Для выбора наиболее эффективного плана выполнения запроса PostgreSQL пользуется накопленной статистикой о распределении значений данных в целевых таблицах.
Она обновляется с помощью явного запуска команд ANALYZE и VACUUM ANALYZE или в фоновом режиме процессом autovacuum/autoanalyze. Но если статистика не успеет актуализироваться — может произойти беда.
Как такую проблему обнаружить и исправить?
Основной вариант, когда такая ситуация вообще может произойти, — если в таблице резко изменился набор данных. То есть по ней прогнали большое количество INSERT/UPDATE/DELETE или просто «влили» данные в пустую таблицу — например, при восстановлении из резервной копии.
В справке по штатной утилите восстановления pg_restore даже явно сказано:
Как выглядит ситуация «все плохо» именно из-за этого? Обычно примерно вот так:
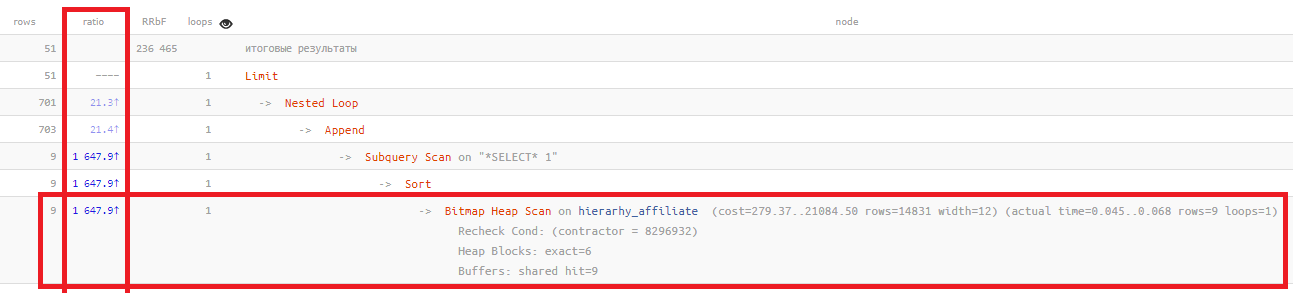
В столбце ratio как раз показывается отношение «в разах» между планировавшимся на основании статистики и фактически прочитанным количеством записей:
Чем больше это значение — тем хуже статистика отражает реальное положение дел в вашей таблице. В норме обычно оно не превышает сотни, в этом примере — полторы тысячи раз.
Приводит это к выбору неэффективного плана и, как следствие, дичайшей нагрузке на базу. Чтобы ее оперативно убрать, достаточно все-таки прислушаться к рекомендаци��м мануала и пройти ANALYZE по основным таблицам.
Вот так выглядит загрузка CPU на сервере базы до и после этой операции для примера выше:

Но что делать, если в таблице действительно меняется большое количество записей? Например, это какой-нибудь буфер или очередь обработки, куда постоянно добавляются новые записи и удаляются старые.
В этом случае нам помогут следующие конфигурационные параметры:
Иногда при настройке сервера autovacuum_naptime «удавливают» до «раз в сутки» (1d), чтобы autoVACUUM'ы ходили по базе пореже и ресурсов ели поменьше.
Иногда, хоть и очень редко, это даже бывает оправдано — например, если у вас в одной БД находятся тысячи таблиц/секций (даже, если они разложены по разным схемам).
Потому что само определение, какие конкретно таблицы из всего перечня надо обработать, при инициализации autovacuum-процесса может занимать солидную долю ресурсов и подтормаживать сервер.
Как раз в этом случае вас и будут ждать проблемы с часто изменяемой таблицей.
Тут — или все-таки выставлять более адекватный интервал запуска, или гонять ANALYZE по такой таблице в «ручном» режиме по каким-то прикладным соображениям (например, по внешнему таймеру или после окончания очередного этапа обработки очереди).
Товарищ, бди актуальность статистики!
Она обновляется с помощью явного запуска команд ANALYZE и VACUUM ANALYZE или в фоновом режиме процессом autovacuum/autoanalyze. Но если статистика не успеет актуализироваться — может произойти беда.
Как такую проблему обнаружить и исправить?
Основной вариант, когда такая ситуация вообще может произойти, — если в таблице резко изменился набор данных. То есть по ней прогнали большое количество INSERT/UPDATE/DELETE или просто «влили» данные в пустую таблицу — например, при восстановлении из резервной копии.
В справке по штатной утилите восстановления pg_restore даже явно сказано:
После восстановления имеет смысл запустить ANALYZE для каждой восстановленной таблицы, чтобы оптимизатор получил актуальную статистику.Поэтому если вы делаете с базой что-то похожее — не поленитесь, сразу прогоните ANALYZE по наиболее «жирным» таблицам или по всей базе целиком.
Определяем наличие проблемы
Как выглядит ситуация «все плохо» именно из-за этого? Обычно примерно вот так:
В столбце ratio как раз показывается отношение «в разах» между планировавшимся на основании статистики и фактически прочитанным количеством записей:
Bitmap Heap Scan on ... (... rows=14831 ...) (actual ... rows=9 ...)
Чем больше это значение — тем хуже статистика отражает реальное положение дел в вашей таблице. В норме обычно оно не превышает сотни, в этом примере — полторы тысячи раз.
Приводит это к выбору неэффективного плана и, как следствие, дичайшей нагрузке на базу. Чтобы ее оперативно убрать, достаточно все-таки прислушаться к рекомендаци��м мануала и пройти ANALYZE по основным таблицам.
Вот так выглядит загрузка CPU на сервере базы до и после этой операции для примера выше:
Часто обновляемая таблица
Но что делать, если в таблице действительно меняется большое количество записей? Например, это какой-нибудь буфер или очередь обработки, куда постоянно добавляются новые записи и удаляются старые.
В этом случае нам помогут следующие конфигурационные параметры:
autovacuum_naptime (integer)
Задаёт минимальную задержку между двумя запусками автоочистки для отдельной базы данных. Демон автоочистки проверяет базу данных через заданный интервал времени и выдаёт команды VACUUM и ANALYZE, когда это требуется для таблиц этой базы. Если это значение задаётся без единиц измерения, оно считается заданным в секундах. По умолчанию задержка равна одной минуте (1min). Этот параметр можно задать только в postgresql.conf или в командной строке при запуске сервера.
autovacuum_analyze_threshold (integer)
Задаёт минимальное число добавленных, изменённых или удалённых кортежей, при котором будет выполняться ANALYZE для отдельно взятой таблицы. Значение по умолчанию — 50 кортежей. Этот параметр можно задать только в postgresql.conf или в командной строке при запуске сервера. Однако данное значение можно переопределить для избранных таблиц, изменив их параметры хранения.
autovacuum_analyze_scale_factor (floating point)
Задаёт процент от размера таблицы, который будет добавляться к autovacuum_analyze_threshold при выборе порога срабатывания команды ANALYZE. Значение по умолчанию — 0.1 (10% от размера таблицы). Задать этот параметр можно только в postgresql.conf или в командной строке при запуске сервера. Однако данное значение можно переопределить для избранных таблиц, изменив их параметры хранения.
ССЗБ
Иногда при настройке сервера autovacuum_naptime «удавливают» до «раз в сутки» (1d), чтобы autoVACUUM'ы ходили по базе пореже и ресурсов ели поменьше.
Иногда, хоть и очень редко, это даже бывает оправдано — например, если у вас в одной БД находятся тысячи таблиц/секций (даже, если они разложены по разным схемам).
Потому что само определение, какие конкретно таблицы из всего перечня надо обработать, при инициализации autovacuum-процесса может занимать солидную долю ресурсов и подтормаживать сервер.
Как раз в этом случае вас и будут ждать проблемы с часто изменяемой таблицей.
Тут — или все-таки выставлять более адекватный интервал запуска, или гонять ANALYZE по такой таблице в «ручном» режиме по каким-то прикладным соображениям (например, по внешнему таймеру или после окончания очередного этапа обработки очереди).
Товарищ, бди актуальность статистики!

