
Недавно я столкнулся с многоминутными задержками на моей рабочей станции. После расследования выяснилось, что причина проблемы заключалась в блокировке, которая могла длиться по пять минут, во время которых источник блокировки в основном крутился в цикле из девяти инструкций.
Для меня очень важно подбирать хорошие заголовки для своих постов, но я сразу же вспомнил, что подходящее название «48 ядер заблокированы девятью инструкциями» уже занято [перевод на Хабре] постом, написанным меньше месяца назад. Количество заблокированных процессоров отличается, а цикл немного длиннее, но на самом деле всё это заставляет испытывать дежавю. Поэтому пока я объясняю новую найденную проблему, мне был хотелось поразмыслить над тем, почему это случается постоянно.
Почему это происходит?
Грубо говоря, такие проблемы возникают вследствие наблюдения, которое я назову Первым законом Доусона о вычислениях: O(n2) — это магнит для алгоритмов, которые плохо масштабируются: они достаточно быстры, чтобы попасть в продакшен, но достаточно медленны, чтобы всё портить, когда туда попадут.

O(n2) в действии — данные взяты из моего случая
Что же происходит? Разработчик пишет код и использует алгоритм O(n2). Возможно, он этого не осознаёт, или алгоритм становится O(n2) из-за бага, или разработчик знает, что он O(n2), но думает, что это никогда не будет важным. В лабораторных условиях скорость кода приемлема, и приемлема она для большинства пользователей в реальном мире, но потом кто-нибудь создаёт 7 000 процессов со включенным App Verifier или создаёт двоичный файл с 180 000 элементов CFG, или собирает такую большую DLL, что при компоновке постоянно сканируется односвязный список, что забирает всё время процессора. При работе над временем запуска движка Source 2 компании Valve я обнаружил множество алгоритмов O(n2), каждый из которых прибавлял к времени запуска движка примерно по 30 секунд, то есть эта проблема возникает у очень разных разработчиков.
O(n2) — это магнит для алгоритмов, которые плохо масштабируются: они достаточно быстры, чтобы попасть в продакшен, но достаточно медленны, чтобы всё портить, когда туда попадут.
Именно.
Например, создание имён файлов лога App Verifier выполняется за линейное время для каждого запущенного процесса, и это нормально, пока ты не осознаешь, что это приводит к O(n2), если запущено множество процессов. Иногда даже неочевидно, что присутствуют вложенные циклы, или что формально это не O(n2), или неочевидно, что циклы могут выполняться так долго, что это может значительно влиять на скорость…
Так что учитывайте эту возможность, думайте о ней при написании кода, следите за тем, как масштабируется производительность при больших нагрузках и исследуйте подозрительные участки кода при профилировании таких больших нагрузок. Или оставьте это мне, чтобы я мог их искать и писать статьи в блог.
Вернёмся к нашим привычным жалобам
Как обычно, я занимался своими делами, работая на своей устаревшей, но всё ещё мощной рабочей станции с 48 логическими процессорами и 96 ГБ ОЗУ. Я ввёл ninja chrome, чтобы собрать Chromium, но… ничего не произошло. Я смотрел и ждал двадцать секунд, но сборка так и не начиналась. Поэтому я, разумеется, переключился на UIforETW, чтобы записать трассировку ETW. Точнее, попробовал это сделать. Попытавшись начать запись трассировки, UIforETW завис. Впервые в моей практике баг использовал меры защиты, чтобы помешать мне его исследовать!
Через одну-две минуты началась сборка Chromium, а UIforETW запустил трассировку, но она началась слишком поздно и у меня не было ни малейших сведений о том, что произошло.
Параметры UIforETW с выбранным Circular Buffer Tracing
Когда спустя пару дней произошло то же самое, UIforETW снова не смог ничего сделать. На этот раз я оставил трассировку работать в кольцевых буферах памяти, чтобы быть готовым к тому, что зависание произойдёт в третий раз. Однако это сильно снизило скорость работы моих инструментов сборки, поэтому спустя несколько часов я сдался.
Потом эта ситуация повторилась снова. На этот раз я запустил инструмент записи трассировок ETW, созданный Microsoft — wprui, и мне удалось начать запись. Примерно 40 секунд спустя сборка начала работать и я получил трассировку!
Теперь можно приступать к расследованию?
Ранее я заметил в «Диспетчере задач», что во время этих зависаний выполнялся WinMgmt.exe. Взглянув на данные CPU Usage (Precise) в WPA, я убедился, что по прошествии более сорока секунд, на протяжении которых почти единственным работающим процессом был WinMgmt.exe, моя машина оживала после того, как WinMgmt.exe завершал работу:
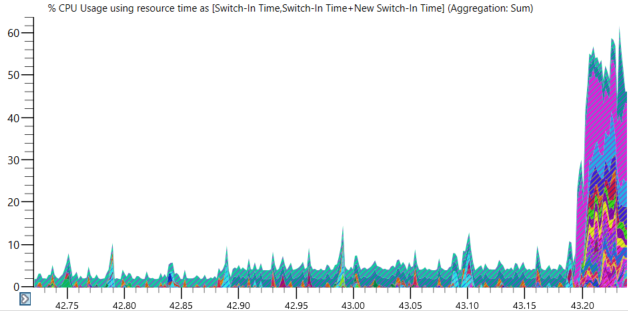
Ожидаем пробуждения процессов после завершения WinMgmt.exe
Всё это довольно подозрительно, но мои мудрые читатели знают, что «после» — не значит «вследствие», и потребуют доказательств.
Как и в прошлый раз, я приблизил на графике момент разблокировки, отсортировав переключения контекста по Switch-In Time и поискав первое переключение с долгим значением Time Since Last (обозначающим длительность времени, в течение которого поток не выполнялся). Пропустив с десяток потоков, которые были просто короткими простоями, я нашёл первый из множества, который ждал 41,57 секунд. Спящий поток не пробуждался WinMgmt.exe, но я быстро выяснил, что он пробуждался потоком, который пробуждался WinMgmt.exe за доли миллисекунды до этого.
Объяснения графиков CPU Usage (Precise) и концепций readying-thread/new-thread см. в этом туториале или в этой документации.
На скриншоте с данными переключения контента в строке 17 находится поток 72,748(WinMgmt.exe), активизирующий поток 74,156 (svchost.exe). Далее в строке 19 поток 74,156 (svchost.exe) активизирует поток 58,704 (svchost.exe), который ожидал в течение 41,57 секунд. Это первый поток, пробуждающийся после долгого сна и с этого продолжается цепочка активизации потоков. Только что активизированные потоки можно увидеть в столбце New Thread Id, а затем спуститься на несколько строк вниз и увидеть их в столбце Readying Thread Id, активизирующими другой поток. Названия и ID процессов помогают разобраться с контекстом. Строка 17 связана со строками 18 и 19, строка 19 связана с 20, которая связана со строкой 23, которая связана со строкой 27, и так далее; каждый поток активизируется предыдущим в цепочке потоком:
Чудовище пробуждается — долго простаивавшие потоки оживают
41,57 — это большое для блокировки потока время, но на самом деле блокировались сотни потоков, и заблокированы они были намного дольше. Единственная причина, по которой их значение Time Since Last примерно равно 41,5 секунды, заключается в том, что это длительность трассировки до того, как зависание не разрешится.
Похоже, результаты согласуются с теорией, что проблема заключается в WinMgmt.exe, но не доказывают этого. Моя уверенность возросла, когда я взглянул на svchost.exe (3024) в Trace-> System Configuration-> Services и выяснил, что он является службой Winmgmt, но мне по-прежнему нужна была бОльшая определённость.
Покопавшись ещё немного (побродив вперёд и назад по времени), я решил, что взаимодействия слишком сложны, чтобы анализировать их подробно, особенно без имён потоков, которые могли бы намекнуть нам, чем занимаются 25 разных потоков в svchost.exe (3024).
Доказательство!
Тогда я решил подойти к доказательству вины WinMgmt.exe иначе. Возможно, с этого и стоило начать, но это было бы слишком просто. Я взял командную строку WinMgmt.exe из таблицы Processes в WPA и запустил её вручную. Команда имеет вид:
winmgmt.exe /verifyrepository
и её выполнение заняло около пяти минут. Пока она работала (и у меня было много времени), я выяснил, что не могу запустить трассировку ETW из UIforETW. Такое доказательство было лучше, чем любой запутанный анализ, который я мог провести.

Конфигурация для отображения только давно дремлющих потоков
Затем я снова выполнил repro с уже запущенной трассировкой; проанализировав трассировку, я обнаружил более сотни процессов, потоки которых были заблокированы более пяти минут!
И снова за дело…
По привычке я снова посмотрел на данные CPU Usage (Sampled), чтобы увидеть, на что WinMgmt.exe тратит время. Я быстро выяснил, что 96,5% сэмплов происходило в repdrvfs.dll!CPageCache::Read(), вызываемой в четырёх разных стеках:

Четыре пути, которые привели меня к CPageCache::Read
Дерево полных стеков к этой функции показаны здесь, в основном для людей из Microsoft, которые захотят исследовать эту проблему:
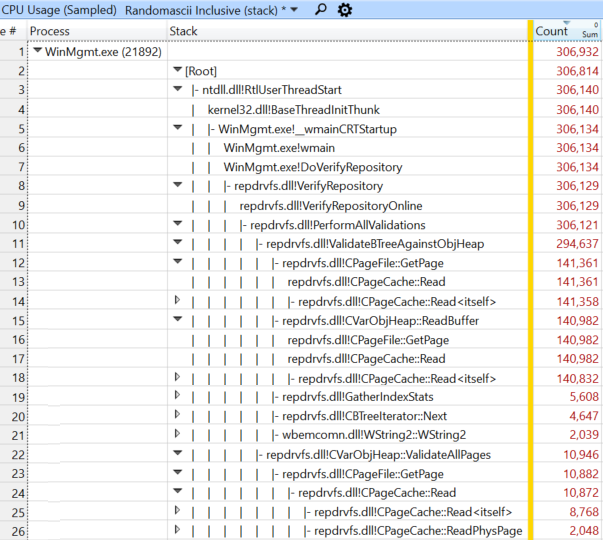
Полные стеки, ведущие к CPageCache::Read по трём путям
Я добавил столбец адреса и выяснил, что 95,3% сэмплов приходилось на один цикл из девяти инструкций (сэмплы всегда попадали только на семь из девяти инструкций (если хотите узнать, почему, то см. здесь), но отладчик показывал полный размер цикла):

Сэмплы по адресу — семь очень «горячих» адресов
Затем я запустил winmgmt.exe /verifyrepository вручную, и параллельно собирал данные счётчика ЦП о выполняемых инструкциях ветвления. Из этого я примерно мог прикинуть, сколько раз выполнялся цикл. Вероятно, это было необязательно, но я хотел убедиться, что цикл выполнялся много раз, а не выполнялся медленно (по какой-то причине). Я подумал, что очень круто, что я могу сделать это просто, достаточно внести крошечное изменение в пакетный файл. Я выяснил, что WinMgmt.exe выполнял приблизительно по одной инструкции ветвления на цикл, то есть цикл (который, как я уже знал, потреблял бОльшую часть времени ЦП) выполнялся чрезвычайно быстро, а замедление возникало из-за того, что он прогонялся сотни миллионов раз.
Задержка Xperf
Просто ради дотошности я решил посмотреть, почему UIforETW не мог запускать трассировку во время этого инцидента. Выяснилось, что UIforETW запускал xperf, но xperf простаивал 41,5 секунд (на самом деле больше) в этом стеке вызовов:
xperf.exe!wmain
xperf.exe!CStopTrace::Execute
perfctrl.dll!LoggingSession::EnumLoggers
perfctrl.dll!LoggingSession::LoggingSession
perfctrl.dll!LoggingSession::CreateProviderList
perfctrl.dll!GetProviderInfoCache
perfctrl.dll!CProviderInfoCache::CProviderInfoCache
tdh.dll!TdhfEnumerateProviders
tdh.dll!TdhpWbemConnect
wbemprox.dll!CLocator::ConnectServer
wbemprox.dll!CDCOMTrans::DoActualConnection
Если вкратце, то xperf вызывается Wbem, а потому блокируется этой проблемой. xperf пытается остановить трассировку, прежде чем начнёт её, потому что я добавил такое поведение, чтобы сделать запуск трассировки более отказоустойчивым. Подозреваю, что зависание всё равно происходило бы, но точно этого не знаю.
Создаём графики вычислительной сложности
Я заметил, что WinMgmt.exe сканирует каталог c:\windows\System32\wbem\Repository, который на моей машине занимает 1,9 ГБ, поэтому попросил на работе и в Twitter сообщить, какой объём занимает этот каталог, чтобы получить точки данных. Также я попросил людей зафиксировать время выполнения winmgmt.exe /verifyrepository и начал составлять график. Даже несмотря на то, что эти тесты проводились на совершенно различных машинах с разными скоростями ЦП, график получился довольно чётким:

Отношение между квадратным корнем от времени и размером репозитория
Этот график отношения sqrt(time) к размеру репозитория неправдоподобно идеален для данных, полученных с шести разных машин, и тем не менее, он реальный. Очевидно функция VerifyRepository имеет производительность O(n2). Если n — размер каталога Repository в ГБ, тогда VerifyRepository занимает примерно 1.6*n2 минут. Это хорошая примерная оценка для всех значений — от доли секунды до десяти минут.
Значимость
Или мне везёт, или я просто наблюдательный, потому что за пару недель никто больше не сталкивался с этой проблемой — я думал, что странности творятся с моей машиной. Но внезапно я начал слышать подозрительно похожие жалобы от коллег. У одного из них был репозиторий на 2,6 ГБ, проверка которого занимала десять минут. Проблема повлияла на некоторых наших CI-разработчиков, и в разной степени — на разных других людей. Мои коллеги обычно знают, что в случае проблем с производительностью машин под Windows нужно сказать об этом мне, однако, вероятно, есть множество других сотрудников Google, работающих под Windows, которым мешает этот баг, но они этого не осознают.
К счастью, я уже начал работать с нашим ИТ-отделом. Я нашёл скрипт, запускавший WinMgmt, и узнал, что он выполняется ежечасно. Это означало, что моя машина выполняла WinMgmt.exe /verifyrepository 10% времени, а у некоторых из моих коллег — больше 16% времени. Существует довольно большая вероятность получить задержку в десять минут перед сборкой.
К моменту, когда начали поступать отчёты, исправление уже было на пути в продакшен. Скрипт был необязательным, и уж точно не стоил вызываемых им проблем, поэтому исправление заключалось в отключении его вызова.
Итоги
winmgmt.exe /verifyrepository содержит цикл из девяти инструкций, количество итераций выполнения которого пропорционально квадрату размера репозитория wbem. Из-за этого выполнение команды может занимать до десяти минут, хотя на самом деле она должна выполняться всего за несколько секунд. Это плохо само по себе.
Но ещё хуже то, что во время своей работы команда выполняет блокировку WMI (Windows Management Instrumentation), поэтому любой процесс, выполняющий операции WMI, зависнет.
Удивительные загадки
Скрипт, выполнявший каждый час winmgmt.exe /verifyrepository, занимался этим многие годы, но проблемное поведение начало проявляться всего один-два месяца назад. Предположительно, это означает, что репозиторий wbem недавно стал становиться намного больше. Задержки при 0,5 ГБ легко не заметить, но от 1,0 ГБ и выше они могут уже напрягать. По предложению в Twitter я запустил strings.exe для файла objects.data. Многие из самых часто встречающихся строк содержат в названии «polmkr», но я не знаю, что это значит.
Я опубликовал отчёт о баге в Twitter, и поначалу он вызвал какое-то движение у команды WMI, но потом я перестал получать ответы, поэтому не знаю, какова ситуация сейчас.
Я бы хотел увидеть фикс проблемы с производительностью, и мне бы хотелось, чтобы наш ИТ-отдел смог найти и устранить проблему, из-за которой наши репозитории wbem становятся такими большими. Но пока ИТ-отдел пообещал не запускать больше каждый час команду /verifyrepository, что должно позволить избежать нам проявления наихудших симптомов.
Ссылки
- Общий список туториалов, расследований и документации ETW выложен здесь: https://tinyurl.com/etwcentral
- Туториал по CPU Usage (Sampled) (для поиска того, на что тратится время ЦП) находится здесь, а документация — здесь
- Туториал по CPU Usage (Precise) (для нахождения причин того, почему не могут выполняться потоки) находится здесь, а документация — здесь
- Ссылки на отдельные статьи приведены в теле поста, так же можно найти их в моей категории Investigate Reporting
- Другие байки об алгоритмах O(n2) можно почитать на Accidentally Quadratic
Обсуждение статьи на Reddit находится здесь, обсуждение на hacker news — здесь, тред в Twitter — здесь и, возможно, здесь

