Раньше я боялся кэширования. Очень не хотелось лезть и выяснять, что это такое, сразу представлялись какие-то подкапотные люто-энтерпрайзные штуки, в которых может разобраться только победитель олимпиады по математике. Оказалось, что это не так. Кэширование оказалось очень простым, понятным и невероятно лёгким во внедрении в любой проект.

В данном посте я постараюсь объяснить о кэшировании так же просто, как это сейчас понимаю я. Вы узнаете о том, как внедрить кэширование за 1 минуту, как кэшировать по ключу, устанавливать время жизни кэша, и многие прочие штуки, которые необходимо знать, если Вам поручили закэшировать что-то в вашем рабочем проекте, и Вы не хотите ударить в грязь лицом.
Почему я говорю «поручили»? Потому что кэширование, как правило, есть смысл применять в больших, высоконагруженных проектах, с десятками тысяч запросов в минуту. В таких проектах, чтобы не перегружать базу, как правило, кэшируют обращения к репозиторию. Особенно если известно, что данные из какой-нибудь мастер-системы обновляются с некоторой периодичностью. Сами мы такие проекты не пишем, мы на них работаем. Если же проект маленький и перегрузки ему не грозят, тогда, конечно, лучше ничего не кэшировать — всегда свежие данные всегда лучше периодически обновляемых.
Обычно в обучающих постах докладчик сначала лезет под капот, начинает копаться в кишочках технологии, чем немало утомляет читателя, а уж потом, когда тот пролистал без дела добрую половину статьи и ничего не понял, повествует, как это работает. У нас всё будет иначе. Сначала мы делаем так, чтобы заработало, и желательно, с приложением наименьших усилий, а уж потом, если интересно, Вы сможете заглянуть под капот кэширования, посмотреть изнутри сам бин и тонко настроить кэширование. Но даже если Вы этого не сделаете (а это начинается с 6 пункта), Ваше кэширование будет работать и так.
Мы создадим проект, в котором разберём все те аспекты кэширования, которые я обещал. В конце, как обычно, будет ссылка на сам проект.
Мы создадим очень простой проект, в котором мы сможем брать сущность из базы данных. Я добавил в проект Lombok, Spring Cache, Spring Data JPA и H2. Хотя, вполне можно обойтись только Spring Cache.
У нас будет только одна сущность, назовём её User.
Добавим репозиторий и сервис:
Когда мы заходим в сервисный метод get(), мы пишем об этом в лог.
Подключим к проекту Spring Cache.
Проект готов.
Что делает Spring Cache? Spring Cache просто кэширует возвращаемый результат для определённых входных параметров. Давайте это проверим. Мы поставим аннотацию @Cacheable над сервисным методом get(), чтобы кэшировать возвращаемые данные. Дадим этой аннотации название «users» (далее мы разберём, зачем это делается, отдельно).
Для того, чтобы проверить, как это работает, напишем простой тест.
Что делает наш тест? Он создаёт двоих юзеров и потом по 2 раза вытаскивает их из базы. Как мы помним, мы поместили аннотацию @Cacheable, которая будет кэшировать возвращаемые значения. После получения объекта из метода get() мы выводим объект в лог. Также, мы выводим в лог информацию о каждом посещении приложением метода get().
Запустим тест. Вот что мы получаем в консоль.
Как мы видим, первые два раза мы действительно сходили в метод get() и реально получили юзера из базы. Во всех остальных случаях, реального захода в метод не было, приложение брало закэшированные данные по ключу (в данном случае, это id).
Бывают ситуации, когда в кэшируемый метод приходит несколько параметров. В таком случае, бывает нужно определить параметр, по которому будет происходить кэширование. Добавим в пример метод, который будет сохранять в базу сущность, собранную по параметрам, но если сущность с таким именем уже есть, мы не будем её сохранять. Для этого мы определим параметр name как ключ для кэширования. Выглядеть это будет так:
Напишем соответствующий тест:
Мы попытаемся создать троих пользователей, для двоих из которых будет совпадать имя
и для двоих из которых будет совпадать email
В методе создания мы логируем каждый факт обращения к методу, а также, мы будем логировать все сущности, которые этот метод нам вернул. Результат будет таким:
Мы видим, что фактически приложение вызывало метод 3 раза, а заходило в него только два раза. Один раз для метода совпадал ключ, и он просто возвращал закэшированное значение.
Бывают ситуации, когда мы хотим кэшировать возвращаемое значение для какой-то сущности, но в то же время, нам нужно обновить кэш. Для таких нужд существует аннотация @CachePut. Оно пропускает приложение в метод, при этом, обновляя кэш для возвращаемого значения, даже если оно уже закэшировано.
Добавим пару методов, в которых мы будем сохранять юзера. Один из них мы пометим обычной аннотацией @Cacheable, второй — @CachePut.
Первый метод будет просто возвращать закэшированные значения, второй — принудительно обновлять кэш. Кэширование будет осуществляться по ключу #user.name. Напишем соответствующий тест.
По той логике, которая уже описывалась, при первом сохранении пользователя с именем «Vasya» через метод createOrReturnCached() далее мы будем получать кэшированную сущность, при этом, в сам метод приложение заходить не будет. Если же мы вызовем метод createAndRefreshCache(), кэшированная сущность для ключа с именем «Vasya» перезапишется в кэше. Выполним тест и посмотрим, что будет выведено в консоль.
Мы видим, что user1 благополучно записался в базу и кэш. При повторной попытке записать юзера с таким же именем мы получаем закэшированный результат выполнения первого обращения (user2, для которого id такой же, как у user1, что говорит нам о том, что юзер не был записан, и это просто кэш). Далее, мы пишем третьего пользователя через второй метод, который даже при имеющемся закэшированном результате всё равно вызвал метод и записал в кэш новый результат. Это user3. Как мы видим, у него уже новый id. После чего, мы вызываем первый метод, который берёт новый кэш, добавленный user3.
Иногда возникает необходимость жёстко обновить какие-то данные в кэше. Например, сущность уже удалена из базы, но она по-прежнему доступна из кэша. Для сохранения консистентности данных, нам необходимо хотя бы не хранить в кэше удалённые данные.
Добавим в сервис ещё пару методов.
Первый будет просто удалять пользователя, второй тоже будет его удалять, но мы пометим его аннотацией @CacheEvict. Добавим тест, который будет создавать двух юзеров, после чего, одного будет удалять через простой метод, а второго — через аннотируемый метод. После чего, мы достанем этих юзеров через метод get().
Логично, что раз наш юзер уже закэширован, удаление не помешает нам его как бы получить — ведь он закэширован. Посмотрим логи.
Мы видим, что приложение благополучно сходило оба раза в метод get() и Spring закэшировал эти сущности. Далее, мы удалили их через разные методы. Первый мы удалили обычным путём, и закэшированное значение осталось, поэтому когда мы попытались получить юзера под id 1, нам это удалось. Когда же мы попытались получить юзера 2, метод вернул нам EntityNotFoundException — такого юзера в кэше не оказалось.
Иногда один метод требует нескольких настроек кэширования. Для этих целей используется аннотация @Caching. Выглядеть это может приблизительно так:
Это единственный способ группировать аннотации. Если Вы попытаетесь нагородить что-то вроде
то IDEA сообщит Вам, что так нельзя.
Наконец-то мы разобрались с кэшем, и он перестал быть для нас чем-то непонятным и страшным. Теперь давайте заглянем под капот и посмотрим, как мы можем настроить кэширование в целом.
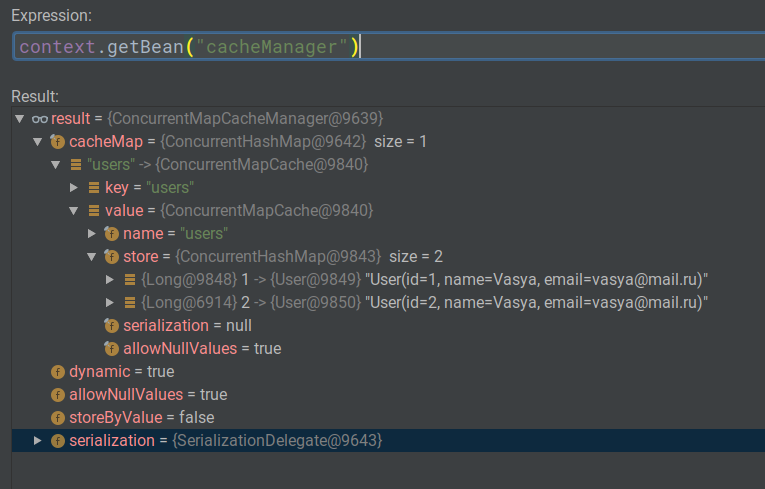
Для таких задач существует CacheManager. Он существует везде, где есть Spring Cache. Когда мы добавили аннотацию @EnableCache, такой кэш менеджер автоматически будет создан Spring. Мы можем убедиться в этом, если заавтовайрим ApplicationContext и вскроем его на брейкпоинте. Среди прочих бинов, будет и бин «cacheManager».

Я остановил приложение на этапе, когда уже два юзера были созданы и помещены в кэш. Если мы вызовем нужный нам бин через Evaluate Expression, то мы увидим, что такой бин действительно есть, в нём есть ConcurentMapCache с ключом «users» и значением ConcurrentHashMap, в которой уже лежат закэшированные юзеры.
Мы, в свою очередь, можем создать свой кэш-менеджер, с хабром и программистами, после чего, тонко настроить его на наш вкус.
Осталось только выбрать, какой именно кэш-менеджер мы будем использовать, потому что их предостаточно. Я не буду перечислять все кэш-менеджеры, достаточно будет знать, что есть такие:
В рамках своего скромного поста я не буду описывать кэш-менеджеры из последней тройки. Вместо этого, мы разберём несколько аспектов настройки кэш-менеджера на примере ConcurrentMapCacheManager.
Итак, досоздадим наш кэш-менеджер.
Наш кэш-менеджер готов.
Для этого нам потребуется довольно популярная библиотека Google Guava. Я взял последнюю.
При создании кэш-менеджера переопределим метод createConcurrentMapCache, в котором вызовем CacheBuilder от Guava. В процессе нам будет предложено настроить кэш-менеджер при помощи инициализации следующих методов:
и прочих.
Определим в менеджере время жизни записи. Чтобы долго не ждать, выставим 1 секунду.
Напишем соответствующий такому случаю тест.
Мы сохраняем несколько значений в базу данных, причём, если данные закэшированы, мы ничего не сохраняем. Сначала мы сохраняем два значения, потом ожидаем 1 секунду, пока кэш не протухнет, после чего, сохраняем ещё одно значение.
Логи показывают, что сначала мы создали юзера, потом попытались ещё одного, но поскольку данные были закэшированы, мы получили их из кэша (в обоих случаях — при сохранении и при получении из базы). Потом протух кэш, о чём сообщает нам запись о фактическом сохранении и фактическом получении юзера.
Рано или поздно, разработчик сталкивается с необходимостью реализации кэширования в проекте. Я надеюсь, что эта статья поможет Вам разобраться в предмете и смотреть на вопросы кэширования смелее.
Гитхаб проекта тут: https://github.com/promoscow/cache
В данном посте я постараюсь объяснить о кэшировании так же просто, как это сейчас понимаю я. Вы узнаете о том, как внедрить кэширование за 1 минуту, как кэшировать по ключу, устанавливать время жизни кэша, и многие прочие штуки, которые необходимо знать, если Вам поручили закэшировать что-то в вашем рабочем проекте, и Вы не хотите ударить в грязь лицом.
Почему я говорю «поручили»? Потому что кэширование, как правило, есть смысл применять в больших, высоконагруженных проектах, с десятками тысяч запросов в минуту. В таких проектах, чтобы не перегружать базу, как правило, кэшируют обращения к репозиторию. Особенно если известно, что данные из какой-нибудь мастер-системы обновляются с некоторой периодичностью. Сами мы такие проекты не пишем, мы на них работаем. Если же проект маленький и перегрузки ему не грозят, тогда, конечно, лучше ничего не кэшировать — всегда свежие данные всегда лучше периодически обновляемых.
Обычно в обучающих постах докладчик сначала лезет под капот, начинает копаться в кишочках технологии, чем немало утомляет читателя, а уж потом, когда тот пролистал без дела добрую половину статьи и ничего не понял, повествует, как это работает. У нас всё будет иначе. Сначала мы делаем так, чтобы заработало, и желательно, с приложением наименьших усилий, а уж потом, если интересно, Вы сможете заглянуть под капот кэширования, посмотреть изнутри сам бин и тонко настроить кэширование. Но даже если Вы этого не сделаете (а это начинается с 6 пункта), Ваше кэширование будет работать и так.
Мы создадим проект, в котором разберём все те аспекты кэширования, которые я обещал. В конце, как обычно, будет ссылка на сам проект.
0. Создание проекта
Мы создадим очень простой проект, в котором мы сможем брать сущность из базы данных. Я добавил в проект Lombok, Spring Cache, Spring Data JPA и H2. Хотя, вполне можно обойтись только Spring Cache.
plugins { id 'org.springframework.boot' version '2.1.7.RELEASE' id 'io.spring.dependency-management' version '1.0.8.RELEASE' id 'java' } group = 'ru.xpendence' version = '0.0.1-SNAPSHOT' sourceCompatibility = '1.8' configurations { compileOnly { extendsFrom annotationProcessor } } repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter-cache' implementation 'org.springframework.boot:spring-boot-starter-data-jpa' compileOnly 'org.projectlombok:lombok' runtimeOnly 'com.h2database:h2' annotationProcessor 'org.projectlombok:lombok' testImplementation 'org.springframework.boot:spring-boot-starter-test' }
У нас будет только одна сущность, назовём её User.
@Entity @Table(name = "users") @Data @NoArgsConstructor @ToString public class User implements Serializable { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(name = "name") private String name; @Column(name = "email") private String email; public User(String name, String email) { this.name = name; this.email = email; } }
Добавим репозиторий и сервис:
public interface UserRepository extends JpaRepository<User, Long> { } @Slf4j @Service public class UserServiceImpl implements UserService { private final UserRepository repository; public UserServiceImpl(UserRepository repository) { this.repository = repository; } @Override public User create(User user) { return repository.save(user); } @Override public User get(Long id) { log.info("getting user by id: {}", id); return repository.findById(id) .orElseThrow(() -> new EntityNotFoundException("User not found by id " + id)); } }
Когда мы заходим в сервисный метод get(), мы пишем об этом в лог.
Подключим к проекту Spring Cache.
@SpringBootApplication @EnableCaching //подключение Spring Cache public class CacheApplication { public static void main(String[] args) { SpringApplication.run(CacheApplication.class, args); } }
Проект готов.
1. Кэширование возвращаемого результата
Что делает Spring Cache? Spring Cache просто кэширует возвращаемый результат для определённых входных параметров. Давайте это проверим. Мы поставим аннотацию @Cacheable над сервисным методом get(), чтобы кэшировать возвращаемые данные. Дадим этой аннотации название «users» (далее мы разберём, зачем это делается, отдельно).
@Override @Cacheable("users") public User get(Long id) { log.info("getting user by id: {}", id); return repository.findById(id) .orElseThrow(() -> new EntityNotFoundException("User not found by id " + id)); }
Для того, чтобы проверить, как это работает, напишем простой тест.
@RunWith(SpringRunner.class) @SpringBootTest public abstract class AbstractTest { }
@Slf4j public class UserServiceTest extends AbstractTest { @Autowired private UserService service; @Test public void get() { User user1 = service.create(new User("Vasya", "vasya@mail.ru")); User user2 = service.create(new User("Kolya", "kolya@mail.ru")); getAndPrint(user1.getId()); getAndPrint(user2.getId()); getAndPrint(user1.getId()); getAndPrint(user2.getId()); } private void getAndPrint(Long id) { log.info("user found: {}", service.get(id)); } }
Небольшое отступление, почему я обычно пишу AbstractTest и наследую от него все тесты.
Если над классом стоит своя аннотация @SpringBootTest, для такого класса каждый раз заново поднимается контекст. Поскольку контекст может подниматься 5 секунд, а может 40 секунд, это в любом случае очень сильно тормозит процесс тестирования. При этом, разницы в контексте обычно нет никакой, и при запуске каждой группы тестов в пределах одного класса нет необходимости заново запускать контекст. Если же мы ставим только одну аннотацию, скажем, над абстрактным классом, как в нашем случае, это позволяет поднимать контекст только один раз.
Поэтому я предпочитаю сокращать количество поднимаемых контекстов при тестировании/сборке, если это возможно.
Поэтому я предпочитаю сокращать количество поднимаемых контекстов при тестировании/сборке, если это возможно.
Что делает наш тест? Он создаёт двоих юзеров и потом по 2 раза вытаскивает их из базы. Как мы помним, мы поместили аннотацию @Cacheable, которая будет кэшировать возвращаемые значения. После получения объекта из метода get() мы выводим объект в лог. Также, мы выводим в лог информацию о каждом посещении приложением метода get().
Запустим тест. Вот что мы получаем в консоль.
getting user by id: 1 user found: User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 user found: User(id=2, name=Kolya, email=kolya@mail.ru) user found: User(id=1, name=Vasya, email=vasya@mail.ru) user found: User(id=2, name=Kolya, email=kolya@mail.ru)
Как мы видим, первые два раза мы действительно сходили в метод get() и реально получили юзера из базы. Во всех остальных случаях, реального захода в метод не было, приложение брало закэшированные данные по ключу (в данном случае, это id).
2. Объявление ключа для кэширования
Бывают ситуации, когда в кэшируемый метод приходит несколько параметров. В таком случае, бывает нужно определить параметр, по которому будет происходить кэширование. Добавим в пример метод, который будет сохранять в базу сущность, собранную по параметрам, но если сущность с таким именем уже есть, мы не будем её сохранять. Для этого мы определим параметр name как ключ для кэширования. Выглядеть это будет так:
@Override @Cacheable(value = "users", key = "#name") public User create(String name, String email) { log.info("creating user with parameters: {}, {}", name, email); return repository.save(new User(name, email)); }
Напишем соответствующий тест:
@Test public void create() { createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Ivan", "ivan1122@mail.ru"); createAndPrint("Sergey", "ivan@mail.ru"); log.info("all entries are below:"); service.getAll().forEach(u -> log.info("{}", u.toString())); } private void createAndPrint(String name, String email) { log.info("created user: {}", service.create(name, email)); }
Мы попытаемся создать троих пользователей, для двоих из которых будет совпадать имя
createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Ivan", "ivan1122@mail.ru");
и для двоих из которых будет совпадать email
createAndPrint("Ivan", "ivan@mail.ru"); createAndPrint("Sergey", "ivan@mail.ru");
В методе создания мы логируем каждый факт обращения к методу, а также, мы будем логировать все сущности, которые этот метод нам вернул. Результат будет таким:
creating user with parameters: Ivan, ivan@mail.ru created user: User(id=1, name=Ivan, email=ivan@mail.ru) created user: User(id=1, name=Ivan, email=ivan@mail.ru) creating user with parameters: Sergey, ivan@mail.ru created user: User(id=2, name=Sergey, email=ivan@mail.ru) all entries are below: User(id=1, name=Ivan, email=ivan@mail.ru) User(id=2, name=Sergey, email=ivan@mail.ru)
Мы видим, что фактически приложение вызывало метод 3 раза, а заходило в него только два раза. Один раз для метода совпадал ключ, и он просто возвращал закэшированное значение.
3. Принудительное кэширование. @CachePut
Бывают ситуации, когда мы хотим кэшировать возвращаемое значение для какой-то сущности, но в то же время, нам нужно обновить кэш. Для таких нужд существует аннотация @CachePut. Оно пропускает приложение в метод, при этом, обновляя кэш для возвращаемого значения, даже если оно уже закэшировано.
Добавим пару методов, в которых мы будем сохранять юзера. Один из них мы пометим обычной аннотацией @Cacheable, второй — @CachePut.
@Override @Cacheable(value = "users", key = "#user.name") public User createOrReturnCached(User user) { log.info("creating user: {}", user); return repository.save(user); } @Override @CachePut(value = "users", key = "#user.name") public User createAndRefreshCache(User user) { log.info("creating user: {}", user); return repository.save(user); }
Первый метод будет просто возвращать закэшированные значения, второй — принудительно обновлять кэш. Кэширование будет осуществляться по ключу #user.name. Напишем соответствующий тест.
@Test public void createAndRefresh() { User user1 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("created user1: {}", user1); User user2 = service.createOrReturnCached(new User("Vasya", "misha@mail.ru")); log.info("created user2: {}", user2); User user3 = service.createAndRefreshCache(new User("Vasya", "kolya@mail.ru")); log.info("created user3: {}", user3); User user4 = service.createOrReturnCached(new User("Vasya", "petya@mail.ru")); log.info("created user4: {}", user4); }
По той логике, которая уже описывалась, при первом сохранении пользователя с именем «Vasya» через метод createOrReturnCached() далее мы будем получать кэшированную сущность, при этом, в сам метод приложение заходить не будет. Если же мы вызовем метод createAndRefreshCache(), кэшированная сущность для ключа с именем «Vasya» перезапишется в кэше. Выполним тест и посмотрим, что будет выведено в консоль.
creating user: User(id=null, name=Vasya, email=vasya@mail.ru) created user1: User(id=1, name=Vasya, email=vasya@mail.ru) created user2: User(id=1, name=Vasya, email=vasya@mail.ru) creating user: User(id=null, name=Vasya, email=kolya@mail.ru) created user3: User(id=2, name=Vasya, email=kolya@mail.ru) created user4: User(id=2, name=Vasya, email=kolya@mail.ru)
Мы видим, что user1 благополучно записался в базу и кэш. При повторной попытке записать юзера с таким же именем мы получаем закэшированный результат выполнения первого обращения (user2, для которого id такой же, как у user1, что говорит нам о том, что юзер не был записан, и это просто кэш). Далее, мы пишем третьего пользователя через второй метод, который даже при имеющемся закэшированном результате всё равно вызвал метод и записал в кэш новый результат. Это user3. Как мы видим, у него уже новый id. После чего, мы вызываем первый метод, который берёт новый кэш, добавленный user3.
4. Удаление из кэша. @CacheEvict
Иногда возникает необходимость жёстко обновить какие-то данные в кэше. Например, сущность уже удалена из базы, но она по-прежнему доступна из кэша. Для сохранения консистентности данных, нам необходимо хотя бы не хранить в кэше удалённые данные.
Добавим в сервис ещё пару методов.
@Override public void delete(Long id) { log.info("deleting user by id: {}", id); repository.deleteById(id); } @Override @CacheEvict("users") public void deleteAndEvict(Long id) { log.info("deleting user by id: {}", id); repository.deleteById(id); }
Первый будет просто удалять пользователя, второй тоже будет его удалять, но мы пометим его аннотацией @CacheEvict. Добавим тест, который будет создавать двух юзеров, после чего, одного будет удалять через простой метод, а второго — через аннотируемый метод. После чего, мы достанем этих юзеров через метод get().
@Test public void delete() { User user1 = service.create(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user1.getId())); User user2 = service.create(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user2.getId())); service.delete(user1.getId()); service.deleteAndEvict(user2.getId()); log.info("{}", service.get(user1.getId())); log.info("{}", service.get(user2.getId())); }
Логично, что раз наш юзер уже закэширован, удаление не помешает нам его как бы получить — ведь он закэширован. Посмотрим логи.
getting user by id: 1 User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 User(id=2, name=Vasya, email=vasya@mail.ru) deleting user by id: 1 deleting user by id: 2 User(id=1, name=Vasya, email=vasya@mail.ru) getting user by id: 2 javax.persistence.EntityNotFoundException: User not found by id 2
Мы видим, что приложение благополучно сходило оба раза в метод get() и Spring закэшировал эти сущности. Далее, мы удалили их через разные методы. Первый мы удалили обычным путём, и закэшированное значение осталось, поэтому когда мы попытались получить юзера под id 1, нам это удалось. Когда же мы попытались получить юзера 2, метод вернул нам EntityNotFoundException — такого юзера в кэше не оказалось.
5. Группировка настроек. @Caching
Иногда один метод требует нескольких настроек кэширования. Для этих целей используется аннотация @Caching. Выглядеть это может приблизительно так:
@Caching( cacheable = { @Cacheable("users"), @Cacheable("contacts") }, put = { @CachePut("tables"), @CachePut("chairs"), @CachePut(value = "meals", key = "#user.email") }, evict = { @CacheEvict(value = "services", key = "#user.name") } ) void cacheExample(User user) { }
Это единственный способ группировать аннотации. Если Вы попытаетесь нагородить что-то вроде
@CacheEvict("users") @CacheEvict("meals") @CacheEvict("contacts") @CacheEvict("tables") void cacheExample(User user) { }
то IDEA сообщит Вам, что так нельзя.
6. Гибкая настройка. CacheManager
Наконец-то мы разобрались с кэшем, и он перестал быть для нас чем-то непонятным и страшным. Теперь давайте заглянем под капот и посмотрим, как мы можем настроить кэширование в целом.
Для таких задач существует CacheManager. Он существует везде, где есть Spring Cache. Когда мы добавили аннотацию @EnableCache, такой кэш менеджер автоматически будет создан Spring. Мы можем убедиться в этом, если заавтовайрим ApplicationContext и вскроем его на брейкпоинте. Среди прочих бинов, будет и бин «cacheManager».
Я остановил приложение на этапе, когда уже два юзера были созданы и помещены в кэш. Если мы вызовем нужный нам бин через Evaluate Expression, то мы увидим, что такой бин действительно есть, в нём есть ConcurentMapCache с ключом «users» и значением ConcurrentHashMap, в которой уже лежат закэшированные юзеры.
Мы, в свою очередь, можем создать свой кэш-менеджер, с хабром и программистами, после чего, тонко настроить его на наш вкус.
@Bean("habrCacheManager") public CacheManager cacheManager() { return null; }
Осталось только выбрать, какой именно кэш-менеджер мы будем использовать, потому что их предостаточно. Я не буду перечислять все кэш-менеджеры, достаточно будет знать, что есть такие:
- SimpleCacheManager — самый простой кэш-менеджер, удобный для изучения и тестирования.
- ConcurrentMapCacheManager — лениво инициализирует возвращаемые экземпляры для каждого запроса. Также рекомендуется для тестирования и изучения работы с кэшем, а также, для каких-то простых действий, вроде наших. Для серьёзной работы с кэшем рекомендуются имплементации ниже.
- JCacheCacheManager, EhCacheCacheManager, CaffeineCacheManager — серьёзные кэш-менеджеры «от партнёров», гибко настраиваемые и выполняющие задачи очень широкого спектра действия.
В рамках своего скромного поста я не буду описывать кэш-менеджеры из последней тройки. Вместо этого, мы разберём несколько аспектов настройки кэш-менеджера на примере ConcurrentMapCacheManager.
Итак, досоздадим наш кэш-менеджер.
@Bean("habrCacheManager") public CacheManager cacheManager() { return new ConcurrentMapCacheManager(); }
Наш кэш-менеджер готов.
7. Настройка кэша. Время жизни, максимальный размер и проч.
Для этого нам потребуется довольно популярная библиотека Google Guava. Я взял последнюю.
compile group: 'com.google.guava', name: 'guava', version: '28.1-jre'
При создании кэш-менеджера переопределим метод createConcurrentMapCache, в котором вызовем CacheBuilder от Guava. В процессе нам будет предложено настроить кэш-менеджер при помощи инициализации следующих методов:
- maximumSize — максимальный размер значений, которые может содержать кэш. При помощи этого параметра можно найти попытаться найти компромисс между нагрузкой на базу данных и на оперативную память JVM.
- refreshAfterWrite — время после записи значения в кэш, после которого оно автоматически обновится.
- expireAfterAccess — время жизни значения после последнего обращения к нему.
- expireAfterWrite — время жизни значения после записи в кэш. Именно этот параметр мы определим.
и прочих.
Определим в менеджере время жизни записи. Чтобы долго не ждать, выставим 1 секунду.
@Bean("habrCacheManager") public CacheManager cacheManager() { return new ConcurrentMapCacheManager() { @Override protected Cache createConcurrentMapCache(String name) { return new ConcurrentMapCache( name, CacheBuilder.newBuilder() .expireAfterWrite(1, TimeUnit.SECONDS) .build().asMap(), false); } }; }
Напишем соответствующий такому случаю тест.
@Test public void checkSettings() throws InterruptedException { User user1 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user1.getId())); User user2 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user2.getId())); Thread.sleep(1000L); User user3 = service.createOrReturnCached(new User("Vasya", "vasya@mail.ru")); log.info("{}", service.get(user3.getId())); }
Мы сохраняем несколько значений в базу данных, причём, если данные закэшированы, мы ничего не сохраняем. Сначала мы сохраняем два значения, потом ожидаем 1 секунду, пока кэш не протухнет, после чего, сохраняем ещё одно значение.
creating user: User(id=null, name=Vasya, email=vasya@mail.ru) getting user by id: 1 User(id=1, name=Vasya, email=vasya@mail.ru) User(id=1, name=Vasya, email=vasya@mail.ru) creating user: User(id=null, name=Vasya, email=vasya@mail.ru) getting user by id: 2 User(id=2, name=Vasya, email=vasya@mail.ru)
Логи показывают, что сначала мы создали юзера, потом попытались ещё одного, но поскольку данные были закэшированы, мы получили их из кэша (в обоих случаях — при сохранении и при получении из базы). Потом протух кэш, о чём сообщает нам запись о фактическом сохранении и фактическом получении юзера.
8. Подведу итог
Рано или поздно, разработчик сталкивается с необходимостью реализации кэширования в проекте. Я надеюсь, что эта статья поможет Вам разобраться в предмете и смотреть на вопросы кэширования смелее.
Гитхаб проекта тут: https://github.com/promoscow/cache

