Язык Python лежит в основе всемирно известных приложений, таких как Youtube, Instagram и Pinterest. Для продвижения на мировом рынке приложению необходима локализация, то есть адаптация к особенностям той или иной страны, и интернационализация – перевод контента. В статье мы поделимся опытом, как ускорить автоматизацию перевода и решить некоторые типичные проблемы в этой области.

Это краткое руководство по интернационализации (i18n) python-приложений. Данное руководство будет интересно всем программистам с опытом разработки на python. Чтение статьи займёт 10-15 минут.
Мы будем пользоваться хорошо протестированным и входящим в состав языка python инструментом gettext.
Для начала разберемся, что такое интернационализация:
Интернационализация (I18N) – это процесс адаптации приложения к языкам различных стран и регионов, отличных от того, в котором оно разрабатывалось.
Но также есть более широкое понятие:
Локализация (L10N) – это процесс адаптации интернационализированного приложения для конкретного региона или языка путем добавления компонентов, специфичных для данной локали и перевода текста.
Локализация означает перевод:

Локализация выходит за рамки перевода контента на другой язык. Есть культурные и функциональные параметры, которые также требуют внимания. Например, формат даты в Северной Америке «ММ / ДД / ГГГГ», но в большинстве стран Азии он записывается как «ДД / ММ / ГГГГ».
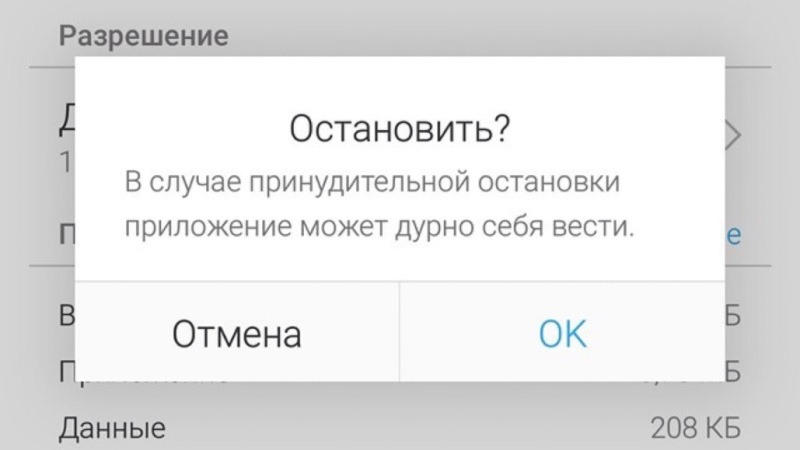
Известный пример ошибки при переводе приложения
Другой пример связан с отображением имен в приложениях. В США называть кого-то по имени приемлемо и даже предпочтительно, имя клиента отображается в заголовке, как только клиент входит в систему. Однако, в Японии всё наоборот: называть кого-то по имени является невежливым или даже оскорбительным. Локализация должна учитывать это и избегать использования имен для японской аудитории.
В данной статье мы рассмотрим только интернационализацию, но механизмы локализации строятся похожим образом. Затронутые в статье библиотеки поддерживают локализацию приложения.
Интернационализация разделяется на:
Для того, чтобы наша интернационализация работала, нам необходимо разобраться с библиотекой babel и инструментарием distutils для управления сборкой проекта для прода и не только.
Начнем с того, что нам необходимо сформировать список переводов. Для начала устанавливаем библиотеку Babel – это общепризнанная python-библиотека для локализации и конвертации даты, валюты, с удобными дополнениями для сборки проекта (рассмотренных ниже).
Python предоставляет инструментарий для мультиязычности – gettext. GNU gettext фактически является универсальным решением по локализации, предоставляющим поддержку для других языков программирования в мультиязычных сообщениях. Gettext используется не только во многих языках программирования, но и в переводе операционных систем, это хорошо протестированное, свободно распространяемое ПО, доступное на github.
Чтобы переводы функционировали, необходимо импортировать модуль gettext и передать на вход скрипты с переводами. Для начала помечаем все переводимые строки специальной функцией _(‘some_text’). Вызов этой функции в проекте будет выглядеть так:
В небольшом фрагменте кода создаём объект интернационализации, который использует каталог ‘locales’ в качестве источника переводимых фраз. Каталог ‘locales’ еще не создан, но именно в нем приложение будет искать переводы во время выполнения.
Для краткости функцию translate.gettext далее будем обозначать в виде _. Подчеркивание является обычным именем этой функции, которое признано сообществом Python.
Функция _() помечает строки, которые нужно перевести. Gettext-модуль сопровождается инструментом xgettext, который разбирает строковые маркеры _() по коду и формирует Portable Object Template (pot-файл). Чтобы создать pot-файл, вернемся к установленной библиотеке Babel, в которой есть множество функций для поддержки интернационализации. Babel расширяет setup.py скрипт для сборки, который можно написать либо с помощью стандартной библиотеки python distutils, либо сторонним пакетом setuptools – на ваш выбор. Сборка модулей Python выходит за рамки нашей статьи, подробнее ознакомиться с этим вопросом можно в документации. Всё, что нужно – создать setup.py файл со следующим содержимым:
Таким образом, мы создали инструкции для сборки проекта и добавили четыре команды по интернационализации из библиотеки babel. Рассмотрим эти команды подробнее в порядке очередности использования.
extract_messages
Эта команда является оберткой над инструментом GNU xgettext, который разбирает _() переводимые метки в pot-файл. Для запуска необходимо несколько настроек для сборки. Для этого в корневой директории создаём файл setup.cfg с содержимым:
Для запуска команды выполняем в консоли:
В pot-файле помеченные строки собираются в список, из которого затем переводчики смогут создать переводы для каждого из желаемых языков.
Далее необходимо сформировать переводы для нескольких языков. Для этого используем следующие команды babel.
init_catalog
Эта команда – обертка над инструментом GNU msginit, который создаёт новый каталог переводов, основанный на pot-файле.
Важно! Файлы локализации хранятся по определенному пути, в соответствии с конвенцией:
locales//LC_MESSAGES/.po
– директория с переводами на определенный язык, в нашем случае это английский (en). Также здесь может быть директория с переводами не только на определенный язык, но и с учетом дополнительных особенностей. Например, перевод на английский язык для США – en_US;
– домен с переводами. Если наше приложение разрастется, переводы будут разделены по доменам, чтобы не перегружать один файл.
update_catalog
Эта команда – обертка над инструментом GNU msgmerge, который обновляет существующие каталоги с переводами для *.po-файлов.
При добавлении новых переводов просто запускаем команду:
Также мы можем указать локализацию на русский, указав ru вместо en.
compile_catalog
Заключительная команда – обертка над инструментом GNU msgfmt. Она берет переводимые сообщения из *.po файлов и компилирует их в бинарные *.mo файлы для оптимизации работы.
--directory – путь к директории с локализацией,
--domain – флаг для указания домена переводов, указываем в соответствии с существующими доменами приложения.
Скрипты Python работают только с оптимизированными *.mo переводами. Поэтому при любом изменении, чтобы оно отобразилось в приложении, необходимо перекомпилировать файлы с локализацией. Для работы с файлами переводов можно воспользоваться приложением poedit – оно доступно для всех операционных систем и является свободно распространяемым ПО.

poedit — приложение для работы с переводами
Каждый перевод отображается отдельной строкой, и это удобно. По завершении работы с переводами при сохранении изменений автоматически компилируется *.mo бинарный файл со всеми изменениями.
В итоге структура каталогов переводов у нас будет выглядеть следующим образом:
Конвенция названия маркеров переводов
po-файлы содержат текстовые переводы и объединены логически в файл с общим названием. Эти группы называются доменами. В приведенном выше примере есть только один домен с именем base. В больших приложениях доменов будет больше, и списки переводов необходимо писать с учетом структуры приложения.
Необходимо сохранять единообразие названий маркеров переводов, чтобы исключить дальнейшую путаницу в переводах. Например, у нас есть форма с сохранением данных пользователя на странице профиля пользователя:
profile.user_form.component.title: Данные пользователя
profile.user_form.component.save: Сохранить
profile.user_form.field.username: Имя пользователя
profile.user_form.field.password: Пароль
Деплой приложения
Для деплоя и развертывания приложения в docker – нужно выполнить компиляцию файлов переводов в бинарные файлы *.mo с помощью следующей команды:
Рекомендуем исключить файлы *.mo и *.pot файлы в .gitignore:
# Translations
*.mo
*.pot
C локализацией в шаблонизаторах всё немного проще. Рассмотрим наиболее популярный python-шаблонизатор – jinja. Для данного шаблонизатора уже реализована поддержка gettext-локализации через дополнения. Чтобы активировать дополнение, необходимо прописать в конструкторе Environment путь к модулю дополнения. Для мультиязычных платформ необходимо загрузить переводы один раз и добавить translation-объекты в Environment-объект при инициализации приложения:
Затем в шаблонах просто используем конструкции:
Рассмотрим варианты работы с переводами в наиболее распространённых реляционных базах. При этом стоит отметить, что реализация переводов и локализации для noSQL и newSQL баз схожая.
Примечание: мы не будем рассматривать случай, когда перевод для каждого языка хранится в отдельной колонке. Такая реализация влечет за собой ограничения при масштабировании и другие риски при дальнейшей поддержке приложения.
При таком подходе для каждого языка перевод на определенный язык в строках основывается на значении столбца, например language_code. Если в данной колонке стоит значение en, то все переводимые значения должны относиться к данной стране и региону.

Для описанной схемы данные в таблице должны выглядеть следующим образом:

Преимущества:
Недостаток:
Переводы на разные языки могут храниться в разных таблицах. Таким образом, вы не знаете, на сколько языков ваше приложение переведено полностью.
Данное решение подходит для приложений, от которых изначально не требуется полная интернационализация всех данных. Но есть возможность добавлять переводы для новых регионов по мере расширения бизнеса.
Запрос на получение данных будет следующим:
В данном подходе для каждой таблицы, требующей локализации, создаём таблицы с переводами.
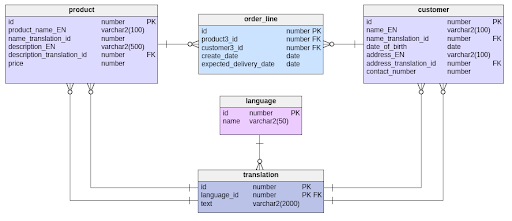
Плюсы:
Недостаток:
Запрос на получение данных будет следующим:
В этом решении таблицы сущностей, которые содержат одно или несколько переведенных полей, расширяют данные с непереведенными.
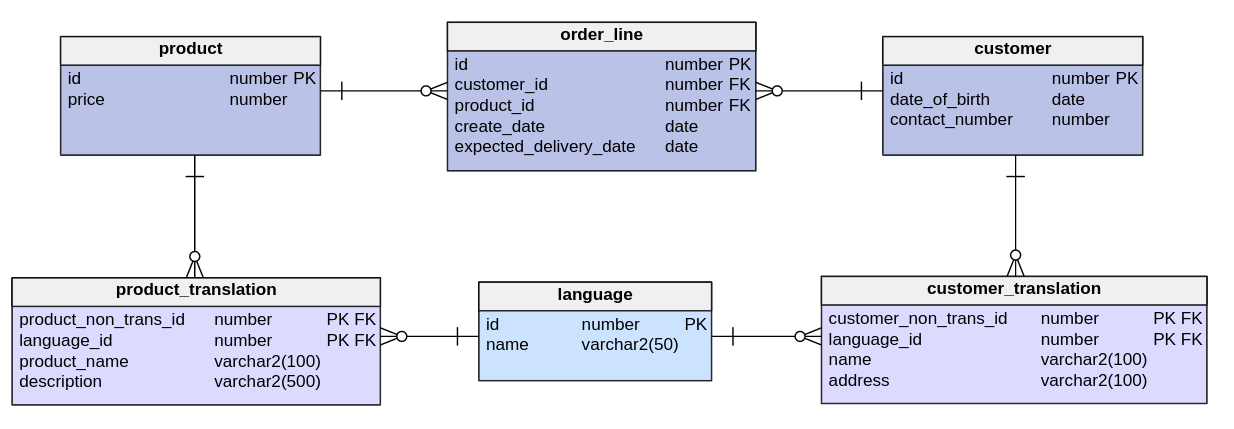
Плюсы:
Недостаток:
Вот пример запроса, который будет извлекать переведенный текст:
При локализации и интернационализации приложений для международного рынка можно использовать различные методы, каждый из которых имеет определенные особенности и ограничения.
В этой статье мы рассмотрели следующие виды интернационализации:
Надеемся, что наша статья поможет вам выбрать наиболее подходящий метод для вашего проекта.
Введение
Это краткое руководство по интернационализации (i18n) python-приложений. Данное руководство будет интересно всем программистам с опытом разработки на python. Чтение статьи займёт 10-15 минут.
Мы будем пользоваться хорошо протестированным и входящим в состав языка python инструментом gettext.
Для начала разберемся, что такое интернационализация:
Интернационализация (I18N) – это процесс адаптации приложения к языкам различных стран и регионов, отличных от того, в котором оно разрабатывалось.
Но также есть более широкое понятие:
Локализация (L10N) – это процесс адаптации интернационализированного приложения для конкретного региона или языка путем добавления компонентов, специфичных для данной локали и перевода текста.
Локализация означает перевод:
- формата даты и времени;
- числового формата;
- часового пояса;
- календаря;
- представления валюты;
- налогов / НДС;
- температуры и других мер;
- почтовых индексов, телефонов;
- форматирование адреса;
- кода населенного пункта.
Локализация выходит за рамки перевода контента на другой язык. Есть культурные и функциональные параметры, которые также требуют внимания. Например, формат даты в Северной Америке «ММ / ДД / ГГГГ», но в большинстве стран Азии он записывается как «ДД / ММ / ГГГГ».
Известный пример ошибки при переводе приложения
Другой пример связан с отображением имен в приложениях. В США называть кого-то по имени приемлемо и даже предпочтительно, имя клиента отображается в заголовке, как только клиент входит в систему. Однако, в Японии всё наоборот: называть кого-то по имени является невежливым или даже оскорбительным. Локализация должна учитывать это и избегать использования имен для японской аудитории.
В данной статье мы рассмотрим только интернационализацию, но механизмы локализации строятся похожим образом. Затронутые в статье библиотеки поддерживают локализацию приложения.
Основные виды
Интернационализация разделяется на:
- Перевод данных непосредственно в python-скриптах.
- Перевод данных в шаблонизаторах.
- Перевод данных, хранимых в базе данных.
1. Перевод данных python-скриптов
Для того, чтобы наша интернационализация работала, нам необходимо разобраться с библиотекой babel и инструментарием distutils для управления сборкой проекта для прода и не только.
Подготовка переводов
Начнем с того, что нам необходимо сформировать список переводов. Для начала устанавливаем библиотеку Babel – это общепризнанная python-библиотека для локализации и конвертации даты, валюты, с удобными дополнениями для сборки проекта (рассмотренных ниже).
Python предоставляет инструментарий для мультиязычности – gettext. GNU gettext фактически является универсальным решением по локализации, предоставляющим поддержку для других языков программирования в мультиязычных сообщениях. Gettext используется не только во многих языках программирования, но и в переводе операционных систем, это хорошо протестированное, свободно распространяемое ПО, доступное на github.
Чтобы переводы функционировали, необходимо импортировать модуль gettext и передать на вход скрипты с переводами. Для начала помечаем все переводимые строки специальной функцией _(‘some_text’). Вызов этой функции в проекте будет выглядеть так:
import gettext import os localedir = os.path.join(os.path.abspath('/path/to/locales'), 'locales') translate = gettext.translation('domain_name', localedir, ['ru']) _ = translate.gettext print(_('some_text')) print(_('some_text_2'))
В небольшом фрагменте кода создаём объект интернационализации, который использует каталог ‘locales’ в качестве источника переводимых фраз. Каталог ‘locales’ еще не создан, но именно в нем приложение будет искать переводы во время выполнения.
Для краткости функцию translate.gettext далее будем обозначать в виде _. Подчеркивание является обычным именем этой функции, которое признано сообществом Python.
Функция _() помечает строки, которые нужно перевести. Gettext-модуль сопровождается инструментом xgettext, который разбирает строковые маркеры _() по коду и формирует Portable Object Template (pot-файл). Чтобы создать pot-файл, вернемся к установленной библиотеке Babel, в которой есть множество функций для поддержки интернационализации. Babel расширяет setup.py скрипт для сборки, который можно написать либо с помощью стандартной библиотеки python distutils, либо сторонним пакетом setuptools – на ваш выбор. Сборка модулей Python выходит за рамки нашей статьи, подробнее ознакомиться с этим вопросом можно в документации. Всё, что нужно – создать setup.py файл со следующим содержимым:
from babel.messages import frontend as babel from distutils.core import setup setup(name='foo', version='1.0', cmdclass = {'extract_messages': babel.extract_messages, 'init_catalog': babel.init_catalog, 'update_catalog': babel.update_catalog, 'compile_catalog': babel.compile_catalog,} )
Таким образом, мы создали инструкции для сборки проекта и добавили четыре команды по интернационализации из библиотеки babel. Рассмотрим эти команды подробнее в порядке очередности использования.
extract_messages
Эта команда является оберткой над инструментом GNU xgettext, который разбирает _() переводимые метки в pot-файл. Для запуска необходимо несколько настроек для сборки. Для этого в корневой директории создаём файл setup.cfg с содержимым:
[extract_messages] input_dirs = foobar output_file = foobar/locales/messages.pot
- input_dirs – название директории, из которой будут выбираться все метки в коде _() для переводов.
- output_file – путь для результирующего .pot файла
Для запуска команды выполняем в консоли:
$ python setup.py extract_messages
running extract_messages extracting messages from foobar/__init__.py extracting messages from foobar/core.py ... writing PO template file to foobar/locales/messages.pot
В pot-файле помеченные строки собираются в список, из которого затем переводчики смогут создать переводы для каждого из желаемых языков.
# SOME DESCRIPTIVE TITLE. # Copyright (C) YEAR ORGANIZATION # FIRST AUTHOR <EMAIL@ADDRESS>, YEAR. # msgid "" msgstr "" "Project-Id-Version: PACKAGE VERSION\n" "POT-Creation-Date: 2018-01-28 16:47+0000\n" "PO-Revision-Date: YEAR-MO-DA HO:MI+ZONE\n" "Last-Translator: FULL NAME <EMAIL@ADDRESS>\n" "Language-Team: LANGUAGE <LL@li.org>\n" "MIME-Version: 1.0\n" "Content-Type: text/plain; charset=UTF-8\n" "Content-Transfer-Encoding: 8bit\n" "Generated-By: pygettext.py 1.5\n" #: src/main.py:5 msgid "some_text" msgstr "" #: src/main.py:6 msgid "some_text_2" msgstr ""
Далее необходимо сформировать переводы для нескольких языков. Для этого используем следующие команды babel.
init_catalog
Эта команда – обертка над инструментом GNU msginit, который создаёт новый каталог переводов, основанный на pot-файле.
$ python setup.py init_catalog -l en -i foobar/locales/messages.pot \ -o foobar/locales/en/LC_MESSAGES/base.po
running init_catalog creating catalog 'foobar/locales/en/LC_MESSAGES/messages.po' based on 'foobar/locales/messages.pot'
Важно! Файлы локализации хранятся по определенному пути, в соответствии с конвенцией:
locales//LC_MESSAGES/.po
– директория с переводами на определенный язык, в нашем случае это английский (en). Также здесь может быть директория с переводами не только на определенный язык, но и с учетом дополнительных особенностей. Например, перевод на английский язык для США – en_US;
– домен с переводами. Если наше приложение разрастется, переводы будут разделены по доменам, чтобы не перегружать один файл.
update_catalog
Эта команда – обертка над инструментом GNU msgmerge, который обновляет существующие каталоги с переводами для *.po-файлов.
При добавлении новых переводов просто запускаем команду:
$ python setup.py update_catalog -l en -i foobar/locales/messages.pot \ -o foobar/locales/en/LC_MESSAGES/base.po
running update_catalog updating catalog 'foobar/locales/en/LC_MESSAGES/base.po' based on 'foobar/locales/messages.pot'
Также мы можем указать локализацию на русский, указав ru вместо en.
compile_catalog
Заключительная команда – обертка над инструментом GNU msgfmt. Она берет переводимые сообщения из *.po файлов и компилирует их в бинарные *.mo файлы для оптимизации работы.
$ python setup.py compile_catalog --directory foobar/locales --domain base
running compile_catalog compiling catalog to foobar/locales/en/LC_MESSAGES/base.mo
--directory – путь к директории с локализацией,
--domain – флаг для указания домена переводов, указываем в соответствии с существующими доменами приложения.
Скрипты Python работают только с оптимизированными *.mo переводами. Поэтому при любом изменении, чтобы оно отобразилось в приложении, необходимо перекомпилировать файлы с локализацией. Для работы с файлами переводов можно воспользоваться приложением poedit – оно доступно для всех операционных систем и является свободно распространяемым ПО.
poedit — приложение для работы с переводами
Каждый перевод отображается отдельной строкой, и это удобно. По завершении работы с переводами при сохранении изменений автоматически компилируется *.mo бинарный файл со всеми изменениями.
В итоге структура каталогов переводов у нас будет выглядеть следующим образом:
locales ├── en │ └── LC_MESSAGES │ ├── base.mo │ └── base.po ├── ru │ └── LC_MESSAGES │ ├── base.mo │ └── base.po └── messages.pot
Конвенция названия маркеров переводов
po-файлы содержат текстовые переводы и объединены логически в файл с общим названием. Эти группы называются доменами. В приведенном выше примере есть только один домен с именем base. В больших приложениях доменов будет больше, и списки переводов необходимо писать с учетом структуры приложения.
Необходимо сохранять единообразие названий маркеров переводов, чтобы исключить дальнейшую путаницу в переводах. Например, у нас есть форма с сохранением данных пользователя на странице профиля пользователя:
profile.user_form.component.title: Данные пользователя
profile.user_form.component.save: Сохранить
profile.user_form.field.username: Имя пользователя
profile.user_form.field.password: Пароль
Деплой приложения
Для деплоя и развертывания приложения в docker – нужно выполнить компиляцию файлов переводов в бинарные файлы *.mo с помощью следующей команды:
$ python setup.py compile_catalog --domain <домен>
Рекомендуем исключить файлы *.mo и *.pot файлы в .gitignore:
# Translations
*.mo
*.pot
2. Перевод данных в шаблонизаторах
C локализацией в шаблонизаторах всё немного проще. Рассмотрим наиболее популярный python-шаблонизатор – jinja. Для данного шаблонизатора уже реализована поддержка gettext-локализации через дополнения. Чтобы активировать дополнение, необходимо прописать в конструкторе Environment путь к модулю дополнения. Для мультиязычных платформ необходимо загрузить переводы один раз и добавить translation-объекты в Environment-объект при инициализации приложения:
translations = get_gettext_translations() env = Environment(extensions=['jinja2.ext.i18n']) env.install_gettext_translations(translations)
Затем в шаблонах просто используем конструкции:
{{ gettext('some_text') }} {{ gettext('Hello %(name)s!')|format(name='World') }}
3. Перевод данных, хранимых в базе
Рассмотрим варианты работы с переводами в наиболее распространённых реляционных базах. При этом стоит отметить, что реализация переводов и локализации для noSQL и newSQL баз схожая.
Примечание: мы не будем рассматривать случай, когда перевод для каждого языка хранится в отдельной колонке. Такая реализация влечет за собой ограничения при масштабировании и другие риски при дальнейшей поддержке приложения.
1) Отдельные строки для каждого языка
При таком подходе для каждого языка перевод на определенный язык в строках основывается на значении столбца, например language_code. Если в данной колонке стоит значение en, то все переводимые значения должны относиться к данной стране и региону.
Для описанной схемы данные в таблице должны выглядеть следующим образом:
Преимущества:
- Простая и эффективная реализация.
- Простые запросы при использовании определенного языкового кода.
Недостаток:
- Отсутствие централизации
Переводы на разные языки могут храниться в разных таблицах. Таким образом, вы не знаете, на сколько языков ваше приложение переведено полностью.
Данное решение подходит для приложений, от которых изначально не требуется полная интернационализация всех данных. Но есть возможность добавлять переводы для новых регионов по мере расширения бизнеса.
Запрос на получение данных будет следующим:
SELECT p.product_name, p.price, p.description FROM product p WHERE p.language_code = @language_code;
2) Отдельные таблицы с переводами
В данном подходе для каждой таблицы, требующей локализации, создаём таблицы с переводами.
Плюсы:
- Нет необходимости объединять таблицы для непереведенных данных.
- Запросы становятся легкими, поскольку есть отдельные таблицы для перевода.
- Нет расхождений в данных.
- Помимо переводов, есть возможность эффективно локализовать остальные данные в языковой таблице.
Недостаток:
- В больших приложениях таблица translation раздувается и замедляет работу. При оптимизации приложения необходимо будет реализовать миграции данных по отдельным таблицам.
Запрос на получение данных будет следующим:
SELECT tp.text, p.price, tc.text, c.contact_name FROM order_line o, product p, customer c, translation tp, translation tc, language l WHERE o.product_id = p.id AND o.customer_id = c.id AND p.name_translation_id = tp.id AND c.name_translation_id = tc.id AND tp.language_id = l.id AND tc.language_id = l.id AND l.name = @language_code AND o.id = ***;
3) Создание сущностей для переводимых и непереводимых полей
В этом решении таблицы сущностей, которые содержат одно или несколько переведенных полей, расширяют данные с непереведенными.
Плюсы:
- Нет необходимости объединять таблицы перевода с таблицами, в которых содержатся данные, не требующие перевода. Поэтому выборка таких данных будет иметь лучшую производительность,
- Легко писать запросы на ORM,
- Простой SQL-запрос для получения переведенного текста,
- Просто поддерживать перевод определенных данных на все доступные языки.
Недостаток:
- Относительная сложность реализации.
Вот пример запроса, который будет извлекать переведенный текст:
SELECT pt.product_name, pt.description, p.price FROM order_line o, product p, product_translation pt, language l WHERE o.product_id = p.id AND AND p.id = pt.product_non_trans_id AND pt.language_id = l.id AND l.name = @language_code;
Выводы
При локализации и интернационализации приложений для международного рынка можно использовать различные методы, каждый из которых имеет определенные особенности и ограничения.
В этой статье мы рассмотрели следующие виды интернационализации:
- в коде: используем переводы при создании сервиса или приложения с gui;
- в шаблонах: используем при разработке web-приложения без динамического фронтэнда;
- в базе данных: используем при хранении либо пользовательских, либо динамически генерируемых данных.
Надеемся, что наша статья поможет вам выбрать наиболее подходящий метод для вашего проекта.

