(достаточно вольный перевод огромной эмоциональной статьи, которая на практике наводит мосты между возможностями Си и Rust в плане решения бизнес-задач и разрешение багов, связанных с ручным управлением памятью. Также должно быть полезно и людям с опытом сборки мусора — отличий в плане семантики намного меньше, чем может показаться — прим.пер.)
С момента, когда я заинтересовался Rust, прошла будто целая вечность. Тем не менее я отчетливо помню знакомство с анализатором заимствований (borrow checker, далее — БЧ — прим.пер.), сопровождаемое головной болью и отчаянием. Разумеется я не один такой страдающий — статей в интернете на тему общения с БЧ предостаточно. Однако я хотел бы выделиться и осветить в данной статье БЧ с точки зрения практической пользы, а не только лишь генератора головной боли.
Периодически мной встречаются мнения, что в Rust — ручное управление памятью (вероятно, раз не автоматическое с GC, тогда какое же еще? — прим.пер.), однако я совершенно не разделяю данную точку зрения. Способ, примененный в Rust, я называю термином "декларативное управление памятью". Почему так — сейчас покажу.
Правила оформления
Вместо того, чтобы теоретизировать, давайте напишем что-то полезное.
Встречайте Овербук — издательство художественной литературы!
Как у любого издательства, в Овербуке есть правила оформления. Точнее, правило всего одно, простое как двери — никаких запятых. Овербук искренне считает, что запятые суть последствие авторской лени и — цитата — "должны быть истреблены как явление". К примеру, фраза "Она прочла и рассмеялась" — хорошая, годная. "Она прочла, после чего рассмеялась" — требует коррекции.
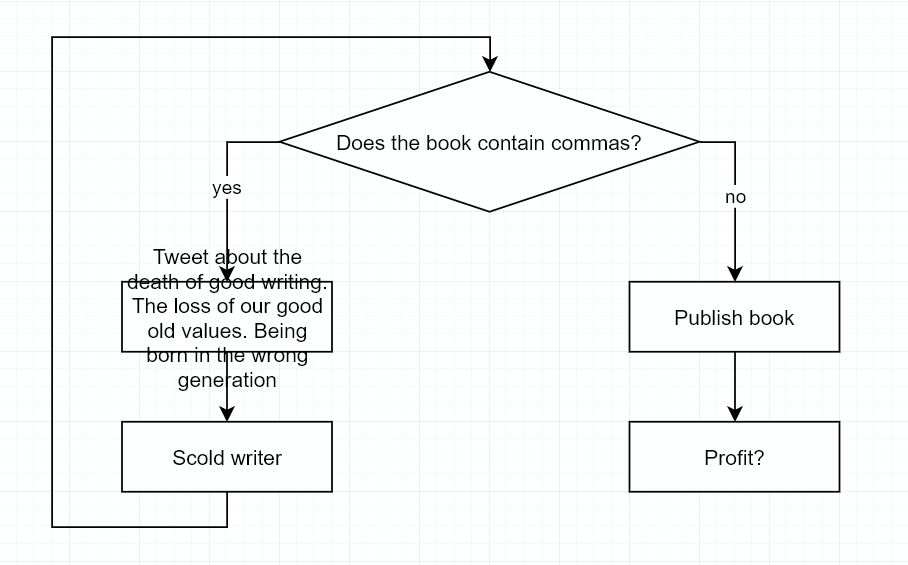
Проще некуда, казалось бы, однако в Овербуке регулярно ловят авторов на патологическом несоблюдении данного правила! Как будто такого правила вообще не существует, возмутительно! Приходится все перепроверять. Вручную. Более того, если по черновику издательством запрашивается правка, автор может прислать версию, исправленную в одном, но испорченную в другом месте, и поэтому все приходится перепроверять с самого начала. Бизнес такого халатного отношения к рабочему времени не терпит, и сама собой возникла необходимость процесс отлова "авторской лени" автоматизировать. Например, компьютерной программой. Можно же, да?
Робин спешит на выручку
Робин — один из сотрудников издательства, который вызвался помочь с написанием программы, так как знал программирование — вот это удача! Правда, в универе все, включая Робина, учили Си и Java, а Java VM в издательстве устанавливать беспричинно запретили — вот так поворот! Ну пусть будет Си, на Си много чего написано, язык уверен и проверен. Все пойдет как надо, инфа 100%.
#include <stdio.h> int main() { printf("Зашибца."); return 0; }
Успех почти в кармане. Но Робин опытный и ожидает в будущем трудности, и запиливает Makefile:
.PHONY: all all: gcc -Wall -O0 -g main.c -o main ./main
Ничего военного:
- Варнинги включены
- Не оптимизировать
- Дебажное инфо
- Запустить после компиляции
Пока что все зашибца:
$ make gcc -Wall -O0 -g main.c -o main ./main Зашибца.
Робин осмелел. "Нам нужные еще некоторые функции и типы данных!"
// пропустим: #include directives struct Mistake { // человеко-читаемое описание ошибки: char *message; }; struct CheckResult { // имя проверяемого файла char *path; // NULL если проблем в файле нет // иначе мы здесь опишем проблему struct Mistake *mistake; }; struct CheckResult check(char *path, char *buf) { struct CheckResult result; result.path = path; result.mistake = NULL; // TODO(Robin): прочесть файл // TODO(Robin): проверить ошибки return result; } // пропустим: main()
"Нам нужен буфер" — продолжал Робин — "Мы в основном работаем с повестями, нам 256КБ должно хватить".
#define BUF_SIZE 256 * 1024 int main() { char buf[BUF_SIZE]; struct CheckResult result = check("sample.txt", buf); if (result.mistake != NULL) { printf("У нас проблемы!"); return 1; } return 0; }
Робин регулярно читает мой блог, и потому, несмотря на отсутствие постоянной практики программирования, смог безошибочно с первого раза написать функцию чтения файлов:
struct CheckResult check(char *path, char *buf) { struct CheckResult result; result.path = path; result.mistake = NULL; FILE *f = fopen(path, "r"); size_t len = fread(buf, 1, BUF_SIZE - 1, f); fclose(f); // не забыть про нулл-терминаторы в строках, это же Си, блин. buf[len] = '\0'; // TODO(Robin): поискать ошибки return result; }
В Овербук принимаются только тексты на литературном английском языке, потому формат принимаемых файлов исключительно *.txt, и переживать по поводу всяких глупых кодировок не стоит. Один раз кто-то пытался протащить в тексте эмодзи, но больше ни этого автора, ни эмодзи в тексте никто никогда не видел...
Энивей, в коде остался всего один TODO — это ли не признак скорого успеха? Робин был горд как никогда. Однако впереди еще была задача выделения памяти:
// надо для malloc #include <stdlib.h> // пропустим: structs, etc. struct CheckResult check(char *path, char *buf) { struct CheckResult result; result.path = path; result.mistake = NULL; FILE *f = fopen("sample.txt", "r"); size_t len = fread(buf, 1, BUF_SIZE - 1, f); fclose(f); buf[len] = '\0'; // Робин в теме C99, и не портит вид функции непонятными // определениями переменных, определяя то, что нужно для цикла, // только в цикле. for (size_t i = 0; i < len; i++) { if (buf[i] == ',') { struct Mistake *m = malloc(sizeof(Mistake)); m->message = "запятые нельзя!"; result.mistake = m; break; } } return result; }
Для проверки написанного Робин сделал выжимку из нетленной классики Льюиса Кэррола "Бармаглот" (в русском переводе Дины Орловской — прим.пер.) в файле sample.txt:
'О, бойся Бармаглота, сын!
Натравил его на программу:
$ make gcc -Wall -O0 -g main.c -o main ./main У нас проблемы!
В файле sample2.txt запятых уже не было — для беспроблемного примера:
Он стал под дерево и ждёт.
И действительно:
$ make gcc -Wall -O0 -g main.c -o main ./main
Проблем не было! Окрыленный успехом Робин отдал программу в релиз и быстро и решительно сбежал на недельку в Европу отдыхать от проделанной работы.
А через неделю...
А через неделю размякшего после отпуска Робина ожидало в корпоративной почте письмо примерно следующего содержания:
Программа работает безукоризненно, определяя, есть ли в тексте ошибка. Однако нам поступило множество запросов от редакторов ее улучшить, возможностью показать, где же именно в тексте произошла ошибка.
Да, мы совершенно уверены, что редакторы в основной своей массе редкостные лентяи и при возможности спихнут с себя любой труд. Однако не мог бы ты все же уделить этой проблеме время?
Робин открыл уже немного подзабытый проект. "Агамсь. Я могу добавить в Mistake указатель на, собственно, ошибку.". Сказано — сделано:
struct Mistake { char *message; // указывает на ошибку char *location; } // ... struct CheckResult check(char *path, char *buf) { // пропустим: определение 'result' // пропустим: чтение файла for (size_t i = 0; i < len; i++) { if (buf[i] == ',') { struct Mistake *m = malloc(sizeof(struct Mistake)); // НОВИНКА: локация проблемы m->location = &buf[i]; m->message = "запятые нельзя!"; result.mistake = m; break; } } return result; }
Надо еще эту инфу напечатать:
void report(struct CheckResult result) { printf("\n"); printf("~ %s ~\n", result.path); if (result.mistake == NULL) { printf("Ошибок нет!!\n"); } else { // внимание: "%s" печатает вообще все. // а нам надо контекст и первых 12 символов текста, или меньше, printf( "проблема: %s: '%.12s'\n", result.mistake->message, result.mistake->location ); } } int main() { char buf[BUF_SIZE]; { struct CheckResult result = check("sample.txt", buf); report(result); } { struct CheckResult result = check("sample2.txt", buf); report(result); } }
«Нормас», — решил Робин. Проверим:
$ make gcc -Wall -O0 -g main.c -o main ./main ~ sample.txt ~ проблема: запятые нельзя!: ', бойся Барм' ~ sample2.txt ~ Ошибок нет!!
Хорошо. А что, если еще более упростить редакторам задачу и проверять все тексты сразу, а в конце выдавать все ошибки?
#define MAX_RESULTS 128 // пропустим: все, что точно работает int main() { char buf[BUF_SIZE]; struct CheckResult bad_results[MAX_RESULTS]; int num_results = 0; char *paths[] = { "sample2.txt", "sample.txt", NULL }; for (int i = 0; paths[i] != NULL; i++) { char *path = paths[i]; struct CheckResult result = check(path, buf); bad_results[num_results++] = result; } for (int i = 0; i < num_results; i++) { report(bad_results[i]); } }
Робин выдохнул. Не то чтобы программисты не любили программирование — просто никогда нельзя знать наверняка, правильно ли работает программа. Но именно здесь вроде все прекрасно.
$ make gcc -Wall -O0 -g main.c -o main ./main ~ sample2.txt ~ Ошибок нет!! ~ sample.txt ~ проблема: запятые нельзя!: ', бойся Барм'
Приключения продолжаются
На следующий день Робин находит письмо:
Приветы, Робин,
Очень классная получилась программа, с помощью нее мы сэкономили уйму времени, особенно с новой фичей, когда можно скормить ей все тексты сразу! Только с отображением места ошибки какая-то шляпа — оно показывает неверный кусок. Глянешь?
"Даблин!" — воскликнул Робин — "У меня же все работало!"
Некоторое время ушло на воспроизведение бага. В конце концов, переставив входные файлы местами, Робин получил ошибку:
int main() { // пропустим: неважный кусок // тут было "sample2.txt", "sample.txt" char *paths[] = { "sample.txt", "sample2.txt", NULL }; for (int i = 0; paths[i] != NULL; i++) { // пропустим проверку } for (int i = 0; i < num_results; i++) { report(results[i]); } } ```bash $ make gcc -Wall -O0 -g main.c -o main ./main ~ sample.txt ~ проблема: запятые нельзя!: 'н стал под д' ~ sample2.txt ~ Ошибок нет!!
Еще какое-то время ушло на вдумчивый осмотр кода. Наконец, отойдя к кофемашине, Робин внезапно понял:
— Итить вы бестолочь, сударь. У меня же общий буфер на все файлы! Я перезаписал его содержимое беспроблемным текстом, а указатель-то с проблемного файла — остался!
Находкой срочно надо было с кем-то поделиться, но ёлки, тут же издательство, а не аутсорс, Робина никто с его проблемами не понимал до конца, хотя его находку все подтверждали:
— Да, точно. Все ошибки были с текстом из самого последнего файла. Зуб даю.
Теперь это бы починить. Выделение отдельного буфера каждому файлу вообще не выход — никакой оперативки не хватит. Отдавать ошибку сразу после отлова — значит отменить последнюю полюбившуюся фичу и кормить прогу по одному файлу по старинке.
"Может тупо копировать только кусок с ошибкой куда-то?" — подумал Робин.
// еще инклуд, для memcpy #include <string.h> struct CheckResult check(char *path, char *buf) { // пропустим: то, что работает for (size_t i = 0; i < len; i++) { if (buf[i] == ',') { struct Mistake *m = malloc(sizeof(struct Mistake)); // копируем максимум 12 символов в "m->location" size_t location_len = len - i; if (location_len > 12) { location_len = 12; } m->location = malloc(location_len + 1); memcpy(m->location, &buf[i], location_len); m->location[location_len] = '\0'; m->message = "запятые нельзя!"; result.mistake = m; break; } } return result; }
Для того, чтоб проблема никогда больше не повторилась, был добавлен новый тестовый файл, sample3.txt:
Но взял он меч, и взял он щит
Опля, работает!
$ make gcc -Wall -O0 -g main.c -o main ./main ~ sample.txt ~ проблема: запятые нельзя!: ', бойся Барм' ~ sample2.txt ~ Ошибок нет!! ~ sample3.txt ~ mistake: запятые нельзя: ', и взял он '
Кореш директора
Разумеется, долго праздник продолжаться не мог — новое письмо от СЕО на следующий день:
Привет, Робин. В чатике Тим,
Я тут показал нашу программку приятелю. Ему дико понравилось, но он заметил, что у нас течет память. Понимаю, что мы в первую очередь издательство, и утечки памяти нам вроде безразличны, но ты мог бы все же глянуть, в чем дело?
"Наша песня хороша", вздохнул Робин и полез открывать проект. Ага, ну да, мы память выделяем с malloc(), а возвращать ее системе с free() не возвращаем. Ну так она должна автоматически освобождаться при завершении программы, не так ли? Робин вроде похожее читал в блоге, но инфа не 100%, к тому же босс вряд ли бы напрягся только из-за того, что кто-то что-то там сказал или написал. В любом случае, надо исправить.
int main() { char buf[BUF_SIZE]; struct CheckResult results[MAX_RESULTS]; int num_results = 0; // пропустим: то, что работает // вернем память системе! for (int i = 0; i < num_results; i++) { free(results[i].mistake); } }
Теперь точно все. Остальное — buf и results определены на стеке и не нуждаются в ручном освобождении. Робин уже было расслабился, как вдруг за спиной появился незнакомец.
— Привет, ты Робин?
— Да, а ты кто?
— Я Джеф, друг Тима. У тебя очень крутая прога.
— Ой, привет, Джеф! Спасибо. Да, и спасибо за утечку. Я ее как раз только что поправил.
— Класс. А можно посмотреть?
Эээ. Ну ладно. Пренебрегая всеми правилами конфиденциальности компании, Робин пустил незнакомого человека за ноутбук. Кореш директора, в конце концов. Через минуту Джеф ответил:
— Почти получилось. Надо добавить еще один free(), и все, в программу можно будет никогда не лезть.
С одной стороны, Робина раздражало, что кто-то прерывает его работу без предупреждения, с другой стороны, он веселился, представив себе новый знак качества "Джеф одобряэ", на случай когда/если его программка снова сломается, и ее снова придется чинить.
int main() { // ну вы поняли... // Больше освобождения памяти богу освобождения памяти! for (int i = 0; i < num_results; i++) { free(results[i].mistake->location); free(results[i].mistake); } }
— Ты это, не переживай. Вызов free() не рекурсивный, освобождает только то, что ты в него передал, прозевать такое просто, как два байта переслать.
Вообще-то я не программист в компании, начнем с этого, подумал Робин. Все пишется на энтузиазме. Я не трогал Си уже черте-сколько, ну короче, Джеф, все ок, замяли. Джеф тем временем продолжал:
— Главное, не перепутай эти вызовы free(). Иначе будет сегфолт.
Робин был вот совсем не уверен, что тут будет именно сегфолт, и вообще, есть же системы, в которых мало того что сегфолтов в принципе не бывает, так и системы, которые не говорят про сегфолт пользователю. Даже Джефу. Пусть живет с этим. А то шибко собой доволен.
— Да-да, безусловно, конечно, спасибо, досвидания.
Спустя год
Робин уже было заскучал. Начальство довольно, программа работает, редакторы эффективны, утечек нет. Овербук усиленно готовился к крупному релизу, и Робин как раз обдумывал рекламную кампанию. Словом, все настолько спокойно, что не могло так долго продолжаться.
Действительно, Робина срочно вызывают на совещание.
— Робин, нам кранты. Ты знаешь, я не люблю такое.
Робин не совсем понимал, что именно не любит Тим. Точно не любит выражаться. Может что-то еще. Может, не любит Си?
— А в чем, собственно, дело?
— Ни черта не работает. Проверялка вчера работала, а сегодня нет.
За последний год поделие Робина стало играть ключевую роль в издательском бизнесе Овербука. Сейчас только после прогона через Проверялку (ей дали название!) издание допускалось к публикации. Это значит, что пока Проверялка не работала, Овербук терял деньги. Десятки долларов в минуту.
Робин немедленно сел за починку. Код выглядел до последнего символа тем же, каким он оставил его год назад. Функционал не изменился, соответственно. Ломаться было нечему.
— Секундочку, — мелькнуло у Робина в голове, — А сколько текстов одновременно загружается в проверялку?
— На этой неделе завал, не меньше 130 текстов в очереди.
А, ну да.
#define MAX_RESULTS 128 int main() { char buf[BUF_SIZE]; struct CheckResult results[MAX_RESULTS]; // ... }
Казалось бы вот, проблема найдена, но Робин знал, что настоящая беда только чудом не вылезла до сих пор. За пределы results Проверялка вылезти не должна (это чревато переполнением стека, но операционка за этим бдит). Но лишь волей случая переменные были определены именно в этом порядке, не позволяя ссылкам на results выходить за пределы самого массива results. Будь buf определен позже, ссылки на results перетекали бы в него, указывая на чужие участки памяти, показывая пользователю произвольный текст из buf вместо ошибок, и вся репутация Овербука пошла бы по грибы. Так оставлять было нельзя. Робин в качестве быстрой заплатки поднял значение MAX_RESULTS до 256. На ближайшее время бизнес был спасен.
— Робин… Спасибо тебе. Ты спас нам всем задницы. Вот в такие моменты мне становится неловко, что мы платим тебе минималку. Не настолько неловко, чтобы почесаться и как-то это изменить, но достаточно, чтобы сожалеть. Ну ты понял. Это фрустрация.
Робину тем временем было не до этого. Амбиции компании легко могут преодолеть барьер в 256 текстов за раз, не сегодня, так через месяц. Проблема не решена. Программу нужно было полностью переписать.
"Да нахрен." — произнес про себя Робин, — "Переписываю на Rust."
Книгой спустя
(видимо, под книгой имеется в виду растбук — прим.пер.)
Робин ввел в консоль cargo new checker и открыл src/main.rs. Удобно. Теперь надо добавить чтение из файла:
use std::fs::read_to_string; fn main() { let s = read_to_string("sample.txt"); }
"Лол, похоже на Ruby!" — за спиной явился Джеф, какого-то лешего тусящий в офисе издательства. Робин промолчал. Хрен тебе, Джеф, а не Ruby. Ты не в теме вообще.
"Так, что у нас тут с поиском запятых?"
fn main() { let s = read_to_string("sample.txt"); s.find(","); }
Не взлетело, понял Робин по сообщению компилятора:
error[E0599]: no method named `find` found for type `std::result::Result<std::string::String, std::io::Error>` in the current scope --> src\main.rs:5:7 | 5 | s.find(","); | ^^^^
Хм. Ошибку чтения файла проигнорировать не удалось — в типе Result<String, Error> метода find() нет, он есть только в String. Робин обязан обработать ошибку чтения.
fn main() -> Result<(), std::io::Error> { let s = read_to_string("sample.txt")?; s.find(","); Ok(()) }
Теперь мы показываем, что main() тоже может упасть, и ошибку из read_to_string() мы перенаправляем в main(), а та роняет всю программу. Это уже выглядело обнадеживающе, даже несмотря на то, что программа по сути ничем полезным не занималась. Можно пойти дальше и посмотреть, что возвращает find():
fn main() -> Result<(), std::io::Error> { let s = read_to_string("sample.txt")?; let result = s.find(","); println!("Result: {:?}", result); Ok(()) }
$ cargo run --quiet Result: Some(22)
Ага. Если оно что-то найдет, вернет Option::Some(index), а если нет, то Option::None. Сюда можно применить сопоставление с образцом (паттерн матчинг, если понятным языком — прим.пер.):
fn main() -> Result<(), std::io::Error> { let path = "sample.txt"; let s = read_to_string(path)?; println!("~ {} ~", path); match s.find(",") { Some(index) => { println!("проблема: запятые нельзя: символ №{}", index); }, None => println!("Ошибок нет!!"), } Ok(()) }
$ cargo run --quiet ~ sample.txt ~ проблема: запятые нельзя: символ №22
Робин читал Песнь Льда и Пламени, потому понимал, что показывать порядковый номер символа в тексте размером с этот слегка бесполезно, даже если ты автор текста. Нужно вернуть отображение позиции с контекстом.
fn main() -> Result<(), std::io::Error> { let path = "sample.txt"; let s = read_to_string(path)?; println!("~ {} ~", path); match s.find(",") { Some(index) => { // так, эта штука ест вообще всю строку, // не только первые 12 символов, // но проблем быть не должно let slice = &s[index..]; println!("проблема: запятые нельзя: {:?}", slice); } None => println!("Ошибок нет!!"), } Ok(()) }
$ cargo run --quiet ~ sample.txt ~ проблема: запятые нельзя: ', бойся Бармаглота, сын!'
Робин готов был обрыдаться от счастья. Нет malloc()! Нет memcpy()! Модный и молодежный синтаксис для нарезания слайсов (ну в Go он тоже есть, например — прим.пер.)! Символьные слайсы можно форматировать с {:?}, и макрос знает, что внутри строка, и сам окружает кавычками. Озадачило, что free() тоже не было. В книге было написано, что память освобожается самостоятельно сразу же, как только переменная выходит за пределы области видимости — то есть s освобождается сразу после match. Слайс (&s[index..]) тоже не выделяет под себя память, но является просто частью изначального массива символов, вычитанного из файла. Вообще надо перечитать этот кусок про память, подумал Робин, а то уже все подзабылось.
Сокращаем разрыв
Смешение всего в main() и общая неструктурированность нового кода Робина раздражала, потому он взялся за рефактор, начав с выделения функции check():
fn main() -> Result<(), std::io::Error> { check("sample.txt")?; Ok(()) } fn check(path: &str) -> Result<(), std::io::Error> { let s = read_to_string(path)?; println!("~ {} ~", path); match s.find(",") { Some(index) => { let slice = &s[index..]; println!("проблема: запятые нельзя: {:?}", slice); } None => println!("Ошибок нет!!"), } Ok(()) }
Что показательно, рефактор не привел к изменению результатов тестирования. Так и надо.
Также было замечено, что новая Проверялка на каждый новый файл выделяет отдельный буфер, то есть аллокаций памяти больше. Подгоним управление памятью под версию Си:
fn main() -> Result<(), std::io::Error> { let mut s = String::with_capacity(256 * 1024); check("sample.txt", &mut s)?; Ok(()) } fn check(path: &str, s: &mut String) -> Result<(), std::io::Error> { use std::fs::File; use std::io::Read; s.clear(); File::open(path)?.read_to_string(s)?; println!("~ {} ~", path); match s.find(",") { Some(index) => { let slice = &s[index..]; println!("проблема: запятые нельзя: {:?}", slice); } None => println!("Ошибок нет!!"), } Ok(()) }
В восторг Робина привели следующие вещи:
- несмотря на изначальный размер буфера
sв 256 КБ, при необходимости он может самостоятельно расширяться. - существенно более читаемый код чтения файла — сразу видно, где и какие ошибки могут выскочить: при открытии файла, и при непосредственном его чтении.
- Можно, в отличие от
#include, лепитьuseровно туда, где его содержимое использовалось: типажReadи его функцияread_to_stringиспользуется только внутриcheck().
Миграция, однако, еще не завершена. В версии Си check() возвращал CheckResult, в котором мог быть Mistake. В версии Rust Робину ничего не мешало убрать CheckResult вовсе, заменив его на Option<Mistake>. Впрочем, Mistake все равно нужен. Робин закатал рукава:
struct Mistake { location: &str, }
Но нет. У компилятора были другие планы.
$ cargo run --quiet error[E0106]: missing lifetime specifier --> src\main.rs:10:15 | 10 | location: &str, | ^ expected lifetime parameter
"Хрень", подумал Робин, "об этом меня и предупреждали!", но общая элегантность уже написанного кода убедила его не бросить все на полпути, а вернуться к книге. Книга в этом вопросе оказалась на редкость неуклюжей в плане объяснения, и все, что Робин оттуда выудил — эта хрень зовется временем жизни (здесь и далее — ВЖ — прим.пер.). Пришлось покурить форумы, и вскоре Робин вернулся с решением:
struct Mistake<'a> { location: &'a str, }
Факт того, что этот стремный код собрался, настолько впечатлила Робина, что он бросился дореализовывать остальные части из версии Си, хотя по хорошему стоило бы остановиться и почитать больше теории по этим самым ВЖ. Если ВЖ настолько важны, я на них еще наткнусь, решил он мимоходом.
В общем, сейчас check() возвращает Option<Mistake> вместо () (спецтип, который возвращается, если из функции ничего не возвращается — прим.пер.):
fn check(path: &str, s: &mut String) -> Result<Option<Mistake>, std::io::Error> { use std::fs::File; use std::io::Read; s.clear(); File::open(path)?.read_to_string(s)?; println!("~ {} ~", path); Ok(match s.find(",") { Some(index) => { let location = &s[index..]; Some(Mistake { location }) } None => None, }) }
Понимание ВЖ Робину пока не особо давалось, зато окружающие концепции он схватывал на лету. Вот например — если функция заканчивается выражением, значение выражения возвращается из функции. match — выражение, потому Ok(match ...) взлетает. Это было слишком круто, чтобы не попробовать его применить к main():
fn main() -> Result<(), std::io::Error> { let mut s = String::with_capacity(256 * 1024); let result = check("sample.txt", &mut s)?; if let Some(mistake) = result { println!("проблема: запятые нельзя: {:?}", mistake.location); } Ok(()) }
"По большому счету, отдельный result мне тут тоже не нужен", защищал себя перед воображаемым ревьюером Робин, "но с ним все куда более читаемо". Еще как-то сразу зашел вот этот if let, вроде и мелочь, можно было оставить и match, но насколько аккуратней выглядит!
От винта!
$ cargo run --quiet error[E0106]: missing lifetime specifier --> src\main.rs:17:55 | 17 | fn check(path: &str, s: &mut String) -> Result<Option<Mistake>, std::io::Error> { | ^^^^^^^ expected lifetime parameter
Невыученные уроки всегда наносят ответный удар, и от этого удара Робин рисковал не оправиться. К счастью, вовремя была замечена рука поддержки от компилятора:
Хелп: Эта функция возвращает тип с заимствованным значением, но в сигнатуре не указывается, было оно заимствовано изpathили изs.
Заимствованное? Этосамое, в Mistake есть location: &'a str — заимствование. Оно пришло из s — одного из параметров. Теоретически их надо объединить одним и тем же ВЖ:
// все эти полные пути и имена типов писать утомительно: use std::io::Error as E; fn check(path: &str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> { // ... }
Так, вроде правильно. Почему ВЖ названо именно 'a? А фиг знает. Может других имен не бывает вовсе? А почему перед именем ВЖ одинарная кавычка, одна? Так надо, что ли? Надо будет опять мануал покурить, потом.
error[E0261]: use of undeclared lifetime name `'a` --> src\main.rs:19:26 | 19 | fn check(path: &str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> { | ^^ undeclared lifetime error[E0261]: use of undeclared lifetime name `'a` --> src\main.rs:19:66 | 19 | fn check(path: &str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> { | ^^ undeclared lifetime
Компилер недоволен. Какое еще декларирование ВЖ? Робин пробежался по коду:
struct Mistake<'a> { location: &'a str, }
Здесь, решил он, компилятор знает про 'a в location: &'a str потому что 'a определено в Mistake<'a>, что в свою очередь страшно напоминает декларацию дженериков из Java. Хохохо. А можно ли подход дженериков из Java в методах применить к ВЖ из Rust?
fn check<'a>(path: &str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> { // ... }
Вот это дела, взлетело!
$ cargo run --quiet ~ sample.txt ~ проблема: запятые нельзя: ", бойся Бармаглота, сын!"
Больше структур!
Передохнув минутку, Робин осмотрел код полностью:
fn main() -> Result<(), std::io::Error> { let mut s = String::with_capacity(256 * 1024); let path = "sample.txt"; let result = check(path, &mut s)?; println!("~ {} ~", path); if let Some(mistake) = result { println!("проблема: запятые нельзя: {:?}", mistake.location); } Ok(()) } struct Mistake<'a> { location: &'a str, } use std::io::Error as E; fn check<'a>(path: &str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> { use std::fs::File; use std::io::Read; s.clear(); File::open(path)?.read_to_string(s)?; Ok(match s.find(",") { Some(index) => { let location = &s[index..]; Some(Mistake { location }) } None => None, }) }
Бесконечные 'a в сигнатурах его напрягали, и вообще не было до конца понятно, на кой пес они там нужны. Впрочем, работает и ладно. Запилим report():
fn main() -> Result<(), std::io::Error> { let mut s = String::with_capacity(256 * 1024); let path = "sample.txt"; let result = check(path, &mut s)?; report(path, result); Ok(()) } fn report(path: &str, result: Option<Mistake>) { println!("~ {} ~", path); if let Some(mistake) = result { println!("проблема: запятые нельзя: {:?}", mistake.location); } else { println!("Ошибок нет!!"); } }
Наверное, путь к файлу надо сделать частью Mistake, тогда я смогу напилить к нему типаж Display и красиво выводить инфо пользователю.
struct Mistake<'a> { // пыщь! path: &'static str, location: &'a str, }
Вовремя Робин вычитал, что для значений, которые живут всю программу, можно и нужно использовать ВЖ 'static. Путь к файлу захардкожен в код, соответственно — жив всю программу от начала до конца. Заполним путь в check():
fn check<'a>(path: &str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> { use std::fs::File; use std::io::Read; s.clear(); File::open(path)?.read_to_string(s)?; Ok(match s.find(",") { Some(index) => { let location = &s[index..]; // пыщь! Some(Mistake { path, location }) } None => None, }) }
Попутно решим уже знакомую проблемку:
$ cargo run --quiet error[E0621]: explicit lifetime required in the type of `path` --> src\main.rs:37:28 | 27 | fn check<'a>(path: &str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> { | ---- help: add explicit lifetime `'static` to the type of `path`: `&'static str` ... 37 | Some(Mistake { path, location }) | ^^^^ lifetime `'static` required
// new: &'static fn check<'a>(path: &'static str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> { // ... }
Вклеим обещаный Display:
use std::fmt; impl<'a> fmt::Display for Mistake<'a> { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!( f, "{}: запятые нельзя: {:?}", self.path, self.location ) } }
И подгоним под это все report():
fn report(result: Option<Mistake>) { if let Some(mistake) = result { println!("{}", mistake); } }
Хорошо, когда все работает :)
$ cargo run --quiet sample.txt: запятые нельзя: ", бойся Бармаглота, сын!"
50 строк кода, включая пустые строки для красоты, пот этом содержание каждой предельно понятно. Если это не счастье, тогда что же?
Сразу несколько текстов
Ай, забыли совсем. Самое главное!
fn main() -> Result<(), std::io::Error> { let mut s = String::with_capacity(256 * 1024); let paths = ["sample.txt", "sample2.txt", "sample3.txt"]; for path in &paths { let result = check(path, &mut s)?; report(result); } Ok(()) }
$ cargo run --quiet sample.txt: запятые нельзя: ", бойся Бармаглота, сын!" sample3.txt: запятые нельзя: ", и взял он щит"
Даже не пришлось напрягаться. Но потом Робин вспомнил, что в версии Си ошибки сначала собирались со всех файлов, а потом выдавались в самом конце. Плевое дело.
fn main() -> Result<(), std::io::Error> { let mut s = String::with_capacity(256 * 1024); let paths = ["sample.txt", "sample2.txt", "sample3.txt"]; // все собери let mut results = vec![]; for path in &paths { let result = check(path, &mut s)?; results.push(result); } // потом отчитайся for result in results { report(result); } Ok(()) }
Как тут вдруг откуда ни возмись...
$ cargo run --quiet error[E0499]: cannot borrow `s` as mutable more than once at a time --> src\main.rs:9:34 | 9 | let result = check(path, &mut s)?; | ^^^^^^ mutable borrow starts here in previous iteration of loop
Паааадажжи. Чего-чего? Нельзя заимствовать s для изменения более одного раза??
Это было что-то совсем уж новое. Заимствование, думал Робин, это ссылка на s, то есть &s. Заимствование для изменения — это, выходит, &mut s. А зачем его заимствовать для изменения несколько раз? Ааа, у нас s это буфер для чтения из файла:
fn check<'a>(path: &'static str, s: &'a mut String) -> Result<Option<Mistake<'a>>, E> { // тут мы пишем в `s` - изменение s.clear(); // и тут мы пишем в `s` - тоже изменение! File::open(path)?.read_to_string(s)?; // все такое. }
Да, и буфер у них один и тот же. Но это получается, что...
Компилятор Rust.
Не собирает программу.
С багом, который уже был в программе на Си!
Но Си его съел и выдавал в рантайме бред, а Rust считает ошибкой компиляции!!
Екарный бабай.
Хорошо. Вероятно, вопрос можно решить способом, аналогичным Си. Только без memcpy(), пожалуйста-пожалуйста.
В первую очередь надо было пересмотреть содержимое Mistake. location сейчас был ссылкой на общую строку, из которой росла по остальному коду зависимость от ВЖ строки. В то же время в Си Mistake владела собственной строкой, в которой хранилась часть оригинала. Как нам завладеть строкой в Rust?
Спустя минуту у Робина было и решение — отдельный тип String, который, в противовес ссылочному &str был владельцем содержимого строки. Изначально Робин ни фига не понимал, зачем нужно два отдельных типа для строки, и просто принимал это как должное. Сейчас было куда понятней.
struct Mistake<'a> { // это все еще ссылка, хоть и вечноживущая path: &'static str, // а вот это всецело принадлежит Mistake location: String, }
Компилятор, настроенный на активацию при каждом сохранении, встрепенулся:
error[E0392]: parameter `'a` is never used --> src\main.rs:27:16 | 27 | struct Mistake<'a> { | ^^ unused parameter | = help: consider removing `'a` or using a marker such as `std::marker::PhantomData`
"Да-да, я в курсе", сказал вслух Робин, удаляя <'a> из структуры. Также оказались не нужны 'a в Display и check():
struct Mistake { // это все еще ссылка, хоть и вечноживущая path: &'static str, // а вот это всецело принадлежит Mistake location: String, } // ... impl fmt::Display for Mistake { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!( f, "{}: запятые нельзя: {:?}", self.path, self.location ) } } // ... fn check(path: &'static str, s: &mut String) -> Result<Option<Mistake>, E> { s.clear(); File::open(path)?.read_to_string(s)?; Ok(match s.find(",") { Some(index) => { let location = &s[index..]; Some(Mistake { path, location }) } None => None, }) }
Компилятор, однако, был неумолим:
error[E0308]: mismatched types --> src\main.rs:43:34 | 43 | Some(Mistake { path, location }) | ^^^^^^^^ | | | expected struct `std::string::String`, found &str | help: try using a conversion method: `location: location.to_string()` | = note: expected type `std::string::String` found type `&str`
Окай. location и был изначально ссылкой на s. А нам надо, чтобы это была отдельная строка с собственным содержимым. Робин рисовал пальцем на стене на воображаемой доске воображаемое расположение разных строк в воображаемой оперативной памяти, отчего коллеги по комнате периодически на него оглядывались. Впрочем, с тех пор, как от Робина стали слышаться слова "Rust" и "переписать", коллеги просто молча понимающе переглядывались и уходили назад в свою работу. Робин тем временем дорисовал воображаемые строки и вернулся к реальной проблеме — как получить строку во владение?
"У меня нет нигде malloc(). Я вообще не видел, чтобы где-то выделял память! Что вообще происходит?" Уже привычным движением Робин переключился на браузер, где его ждала документация. Спустя минуту была найдена страница с интересным содержимым:

"Вроде как я могу использовать оба варианта. Типаж ToString реализует преобразование именно в строку, а ToOwned — для всех остальных типов из ссылки в отдельный экземпляр, которым можно завладеть. Робин поспешил применить свежее знание:
fn check(path: &'static str, s: &mut String) -> Result<Option<Mistake>, E> { s.clear(); File::open(path)?.read_to_string(s)?; Ok(match s.find(",") { Some(index) => { let location = s[index..].to_string(); Some(Mistake { path, location }) } None => None, }) }
```bash $ cargo run --quiet sample.txt: запятые нельзя: ", бойся Бармаглота, сын!" sample3.txt: запятые нельзя: ", и взял он щит"
На этом задача считалась законченой. Робин отправил новую Проверялку в прод, а старую, написанную на Си, спрятал поглубже в дебри компа, чтоб никто случайно не нашел.
Прошло пять лет
Пять долгих лет Rust-версия Проверялки трудилась на благо Овербука, не получив ни упрека в свой адрес. Для софта, тем более написанного за вечер на коленке, это значимое достижение. Тем не менее ни мир, ни Овербук не стояли на месте, и, как читатель уже мог догадаться, Робин снова был приглашен на совещание. На этот раз с амбициозной целью — создать на базе Проверялки Суперпроверялку!
Здравствуй Робин,
Проверялка работает безукоризненно. Однако сотрудники периодически жалуются, что она находит всего лишь одну ошибку, после чего надо отправлять текст автору, ждать исправления, и потом запускать Проверялку снова, чтобы она нашла новую ошибку, и так далее. В итоге мы поштормили немного и пришли к выводу, что было бы крайне желательно модифицировать Проверялку выдавать все ошибки сразу, а не по одной.
"Логично. Хорошо. Но это в самый последний раз я лезу в код."
Робин полез в подзабытый проект. Кажется, это уже происходило, кажется, даже совсем недавно...
"Мне определенно нужен массив..." Робин заимел привычку говорить вслух все, что касается работы. Во-первых, его сотрудники как-то отучились делать вид, будто их кто-то вообще слушает, взамен теперь произнося вслух любую мелочь, что взбредет в голову. Во вторых, дела у Овербука шли настолько хорошо, что всех расселили из опенспейса по отдельным кабинетам, и это до одури злило друзей Робина, которые все еще жили в опенспейсах в своих компаниях.
"Так. Ах да. Мне нужен массив."
struct Mistake { path: &'static str, locations: Vec<String>, }
Безусловно, Робин был в курсе связных списков (да все в курсе, этому всех учат!). Однако Овербук использовал железо с предсказателями ветвлений, бездонными кешами, короче, обычное современное железо, с которым данные, организованные в массив подряд идущих частей, создавали куда меньше проблем с производительностью, чем данные, рассыпанные по оперативке, за которыми надо постоянно прыгать туда-сюда. Но основной проблемой была не организация данных, а то, что старый добрый find() уже не подходил в принципе.
"Нет, я конечно могу бегать findом по строке, каждый раз подсовывая ему все меньший и меньший ее хвост. Но это как-то некузяво совсем. Неужели нет ничего удобней?"
Робин снова открыл доку к 'str и нашел следующее:
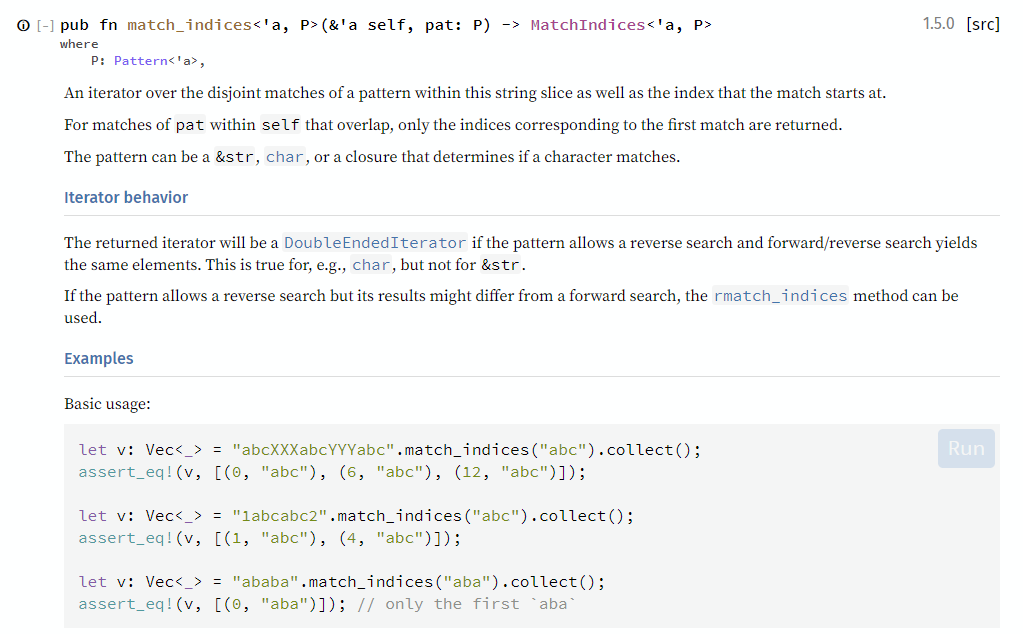
fn check(path: &'static str, s: &mut String) -> Result<Option<Mistake>, E> { s.clear(); File::open(path)?.read_to_string(s)?; let locations: Vec<_> = s .match_indices(",") .map(|(index, slice)| slice.to_string()) .collect(); Ok(if locations.is_empty() { None } else { Some(Mistake { path, locations }) }) }
"Ха, if это тоже выражение с возвратом результата!" Робин уже настолько к этому привык, что сначала писал код, а потом осмысливал написанное. Еще оказалось странным, но невероятно удобным отделить понимание хранения данных в массиве от перечисления этих данных, то есть разница между массивом и итератором. Отсюда вырос навык использования map() и collect().
Пришлось подпилить Display, и готово:
impl fmt::Display for Mistake { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { for location in &self.locations { write!(f, "{}: запятые нельзя: {:?}\n", self.path, location)?; } Ok(()) } }
Для проверки пришлось создать новый sample.txt с более сложным куском Бармаглота:
О, бойся Бармаглота, сын! Он так свирлеп и дик! А в глу́ше ры́мит исполин — Злопастный Брандашмыг! Но взял он меч, и взял он щит Высоких полон дум. В глущобу путь его лежит Под дерево Тумтум.
"Немного похоже на ситуацию, когда надо идти объяснять заказчику, почему упал прод", подумал Робин после прочтения стиха. Впрочем, мы отвлеклись.
$ cargo run --quiet sample4.txt: запятые нельзя: "," sample4.txt: запятые нельзя: "," sample4.txt: запятые нельзя: ","
Ну. Технически программа работает правильно. Корректно. Без ошибок. Только бесполезно. "Может подсунуть в location индексы найденных запятых, чтобы при выводе по ним искать в строке контекст?"
// check(): let locations: Vec<_> = s .match_indices(",") .map(|(index, _)| { use std::cmp::{max, min}; let start = max(0, index - 12); let end = min(index + 12, s.len()); s[start..end].to_string() }) .collect();
прим.автора: не пишите так адресацию в строках никогда. Ладно, если бы все происходило в восьмидесятые, когда стандартом был однобайтный ASCII, но в 21 веке с его UTF-кодировками у вас очень ненулевые шансы получить по пальцам линейкой.
(прим.пер: прочтите Спольски, там полезно.)
$ cargo run --quiet sample4.txt: запятые нельзя: "О, бойся Барма" sample4.txt: запятые нельзя: "я Бармаглота, сын!" sample4.txt: запятые нельзя: " взял он меч, и взял он щ"
"Уже существенно лучше, но чего-то не хватает." Робин нахмурился. "Было бы очень неплохо показывать, во-первых, номер строки с запятой, во вторых, подсвечивать само место ошибки. А еще не нравятся эти манипуляции со строкой в check(), им самое место в report(). Попадется какой-то автор — фанат запятых, и отчет по его тексту будет занимать больше места, чем сам текст."
"И да, я вот это сделаю, и все, и больше никаких правок, хватит."
План
Значит так.
Номер раз. check() у нас отвечает только за проверку, а report() — только за вывод ошибок.
Номер два. Ошибки — это позиции в оригинальном тексте, а не копии текста.
Номер раз оказался несложным:
struct Mistake { path: &'static str, text: String, locations: Vec<usize>, } fn check(path: &'static str) -> Result<Option<Mistake>, E> { let text = std::fs::read_to_string(path)?; let locations: Vec<_> = text.match_indices(",").map(|(index, _)| index).collect(); Ok(if locations.is_empty() { None } else { Some(Mistake { path, text, locations }) }) }
Робину было неспокойно хранить индексы вместо ссылок на символы в строке. Он на это согласился лишь потому, что соответствующая строка хранилась тут же рядом, а все это добро было запривачено внутри Mistake, чтобы никто нечаянно не влез (хотя кто влез бы?).
(вы же еще помните про Спольски и UTF-8? — прим.пер.)
Еще можно грохнуть глобальный буфер — все равно его копии хранились в Mistake.
$ cargo run --quiet warning: field is never used: `text` --> src\main.rs:28:5 | 28 | text: String, | ^^^^^^^^^^^^ | = note: #[warn(dead_code)] on by default sample4.txt: запятые нельзя: 1 sample4.txt: запятые нельзя: 19 sample4.txt: запятые нельзя: 83
Правильно, вывод-то еще не исправлен. Для начала надо найти индексы начала и конца соответствующей строки. Появляется соответствующий приватный метод:
impl Mistake { fn line_bounds(&self, index: usize) -> (usize, usize) { let len = self.text.len(); let before = &self.text[..index]; let start = before.rfind("\n").map(|x| x + 1).unwrap_or(0); let after = &self.text[index + 1..]; let end = after.find("\n").map(|x| x + index + 1).unwrap_or(len); (start, end) } }
"Я использую реверсивный поиск rfind(). Также, если строка первая или последняя в тексте, начальный и конечный перевод строки я могу и не найти, потому для таких ситуаций мне нужен unwrap_or()."
Новый метод казался сложным, и требовал немедленного испытания:
impl fmt::Display for Mistake { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { for &location in &self.locations { let (start, end) = self.line_bounds(location); let line = &self.text[start..end]; write!(f, "{}: запятые нельзя:\n", self.path)?; write!(f, "\n")?; write!(f, " | {}", line)?; write!(f, "\n\n")?; } Ok(()) } }
$ cargo run --quiet sample4.txt: запятые нельзя: | О, бойся Бармаглота, сын! sample4.txt: запятые нельзя: | О, бойся Бармаглота, сын! sample4.txt: запятые нельзя: | Но взял он меч, и взял он щит
Вопль победы вырвался из груди Робина. Почти оно!
Остались номера строк, и кое-что по мелочи:
impl fmt::Display for Mistake { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { for &location in &self.locations { let (start, end) = self.line_bounds(location); let line = &self.text[start..end]; let line_number = self.text[..start].matches("\n").count() + 1; write!(f, "{}: запятые нельзя:\n", self.path)?; write!(f, "\n")?; write!(f, "{:>8} | {}", line_number, line)?; write!(f, "\n\n")?; } Ok(()) } }
$ cargo run --quiet sample4.txt: запятые нельзя: 1 | О, бойся Бармаглота, сын! sample4.txt: запятые нельзя: 1 | О, бойся Бармаглота, сын! sample4.txt: запятые нельзя: 6 | Но взял он меч, и взял он щит
(вы же заметили, как наловчился Робин писать код на Rust без войны с компилятором?)
Последний рывок — показывать, где именно в выделенном тексте затесалась запятая. Робину очень понравилось, как на ошибки в коде указывает сам Rust, и он решил применить сюда тот же стиль с символом ^. Изменений на самом деле немного — подпилить Display, добавив строку с указателем, которая отсчитывалась от начала строки, которая, в свою очередь, отсчитывалась от начала текста. Ну еще 11 пробелов (для самого номера строки длиной в 8 цифр + разделитель |, еще 3 символа):
(как верно подметил в комментарии technic93, здесь у нас таки utf-8, и нужно считать символы, а не байты, потому ниже исправленный листинг, а не оригинал. Ссылка на Спольски вверх по тексту, да — прим.пер.)
impl fmt::Display for Mistake { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { for &location in &self.locations { let (start, end) = self.line_bounds(location); let line = &self.text[start..end]; let line_number = self.text[..start].matches("\n").count() + 1; let comma_index = self.text[start..location].chars().count(); write!(f, "{}: запятые нельзя:\n\n", self.path)?; // напечатать строку с номером write!(f, "{:>8} | {}\n", line_number, line)?; // показать запятую write!(f, "{}^\n\n", " ".repeat(11 + comma_index))?; } Ok(()) } }
$ cargo run --quiet sample4.txt: запятые нельзя: 1 | О, бойся Бармаглота, сын! ^ sample4.txt: запятые нельзя: 1 | О, бойся Бармаглота, сын! ^ sample4.txt: запятые нельзя: 6 | Но взял он меч, и взял он щит ^
Всё.
Робин осмотрел полный текст программы. 85 строк.
fn main() -> Result<(), std::io::Error> { let paths = ["sample4.txt"]; // все проверить let mut results = vec![]; for path in &paths { let result = check(path)?; results.push(result); } // все доложить пользователю for result in results { report(result); } Ok(()) } fn report(result: Option<Mistake>) { if let Some(mistake) = result { println!("{}", mistake); } } struct Mistake { path: &'static str, text: String, locations: Vec<usize>, } use std::io::Error as E; fn check(path: &'static str) -> Result<Option<Mistake>, E> { let text = std::fs::read_to_string(path)?; let locations: Vec<_> = text.match_indices(",").map(|(index, _)| index).collect(); Ok(if locations.is_empty() { None } else { Some(Mistake { path, text, locations, }) }) } use std::fmt; impl Mistake { fn line_bounds(&self, index: usize) -> (usize, usize) { let len = self.text.len(); let before = &self.text[..index]; let start = before.rfind("\n").map(|x| x + 1).unwrap_or(0); let after = &self.text[index + 1..]; let end = after.find("\n").map(|x| x + index + 1).unwrap_or(len); (start, end) } } impl fmt::Display for Mistake { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { for &location in &self.locations { let (start, end) = self.line_bounds(location); let line = &self.text[start..end]; let line_number = self.text[..start].matches("\n").count() + 1; let comma_index = self.text[start..location].chars().count(); write!(f, "{}: запятые нельзя:\n\n", self.path)?; // напечатать строку с номером write!(f, "{:>8} | {}\n", line_number, line)?; // показать запятую write!(f, "{}^\n\n", " ".repeat(11 + comma_index))?; } Ok(()) } }
Заключение
Несмотря на оглушительный успех новой Проверялки, Робин не получил за нее ни гроша.
Совершенно логичным его шагом было уйти прочь из Овербука и основать собственную компанию. Книги там не проверяли, зато использовали Rust. Робин впоследствии натыкался на фразу "в Rust ручное управление памятью", но, как ему уже было известно, это было очень далеко от правды. Ни единого байта ему не пришлось выделять вручную, вместо этого он просто декларировал экземпляры типов, которые ему были нужны, договаривался с БЧ о временах жизни этих экземпляров и следил, чтобы при этом его задачи были решены.
(А еще ему повезло, что не пришлось работать с FFI.)

