Содержание
Иногда баги сами нас находят. Вот мы впихали большую строку данных — и система подвисла. Это она из-за 1 млн символов упала? Или ей какой-то конкретный не понравился?
Или файл загрузили в систему и он упал. Отчего? Из-за названия, расширения, данных внутри или размеров? Можно спихнуть локализацию на разработчика, пусть сам думает, что плохого в файле. Но часто можно найти причину и самому, а потом более точно описать проблему.
Если найти минимальные данные для воспроизведения, то:
- Вы сэкономите время разработчику — ему не придется подключаться к тестовому стенду, самому грузить файл и дебажить
- Менеджер сможет легко оценить приоритет задачи — это нужно срочно исправлять, или баг может подождать? Пока название «некоторые файлы падают, хз почему» — это сделать сложно...
- Описание бага от понимания причины падения тоже только выиграет.
Как найти минимальные данные для воспроизведения бага? Если есть какие-то подсказки в логах, применяем их. Если подсказок нет, то самый оптимальный метод — метод бисекционного деления (также известный как метод «деления пополам» или «дихотомия»).
Описание метода
Метод применяется для поиска точного места падения:
- Взять падающую пачку данных.
- Разбить пополам.
- Проверить половину 1
- Если упало — значит, проблема там. Работаем дальше с ней.
- Если не упало → проверяем половину 2.
- Повторяем шаги 1-3 до тех пор, пока не останется одно падающее значение.

Метод позволяет довольно быстро локализовать проблему, особенно если это делается программно. Разработчики встраивают такие механизмы в обработку данных. А если не встраивают, то сами и страдают потом, когда к ним приходит тестировщик и говорит «Вот на этом файле падает, а точную причину я не смог найти».
Применение тестировщиками
Строка данных
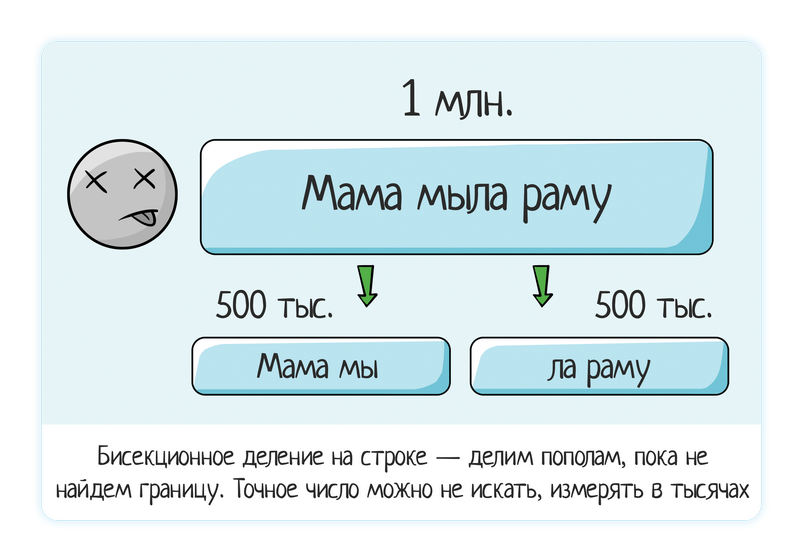
Загрузили строку в 1 млн данных — система зависла.
Пробуем 500 тыс (поделили пополам) — все еще виснет.
Пробуем 250 тыс — не виснет, все ок.
↓
Отсюда вывод, что проблема где-то между 250 и 500 тыс. Снова применяем бисекционное деление.
Пробуем 350 тыс (поделить «на глазок» — вполне допустимо, не надо упарываться на точные цифры при ручном воспроизведении) — все ок
Пробуем 450 тыс — плохо.
Пробуем 400 тыс — плохо.
↓
В целом, уже можно заводить баг. От тестировщика очень редко требуется сообщить, что граница или баг находится четко в числе 286 586. Вполне достаточно локализовать ее примерно — 290 тысяч.
Просто одно дело — проверить «10» и сразу «300 тысяч», и совершенно другое — предоставить более полную информацию: «до 10 тысяч все ок, от 10 до 280 тысяч начинаются тормоза, на 290 тысячах уже падает».
Понятное дело, что когда количество измеряется в тысячах, искать конкретную грань вручную будет слишком долго. Да разработчику это и не нужно. Ну а терять время впустую не хочет никто.
Разумеется, если исходная проблема была на строке длиной в 10-30 символов, можно и точную границу найти. Все дело в разумном отношении ко времени — если с помощью догадок или бисекционного деления можно быстро найти точное значение и оно небольшое (до 100 обычно) — ищем точно. Если проблемы на больших строках, более 1000 → ищем примерно.
Файл
Загрузили файл — упал! Как, почему? Сначала пытаемся сами проанализировать, что могло повлиять, что проверял наш тест? В этом фишка главного правила «сначала позитив, потом негатив». Если не пытаться запихивать в один тест все и сразу:
- Проверили небольшой файл-образец
- Проверили огромный файл на 2гб, с кучей колонок, кучей столбцов, плюс разные вариации внутренних данных
Вот тут будет тяжело локализовать. А если разделять проверки:
- Много строк (но данные позитивные и проверенные ранее)
- Много столбцов
- Большой вес
- ...
То уже примерно понятно, в чем причина. Например, падает на большом количестве строк — от 100 тысяч. Ок, ищем более точную границу с помощью бисекционного деления:
- Разделили файл на два по 50 тысяч, проверили первый.
- Если упал, делим его
- И так, пока не найдем конкретное место падения

Если падение зависит от количества строк — ищем границу примерную: «После 5000 падает, на 4000 тысячах нет». Искать конкретное место (4589), не надо. Слишком долго и не стоит затраченного времени.
Этот баг нашли студенты в Дадате. Туда можно грузить файлы с данными, система эти данные обработает и стандартизирует: исправит опечатки, определит недостающую информацию по справочникам (код КЛАДР, ФИАС, геокоординаты, район города, индекс...).
Девочка попробовала загрузить большой файл и получила результат: система показывает прогресс-бар на 100% загрузки и при этом висит более 30 минут.
Дальше пошла локализация — когда начинается зависание? Это важно, так как влияет на приоритет задачи. Какой типовой объем загружаемых файлов? Как часто пользователи грузят прям МНОГО?
Может быть, система предназначена для обработки тысячи строк, тогда такой баг запихивается в «Исправить когда-нибудь». Или типовые загрузки — 10-50 тысяч строк, которые обрабатывают нормально, ну, значит, баг не горит, исправим чуть позже.
Локализация задачи:
- для файла с 50 тыс строк висит секунд 15,
- для файла с 100 тыс строк висит секунд 30,
- для файла с 150 тыс строк висит 1 мин,
- для файла с 165 тыс строк висит 4 мин,
- для файла 172 тыс. строк при 100% заполненном прогресс-баре зависает больше чем на пол часа
Вот тут уже качественно выполнена работа тестировщика. Предоставлена полная информация о работе системы, на основании которой менеджер уже может сделать вывод, как срочно нужно баг исправлять.
Занимает проверка тоже не слишком много времени. Можно идти или с конца — вот мы загрузили 200 тысяч строк, а когда проблема начинается? Используем метод бисекционного деления!
Или начинаем с относительно небольшого числа — 50 тысяч, постепенно увеличивая (вдвое, метод бисекционного деления, только наоборот). Зная, что на 200 тысячах будет все плохо, понимаем, что тестов будет не сильно много. Проверили 50, 100, 150 — за три теста примерную границу нашли. А дальше копать уже и не надо.

Но помним, что свою теорию тоже надо тестировать. Правда ли, что проблема именно в количестве строк, а не данных внутри файла? Проверить это очень легко — создаете файл на 5000 строк с одним-единственным «позитивным» значением. Тем значением, которое точно работает, которое вы уже проверяли ранее. Если падения нет, значит, тут дело нечисто =)) Похоже, теория о количестве строк была ошибочная и дело в самих данных.

Хотя можно попробовать 10 тысяч строк с точно позитивным значением. Вполне возможно, что падение повторится. Просто ваш исходный файл был на несколько колонок. Или там внутри были символы, занимающие больше байт, чем позитивное значение… В общем, не стоит сразу отвергать теорию о размере файла или количестве строк. Попробуйте бисекционное деление наоборот — увеличьте файл вдвое.
Но в любом случае, помните о том, что чем больше проверок смешано в одной, тем сложнее локализовать баг. Поэтому лучше сразу тестировать количество строк или столбцов на каком-то одном позитивном значении. Чтобы вы были точно уверены, что тестируете количество данных, а не сами данные. Тест-анализ и все такое =)

А что делать, если проблема не в количестве строк, а в самих данных? И вы не знаете, где конкретно. Возможно, вы запихали в тестовый файл данные из «Войны и мира», или откуда-то из интернета скачали большую таблицу… Или проблему вообще нашел пользователь — он загрузил свой файл и у него все упало. Он пришел в саппорт, саппорт пришел к вам: на тебе файл, воспроизводи.
Дальнейшие действия зависят от ситуации. Если у пользователя горят сроки или с него сначала списались деньги, а потом обработка файла упала, то это блокер-баг. И тут нет времени на обучение тестировщика локализации. Проще отдать точно-падающий файл разработчику, пусть подебажит и найдет причину сам.
А вот если вы сами нашли ошибку, то есть время копнуть самому. Опять же, не забывая о здравом смысле, как всегда при локализации. Сначала попробовали сделать выводы сами, потом пошли за помощью. Чтобы сделать вывод самому, нужно:
- проверить логи, там может быть нужный ответ;
- просмотреть содержимое файла: что-то может броситься в глаза, вот и будет первая теория;
- использовать метод бисекционного деления.
В итоге вместо бага «Падает файл, хз почему, вот в аттаче файл на 2гб» вы ставите продуманный и локализованный баг: «Падает файл, если внутри дата формата ДД/ММ/ГГГГГ». И тогда вам не нужен уже файл на 2гб, вам хватит файла на одну строку и одну колонку!

Применение разработчиками
На большом объеме данных тестировщик не ищет четкую границу, потому что это неразумно делать вручную. А вот разработчики применяют метод бисекционного деления в коде и всегда могут найти конкретное место падения. Ведь делить до победного будет система, а не человек!

Например, у нас есть механизм загрузки данных в систему. Загружаться может как 10 тысяч, так и миллион. Но это не суть важно, так как загрузка идет пачками по 200 записей. Если что-то пошло не так, система сама проводит бисекционное деление. Сама. Пока не найдет проблемное место. В логах потом так и читаешь:
- Получил 1000 записей
- Обработал 200 записей
- Обработал 400 записей
- Упс, упал на пачке размером 200 записей!
- Пробую обработать пачку размером 100
- Пробую обработать пачку размером 50
- Пробую обработать пачку размером 25
…
- На таких-то идентификаторах ошибка: не заполнено обязательное поле Email
- Обработал 600 записей
...
Тут, конечно, дальнейшая логика тоже зависит от разработчика. Или обработка прекращается после того, как столкнулись с ошибкой, или идет дальше. Споткнулись на пачке в 200 записей? Доделились до того, чтобы найти узкое место, пометили запись как ошибочную, остальные 199 обработали, поехали дальше.
А вот что делать, если вся пачка разваливается? Пометили запись как ошибочную, но оставшиеся 199 тоже не смогли обработать. Почему? Применяем все тот же метод, ищем новую проблему. Фишка в том, что всегда надо уметь вовремя остановиться.

Если количество ошибок больше 10-50-100, то лучше остановить загрузку. Вполне возможно, что в исходной системе произошла ошибка выгрузки и мы получили миллион «кривых» данных. Если система будет каждую пачку в 200 записей делить пополам, а потом оставшиеся 199 делить, и так далее, то всем будет плохо:
- Лог разрастается с привычных 15 мб до 3 гб и становится нечитаем;
- Система может упасть на попытке генерации итогового сообщения об ошибках (я рассказывала о такой ситуации в разделе «Мнемоника БМВ» ) ;
- Много времени тратится на поиск всех ошибок. Да, система делает это быстрее, чем человек, но если делить миллион пачками по 200 записей, это займет время.
Так что мозг надо включать везде — как на ручном тестировании, так и при написании программного кода. Всегда надо понимать, когда остановиться. Только в случае ручного тестирования это будет «примерно найти границу», а в разработке «остановиться, если падений много».
Резюме
Метод бисекционного деления применяется для поиска точного места падения и локализации бага.
Ищите число и начинайте делить его пополам:
- длина строки;
- размер файла;
- вес файла;
- количество строк / столбцов;
- объем свободной памяти в мобильнике;
- ...

Но помните — когда-то придется остановится! Не надо упарываться и искать точное число, если это потребует проведения тысяч дополнительных тестов. А вот минут 5-10 уделить локализации можно.
PS — больше полезных статей ищите в моем блоге по метке «полезное»

