
Всем привет! Меня зовут Влад и я работаю data scientist-ом в команде речевых технологий Тинькофф, которые используются в нашем голосовом помощнике Олеге.
В этой статье я бы хотел сделать небольшой обзор технологий синтеза речи, использующихся в индустрии, и поделиться опытом нашей команды построения собственного движка синтеза.

Синтез речи
Синтез речи — это создание звука на основе текста. Эту задачу сегодня решают двумя подходами:
- Unit selection [1], или конкатенативный подход. Он основан на склейке фрагментов записанного аудио. С конца 90-х долгое время он считался де-факто стандартом для разработки движков синтеза речи. Например, голос, звучащий по методу unit selection, можно было встретить в Siri [2].
- Параметрический синтез речи [3], суть которого состоит в построении вероятностной модели, предсказывающей акустические свойства аудиосигнала для данного текста.
Речь моделей unit selection имеет высокое качество, низкую вариативность и требует большого объема данных для обучения. В то же время для тренировки параметрических моделей необходимо гораздо меньшее количество данных, они генерируют более разнообразные интонации, но до недавнего времени страдали от общего достаточно низкого качества звука по сравнению с подходом unit selection.
Однако с развитием технологий глубокого обучения модели параметрического синтеза достигли существенного прироста по всем метрикам качества и способны создавать речь, практически неотличимую от человеческой.
Метрики качества
Прежде чем говорить о том, какие модели синтеза речи лучше, нужно определить метрики качества, по которым будет проводиться сравнение алгоритмов.
Поскольку один и тот же текст можно прочитать бесконечным количеством способов, априори правильного способа для произношения конкретной фразы не существует. Поэтому зачастую метрики качества синтеза речи субъективны и зависят от восприятия слушающего.
Стандартная метрика — это MOS (mean opinion score), усредненная оценка естественности речи, выданная асессорами для синтезированных аудио по шкале от 1 до 5. Единица означает совсем неправдоподобное звучание, а пятерка — речь, неотличимую от человеческой. Реальные записи людей обычно получают значения примерно 4,5, и значение больше 4 считается достаточно высоким.
Как работает синтез речи
Первый шаг к построению любой системы синтеза речи — сбор данных для обучения. Обычно это аудиозаписи высокого качества, на которых диктор читает специально подобранные фразы. Примерный размер датасета, необходимый для обучения моделей unit selection, составляет 10—20 часов чистой речи [2], в то время как для нейросетевых параметрических методов верхняя оценка равна примерно 25 часам [4, 5].
Обсудим обе технологии синтеза.
Unit selection
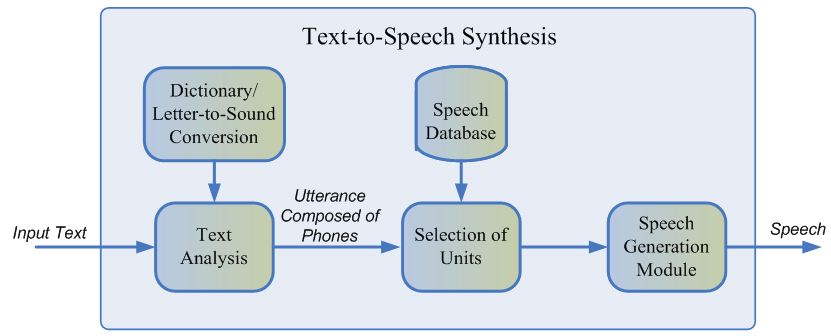
Обычно записанная речь диктора не может покрыть всех возможных случаев, в которых будет использоваться синтез. Поэтому суть метода состоит в разбиении всей аудиобазы на небольшие фрагменты, называющиеся юнитами, которые затем склеиваются друг с другом с использованием минимальной постобработки. В качестве юнитов обычно выступают минимальные акустические единицы языка, такие как полуфоны или дифоны [2].
Весь процесс генерации состоит из двух этапов: NLP frontend, отвечающий за извлечение лингвистического представления текста, и backend, который вычисляет функцию штрафа юнитов для заданных лингвистических признаков. В NLP frontend входят:
- Задача нормализации текста — перевод всех небуквенных символов (цифр, знаков процентов, валют и так далее) в их словесное представление. Например, “5 %” должно быть переведено в “пять процентов”.
- Извлечение лингвистических признаков из нормализованного текста: фонемное представление, ударения, части речи и так далее.
Обычно NLP frontend реализован с помощью вручную прописанных правил для конкретного языка, однако в последнее время происходит все больший уклон в сторону использования моделей машинного обучения [7].
Штраф, оцениваемый backend-подсистемой, — это сумма target cost, или соответствия акустического представления юнита для конкретной фонемы, и concatenation cost, то есть уместности соединения двух соседних юнитов. Для оценки штраф функций можно использовать правила или уже обученную акустическую модель параметрического синтеза [2]. Выбор наиболее оптимальной последовательности юнитов с точки зрения выше определенных штрафов происходит с помощью алгоритма Витерби [1].
Примерные значения MOS моделей unit selection для английского языка: 3,7—4,1 [2, 4, 5].
Достоинства подхода unit selection:
- Естественность звучания.
- Высокая скорость генерации.
- Небольшой размер моделей — это позволяет использовать синтез прямо на мобильном устройстве.
Недостатки:
- Синтезируемая речь монотонна, не содержит эмоций.
- Характерные артефакты склейки.
- Требует достаточно большой тренировочной базы аудиоданных для покрытия всевозможных контекстов.
- В принципе не может генерировать звук, не встречающийся в обучающей выборке.
Параметрический синтез речи
В основе параметрического подхода лежит идея о построении вероятностной модели, оценивающей распределение акустических признаков заданного текста.
Процесс генерации речи в параметрическом синтезе можно разделить на четыре этапа:
- NLP frontend — такая же стадия предобработки данных, как и в подходе unit selection, результат которой — большое количество контекстно-зависимых лингвистических признаков.
- Duration model, предсказывающая длительность фонем.
- Акустическая модель, восстанавливающая распределение акустических признаков по лингвистическим. В акустические признаки входят значения фундаментальной частоты, спектральное представление сигнала и так далее.
- Вокодер, переводящий акустические признаки в звуковую волну.
Для обучения duration и акустической моделей можно использовать скрытые марковские модели [3], глубокие нейронные сети или их рекуррентные разновидности [6]. Традиционный вокодер — это алгоритм, основанный на source-filter модели [3], которая предполагает, что речь — это результат применения линейного фильтра шума к первоначальному сигналу.
Общее качество речи классических параметрических методов оказывается достаточно низким из-за большого количества независимых предположений об устройстве процесса генерации звука.
Однако с приходом технологий глубокого обучения стало возможным обучать end-to-end модели, которые напрямую предсказывают акустические признаки по буквам. Например, нейронные сети Tacotron [4] и Tacotron 2 [5] принимают на вход последовательность букв и возвращают мел-спектрограмму с помощью алгоритма seq2seq [8]. Таким образом шаги 1—3 классического подхода заменяются одной нейросетью. На схеме ниже показана архитектура сети Tacotron 2, достигающей достаточно высокого качества звука.

Другим фактором существенного прироста в качестве синтезируемой речи стало применение нейросетевых вокодеров вместо алгоритмов цифровой обработки сигналов.
Первым таким вокодером была нейронная сеть WaveNet [9], которая последовательно, шаг за шагом, предсказывала значения амплитуды звуковой волны.
Благодаря использованию большого количества сверточных слоев с пропусками для захвата большего контекста и skip connection в архитектуре сети удалось достичь примерно 10%-го улучшения MOS по сравнению с моделями unit selection. На схеме ниже представлена архитектура сети WaveNet.

Главный недостаток WaveNet — низкая скорость работы, связанная с последовательной схемой сэмплирования сигнала. Эту проблему можно решить либо с помощью инженерной оптимизации для конкретной архитектуры железа, либо заменой схемы сэмплирования на более быструю.
Оба подхода были успешно реализованы в индустрии. Первый — в Tinkoff.ru, а в рамках второго подхода компания Google представила сеть Parallel WaveNet [10] в 2017 году, наработки которой используются в Google Assistant.
Примерные значения MOS для нейросетевых методов: 4,4—4,5 [5, 11], то есть синтезируемая речь практически не отличается от человеческой.
Достоинства параметрического синтеза:
- Естественное и плавное звучание при использовании end-to-end подхода.
- Большее разнообразие в интонациях.
- Использование меньшего объема данных по сравнению с моделями unit selection.
Недостатки:
- Низкая скорость работы по сравнению с unit selection.
- Большая вычислительная сложность.
Как работает синтез речи в Tinkoff
Как следует из обзора, методы параметрического синтеза речи, основанные на нейросетях, на текущий момент существенно превосходят по качеству подход unit selection и гораздо проще для разработки. Поэтому для построения собственного движка синтеза мы использовали именно их.
Для обучения моделей было использовано около 25 часов чистой речи профессионального диктора. Тексты для чтения были специально подобраны так, чтобы наиболее полно покрыть фонетику разговорной речи. Кроме того, чтобы добавить синтезу большее разнообразие в интонации, мы попросили диктора читать тексты с выражением, зависящим от контекста.
Архитектура нашего решения концептуально выглядит так:
- NLP frontend, в который входит нейросетевая текстовая нормализация и модель по расстановке пауз и ударений.
- Tacotron 2, принимающий на вход буквы.
- Авторегрессионный WaveNet, работающий в real time на CPU.
Благодаря такой архитектуре наш движок генерирует выразительную речь высокого качества в режиме реального времени, не требует построения фонемного словаря и дает возможность управлять ударениями в отдельных словах. Примеры синтезированных аудио можно прослушать, перейдя по ссылке.
Ссылки:
[1] A. J. Hunt, A. W. Black. Unit selection in a concatenative speech synthesis system using a large speech database, ICASSP, 1996.
[2] T. Capes, P. Coles, A. Conkie, L. Golipour, A. Hadjitarkhani, Q. Hu, N. Huddleston, M. Hunt, J. Li, M. Neeracher, K. Prahallad, T. Raitio, R. Rasipuram, G. Townsend, B. Williamson, D. Winarsky, Z. Wu, H. Zhang. Siri On-Device Deep Learning-Guided Unit Selection Text-to-Speech System, Interspeech, 2017.
[3] H. Zen, K. Tokuda, A. W. Black. Statistical parametric speech synthesis, Speech Communication, Vol. 51, no. 11, pp. 1039-1064, 2009.
[4] Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Yannis Agiomyrgiannakis, Rob Clark, Rif A. Saurous. Tacotron: Towards End-to-End Speech Synthesis.
[5] Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu. Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions.
[6] Heiga Zen, Andrew Senior, Mike Schuster. Statistical parametric speech synthesis using deep neural networks.
[7] Hao Zhang, Richard Sproat, Axel H. Ng, Felix Stahlberg, Xiaochang Peng, Kyle Gorman, Brian Roark. Neural Models of Text Normalization for Speech Applications.
[8] Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Sequence to Sequence Learning with Neural Networks.
[9] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu. WaveNet: A Generative Model for Raw Audio.
[10] Aaron van den Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu, George van den Driessche, Edward Lockhart, Luis C. Cobo, Florian Stimberg, Norman Casagrande, Dominik Grewe, Seb Noury, Sander Dieleman, Erich Elsen, Nal Kalchbrenner, Heiga Zen, Alex Graves, Helen King, Tom Walters, Dan Belov, Demis Hassabis. Parallel WaveNet: Fast High-Fidelity Speech Synthesis.
[11] Wei Ping Kainan Peng Jitong Chen. ClariNet: Parallel Wave Generation in End-to-End Text-to-Speech.
[12] Dario Rethage, Jordi Pons, Xavier Serra. A Wavenet for Speech Denoising.
