На днях заинтересовался тем, как работает Python Memory Management в CPython для Python3
Немного теории
В системной библиотеке glibc есть аллокатор malloc. У каждого процесса есть область памяти, называемая кучей. Выделяя память динамически вызовом функции malloc, мы получаем чанк из кучи этого процесса. Если размер запрашиваемой памяти небольшой (не более 128KB), то память может браться из списков свободных чанок. Если это невозможно, то память выделится системным вызовом mmap
Информация взята из лекции по аллокаторам в Си.
У CPython есть свой аллокатор (PyMalloc) для «приватной кучи» и аллокаторы для каждого типа объектов, которые работают «поверх» первого. PyMalloc запрашивает чанки памяти по 256KB через malloc в библиотеке операционной системы, которые называются Аренами. Они же в свою очередь разделяются на Пулы по 4KB. Каждый Пул делится на Чанки фиксированного размера, и каждый может быть поделен на Чанки одного из 64 размеров.
Аллокаторы для каждого типа пользуются уже выделенными Чанками при их наличии. Если таковых нет, PyMalloc выдаёт новый Пул из первой Арены, в которой найдётся место для нового Пула (Арены «отсортированы» по убыванию заполненности). Если и это не срабатывает, то PyMalloc запрашивает у ОС новую Арену. Кроме случая, когда размер запрашиваемой памяти более 512B, тогда память напрямую выделяется через malloc из системной библиотеки.
При удалении объекта, память не возвращается ОС, а просто Чанки возвращаются в соответствующие Пулы, а Пулы — в Арены. Арена возвращается операционной системе, когда все Чанки из неё освобождаются. Из чего получается, что, если в Арене будет использоваться относительно небольшое количество Чанок, то всё равно вся память в Арене будет использоваться PVM. Но так как, чанки более 128KB выделяются через mmap, то свободная Арена сразу вернётся операционной системе.
Хотелось бы акцентировать внимание на двух моментах:
- Выходит, что PyMalloc выделяет 256KB физической памяти при создании новой Арены.
- Операционной системе возвращаются только свободные Арены.
Пример
Рассмотрим следующий пример:
iterations = 2000000 l = [] for i in range(iterations): l.append(None) for i in range(iterations): l[i] = {} s = [] # [1] # s = l[::2] # [2] # s = l[2000000 // 2::] # [3] # s = l[::100] # [4] for i in range(iterations): l[i] = None for i in range(iterations): l[i] = {}
В примере создаётся список l из 2-х миллионов элементов, все из которых указывают на один объект None. В следующем цикле для каждого элемента создаётся объект — пустой словарь. После чего создаётся второй список s, элементы которого указывают на некоторые объекты, на которые ссылаются некоторые элементы первого списка. После очередного обхода элементы из списка l снова начинают указывать на объект None. И в последнем цикле опять создаются словари для каждого элемента из первого списка.
Варианты списков s:
s = []s = l[::2]s = l[200000 // 2::]s = l[::100]
Нас интересует потребление памяти в каждом из случаев.
Будем запускать данный скрипт с включенным логированием PyMalloc:
export PYTHONMALLOCSTATS="True" && python3 source.py 2>result.txt
Пояснения к результатам
На картинках можно увидеть потребление памяти в каждом из случаев. По оси абсцисс нет соотнесения значений с временем, когда такие потребления имели место быть, просто каждому значению в логах сопоставлен его порядковый номер.
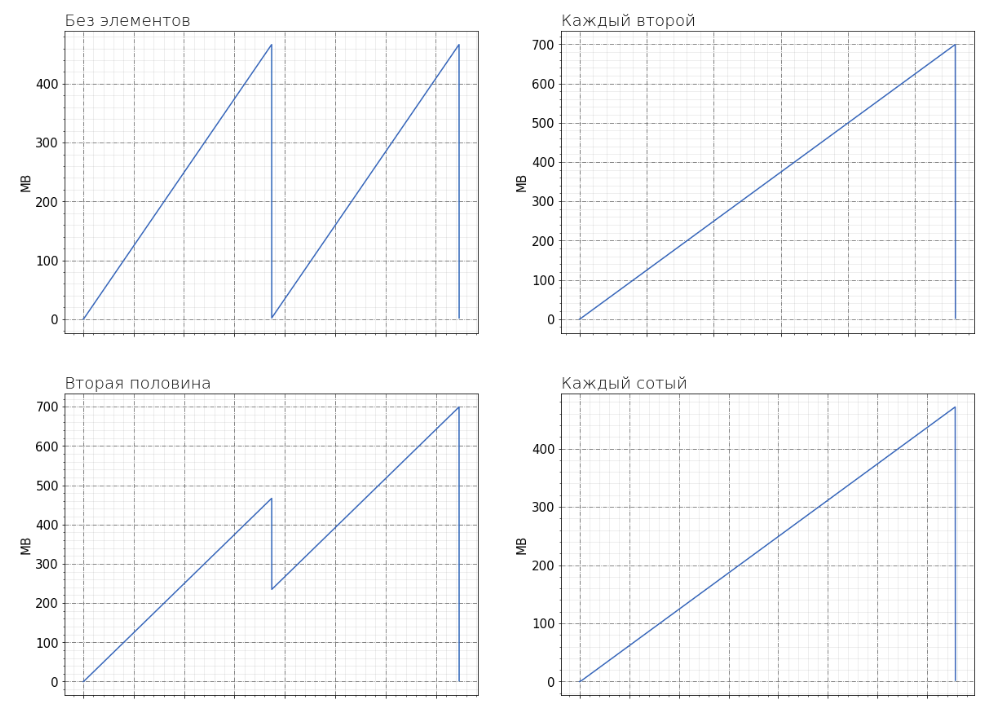
«Без элементов»
В первом случае список s пустой. После создания объектов во втором цикле потребляется примерно 500MB памяти. И все эти объекты удаляются в третьем цикле, а используемая память возвращается операционной системе. В последнем цикле память для объектов выделяется заново, что приводит к потреблению всё тех же 500MB.
«Каждый второй»
В случае, когда мы создаём список с каждым вторым элементом списка l, можно заметить, что память не возвращается операционной системе. То есть в данном случае мы наблюдаем ситуацию, когда удаляются словари примерно на 250MB, но в каждом Пуле остаются Чанки, которые не удаляются, из-за чего соответствующие Арены не освобождаются. Но, когда мы создаём словари во второй раз, свободные Чанки из этих Пулов используются повторно, из-за чего выделяется только около 250MB новой памяти.
«Вторая половина»
В случае, когда мы создаём список из второй половины элементов списка l, то первая половина находится в отдельных Аренах, из-за чего примерно 250MB памяти возвращается операционной системе. После чего выделяется заново примерно 500MB на новые словари, из-за чего суммарное потребление в районе 750MB.
В таком случае в отличие от второго память частично возвращается операционной системе. Что с одной стороны позволяет другим процессам использовать эту память, с другой требует системных вызовов на её освобождение и повторное выделение.
«Каждый сотый»
Самым же интересным представляется последний случай. Там мы создаём второй список из каждого сотого элемента первого списка, что требует примерно 5MB. Но из-за того, что в каждой Арене остаётся некоторое количество занятых Чанок, эта память не освобождается, и потребление остаётся на уровне 500MB. Когда же мы создаём словари во второй раз, то новой памяти почти не выделяется, а переиспользуются те Чанки, что были выделены в первый раз.
В данной ситуации из-за фрагментирования памяти мы используем в 100 раз больше, чем нам нужно. Но, когда эта память требуется повторно, нам не приходится делать системных вызовов, чтобы её аллоцировать.
Итог
Стоит отметить, что фрагментация памяти возможна при использовании многих аллокаторов. Но тем не менее, нужно осторожно использовать некоторые структуры данных, например те, которые имеют древовидную структуру, такие как деревья поиска. Потому что произвольные операции добавления и удаления могут привести к такой ситуации, изложенной выше, из-за чего целесообразность использования оных структур в плане потребляемой памяти будет под сомнением.
Код для отрисовки картинок
def parse_result(filename): ms = [] with open(filename, "r") as f: for line in f: if line.startswith("Total"): m = float(line.split()[-1].replace(",", "")) / 1024 / 1024 ms.append(m) return ms ms_1 = parse_result("_1.txt") ms_2 = parse_result("_2.txt") ms_3 = parse_result("_3.txt") ms_4 = parse_result("_4.txt") import matplotlib.pyplot as plt plt.figure(figsize=(20, 15)) fontdict = { "fontsize": 20, "fontweight" : 1, } plt.subplot(2, 2, 1) plt.title("Без элементов", fontdict=fontdict, loc="left") plt.plot(ms_1) plt.grid(b=True, which='major', color='#666666', linestyle='-.') plt.minorticks_on() plt.grid(b=True, which='minor', color='#999999', linestyle='-', alpha=0.2) plt.tick_params(axis='both', which='major', labelsize=15, labelbottom=False) plt.ylabel("MB", fontsize=15) plt.subplot(2, 2, 2) plt.title("Каждый второй", fontdict=fontdict, loc="left") plt.plot(ms_2) plt.grid(b=True, which='major', color='#666666', linestyle='-.') plt.minorticks_on() plt.grid(b=True, which='minor', color='#999999', linestyle='-', alpha=0.2) plt.tick_params(axis='both', which='major', labelsize=15, labelbottom=False) plt.ylabel("MB", fontsize=15) plt.subplot(2, 2, 3) plt.title("Вторая половина", fontdict=fontdict, loc="left") plt.plot(ms_3) plt.grid(b=True, which='major', color='#666666', linestyle='-.') plt.minorticks_on() plt.grid(b=True, which='minor', color='#999999', linestyle='-', alpha=0.2) plt.tick_params(axis='both', which='major', labelsize=15, labelbottom=False) plt.ylabel("MB", fontsize=15) plt.subplot(2, 2, 4) plt.title("Каждый сотый", fontdict=fontdict, loc="left") plt.plot(ms_4) plt.grid(b=True, which='major', color='#666666', linestyle='-.') plt.minorticks_on() plt.grid(b=True, which='minor', color='#999999', linestyle='-', alpha=0.2) plt.tick_params(axis='both', which='major', labelsize=15, labelbottom=False) plt.ylabel("MB", fontsize=15)

