Микроконтроллеры AVR довольно дешевы и широко распространены. Наверно, с них начинает почти любой embedded разработчик. А среди любителей правит балом Arduino, сердцем которого обычно является ATmega328p. Наверняка многие задумывались: как можно заставить их звучать?
Если посмотреть на существующие проекты, то они бывают нескольких типов:
Последний тип для меня был особенно интересен, т.к. почти не требует дополнительного оборудования. Представляю сообществу свой вариант. Для начала небольшое демо:
Заинтересовавшихся прошу под кат.
Итак, оборудование:
Вроде все.
Простая RC цепочка вместе с динамиком подключается к выводу микроконтроллера. На выходе получаем 8 битный звук с частотой дискретизации 31250Гц. При частоте кристалла в 8МГц можно генерировать до 5 каналов звука + один шумовой канал для перкуссии. При этом используется почти все процессорное время, но после заполнения буфера процессор можно занять чем-то полезным помимо звука:
Данный пример полностью помещается в память ATmega8, 5 каналов + шум обрабатываются при частоте кристалла 8МГц и остается немного времени на анимацию на дисплее.
Так же я хотел показать в этом примере, что библиотеку можно использовать не только как очередную музыкальную открытку, но и подключить звук к уже существующим проектам, например, для уведомлений. И даже при использовании всего одного звукового канала уведомления могут быть гораздо интереснее простой пищалки.
А теперь подробности…
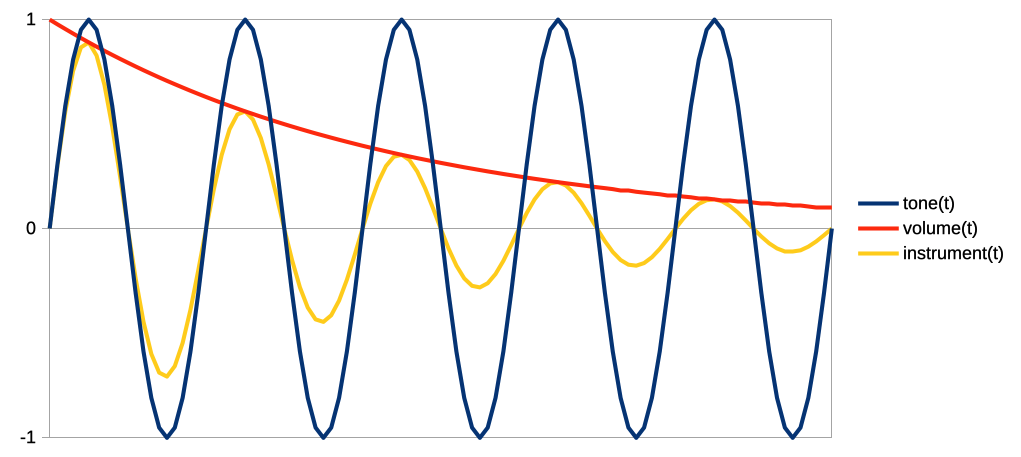
Математика предельно проста. Есть периодичная функция тона, например tone(t) = sin(t * freq / (2 * Pi)).
Так же есть функция изменения громкости основного тона от времени, например volume(t) = e ^ (- t).
В самом простом случае звучание инструмента – это произведение этих функций instrument(t) = tone(t) * volume(t):
На графике это все выглядит примерно так:
Дальше берем все звучащие в данный момент времени инструменты и суммируем их с некоторыми коэффициентами громкости (псевдокод):
Надо только подбирать громкости так, чтобы не было переполнения. И это почти все.
Шумовой канал работает приблизительно так же, только вместо функции тона генератор псевдослучайной последовательности.
Перкуссия — это микс шумового канала и низкочастотной волны, приблизительно в 50-70 Гц.
Конечно, качественного звука таким образом добиться сложно. Но у нас же всего 8 килобайт на все. Надеюсь, это можно простить.
Изначально я ориентировался на ATmega8. Без внешнего кварца она работает на частоте 8МГц и имеет 8 битный ШИМ, что дает базовую частоту дискретизации 8000000 / 256 = 31250Гц. Один таймер использует ШИМ для вывода звука и он же при переполнении вызывает прерывание для передачи следующего значения в генератор ШИМ. Соответственно, у нас 256 тактов для вычисления значения сэмпла на все, включая накладные расходы на прерывание, обновление параметров звуковых каналов, отслеживание времени, когда надо проигрывать очередную ноту и т.д.
Для оптимизации будем активно использовать следующие трюки:
Для начала, разделим время на промежутки по 4 миллисекунды (я назвал их тиками). При частоте дискретизации 31250Гц получаем 125 сэмплов на тик. То, что обязательно нужно считать каждый сэмпл – будем считать каждый сэмпл, а остальное – раз в тик или реже. Например, в рамках одного тика громкость инструмента будет постоянной: instrument(t) = tone(t) * currentVolume; а сам currentVolume будет пересчитываться раз в тик с учетом volume(t) и выбранной громкости звукового канала.
Длительность тика в 4мс была выбрана исходя из простого 8 битного ограничения: при восьмибитном счетчике сэмплов можно работать с частотой дискретизации до 64кГц, при восьмибитном счетчике тиков мы можем измерять время до 1-й секунды.
Сам канал описывается такой структурой:
Условно данные тут разделены на 3 части:
Обратите внимание: форма волны – восьмибитная, громкость – тоже восьмибитная, а результат – 16 битный. С небольшой потерей производительности можно сделать звук (почти) 16 битным.
При борьбе за производительность пришлось прибегнуть к некоторой черной магии.
Пример номер 1. Как пересчитывать громкость каналов:
Таким образом, все каналы пересчитывают громкость раз в тик, но не одновременно.
Пример номер 2. Держать информацию о канале в статической структуре дешевле, чем в массиве. Не вдаваясь в подробности реализации wavechannel.h скажу, что этот файл вставляется в код несколько раз (равное количеству каналов) с разными директивами препроцессора. При каждой вставке создаются новые глобальные переменные и новая функция расчета канала, которая потом инлайнится в основной код:
Пример номер 3. Если мы начнем проигрывать очередную ноту чуть-чуть позже, то все равно никто не заметит. Давайте представим ситуацию: мы чем-то заняли процессор и за это время буфер почти опустошился. Затем мы начинаем его заполнять и тут вдруг оказывается, что на подходе новый такт: надо обновлять текущие ноты, читать из массива что там дальше и т.д. Если мы не успеем, то будут характерные заикания. Гораздо лучше немного заполнить буфер старыми данными, и только потом обновить состояние каналов.
По-хорошему надо бы еще донаполнить буфер после цикла, но, поскольку у нас почти все inline, то заметно раздувается размер кода.
Используется восьмибитный счетчик тиков. При достижении нуля начинается новый такт, счетчику присваивается длительность такта (в тиках), чуть позже проверяется массив музыкальных команд.
Музыкальные данные хранятся в массиве байтов. Записывается примерно так:
Все что начинается с DATA_ – препроцессорные макросы, которые разворачивают параметры в необходимое количество байт данных.
Например, команда DATA_PLAY разворачивается в 2 байта, в которых хранятся: маркер команды (1 бит), пауза перед следующей командой (3 бита), номер канала, на котором играть ноту (4 бита), информация о ноте (8 бит). Самое существенное ограничение – этой командой нельзя делать большие паузы, максимум 7 тактов. Если надо больше, то надо использовать команду DATA_WAIT (до 63 тактов). К сожалению, я так и не нашел, можно ли макрос развернуть в разное количество байт массива в зависимости от параметра макроса. И даже warning не знаю как вывести. Может быть вы подскажите.
В каталоге demos есть несколько примеров под разные микроконтроллеры. Но если коротко, то вот кусок из readme, мне добавить особо нечего:
Если хочется еще что-то делать помимо музыки, то можно увеличить размер буфера с помощью BUFFER_SIZE. Размер буфера должен быть 2^n, но, к сожалению, при размере в 256 происходит падение производительности. Пока не разобрался с этим.
Для увеличения производительности можно увеличить частоту внешним кварцем, можно уменьшить количество каналов, можно уменьшить частоту дискретизации. С последним приемом можно использовать линейную интерполяцию, что несколько компенсирует падение качества звука.
Всякие delay не рекомендуется использовать, т.к. процессорное время расходуется впустую. Вместо этого реализован свой метод в файле microsound/delay.h, который помимо самой паузы занимается наполнением буфера. Данный метод может работать не очень точно на коротких паузах, но на длинных более-менее вменяемо.
Если писать команды вручную, то надо иметь возможность послушать то, что получается. Заливать каждое изменение в микроконтроллер не удобно, особенно если есть альтернатива.
Существует довольно забавный сервис wavepot.com – онлайн редактор JavaScript, в котором надо задать функцию звукового сигнала от времени, и этот сигнал выводится на звуковую карту. Простейший пример:
Я портировал движок на JavaScript, он находится в demos/wavepot.js. Содержимое файла надо вставить в редакторе wavepot.com и можно проводить эксперименты. Пишем свои данные в массив soundData, слушаем, не забываем сохранять.
UPD: На данный момент wavepot сильно поменялся и мой код с ним не совместим. Можно локально поднять старую версию с github, но она работает только с firefox, а в chrome не выводит звук.
Отдельно стоит упомянуть о переменной simulate8bits. Она, согласно названию, симулирует восьмибитный звук. Если вдруг покажется, что барабаны гудят, а в затухающих инструментах при тихом звуке появляются помехи, то это оно, искажение восьмибитного звука. Можно попробовать отключить эту опцию и послушать разницу. Проблема гораздо менее ощутима, если в музыке нет тишины.
В простом варианте схема выглядит так:
Выходной пин зависит от микроконтроллера. Резистор R1 и конденсатор C1 надо подбирать исходя из нагрузки, усилителя (если есть) и т.д. Я не электронщик и приводить формулы не буду, их легко нагуглить вместе с онлайн калькуляторами.
У меня R1 = 130 Ом, С1 = 0.33 мкФ. На выход подключаю обычные китайские наушники.
Как я говорил выше, при умножении двух восьмибитных чисел (частота и громкость) мы получаем 16 битное число. Его можно не округлять до восьмибитного, а выводить оба байта в 2 ШИМ канала. Если эти 2 канала смешать в пропорции 1/256, то мы можем получить 16 битный звук. Разницу с восьмибитным особенно легко услышать на плавно затухающих звуках и барабанах в моменты, когда звучит только один инструмент.
Подключение 16 битного выхода:
Здесь важно правильно смешать 2 выхода: сопротивление R2 должно быть в 256 раз больше сопротивления R1. Чем точнее, тем лучше. К сожалению, даже резисторы с погрешностью 1% не дают требуемой точности. Однако, даже с не очень точным подбором резисторов искажения можно заметно ослабить.
К сожалению, при использовании 16 битного звука проседает производительность и 5 каналов + шум уже не успевают обрабатываться за отведенные 256 тактов.
Да, можно. У меня только китайский клон nano на ATmega328p, на нем работает. Скорее всего другие ардуины на ATmega328p тоже должны работать. ATmega168 вроде бы имеет те же регистры управления таймерами. Скорее всего на них будет работать без изменений. На других микроконтроллерах надо проверять, возможно потребуется дописать драйвер.
В demos/arduino328p есть скетч, но чтобы он нормально открылся в Arduino IDE, его нужно скопировать в корень проекта.
В примере генерируется 16 битный звук и используются выходы D9 и D10. Для упрощения можно ограничиться 8 битным звуком и использовать только один выход D9.
Поскольку почти все ардуины работают на 16МГц, то, при желании, можно увеличить количество каналов до 8.
В ATtiny нет аппаратного умножения. Программное умножение, которое использует компилятор дико медленное и его лучше не использовать. При использовании оптимизированных ассемблерных вставок производительность падает раза в 2 по сравнению с ATmega. Казалось бы, смысла использовать ATtiny нет вообще, но…
На некоторых ATtiny есть умножитель частоты, PLL. А это значит, что на таких микроконтроллерах есть 2 интересные особенности:
Отсюда вывод: некоторые ATtiny использовать для генерации звука можно. Они успевают обрабатывать те же 5 инструментов + шумовой канал, но на 16 МГц и им не нужен внешний кварц.
Минус в том, что больше частоту уже не повысить, а вычисления занимают почти все время. Для освобождения ресурсов можно уменьшать количество каналов или частоту дискретизации.
Еще один минус в необходимости использования сразу двух таймеров: один для ШИМ, второй для прерывания. На этом, обычно, таймеры и заканчиваются.
Из известных мне микроконтроллеров с PLL могу упомянуть ATtiny85/45/25 (8 ног), ATtiny861/461/261 (20 ног), ATtiny26 (20 ног).
Что касается памяти, то разница с ATmega не велика. В 8кб вполне поместится несколько инструментов и мелодий. В 4кб можно поместить 1-2 инструмента и 1-2 мелодии. В 2 килобайта что-то поместить сложно, но если очень хочется, то можно. Надо разинлайнивать методы, отключать некоторые функции типа контроля громкости по каналам, уменьшать частоту дискретизации и количество каналов. В общем, на любителя, но рабочий пример на ATtiny26 есть.
Проблемы есть. И самая большая проблема – это скорость вычислений. Код полностью написан на C с небольшими ассемблерными вставками умножения для ATtiny. Оптимизация отдается компилятору и он иногда ведет себя странно. При небольших изменениях, которые вроде бы не должны ни на что влиять, можно получить заметное просаживание производительности. Причем изменение с -Os на -O3 не всегда помогает. Один из таких примеров – использование буфера размером 256 байт. Особенно неприятно то, что нет гарантии, что в новых версиях компилятора мы не получим падение производительности на том же коде.
Другая проблема в том, что совсем не реализован механизм затухания перед следующей нотой. Т.е. когда на каком-то канале одна нота сменяется другой, то старое звучание резко прерывается, иногда слышен небольшой щелчок. Хотелось бы найти способ избавиться от этого без потери производительности, но пока так.
Нет команд для плавного нарастания/затухания громкости. Особенно критично для коротких мелодий-уведомлений, где в конце надо сделать быстрое затухание громкости, чтобы не было резкого обрыва звучания. Частично проблема обходится написанием череды команд с ручной установкой громкости и короткой паузы.
Выбранный подход в принципе не способен обеспечить натуралистичное звучание инструментов. Для более натуралистичного звучания нужно разделить звуки инструментов на attack-sustain-release, использовать хотя бы первые 2 части и с гораздо большей длительностью, чем один период колебания. Но тогда данных для инструмента потребуется гораздо больше. Была идея использовать более короткие волновые таблицы, например в 32 байта вместо 256, но без интерполяции сильно падает качество звука, а с интерполяцией падает производительность. А еще 8 бит дискретизации явно мало для музыки, но это можно обойти.
Размер буфера ограничен в 256 сэмплов. Это соответствует примерно 8 миллисекундам и это максимальный цельный промежуток времени, который можно отдать другим задачам. При этом выполнение задач все равно периодически приостанавливается прерываниями.
Замена стандартного delay работает не очень точно на коротких паузах.
Уверен, что это не полный список.
Если посмотреть на существующие проекты, то они бывают нескольких типов:
- Генераторы квадратных импульсов. Генерация с помощью ШИМ или дергать пины в прерываниях. В любом случае, получается очень характерный пищащий звук.
- Использование внешнего оборудования типа MP3 декодера.
- Использование ШИМ для вывода 8 битного (иногда 16 битного) звука в формате PCM или ADPCM. Поскольку памяти в микроконтроллерах для этого явно не достаточно, то обычно используют SD карту.
- Использование ШИМ для генерации звука на основе волновых таблиц, подобных MIDI.
Последний тип для меня был особенно интересен, т.к. почти не требует дополнительного оборудования. Представляю сообществу свой вариант. Для начала небольшое демо:
Заинтересовавшихся прошу под кат.
Итак, оборудование:
- ATmega8 или ATmega328. Портировать на другие ATmega не сложно. И даже на ATtiny, но об этом позже;
- Резистор;
- Конденсатор;
- Динамик или наушники;
- Питание;
Вроде все.
Простая RC цепочка вместе с динамиком подключается к выводу микроконтроллера. На выходе получаем 8 битный звук с частотой дискретизации 31250Гц. При частоте кристалла в 8МГц можно генерировать до 5 каналов звука + один шумовой канал для перкуссии. При этом используется почти все процессорное время, но после заполнения буфера процессор можно занять чем-то полезным помимо звука:
Данный пример полностью помещается в память ATmega8, 5 каналов + шум обрабатываются при частоте кристалла 8МГц и остается немного времени на анимацию на дисплее.
Так же я хотел показать в этом примере, что библиотеку можно использовать не только как очередную музыкальную открытку, но и подключить звук к уже существующим проектам, например, для уведомлений. И даже при использовании всего одного звукового канала уведомления могут быть гораздо интереснее простой пищалки.
А теперь подробности…
Волновые таблицы или wavetables
Математика предельно проста. Есть периодичная функция тона, например tone(t) = sin(t * freq / (2 * Pi)).
Так же есть функция изменения громкости основного тона от времени, например volume(t) = e ^ (- t).
В самом простом случае звучание инструмента – это произведение этих функций instrument(t) = tone(t) * volume(t):
На графике это все выглядит примерно так:
Дальше берем все звучащие в данный момент времени инструменты и суммируем их с некоторыми коэффициентами громкости (псевдокод):
for (i = 0; i < CHANNELS; i++) { value += channels[i].tone(t) * channels[i].volume(t) * channels[i].volume; }
Надо только подбирать громкости так, чтобы не было переполнения. И это почти все.
Шумовой канал работает приблизительно так же, только вместо функции тона генератор псевдослучайной последовательности.
Перкуссия — это микс шумового канала и низкочастотной волны, приблизительно в 50-70 Гц.
Конечно, качественного звука таким образом добиться сложно. Но у нас же всего 8 килобайт на все. Надеюсь, это можно простить.
Что можно выжать из 8 бит
Изначально я ориентировался на ATmega8. Без внешнего кварца она работает на частоте 8МГц и имеет 8 битный ШИМ, что дает базовую частоту дискретизации 8000000 / 256 = 31250Гц. Один таймер использует ШИМ для вывода звука и он же при переполнении вызывает прерывание для передачи следующего значения в генератор ШИМ. Соответственно, у нас 256 тактов для вычисления значения сэмпла на все, включая накладные расходы на прерывание, обновление параметров звуковых каналов, отслеживание времени, когда надо проигрывать очередную ноту и т.д.
Для оптимизации будем активно использовать следующие трюки:
- Поскольку процессор у нас восьмибитный, то переменные будем стараться делать такими же. Иногда будем пользоваться 16 битными.
- Вычисления условно разделим на частые и не очень. Первые необходимо вычислять для каждого сэмпла, вторые – заметно реже, раз в несколько десятков/сотен сэмплов.
- Для равномерного распределения нагрузки во времени мы используем циклический буфер. В основном цикле программы мы буфер наполняем, в прерывании вычитываем. Если все хорошо, то наполняется буфер быстрее, чем опустошается и у нас есть время на что-то еще.
- Код написан на C с большим количеством inline. Практика показывает, что так заметно быстрее.
- Все что можно просчитать препроцессором, особенно с участием деления, делается препроцессором.
Для начала, разделим время на промежутки по 4 миллисекунды (я назвал их тиками). При частоте дискретизации 31250Гц получаем 125 сэмплов на тик. То, что обязательно нужно считать каждый сэмпл – будем считать каждый сэмпл, а остальное – раз в тик или реже. Например, в рамках одного тика громкость инструмента будет постоянной: instrument(t) = tone(t) * currentVolume; а сам currentVolume будет пересчитываться раз в тик с учетом volume(t) и выбранной громкости звукового канала.
Длительность тика в 4мс была выбрана исходя из простого 8 битного ограничения: при восьмибитном счетчике сэмплов можно работать с частотой дискретизации до 64кГц, при восьмибитном счетчике тиков мы можем измерять время до 1-й секунды.
Немного кода
Сам канал описывается такой структурой:
typedef struct { // Info about wave const int8_t* waveForm; // Wave table array uint16_t waveSample; // High byte is an index in waveForm array uint16_t waveStep; // Frequency, how waveSample is changed in time // Info about volume envelope const uint8_t* volumeForm; // Array of volume change in time uint8_t volumeFormLength; // Length of volumeForm uint8_t volumeTicksPerSample; // How many ticks should pass before index of volumeForm is changed uint8_t volumeTicksCounter; // Counter for volumeTicksPerSample // Info about volume uint8_t currentVolume; // Precalculated volume for current tick uint8_t instrumentVolume; // Volume of channel } waveChannel;
Условно данные тут разделены на 3 части:
- Информация о форме волны, фаза, частота.
waveForm: информация о функции tone(t): ссылка на массив длиной 256 байт. Задает тембр, звучание инструмента.
waveSample: старший байт указывает на текущий индекс массива waveForm.
waveStep: задает частоту, на сколько waveSample будет увеличен при подсчете следующего сэмпла.
Каждый сэмпл считается примерно так:
int8_t tone = channelData.waveForm[channelData.waveSample >> 8]; channelData.waveSample += channelaData.waveStep; return tone * channelData.currentVolume;
- Информация о громкости. Задает функцию изменения громкости от времени. Постольку громкость меняется не так часто, то пересчитывать ее можно реже, раз в тик. Делается это примерно так:
if ((channel->volumeTicksCounter--) == 0 && channel->volumeFormLength > 0) { channel->volumeTicksCounter = channel->volumeTicksPerSample; channel->volumeFormLength--; channel->volumeForm++; } channel->currentVolume = channel->volumeForm * channel->instrumentVolume >> 8;
- Задает громкость канала и посчитанную текущую громкость.
Обратите внимание: форма волны – восьмибитная, громкость – тоже восьмибитная, а результат – 16 битный. С небольшой потерей производительности можно сделать звук (почти) 16 битным.
При борьбе за производительность пришлось прибегнуть к некоторой черной магии.
Пример номер 1. Как пересчитывать громкость каналов:
if ((tickSampleCounter--) == 0) { // Наступил новый тик tickSampleCounter = SAMPLES_PER_TICK – 1; // Посчитать еще что-то } // volume recalculation should no be done so often for all channels if (tickSampleCounter < CHANNELS_SIZE) { recalculateVolume(channels[tickSampleCounter]); }
Таким образом, все каналы пересчитывают громкость раз в тик, но не одновременно.
Пример номер 2. Держать информацию о канале в статической структуре дешевле, чем в массиве. Не вдаваясь в подробности реализации wavechannel.h скажу, что этот файл вставляется в код несколько раз (равное количеству каналов) с разными директивами препроцессора. При каждой вставке создаются новые глобальные переменные и новая функция расчета канала, которая потом инлайнится в основной код:
#if CHANNELS_SIZE >= 1 val += channel0NextSample(); #endif #if CHANNELS_SIZE >= 2 val += channel1NextSample(); #endif …
Пример номер 3. Если мы начнем проигрывать очередную ноту чуть-чуть позже, то все равно никто не заметит. Давайте представим ситуацию: мы чем-то заняли процессор и за это время буфер почти опустошился. Затем мы начинаем его заполнять и тут вдруг оказывается, что на подходе новый такт: надо обновлять текущие ноты, читать из массива что там дальше и т.д. Если мы не успеем, то будут характерные заикания. Гораздо лучше немного заполнить буфер старыми данными, и только потом обновить состояние каналов.
while ((samplesToWrite) > 4) { // Ждем в цикле пока буфер не будет почти заполнен fillBuffer(SAMPLES_PER_TICK); // Наполняем буфер в течение какого-то времени updateMusicData(); // Обновляем состояние нот }
По-хорошему надо бы еще донаполнить буфер после цикла, но, поскольку у нас почти все inline, то заметно раздувается размер кода.
Музыка
Используется восьмибитный счетчик тиков. При достижении нуля начинается новый такт, счетчику присваивается длительность такта (в тиках), чуть позже проверяется массив музыкальных команд.
Музыкальные данные хранятся в массиве байтов. Записывается примерно так:
const uint8_t demoSample[] PROGMEM = { DATA_TEMPO(160), // Set beats per minute DATA_INSTRUMENT(0, 1), // Assign instrument 1 (see setSample) to channel 0 DATA_INSTRUMENT(1, 1), // Assign instrument 1 (see setSample) to channel 1 DATA_VOLUME(0, 128), // Set volume 128 to channel 0 DATA_VOLUME(1, 128), // Set volume 128 to channel 1 DATA_PLAY(0, NOTE_A4, 1), // Play note A4 on channel 0 and wait 1 beat DATA_PLAY(1, NOTE_A3, 1), // Play note A3 on channel 1 and wait 1 beat DATA_WAIT(63), // Wait 63 beats DATA_END() // End of data stream };
Все что начинается с DATA_ – препроцессорные макросы, которые разворачивают параметры в необходимое количество байт данных.
Например, команда DATA_PLAY разворачивается в 2 байта, в которых хранятся: маркер команды (1 бит), пауза перед следующей командой (3 бита), номер канала, на котором играть ноту (4 бита), информация о ноте (8 бит). Самое существенное ограничение – этой командой нельзя делать большие паузы, максимум 7 тактов. Если надо больше, то надо использовать команду DATA_WAIT (до 63 тактов). К сожалению, я так и не нашел, можно ли макрос развернуть в разное количество байт массива в зависимости от параметра макроса. И даже warning не знаю как вывести. Может быть вы подскажите.
Использование
В каталоге demos есть несколько примеров под разные микроконтроллеры. Но если коротко, то вот кусок из readme, мне добавить особо нечего:
#include "../../microsound/devices/atmega8timer1.h" #include "../../microsound/micromusic.h" // Make some settings #define CHANNELS_SIZE 5 #define SAMPLES_SIZE 16 #define USE_NOISE_CHANNEL initMusic(); // Init music data and sound control sei(); // Enable interrupts, silence sound should be generated setSample(0, instrument1); // Use instrument1 as sample 0 setSample(1, instrument2); // Init all other instruments… playMusic(mySong); // Start playing music at pointer mySong while (!isMusicStopped) { fillMusicBuffer(); // Fill music buffer in loop // Do some other stuff }
Если хочется еще что-то делать помимо музыки, то можно увеличить размер буфера с помощью BUFFER_SIZE. Размер буфера должен быть 2^n, но, к сожалению, при размере в 256 происходит падение производительности. Пока не разобрался с этим.
Для увеличения производительности можно увеличить частоту внешним кварцем, можно уменьшить количество каналов, можно уменьшить частоту дискретизации. С последним приемом можно использовать линейную интерполяцию, что несколько компенсирует падение качества звука.
Всякие delay не рекомендуется использовать, т.к. процессорное время расходуется впустую. Вместо этого реализован свой метод в файле microsound/delay.h, который помимо самой паузы занимается наполнением буфера. Данный метод может работать не очень точно на коротких паузах, но на длинных более-менее вменяемо.
Создание своей музыки
Если писать команды вручную, то надо иметь возможность послушать то, что получается. Заливать каждое изменение в микроконтроллер не удобно, особенно если есть альтернатива.
Существует довольно забавный сервис wavepot.com – онлайн редактор JavaScript, в котором надо задать функцию звукового сигнала от времени, и этот сигнал выводится на звуковую карту. Простейший пример:
function dsp(t) { return 0.1 * Math.sin(2 * Math.PI * t * 440); }
Я портировал движок на JavaScript, он находится в demos/wavepot.js. Содержимое файла надо вставить в редакторе wavepot.com и можно проводить эксперименты. Пишем свои данные в массив soundData, слушаем, не забываем сохранять.
UPD: На данный момент wavepot сильно поменялся и мой код с ним не совместим. Можно локально поднять старую версию с github, но она работает только с firefox, а в chrome не выводит звук.
Отдельно стоит упомянуть о переменной simulate8bits. Она, согласно названию, симулирует восьмибитный звук. Если вдруг покажется, что барабаны гудят, а в затухающих инструментах при тихом звуке появляются помехи, то это оно, искажение восьмибитного звука. Можно попробовать отключить эту опцию и послушать разницу. Проблема гораздо менее ощутима, если в музыке нет тишины.
Подключение
В простом варианте схема выглядит так:
+5V ^ MCU | +-------+ +---+VC | R1 | Pin+---/\/\--+-----> OUT | | | +---+GN | === C1 | +-------+ | | | --- Grnd --- Grnd
Выходной пин зависит от микроконтроллера. Резистор R1 и конденсатор C1 надо подбирать исходя из нагрузки, усилителя (если есть) и т.д. Я не электронщик и приводить формулы не буду, их легко нагуглить вместе с онлайн калькуляторами.
У меня R1 = 130 Ом, С1 = 0.33 мкФ. На выход подключаю обычные китайские наушники.
Что там было про 16 битный звук?
Как я говорил выше, при умножении двух восьмибитных чисел (частота и громкость) мы получаем 16 битное число. Его можно не округлять до восьмибитного, а выводить оба байта в 2 ШИМ канала. Если эти 2 канала смешать в пропорции 1/256, то мы можем получить 16 битный звук. Разницу с восьмибитным особенно легко услышать на плавно затухающих звуках и барабанах в моменты, когда звучит только один инструмент.
Подключение 16 битного выхода:
+5V ^ MCU | +-------+ +---+VCC | R1 | PinH+---/\/\--+-----> OUT | | | | | R2 | | PinL+---/\/\--+ +---+GND | | | +-------+ === C1 | | --- Grnd --- Grnd
Здесь важно правильно смешать 2 выхода: сопротивление R2 должно быть в 256 раз больше сопротивления R1. Чем точнее, тем лучше. К сожалению, даже резисторы с погрешностью 1% не дают требуемой точности. Однако, даже с не очень точным подбором резисторов искажения можно заметно ослабить.
К сожалению, при использовании 16 битного звука проседает производительность и 5 каналов + шум уже не успевают обрабатываться за отведенные 256 тактов.
А на Arduino можно?
Да, можно. У меня только китайский клон nano на ATmega328p, на нем работает. Скорее всего другие ардуины на ATmega328p тоже должны работать. ATmega168 вроде бы имеет те же регистры управления таймерами. Скорее всего на них будет работать без изменений. На других микроконтроллерах надо проверять, возможно потребуется дописать драйвер.
В demos/arduino328p есть скетч, но чтобы он нормально открылся в Arduino IDE, его нужно скопировать в корень проекта.
В примере генерируется 16 битный звук и используются выходы D9 и D10. Для упрощения можно ограничиться 8 битным звуком и использовать только один выход D9.
Поскольку почти все ардуины работают на 16МГц, то, при желании, можно увеличить количество каналов до 8.
А что с ATtiny?
В ATtiny нет аппаратного умножения. Программное умножение, которое использует компилятор дико медленное и его лучше не использовать. При использовании оптимизированных ассемблерных вставок производительность падает раза в 2 по сравнению с ATmega. Казалось бы, смысла использовать ATtiny нет вообще, но…
На некоторых ATtiny есть умножитель частоты, PLL. А это значит, что на таких микроконтроллерах есть 2 интересные особенности:
- Частота генератора ШИМ 64МГц, что дает период ШИМ в 250кГц, что гораздо лучше, чем 31250Гц при 8 МГц или 62500Гц с кварцем на 16 МГц на любых ATmega.
- Этот же умножитель частоты позволяет без кварца тактовать кристалл на 16 МГц.
Отсюда вывод: некоторые ATtiny использовать для генерации звука можно. Они успевают обрабатывать те же 5 инструментов + шумовой канал, но на 16 МГц и им не нужен внешний кварц.
Минус в том, что больше частоту уже не повысить, а вычисления занимают почти все время. Для освобождения ресурсов можно уменьшать количество каналов или частоту дискретизации.
Еще один минус в необходимости использования сразу двух таймеров: один для ШИМ, второй для прерывания. На этом, обычно, таймеры и заканчиваются.
Из известных мне микроконтроллеров с PLL могу упомянуть ATtiny85/45/25 (8 ног), ATtiny861/461/261 (20 ног), ATtiny26 (20 ног).
Что касается памяти, то разница с ATmega не велика. В 8кб вполне поместится несколько инструментов и мелодий. В 4кб можно поместить 1-2 инструмента и 1-2 мелодии. В 2 килобайта что-то поместить сложно, но если очень хочется, то можно. Надо разинлайнивать методы, отключать некоторые функции типа контроля громкости по каналам, уменьшать частоту дискретизации и количество каналов. В общем, на любителя, но рабочий пример на ATtiny26 есть.
Проблемы
Проблемы есть. И самая большая проблема – это скорость вычислений. Код полностью написан на C с небольшими ассемблерными вставками умножения для ATtiny. Оптимизация отдается компилятору и он иногда ведет себя странно. При небольших изменениях, которые вроде бы не должны ни на что влиять, можно получить заметное просаживание производительности. Причем изменение с -Os на -O3 не всегда помогает. Один из таких примеров – использование буфера размером 256 байт. Особенно неприятно то, что нет гарантии, что в новых версиях компилятора мы не получим падение производительности на том же коде.
Другая проблема в том, что совсем не реализован механизм затухания перед следующей нотой. Т.е. когда на каком-то канале одна нота сменяется другой, то старое звучание резко прерывается, иногда слышен небольшой щелчок. Хотелось бы найти способ избавиться от этого без потери производительности, но пока так.
Нет команд для плавного нарастания/затухания громкости. Особенно критично для коротких мелодий-уведомлений, где в конце надо сделать быстрое затухание громкости, чтобы не было резкого обрыва звучания. Частично проблема обходится написанием череды команд с ручной установкой громкости и короткой паузы.
Выбранный подход в принципе не способен обеспечить натуралистичное звучание инструментов. Для более натуралистичного звучания нужно разделить звуки инструментов на attack-sustain-release, использовать хотя бы первые 2 части и с гораздо большей длительностью, чем один период колебания. Но тогда данных для инструмента потребуется гораздо больше. Была идея использовать более короткие волновые таблицы, например в 32 байта вместо 256, но без интерполяции сильно падает качество звука, а с интерполяцией падает производительность. А еще 8 бит дискретизации явно мало для музыки, но это можно обойти.
Размер буфера ограничен в 256 сэмплов. Это соответствует примерно 8 миллисекундам и это максимальный цельный промежуток времени, который можно отдать другим задачам. При этом выполнение задач все равно периодически приостанавливается прерываниями.
Замена стандартного delay работает не очень точно на коротких паузах.
Уверен, что это не полный список.

