Для чего
При сложной структуре рекламных кампаний и большого количества звонков становятся необходимы дополнительные инструменты хранения, обработки и анализа информации о поступающих обращениях. Часто нужен быстрый доступ к данным за большой период времени. Иногда необходима сложная обработка данных, соотнесение звонков к определенному каналу или кампании.
Одним из вариантов ускорения работы, который также дает дополнительные преимущества является импорт звонков из CoMagic в Google BigQuery. О преимуществах BigQuery пишут много, так что перейдем непосредственно к созданию.
Для создания автоматического импорта понадобится:
- Google аккаунт (если его еще нет) с созданным проектом
- Знание Python
- Знакомство с документацией Google Cloud
Как создать проект описано тут. После того как проект создан необходимо создать набор данных в BigQuery. Документация BQ и инструкция по созданию набора данных.
Извлекаем данные из CoMagic
Обращаемся к документации CoMagic. Чтобы получить список обращений или звонков нам нужен раздел отчеты.
Создаем простой класс для работы с API CoMagic. Все необходимые requirements будут указаны в конце в ссылке на GitHub.
import json import requests import random import pandas as pd class ComagicClient: """Базовый класс для работы с CoMagic""" def __init__(self, login, password): """Конструктор принимает логин и пароль CoMagic""" self.login = login self.password = password self.base_url = 'https://dataapi.comagic.ru/v2.0' self.payload_ = {"jsonrpc":"2.0", "id":1, "method":None, "params": None} self.token = self.get_token(self.login, self.password) def base_request(self, method, params): """Основной метод для запросов в CoMagic. В качестве параметра принимает метод API и параметры запроса. Возвращает ответ в JSON-like формате. Подбробнее: https://www.comagic.ru/support/api/data-api/""" id_ = random.randrange(10**7) #случайный идентификатор payload = self.payload_.copy() payload["method"] = method payload["params"] = params payload["id"] = id_ self.r = requests.post(self.base_url, data=json.dumps(payload)) self.last_response = json.loads(self.r.text) return self.last_response def get_token(self, login, password): """Метод для получения токена. В качестве параметров принимает логин и пароль. Возвращает токен.""" method = "login.user" params = {"login":self.login, "password":self.password} response = self.base_request(method, params) token = response['result']['data']['access_token'] return token def get_report_per_page(self, method, params): """Реализация постраничного вывода. Отправляет запрос и получает по 10000 записей. Есть ограничение на вывод. Не может получить более 110000 записей. Возвращает ответ от в JSON-like формате.""" response = self.base_request(method, params) print(f"""Запрос звонков c {params["date_from"]} до {params["date_till"]}. Сдвиг = {params["offset"]}""") result = response['result']['data'] if len(result) < 10000: return result else: params['offset'] += 10000 add_result = self.get_report_per_page(method, params) return result + add_result def get_basic_report(self, method, fields, date_from, date_till, filter=None, offset=0): """Метод для получения отчетов. Вид отчета и поля определяются параметрами method и fields. Возвращает список словарей с записями по звонкам. В качестве параметров принимает время начала периода, время конца периода, параметры звонка и сдвиг для постраничного вывода. method -- <string> метод отчета date_from -- <string> дата старта. Формат "YYYY-MM-DD hh:mm:ss" date_till -- <string> дата окончания. Формат "YYYY-MM-DD hh:mm:ss" fields -- <list>, представление возвращаемых данных filter [ОПЦИОНАЛЬНО] - <dict> фильтр offset [ОПЦИОНАЛЬНО] -- <int> сдвиг return -- <list> отчет """ params = {"access_token":self.token, "limit":10000, "date_from":date_from, "date_till":date_till, "fields": fields, "offset": offset} if filter: params['filter'] = filter report = self.get_report_per_page(method, params) return report
Теперь нужно определить какие именно данные нужны. Данные нужно обработать и привести к виду, чтобы можно было загрузить в BigQuery.
Создадим вспомогательный класс и определим получаемые из CoMagic данные.
class ComagicHandler(ComagicClient): """Класса для работы с данными, получаемыми от CoMagic""" time_partition_field = 'PARTITION_DATE' def __init__(self, login, password, first_call_date): self.day_before_first_call = pd.to_datetime(first_call_date) - pd.Timedelta(days=1) super().__init__(login, password) def get_calls_report(self, date_from, date_till): """Получение отчета по звонкам с дополнтиельными параметрами за период. В качестве параметров принимает дату начала отчета и дату завершения отчета. Преобразовывает данные в Pandas DataFrame. Создает колонку для партицирования по дням. Название колонки получает из класса Connector или берет по умолчанию. Преобразовывает колонку с тегами. Оставляет только название тегов. Возвращает Pnadas.DataFrame""" method = "get.calls_report" fields = ['id', 'visitor_id', 'person_id', 'start_time', 'finish_reason', 'is_lost', 'tags', 'campaign_name','communication_number', 'contact_phone_number', 'talk_duration', 'clean_talk_duration', 'virtual_phone_number', 'ua_client_id', 'ym_client_id', 'entrance_page', 'gclid', 'yclid', 'visitor_type', 'visits_count', 'visitor_first_campaign_name', 'visitor_device', 'site_domain_name','utm_source', 'utm_medium', 'utm_campaign', 'utm_content', 'eq_utm_source', 'eq_utm_medium', 'eq_utm_campaign', 'attributes'] #Получение данных из CoMagic calls_data = self.get_basic_report(method, fields, date_from, date_till) #Создание DataFrame df = pd.DataFrame(calls_data) #Создание поля с датой звонка. Поле используется для партицирования. df[self.time_partition_field] = pd.to_datetime(df.start_time).apply(lambda x: x.date()) #Преобразование поле tags, так как BigQuery не может работать с таким типом данных, который #отдает CoMagic. Оставляем только название тэгов. df['tags'] = df.tags.apply(lambda x: x if x == None else [i['tag_name'] for i in x]) return df
Отправляем данные в BigQuery
После того, как данные из CoMagic получены и преобразованы, нужно их отправить в BigQuery.
from google.cloud import bigquery from google.cloud.exceptions import NotFound import pandas as pd class BQTableHanler: """Класс для работы с таблицей BigQuery""" time_partition_field = 'PARTITION_DATE' def __init__(self, full_table_id, service_account_file_key_path = None): """Конструтор принимает полное название таблицы в формате `myproject.mydataset.mytable`. Для аутентификации, если нет Application Default Credentials, в качестве дополнительного параметра может принимать путь к файлу сервисного аккаунта.""" self.full_table_id = full_table_id project_id, dataset_id, table_id = full_table_id.split(".") self.project_id = project_id self.dataset_id = dataset_id self.table_id = table_id if service_account_file_key_path: #если указан путь к сервисному аккаунту from google.oauth2 import service_account self.credentials = service_account.Credentials.from_service_account_file( service_account_file_key_path, scopes=["https://www.googleapis.com/auth/cloud-platform"],) self.bq_client = bigquery.Client(credentials = self.credentials, project = self.project_id) else: self.bq_client = bigquery.Client() self.dataset = self.bq_client.get_dataset(self.dataset_id) self.location = self.dataset.location self.table_ref = self.dataset.table(self.table_id) def get_last_update(self): """Получает дату последнего звонка из таблицы в формате Pandas datetime. Если таблицы не существует возвращает False.""" try: self.bq_client.get_table(self.full_table_id) except NotFound as error: return False query = f"""SELECT MAX({self.time_partition_field}) as last_call FROM `{self.full_table_id}`""" result = self.bq_client.query(query,location=self.location).to_dataframe() date = pd.to_datetime(result.iloc[0,0]).date() return date def insert_dataframe(self, dataframe): """Метод для передачи данных в таблицу BigQuery. В качестве параметров принимает Pandas DataFrame. Если таблицы не существет, то клиент создаст таблицу и добавит данные.""" job_config = bigquery.LoadJobConfig() #Определяем секционирование на уровне дней job_config._properties['load']['timePartitioning'] = {'type': 'DAY', 'field': self.time_partition_field} result = self.bq_client.load_table_from_dataframe(dataframe, self.table_ref, job_config=job_config).result() return result
Определяем логику обновления данных
Так как есть ограничение на количество получаемых строк данных от CoMagic необходимо ограничить количество запрашиваемых данных. Будем ограничивать период запроса. Для этого понадобится вспомогательная функция, которая будет дробить большой период времени на отрезки установленной длины.
def interval_split(array, interval): """Функция разбивает список на интервалы заданной длины. Возвращает список списков, при чем длина подсписка равна 2, где первое значение - первый элемент интервала, а второй элемент подсписка - это последний элемент интервала. Пример: get_intervals([1,2,3,4,5,6,7], 3) => [[1,3], [4,6], [7]] get_intervals([1,2,3], 4) => [[1,3]]""" intervals = [] iw, i = 0, 0 l = len(array) for v in array: if i==0 or (i)%interval==0: intervals.append([v]) if (i+1)%interval == 0 or (i+1) == l: intervals[iw].append(v) iw+=1 i+=1 return intervals
Это необходимо при первой загрузке данных, когда нужно загрузить данные за большой период времени. Период дробится на несколько мелких периодов. Делать это, кстати, лучше не используя Cloud Function, так как у них есть ограничение на время исполнения. Ну, или, как вариант, можно много-много раз запускать функцию.
Создаем класс коннектор, для связи таблицы BigQuery, куда мы хотим складывать данные, и данных из CoMagic.
from helpfunctions import interval_split import pandas as pd class Connector: """Соединяет источник данных и место назначения данных""" time_partition_field = 'PARTITION_DATE' #название поля по-умолчанию. Переопределяет название поля в других классах def __init__ (self, source, dest): """Конструктор принимает на вход класс источник и класс пункта назначения данных""" self.source = source self.dest = dest self.source.time_partition_field = self.time_partition_field self.dest.time_partition_field = self.time_partition_field def insert_data_in_dest(self, start_date, end_date): """Добавляет данные из источника в место назначения. В качестве параметров принимает дату старта и дату окончания отчеа, которые нужно взять из источника.""" dates = pd.date_range(start_date, end_date) week_intervals = interval_split(dates, 7) #разбиваем данные на периоды по 7 дней for week_interval in week_intervals: date_from = week_interval[0].strftime("%Y-%m-%d") + " 00:00:00" date_till = week_interval[1].strftime("%Y-%m-%d") + " 23:59:59" calls_df = self.source.get_calls_report(date_from, date_till) self.dest.insert_dataframe(calls_df) print (f"Данные с {date_from} по {date_till} добавлены в таблицу") return True def update_dest_data(self): #Получение последней даты звонка из BigQuery last_date = self.dest.get_last_update() if not last_date: #Если таблицы не существует last_date = self.source.day_before_first_call yesterday = pd.Timestamp.today(tz='Europe/Moscow').date() - pd.Timedelta(days=1) if last_date == yesterday: print("Данные уже обновлены") else: last_date = last_date + pd.Timedelta(days=1) self.insert_data_in_dest(last_date, yesterday) return True
Далее прописываем главную функцию для обновления данных, которая будет запускаться по расписанию.
from connector import Connector from bqhandler import BQTableHanler from comagichandler import ComagicHandler from credfile import * def main(event, context): """Функция принимает на вход event, context Подбробнее тут: https://cloud.google.com/functions/docs/writing/background#functions-writing-background-hello-pubsub-python""" #import base64 #pubsub_message = base64.b64decode(event['data']).decode('utf-8') #создает иcточник данных и место назначения данных comagic_handler = ComagicHandler(COMAGIC_LOGIN, COMAGIC_PASSWORD, FIRST_CALL_DATE) bq_handelr = BQTableHanler(full_table_id, google_credintials_key_path) #созздаем коннектор connector = Connector(comagic_handler, bq_handelr) #обновляем данные в месте назначения connector.update_dest_data()
Настраиваем Google Cloud Platform
Собираем все файлы в ZIP-архив. В файл credfile.py прописываем логин и пароль от CoMagic для получения токена, а также полное название таблицы в BigQuery и путь до файла сервисного аккаунта, если скрипт запускается с локальной машины.
Создаем Cloud Function
- Переходим в консоль
- Если еще не создана ни одна функция кликаем “Создать функцию”
- В поле триггера выбираем PUB/SUB
- Создаем новую тему для PUB/SUB. Например ‘update_calls’
- Источник: ZIP upload (локальный ZIP-файл)
- Среда: Python 3.7
- Загружаем ZIP-файл
- Выбираем временный сегмент Cloud Storage
- В поле `вызываемая функция` прописываем ‘main’
- Выделенный объем памяти: по усмотрению

Настраиваем Scheduler и PUB/SUB
На прошлом шаге мы создали триггер `update_calls`. Эта тема автоматические появилась в списке тем.

Теперь, с помощью Cloud Sсheduler нужно настроить триггер. когда он будет срабатывать и будет запускаться GCF.
- Переходим в консоль
- В поле периодичность в формате CRON устанавливаем когда должен срабатывать триггер и запускаться функция.
- Место назначения: Pub/Sub
- Тема: прописываем ту тему, которую указывали при создании функции: “update_calls”
- Полезная нагрузка* (Payloads) — это информация, которая будет передана в Pub/Sub и в функцию main
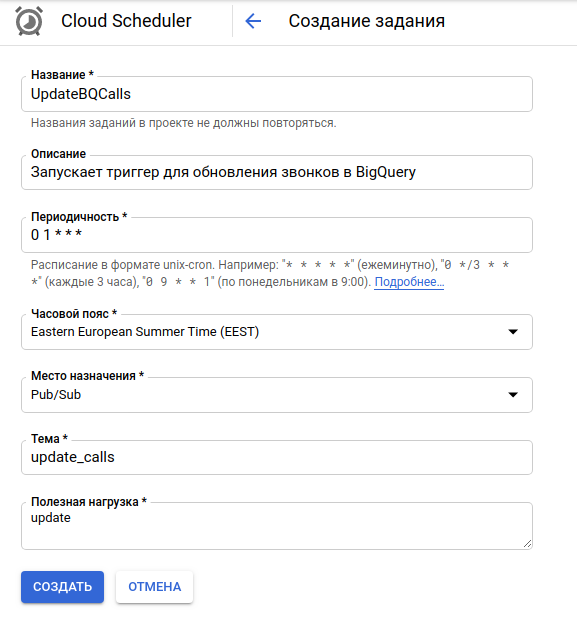
Теперь скрипт будет запускаться ежедневно в 01:00 и данные о звонках будут обновлены на конец предыдущего дня.
Ссылка на GitHub для запуска с локального компьютера
Ссылка на GitHub на ZIP-файл

