Когда речь заходит о мониторинге безопасности внутренней корпоративной или ведомственной сети, то у многих возникает ассоциация с контролем утечек информации и внедрением DLP-решений. А если попробовать уточнить вопрос и спросить, как вы обнаруживаете атаки во внутренней сети, то ответом будет, как правило, упоминание систем обнаружения атак (intrusion detection systems, IDS). И то, что было единственным вариантом еще лет 10-20 назад, то сегодня становится анахронизмом. Существует более эффективный, а местами и единственно возможный вариант мониторинга внутренней сети — использовать flow-протоколов, изначально предназначенных для поиска сетевых проблем (troubleshooting), но со временем трансформировавшихся в очень интересный инструмент безопасности. Вот о том, какие flow-протоколы бывают и какие из них лучше помогают обнаруживать сетевые атаки, где лучше всего внедрять мониторинг flow, на что обратить внимание при развертывании такой схемы, и даже как это все “поднять” на отечественном оборудовании, мы и поговорим в рамках данной статьи.
Я не буду останавливаться на вопросе “Зачем нужен мониторинг безопасности внутренней инфраструктуры?” Ответ на него вроде и так понятен. Но если все-таки вы хотели бы еще раз убедиться, что сегодня без этого никуда, посмотрите небольшое видео с рассказом о том, как можно 17-тью способами проникнуть в корпоративную сеть, защищенную межсетевым экраном. Поэтому будем считать, что мы понимаем, что внутренний мониторинг — штука нужная и осталось только понять, как его можно организовать.
Я бы выделил три ключевых источника данных для мониторинга инфраструктуры на сетевом уровне:

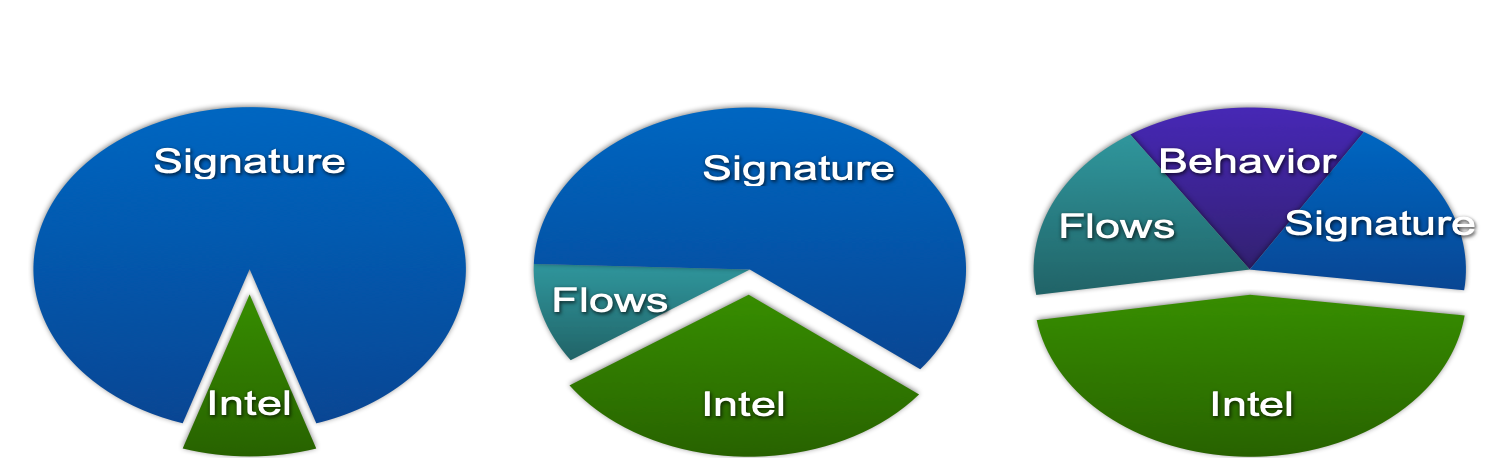
Захват сырого трафика — самый популярный у безопасников вариант, потому что он исторически появился и самым первым. Обычные сетевые системы обнаружения атак (самой первой коммерческой системой обнаружения атак была NetRanger от компании Wheel Group, купленная в 1998-м году Cisco) как раз и занимались захватом пакетов (а позже и сессий), в которых искались определенные сигнатуры (“решающие правила” в терминологии ФСТЭК), сигнализирующие об атаках. Разумеется, анализировать сырой трафик можно не только с помощью IDS, но и с помощью иных средств (например, Wireshark, tcpdum или функционал NBAR2 в Cisco IOS), но им обычно не хватает базы знаний, которая отличает средство ИБ от обычного ИТ-инструмента.
Итак, системы обнаружения атак. Самый старый и самый популярный метод обнаружения сетевых атак, который неплохо справляется со своей задачей на периметре (неважно каком — корпоративном, ЦОДа, сегмента и т.п.), но пасует в современных коммутируемых и программно-определяемых сетях. В случае с сетью, построенной на базе обычных коммутаторов, инфраструктура сенсоров обнаружения атак становится слишком большой — вам придется ставить по сенсору на каждый соединение с узлом, атаки на который вы хотите мониторить. Любой производитель, конечно, будет рад продать вам сотни и тысячи сенсоров, но думаю ваш бюджет не выдержить таких расходов. Могу сказать, что даже в Cisco (а мы являемся разработчиками NGIPS) мы не смогли это сделать, хотя, казалось бы, вопрос цены перед нами. стоять не должен — это же наше собственное решение. Кроме того, возникает вопрос, а как подключать сенсор в таком варианте? В разрыв? А если сам сенсор будет выведен из строя? Требовать наличия bypass-модуля в сенсоре? Использовать разветвители (tap)? Все это удорожает решение и делает его неподъемным для компании любого масштаба.
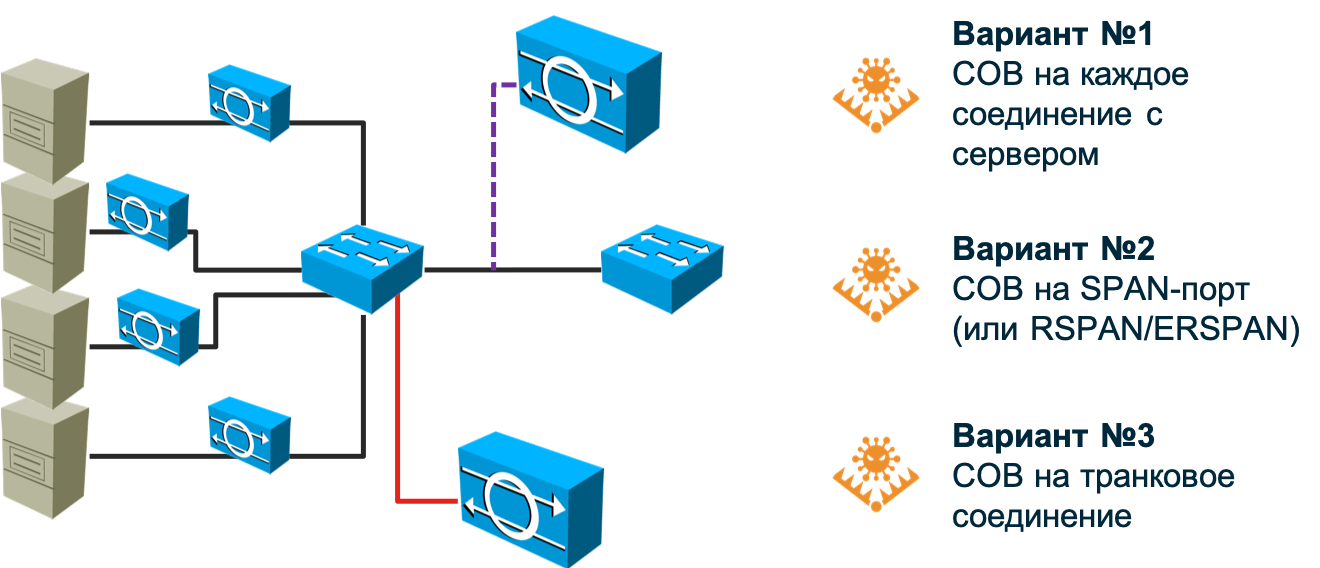
Можно попробовать “повесить” сенсор на SPAN/RSPAN/ERSPAN-порт и направить на него трафик с необходимых портов коммутатора. Этот вариант частично снимает проблему, описанную в предыдущем абзаце, но ставит другую — SPAN-порт не может принять абсолютно весь трафик, который в него будет направляться — ему не хватит пропускной способности. Приджется чем-то жертвовать. Или часть узлов оставить без мониторинга (тогда предварительно вам надо провести их приоритезацию), или направлять не весь трафик с узла, а только определенного типа. В любой случае мы можем пропустить какие-то атаки. Кроме того, SPAN-порт может быть занят под другие нужды. В итоге, нам придется пересмотреть существующую топологию сети и внести, возможно, в нее коррективы, чтобы охватить по максимуму вашу сеть имеющимся у вас числом сенсоров (и согласовать это с ИТ).
А если у вас сеть использует асимметричные маршруты? А если у вас внедрен или планируется к внедрению SDN? А если вам надо мониторить виртуализированные машины или контейнеры, трафик которых вообще не доходит до физического коммутатора? Эти вопросы не любят производители традиционных IDS, потому что не знают, как ответить на них. Возможно, они будут склонять вас к тому, что все эти модные технологии — хайп и вам он не нужен. Возможно, они будут говорить о необходимости начать с малого. А может быть быть они скажут, что вам надо поставить мощную молотилку в центр сети и направить весь трафик в нее с помощью балансировщиков. Какой бы вариант вам не предлагали, вам нужно самим четко понять, насколько он вам подходит. И только после этого принимать решение о выборе подхода к мониторингу ИБ сетевой инфраструктуры. Возвращаясь же к захвату пакетов, хочу сказать, что этот метод продолжает оставаться очень популярным и важным, но его основное предназначение — контроль границ; границ между вашей организацией и Интернет, границ между ЦОДом и остальной сетью, границ между АСУ ТП и корпоративным сегментом. В этих местах классические IDS/IPS по-прежнему имеют право на существование и неплохо справляются с поставленными задачами.
Перейдем ко второму варианту. Анализ событий, поступаемых с сетевых устройств, тоже может быть использован для целей обнаружения атак, но не как основной механизм, так как он позволяет детектировать только небольшой класс вторжений. К тому же ему присуща некоторая реактивность — атака сначала должна произойти, потом она должна быть зафиксирована сетевым устройством, которое тем или иным способом будет сигнализировать о проблеме с ИБ. Способов таких несколько. Это может быть syslog, RMON или SNMP. Последние два протокола для сетевого мониторинга в контексте ИБ применяются только если нам необходимо обнаружить DoS-атаку на само сетевое оборудование, так как с помощью RMON и SNMP можно, например, отслеживать загрузку центрального процессора устройства или его интерфейсов. Это один из самых “дешевых” (syslog или SNMP есть у всех), но и самый неэффективный из всех способов мониторинга ИБ внутренней инфраструктуры — многие атаки просто скрыты от него. Разумеется им не надо пренебрегать и тот же анализ syslog помогает вам своевременно идентифицировать изменения в конфигурации самого устройства, компрометацию именно его, но обнаруживать атаки на всю сеть он не очень подходит.
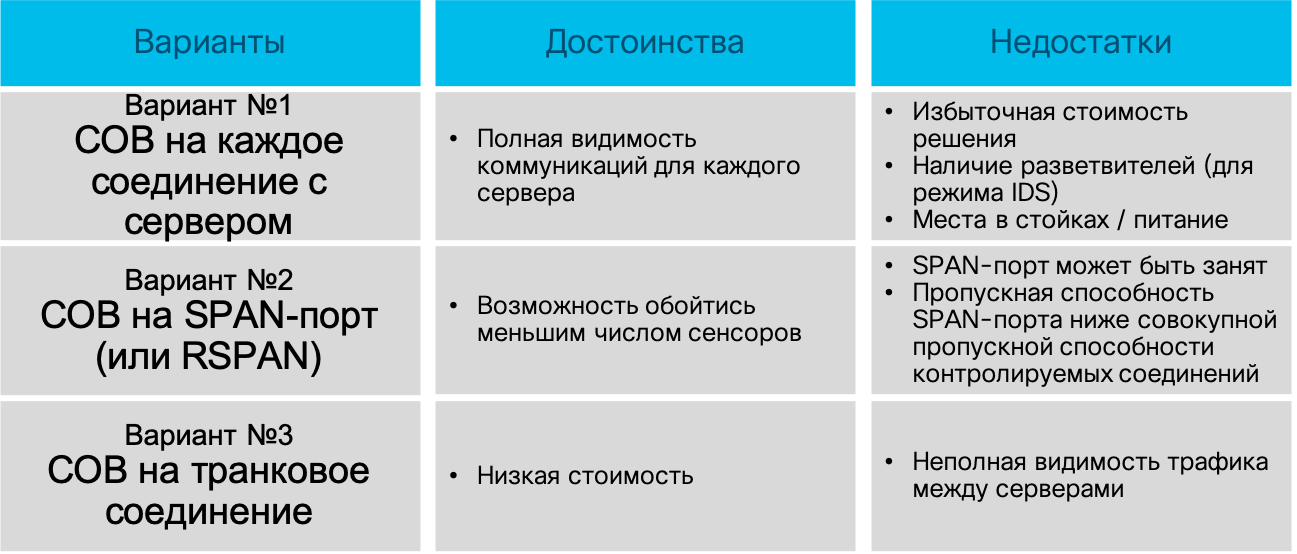
Третий вариант — это анализ информации о трафике, проходящем через устройство, поддерживающее один из нескольких flow-протоколов. В данном случае, независимо от протокола, инфраструктура работы с потоками обязательно состоит из трех компонентов:
Не стоит думать, что такая трехзвенная архитектура слишком сложна — все остальные варианты (исключая, быть может, системы сетевого мониторинга, работающие с SNMP и RMON) также работает согласно ней. У нас есть генератор данных для анализа, в качестве которого выступает сетевое устройство или отдельно стоящий сенсор. У нас есть система сбора сигналов тревоги и есть система управления всей инфраструктурой мониторинга. Последние два компонента могут быть объединены в рамках одного узла, но в более-менее крупных сетях они обычно разнесены по двум, как минимум, устройствам с целях обеспечения масштабирования и надежности.

В отличие от анализа пакетов, базирующемся на изучении заголовка и тела данных каждого пакета и состоящих из них сессий, анализ потоков опирается на сбор метаданных о сетевом трафике. Когда, сколько, откуда и куда, как… вот вопросы, на которые отвечает анализ сетевой телеметрии с помощью различных протоколов flow. Первоначально они использовались для анализа статистики и поиска ИТ-проблем в сети, но потом, по мере развития аналитических механизмов, их стало возможным применять к той же телеметрии и для целей безопасности. Здесь стоит еще раз отметить, что анализ потоков не заменяет и не отменяет захвата пакетов. Каждый из этих методов имеют свою область применения. Но в контексте данной статьи, именно анализ потоков лучше всего подходит для мониторинга внутренней инфраструктуры. У вас есть сетевые устройства (и не важно, работают они в программно-определяемой парадигме или согласно статическим правилам), которые атака миновать не может. Сенсор классической IDS она обойти может, а сетевое устройство, поддерживающее flow-протокол, нет. В этом преимущество этого метода.
С другой стороны, если вам нужна доказательная база для правоохранительных органов или собственной группы расследования инцидентов, без захвата пакетов вам не обойтись — сетевая телеметрия не является копией трафика, который можно использовать при сборе улик; она нужна для оперативного обнаружения и принятия решений в области ИБ. С другой стороны, используя анализ телеметрии, вы можете “писать” не весь сетевой трафик (если что, то Cisco и ЦОДами занимается :-), а только тот, который участвует в атаке. Средства анализа телеметрии в этом плане хорошо дополнят традиционные механизмы захвата пакетов, давая команду на выборочный захват и хранение. В противном случае вам придется иметь колоссальную инфраструктуру хранения.
Представим сеть, работающую на скорости 250 Мбит/сек. Если вы захотите сохранять весь этот объем, то вам понадобится хранилище на 31 Мб для одной секунды передачи трафика, 1,8 Гб — для одной минуты, 108 Гб — для одного часа, и 2,6 Тб — для одних суток. Для хранения суточных данных с сети с пропускной способностью в 10 Гбит/сек вам понадобится хранилище на 108 Тб. А ведь некоторые регуляторы требуют хранить данные по безопасности годами… Запись «по требованию», которую вам помогает реализовать анализ потоков, помогает сократить эти значения на порядки. Кстати, если говорить о соотношении объема записываемых данных сетевой телеметрии и полного захвата данных, то оно составляет примерно 1 к 500. Для тех же приведенных выше значений, хранение полной расшифровки всего дневного трафика составит 5 и 216 Гб соответственно (можно даже на обычную флешку записать).
Если у средств анализа сырых сетевых данных метод их захвата почти не отличается от вендора к вендору, то в случае с анализом потоков ситуация иная. Существует несколько вариантов flow-протоколов, об отличиях в которых необходимо знать именно в контексте безопасности. Самым популярным является протокол Netflow, разработанный компанией Cisco. Существует несколько версий этого протокола, отличающихся по своим возможностям и объему записываемой о трафике информации. Текущая версия — девятая (Netflow v9), на базе которой был разработан промышленный стандарт Netflow v10, также известный как IPFIX. Сегодня большинство сетевых вендоров поддерживает именно Netflow или IPFIX в своем оборудовании. Но есть и различные другие варианты flow-протоколов — sFlow, jFlow, cFlow, rFlow, NetStream и т.п., из которых более популярным является sFlow. Именно он чаще всего поддерживается отечественными производителями сетевого оборудования ввиду простоты реализации. В чем ключевые отличия между Netflow, как стандарта ставшим таковым де-факто, и тем же sFlow? Ключевых я бы выделил несколько. Во-первых, Netflow имеет настраиваемые пользователем поля в отличие от фиксированных полей в sFlow. А во-вторых, и это самое главное в нашем случае, sFlow собирает так называемую семплированную телеметрию; в отличие от несемплированной у Netflow и IPFIX. В чем же между ними разница?
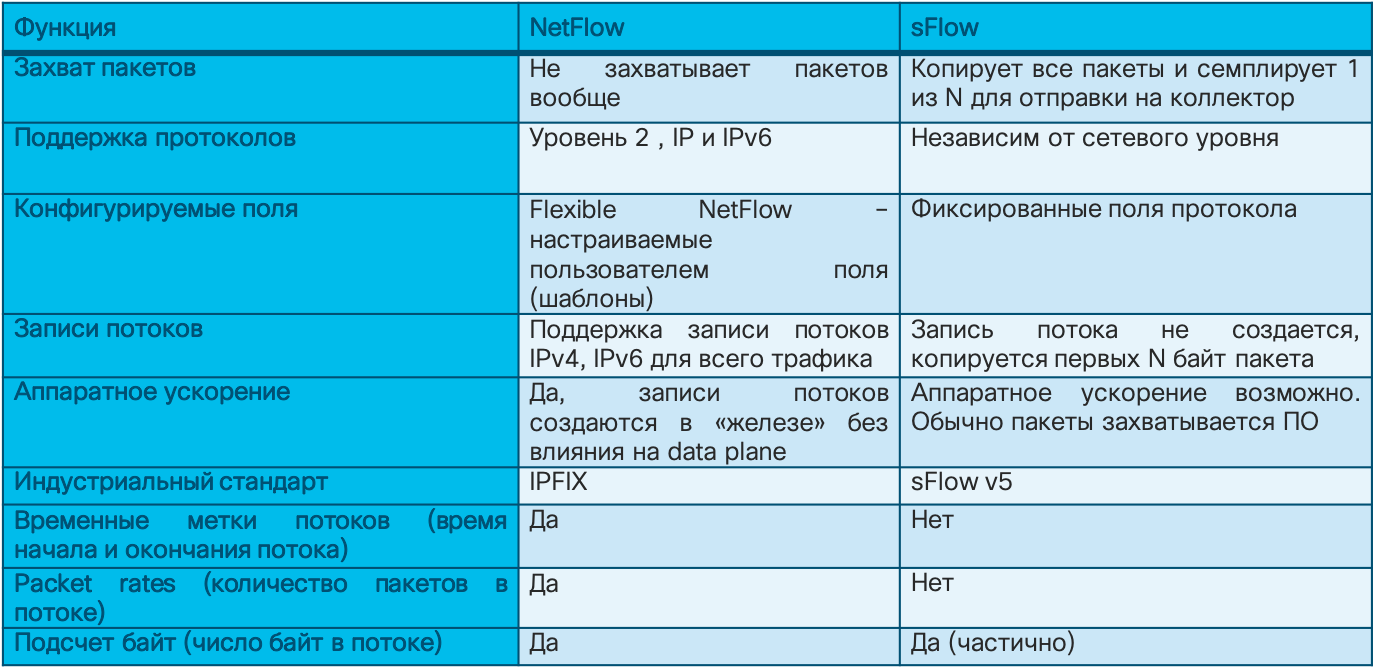
Представьте, что вы решили ознакомиться с книгой “Security Operations Center: Building, Operating, and Maintaining your SOC” моих коллег — Гари Макинтайра, Джозефа Муница и Надема Альфардана (по ссылке вы можете скачать часть книги). У вас есть три варианта достичь поставленной цели — прочитать книгу целиком, пробежать ее глазами, останавливаясь на каждой 10-й или 20-й странице, или попробовать найти пересказ ключевых концепций в каком-либо блоге или сервисе типа SmartReading. Так вот несемплированная телеметрия — это чтение каждой “страницы” сетевого трафика, то есть анализ метаданных по каждому пакету. Семплированная телеметрия — это выборочное изучение трафика в надежде, что в избранных семплах окажется то, что вам нужно. В зависимости от скорости канала семплированная телеметрия будет отдавать для анализа каждый 64-й, 200-й, 500-й, 1000-й, 2000-й или даже 10000-й пакет.

В контексте мониторинга ИБ это означает, что семплированная телеметрия хорошо подходит для обнаружения DDoS-атак, сканирования, распространения вредоносного кода, но может пропустить атомарные или многопакетные атаки, не попавшие в семпл, отправленный для анализа. У несмеплированной телеметрии таких недостатков нет и с ее. помощью спектр обнаруживаемых атак гораздо шире. Вот небольшой перечень событий, которые можно обнаруживать с помощью средств анализа сетевой телеметрии.
Разумеется, какой-нибудь open source анализатор Netflow вам этого не позволит, так как его основная задача — собрать телеметрию и провести над ней базовый анализ с точки зрения ИТ. Для выявления на базе flow угроз ИБ необходимо оснастить анализатор различными движками и алгоритмами, которые и будут на базе стандартных или пользовательских полей Netflow выявлять проблемы кибербезопасности, обогащать стандартные данные внешними данными от различных источников Threat Intelligence и т.п.
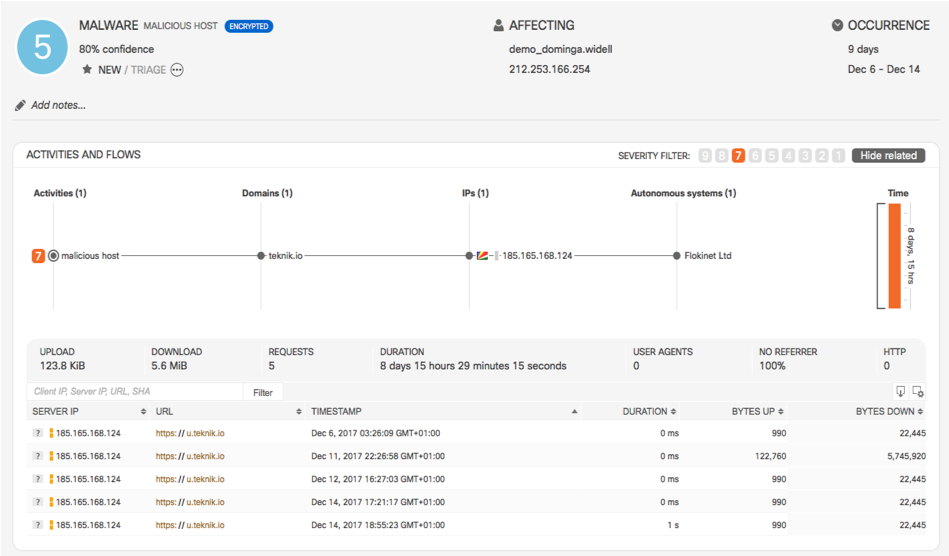
Поэтому если у вас есть выбор, то останавливайте его на Netflow или IPFIX. Но даже если ваше оборудование работает только с sFlow, как у отечественных производителей, то даже в этом случае вы можете извлечь из него пользу в контексте безопасности.
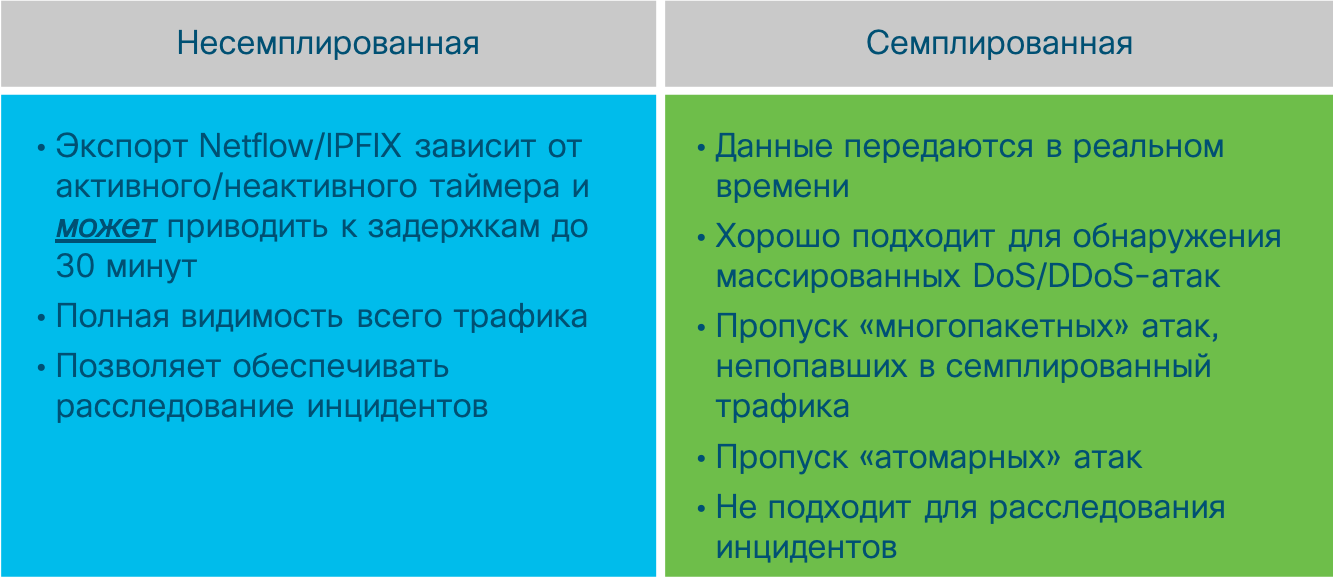
Летом 2019-го года я проводил анализ возможностей, которые есть у российских производителей сетевого железа и все они, исключая NSG, Полигона и Крафтвея, заявляли о поддержке sFlow (как минимум, Зелакс, Натекс, Элтекс, QTech, Рустелетех).
Следующий вопрос, который перед вами встанет, — где внедрять поддержку flow для целей безопасности? На самом деле, вопрос поставлен не совсем корректно. На современном оборудовании поддержка flow-протоколов есть почти всегда. Поэтому вопрос я бы переформулировал иначе — где эффективнее всего собирать телеметрию с точки зрения безопасности? Ответ будет достаточно очевидным — на уровне доступа, где вы увидите 100% всего трафика, где у вас будет детальная информация по хостам (MAC, VLAN, ID интерфейса), где вы сможете отслеживать даже P2P-трафик между хостами, что критично для обнаружения сканирования и и распространения вредоносного кода. На уровне ядра часть трафика вы можете просто не увидеть, а на уровне периметра вы увидите хорошо если четверть всего вашего сетевого трафика. Но если по каким-то причинам у вас в сети завелись посторонние устройства, позводляющие злоумышленникам “входить и выходить”, минуя периметр, то анализ телеметрии с него вам ничего не даст. Поэтому для максимального охвата рекомендуется включать сбор телеметрии именно на уровне доступа. При этом, стоит отметить, что даже если мы говорим о виртуализации или контейнерах, то в современных виртуальных коммутаторах также часто встречается поддержка flow, что позволяет контролировать трафик и там.
Но раз уж я поднял тему, то надо ответить на вопрос, а что если все-таки оборудование, физическое или виртуальное, не поддерживает flow-протоколы? Или его включение запрещено (например, в промышленных сегментах для обеспечения надежности)? Или его включение приводит к высокой загрузке центрального процессора (такое бывает на устаревшем оборудовании)? Для решения этой задачи существуют специализированные виртуальные сенсоры (flow sensor), которые по сути являются обычными разветвителями, пропускающими через себя трафик и транслирующие его в виде flow на модуль сбора. Правда, в этом случае мы получаем весь ворох проблем, о которых мы говорили выше применительно к средствам захвата пакетов. То есть надо понимать не только преимущества технологии анализа потоков, но и ее ограничения.
Еще один момент, который важно помнить, говоря о средствах анализа потоков. Если применительно к обычным средствам генерации событий безопасности мы применяем метрику EPS (event per second, событий в секунду), то к анализу телеметрии этот показатель неприменим; он заменяется на FPS (flow per second, поток в секунду). Как и в случае с EPS, вычислить заранее его нельзя, но можно оценить примерное количество потоков, которое генерит то или иное устройство в зависимости от его задачи. В Интернет вы можете найти таблицы с примерными значениями для разных типов корпоративных устройств и услов, что позволит вам прикинуть, какие лицензии вам нужны для средств анализа и какова будет их архитектура? Дело в том, что сенсор IDS ограничен определенной пропускной способностью, которую он “вытянет”, так и коллектор потоков имеет свои ограничения, которые надо понимать. Поэтому в крупных, территориально-распределенных сетях коллекторов обычно несколько. Когда я описывал, как мониторится сеть внутри Cisco, я уже приводил число наших коллекторов — их 21. И это на сеть, разбросанную по пяти материкам и насчитывающую около полумиллиона активных устройств).
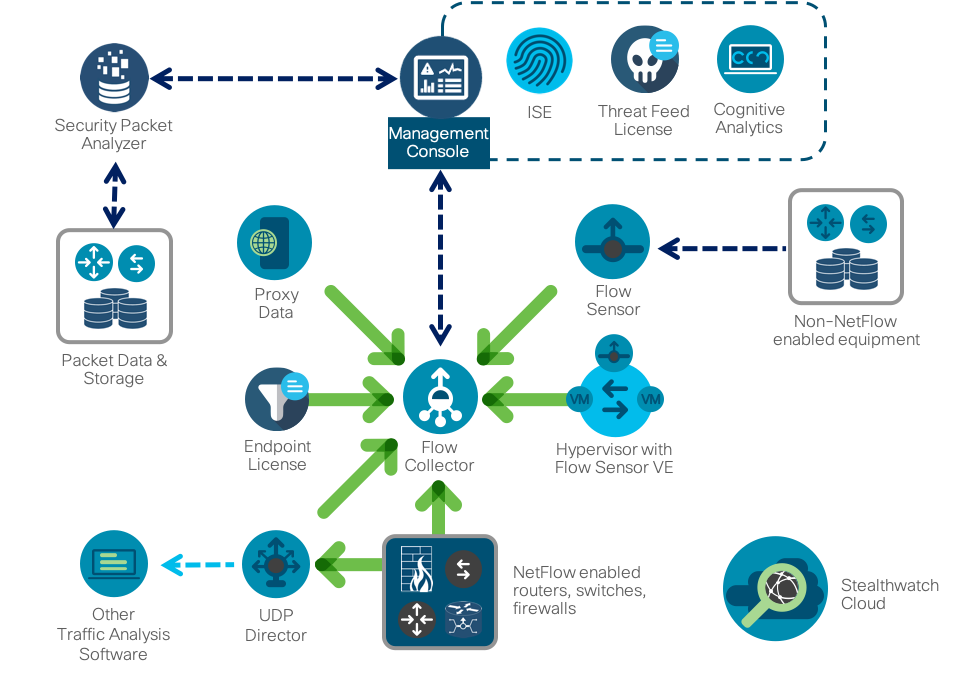
В качестве системы мониторинга Netflow мы используем наше собственное решение Cisco Stealthwatch, которое специально ориентировано на решение задач безопасности. У него много встроенных движков обнаружения аномальной, подозрительной и явно вредоносной активности, позволяющей детектировать широкий спектр различных угроз — от криптомайнинга до утечек информации, от распространения вредоносного кода до мошенничества. Как и большинство анализаторов потоков Stealthwatch построен по трехуровневой схеме (генератор — коллектор — анализатор), но он дополнен рядом интересных особенностей, которые важны в контексте рассматриваемого материала. Во-первых, он интегрируется с решениями по захвату пакетов (например, Cisco Security Packet Analyzer), что позволяет записывать выбранные сетевые сессии для последующего глубокого расследования и анализа. Во-вторых, специально для расширения задач безопасности мы разработали специальный протокол nvzFlow, который позволяет “транслировать” активность приложений на оконечных узлах (серверах, рабочих станциях и т.п.) в телеметрию и передавать ее на коллектор для дальнейшего анализа. Если в своей исконном варианте Stealthwatch работает с любым flow-протоколом (sFlow, rFlow, Netflow, IPFIX, cFlow, jFlow, NetStream) на уровне сети, то поддержка nvzFlow позволяет проводить корреляцию данных еще и на уровне узла, тем самым. повышая эффективности всей системы и видя больше атак, чем обычные сетевые анализаторы потоков.
Понятно, что говоря о системах анализа Netflow с точки зрения безопасности, рынок не ограничен единственным решением от Cisco. Вы можете использовать как коммерческие, так и бесплатные или условно бесплатные решения. Достаточно странно, если я в блоге Cisco буду приводить в пример решения конкурентов, поэтому скажу пару слов о том, как сетевая телеметрия может быть проанализирована с помощью двух популярных, схожих по названию, но все-таки разных инструментов — SiLK и ELK.
SiLK — это набор инструментов (the System for Internet-Level Knowledge) для анализа трафика, разработанный американским CERT/CC и который поддерживает, в контексте сегодняшней статьи, Netflow (5-й и 9-й, самых популярных версий), IPFIX и sFlow и с помощью различных утилит (rwfilter, rwcount, rwflowpack и др.) производить различные операции над сетевой телеметрией с целью обнаружения в ней признаков несанкционированных действий. Но надо отметить пару важных моментов. SiLK — это инструмент командной строки и проводить оперативный анализ, все время ввода команды вида (обнаружение ICMP-пакетов размером более 200 байт):
не очень удобно. Вы можете использовать графический интерфейс iSiLK, но он не сильно облегчит вашу жизнь, решая только функцию визуализации, а не замены аналитика. И это второй момент. В отличие от коммерческих решений, в которые уже заложена солидная аналитическая база, алгоритмы обнаружения аномалий, соответствующие workflow и т.п., в случае с SiLK вы все это должны будете проделать самостоятельно, что потребует от вас немного иных компетенций, чем от использования уже готового к работе инструментария. Это нехорошо и неплохо — это особенность почти любого бесплатного инструмента, который исходит из того, что вы знаете, что делать, а он вам только поможет в этом (коммерческий инструментарий менее зависим от компетенций его пользователей, хотя тоже предполагает, что аналитики понимают хотя бы основы проведения сетевых расследований и мониторинга). Но вернемся к SiLK. Цикл работы аналитика с ним выглядит следующим образом:
Этот цикл будет применим и к тому же Cisco Stealthwatch, только последний эти пять шагов автоматизирует по максимуму, снижая число ошибок аналитика и повышая оперативность обнаружения инцидентов. Например, в SiLK сетевую статистику вы можете обогатить внешними данными по вредоносным IP с помощью собственноручно написанных скриптов, а в Cisco Stealthwatch — это встроенная функция, которая сразу вам отображает сигнал тревоги, если в сетевом трафике встречается взаимодействие с IP-адресами из черного списка.
Если пойти выше по пирамиде «платности» ПО по анализу flow, то за абсолютно бесплатным SiLK будет идти условно бесплатный ELK, состоящий из трех ключевых компонентов — Elasticsearch (индексация, поиск и анализ данных), Logstash (ввод/вывод данных)и Kibana (визуализация). В отличие от SiLK, где все приходится писать самому, у ELK уже есть много готовых библиотек/модулей (часть платные, часть нет), которые автоматизируют анализ сетевой телеметрии. Например, фильтр GeoIP в Logstash позволяет привязать наблюдаемые IP-адреса к их географическому местоположению (у того же Stealthwatch это встроенная функция).
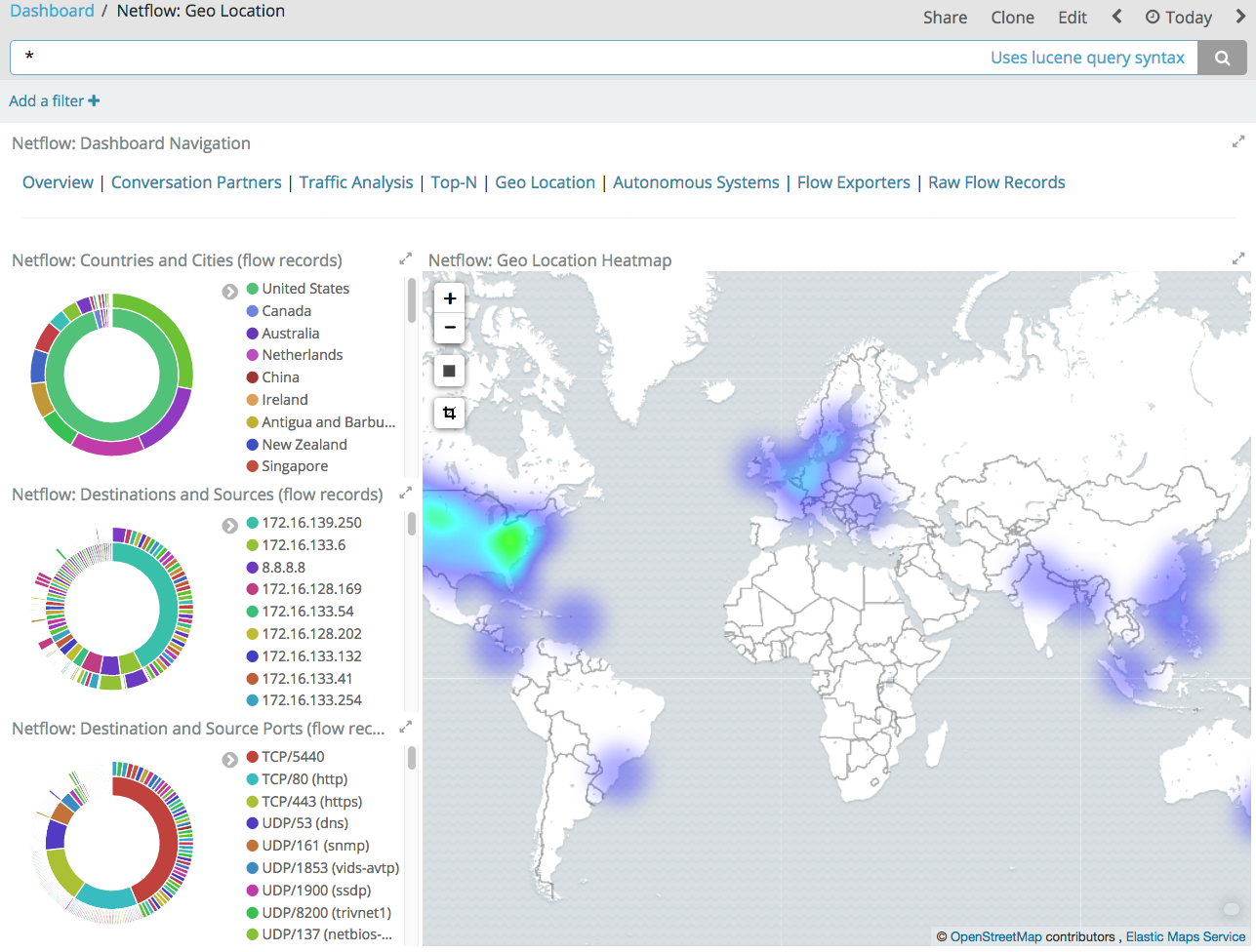
У ELK также достаточно большое комьюнити, которое дописывает недостающие компоненты для этого решения по мониторингу. Например, чтобы работать с Netflow, IPFIX и sFlow вы можете воспользоваться модулем elastiflow, если вас не устраивает Logstash Netflow Module, поддерживающий только Netflow.
Давая больше оперативности по сбору flow и поиску в нем, у ELK на текущий момент отсутствует богатая встроенная аналитика по обнаружению аномалий и угроз в сетевой телеметрии. То есть, следуя выше описанному жизненному циклу, вам придется самостоятельно описывать модели нарушений и потом уже пользоваться им в боевой системе (встроенных моделей там нет).
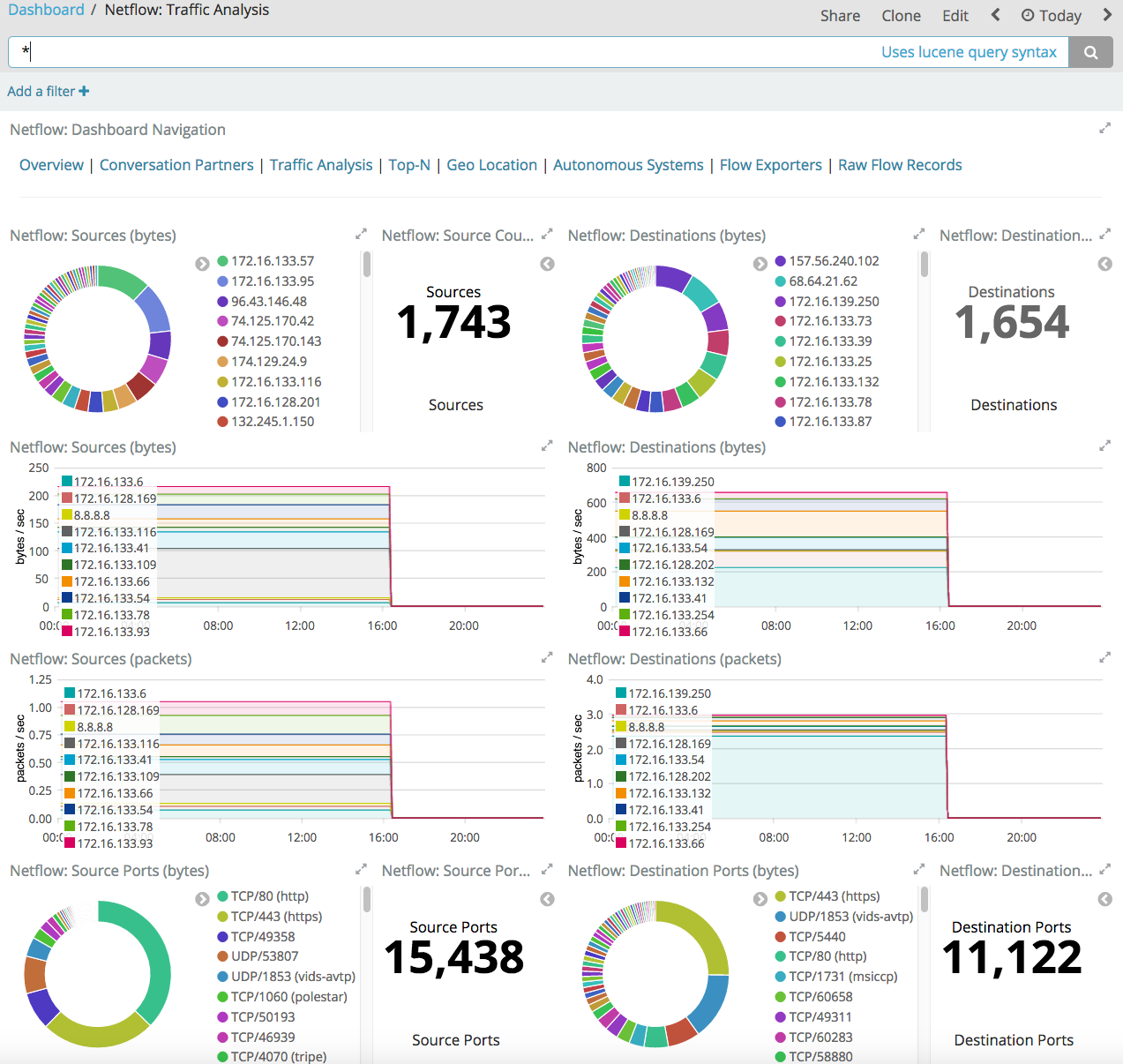
Есть конечно и более навороченные расширения для ELK, в которых уже заложены некоторые модели выявления аномалий в сетевой телеметрии, но такие расширения стоят денег и тут уже вопрос, стоит ли овчинка выделки — писать аналогичную модель самому, покупать ее реализацию для своего средства мониторинга или купить готовое решение класса Network Traffic Analysis.
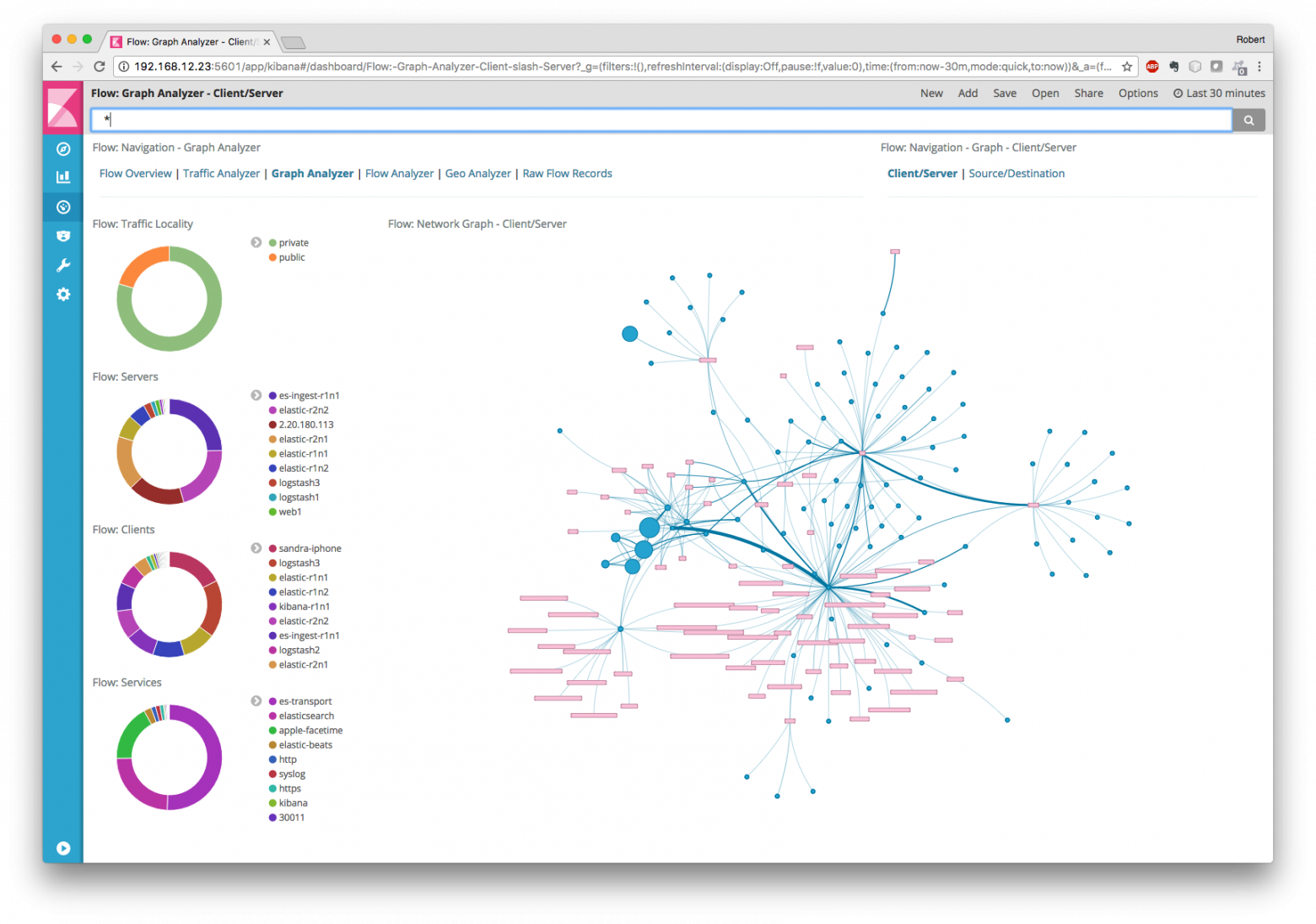
Вообще не хочу вдаваться в полемику, что лучше потратить деньги и купить готовое решение для мониторинга аномалий и угроз в сетевой телеметрии (например, Cisco Stealthwatch) или разобраться самостоятельно и докручивать под каждую новую угрозу тот же SiLK, ELK или nfdump или OSU Flow Tools (я про последние два из них рассказывал в прошлый раз)? Каждый выбирает для себя и у каждого есть свои мотивы выбрать любой из двух вариантов. Я же хотел просто показать, что сетевая телеметрия — это очень важный инструмент в обеспечении сетевой безопасности свой внутренней инфраструктуры и пренебрегать им не стоит, чтобы не пополнить список компания, чье имя упоминается в СМИ вместе с эпитетами «взломанная», «несоблюдавшая требования по ИБ», «недумающая о безопасности своих данных и данных клиентов».
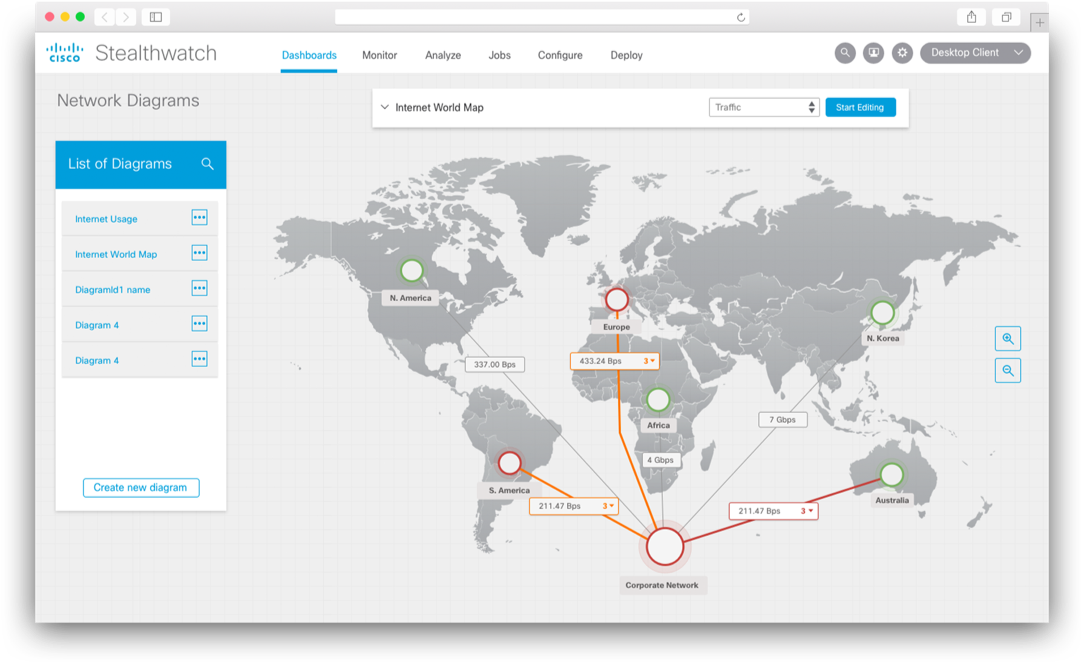
Подводя итоги, я бы хотел перечислить ключевые советы, которым стоит следовать при выстраивании мониторинга ИБ своей внутренней инфраструктуры:
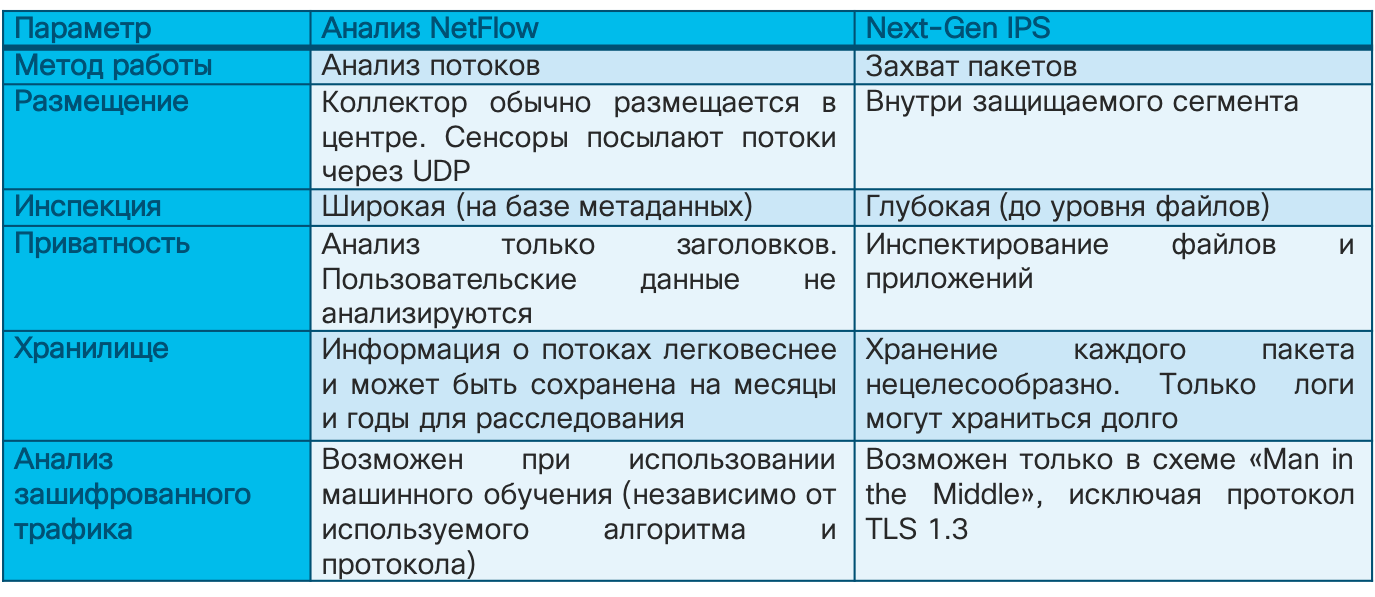
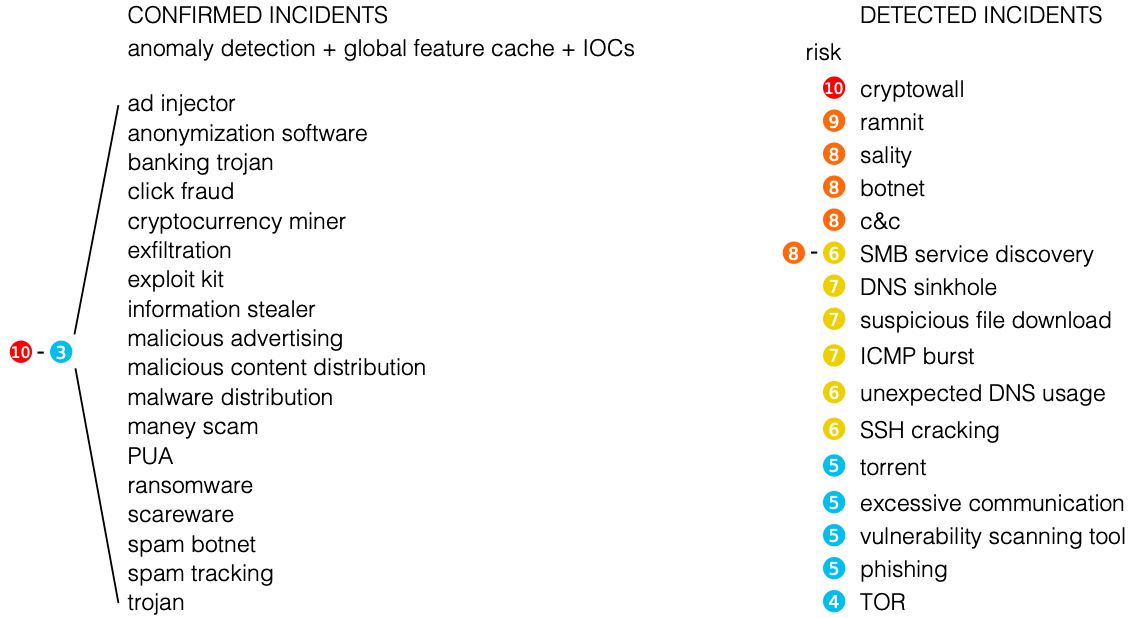
Что касается последнего совета, то я бы хотел привести иллюстрацию, которую уже приводил раньше. Вы видите, что если раньше служба ИБ Cisco почти целиком выстраивала свою систему мониторинга ИБ на базе систем обнаружения вторжений и сигнатурных методов, то сейчас на их долю приходится всего 20% инцидентов. Еще 20% приходится на системы анализа потоков, что говорит о том, что эти решения — не блажь, а реальный инструмент в деятельности служб ИБ современного предприятия. Тем более, что у вас для их внедрения есть самое главное — сетевая инфраструктура, инвестиции в которую можно дополнительно защитить, возложив на сеть еще и функции мониторинга ИБ.
Я специально не стал касаться темы реагирования на выявленные в сетевых потоках аномалии или угрозы, но думаю, что и так понятно, что мониторинг не должен завершаться только обнаружением угрозы. За ним должно следовать реагирование и желательно в автоматическом или автоматизированном режиме. Но это уже тема отдельного материала.
Дополнительная информация:
ЗЫ. Если вам проще воспринимать на слух все, что было написано выше, то вы можете посмотреть часовую презентацию, которая легла в основу данной заметки.
Я не буду останавливаться на вопросе “Зачем нужен мониторинг безопасности внутренней инфраструктуры?” Ответ на него вроде и так понятен. Но если все-таки вы хотели бы еще раз убедиться, что сегодня без этого никуда, посмотрите небольшое видео с рассказом о том, как можно 17-тью способами проникнуть в корпоративную сеть, защищенную межсетевым экраном. Поэтому будем считать, что мы понимаем, что внутренний мониторинг — штука нужная и осталось только понять, как его можно организовать.
Я бы выделил три ключевых источника данных для мониторинга инфраструктуры на сетевом уровне:
- “сырой” трафик, который мы захватываем и подаем на разбор неким системам анализа,
- события с сетевых устройств, через которые проходит трафик,
- информация о трафике, получаемая по одному из flow-протоколов.
Захват сырого трафика — самый популярный у безопасников вариант, потому что он исторически появился и самым первым. Обычные сетевые системы обнаружения атак (самой первой коммерческой системой обнаружения атак была NetRanger от компании Wheel Group, купленная в 1998-м году Cisco) как раз и занимались захватом пакетов (а позже и сессий), в которых искались определенные сигнатуры (“решающие правила” в терминологии ФСТЭК), сигнализирующие об атаках. Разумеется, анализировать сырой трафик можно не только с помощью IDS, но и с помощью иных средств (например, Wireshark, tcpdum или функционал NBAR2 в Cisco IOS), но им обычно не хватает базы знаний, которая отличает средство ИБ от обычного ИТ-инструмента.
Итак, системы обнаружения атак. Самый старый и самый популярный метод обнаружения сетевых атак, который неплохо справляется со своей задачей на периметре (неважно каком — корпоративном, ЦОДа, сегмента и т.п.), но пасует в современных коммутируемых и программно-определяемых сетях. В случае с сетью, построенной на базе обычных коммутаторов, инфраструктура сенсоров обнаружения атак становится слишком большой — вам придется ставить по сенсору на каждый соединение с узлом, атаки на который вы хотите мониторить. Любой производитель, конечно, будет рад продать вам сотни и тысячи сенсоров, но думаю ваш бюджет не выдержить таких расходов. Могу сказать, что даже в Cisco (а мы являемся разработчиками NGIPS) мы не смогли это сделать, хотя, казалось бы, вопрос цены перед нами. стоять не должен — это же наше собственное решение. Кроме того, возникает вопрос, а как подключать сенсор в таком варианте? В разрыв? А если сам сенсор будет выведен из строя? Требовать наличия bypass-модуля в сенсоре? Использовать разветвители (tap)? Все это удорожает решение и делает его неподъемным для компании любого масштаба.
Можно попробовать “повесить” сенсор на SPAN/RSPAN/ERSPAN-порт и направить на него трафик с необходимых портов коммутатора. Этот вариант частично снимает проблему, описанную в предыдущем абзаце, но ставит другую — SPAN-порт не может принять абсолютно весь трафик, который в него будет направляться — ему не хватит пропускной способности. Приджется чем-то жертвовать. Или часть узлов оставить без мониторинга (тогда предварительно вам надо провести их приоритезацию), или направлять не весь трафик с узла, а только определенного типа. В любой случае мы можем пропустить какие-то атаки. Кроме того, SPAN-порт может быть занят под другие нужды. В итоге, нам придется пересмотреть существующую топологию сети и внести, возможно, в нее коррективы, чтобы охватить по максимуму вашу сеть имеющимся у вас числом сенсоров (и согласовать это с ИТ).
А если у вас сеть использует асимметричные маршруты? А если у вас внедрен или планируется к внедрению SDN? А если вам надо мониторить виртуализированные машины или контейнеры, трафик которых вообще не доходит до физического коммутатора? Эти вопросы не любят производители традиционных IDS, потому что не знают, как ответить на них. Возможно, они будут склонять вас к тому, что все эти модные технологии — хайп и вам он не нужен. Возможно, они будут говорить о необходимости начать с малого. А может быть быть они скажут, что вам надо поставить мощную молотилку в центр сети и направить весь трафик в нее с помощью балансировщиков. Какой бы вариант вам не предлагали, вам нужно самим четко понять, насколько он вам подходит. И только после этого принимать решение о выборе подхода к мониторингу ИБ сетевой инфраструктуры. Возвращаясь же к захвату пакетов, хочу сказать, что этот метод продолжает оставаться очень популярным и важным, но его основное предназначение — контроль границ; границ между вашей организацией и Интернет, границ между ЦОДом и остальной сетью, границ между АСУ ТП и корпоративным сегментом. В этих местах классические IDS/IPS по-прежнему имеют право на существование и неплохо справляются с поставленными задачами.
Перейдем ко второму варианту. Анализ событий, поступаемых с сетевых устройств, тоже может быть использован для целей обнаружения атак, но не как основной механизм, так как он позволяет детектировать только небольшой класс вторжений. К тому же ему присуща некоторая реактивность — атака сначала должна произойти, потом она должна быть зафиксирована сетевым устройством, которое тем или иным способом будет сигнализировать о проблеме с ИБ. Способов таких несколько. Это может быть syslog, RMON или SNMP. Последние два протокола для сетевого мониторинга в контексте ИБ применяются только если нам необходимо обнаружить DoS-атаку на само сетевое оборудование, так как с помощью RMON и SNMP можно, например, отслеживать загрузку центрального процессора устройства или его интерфейсов. Это один из самых “дешевых” (syslog или SNMP есть у всех), но и самый неэффективный из всех способов мониторинга ИБ внутренней инфраструктуры — многие атаки просто скрыты от него. Разумеется им не надо пренебрегать и тот же анализ syslog помогает вам своевременно идентифицировать изменения в конфигурации самого устройства, компрометацию именно его, но обнаруживать атаки на всю сеть он не очень подходит.
Третий вариант — это анализ информации о трафике, проходящем через устройство, поддерживающее один из нескольких flow-протоколов. В данном случае, независимо от протокола, инфраструктура работы с потоками обязательно состоит из трех компонентов:
- Генерация или экспорт flow. Эта роль обычно возлагается на маршрутизатор, коммутатор или иное сетевое устройство, которое, пропуская через себя сетевой трафик, позволяет выделять из него ключевые параметры, которые затем передаются на модуль сбора. Например, у Cisco протокол Netflow поддерживается не только на маршрутизаторах и коммутаторах, включая и виртуальные и промышленные, но и на беспроводных контролерах, межсетевых экранах и даже серверах.
- Сбор flow. Учитывая, что в современной сети обычно более одного сетевого устройства, возникает задача сбора и консолидации потоков, которая решается с помощью так называемых коллекторов, которые проводят обработку полученных потоков и затем передают их для анализа.
- Анализ flow. Анализатор берет на себя основную интеллектуальную задачу и, применяя к потокам различные алгоритмы, делает те или иные выводы. Например, в рамках ИТ-функции такой анализатор может выявлять узкие места сети или анализировать профиль загрузки трафика для дальнейшей оптимизации сети. А для ИБ такой анализатор может выявлять утечки данных, распространение вредоносного кода или DoS-атаки.
Не стоит думать, что такая трехзвенная архитектура слишком сложна — все остальные варианты (исключая, быть может, системы сетевого мониторинга, работающие с SNMP и RMON) также работает согласно ней. У нас есть генератор данных для анализа, в качестве которого выступает сетевое устройство или отдельно стоящий сенсор. У нас есть система сбора сигналов тревоги и есть система управления всей инфраструктурой мониторинга. Последние два компонента могут быть объединены в рамках одного узла, но в более-менее крупных сетях они обычно разнесены по двум, как минимум, устройствам с целях обеспечения масштабирования и надежности.
В отличие от анализа пакетов, базирующемся на изучении заголовка и тела данных каждого пакета и состоящих из них сессий, анализ потоков опирается на сбор метаданных о сетевом трафике. Когда, сколько, откуда и куда, как… вот вопросы, на которые отвечает анализ сетевой телеметрии с помощью различных протоколов flow. Первоначально они использовались для анализа статистики и поиска ИТ-проблем в сети, но потом, по мере развития аналитических механизмов, их стало возможным применять к той же телеметрии и для целей безопасности. Здесь стоит еще раз отметить, что анализ потоков не заменяет и не отменяет захвата пакетов. Каждый из этих методов имеют свою область применения. Но в контексте данной статьи, именно анализ потоков лучше всего подходит для мониторинга внутренней инфраструктуры. У вас есть сетевые устройства (и не важно, работают они в программно-определяемой парадигме или согласно статическим правилам), которые атака миновать не может. Сенсор классической IDS она обойти может, а сетевое устройство, поддерживающее flow-протокол, нет. В этом преимущество этого метода.
С другой стороны, если вам нужна доказательная база для правоохранительных органов или собственной группы расследования инцидентов, без захвата пакетов вам не обойтись — сетевая телеметрия не является копией трафика, который можно использовать при сборе улик; она нужна для оперативного обнаружения и принятия решений в области ИБ. С другой стороны, используя анализ телеметрии, вы можете “писать” не весь сетевой трафик (если что, то Cisco и ЦОДами занимается :-), а только тот, который участвует в атаке. Средства анализа телеметрии в этом плане хорошо дополнят традиционные механизмы захвата пакетов, давая команду на выборочный захват и хранение. В противном случае вам придется иметь колоссальную инфраструктуру хранения.
Представим сеть, работающую на скорости 250 Мбит/сек. Если вы захотите сохранять весь этот объем, то вам понадобится хранилище на 31 Мб для одной секунды передачи трафика, 1,8 Гб — для одной минуты, 108 Гб — для одного часа, и 2,6 Тб — для одних суток. Для хранения суточных данных с сети с пропускной способностью в 10 Гбит/сек вам понадобится хранилище на 108 Тб. А ведь некоторые регуляторы требуют хранить данные по безопасности годами… Запись «по требованию», которую вам помогает реализовать анализ потоков, помогает сократить эти значения на порядки. Кстати, если говорить о соотношении объема записываемых данных сетевой телеметрии и полного захвата данных, то оно составляет примерно 1 к 500. Для тех же приведенных выше значений, хранение полной расшифровки всего дневного трафика составит 5 и 216 Гб соответственно (можно даже на обычную флешку записать).
Если у средств анализа сырых сетевых данных метод их захвата почти не отличается от вендора к вендору, то в случае с анализом потоков ситуация иная. Существует несколько вариантов flow-протоколов, об отличиях в которых необходимо знать именно в контексте безопасности. Самым популярным является протокол Netflow, разработанный компанией Cisco. Существует несколько версий этого протокола, отличающихся по своим возможностям и объему записываемой о трафике информации. Текущая версия — девятая (Netflow v9), на базе которой был разработан промышленный стандарт Netflow v10, также известный как IPFIX. Сегодня большинство сетевых вендоров поддерживает именно Netflow или IPFIX в своем оборудовании. Но есть и различные другие варианты flow-протоколов — sFlow, jFlow, cFlow, rFlow, NetStream и т.п., из которых более популярным является sFlow. Именно он чаще всего поддерживается отечественными производителями сетевого оборудования ввиду простоты реализации. В чем ключевые отличия между Netflow, как стандарта ставшим таковым де-факто, и тем же sFlow? Ключевых я бы выделил несколько. Во-первых, Netflow имеет настраиваемые пользователем поля в отличие от фиксированных полей в sFlow. А во-вторых, и это самое главное в нашем случае, sFlow собирает так называемую семплированную телеметрию; в отличие от несемплированной у Netflow и IPFIX. В чем же между ними разница?
Представьте, что вы решили ознакомиться с книгой “Security Operations Center: Building, Operating, and Maintaining your SOC” моих коллег — Гари Макинтайра, Джозефа Муница и Надема Альфардана (по ссылке вы можете скачать часть книги). У вас есть три варианта достичь поставленной цели — прочитать книгу целиком, пробежать ее глазами, останавливаясь на каждой 10-й или 20-й странице, или попробовать найти пересказ ключевых концепций в каком-либо блоге или сервисе типа SmartReading. Так вот несемплированная телеметрия — это чтение каждой “страницы” сетевого трафика, то есть анализ метаданных по каждому пакету. Семплированная телеметрия — это выборочное изучение трафика в надежде, что в избранных семплах окажется то, что вам нужно. В зависимости от скорости канала семплированная телеметрия будет отдавать для анализа каждый 64-й, 200-й, 500-й, 1000-й, 2000-й или даже 10000-й пакет.
В контексте мониторинга ИБ это означает, что семплированная телеметрия хорошо подходит для обнаружения DDoS-атак, сканирования, распространения вредоносного кода, но может пропустить атомарные или многопакетные атаки, не попавшие в семпл, отправленный для анализа. У несмеплированной телеметрии таких недостатков нет и с ее. помощью спектр обнаруживаемых атак гораздо шире. Вот небольшой перечень событий, которые можно обнаруживать с помощью средств анализа сетевой телеметрии.
Разумеется, какой-нибудь open source анализатор Netflow вам этого не позволит, так как его основная задача — собрать телеметрию и провести над ней базовый анализ с точки зрения ИТ. Для выявления на базе flow угроз ИБ необходимо оснастить анализатор различными движками и алгоритмами, которые и будут на базе стандартных или пользовательских полей Netflow выявлять проблемы кибербезопасности, обогащать стандартные данные внешними данными от различных источников Threat Intelligence и т.п.
Поэтому если у вас есть выбор, то останавливайте его на Netflow или IPFIX. Но даже если ваше оборудование работает только с sFlow, как у отечественных производителей, то даже в этом случае вы можете извлечь из него пользу в контексте безопасности.
Летом 2019-го года я проводил анализ возможностей, которые есть у российских производителей сетевого железа и все они, исключая NSG, Полигона и Крафтвея, заявляли о поддержке sFlow (как минимум, Зелакс, Натекс, Элтекс, QTech, Рустелетех).
Следующий вопрос, который перед вами встанет, — где внедрять поддержку flow для целей безопасности? На самом деле, вопрос поставлен не совсем корректно. На современном оборудовании поддержка flow-протоколов есть почти всегда. Поэтому вопрос я бы переформулировал иначе — где эффективнее всего собирать телеметрию с точки зрения безопасности? Ответ будет достаточно очевидным — на уровне доступа, где вы увидите 100% всего трафика, где у вас будет детальная информация по хостам (MAC, VLAN, ID интерфейса), где вы сможете отслеживать даже P2P-трафик между хостами, что критично для обнаружения сканирования и и распространения вредоносного кода. На уровне ядра часть трафика вы можете просто не увидеть, а на уровне периметра вы увидите хорошо если четверть всего вашего сетевого трафика. Но если по каким-то причинам у вас в сети завелись посторонние устройства, позводляющие злоумышленникам “входить и выходить”, минуя периметр, то анализ телеметрии с него вам ничего не даст. Поэтому для максимального охвата рекомендуется включать сбор телеметрии именно на уровне доступа. При этом, стоит отметить, что даже если мы говорим о виртуализации или контейнерах, то в современных виртуальных коммутаторах также часто встречается поддержка flow, что позволяет контролировать трафик и там.
Но раз уж я поднял тему, то надо ответить на вопрос, а что если все-таки оборудование, физическое или виртуальное, не поддерживает flow-протоколы? Или его включение запрещено (например, в промышленных сегментах для обеспечения надежности)? Или его включение приводит к высокой загрузке центрального процессора (такое бывает на устаревшем оборудовании)? Для решения этой задачи существуют специализированные виртуальные сенсоры (flow sensor), которые по сути являются обычными разветвителями, пропускающими через себя трафик и транслирующие его в виде flow на модуль сбора. Правда, в этом случае мы получаем весь ворох проблем, о которых мы говорили выше применительно к средствам захвата пакетов. То есть надо понимать не только преимущества технологии анализа потоков, но и ее ограничения.
Еще один момент, который важно помнить, говоря о средствах анализа потоков. Если применительно к обычным средствам генерации событий безопасности мы применяем метрику EPS (event per second, событий в секунду), то к анализу телеметрии этот показатель неприменим; он заменяется на FPS (flow per second, поток в секунду). Как и в случае с EPS, вычислить заранее его нельзя, но можно оценить примерное количество потоков, которое генерит то или иное устройство в зависимости от его задачи. В Интернет вы можете найти таблицы с примерными значениями для разных типов корпоративных устройств и услов, что позволит вам прикинуть, какие лицензии вам нужны для средств анализа и какова будет их архитектура? Дело в том, что сенсор IDS ограничен определенной пропускной способностью, которую он “вытянет”, так и коллектор потоков имеет свои ограничения, которые надо понимать. Поэтому в крупных, территориально-распределенных сетях коллекторов обычно несколько. Когда я описывал, как мониторится сеть внутри Cisco, я уже приводил число наших коллекторов — их 21. И это на сеть, разбросанную по пяти материкам и насчитывающую около полумиллиона активных устройств).
В качестве системы мониторинга Netflow мы используем наше собственное решение Cisco Stealthwatch, которое специально ориентировано на решение задач безопасности. У него много встроенных движков обнаружения аномальной, подозрительной и явно вредоносной активности, позволяющей детектировать широкий спектр различных угроз — от криптомайнинга до утечек информации, от распространения вредоносного кода до мошенничества. Как и большинство анализаторов потоков Stealthwatch построен по трехуровневой схеме (генератор — коллектор — анализатор), но он дополнен рядом интересных особенностей, которые важны в контексте рассматриваемого материала. Во-первых, он интегрируется с решениями по захвату пакетов (например, Cisco Security Packet Analyzer), что позволяет записывать выбранные сетевые сессии для последующего глубокого расследования и анализа. Во-вторых, специально для расширения задач безопасности мы разработали специальный протокол nvzFlow, который позволяет “транслировать” активность приложений на оконечных узлах (серверах, рабочих станциях и т.п.) в телеметрию и передавать ее на коллектор для дальнейшего анализа. Если в своей исконном варианте Stealthwatch работает с любым flow-протоколом (sFlow, rFlow, Netflow, IPFIX, cFlow, jFlow, NetStream) на уровне сети, то поддержка nvzFlow позволяет проводить корреляцию данных еще и на уровне узла, тем самым. повышая эффективности всей системы и видя больше атак, чем обычные сетевые анализаторы потоков.
Понятно, что говоря о системах анализа Netflow с точки зрения безопасности, рынок не ограничен единственным решением от Cisco. Вы можете использовать как коммерческие, так и бесплатные или условно бесплатные решения. Достаточно странно, если я в блоге Cisco буду приводить в пример решения конкурентов, поэтому скажу пару слов о том, как сетевая телеметрия может быть проанализирована с помощью двух популярных, схожих по названию, но все-таки разных инструментов — SiLK и ELK.
SiLK — это набор инструментов (the System for Internet-Level Knowledge) для анализа трафика, разработанный американским CERT/CC и который поддерживает, в контексте сегодняшней статьи, Netflow (5-й и 9-й, самых популярных версий), IPFIX и sFlow и с помощью различных утилит (rwfilter, rwcount, rwflowpack и др.) производить различные операции над сетевой телеметрией с целью обнаружения в ней признаков несанкционированных действий. Но надо отметить пару важных моментов. SiLK — это инструмент командной строки и проводить оперативный анализ, все время ввода команды вида (обнаружение ICMP-пакетов размером более 200 байт):
rwfilter --flowtypes=all/all --proto=1 --bytes-per-packet=200- --pass=stdout | rwrwcut --fields=sIP,dIP,iType,iCode --num-recs=15не очень удобно. Вы можете использовать графический интерфейс iSiLK, но он не сильно облегчит вашу жизнь, решая только функцию визуализации, а не замены аналитика. И это второй момент. В отличие от коммерческих решений, в которые уже заложена солидная аналитическая база, алгоритмы обнаружения аномалий, соответствующие workflow и т.п., в случае с SiLK вы все это должны будете проделать самостоятельно, что потребует от вас немного иных компетенций, чем от использования уже готового к работе инструментария. Это нехорошо и неплохо — это особенность почти любого бесплатного инструмента, который исходит из того, что вы знаете, что делать, а он вам только поможет в этом (коммерческий инструментарий менее зависим от компетенций его пользователей, хотя тоже предполагает, что аналитики понимают хотя бы основы проведения сетевых расследований и мониторинга). Но вернемся к SiLK. Цикл работы аналитика с ним выглядит следующим образом:
- Формулирование гипотезы. Мы должны понимать, что мы будем искать внутри сетевой телеметрии, знать уникальные атрибуты, по которым будем выявлять те или иные аномалии или угрозы.
- Построение модели. Сформулировав гипотезу, мы программируем ее с помощью того же Python, шелла или иных инструментов, не входящих в SiLK.
- Тестирование. Наступает черед проверки правильности нашей гипотезы, которая подтверждается или опровергается с помощью утилит SiLK, начинающихся с 'rw', 'set', 'bag'.
- Анализ реальных данных. В промышленной эксплуатации SiLK нам помогает нам выявлять нечто и аналитик должен ответить на вопросы «Нашли ли мы то, что предполагали?», «Соответствует ли это нашей гипотезе?», «Как снизит число ложных срабатываний?», «Как улучшить уровень распознавания?» и т.п.
- Улучшение. На финальном этапе мы улучшаем сделанное ранее — создаем шаблоны, улучшаем и оптимизируем код, переформулируем и уточняем гипотезу и др.
Этот цикл будет применим и к тому же Cisco Stealthwatch, только последний эти пять шагов автоматизирует по максимуму, снижая число ошибок аналитика и повышая оперативность обнаружения инцидентов. Например, в SiLK сетевую статистику вы можете обогатить внешними данными по вредоносным IP с помощью собственноручно написанных скриптов, а в Cisco Stealthwatch — это встроенная функция, которая сразу вам отображает сигнал тревоги, если в сетевом трафике встречается взаимодействие с IP-адресами из черного списка.
Если пойти выше по пирамиде «платности» ПО по анализу flow, то за абсолютно бесплатным SiLK будет идти условно бесплатный ELK, состоящий из трех ключевых компонентов — Elasticsearch (индексация, поиск и анализ данных), Logstash (ввод/вывод данных)и Kibana (визуализация). В отличие от SiLK, где все приходится писать самому, у ELK уже есть много готовых библиотек/модулей (часть платные, часть нет), которые автоматизируют анализ сетевой телеметрии. Например, фильтр GeoIP в Logstash позволяет привязать наблюдаемые IP-адреса к их географическому местоположению (у того же Stealthwatch это встроенная функция).
У ELK также достаточно большое комьюнити, которое дописывает недостающие компоненты для этого решения по мониторингу. Например, чтобы работать с Netflow, IPFIX и sFlow вы можете воспользоваться модулем elastiflow, если вас не устраивает Logstash Netflow Module, поддерживающий только Netflow.
Давая больше оперативности по сбору flow и поиску в нем, у ELK на текущий момент отсутствует богатая встроенная аналитика по обнаружению аномалий и угроз в сетевой телеметрии. То есть, следуя выше описанному жизненному циклу, вам придется самостоятельно описывать модели нарушений и потом уже пользоваться им в боевой системе (встроенных моделей там нет).
Есть конечно и более навороченные расширения для ELK, в которых уже заложены некоторые модели выявления аномалий в сетевой телеметрии, но такие расширения стоят денег и тут уже вопрос, стоит ли овчинка выделки — писать аналогичную модель самому, покупать ее реализацию для своего средства мониторинга или купить готовое решение класса Network Traffic Analysis.
Вообще не хочу вдаваться в полемику, что лучше потратить деньги и купить готовое решение для мониторинга аномалий и угроз в сетевой телеметрии (например, Cisco Stealthwatch) или разобраться самостоятельно и докручивать под каждую новую угрозу тот же SiLK, ELK или nfdump или OSU Flow Tools (я про последние два из них рассказывал в прошлый раз)? Каждый выбирает для себя и у каждого есть свои мотивы выбрать любой из двух вариантов. Я же хотел просто показать, что сетевая телеметрия — это очень важный инструмент в обеспечении сетевой безопасности свой внутренней инфраструктуры и пренебрегать им не стоит, чтобы не пополнить список компания, чье имя упоминается в СМИ вместе с эпитетами «взломанная», «несоблюдавшая требования по ИБ», «недумающая о безопасности своих данных и данных клиентов».
Подводя итоги, я бы хотел перечислить ключевые советы, которым стоит следовать при выстраивании мониторинга ИБ своей внутренней инфраструктуры:
- Не ограничивайтесь только периметром! Используйте (и выбирайте) сетевую инфраструктуру не только для передачи трафика из точки А в точку Б, но и для решения вопросов кибербезопасности.
- Изучите существущие механизмы мониторинга ИБ в вашем сетевом оборудовании и задействуйте их.
- Для внутреннего мониторинга отдавайте предпочтение анализу телеметрии — он позволяет обнаруживать до 80-90% всех сетевых инцидентов ИБ, делая при этом то, что невозможно при захвате сетевых пакетов и экономя пространство для хранения всех событий ИБ.
- Для мониторинга потоков используйте Netflow v9 или IPFIX – они дают больше информации в контексте безопасности и позволяют мониторить не только IPv4, но и IPv6, MPLS и т.д.
- Используйте несемплированный flow-протокол – он дает больше информации для обнаружения угроз. Например, Netflow или IPFIX.
- Проверьте загрузку вашего сетевого оборудования – возможно оно не справится с обработкой еще и flow-протокола. Тогда продумайте применение виртуальных сенсоров или Netflow Generation Appliance.
- Реализуйте контроль в первую очередь на уровне доступа – это даст вам возможность видеть 100% всего трафика.
- Если вы у вас не выбора и вы используете российское сетевое оборудование, то выбирайте то, которое поддерживает flow-протоколы или имеет SPAN/RSPAN-порты.
- Комбинируйте системы обнаружения/ предотвращения вторжения/атак на границах и системы анализа потоков во внутренней сети (в том числе и в облаках).
Что касается последнего совета, то я бы хотел привести иллюстрацию, которую уже приводил раньше. Вы видите, что если раньше служба ИБ Cisco почти целиком выстраивала свою систему мониторинга ИБ на базе систем обнаружения вторжений и сигнатурных методов, то сейчас на их долю приходится всего 20% инцидентов. Еще 20% приходится на системы анализа потоков, что говорит о том, что эти решения — не блажь, а реальный инструмент в деятельности служб ИБ современного предприятия. Тем более, что у вас для их внедрения есть самое главное — сетевая инфраструктура, инвестиции в которую можно дополнительно защитить, возложив на сеть еще и функции мониторинга ИБ.
Я специально не стал касаться темы реагирования на выявленные в сетевых потоках аномалии или угрозы, но думаю, что и так понятно, что мониторинг не должен завершаться только обнаружением угрозы. За ним должно следовать реагирование и желательно в автоматическом или автоматизированном режиме. Но это уже тема отдельного материала.
Дополнительная информация:
- Описание Cisco IOS Netflow
- Матрица поддержки Netflow в различных решениях Cisco
- Руководство по настройке Netflow на различных платформах Cisco
- Сообщество sFlow
- Лабораторная работа по использованию Stealtjwatch, SiLK и ELK для анализа Netflow с точки зрения безопасности
- Сайт SiLK
- Трехсотстраничное руководство по использованию SiLK с кучей примеров
- Logstash Netflow Module
- Пошаговое руководство Cisco по анализу Netflow в ELK
- Анализ NetFlow v.9 Cisco ASA с помощью Logstash (ELK)
- Решение Cisco Stealthwatch
ЗЫ. Если вам проще воспринимать на слух все, что было написано выше, то вы можете посмотреть часовую презентацию, которая легла в основу данной заметки.

