
Как проверить идеи, архитектуру и алгоритмы без написания кода? Как сформулировать и проверить их свойства? Что такое model-checkers и model-finders? Что делать, когда возможностей тестов недостаточно?
Привет. Меня зовут Васил Дядов, сейчас я работаю программистом в Яндекс.Почте, до этого работал в Intel, ещё раньше разрабатывал RTL-код (register transfer level) на Verilog/VHDL для ASIC/FPGA. Давно увлекаюсь темой надёжности софта и аппаратуры, математикой, инструментами и методами, применяемыми для разработки ПО и логики с гарантированными, заранее определёнными свойствами.
Это вторая статья из цикла (первая статья тут), призванного привлечь внимание разработчиков и менеджеров к инженерному подходу к разработке ПО. В последнее время он незаслуженно обойдён вниманием, несмотря на революционные изменения в подходе и инструментах поддержки.
Первая статья некоторым читателям показалась слишком абстрактной. Многие хотели бы увидеть пример использования инженерного подхода и формальных спецификаций в условиях, близких к реальности.
В этой статье мы рассмотрим пример реального применения TLA+ для решения практической задачи.
Я всегда открыт для обсуждения вопросов, связанных с разработкой ПО, и буду рад пообщаться с читателями (координаты для связи есть в моём профиле).
Что такое TLA+?
Для начала, хочу сказать пару слов про TLA+ и TLC.
TLA+ (Temporal Logic of Actions + Data) — это формализм, который основан на разновидности временно́й логики. Разработан Лесли Лэмпортом.
В рамках этого формализма можно описывать пространство вариантов поведения системы и свойства этих поведений.
Для простоты можно считать, что поведение системы представлено последовательностью её состояний (как бесконечные бусы, шарики на ниточке), а формула TLA+ задаёт класс таких цепочек, которые описывают все возможные варианты поведения системы (большое количество бус).
TLA+ хорошо подходит, чтобы описывать взаимодействующие недетерминированные конечные автоматы (например, взаимодействие сервисов в системе), хотя его выразительности хватает и для описания многих других вещей (которые можно выразить в логике первого порядка).
А TLC — это explicit-state model-checker: программа, которая по заданному TLA+ описанию системы и формулам свойств перебирает состояния системы и определяет, удовлетворяет ли система заданным свойствам.
Обычно работа с TLA+/TLC строится таким образом: описываем систему в TLA+, формализуем в TLA+ интересные свойства, запускаем TLC для проверки.
Так как в TLA+ непосредственно описывать более-менее сложную систему непросто, был придуман язык более высокого уровня — PlusCal, который транслируется в TLA+. PlusCal существует в двух ипостасях: с Pascal- и с C-подобным синтаксисом. В статье я использовал Pascal-подобный синтаксис, он, мне кажется, лучше читается. PlusCal по отношению к TLA+ — это примерно как C по отношению к ассемблеру.
Здесь мы не будем глубоко уходить в теорию. Литература для погружения в TLA+/PlusCal/TLC приведена в конце статьи.
Моя основная задача — это показать применение TLA+/TLC на простом и понятном примере из реальной жизни.
В некоторых комментариях к предыдущей статье меня упрекали, что я мало расписываю теоретические основы инструментов, но цель этого цикла статей — показать именно практическое применение инструментов для инженерного подхода в разработке ПО.
Думаю глубокое погружение в теорию мало кому интересно, а если вам интересно — всегда можете обратиться в личку за ссылками и разъяснениями, и я, насколько у меня хватит знаний (всё-таки я не математик-теоретик, а инженер-программист), постараюсь ответить.
Постановка задачи
Сначала немного расскажу о задаче, для которой применялся TLA+.
Задача связана с обработкой потока событий. А именно — создать очередь для хранения событий и рассылки уведомлений об этих событиях.
Хранилище данных физически организовано на базе СУБД PostgreSQL.
Главное, что нужно знать:
- Есть источники событий. Для наших целей можно ограничиться тем, что каждое событие характеризуется временем, в котором запланирована его обработка. Эти источники пишут события в БД. Обычно время записи в БД и время планируемой обработки никак не связаны.
- Есть процессы-координаторы, которые вычитывают события из БД и отправляют уведомления о ближайших событиях тем компонентам системы, которые должны реагировать на эти уведомления.
- Фундаментальное требование: мы не должны терять событий. Уведомление о событии в крайнем случае можно повторить, т. е. должна быть гарантия at least once. В распределённых системах гарантию only once реализовать крайне тяжело (может быть, даже невозможно, но это нужно доказывать) без механизмов консенсуса, а они (по крайней мере, все мне известные) весьма сильно влияют на систему с точки зрения задержки и пропускной способности.
Теперь немного деталей:
- Процессов-источников много, они могут генерировать миллионы (в худшем случае) событий, попадающих в узкий интервал времени.
- События могут генерироваться и для будущего, и для прошлого времени (например, если процесс-источник из-за чего-то протормозил и записал событие для момента, который уже прошёл).
- Приоритет обработки событий — по времени, т. е. сначала мы должны обработать наиболее ранние события.
- Для каждого события процесс-источник генерирует случайный номер worker_id, за счёт которого события распределяются по координаторам.
- Процессов-координаторов несколько (масштабируется под потребности исходя из загрузки системы).
- Каждый процесс-координатор обрабатывает события для своего множества worker_id, т. е. за счёт worker_id мы избегаем конкуренции между координаторами и необходимости блокировок.
Как видно из описания, мы можем рассматривать только один процесс-координатор и не учитывать worker_id в нашей задаче.
То есть для простоты будем считать, что:
- Процессов-источников много.
- Процесс-координатор один.
Эволюцию идеи решения данной задачи опишу по этапам, чтобы было понятнее, как мысль развивалась от простой реализации до оптимизированной.
Решение в лоб
Заведём для событий табличку, где будем хранить события в виде просто временно́й метки (timestamp) (остальные параметры нас в данной задаче не интересуют). Построим индекс по полю timestamp.
Кажется, вполне нормальное решение.
Только тут есть проблема с масштабируемостью: чем больше событий, тем медленнее операции с БД.
События могут приходить и для прошлого времени, так что координатору придётся постоянно просматривать всю временную шкалу.
Проблему можно решить экстенсивно, разбив БД на шарды по времени и т. д. Но это ресурсоёмкий способ.
В итоге замедлится работа координаторов, так как придётся вычитывать и объединять данные из нескольких баз.
Сложно реализовать кэширование событий в координаторе, чтобы не ходить в базы на обработку каждого события.
Больше баз — больше проблем с отказоустойчивостью.
И так далее.
Подробно на этом лобовом решении останавливаться не будем, так как оно тривиально и неинтересно.
Первая оптимизация
Посмотрим, как улучшить лобовое решение.
Чтобы оптимизировать доступ к БД, можно немного усложнить индекс, добавить к событиям монотонно возрастающий идентификатор, который будет генерироваться при коммите транзакции в БД. То есть событие теперь характеризуется парой {time, id}, где time — это время, в которое событие запланировано, id — монотонно возрастающий счётчик. Есть гарантия уникальности id для каждого события, но нет гарантии, что значения id идут без дырок (т. е. может быть такая последовательность: 1, 2, 7, 15).
Казалось бы, теперь мы можем хранить в процессе-координаторе идентификатор последнего прочитанного события и при выборке выбирать события с идентификаторами больше, чем у последнего обработанного события.
Но тут сразу всплывает проблема: процессы-источники могут записать событие с временно́й меткой далеко в будущем. Тогда нам придётся постоянно учитывать в процессе-координаторе множество событий с малыми идентификаторами, время обработки которых ещё не наступило.
Можно заметить, что события относительно текущего времени делятся на два класса:
- События с временно́й меткой в прошлом, но с большим идентификатором. Они были записаны в БД недавно, уже после того как мы обработали тот временно́й интервал. Это высокоприоритетные события, и их нужно обработать в первую очередь, чтобы уведомление — которое уже опоздало — не опоздало ещё больше.
- События, записанные когда-то давно, с временны́ми метками, близкими к текущему моменту. У таких событий будет низкое значение идентификатора.
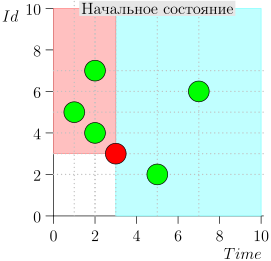
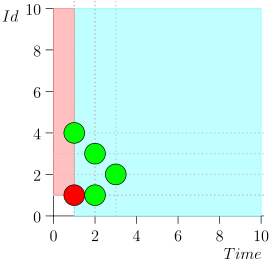
Соответственно, текущее состояние (state) процесса-координатора характеризует пара {state.time, state.id}.
Получается, что высокоприоритетные события находятся левее и выше этой точки (розовая область), а нормальные события — правее (светло-голубая):

Блок-схема
Алгоритм работы координатора такой:
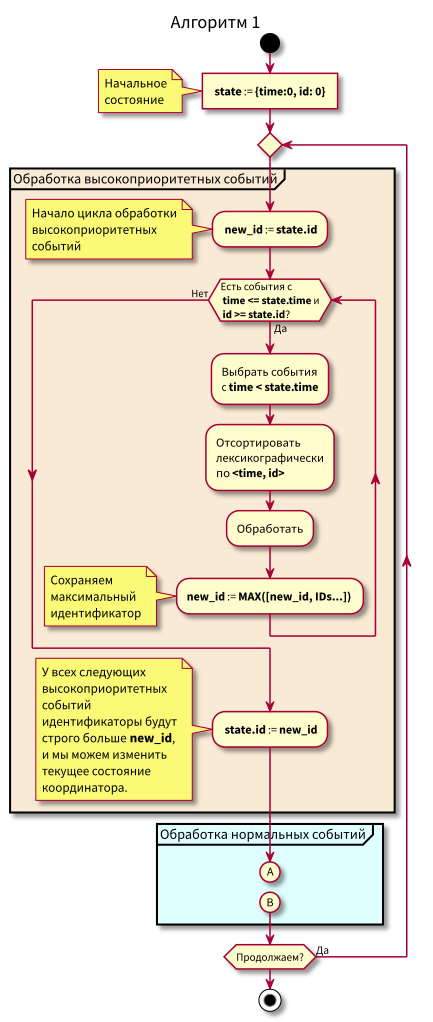

При изучении алгоритма могут возникнуть вопросы:
- Что, если начнётся обработка нормальных событий и в этот момент поступят новые события в прошлом (в розовую область), не потеряются ли они? Ответ: они будут обработаны при следующем цикле обработки высокоприоритетных событий. Потеряться они не могут, так как их id гарантированно будет выше state.id.
- Что, если после обработки всех нормальных событий — в момент перехода к обработке высокоприоритетных событий — поступят новые события с временны́ми метками из интервала [state.time, state.time + Delta], не потеряем ли мы их? Ответ: они попадут уже в розовую область, так как у них будет time < state.time и id > state.id: они поступили недавно, а id монотонно возрастающий.
Пример работы алгоритма
Посмотрим на несколько шагов алгоритма:
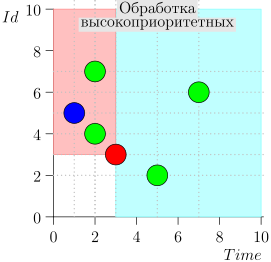

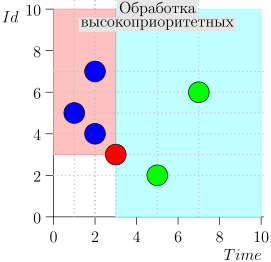
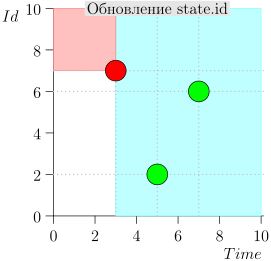
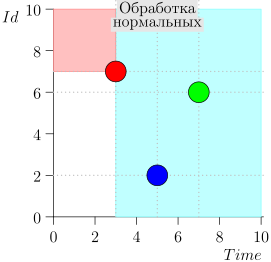
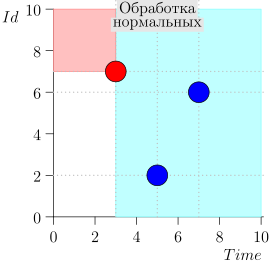

Модель
Убедимся, что алгоритм не пропустит событий и все уведомления будут отправлены: составим простую модель и проверим её.
Для модели используем TLA+, точнее PlusCal, который транслируется в TLA+.
---------------- MODULE events ---------------- EXTENDS Naturals, FiniteSets, Sequences, TLC (* --algorithm Events \* Основные параметры выбраны по принципу \* так называемой (by Daniel Jackson) \* small-scope hypothesis, которая говорит \* о том, что бо́льшая часть багов \* алгоритма проявляется в относительно \* небольших моделях \* Объявляем переменные: \* Events - имитация БД - множество, в котором \* будем хранить записи [time, id], \* при моделировании нужно будет \* явно задать ограничение на размер \* этого множества \* Event_Id - имтируем монотонный глобальный \* счётчик для id \* MAX_TIME - максимальное время, до которого \* ведём моделирование \* TIME_DELTA - множество значений Delta, \* для которых будем проверять \* модель variables Events = {}, Event_Id = 0, MAX_TIME = 5, TIME_DELTA \in 1..3 define \* вспомогательные определения \* начальное состояние ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x \* аналог fold_left/fold_right из функциональных ЯП RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) (* преобразование множества в последовательность (вводим произвольный порядок) *) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) (* обратно: последовательность в множество *) ToSet(S) == {S[i] : i \in DOMAIN(S)} (* аналог map в функциональных языках *) MapSet(Op(_), S) == {Op(x) : x \in S} (* вспомогательные функции *) \* получить множество id событий GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) \* получить множество time событий GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) (* Тут имитируем SQL выражения *) \* сначала определим отношение порядка \* для имитации ORDER BY EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \* лексикографически по time, id \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) \* SELECT * FROM events \* WHERE time <= curr_time AND id >= max_id \* ORDER BY time, id SELECT_HIGH_PRIO(state) == LET \* сначала выбираем множество по условиям \* time <= curr_time \* AND id >= maxt_id selected == {e \in Events : /\ e.time <= state.time /\ e.id >= state.id } IN selected \* SELECT * FROM events \* WHERE time > current_time AND time - Time <= delta_time \* ORDER BY time, id SELECT_NORMAL(state, delta_time) == LET selected == {e \in Events : /\ e.time <= state.time + delta_time /\ e.time > state.time } IN selected \* Safety predicate \* должен выполняться во всех состояниях модели ALL_EVENTS_PROCESSED(state) == \A e \in Events: \/ e.time >= state.time \/ e.id >= state.id end define; \* процессы - источники событий fair process inserter = "Sources" variable n, t; begin forever: while TRUE do \* выбираем произвольное время для события get_time: \* метки задают атомарные шаги \* всё, что находится под одной меткой, \* будет выполнено атомарно with evt_time \in 0..MAX_TIME do t := evt_time; end with; \* тут делаем запись в базу; \* возможны два варианта: \* 1. Транзакция завершилась нормально. \* 2. Транзакция откатилась, но так как \* Event_Id - атомарный глобальный счётчик, \* то он остался проинкрементированным commit: \* either - недетерминированно выбирает между ветками either Events := Events \cup {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process coordinator = "Coordinator" variable state = ZERO_EVT, events = {}; begin forever: while TRUE do \* сначала выбираем высокоприоритетные high_prio: events := SELECT_HIGH_PRIO(state); \* затем обрабатываем process_high_prio: \* так как цикл не имеет видимости за пределами этого кода, \* кроме как мутирования Events, \* то шаг можно сделать полностью атомарным state.id := MAX({state.id} \union GetIds(events)) || \* обработанные убираем в этом же шаге, \* чтобы трасса выполнения была читаемее Events := Events \ events || \* обнулять events нет необходимости, \* но так трасса выглядит понятнее events := {}; \* теперь - нормальные события normal: events := SELECT_NORMAL(state, TIME_DELTA); process_normal: state.time := MAX({state.time} \union GetTimes(events)) || Events := Events \ events || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* Тут TLA+, автоматически сгенерированный из вышеприведённого PlusCal описания \* END TRANSLATION ================================
Как видим, описание получается относительно небольшое, несмотря на довольно объёмную секцию определений (define), которую можно было бы вынести в отдельный модуль, чтобы потом переиспользовать.
В комментариях постарался объяснить, что происходит в модели. Надеюсь, что это
мне удалось и нет необходимости детальнее расписывать модель.
Хотел бы только пояснить один момент относительно атомарности переходов между состояниями и особенностей моделирования.
Моделирование идёт путём выполнения атомарных шагов процессов. За один переход выполняется один атомарный шаг какого-либо процесса, в котором этот шаг можно сделать. Выбор шага и процесса недетерминированный: при моделировании перебираются все возможные цепочки атомарных шагов всех процессов.
Тут может возникнуть вопрос: а что же по поводу моделирования истинной параллельности, когда у нас одновременно выполняется несколько атомарных шагов в разных процессах?
На этот вопрос Лесли Лэмпорт уже давно дал ответ в книге Specifying Systems и других работах.
Полностью цитировать ответ не буду, вкратце суть такова: если нет точной шкалы времени, где каждое событие привязано к конкретному моменту, то нет никакой разницы в моделировании параллельных событий как недетерминированно происходящих последовательных, ведь мы всегда можем считать, что одно событие произошло раньше другого на бесконечно малую величину.
А вот что действительно важно, так это грамотное выделение атомарных шагов. Если их слишком много — то случится комбинаторный взрыв пространства состояний. Если сделать шагов меньше, чем нужно, или неправильно их выделить — то есть вероятность пропуска невалидного состояния/перехода (т. е. мы пропустим ошибки на модели).
Чтобы правильно разбить процессы на атомарные шаги, нужно хорошо представлять работу системы в плане зависимости процессов по данным и по механизмам синхронизации.
Как правило, разбиение процессов на атомарные шаги больших проблем не вызывает. А если вызывает, то это скорее говорит о недостаточном понимании задачи, а не о проблемах с составлением модели и написанием TLA+ спецификации. Это ещё одно весьма полезное свойство формальных спецификаций: они требуют досконально изучить и проанализировать
проблему. Как правило, если задача осмыслена и хорошо понята, никаких проблем с её формализацией нет.
Проверка модели
Для моделирования буду использовать TLA-toolbox. Можно, конечно, и из командной строки всё запускать, но IDE всё-таки удобнее, особенно для начала изучения моделирования с использованием TLA+.
Создание проекта хорошо описано в руководствах, статьях и книгах, ссылки на которые я привёл в конце статьи, поэтому повторяться не буду. Единственное, на что обращу ваше внимание, — это настройки моделирования.
TLC — это model checker с явной проверкой состояний. Понятно, что пространство состояний нужно ограничить разумными пределами. С одной стороны, оно должно быть достаточно большим для возможности проверки интересных нам свойств, с другой — достаточно маленьким, чтобы моделирование выполнилось за приемлемое время с использованием приемлемых ресурсов.
Это довольно тонкий момент, тут нужно хорошо понимать свойства системы и модели. Но это быстро приходит с опытом. Для начала можно просто ставить максимально возможные ограничения, которые ещё приемлемы с точки зрения времени моделирования и потребляемых ресурсов.
Есть ещё режим проверки не всего пространства состояний, а выборочных цепочек на определённую глубину. Им тоже иногда можно и нужно пользоваться.
Возвращаемся к настройкам моделирования.
Для начала определим ограничения на пространство состояний системы. Ограничения задаются в разделе настроек моделирования Advanced Options/State Constraint.
Там я указал TLA+ выражение: Cardinality(Events) <= 5 /\ Event_Id <= 5,
где Event_Id — ограничение сверху на значение идентификатора событий, Cardinality(Events) — размер множества записей о событиях (ограничили модель базы
данных пятью записями в табличке).
При моделировании TLC будет просматривать только те состояния, в которых эта формула истинна.
Ещё можно допустимые переходы между состояниями (Advanced Options/Action Constraint),
но это нам не понадобится.
Далее укажем TLA+ формулу, которая описывает нашу систему: Model Overview/Temporal Formula = Spec, где Spec — это имя автосгенерированной по PlusCal описанию TLA+ формулы (в приведённом коде модели её нет: для экономии места я не стал приводить результат трансляции PlusCal в TLA+).
Следующая настройка, на которую стоит обратить внимание, — это проверка deadlock
(галочка в Model Overview/Deadlock). При включении этого флага TLC будет проверять модель на "висячие" состояния, т. е. те, из которых нет исходящих переходов. Если в пространстве состояний есть такие состояния, это означает явную ошибку в модели. Или в TLC, который, как и любая другая нетривиальная программа, не застрахован от ошибок :) В своей (не такой уж и большой) практике с дедлоками я ещё не сталкивался.
И наконец, то, ради чего вся эта проверка и затевалась, safety-формула в Model Overview/Invariants = ALL_EVENTS_PROCESSED(state).
TLC будет проверять истинность формулы в каждом состоянии, а если она станет ложной,
выдаст сообщение об ошибке и покажет последовательность состояний, которая привела к ошибке.
После запуска TLC, проработав около 8 минут, сообщил "No errors". Значит, модель проверена и соответствует заданным свойствам.
Ещё TLC выводит много интересной статистики. Например, для данной модели получилось 7 677 824 уникальных состояний, всего TLC просмотрел 27 109 029 состояний, диаметр пространства состояний — 47 (это максимальная длина цепочки состояний до повторения,
максимальная длина цикла из неповторяющихся состояний в графе состояний и переходов).
Если 27 млн состояний разделить на 8 минут, то получим примерно 56 тыс. состояний в секунду, что может показаться не особо быстрым. Но имейте в виду, что я запускал моделирование на ноутбуке, который работал в энергосберегающем режиме (я принудительно установил частоту ядер в 800 МГц, так как ехал в этот момент в электричке), и совсем не оптимизировал модель для скорости моделирования.
Есть много способов ускорить моделирование: от переноса части кода TLA+ модели в Java и подключения к TLC на лету (так полезно ускорять всякие вспомогательные функции) до запуска TLC в облаках и на кластерах (поддержка облаков Amazon и Azure встроена прямо в сам TLC).
Вторая оптимизация
В предыдущем алгоритме всё хорошо, за исключением нескольких проблем:
- Пока не обработаем все события из голубой зоны в интервале
[state.time, state.time + Delta], мы не можем перейти к высокоприоритетным событиям. То есть опаздывающие события опоздают ещё больше. И обычно задержка непредсказуема. Из-за этого state.time может сильно отстать от текущего времени, и это — причина следующей проблемы. - События, прилетающие в область нормальных событий, могут опаздывать (id > state.id). Они уже высокоприоритетные и должны считаться событиями из розовой области, а мы по-прежнему считаем их нормальными и обрабатываем как нормальные.
- Сложно организовать кэширование событий и дозаполнение кэша (дочитывание из БД).
Если первые два пункта очевидны, то третий, наверное, вызовет больше всего вопросов. Остановимся на нём подробнее.
Допустим, мы хотим сначала читать в память фиксированное количество событий, а затем их обрабатывать.
После обработки мы хотим блочными запросами помечать события в БД как обработанные, так как если работать не с блоками, а с одиночными событиями, то большого выигрыша от кэширования не будет.
Допустим, мы обработали часть блоков и хотим дополнить кэш. Тогда, если во время обработки прилетят опаздывающие высокоприоритетные события, мы сможем их обработать пораньше.
То есть очень желательно иметь возможность дочитывания событий небольшими блоками, чтобы как можно быстрее обработать опаздывающие, но обновлять признак обработанности в базе сразу большими блоками — для эффективности.
Что в этом случае делать?
Постараться работать с БД небольшими блоками с синей и розовой областью и двигать точку state небольшими шагами.
Таким образом был введён кэш и дочитывание в него из БД порций данных, после каждого дочитывания точка state смещалась, чтобы не перечитывать уже считанные события.
Теперь алгоритм стал чуть сложнее, мы стали читать ограниченными порциями.
Блок-схема


В данном алгоритме видно, что за счёт ограничения на блоки читаемых событий максимальная задержка перехода от обработки низкоприоритетных к обработке высокоприоритетных будет равна максимальной длительности обработки блока.
То есть теперь мы можем как дочитывать события в кэш небольшими блоками, так и управлять максимальной задержкой перехода к обработке высокоприоритетных событий через управление максимальным размером блока для считывания.
Пример работы алгоритма
Посмотрим на алгоритм в работе, по шагам. Для удобства возьмём LIMIT = 2.







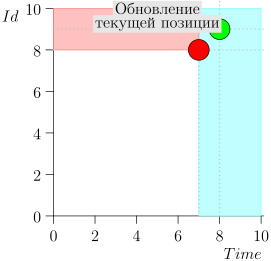
Получается задача решена? А вот и нет. (Понятно, что если бы задача была полностью решена на этом этапе, то
статьи бы этой не было :) )
Ошибка?
В таком виде алгоритм и работал довольно длительное время. Тесты все проходили нормально. В продакшне тоже проблем не замечалось.
Но разработчик алгоритма и его реализации (мой коллега Пётр Резников) очень опытен, и он интуитивно чувствовал, что здесь что-то не так. Поэтому рядом с основным кодом был сделан чекер, который по таймеру раз в какое-то время проверял, а нет ли пропущенных событий, и
если есть, то обрабатывал их.
В таком виде система успешно работала. Правда, статистику количества событий, подбираемых чекером, никто не вёл. Так что мы, к сожалению, не знаем, сколько было сбоев, связанных с несвоевременной обработкой событий.
Я реализовывал похожую очередь объектов, привязанных ко времени. Обсуждая реализацию и оптимизацию алгоритмов с Петром Резниковым, мы поговорили и об этом алгоритме работы с событиями. Засомневались, что алгоритм корректен. Решили сделать небольшую модель, чтобы либо подтвердить, либо развеять сомнения. В итоге мы обнаружили ошибку.
Модель
Прежде чем разбирать трассу с ошибкой, я приведу исходный код модели, на которой и была обнаружена ошибка.
От предыдущей модели отличия весьма небольшие, появилось только ограничение размера считываемых блоков: добавлен оператор Limit и, соответственно, изменены операторы выборки событий.
Для экономии места я оставил комментарии только к изменившимся частям модели.
---------------- MODULE events ---------------- EXTENDS Naturals, FiniteSets, Sequences, TLC (* --algorithm Events \* Добавили новую переменную LIMIT, \* значения которой из множества \* моделируемых лимитов на количество \* считываемых событий variables Events = {}, Event_Id = 0, MAX_TIME = 5, LIMIT \in 1..3, TIME_DELTA \in 1..2 define ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) ToSet(S) == {S[i] : i \in DOMAIN(S)} MapSet(Op(_), S) == {Op(x) : x \in S} GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) Limit(S, limit) == LET amount == MIN({limit, Len(S)}) result == IF amount > 0 THEN SubSeq(S, 1, amount) ELSE << >> IN result \* SELECT * FROM events \* WHERE time <= curr_time AND id > max_id \* ORDER BY id \* LIMIT limit SELECT_HIGH_PRIO(state, limit) == LET selected == {e \in Events : /\ e.time <= state.time /\ e.id >= state.id } \* сортируем по Id sorted == SortSeq(ToSeq(selected), EventsOrderById) \* выбираем до лимита limited == Limit(sorted, limit) IN ToSet(limited) \* SELECT * FROM events \* WHERE time > current_time \* AND time - Time <= delta_time \* ORDER BY time, id \* LIMIT limit SELECT_NORMAL(state, delta_time, limit) == LET selected == {e \in Events: /\ e.time <= state.time + delta_time /\ e.time > state.time } \* сортируем лексикографически sorted == SortSeq(ToSeq(selected), EventsOrder) \* ограничиваем выборку limited == Limit(sorted, limit) IN ToSet(limited) ALL_EVENTS_PROCESSED(state) == \A e \in Events: \/ e.time >= state.time \/ e.id >= state.id end define; fair process inserter = "Sources" variable t; begin forever: while TRUE do get_time: with evt_time \in 0..MAX_TIME do t := evt_time; end with; commit: either Events := Events \union {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process event_processor = "Event_processor" variable state = ZERO_EVT, events = {}; begin forever: while TRUE do select: events := LET evts_high_prio == SELECT_HIGH_PRIO(state, LIMIT) new_limit == LIMIT - Cardinality(evts_high_prio) evts_normal == SELECT_NORMAL(state, TIME_DELTA, new_limit) IN evts_high_prio \union evts_normal; proc_evts: Events := Events \ events || state := [ time |-> MAX({state.time} \union GetTimes(events)), id |-> MAX({state.id} \union GetIds(events))] || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* Тут TLA+, автоматически сгенерированный из вышеприведённого PlusCal описания \* END TRANSLATION ===================================================
Внимательный читатель может заметить, что, кроме введения Limit, ещё были изменены метки в event_processor. Цель — чуть лучше имитировать реальный код, который два select’а выполняют в одной транзакции, т. е. выборка событий, можно сказать, выполняется атомарно.
Ну и если мы находим ошибку в модели с более крупными атомарными операциями, это практически гарантирует, что эта же ошибка встретится в этой же модели, но с более мелкими атомарными шагами (довольно сильное утверждение, но, думаю, оно интуитивно понятно; хотя по-хорошему его следовало бы если не доказать, то проверить на широкой выборке моделей).
Проверка модели
Моделирование запускаем с теми же самыми параметрами, что и в первом варианте.
И получаем нарушение свойства ALL_EVENTS_PROCESSED на 19-м шаге моделирования при поиске в ширину.
При заданных начальных данных (это весьма малое пространство состояний) ошибка на 19-м шаге говорит о том, что ошибка весьма редкая и сложнообнаружимая, так как до этого были просмотрены все цепочки состояний длиной меньше 19.
Поэтому эту ошибку тяжело поймать на тестах. Только если знать, где искать, и специально подбирать тесты и времянку.
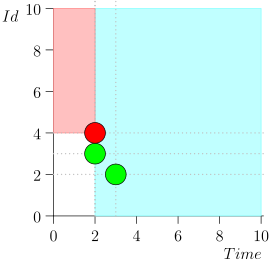
Всю трассу приводить не буду ради экономии места и времени. Вот отрезок из нескольких состояний вместе с ошибочным:



Анализ и исправление
Что же произошло?
Как видим, ошибка проявилась в том, что мы пропустили событие {2, 3} из-за того, что лимит кончился на событии {2, 1}, и после этого мы изменили состояние координатора. Это может случиться, только если в одном моменте времени находится несколько событий.
Именно поэтому ошибка была трудноуловима на тестах. Для её проявления нужно, чтобы совпали достаточно редкие вещи:
- Несколько событий попали в один и тот же момент времени.
- Лимит на выборку событий закончился до момента чтения всех этих событий.
Ошибку можно относительно несложно поправить, если немного расширить состояние координатора: добавить время и идентификатор последнего считанного события из области нормальных событий с максимальным id, если time этого события соответствует следующему значению state.time.
Если же такого события нет, то мы дополнительное состояние (extra_state) устанавливаем в невалидное состояние (UNDEF_EVT) и не учитываем при работе.
Те события из области нормальных, которые не были обработаны на предыдущем шаге координатора, мы будем считать уже высокоприоритетными и соответствующим образом поправим выборку высокоприоритетных и safety-предикат.
Можно было бы ввести ещё одну область, промежуточную между высокоприоритетными и нормальными, и изменить алгоритм. Вначале он будет обрабатывать высокоприоритетные, потом промежуточные, а затем переходить к нормальным с последующим изменением state.
Но такие изменения привели бы к большему объёму рефакторинга при неочевидных преимуществах (алгоритм будет чуть понятнее; других преимуществ с ходу не видно).
Поэтому решили только немного поправить текущее состояние и выборку событий из базы данных.
Скорректированная модель
Вот исправленная модель.
------------------- MODULE events ------------------- EXTENDS Naturals, FiniteSets, Sequences, TLC \* Для удобства вынес значения в настройки моделирования CONSTANTS MAX_TIME, LIMIT, TIME_DELTA (* --algorithm Events variables Events = {}, Limit \in LIMIT, Delta \in TIME_DELTA, Event_Id = 0 define \* добавлено неопределённое значение \* для события, используется в extra_state UNDEF_EVT == [time |-> MAX_TIME + 1, id |-> 0] ZERO_EVT == [time |-> 0, id |-> 0] MAX(S) == CHOOSE x \in S: \A y \in S: y <= x MIN(S) == CHOOSE x \in S: \A y \in S: y >= x RECURSIVE SetReduce(_, _, _) SetReduce(Op(_, _), S, value) == IF S = {} THEN value ELSE LET s == CHOOSE s \in S : TRUE IN SetReduce(Op, S \ {s}, Op(s, value)) ToSeq(S) == LET op(e, val) == Append(val, e) IN SetReduce(op, S, << >>) ToSet(S) == {S[i] : i \in DOMAIN(S)} MapSet(Op(_), S) == {Op(x) : x \in S} GetIds(Evts) == MapSet(LAMBDA x: x.id, Evts) GetTimes(Evts) == MapSet(LAMBDA x: x.time, Evts) EventsOrderByTime(e1, e2) == e1.time < e2.time EventsOrderById(e1, e2) == e1.id < e2.id EventsOrder(e1, e2) == \/ EventsOrderByTime(e1, e2) \/ /\ e1.time = e2.time /\ EventsOrderById(e1, e2) TakeN(S, limit) == LET amount == MIN({limit, Len(S)}) result == IF amount > 0 THEN SubSeq(S, 1, amount) ELSE << >> IN result (* SELECT * FROM events WHERE time <= curr_time AND id > max_id ORDER BY id Limit limit *) SELECT_HIGH_PRIO(state, limit, extra_state) == LET \* сначала выбираем множество по условиям \* time <= curr_time \* AND id > maxt_id selected == {e \in Events : \/ /\ e.time <= state.time /\ e.id >= state.id \/ /\ e.time = extra_state.time /\ e.id > extra_state.id} sorted == \* упорядочиваем SortSeq(ToSeq(selected), EventsOrderById) limited == TakeN(sorted, limit) IN ToSet(limited) SELECT_NORMAL(state, delta_time, limit) == LET selected == {e \in Events : /\ e.time <= state.time + delta_time /\ e.time > state.time } sorted == SortSeq(ToSeq(selected), EventsOrder) limited == TakeN(sorted, limit) IN ToSet(limited) \* Оператор для обновления extra_state UpdateExtraState(events, state, extra_state) == LET exact == {evt \in events : evt.time = state.time} IN IF exact # {} THEN CHOOSE evt \in exact : \A e \in exact: e.id <= evt.id ELSE UNDEF_EVT \* теперь нужно учесть extra_state ALL_EVENTS_PROCESSED(state, extra_state) == \A e \in Events: \/ e.time >= state.time \/ e.id > state.id \/ /\ e.time = extra_state.time /\ e.id > extra_state.id end define; fair process inserter = "Sources" variable t; begin forever: while TRUE do get_time: with evt_time \in 0..MAX_TIME do t := evt_time; end with; commit: either Events := Events \union {[time |-> t, id |-> Event_Id]} || Event_Id := Event_Id + 1; or Event_Id := Event_Id + 1; end either; end while; end process fair process event_processor = "Event_processor" variable events = {}, state = ZERO_EVT, extra_state = UNDEF_EVT; begin forever: while TRUE do select: events := LET evts_high_prio == SELECT_HIGH_PRIO(state, Limit, extra_state) new_limit == Limit - Cardinality(evts_high_prio) evts_normal == SELECT_NORMAL(state, Delta, new_limit) IN evts_high_prio \union evts_normal; proc_evts: Events := Events \ events || state := [ time |-> MAX({state.time} \union GetTimes(events)), id |-> MAX({state.id} \union GetIds(events)) ]; extra_state := UpdateExtraState(events, state, extra_state) || events := {}; end while; end process end algorithm; *) \* BEGIN TRANSLATION \* Тут TLA+, автоматически сгенерированный из вышеприведённого PlusCal описания \* END TRANSLATION ===================================================
Как можно увидеть, изменения совсем небольшие:
- Добавили дополнительные данные к состоянию extra_state.
- Изменили выборку высокоприоритетных событий.
- Добавили определение UpdateExtraState для изменения extra_state.
- Поправили safety-предикат для учёта изменений состояния.
Моделирование
Теперь моделирование прошло успешно, ошибок не нашли. Значит, эту конкретную проблему удалось исправить (что, конечно же, не говорит о том, что других проблем не осталось).
Но если возникнут подозрения на другие ошибки, то мы уже сможем их встретить достойно, с TLA+/TLC наперевес. :)
Заключение
С практической точки зрения вам, наверное, интересна трудоёмкость этого процесса (разработка модели, моделирование, поиск ошибки, исправление и повторное моделирование).
Учитывая то, что автор модели не был знаком с кодом координатора и нюансами алгоритма, а автор кода координатора впервые познакомился с TLA+/TLC, чистого времени ушло относительно немного. Думаю, суммарно около рабочего дня.
Если бы один человек с опытом работы с TLA+/TLC создавал алгоритм, код и модель, то на разработку модели и моделирование он бы потратил существенно (в разы, а то и на порядок) меньше времени.
В целом, как показывает практика и конкретный, рассмотренный в данной статье случай, знание TLA+/TLC разработчиками и даже его эпизодическое ретроспективное применение может приносить существенную пользу при относительно невысоких затратах времени.
Библиография
Книги
Для погружения в область
Тут собраны книги, которые отличаются практическим подходом, минимумом сложной математики, максимумом объяснений и примеров. Список упорядочен от простого к сложному.
Michael Jackson Problem Frames: Analysing & Structuring Software Development Problems
Хорошая книга об анализе проблем (не способов решения!), которые встают перед разработчиками ПО. Содержит множество примеров, как изучать проблемы. В первую очередь будет интересна тем, кто хочет грамотно анализировать задачи и составлять требования.
Hillel Wayne Practical TLA+: Planning Driven Development
Отличная книга об использовании TLA+/PlusCal для моделирования алгоритмов и др. Написана просто, со множеством понятных примеров. Специальной подготовки от читателя не требуется. Могу рекомендовать её всем программистам независимо от области работы: она будет полезна каждому.
Юрий Карпов MODEL CHECKING. Верификация параллельных и распределённых программных систем
Хорошая обзорная книга о моделировании. Доходчиво написана, рассмотрены все основные темы, много примеров. Серьёзной подготовки от читателя не требуется, знания матлогики и дискретки в объёме стандартной вузовской программы более чем достаточно.
Leslie Lamport Specifying Systems: The TLA+ Language and Tools for Hardware and Software Engineers
Основная книга о TLA+. Материал хорошо подан, хоть и суховато. Но это отличительный стиль Лесли Лэмпорта: предельно ясное и точное изложение, но немного сухое. Рекомендую всем, кто хочет детально понять TLA+ и идеи, лежащие в его основе.
Примеры из промышленности
Formal Development of a Network-Centric RTOS
Описывается опыт применения TLA+ для создания спецификаций при разработке сетецентричной ОС реального времени (RTOS) и опыт моделирования спецификаций с помощью TLC.
Книга интересна в первую очередь тем, что описывает разработку реального коммерческого продукта. А ещё тем, что использование TLA+ и моделирование позволило оптимизировать архитектуру настолько, что в результате объём кода уменьшился на порядок для той же самой функциональности, что и у RTOS предыдущей версии — Virtuoso. Разработчики даже не подозревали о таком эффекте, для них он стал весьма приятным сюрпризом.
То есть формальная спецификация помогает найти такие способы оптимизации архитектуры, которые позволяют сохранить функциональность ПО и радикально уменьшить объёмы кода (и, соответственно, объёмы ошибок, время отладки, стоимость поддержки и сопровождения).
Ноw Amazon Web Services Uses Formal Methods
Реальное применение TLA+ при разработке системных сервисов в AWS. Часть материалов можно найти на сайте Лесли Лэмпорта: http://lamport.azurewebsites.net/tla/amazon-excerpt.html
Интернет
Блоги
Hillel Wayne (автор книги "Practical TLA+") ссылка
Много интересного материала и примеров. Лёгкий стиль, простая подача. Очень рекомендую тем, кто только-только начинает изучать моделирование.
Ron Pressler ссылка
Очень интересные статьи. Автор объясняет серьёзные вещи весьма просто и понятно. Рекомендую тем, кто хочет поглубже понять теорию TLA+. Есть интересные статьи не только о TLA+, но и о computer science и математике в целом.
Leslie Lamport ссылка
Просто кладезь интересного материала о TLA+ и computer science. О TLA+ много всего тут.
Презентации и видеокурсы
Интересная презентация, где вкратце объясняется, что такое моделирование и зачем оно нужно.
Лесли Лэмпорт TLA+, видеокурс ссылка
Крайне рекомендую всем, кто начинает знакомиться с TLA+. Просто, понятно и доходчиво объясняются основные моменты TLA+.
Hillel Wayne
Могу рекомендовать эти видео выступлений Hillel Wayne на конференциях. Отличаются лёгкостью подачи материала и юмором.
- The Two Hardest Problems in CS (June 5, 2018)
- Everything about distributed systems is terrible | Code Mesh LDN 18
- Designing Distributed Systems with TLA+ | Øredev 2018
- Tackling Concurrency Bugs with TLA+
Ron Pressler
Меньше юмора, чем у Hillel Wayne, зато более глубоко рассматриваются темы. Рекомендую тем, кто хочет серьёзнее разобраться. Ron Pressler хорошо умеет объяснить фундаментальные математические понятия. Бо́льшая часть его материала о математике и теории, а не о практике, но очень интересно и полезно.
- The Practice and Theory of TLA+
- Why Writing Correct Software Is Hard and Why Math (Alone) Won’t Help Us
- On the Nature of Abstraction
- Finite of sense & infinite of thought | Code Mesh LDN 18
Моделирование
TLA toolbox + TLAPS: эти инструменты для работы со спецификациями на TLA+ я
использовал сам для изучения и решения задач в процессе разработки ПО. Они показались мне наиболее полезными на практике наряду с Alloy Analyzer.
