Эта статья — перевод статьи Томаса Нильда How It Feels to Learn Data Science in 2019
Видение (случайного) леса через деревья (решений)
Время чтения: 16 минут
Вдохновением к нижеизложенному послужила статья о том, каково это — изучать JavaScript в 2016 году. Не воспринимайте эту статью слишком серьезно. Это сатира, поэтому не относитесь к ней как к жизненному совету. Как и все советы, некоторые из них полезны, а некоторые — бестолковы. Этот текст — просто мнение, очень похожее на определение data science.
Я слышал, что за советом — к тебе. Спасибо за встречу со мной, и спасибо за кофе. Ты знаешь data science, верно?
Ну, да, знаю. В прошлом году я ездил на PyData и O’Reilly Strata (конференции по анализу данных — прим. пер.) и на моём счету есть парочка моделей.
Да, я слышал, на прошлой неделе ты провел отличную презентацию по машинному обучению для нашей компании. Мой коллега сказал, что было очень полезно.
О, классификатор фотографий кошек и собак? Да, спасибо.
Короче говоря, я решил, что больше не могу игнорировать data science, искусственный интеллект и машинное обучение. Я работал аналитиком и консультантом в течение многих лет, переставляя числа в Excel, составляя сводные таблицы и диаграммы. Но мне все время попадаются статьи, в которых говорится, что ИИ заберет рабочие места, даже у таких «белых воротничков», как я.
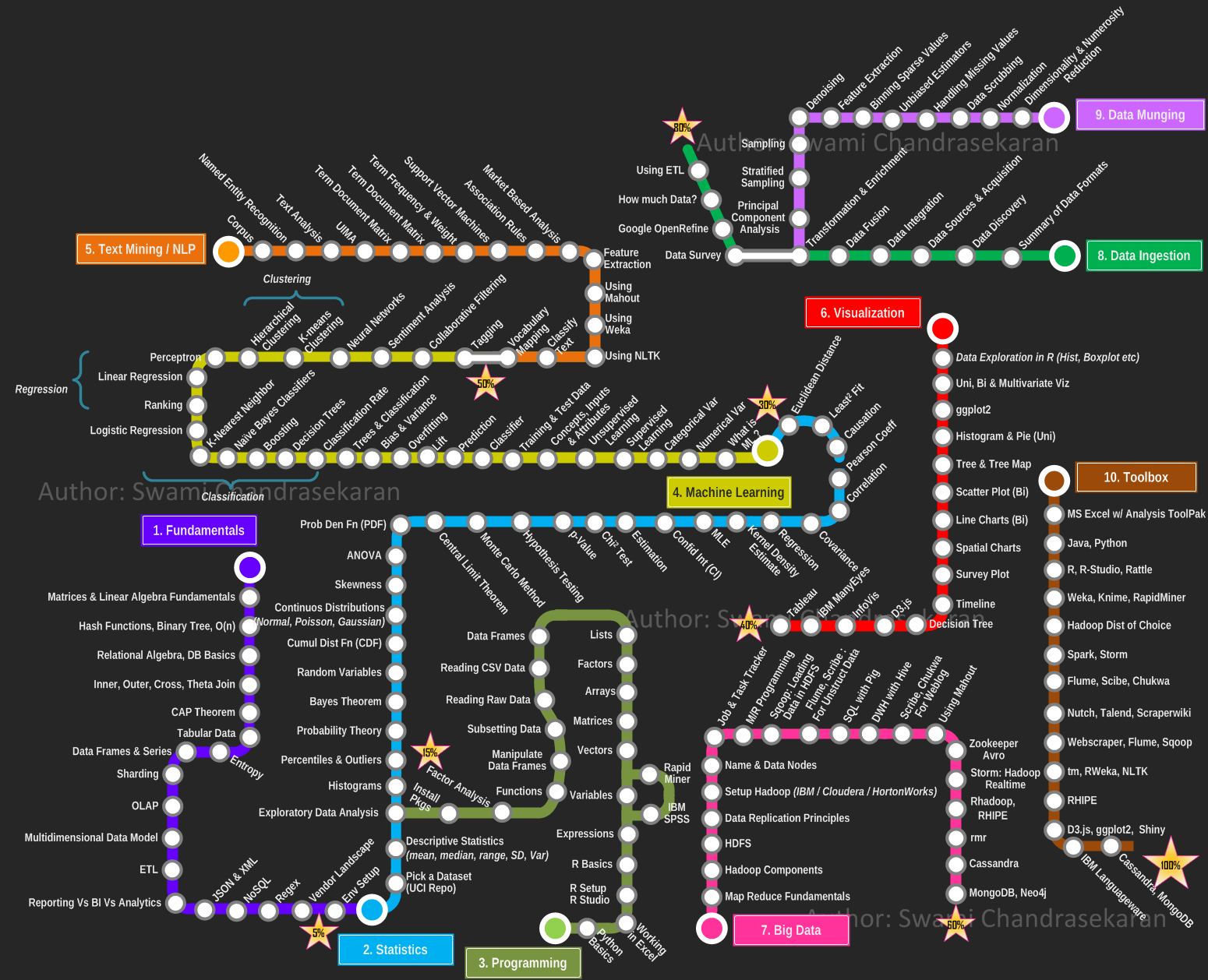
Это все, что нужно, чтобы стать уверенным дата-сайентистом (по состоянию на 2013 год). Вполне достижимо, да? (Источник: Swami Chandrasekaran)
Я погуглил, как стать дата сайентистом, нашел этот “план” и познал экзистенциальный кризис. Позволь спросить, действительно ли я должен освоить всё в этой диаграмме, чтобы стать дата сайентистом?
Отвечу коротко — нет. Никто больше не использует этот план. Он 2013 года. В нем даже нет TensorFlow, и некоторые пути на нем можно попросту вычеркнуть. Я думаю, что уже в то время «data science» стал более сложной и специализированной. Было бы лучше использовать другой подход.
Ладно, немного полегчало. Так мне все-таки стоит вернуться в школу? Я где-то читал, что многие дата сайентисты имеют, по крайней мере, магистерское образование. Должен ли я получить степень магистра в области науки о данных?
Господи, зачем тебе это? Нужно вообще быть осторожным с направлениями обучения «data science“, которые по большому счету переделанные курсы ”бизнес-аналитики». Вдобавок, современные академики, как правило, отстают от индустрии и могут преподавать устаревшие технологии. Чтобы идти в ногу со временем, тебе лучше заниматься самообучением на Coursera, Stepik или Khan Academy.
Вот как.
Хотя если и поступать в вуз, может тогда на физику или на математические методы исследования операций? Трудно сказать. Как ни странно, многие хорошие дата сайентисты, с которыми я знаком, пришли из этих областей. Возможно, тебе удастся найти хорошую программу обучения “data science”. Я не знаю, поговори с этим доктором наук, он тебе изложит свою позицию.
Так как же начать самообразование? Какой-то парень в LinkedIn сказал, что те, кто интересуется data science, должны начать с изучения Linux. Потом в Twitter я читаю, что какой-то другой парень настаивает на том, что дата сайентисты должны изучать Scala, а не Python или R.
Ну и сморозил этот парень на LinkedIn. Что касается «знатока» Scala, если и нырять с головой, то, пожалуйста, только не в этот омут. Доверься мне. Уже 2019 на дворе. Scala давно не в ходу в сообществе data science. А если бы и была, PySpark бы не появился. И уж точно не слушай хипстеров, как тот парень, который все время говорит о Kotlin.
Ок! А как насчет R? Похоже, людям нравится.
R хорош в математическом моделировании, и только. С Python ты получишь гораздо больше от своих инвестиций в обучение и сможешь выполнять более широкий спектр задач, таких как сбор данных и настройка веб-сервисов.
Но R по-прежнему занимает довольно высокое место в Tiobe, и у него куча последователей и ресурсов. Его использовать — себе вредить?
Смотри, ты можешь использовать R. Если тебе просто интересна математика, он, спорно, конечно, но лучше, но еще лучше он работает с Tidyverse. Но data science по-прежнему нечто гораздо, ГОРАЗДО большее, чем математика и статистика. Поверь мне, на Python в 2019 можно намного дальше уехать.
Хорошо, так… Видимо, я начинаю изучать Python.
Ты не пожалеешь.
Python сложный? Удержусь ли я с ним на плаву, когда роботы возьмут верх?
Ну конечно, Python — довольно простой язык. С ним можно автоматизировать много задач и делать классные ништяки. Но тебе даже и не нужен Python. Data science — это гораздо больше, чем скрипты и машинное обучение.
Что ты имеешь в виду?
Ну, это всего лишь инструменты. Ты используешь Python для получения информации из данных. Иногда это требует машинного обучения, но в большинстве случаев нет. Data science может просто подразумевать создание диаграммы. По факту, даже не нужно изучать Python, можно просто использовать Tableau. Они рекламируют, что могут ”сделать всех в вашей организации дата сайентистами", если те просто будут использовать их продукт.
Tableau уверены, что могут решить кадровую проблему нехватки дата сайентистов.
Стоп, чего? Так что, я просто покупаю лицензию на Tableau, и я теперь дата сайентист? Хорошо, давай поговорим об этом коммерческом предложении с ноткой скепсиса. Может я и невежда, но знаю, что data science не просто создание красивых визуализаций. Я могу и в Excel это сделать.
Конечно. Тем не менее, нужно признать, что это отличный маркетинг. Построение графиков — это, конечно, весело, но они упускают всю ту боль и уйму времени, что отнимают очистка, обработка, изменение и загрузка данных.
Да, и именно поэтому я подозреваю, что есть ценность в изучении кода. Давай поговорим о Python.
Вообще-то, подожди. Может быть, тебе выучить Alteryx.
Что?
Есть еще одно программное обеспечение под названием Alteryx, которое позволяет очищать, обрабатывать, изменять и загружать данные. Это здорово, потому что он использует Drag&Drop для объединения данных и…

Alteryx тоже обещают “data science" без кода.
О Боже, пожалуйста, остановись. Больше никакого Drag&Drop. Я хочу изучать Python, а не Alteryx или Tableau.
Ладно, извини. Я просто пытался облегчить тебе жизнь, избежать кодинга. Может быть, я сделал это еще потому, что наша компания купила лицензии, которые мы должны использовать. Но в любом случае, чтобы использовать Python, нужно изучить несколько библиотек, таких как Pandas для управления DataFrame и matplotlib для создания диаграмм. Вообще-то, вычеркни matplotlib. Используй Plotly. Он использует d3.js и вообще намного приятнее.
Я знаю некоторые из произнесенных тобой слов. Но что такое DataFrame?
Ну, это такая структура данных в виде таблицы со строками и столбцами. Можно делать все эти крутые преобразования, сводные таблицы и агрегации с DataFrame в среде Python.
Погоди, так чем же это отличается от Excel? Я все это делал еще с момента выпуска из колледжа. Означает ли это, что я уже дата сайентист?
Если тебе льстит называть себя так, конечно. Я бы объявлял во всеуслышание этот самопровозглашенный титул каждый раз, когда шел на вечеринку или писал резюме.
Так что же отличает Python от Excel?
Python отличается тем, что все можно сделать в Jupyter-ноутбуке. Ты можешь провести все этапы анализа данных, и ноутбук визуализирует каждый шаг. Это почти как написать историю, которой можно поделиться с другими. А коммуникация и истории, в конце концов, — чертовски важная часть data science.
Звучит как PowerPoint. Я уже и это делаю. Я так запутался.
О боже, нет. Ноутбуки гораздо более автоматизированы и оптимизированы, и это позволяет легко отслеживать каждый шаг анализа. Но если подумать, я просто вспомнил, что некоторые вообще не любят ноутбуки, потому что код в них не очень удобно переиспользовать. Проще распределить код по модулям вне ноутбуков, если нужно превратить его в программный продукт.
Так, теперь data science еще и разработка программного обеспечения?
Может быть, но давай не будем отвлекаться на это. Есть гораздо более насущные вещи, которые нужно выучить на первых порах. Чтобы заниматься data science, тебе, очевидно, потребуется data — данные.
Конечно.
И нет ничего лучше для новичка, чем сбор данных в сети, с тех же страничек из Википедии, которые можно сбросить на жесткий диск.
Подожди, чего мы опять пытаемся достичь?
Ну, мы пытаемся получить какие-нибудь данные для практики. Скрапинг веб-страниц и их парсинг с помощью Beautiful Soup даст нам кучу неструктурированных текстовых данных для работы.
Я в замешательстве. Я только что закончил читать отличную 130-страничную книгу по SQL, и я думал, что буду запрашивать таблицы, а не скрапить интернет. Разве SQL не является типичным способом доступа к данным?
Ну, мы можем сделать много интересного с неструктурированными текстовыми данными. Мы можем использовать их для классификации настроений в сообщениях из социальных сетей или для другой обработки естественного языка. NoSQL отлично подходит для хранения такого типа данных, потому что мы можем хранить огромные их объемы, не заботясь о том, чтобы делать их пригодными для аналитики.
Я слышал термин NoSQL. Так это SQL? Анти-SQL? Подожди, я думаю, что это как-то связано с big data, верно?
Ну во-первых, “big data” это из 2016. Большинство людей больше не используют этот термин, так что просто не круто так говорить. Как и многие хайповые технологии, он прошел свой пик популярности и нашел применение только в нескольких местах. Но NoSQL — это по сути результат движения «big data», взрастивший такие платформы, как MongoDB.
Хорошо, но откуда тогда название “NoSQL”?
NoSQL означает «не только SQL» и поддерживает структуры данных за пределами реляционных таблиц. Однако, базы данных NoSQL, как правило, не используют SQL, а, скорее, собственный язык запросов. Вот MongoDB в сравнении с SQL:

Боже мой, это ужасно. Так ты утверждаешь, что каждая платформа NoSQL имеет свой собственный язык запросов? Что не так с SQL?
Понял тебя. С SQL все в порядке, кроме того, что ему уже десятки лет. Повальное увлечение неструктурированными данными стало возможностью сделать что-то новое и широко масштабироваться недоступными раньше способами. Тем не менее, я думаю, все больше людей приходят к выводу, что смысл в сохранении SQL все же есть. Это значительно упрощает аналитику. На самом деле настолько, что многие технологии NoSQL и “больших данных” скремблировали, чтобы добавить слой SQL в той или иной форме. В конце концов, SQL — довольно универсальный язык, даже если некоторым людям он даётся с трудом.
Ух, ну ладно. Итак, я понял, что изучение NoSQL для меня, как дата сайентиста, не критично, если только моя работа не потребует обратного. Звучит так, будто я в безопасности, зная только SQL.
Чем больше я думаю об этом, тем больше верю, что да, ты прав, но лишь до тех пор, пока тебя не потянет стать дата-инженером.
Дата-инженером?
Да, дата сайентисты как бы разделились на две профессии. Дата-инженеры работают с производственными системами и помогают сделать данные и модели пригодными для использования, но меньше занимаются машинным обучением и математическим моделированием, что, всвою очередь, остаётся дата сайентистам. Вероятно, это было необходимо, поскольку большинство HR и рекрутеров не видят дальше титула “дата сайентист”. Подумай об этом, если хочешь быть дата-инженером, я бы уделил особое внимание изучению Apache Kafka а не NoSQL. Apache Kafka сейчас просто бомба.
Вот, эта диаграмма Венна тебе поможет. Чтобы получить титул «дата сайентист», нужно быть где-то в математическом/статистическом круге, а в идеале, на пересечении с другой дисциплиной.

Data Science Диаграмма Венна
Ну ладно, я сейчас понятия не имею, хочу ли я быть дата сайентистом или инженером данных. Давай просто двигаться дальше. Итак, возвращаясь назад, почему мы парсим страницы Википедии?
Ну, они служат в качестве входных данных для обработки естественного языка, и с их помощью можно делать, например, чат-ботов.
Как Tay от Microsoft? Будет ли этот бот достаточно умен, чтобы прогнозировать продажи и помогать мне запускать новые продукты с правильным количеством запасов? Есть ли риск, что он неизбежно станет расистом?
Теоретически, есть. Если ты накормишь его новостными статьями, возможно, получится создать модель, которая определяет некоторые тенденции и, в результате, дает рекомендации по бизнес решениям. Но это НЕРЕАЛЬНО сложно. Подумай хорошенько, это может быть не лучшим вариантом для начала.
Итак, что ж… обработка естественного языка, чат-боты и неструктурированные текстовые данные, возможно, не для меня?
Возможно, но имей ввиду, что в настоящее время data science повсюду. Компании Кремниевой долины, такие как Google и Facebook, имеют дело с большим количеством неструктурированных данных (таких как сообщения в социальных сетях и новостные статьи), и, очевидно, они оказывают большое влияние на определение “data science”. Ну а остальные, такие как мы, используем бизнес-операционные данные в виде реляционных баз данных и менее вдохновляющие технологии, такие как SQL.
Звучит правдоподобно. Я предполагаю, что они посвящают свои таланты в сфере неструктурированных данных в основном для добычи пользовательских сообщений, электронных писем, историй для рекламы и других гнусных целей.
Так и есть. Знаешь, наивный байесовский классификатор может показаться тебе интересным и в своем роде полезным. Можно взять текст и предсказать категорию для него. Это довольно легко реализуется с нуля:
Категоризация тел текста с помощью наивного байесовского классификатора
Ты прав, он крут. Но кроме этого никакой ценности в неструктурированных данных я не вижу.
Тогда двигаемся дальше. Так значит ты работаешь с табличными данными: электронными таблицами и кучей записанных чисел. Это даже звучит почти так, будто ты хочешь делать прогнозы или статистический анализ.
Да, наконец-то мы хоть что-то выяснили! Наконец займемся решением реальных проблем. Так это теперь начнется тема нейронок и глубокого обучения?
Э-гей, придержи-ка лошадей. Я собирался предложить начать с нормальных распределений со средними и стандартными отклонениями. Может, вычислить вероятности с z-оценкой и одной-двумя линейными регрессиями.
Но опять же, я могу это все в Excel сделать! Разве не могу?
Ну… эм… да, это верно, ты многое из перечисленного можешь сделать в Excel. Но при написании скриптов, ты получаешь большую гибкость.
Как с VBA? Visual Basic?
Ладно, я начну сначала и притворюсь, что ты этого не говорил. У Excel действительно отличные статистические операторы и достойные модели линейной регрессии. Но если тебе нужно сделать отдельное нормальное распределение или регрессию для каждой категории элементов, гораздо проще написать скрипт на Python, а не создавать адские формулы, длина которых может стать метрикой расстояния до Луны.

When you become advanced at Excel, you inflict pain on everyone who works with you. (Когда становишься крут в эксель, все вокруг испытывают боль)
Ты же можешь использовать крутую библиотеку scikit-learn. С ней ты получишь гораздо более мощные возможности для различных регрессий и машинного обучения.
Ладно, справедливо. Так, похоже, теперь разговор переходит в область математического моделирования. Вот передо мной куча математических задач, с чего мне начать?
Ну, в традиционном представлении линейная алгебра — это строительный блок для многого в data science, и именно с неё нужно начать. Умножение и сложение матриц (так называемое скалярное произведение) — это то, что ты будешь делать все время, и есть другие важные понятия, такие как детерминанты и собственные векторы. 3Blue1Brown — это практически единственный канал, где можно найти интуитивное объяснение линейной алгебры (англ).
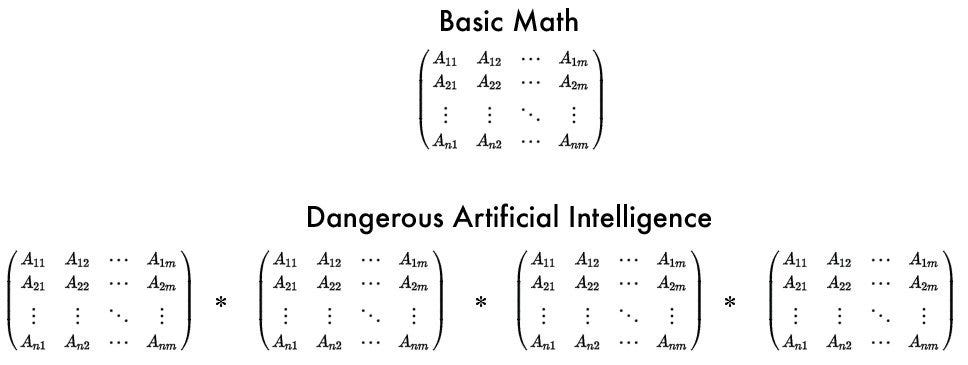
Итак… умножение/сложение одной матрицы с другой — это то, чем я в основном буду заниматься? Звучит реально бессмысленно и скучно. Ты можешь привести пример?
Ну… машинное обучение! Когда делаешь линейную регрессию или строишь свою собственную нейронную сеть, придется много раз провести умножение матриц и масштабирование со случайными значениями веса.
Хорошо, так матрицы имеют какое-то отношение к data frame? Звучат они похоже.
Вообще-то, погоди… я это переосмыслил. Вернемся к этому утверждению. На практике тебе не нужно заниматься линейной алгеброй.

Ой, Да ладно тебе! Серьезно? Так мне изучать линейную алгебру или нет?
На практике тебе, вероятно, не нужно изучать линейную алгебру. Библиотеки, такие как TensorFlow и scikit-learn, сделают все за тебя. В конце концов, это действительно утомительно и скучно. Ты, конечно, можешь разобраться и получить некоторое представление о том, как работают эти библиотеки. Но сейчас просто начни использовать библиотеки машинного обучения и полностью игнорируй линейную алгебру.
Твоя неуверенность меня тревожит. Могу ли я доверять тебе?
Прояви хоть немного уважения! Я только что вытащил тебя из ещё одного омута. Не за что.
Ох.
И еще, пока не забыл. Ты сам по себе TensorFlow не используй. Используй его с Keras, потому что с ним TensorFlow гораздо проще.
Если вернуться обратно, действительно ли линейная регрессия относится к машинному обучению?
Да, линейная регрессия включена в список инструментов «машинного обучения».
Круто, я все время делаю это в Excel. Так могу ли я назвать себя ещё и практиком машинного обучения?
*Вздыхат* технически, да. Но тебе, возможно, захочется немного расширить свой кругозор. Видишь ли, машинное обучение (независимо от техники) зачастую состоит из двух задач: регрессии и классификации. Технически, классификация — это регрессия. Деревья решений, нейронные сети, метод опорных векторов, логистическая регрессия и да… линейная регрессия, — все они в своем роде выполняют подгонку кривых. Каждая модель имеет плюсы и минусы в зависимости от ситуации.
Подожди, так машинное обучение — это просто регрессия? Все это просто эффективная подгонка кривых к точкам?
Примерно так. Некоторые модели, такие как линейная регрессия, ясные как день, в то время как более продвинутые модели, такие как нейронные сети, по определению запутаны и трудны для интерпретации. Нейронные сети — это просто многослойные регрессии с нелинейными функциями. Возможно, не очень впечатляет, когда у тебя только 2-3 переменные, но когда у тебя их сотни или тысячи, вот где становится интересно.
Ну, если зайти с этой стороны, конечно. А распознавание изображений — это тоже регрессия?
Да. Каждый пиксель изображения становится входной переменной с числовым значением. Только вспомнил: нужно быть осторожным с проклятием размерности. Это значит, что чем больше переменных (измерений) у тебя есть, тем больше данных тебе нужно, чтобы они не становились разреженными. Это одна из многих причин, почему машинное обучение может быть настолько ненадежным и беспорядочным, и может потребовать абсурдного количества размеченных данных, которых у тебя, вполне вероятно, не будет.
У меня сейчас много вопросов.
(Поехали!)
Как насчет таких проблем, как планирование расписаний персонала или транспорта? Или решение судоку? Может ли машинное обучение решить все эти проблемы?
Ну, если говорить о таком типе проблем, найдутся люди, которые скажут, что это не data science или машинное обучение. Это “исследование операций”.
На мой взгляд, это практические проблемы. Значит, исследование операций не имеет ничего общего с наукой о данных?
На самом деле, есть приличное количество пересечений. Исследование операций дало много алгоритмов оптимизации, которые использует машинное обучение. Оно также предоставило множество решений общих проблем «ИИ», таких как те, что ты упомянул.
А какие алгоритмы используют для решения таких проблем?
Ну, определенно не алгоритмы машинного обучения, и слишком мало людей об этом знают. Есть и лучшие алгоритмы, которые существуют в течение десятилетий. Дерево поиска, метаалгоритмы, линейное программирование и другие методы исследования операций используются уже давно и выполняют свою работу гораздо лучше, чем алгоритмы машинного обучения для таких же категорий задач.
Так почему же все говорят о машинном обучении, а не об этих алгоритмах?
* Вздыхает * потому что эти задачи оптимизации были в какой-то момент решены, и эти методы с тех пор не мелькали в заголовках. Хочешь верь, хочешь нет, несколько десятилетий назад первая реклама ИИ акцентировала внимание именно на этих алгоритмах. В настоящее время шумиху вокруг ИИ подняло машинное обучение и типы проблем, которые он хорошо решает: распознавание изображений, обработка естественного языка, генерация изображений и т. д.
Поэтому, когда люди предлагают использовать машинное обучение для решения проблемы планирования или чего-то простого, как Судоку, например, они ошибаются?
В значительной степени, да. Машинное обучение, глубокое обучение и т. д… Все, что сегодня «на хайпе», обычно не решает проблем дискретной оптимизации, ну или решает, но плохо. Люди делали попытки, но результаты были весьма посредственными.
Итак, если машинное обучение — это просто регрессия, почему все так суетятся вокруг роботов и ИИ, ставя под угрозу нашу работу и общество? Я имею в виду… подгонка кривой действительно так опасна? Сколько самосознания имеет «ИИ», когда он просто делает регрессию?
Ну, люди нашли несколько умных применений для регрессий, таких как поиск лучшего следующего шахматного хода (что также может сделать и дискретная оптимизация) или самодвижущийся автомобиль, вычисляющий, в каком направлении повернуть. Но да, шумихи довольно много, и регрессия может иметь так много применений и решать лишь одну задачу.
Я все еще не могу смириться с этим. Я читал статьи о том, как DeepMind подражает человеческому интеллекту в шахматных играх, и теперь он побеждает людей в StarCraft! Эти алгоритмы машинного обучения обходят людей во всех этих играх! Значит ли это, что в будущем они заменят меня на моей работе?
Сколько игроков StarCraft претендует на твою работу?
(Неловкое молчание)
Можешь ли ты сказать, что игра в StarCraft похожа на твою работу?
Если тебе не угрожает игрок StarCraft, почему тебе вдруг надо беспокоиться о роботе-игроке StarCraft? Они жестко запрограммированы и обучены хорошо выполнять эту задачу: играть в StarCraft. То же самое можно сказать о человеке, который ничего кроме этого в жизни не делал, и становится тебе угрозой.
Я не знаю, радоваться мне или сомневаться. Сначала шахматы, потом Старкрафт… может быть, дальше будет автоматизированная аналитика и роботы, принимающие стратегические бизнес-решения. Но, возможно, третий пункт — это большой скачок из первых двух. Я уже и не знаю.
Какой-то парень написал статью по Data Science о глубоком обучении, выходящем за рамки своих ограничений. Возможно, захочешь прочитать ее.
Хорошо, так как же мы перешли от науки о данных к искусственному интеллекту? Чем больше я пытаюсь определить «data science», тем больше я просто… я просто… я не могу её описать. Все это так безумно и неясно.
Вот, я читал еще одну статью того же автора. Отличный парень.
Спасибо. Мне нужно прогуляться и все обдумать. Если я хоть что-то понял, я думаю, что моя работа в Excel квалифицируется как “data science”. Хотя я и не знаю, хочу ли я иметь титул дата сайентиста. Похоже, это может быть все что угодно. Я могу потратить свое время на что-то другое. Надеюсь, следующий «Новый Хит», который придёт вслед за data science будет менее сумасшедшим.
Может быть, тебе стоит какое-то время поработать на IBM?
Зачем?
Когда-нибудь слышал о квантовых вычислениях?

