Сегодня речь пойдёт о том, как устроен графический UI Фантома.
(Что такое ОС Фантом можно узнать, прочитав вот эти статьи.)
Точнее — как этот графический UI появился на свет. Ибо долгое время у Фантома был только графический вывод — донести системе что-либо с помощью мышки было почти невозможно.
Теперь же подошла пора сделать хоть несложные — но приложения, а значит — нужен UI. Да и вообще — система, будем откровенны, выглядела страшновато. А это нынче не в моде.
Что было в наличии на начало проекта UI? В принципе — немало.
Была, собственно, графика — видеодрайвер, оконная подсистема в режиме только отображения, bitmap шрифты, подсистема оконных событий (events), управление фокусом окон и сопутствующие примитивы.
Теперь по шагам и чуть подробнее.
Подсистема видеодрайверов умеет запустить по очереди функцию probe() нескольких драйверов, получить от них заявки на максимальное разрешение и битность цвета, плюс способность работать в режиме 2D акселератора. Система при этом требует минимум 24-битного цвета. На этом уровне мы имеем фреймбуфер (экран в памяти), мышь и примитивы bitblt нескольких типов.
Примитивы bitblt — были реализованы три базовых типа — полное копирование графики (с вырезанием прямоугольников), копирование с учётом бинарной прозрачности (пиксель или полностью прозрачный, или полностью непрозрачный) и z-buffer. То есть способность скопировать на экран только те пиксели, которые имеют z-координату больше, чем z-координата у имеющегося пикселя — для отработки частичного перекрытия окон.
Следующий слой функций — оконная подсистема. Тут есть понятие окна, декорации окна (рамка, title window с кнопками), x/y/z координаты окон и набор функций, которые отвечают за отрисовку окон на экран и управление их перемещением по всем осям.
Далее следуют события — очередь микрозадач, которые отрабатываются нижнеуровневым драйвером отрисовки и управления состоянием окон.
Тут надо отметить, что лучшие умы человечества утверждают — оконно-графическую систему, которая бы стабильно и без проблем работала в mutithreaded среде без очереди событий написать нельзя. Мои скромные попытки проигнорировать это утверждение пока что его только подтвердили. Обойтись без очереди сообщений и делать всё из нитей запрашивающих оконные события программ очень трудно и приводит иногда к войне на экране.
Поэтому большинство примитивов оконной системы, касающихся чего-либо большего, чем изображение внутри окна реализованы через очередь сообщений. Запрос посылает в очередь сообщение «отрисуй данную область на экране» или «переставь окно поверх других», а отдельная нить внизу выполняет их упорядоченно и вдумчиво.
Сюда же попадает просто поток событий от мышки (нажали, потащили), клавиатуры (нажали, отпустили) и самой оконной системы (вторичные события — после переноса окна вверх перерисовать область экрана).
Отдельная задача на уровне потока событий — так называемый фокус. Сфокусированное окно получает поток событий от клавиатуры, да и вообще явно выделено на экране как точка адресации активности пользователя. Кроме очевидной задачи выбора окна для направления события эта система также информирует окна о потере фокуса, что иногда важно.
Следующий уровень — графические примитивы для рисования на окне.
Здесь существуют два основных варианта реализации. Старый, экономный — когда окно не хранит копию того, что в него нарисовано. Если такое окно стёрли, и нужно нарисовать стёртое снова (например, окно вернули на экран из-за края), то окно зовёт функцию из своей программы, и эта функция должна нарисовать всё, что надо. Это типовая и ужасно неудобная по массе причин модель. В Фантоме выбрана вторая — у каждого окна есть битмеп, в котором нарисовано содержание окна на данный момент. Графическая система всегда может обратиться к этой копии и обновить её на экране, не дёргая программу пользователя.
Обратим внимание, что окно, принадлежащее пользовательской программе (а не ядру) в Фантоме, конечно, является персистентным, хранится в персистентной памяти и после перезагрузки ОС сохраняет всё в нём нарисованное. Это, кстати, на удивление полезно и упрощает прикладной код местами до неприличия.
Набор примитивов рисования позволяет прикладному коду, как водится, нарисовать в окне точку, линию, битмеп, строку текста битмеповым шрифтом и некоторые другие мелочи.
На этом богатство графической подсистемы на начало проекта «Новый UI Фантома» и заканчивалось. В принципе, этого джентльменского комплекта хватало на многое, но только в сторону пользователя. Без ввода.
Точнее сказать, была рудиментарная поддержка понятия «кнопка», но только мышкой, только в тулбаре и только чтобы закрыть окно. :)
Задача на развитие стояла так:
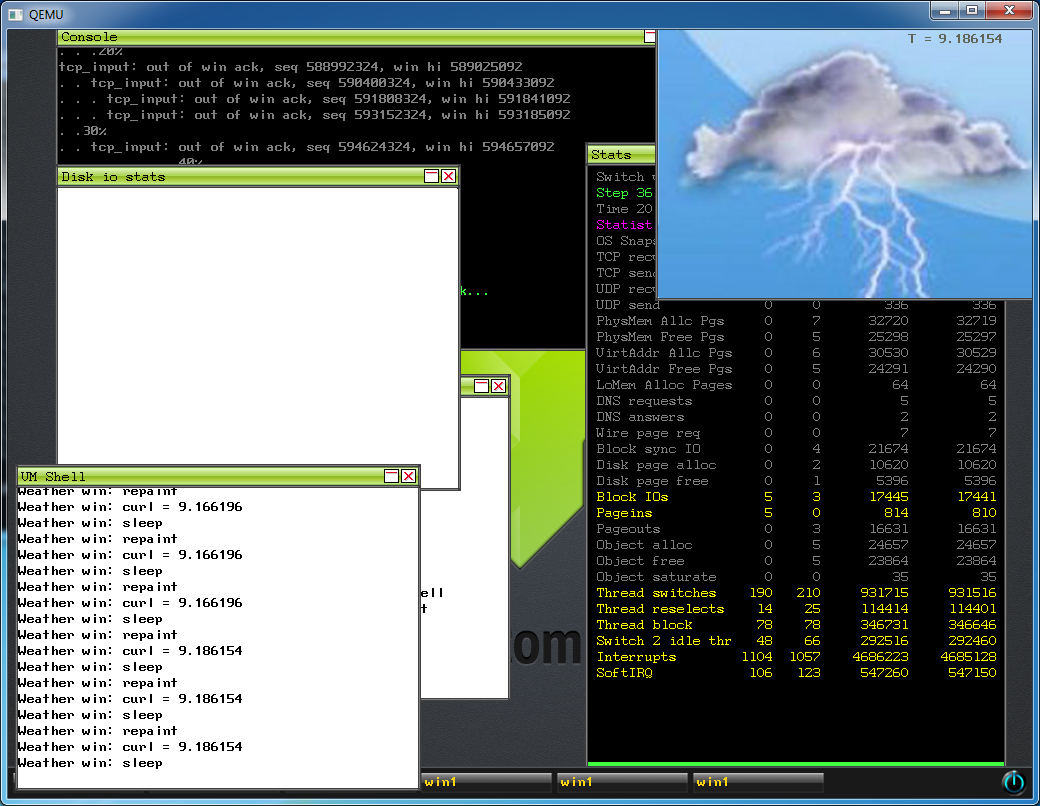
А было так:
По дороге выяснилось, что нужен ещё и альфа-блендинг, то есть частичная прозрачность пикселей при наложении картинок. Ну и стало понятно, что пора трогать за вымя Юникод.
Подход к этому весу делится на три больших части: Дизайн, Трутайп, остальное.
Про дизайн, коротко: в Интернете есть бесплатные дизайны UI без злых требований по использованию. Три дня на поиски и отбор, бесконечное время на художественное выпиливание графических элементов.
Этого я боялся, но, как выяснилось, зря. Есть libfreetype, есть примеры применения, через два дня рендеринг векторных шрифтов вполне работал в тестовом режиме.
Впрочем, тут есть тонкости, и не весь путь пройден. А именно. Работа со шрифтами из ядра — есть. Шрифты при этом загнаны хардкодом в бинарник ядра. Это неизбежно для системного шрифта, но пользовательский код должен иметь свои механизмы загрузки. И хотя какие-то ФС в Фантоме, конечно, есть и будут, эта модель для него неестественна. Нужно уметь хранить шрифты в персистентных объектах и добывать их по сети.
Второе проще — лежбища бесплатных шрифтов есть в изобилии, да и своё организовать недолго.
А вот первое…
Вы, наверное, не знаете, но строковые переменные в Фантоме обладают неожиданным для непривыкших к персистентности программистов свойствами. Ими можно заменять файлы. Поток байт есть поток байт. Мало того, он ещё и по определению memory mapped — это же переменная. То есть, в принципе, то, что мы в обычной ОС храним в файле, в Фантоме можно просто положить в строковую переменную. Я так часто и поступаю — а компилятор языка Фантом даже имеет конструкцию — всосать файл в строковую константу. Так в userland Фантома проникают, например, битмепы. Но это тоже стыдноватый способ, потому что потом в рантайме эту переменную нужно отпарсить, чтобы получить операбельное представление объекта. Впрочем, что касается битмепов, то, к чести Фантомовской концепции, тут всё хорошо. Мы всасываем при компиляции графический файл в строку, при первом запуске Фантома она конвертируется в персистентный же бинарный объект типа битмеп, и он уже используется дальше после любого количества перезагрузок ОС и оригинального источника не требует. Так же надо бы сделать и со шрифтами, но это чуть менее банально. При работе векторный шрифт рендерится в растр, и хранить надо бы именно такие вот отрендеренные растры. Это не фокус и не проблема — они опять же могут быть сложены в Фантомовские объекты типа bitmap, но тут уже нужна какая-никакая инфраструктура — дерево хранения вида шрифт — начертание — размер — глиф (код UTF) — битмап глифа.
Это не то, чтобы сложно, но, видимо, задача следующего этапа. Пока шрифты растеризуются по факту обращения.
Рендеринг шрифтов по определению предполагает работу с Юникодом. Это, конечно, хорошо, потому что надо же было когда-то начинать. По факту достаточно было снабдить рендерер конвертером из UTF-8 в UTF-32 (а это и есть номер глифа в шрифте), скачать шрифты с Кириллицей и эта часть локализации заработала. Более того, если мы хотим другие языки, то необходимо и достаточно заменить шрифт. Впрочем, выбранный базовый шрифт содержит немало — для европы точно хватит. Китаю потребуется замена шрифта, да.
Тут вообще ничего не предвещало военных действий, но, паче чаяния, воевать пришлось. Выяснилось, что старый драйвер клавиатуры всё ещё… надеется увидеть железо от IBM PC XT. Да, прошлого века. Дело в том, что контроллер клавиатуры штатно умеет (умел!) конвертировать скан коды современных клавиатур (так называемый второй набор кодов) в тот, древний.
Выяснилось это потому, что из поздних QEMU такую конвертацию, видимо, наконец выкинули. Или случайно сломали. Но факт в том, драйвер работать отказался. С горя я за час с помощью какой-то матери портанул в Фантом драйвер из дружественной uOS. Только чтобы узнать, что у него та же проблема. Первый набор. Пришлось переписать таблицу скан-кодов и парсер. К старому драйверу я возвращаться не стал, и вот почему. Оказалось, что драйвер от uOS имеет более изящный интерфейс в систему. А именно — он возвращает в неё не, как это было принято, пару (код символа, скан-код кнопки), а один 32-битный UTF-32 символ. Оказывается, в UTF есть специальный диапазон кодов, выделенных для локального употребления, и их более чем хватает на все возможные функциональные клавиши. Работать с таким потоком событий в коде UI гораздо проще.
Мало того, на такую модель отлично легла локализация. Достаточно наложить сверху таблицу ASCII->UTF32 для нужного языка (набора символов), и ура — у нас есть кириллица. Ну — почти есть. Теперь бы надо или перекодировать это в UTF-8, или переделать на UTF-32 потроха некоторых частей UI. Этот момент я тоже пока отложил в низкий приоритет.
Кнопки, радио, чекбоксы и прочие конкретные элементы UI.
Общая инфраструктура включает в себя:
Для того, чтобы контрол (кнопка, например) мог быть использован без мыши, нужны несколько вещей.
Последнее сложнее всего.
Фактически контрол фокусируется как клавиатурой, так и мышью, причём это одна и та же сущность — если мы выбрали текстовое поле мышкой, то оно будет реагировать и на клавиши. Если после этого нажать TAB, право работы с клавиатурой уйдёт другому.
Отдельная задача состоит в том, что некоторые контролы могут быть собраны в группы и их состояние требуется обновлять связанным образом. Нажатие радиобатторна «отжимает» его соседей по группе.
Ещё раз вернусь к тому, что мы пишем персистентную ОС. Это значит, что потенциально контрол может храниться в персистентной оперативной памяти и пережить перезагрузку ядра системы.
То есть его связи с ядром хорошо бы минимизировать. Каждый пойнтер в неперсистентную память (собственно в ядро) после перезагрузки будет невалиден и его придётся восстановить. Это значит, что такой пойнтер не имеет права хранить информацию о состоянии контрола. Позиция курсора в виде целого числа — да. Пойнтер в буфер в ядре, чьё положение определяется позицией курсора — нет. Ну или да, только целое число всё равно есть и оно главнее. Это на практике не очень обременяет, но помнить надо.
Наконец, таск бар. Это такая штуковина внизу (сбоку, сверху) экрана, куда пользователь тычет, если потерял окно.
В принципе, это бы уже должно быть частью user land, но… ядро уже активно пользуется GUI, так что пока эта часть тоже будет внизу. Надеюсь, временно.
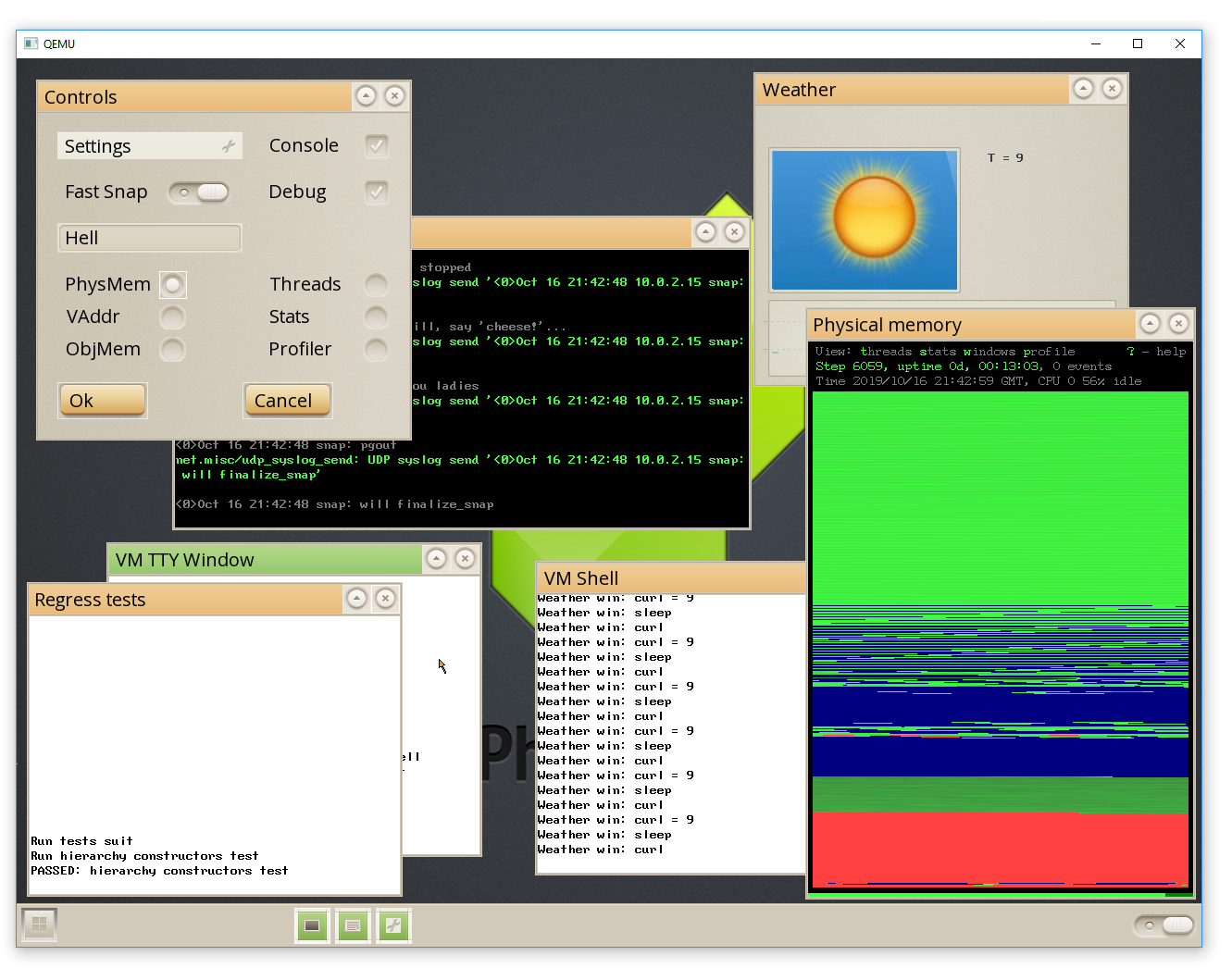
На мой взгляд, задачи, которые были поставлены по этому направлению в целом решены. Конечно, нет предела совершенству, но, как мне кажется, интерфейс сделал ощутимый шаг от хакерского к общечеловеческому.
(Что такое ОС Фантом можно узнать, прочитав вот эти статьи.)
Точнее — как этот графический UI появился на свет. Ибо долгое время у Фантома был только графический вывод — донести системе что-либо с помощью мышки было почти невозможно.
Теперь же подошла пора сделать хоть несложные — но приложения, а значит — нужен UI. Да и вообще — система, будем откровенны, выглядела страшновато. А это нынче не в моде.
Что было в наличии на начало проекта UI? В принципе — немало.
Была, собственно, графика — видеодрайвер, оконная подсистема в режиме только отображения, bitmap шрифты, подсистема оконных событий (events), управление фокусом окон и сопутствующие примитивы.
Теперь по шагам и чуть подробнее.
Подсистема видеодрайверов умеет запустить по очереди функцию probe() нескольких драйверов, получить от них заявки на максимальное разрешение и битность цвета, плюс способность работать в режиме 2D акселератора. Система при этом требует минимум 24-битного цвета. На этом уровне мы имеем фреймбуфер (экран в памяти), мышь и примитивы bitblt нескольких типов.
Примитивы bitblt — были реализованы три базовых типа — полное копирование графики (с вырезанием прямоугольников), копирование с учётом бинарной прозрачности (пиксель или полностью прозрачный, или полностью непрозрачный) и z-buffer. То есть способность скопировать на экран только те пиксели, которые имеют z-координату больше, чем z-координата у имеющегося пикселя — для отработки частичного перекрытия окон.
Следующий слой функций — оконная подсистема. Тут есть понятие окна, декорации окна (рамка, title window с кнопками), x/y/z координаты окон и набор функций, которые отвечают за отрисовку окон на экран и управление их перемещением по всем осям.
Документация
Далее следуют события — очередь микрозадач, которые отрабатываются нижнеуровневым драйвером отрисовки и управления состоянием окон.
Тут надо отметить, что лучшие умы человечества утверждают — оконно-графическую систему, которая бы стабильно и без проблем работала в mutithreaded среде без очереди событий написать нельзя. Мои скромные попытки проигнорировать это утверждение пока что его только подтвердили. Обойтись без очереди сообщений и делать всё из нитей запрашивающих оконные события программ очень трудно и приводит иногда к войне на экране.
Поэтому большинство примитивов оконной системы, касающихся чего-либо большего, чем изображение внутри окна реализованы через очередь сообщений. Запрос посылает в очередь сообщение «отрисуй данную область на экране» или «переставь окно поверх других», а отдельная нить внизу выполняет их упорядоченно и вдумчиво.
Сюда же попадает просто поток событий от мышки (нажали, потащили), клавиатуры (нажали, отпустили) и самой оконной системы (вторичные события — после переноса окна вверх перерисовать область экрана).
Отдельная задача на уровне потока событий — так называемый фокус. Сфокусированное окно получает поток событий от клавиатуры, да и вообще явно выделено на экране как точка адресации активности пользователя. Кроме очевидной задачи выбора окна для направления события эта система также информирует окна о потере фокуса, что иногда важно.
Документация
Следующий уровень — графические примитивы для рисования на окне.
Здесь существуют два основных варианта реализации. Старый, экономный — когда окно не хранит копию того, что в него нарисовано. Если такое окно стёрли, и нужно нарисовать стёртое снова (например, окно вернули на экран из-за края), то окно зовёт функцию из своей программы, и эта функция должна нарисовать всё, что надо. Это типовая и ужасно неудобная по массе причин модель. В Фантоме выбрана вторая — у каждого окна есть битмеп, в котором нарисовано содержание окна на данный момент. Графическая система всегда может обратиться к этой копии и обновить её на экране, не дёргая программу пользователя.
Обратим внимание, что окно, принадлежащее пользовательской программе (а не ядру) в Фантоме, конечно, является персистентным, хранится в персистентной памяти и после перезагрузки ОС сохраняет всё в нём нарисованное. Это, кстати, на удивление полезно и упрощает прикладной код местами до неприличия.
Набор примитивов рисования позволяет прикладному коду, как водится, нарисовать в окне точку, линию, битмеп, строку текста битмеповым шрифтом и некоторые другие мелочи.
На этом богатство графической подсистемы на начало проекта «Новый UI Фантома» и заканчивалось. В принципе, этого джентльменского комплекта хватало на многое, но только в сторону пользователя. Без ввода.
Точнее сказать, была рудиментарная поддержка понятия «кнопка», но только мышкой, только в тулбаре и только чтобы закрыть окно. :)
Задача на развитие стояла так:
- TrueType. Без этого уже стыдно.
- Клавиатурные события и управление с клавиатуры. Хотя бы базово.
- Подумать в сторону локализации раскладок — кириллицу как минимум, но заложить фундамент под смену раскладок.
- Контролы — кнопки, радиокнопки, поля текста, лейблы, меню и проч.
- Фокус контрола — выбор точки управления внутри окна.
- Какой-то экранный компонент для управления окнами на экране. Таск бар?
- Собственно изображения контролов и вообще какой-то дизайн UI — должно быть не так колхозно, как было.
А было так:
По дороге выяснилось, что нужен ещё и альфа-блендинг, то есть частичная прозрачность пикселей при наложении картинок. Ну и стало понятно, что пора трогать за вымя Юникод.
Подход к этому весу делится на три больших части: Дизайн, Трутайп, остальное.
Про дизайн, коротко: в Интернете есть бесплатные дизайны UI без злых требований по использованию. Три дня на поиски и отбор, бесконечное время на художественное выпиливание графических элементов.
Трутайп
Этого я боялся, но, как выяснилось, зря. Есть libfreetype, есть примеры применения, через два дня рендеринг векторных шрифтов вполне работал в тестовом режиме.
Впрочем, тут есть тонкости, и не весь путь пройден. А именно. Работа со шрифтами из ядра — есть. Шрифты при этом загнаны хардкодом в бинарник ядра. Это неизбежно для системного шрифта, но пользовательский код должен иметь свои механизмы загрузки. И хотя какие-то ФС в Фантоме, конечно, есть и будут, эта модель для него неестественна. Нужно уметь хранить шрифты в персистентных объектах и добывать их по сети.
Второе проще — лежбища бесплатных шрифтов есть в изобилии, да и своё организовать недолго.
А вот первое…
Вы, наверное, не знаете, но строковые переменные в Фантоме обладают неожиданным для непривыкших к персистентности программистов свойствами. Ими можно заменять файлы. Поток байт есть поток байт. Мало того, он ещё и по определению memory mapped — это же переменная. То есть, в принципе, то, что мы в обычной ОС храним в файле, в Фантоме можно просто положить в строковую переменную. Я так часто и поступаю — а компилятор языка Фантом даже имеет конструкцию — всосать файл в строковую константу. Так в userland Фантома проникают, например, битмепы. Но это тоже стыдноватый способ, потому что потом в рантайме эту переменную нужно отпарсить, чтобы получить операбельное представление объекта. Впрочем, что касается битмепов, то, к чести Фантомовской концепции, тут всё хорошо. Мы всасываем при компиляции графический файл в строку, при первом запуске Фантома она конвертируется в персистентный же бинарный объект типа битмеп, и он уже используется дальше после любого количества перезагрузок ОС и оригинального источника не требует. Так же надо бы сделать и со шрифтами, но это чуть менее банально. При работе векторный шрифт рендерится в растр, и хранить надо бы именно такие вот отрендеренные растры. Это не фокус и не проблема — они опять же могут быть сложены в Фантомовские объекты типа bitmap, но тут уже нужна какая-никакая инфраструктура — дерево хранения вида шрифт — начертание — размер — глиф (код UTF) — битмап глифа.
Это не то, чтобы сложно, но, видимо, задача следующего этапа. Пока шрифты растеризуются по факту обращения.
Документация
Юникод
Рендеринг шрифтов по определению предполагает работу с Юникодом. Это, конечно, хорошо, потому что надо же было когда-то начинать. По факту достаточно было снабдить рендерер конвертером из UTF-8 в UTF-32 (а это и есть номер глифа в шрифте), скачать шрифты с Кириллицей и эта часть локализации заработала. Более того, если мы хотим другие языки, то необходимо и достаточно заменить шрифт. Впрочем, выбранный базовый шрифт содержит немало — для европы точно хватит. Китаю потребуется замена шрифта, да.
Работа с клавиатурой
Тут вообще ничего не предвещало военных действий, но, паче чаяния, воевать пришлось. Выяснилось, что старый драйвер клавиатуры всё ещё… надеется увидеть железо от IBM PC XT. Да, прошлого века. Дело в том, что контроллер клавиатуры штатно умеет (умел!) конвертировать скан коды современных клавиатур (так называемый второй набор кодов) в тот, древний.
Выяснилось это потому, что из поздних QEMU такую конвертацию, видимо, наконец выкинули. Или случайно сломали. Но факт в том, драйвер работать отказался. С горя я за час с помощью какой-то матери портанул в Фантом драйвер из дружественной uOS. Только чтобы узнать, что у него та же проблема. Первый набор. Пришлось переписать таблицу скан-кодов и парсер. К старому драйверу я возвращаться не стал, и вот почему. Оказалось, что драйвер от uOS имеет более изящный интерфейс в систему. А именно — он возвращает в неё не, как это было принято, пару (код символа, скан-код кнопки), а один 32-битный UTF-32 символ. Оказывается, в UTF есть специальный диапазон кодов, выделенных для локального употребления, и их более чем хватает на все возможные функциональные клавиши. Работать с таким потоком событий в коде UI гораздо проще.
Мало того, на такую модель отлично легла локализация. Достаточно наложить сверху таблицу ASCII->UTF32 для нужного языка (набора символов), и ура — у нас есть кириллица. Ну — почти есть. Теперь бы надо или перекодировать это в UTF-8, или переделать на UTF-32 потроха некоторых частей UI. Этот момент я тоже пока отложил в низкий приоритет.
Контролы
Документация
Кнопки, радио, чекбоксы и прочие конкретные элементы UI.
Общая инфраструктура включает в себя:
- Механизм хранения контролов в привязке к окну
- Типовые элементы визуализации контрола — рамка, фон, текст, иконка и т.п.
- Передача контролу событий и типовые схемы реакции (push/toggle)
- Отслеживание событий мыши и hover state
- Коллбеки и генерация вторичных событий для информирования об изменении состояния
Фокус контрола
Для того, чтобы контрол (кнопка, например) мог быть использован без мыши, нужны несколько вещей.
- Возможность его выбрать с клавиатуры
- Отображение этого выбора
- Реакция на нужные клавиши
- Детектирование потери фокуса.
Последнее сложнее всего.
Фактически контрол фокусируется как клавиатурой, так и мышью, причём это одна и та же сущность — если мы выбрали текстовое поле мышкой, то оно будет реагировать и на клавиши. Если после этого нажать TAB, право работы с клавиатурой уйдёт другому.
Отдельная задача состоит в том, что некоторые контролы могут быть собраны в группы и их состояние требуется обновлять связанным образом. Нажатие радиобатторна «отжимает» его соседей по группе.
Ещё раз вернусь к тому, что мы пишем персистентную ОС. Это значит, что потенциально контрол может храниться в персистентной оперативной памяти и пережить перезагрузку ядра системы.
То есть его связи с ядром хорошо бы минимизировать. Каждый пойнтер в неперсистентную память (собственно в ядро) после перезагрузки будет невалиден и его придётся восстановить. Это значит, что такой пойнтер не имеет права хранить информацию о состоянии контрола. Позиция курсора в виде целого числа — да. Пойнтер в буфер в ядре, чьё положение определяется позицией курсора — нет. Ну или да, только целое число всё равно есть и оно главнее. Это на практике не очень обременяет, но помнить надо.
Наконец, таск бар. Это такая штуковина внизу (сбоку, сверху) экрана, куда пользователь тычет, если потерял окно.
В принципе, это бы уже должно быть частью user land, но… ядро уже активно пользуется GUI, так что пока эта часть тоже будет внизу. Надеюсь, временно.
Итого
На мой взгляд, задачи, которые были поставлены по этому направлению в целом решены. Конечно, нет предела совершенству, но, как мне кажется, интерфейс сделал ощутимый шаг от хакерского к общечеловеческому.

