
В 1985 году Институт инженеров электротехники и электроники (IEEE) установил стандарт IEEE 754, отвечающий за форматы чисел с плавающей запятой и арифметики, которому суждено будет стать образцом для всего железа и ПО на следующие 30 лет.
И хотя большинство программистов использует плавающую точку в любой момент без разбора, когда им нужно проводить математические операции с вещественными числами, из-за определённых ограничений представления этих чисел, быстродействие и точность таких операций часто оставляют желать лучшего.
Много лет стандарт подвергался резкой критике со стороны специалистов по информатике, знакомых с этими проблемами, однако больше всего среди них выделялся Джон Густафсон, в одиночку ведший крестовый поход с целью замены плавающей запятой на что-то более подходящее. В данном случае более подходящим вариантом считается posit или unum – третий вариант результата его исследования «универсальных чисел». Он говорит, что числа формата posit решат большинство главнейших проблем стандарта IEEE 754, дадут улучшенную производительность и точность, и при этом будут использовать меньше битов. Что ещё лучше, он заявляет, что новый формат может заменить стандартные числа с плавающей запятой «на лету», без необходимости менять исходный код приложений.
Мы встретились с Густафсоном на конференции ISC19. И для находящихся там специалистов, занимающихся суперкомпьютерами, одно из главных преимуществ формата posit состоит в том, что можно достичь большей точности и динамического диапазона, используя меньше битов, чем числа из IEEE 754. И не просто немного меньше. Густафсон сказал, что 32-битный posit заменяет 64-битное float почти во всех случаях, что может иметь серьёзные последствия для научных вычислений. Если уполовинить количество битов, можно не только уменьшить объёмы кэша, памяти и хранилища для этих чисел, но и серьёзно уменьшить ширину канала, необходимого для передачи их на процессор и обратно. Это главная причина, по которой арифметика на базе posit, по его мнению, даст от двойного до четверного ускорения расчётов по сравнению с числами с плавающей запятой от IEEE.
Ускорения можно будет достичь через уплотнённое представление вещественных чисел. Вместо экспоненты и дробной части фиксированного размера, используемой в стандарте IEEE, posit кодирует экспоненту переменным количеством бит (комбинацией битов режима и битов экспоненты), так, что в большинстве случаев их требуется меньше. В итоге на дробную часть остаётся больше битов, что даёт большую точность. Динамическую экспоненту стоит использовать благодаря её сужающейся точности. Это означает, что величины с небольшой экспонентой, которые чаще всего используются, могут иметь большую точность, а реже используемые очень крупные и очень мелкие числа будут иметь меньшую точность. Работа Густафсона от 2017 года, описывающая формат posit, даёт подробное описание того, как это работает.
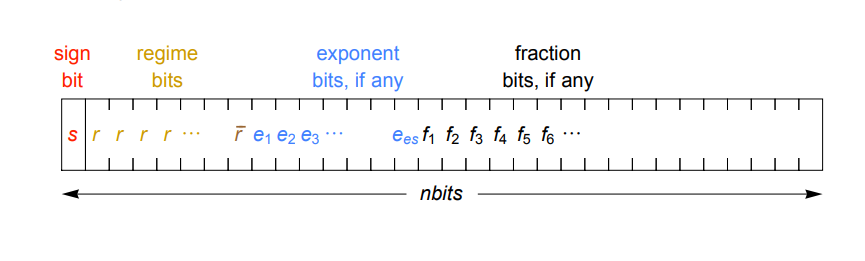
Ещё одно важное преимущество формата в том, что, в отличие от обычных чисел с плавающей запятой, posit дают одинаковые побитовые результаты на любой системе, чего часто нельзя гарантировать с форматом от IEEE (тут даже одинаковые вычисления на одной и той же системе могут дать разные результаты). Также новый формат расправляется с ошибками округления, переполнением и исчезновением значащих разрядов, денормализованными числами, и множеством значений типа not-a-number (NaN). Кроме того, posit избегает такой странности, как несовпадающие значения 0 и -0. Вместо этого формат использует для знака двоичное дополнение, как у целых чисел, что означает, что побитовое сравнение будет выполняться правильно.
С числами posit связано нечто под названием quire – механизм накопления, позволяющий программистам выполнять воспроизводимую линейную алгебру – процесс, недоступный обычным числам формата IEEE. Он поддерживает обобщённую операцию совмещённого умножения-сложения и другие совмещённые операции, позволяющие вычислять скалярные произведения или суммы без ошибок округления или переполнений. Тесты, запущенные в Калифорнийском университете в Беркли, продемонстрировали, что операции quire проходят в 3-6 раз быстрее, чем последовательное их выполнение. Густафсон говорит, что они позволяют числам posit «драться за пределами своей весовой категории».
Хотя этот формат чисел существует всего пару лет, в сообществе специалистов по высокопроизводительным вычислениям (HPC) уже есть интерес к изучению возможностей их применения. В настоящий момент вся работа остаётся экспериментальной, и основана на предполагаемом быстродействии будущего железа или на использовании инструментов, эмулирующих posit-арифметику на обычных процессорах. Пока в производстве нет чипов, реализующих posit на аппаратном уровне.
Одно из потенциальных применений формата – строящийся радиоинтерферометр Square Kilometer Array (SKA), при проектировании которого рассматривают числа posit как способ кардинально уменьшить ширину канала и вычислительную нагрузку для обработки данных, поступающих с радиотелескопа. Необходимо, чтобы обслуживающие его суперкомпьютеры потребляли не более 10 МВт, и один из наиболее многообещающих способов достичь этого, по мнению проектировщиков, — использовать более плотный формат posit для того, чтобы вдвое урезать предполагаемую ширину канала памяти (200 ПБ/сек), канала передачи данных (10 ТБ/сек) и сетевого соединения (1 ТБ/сек). Вычислительная мощность также должна возрасти.
Ещё одно применение – использование в предсказаниях погоды и прогнозированиях климата. Британская команда показала, что 16-битные числа posit явно опережают стандартные 16-битные числа с плавающей запятой, и у них «есть прекрасный потенциал для использования в более сложных моделях». 16-битная эмуляция posit в этой модели работала так же хорошо, как 64-битные числа с плавающей запятой.
Ливерморская национальная лаборатория оценивает posit и другие форматы чисел, изучая возможности уменьшения количества перемещаемых данных в эксафлопсных суперкомпьютерах будущего. В некоторых случаях у них тоже получились лучшие результаты. К примеру, числа posit смогли дать превосходящую точность в таких физических расчётах, как ударная гидродинамика, и в целом опередили числа с плавающей запятой в различных измерениях.

Возможно, наибольшими возможностями posit будут обладать в области машинного обучения, где 16-битные числа можно использовать для обучения, а 8-битные – для проверки. Густафсон сказал, что для обучения 32-битные числа с плавающей точкой являются перебором, и в некоторых случаях они даже не демонстрируют таких хороших результатов, как 16-битные posit, пояснив, что стандарт IEEE 754 «абсолютно не был предназначен для использования с ИИ».
Неудивительно, что на них обратило внимание и ИИ-сообщество. Джефф Джонсон из Facebook разработал экспериментальную платформу с FGPA при помощи posit, демонстрирующую лучшую энергоэффективность по сравнению как с float16, так и с bfloat16 от IEEE на задачах по машинному обучению. Они планируют исследовать использование 16-битных аппаратных quire для обучения и сравнить их с конкурирующими форматами.
Стоит отметить, что Facebook работает с Intel над процессором Nervana Neural Network (NNP), который должен ускорить некоторые из задач социального гиганта, связанные с ИИ. Не исключается вариант использования формата posit, хотя более вероятно, что Intel оставит для Nervana его изначальный формат FlexPoint. В любом случае, этот момент стоит отслеживать.
Густафсону известно, по крайней мере, об одном ИИ-чипе, в котором пытаются использовать числа posit при проектировании, хотя он не имеет права разглашать названия компании. Французская компания Kalray, работающая с инициативой European Processor Initiative (EPI), также продемонстрировала интерес в поддержке posit в их ускорителе следующего поколения Massively Parallel Processor Array (MPPA), поэтому эта технология может попасть на европейские эксафлопсные суперкомпьютеры.
Густафсона всё это, естественно, вдохновляет, и он считает, что эта третья попытка продвижения его универсальных чисел может увенчаться успехом. В отличие от версий один и два, posit легко реализовать в железе. А учитывая яростную конкуренцию в области ИИ, возможно, стоит ожидать коммерческого успеха нового формата. Среди других платформ, на которых posit может ожидать блестящее будущее – цифровая обработка сигналов, GPU (для графики и других вычислений), устройства для интернета вещей, edge computing. И, конечно же, HPC.
Если технология получит коммерческое распространение, Густафсон вряд ли сможет заработать на её успехе. Его проект, как указано в 10-страничном стандарте, полностью открыт, и доступен для использования любой компанией, желающей разработать соответствующие ПО и железо. Что, вероятно, объясняет внимание к технологии со стороны таких компаний, как IBM, Google, Intel, Micron, Rex Computing, Qualcomm, Fujitsu, Huawei и многих других.
Тем не менее, замена IEEE 754 чем-то более подходящим – огромнейший проект, даже для человека с таким впечатляющим резюме, как у Густафсона. Ещё до того, как поработать в ClearSpeed, Intel и AMD, он изучал способы улучшения научных расчётов на современных процессорах. «Я пытался разобраться в этом вопросе последние 30 лет», — сказал он.

