Привет, Хабр!
Несколько месяцев назад я выступал на конференции FrontendConf 2019 с докладом Docker для фронтендера и хотел бы сделать небольшую расшифровку доклада для тех, кто больше любит читать, а не слушать.
Приглашаю под кат всех веб-разработчиков, особенно фронтендеров.
Содержание
- Docker для фронтендера. Часть 1. Зачем?
- Docker для фронтендера. Часть 2. Что ты такое?
- Docker для фронтендера. Часть 3. Немного рецептов
Восхождение Docker
Docker инструмент не новый, он впервые был опубликован ещё в марте 2013 года и с тех пор его популярность только растёт.
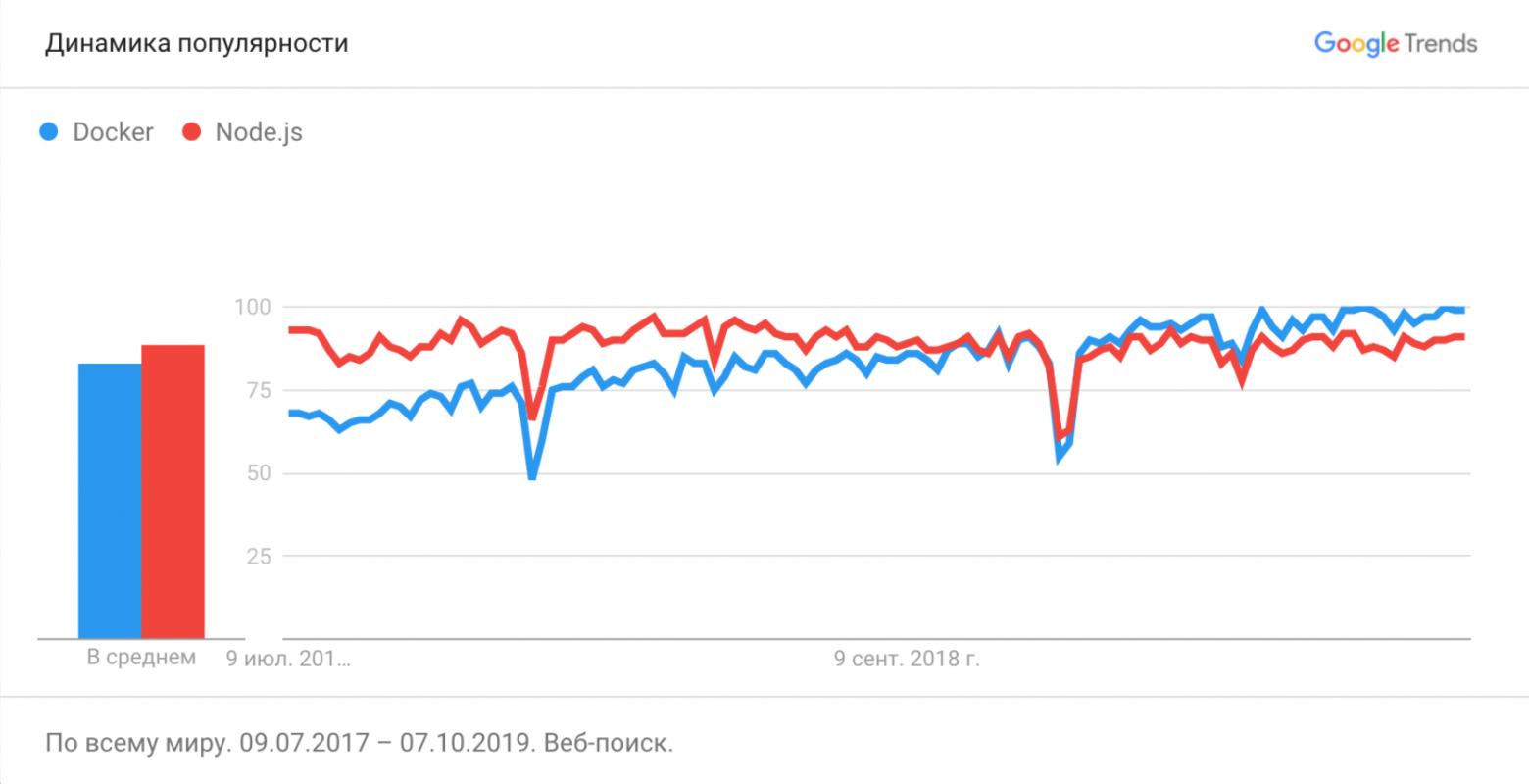
Тут мы видим, что частота запросов по Node.js достигла плато и никуда не двигается, а запросов про Docker продолжает увеличиваться.

Вот такая игрушка была на конференции РИТ++ 2019 в рамках DevOps-секции. И по моему опыту ни одна конференция по DevOps не проходит без докладов про Docker, так же, как и фронтендерские конференции не проходят без докладов про сравнение фреймворков, настройку вебпака и профессиональное выгорание.
Давайте и мы во фронтенд-тусовке тоже начнём говорить про эту технологию.
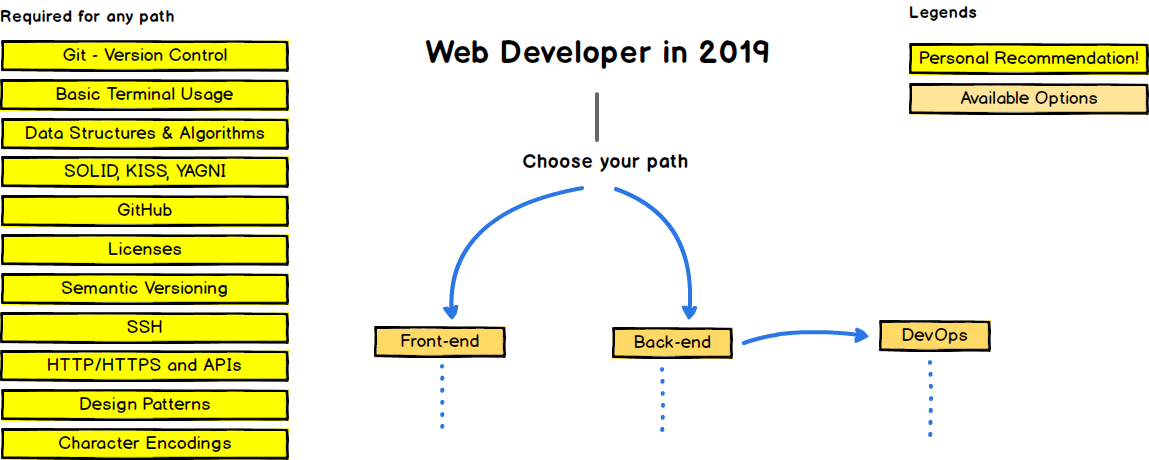
Это дорожная карта веб-разработчика. Слева изображены навыки, обязательные для любого пути развития. Действительно, сложно представить хорошего веб-разработчика, который не умеет в Git, терминал или не знает HTTP.
Docker тут тоже присутствует, но где в недрах ветки развития DevOps'а в блоке Infrastructure as a code -> Containers.
Но мы знаем, что Docker — это ещё и отличный инструмент для разработки, а не только для эксплуатации. И, по моему мнению, он имеет все шансы через некоторое время попасть в секцию Required for any path и стать обязательным требованием во многих вакансиях фронтенд-разработчиков.
Можно сказать, что мы сейчас живём в Эру Docker. Поэтому, если вы фронтенд-разработчик и ещё с ним не познакомились, то я расскажу, почему это стОит сделать.
Зачем?
Кейс 1. Поднимаем backend
Первый и самый полезный кейс, который мы можем рассмотреть — это запуск API на своём уютном макбуке. Да, мы отлично знаем наши технологии, но разворачивать что-то стороннее всегда испытание не из лёгких.
На одном из наших проектов фронтенд-разработчику нужно было поставить на компьютер вот такой набор, чтобы API заработал:
* go1.11 * MySQL * Redis * Elasticsearch * Capistrano * syslog * PostgreSQL
К счастью, у нас были инструкции по развёртыванию проекта в README-файлах. Они выглядели примерно так:
1. Установить GVM (https://github.com/moovweb/gvm) 2. `gvm install go1.11.13 --binary` 3. `gvm use go1.11.13 --default` 4. В папке с проектом создать ссылку на golang (`gvm linkthis`) 5. Установить `gb` `go get github.com/constabulary/gb/...` 6. Настроить авторизацию `git config --global url."git@git.example.com:".insteadOf "https://git.example.com/"` 7. Установить зависимости `gb vendor restore` 8. Поднять БД 9. Собрать ассеты `npm run build` (`npm run build:dev` для разработки) 10. Запустить сервер `npm start`
И вот так:
## Elasticsearch 1. Скачать и установить Elasticsearch `brew install elasticsearch` - macOS (предложит установить дистрибутив java) 2. Установка плагина * выбери в https://github.com/imotov/elasticsearch-analysis-morphology из списка подходящий к твоей версии плагин, и запусти `/usr/local/Cellar/elasticsearch/2.3.3/libexec/bin/plugin install http://dl.bintray.com/content/imotov/elasticsearch-plugins/org/elasticsearch/elasticsearch-analysis-morphology/2.3.3/elasticsearch-analysis-morphology-2.3.3.zip` - пример * потом перезапусти эластик `brew services restart elasticsearch` 3. в проекте админки `rake environment elasticsearch:import:model CLASS='Tag' FORCE=y ` `rake environment elasticsearch:import:model CLASS='Post' FORCE=y` индексировать будет долго, но пользоваться можно сразу ## Postgres comments db 1. `psql -U postgres -h localhost` 2. `create database comments_dev;` ## Redis install and start 1. `brew install redis` 2. Перед запуском `brew services start redis`
Как вы думаете, сколько времени требовалось начинающему разработчику, чтобы развернуть у себя проект и начать делать задачи?
Около недели.
Естественно, не все команды терминала проходили с первого раза, довольно часто инструкция устаревала.
Это считалось нормальным и всех устраивало. То есть, чтобы сделать фичу в 1 час работы, требовалось сначала потратить 40 часов на разворачивание всех компонент локально.
Сейчас разворачивание проекта со всеми сервисами для разработки выглядит вот так и при холодном старте занимает около 10 минут.
$ docker-compose up api ... Listening localhost:8080
Все команды разворачивания сервисов выполняются во время сборки Docker образов. Они автоматизированы и не могут устареть.
Кейс 2. Устойчивость
Второй кейс — устойчивость системы нашего рабочего компьютера.
Кому нравится ставить на свой любимый компьютер какой-то сторонний софт? Кому нравится устанавливать несколько разных баз данных, новые компиляторы, интерпретаторы?
А это приходится делать, когда мы разворачивает локально сторонний API.
Более того, вы можете сломать вашу систему и потратить несколько часов на её восстановление.

Использование Docker для разработки достаточно хорошо справляет с этой проблемой. Весь сторонний софт крутится в изолированных контейнерах и при необходимости легко удаляется.
$ docker rm --volumes api $ docker system prune --all
Кейс 3. Контролируем эксплуатацию
И третий кейс, про который бы я хотел рассказать — это возможность фронтенд-разработчику контролировать эксплуатацию своего сервиса. Самому решать, как его сервис будет работать в продакшене.
Я знаю, что передача проекта в эксплуатация довольно часто выглядит следующим образом.
Фронт: Ребят, я всё сделал. Код в репе. Выкатите, плиз!
Админ: Как оно выкатывается?
Фронт: Собираешь нодой и раздаёшь статику веб-сервером из папки /build
Админ: Какой версией ноды собирать? Какая команда сборки? Каким веб-сервером раздавать?
В итоге для админа развёртывание вашего проекта превращается в не менее увлекательный квест, как для вас развёртывание API на локальной машине из предыдущих кейсов.
Даже если проект будет работать у вас на компьютере, совсем не обязательно, что всё так же будет работать на продакшене. И мы получаем классическую проблему "это работает на моей машине".

Docker помогает нам и с этим. Решение простое, если мы запаковали наш проект в Docker, тем самым автоматизировав его сборку и настроив запуск, то он будет одинаково работать на всех серверах, которые поддерживают Docker.

А инструкция для админов сведётся к:
Фронт: Ребят, я всё сделал. Собрал для вас Docker-образ. Выкатите, плиз!
Админ: Ок
Уж с чем, а с Docker-образами админы точно должны уметь работать. Не то, что с нашей нодой.
Что же такое Docker?
Надеюсь, я смог объяснить, почему стоит присмотреться к этой технологии, если вы фронтенд-разработчик и до сих пор её не знаете. Но я так и не рассказал, что это такое.

Планирую написать про это в следующих частях статьи и дать немного полезных рецептов для фронтенд-разработчиков.

