Представьте себе такую картину: близится конец цикла разработки, ваша игра едва ползает, но в профайлере вы не можете найти очевидных проблемных мест. Кто же виноват? Паттерны произвольного доступа к памяти и постоянные промахи кеша. Пытаясь повысить производительность, вы пробуете распараллелить части кода, но это стоит героических усилий, и в конечном итоге из-за всей синхронизации, которую пришлось добавить, ускорение едва заметно. К тому же код настолько сложен, что исправление багов вызывает ещё больше проблем, и мысль о добавлении новых возможностей сразу отбрасывается. Звучит знакомо?
Такое развитие событий довольно точно описывает почти каждую игру, в разработке которой я участвовал на протяжении последних десяти лет. Причины заключаются не в языках программирования и не в инструментах разработки, и даже не в отсутствии дисциплины. По моему опыту, в большой степени в этом стоит винить объектно-ориентированное программирование (ООП) и окружающую его культуру. ООП может не помогать, а мешать вашим проектам!
Всё дело в данных
ООП настолько проникло в существующую культуру разработки видеоигр, что когда думаешь об игре, трудно представить кроме объектов что-то ещё. Мы уже многие годы создаём классы, обозначающие машины, игроков и конечные автоматы. Какие же есть альтернативы? Процедурное программирование? Функциональные языки? Экзотические языки программирования?
Data-oriented design — это другой способ проектирования программ, предназначенный для решения всех этих проблем. Основным элементом процедурного программирования являются вызовы процедур, а ООП в основном имеет дело с объектами. Заметьте, что в обоих случаях в центр ставится код: в одном случае это обычные процедуры (или функции), в другом — сгруппированный код, связанный с неким внутренним состоянием. Data-oriented design смещает фокус внимания с объектов на сами данные: тип данных, их расположение в памяти, способы их считывания и обработки в игре.
Программирование по определению является способом преобразования данных: актом создания последовательности машинных команд, описывающих процесс обработки входящих данных и создания выходных данных. Игра — это не что иное, как интерактивная программа, поэтому не будет ли логичнее сконцентрироваться в основном на данных, а не на обрабатывающем их коде?
Чтобы не запутывать вас, сразу же поясню: data-oriented design не означает, что программа управляется данными. Управляемая данными (data-driven) игра — это обычно игра, функциональность которой в большой степени находится за пределами кода; она позволяет данным определять поведение игры. Эта концепция независима от data-oriented design и может использоваться в любом методе программирования.
Идеальные данные
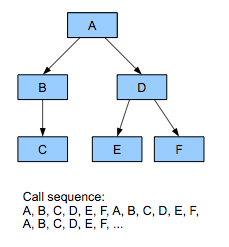
Рисунок 1a. Последовательность вызовов при объектно-ориентированном подходе
Если мы посмотрим на программу с точки зрения данных, то как будут выглядеть идеальные данные? Это зависит от самих данных и способов их использования. В общем случае, идеальные данные находятся в формате, который можно использовать с минимальным количеством усилий. В наилучшем случае формат будет полностью совпадать с ожидаемым результатом на выходе, то есть обработка заключается только в копировании данных. Очень часто схема идеальных данных выглядит как большие блоки смежных однородных данных, которые можно обрабатывать последовательно. Как бы то ни было, цель заключается в минимизации количества преобразований; по возможности нужно «запекать» данные в этот идеальный формат заранее, на этапе создания ресурсов игры.
Поскольку data-oriented design на первое место ставит данные, мы можем создавать архитектуру целой программы вокруг идеального формата данных. Нам не всегда будет удаваться делать его полностью идеальным (так же, как код редко бывает похож на ООП из учебника), но это наша основная цель, которую мы всегда помним. Когда мы этого достигаем, большинство упомянутых в начале статьи проблем просто растворяется (подробнее об этом следующем разделе).
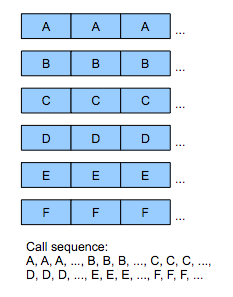
Когда мы думаем про объекты, то сразу вспоминаем деревья — деревья наследования, деревья вложенности или деревья передачи сообщений, и наши данные естественно упорядочиваются таким образом. Поэтому когда мы выполняем операцию над объектом, это обычно приводит к тому, что объект в свою очередь выполняет доступ к другим объектам вниз по дереву. При итерациях над множеством объектов выполнение одинаковой операции генерирует нисходящие, совершенно различные операции каждого объекта (см. Рисунок 1a).
Рисунок 1b. Последовательность вызовов в ориентированной на данные методике
Чтобы получить наилучшую схему хранения данных, бывает полезно разбить каждый объект на разные компоненты и сгруппировать в памяти компоненты одного типа, вне зависимости от объекта, из которого мы их взяли. Такое упорядочивание приводит к созданию больших блоков однородных данных, позволяющих нам обрабатывать данные последовательно (см. Рисунок 1b). Основная причина мощи концепции data-oriented design заключается в том, что она очень хорошо работает с большими группами объектов. ООП, по определению, работает с одним объектом. Вспомните последнюю игру, над которой вы работали: как часто в коде встречались места, где нужно было работать только с одним элементом? Одним врагом? Одним транспортным средством? Одним узлом поиска пути? Одной пулей? Одной частицей? Никогда! Там, где есть один, есть и ещё несколько. ООП игнорирует это и работает с каждым объектом по отдельности. Поэтому мы можем упростить работу себе и оборудованию, упорядочив данные так, чтобы нужно было обрабатывать множество элементов одного типа.
Вам такой подход кажется странным? Но знаете, что? Скорее всего, вы уже используете его в каких-то частях кода: а именно, в системе частиц! Data-oriented design превращает всю кодовую базу в огромную систему частиц. Возможно, чтобы этот метод казался более знакомым разработчикам игр, его нужно было бы назвать particle-driven programming.
Преимущества Data-Oriented Design
Если мы будем в первую очередь думать о данных и создавать архитектуру программы на основании этого, то это даст нам множество преимуществ.
Параллельность
В наши дни невозможно избавиться от того факта, что нам необходимо работать с несколькими ядрами. Те, кто пытался распараллелить ООП-код, могут подтвердить, насколько это сложная, подверженная ошибкам, и, возможно, не особо эффективная задача. Часто приходится добавлять множество примитивов синхронизации, чтобы избежать одновременного доступа к данным из нескольких потоков, и обычно многие потоки долгое время простаивают, ожидая завершения работы других потоков. В результате повышение производительности оказывается довольно посредственным.
Если мы применим data-oriented design, то параллелизация становится намного проще: у нас есть входящие данные, небольшая обрабатывающая их функция и выходные данные. Нечто подобное можно легко разделить на несколько потоков с минимальной синхронизацией между ними. Можно даже сделать ещё один шаг вперёд и выполнять этот код в процессорах с локальной памятью (например, в SPU процессоров Cell), не меняя никаких операций.
Использование кеша
Кроме использования многоядерности одним из ключевых способов достижения высокой производительности на современном оборудовании с глубокими конвейерами команд и медленными системами памяти с несколькими уровнями кеша — это реализация удобного для кеширования доступа к данным. Data-oriented design позволяет очень эффективно использовать кеш команд, потому что в нём постоянно выполняется один и тот же код. Кроме того, если мы расположим данные большими смежными блоками, то сможем обрабатывать данные последовательно, добившись почти идеального использования кеша данных и отличной производительности.
Возможность оптимизаций
Когда мы думаем об объектах или функциях, то обычно зацикливаемся на оптимизации на уровне функции или даже алгоритма: пытаемся изменить порядок вызова функций, меняем метод сортировки или даже переписываем часть кода на C на языке ассемблера.
Подобные оптимизации конечно полезны, но если сначала задуматься о данных, то мы можем отойти назад и создать более масштабные и важные оптимизации. Не забывайте, что игра занимается только преобразованием неких данных (ресурсов, ввода пользователя, состояния) в какие-то другие данные (графические команды, новые игровые состояния). Помня о таком потоке данных, мы можем принимать высокоуровневые, более осознанные решения на основании способов преобразования и применения данных. Подобные оптимизации в более традиционных ООП-методиках могут быть чрезвычайно сложными и затратными по времени.
Модульность
Все перечисленные выше преимущества data-oriented design были связаны с производительностью: использование кеша, оптимизации и параллелизация. Нет никаких сомнений, что для нас, программистов игр, производительность чрезвычайно важна. Часто возникает конфликт между техниками, повышающими производительность, и техниками, способствующими читаемости кода и простоте разработки. Например, если переписать часть кода на языке ассемблера, то мы повысим производительность, но это обычно приводит к снижению читаемости и усложнению поддержки кода.
К счастью, data-oriented design идёт на пользу и производительности, и простоте разработки. Если вы пишете код специально для преобразования данных, то у вас получаются маленькие функции с очень малым количеством зависимостей с другими частями кода. Кодовая база остаётся очень «плоской», со множеством функций-«листьев», не имеющих больших зависимостей. Такой уровень модульности и отсутствие зависимостей сильно упрощает понимание, замену и обновление кода.
Тестирование
Последнее важное преимущество data-oriented design — это простота тестирования. Многие знают, что написание юнит-тестов для проверки взаимодействия объектов — нетривиальная задача. Необходимо создавать макеты и тестировать элементы косвенно. Честно говоря, это довольно мучительно. С другой стороны, работая непосредственно с данными, писать юнит-тесты абсолютно легко: создаём некие входящие данные, вызываем преобразующую их функцию, и проверяем, соответствуют ли выходные данные ожидаемым. И на этом всё. На самом деле это огромное преимущество, сильно упрощающее тестирование кода, будь то test-driven development или написание юнит-тестов после кода.
Недостатки Data-Oriented Design
Data-oriented design — это не «серебряная пуля», решающая все проблемы в разработке игр. Оно действительно помогает в написании высокопроизводительного кода и создании более читаемых и удобных в поддержке программ, но само по себе имеет некоторые недостатки.
Основная проблема data-oriented design: оно отличается от того, что изучало и к чему привыкло большинство программистов. Оно требует поворота нашей ментальной модели программы на девяносто градусов и сдвига точки зрения на неё. Чтобы такой подход стал второй натурой, требуется практика.
Кроме того, из-за разности в подходах, оно может вызывать сложности во взаимодействии с уже имеющимся кодом, написанным в процедурном или ООП-стиле. Сложно писать одну функцию в отдельности, но как только вы сможете применить data-oriented design к целой подсистеме, то сможете получить множество преимуществ.
Применение Data-Oriented Design
Достаточно теории и обзоров. Как приступить к реализации метода data-oriented design? Для начала выберите конкретную область своего кода: навигацию, анимации, коллизии, или что-то другое. Позже, когда основная часть игрового движка будет сконцентрирована на данных, вы сможете заняться настройкой потока данных по всему пути, от начала кадра до конца.
Далее надо чётко идентифицировать требуемые системе входные данные и тип данных, которые она должна генерировать. Вы вполне можете пока думать в терминологии ООП, просто для того, чтобы идентифицировать данные. Например, для системы анимации частью входящих данных будут скелеты, базовые позы, данные анимаций и текущее состояние. Результатом будет не «код, воспроизводящий анимации», а данные, сгенерированные текущими воспроизводимыми анимациями. В данном случае выходными данными будут новое множество поз и обновлённое состояние.
Важно отступить на шаг назад и классифицировать входящие данные на основании того, как они используются. Они применяются только для чтения, для чтения и записи, или только для записи? Такая классификация поможет принимать решения о том, где хранить данные и когда их обрабатывать в связи с зависимостями от других частей программы.
На этом этапе нужно перестать думать о данных, необходимых для одной операции, и начинать думать о применении их к десяткам или сотням элементов. У нас больше нет одного скелета, одной базовой позы и текущего состояния: мы имеем блок каждого из этих типов со множеством экземпляров в каждом из блоков.
Очень тщательно продумайте, как будут использоваться данные в процессе трансформации от ввода до вывода. Возможно, вы поймёте, что для передачи данных нужно сканировать определённое поле в структуре, а затем понадобится использовать результаты для выполнения ещё одного прохода. В таком случае возможно будет логичнее разделить это исходное поле на отдельный блок памяти, который можно обрабатывать отдельно, что позволит оптимальнее использовать кеш и подготовит код к потенциальной параллелизации. Или, возможно, вам понадобится векторизировать часть кода, если для него получать данные из различных мест, чтобы поместить их в один векторный регистр. В таком случае данные будут храниться смежно, чтобы векторные операции можно было применять напрямую, без лишних преобразований.
Теперь у вас уже должно наработаться очень хорошее понимание своих данных. Написание кода для их преобразования станет намного проще. Оно будет походить на создание кода заполнением пробелов. Вас приятно удивит то, что код оказался намного проще и компактнее, чем вы думали изначально, по сравнению с аналогичным ООП-кодом.
Большинство постов в моём блоге готовило вас к такому типу проектирования. Теперь нам нужно быть внимательными с тем, как располагаются данные, запекать данные во входящий формат, чтобы их можно было использовать эффективно и использовать между блоками данных ссылки без указателей, чтобы их можно было легко перемещать.
Осталось ли место для использования ООП?
Значит ли это, что ООП бесполезно и его никогда не стоит применять при создании программ? Такого я сказать не могу. Думать в контексте объектов не вредно, если речь идёт только об одном экземпляре каждого объекта (например, о графическом устройстве, менеджере логов, и т.д.), хотя в этом случае код можно реализовать на основе более простых функций в стиле C и статичных данных файлового уровня. И даже в этой ситуации по-прежнему важно, чтобы объекты проектировались с упором на преобразование данных.
Ещё одна ситуация, в которой я по-прежнему пользуюсь ООП — это системы GUI. Возможно, так получилось потому, что здесь мы работаем с системой, уже спроектированной объектно-ориентированным образом, или, возможно, потому, что для кода GUI производительность и сложность не являются критичными факторами. Как бы то ни было, я больше предпочитаю GUI API, которые слабо используют наследование и максимально реализуют вложенность (хорошими примерами здесь являются Cocoa и CocoaTouch). Вполне вероятно, что для игр можно написать и приятные в работе системы GUI с ориентацией на данные, но пока я таких не встречал.
В конце концов, ничто не мешает вам всё равно создавать ментальную картину на основе объектов, если вы предпочитаете думать об игре таким образом. Просто сущность врага не будет занимать одно физическое место в памяти, а окажется разделённой на меньшие субкомпоненты, каждый из которых образует часть большой таблицы данных схожих компонентов.
Data-oriented design стоит немного вдалеке от традиционных методов программирования, но если вы всегда будете думать о данных и необходимых способах их преобразования, то это даст вам большие преимущества с точки зрения производительности и простоты разработки.

