, мы можем положиться на проход оптимизации mem2reg в составе LLVM для преобразования аллоцированных в памяти локальных переменных в регистры в SSA-форме (с использованием phi-узлов там, где это необходимо).
Библиотека LLVM IR на чистом Go
Есть две главные библиотеки для работы с LLVM IR в Go:
https://godoc.org/llvm.org/llvm/bindings/go/llvm: официальные биндинги LLVM для языка Go.
github.com/llir/llvm: чистая библиотека Go для взаимодействия с LLVM IR.
Официальные биндинги LLVM для языка Go используют Cgo для того, чтобы предоставить доступ к богатому и мощному API фреймворка компилятора LLVM, в то время, как проект llir/llvm полностью написан на Go и использует LLVM IR для взаимодействия с фреймворком LLVM.
Эта статья сфокусирована на llir/llvm, но может быть обобщена для работы и с другими библиотеками.
Зачем писать новую библиотеку?
Главной мотивацией для разработки чистой библиотеки на Go для взаимодействия с LLVM IR было сделать более весёлым занятием написание компиляторов и инструментов статического анализа, которые основаны на фреймворке компиляции LLVM IR. Также повлияло то, что время компиляции проекта, основанного на официальных биндингах LLVM с Go может быть существенным (благодаря @aykevl, автору TinyGo, сейчас возможно ускорение компиляции за счёт динамической линковки, в противовес стандартной версии LLVM 4).
Спойлер
Проект github.com/aykevl/go-llvm предоставляет биндинги Go для установленного в системе LLVM.
Другой большой мотивацией было попробовать разработать Go API с нуля. Главным различием между API LLVM биндингов для Go и llir/llvm состоит в том, как моделируются значения LLVM. В LLVM биндингах для Go значения LLVM моделируются как конкретный структурный тип, который, по сути, содержит все возможные методы для всех возможных значений LLVM. Мой личный опыт с использованием этого API говорит о том, что трудно узнать, какое подмножество методов разрешено вызывать для данного значения. Например, для получения опкода инструкции, вы вызываете метод InstructionOpcode, что интуитивно понятно. Однако, если вы вызовете вместо этого метод Opcode, который предназначен для получения опкода константного выражения, вы получите runtime error: “cast() argument of incompatible type!” (преобразование аргумента к несовместимому типу).
Библиотека llir/llvm была разработана так, что проверяет типы в compile-time и гарантирует их правильное использование с системой типов Go. LLVM-значения в llir/llvm моделируются как интерфейсные типы. Такой подход делает доступными только минимальный набор методов, разделяемых всеми значениями, и если вы хотите получить доступ к специфичным методам или полям, используйте переключение типов (как показано в примере ниже).
Пример использования
Сейчас давайте рассмотрим несколько примеров конкретного использования. пусть у нас есть библиотека, но что мы должны делать с LLVM IR?
Во-первых, мы можем захотеть распарсить LLVM IR, сгенерированный другим инструментом, таким, как Clang и оптимизатором LLVM opt (см. пример входного кода ниже).
Во-вторых, мы можем захотеть обрабатывать LLVM IR и производить над ним свой собственный анализ, или делать собственные проходы оптимизации, или реализовать интерпретатор, или JIT-компилятор (см. пример анализа ниже).
В-третьих, мы можем захотеть генерировать LLVM IR, который будет входным для других инструметов. Такой подход можно избрать, если мы разрабатываем фронтенд для нового языка программирования (см. пример выходного кода ниже).
Пример входного кода — парсинг LLVM IR
// этот пример программы парсит файл ассемблера LLVM IR, и печатает распарсенный // модуль в стандартный вывод package main import ( "fmt" "github.com/llir/llvm/asm" ) func main() { // Парсим ассемблерный файл LLVM IR. m, err := asm.ParseFile("foo.ll") if err != nil { panic(err) } // обрабатываем, интерпретируем или оптимизируем LLVM IR. // Print LLVM IR module. fmt.Println(m) }
Пример анализа — обрабатываем LLVM IR
// Этот пример программы анализа модуля LLVM IR производит граф вызовов в // формате Graphviz DOT package main import ( "bytes" "fmt" "io/ioutil" "github.com/llir/llvm/asm" "github.com/llir/llvm/ir" ) func main() { // Парсим ассемблерный файл LLVM IR. m, err := asm.ParseFile("foo.ll") if err != nil { panic(err) } // генерируем граф вызовов модуля. callgraph := genCallgraph(m) // выводим граф вызовов в формате Graphviz DOT. if err := ioutil.WriteFile("callgraph.dot", callgraph, 0644); err != nil { panic(err) } } // genCallgraph возвращает граф вызовов в формате Graphviz DOT для данного модуля LLVM IR func genCallgraph(m *ir.Module) []byte { buf := &bytes.Buffer{} buf.WriteString("digraph {\n") // Для каждой функции в модуле for _, f := range m.Funcs { // Вызывающий узел caller := f.Ident() fmt.Fprintf(buf, "\t%q\n", caller) // Для каждого базового блока в функции for _, block := range f.Blocks { // Для каждой команды, не являющейса командой перехода в базовом блоке. for _, inst := range block.Insts { // Тип инструкции. Находим команду call. switch inst := inst.(type) { case *ir.InstCall: callee := inst.Callee.Ident() // Добавляем ребро графа с вызывающей функции до вызываемой. fmt.Fprintf(buf, "\t%q -> %q\n", caller, callee) } } // Завершающие команды базового блока switch term := block.Term.(type) { case *ir.TermRet: // делаем что-то _ = term } } } buf.WriteString("}") return buf.Bytes() }
Пример выходного кода — генерация LLVM IR
// Этот пример генерирует код LLVM IR, эквивалентный следующему коду C, // реализующему генератор псевдослучайных чисел. // // int abs(int x); // // int seed = 0; // // // ref: https://en.wikipedia.org/wiki/Linear_congruential_generator // // a = 0x15A4E35 // // c = 1 // int rand(void) { // seed = seed*0x15A4E35 + 1; // return abs(seed); // } package main import ( "fmt" "github.com/llir/llvm/ir" "github.com/llir/llvm/ir/constant" "github.com/llir/llvm/ir/types" ) func main() { // Создаём нужные типы и константы i32 := types.I32 zero := constant.NewInt(i32, 0) a := constant.NewInt(i32, 0x15A4E35) // умножаем PRNG. c := constant.NewInt(i32, 1) // инкрементируем PRNG. // Создаём новый модуль LLVM IR. m := ir.NewModule() // Создаём объявление внешней функции и добавляем его к модулю. // // int abs(int x); abs := m.NewFunc("abs", i32, ir.NewParam("x", i32)) // Создаём определение глобальной переменной и добавляем его к модулю. // // int seed = 0; seed := m.NewGlobalDef("seed", zero) // Создаём определение функции и добавляем его к модулю. // // int rand(void) { ... } rand := m.NewFunc("rand", i32) // Создаём неименованный входной базовый блок и добавляем его к функции `rand`. entry := rand.NewBlock("") // Создаём команды и добавляем их к входному базовому блоку. tmp1 := entry.NewLoad(seed) tmp2 := entry.NewMul(tmp1, a) tmp3 := entry.NewAdd(tmp2, c) entry.NewStore(tmp3, seed) tmp4 := entry.NewCall(abs, tmp3) entry.NewRet(tmp4) // Печатаем ассемблер LLVM IR этого модуля. fmt.Println(m) }
Заключение
Разработка и реализация llir/llvm производилась и направлялась сообществом контрибьюторов, которые не только писали код, но также вели обсуждения, сессии парного программирования, производили отладку, профилирование, и проявляли любознательность в процессе обучения.
Одна из самых сложных частей проекта llir/llvm было конструирование грамматики EBNF для LLVM IR, покрывающей весь язык LLVM IR до версии LLVM 7.0. Сложность здесь не в самом по себе процессе, а в том, что не существует официально опубликованной грамматики, покрывающей весь язык. Некоторые опенсорсные сообщества пытались определить формальную грамматику для ассемблера LLVM, но они покрывают, насколько мы знаем, только подмножества языка.
Грамматика LLVM IR открывает путь интересным проектам. Например, генерация синтаксически валидного ассемблера LLVM IR, может быть использована для различных инструментов и библиотек, использующих LLVM IR, сходный подход использован в GoSmith. Это может быть использовано для кроссвалидации проектов LLVM, реализованных в других языках, и также проверок на уязвимости и баги реализации.
Будущее прекрасно, счастливого хакинга!
Ссылки
1. Очень хорошо написанная глава про LLVM, написанная Крисом Латтнером – автором начального проекта LLVM, в книге «Architecture of Open Source Applications».
2. The Implement a language with LLVM tutorial – часто именуемая также руководством по языку Калейдоскоп – описывает в деталях, как реализовать простой язык программирования, компилируемый в LLVM IR. Статья описывает все главные стадии написания фронтенда, включая лексический анализатор, парсер и генерацию кода.
3. Для тех, кто заинтересован в написании компилятора из входного языка в LLVM IR, рекомендуется книга "Mapping High Level Constructs to LLVM IR".
Хороший набор слайдов — LLVM, in Great Detail, который описывает важные концепции LLVM IR, даётся введение в LLVM C++ API, и описываются очень полезные проходы оптимизации LLVM.
Официальные биндинги Go для LLVM подходят для множества проектов, представляют LLVM C API, мощный и стабильный.
Хорошим дополнением к посту является статья An introduction to LLVM in Go.

