Всем привет! Меня зовут Денис Олейник, я работаю техническим директором в 1Service.
В нашей компании мы достаточно много времени уделяем работе с требованиями. По мере обретения опыта мы стали осознавать, что инструменты, обычно используемые при разработке программных продуктов, приводят нас к состоянию, когда мы не можем утверждать, что реализовали именно то, что хотел от нас заказчик. Именно потому, что в какой-то момент происходит отрыв (gap) первоначально собранных требований от их программной реализации и последующих тестов.

Грань эта находится где-то между требованиями, записанными в Confluence и задачами на их реализацию в Jira. Другая грань проходит между тест-кейсами в инструменте для тестирования и теми же требованиями в Confluence, с оглядкой на код привязанный к задачам в Jira. Отсутствие внятных ответов на вопросы: «зачем/почему мы это реализовали именно так» или «всё ли мы сделали, что хотел от нас заказчик» — вызывали у нас живое беспокойство.
И вот в какой-то момент нам показалось, что концепция «документация — это код» (documentation as code) позволит найти ответы на эти вопросы. Концепция «документация — это код» предполагает, что мы храним требования, архитектурные решения, пользовательские инструкции в виде простых текстовых файлов, которые поддаются версионированию посредством применения систем (D)VCS-класса, макеты входных-выходных данных в идеале также должны храниться в плоском текстовом виде. Реальные «читабельные» документы (так же как и исполняемые модули) будут появляться в результате сборки проекта. В этом случае техническая документация будет развиваться вместе с развитием всего проекта на единых принципах версионирования кода, что позволит ей удовлетворять критериям сквозной прослеживаемости, верифицируемости и актуальности. Также данный подход нативно решает задачу организации так называемых «основных версий требований» (baselines), которая для многих систем управления требованиями становится реальной проблемой. В частности, в Confluence эту задачу рекомендуется решать путём создания копии изначального пространства, в котором велись требования, при этом всякая связь и наследственность требований теряется. Собственно, полевым исследованиям данной концепции в нашей компании и посвящена эта статья.
Что на наш взгляд останавливает широкое применение этой концепции в массах — это убогость инструментария для наглядного представления и управления требованиями в плоском текстовом виде. Имеется в виду, что плоские текстовые файлы не покажешь Product Owner, чтобы он увидел в них Project Scope, текстовые файлы не выведешь на страничку презентации для стейкхолдеров, в них нет графиков, диаграмм и картинок на этапе редактирования — а это уже отвращает бизнес-аналитиков, которые по сути должны генерировать контент. И только разработчики довольны и кричат: «кул! только хардкор! больше коммитов!» и прочую ересь.
Есть ещё один достаточно тонкий момент. Апологеты концепции «документация — это код» почему-то уверены, что как только документация ляжет рядом с кодом в репозиторий — это приведёт к обязательной её адаптации и синхронизации с изменениями в коде, что позволит поддерживать её в актуальном состоянии (п. 1.2.1). Но на наш взгляд — этот момент так и останется вопросом дисциплины, ведь никто не мешает менять код, а документацию не менять. То есть актуальность документации при такой реализации концепции отдаётся на откуп менеджменту процесса разработки, где обязательным шагом перед релизом будет «проверять актуальность документации». В таком случае «документация — это код» недалеко уходит от вордовских файликов, если не учитывать некоторой автоматизации в вопросах компоновки результирующих документов.
Ну так вот да — во-первых, «неудобно, ненаглядно, сухо», во-вторых — технические фишки «прикрывают тряпочкой» проблему актуализации документации. Существует расхожий стереотип: «мы по аджайлу — а в аджайле документация не нужна!». Это мягко говоря не совсем так. Мне нравится опровергать это заблуждение, приводя сравнение подходов Use Case и User Story из отличной книжки Карла Вигерса «Разработка требований к ПО» [4]. Если мы относим подходы разработки, основанные на User Stories, к методике Agile, то Вигерс так формулирует эволюцию требований, основанных на User Stories:
Стало быть, для того чтобы поддержать реализацию концепции «документация — это код» в проектах гибкой разработки нужен инструмент, который позволит сопровождать эволюцию требований от формата User Story до приёмочных тестов, которые в результате своего удачного выполнения сгенерируют актуальную документацию. К сожалению, на сегодняшний день инструмента, который бы в полной мере поддерживал этот процесс (или хотя бы постулировал своё стремление его поддержать) не существует.
Итак, инструмента нет, а концепцию исследовать хочется. От безысходности нам пришлось его разработать. Если бы такой инструмент (назовём его условно StoryMapper) уже существовал, то какая бы у него была архитектура, чтобы ненавязчиво, с минимальным напряжением встроиться в уже существующую экосистему процесса разработки? Если это уже отстроенный процесс разработки, то в нём наверняка уже был бы запущен контур CI/CD, и несомненно использовалась бы система контроля версий, скорее всего git-based. В таком случае ниже приводится схема, на которой обозначено место StoryMapper в процессе разработки:

Рис. 1 Место инструмента StoryMapper в структуре процесса разработки
Таким образом, StoryMapper напрямую будет взаимодействовать с сервисами хостинга git-репозиториев и с контуром CI/CD. Интеграция с сервисами git-хостинга нужна, чтобы получить текущую коллекцию feature-файлов (если она имеется), а также поместить обратно в репозиторий результаты внесения изменений в feature-файлы, сервисные файлы, касающиеся структуризации документации, примеры входных-выходных данных и т. д. Взаимодействие с контуром CI/CD необходимо, чтобы иметь возможность запускать сборку сценарного тестирования (вручную или по расписанию), и для последующего получения результатов тестирования — чтобы соотнести их с с соответствующими feature-файлами (таким образом будет происходить верификация и проверка на актуальность документации).
Надо понимать, что StoryMapper едва ли должен претендовать на звание «yet another Gherkin-editor». Да, базовая возможность редактировать feature-файлы должна быть заложена, но мы отчётливо осознаём, что если BA или QA сделали свой выбор в пользу VSC, Sublime, Notepad++ или даже vi (почему нет?) — то переубедить их работать с требованиями только в StoryMapper задача не то чтобы неблагодарная, скорее некорректная. Поэтому мы предполагаем, что должна быть заложена возможность разнопланового использования StoryMapper, в частности: разработка фич в любимом редакторе, а StoryMapper используется для структурирования уже готовых feature-файлов. Подробнее об этом в разделе о направлениях исследования.
Поскольку StoryMapper на сегодняшний день находится в состоянии MVP, то вот те самые минимальные требования, которые мы к нему предъявляли, чтобы им можно было реально начать пользоваться:
Я не буду подробно останавливаться на функционале инструмента, поскольку тема данной статьи — это ход операции, а не скальпель хирурга.
Основная мысль такая: если применяя концепцию «документация — это код», не идти от требований заказчика, а писать какую-то произвольную документацию по мере написания кода, то такая документация умрёт и станет неактуальной также быстро, как и вариант с файликами в формате MS Word. Поэтому мы хотели продумать и исследовать вариант использования концепции применительно к полному циклу разработки. С другой стороны, нас интересовал и переходный момент, когда у команды не используется концепция «документация — это код», но есть желание её применять — как действовать в таком случае?
Итак, StoryMapper — это инструмент, он не регламентирует единственно верный вариант использования. Напротив, каждый потенциальный пользователь может увидеть свои варианты применения инструмента. Мы же сосредоточились на трёх основных направлениях:
Ниже я подробно опишу, каких результатов мы достигли по каждому направлению.
Данное направление предполагает разработку нового продукта или доработку уже существующего. Работы по этому направлению проходили под кодовым названием «BDDSM»: как объединение техники Story Mapping и методики разработки BDD. Так и прижилось.
Итак, для начала создаётся git-репозиторий для feature файлов, в нём выделяется ветка для взаимодействия со StoryMapper. В StoryMapper создаётся проект, его подключают бизнес-аналитикам, которые будут работать на проекте. Общаясь со стейкхолдерами, бизнес-аналитики начинают формировать общее видение продукта и закрепляют его в виде скелета карты пользовательских историй [1,2], сначала набросок первого уровня UF:

Рис. 6 Верхний уровень скелета карты пользовательских историй (кликабельно)
А потом постепенно наполняя и второй уровень пользовательских активностей:

Рис. 7 Второй уровень скелета карты пользовательских историй
Поскольку каждая карточка — это текстовый файл, то или на этапе сбора требований (если карта составляется по ходу общения с пользователем), или на этапе пост-обработки проведенных интервью результаты общения переносятся непосредственно в карточки UF и UA. Это является базой для дальнейшей декомпозиции требований до уровня пользовательский историй.

Рис. 8 Свободный текст с описанием требований, соответствующий синтаксису Gherkin, на уровне UF
Далее бизнес-аналитики осознают, каким образом декомпозировать пользовательские активности до пользовательских историй, и формируют в StoryMapper третий уровень карты — US. Выделение US сопряжено с формулировкой критериев приёмки, то есть если «ты как кто-то хочешь что-то», то как мы проверим постфактум, что ты это получил [3]. Критерии приёмки для начала могут также фиксироваться в US в виде плоского текста.
После того, как критерии приёмки устоялись и согласованы со стейкхолдерами, бизнес-аналитики оформляют их в виде сценариев на языке Gherkin. Фактически перед каждым критерием приёмки дописывается текст «Сценарий: КП-№», что превращает абстрактную доселе пользовательскую историю в feature-файл.

Рис. 8.1 Критерии приёмки пользовательской истории в виде сценариев на Gherkin
После этого каждый сценарий расшифровывается несколькими укрупнёнными шагами, которые раскрывают, как именно конкретный критерий приёмки будет проверяться. Далее эти шаги либо программируются разработчиками, либо набираются из библиотеки шагов используемого фреймворка Gherkin и выносятся в экспортные сценарии.
Параллельно с этим организуется тестовый стенд, на котором сервер сборок будет прогонять функциональные тесты и до поры ждать, когда будут готовы US со сценариями. По мере готовности продукта и сценариев, реализующих критерии приёмки, сервер сборок начинает выдавать отчёты в формате Allure и Cucumber и отправлять их в StoryMapper, который в свою очередь проецирует результат сборки в формате Cucumber на карту пользовательских историй:

Рис. 9 Карта пользовательских историй с результатами выполнения сценариев
При этом StoryMapper обеспечивает три уровня понимания готовности продукта: UF — это верхний уровень, который показывает количество правильно работающих сценариев (удовлетворяющих критериям приёмки), работающих с ошибками, и ещё неготовых. То есть фактически верхний уровень является индикатором готовности продукта и показателем того, сколько ещё осталось сделать (это уровень product owner). Нижние уровни позволяют разобраться с тем, в каких именно пользовательских активностях есть трудности, и куда нужно приложить усилия, чтобы приблизить продукт к завершению (это уровень скрам-мастеров в большей степени и product owner в меньшей). Нижний уровень US — это уровень, на котором взаимодействуют бизнес-аналитики, разработчики и QA, совместными усилиями разрабатывая именно тот продукт, который от них ожидают стейкхолдеры.
Также в одном из завершающих шагов сборочной линии производится создание автодокументации. Подробнее об этом можно почитать у коллег. Это не единственный вариант, мы планируем подключить в наш инструмент пакет Pickles — стандарт де-факто в мире «живой документации».
Работая в этом направлении, мы рассматривали такой кейс. Команда разработчиков на волне хайпа вокруг темы BDD, функционального тестирования и промышленных стандартов разработки взялась писать feature-файлы. И прорываясь сквозь тернии, накопила в репозитории достаточно большую коллекцию. Однако, когда у тебя в коллекции 10 файлов — то отчёт в формате Allure ещё даёт какую-то достоверную картину состояния продукта. Но если количество feature-файлов измеряется десятками, а иногда и сотнями, то рано или поздно тебе захочется их как-то структурировать. Первое, что приходит в голову — это разложить их по тематическим папочками. А по каким? По стейкхолдерам, по метаданным, по подсистемам? Это далеко не праздные вопросы. А если потом окажется, что feature-файлы писались изначально как Бог на душу положит, и в нём есть сценарии относящиеся сразу к нескольким папкам, то тогда как?
Итак, данный вариант использования предполагает желание навести порядок в своей документации, чтобы из состояния «фичи отдельно, документация отдельно» перейти к «документации — это код». Когда такой репозиторий подключается в StoryMapper, то все feature-файлы попадают в первую колонку под UF0 и UA0. Следующий шаг в деле структурирования — это составление скелета структуры. В StoryMapper — это всё те же UF и UA, но никто не настаивает на рассмотрении их только в таком ракурсе. Их можно рассматривать просто как 2 уровня иерархии, под которыми существует возможность разместить до того неструктурированные feature-файлы. После того, как структура задана, feature-файлы из первой колонки растаскиваются под соответствующие UA. Несомненно этот процесс вызывает приступ рефлексии и рефакторинга фич, потому что по мере перетаскивания становится понятной вся та глубина хаоса, которая имела место быть в ходе их первоначального написания. Иногда достаточно перенести сценарий из одного файла в другой, иногда разбить один большой файл на несколько, чтобы восстановить семантическую связность, а иногда и просто выбросить на помойку, потому что в репозитории завалялись древние неисполняемые рукописи.
Если сборочная линия уже была настроена (ну а раз репозиторий feature-файлов есть, то они должны где-то собираться), то в ней нужно добавить шаг по отправке результатов сборки в StoryMapper. В конечном результате будет получена последняя картинка из предыдущего раздела (рис. 9): структурированные feature-файлы с отметками о результатах выполнения их сценариев.
Как пользоваться такой картинкой? Её можно показывать руководящему составу, с тем чтобы отчитываться о результатах работы команды и демонстрировать степень готовности/качества продукта. Может использоваться командой при проведении ретроспективы, чтобы подкорректировать DoD либо ещё как-то подкорректировать процесс. Может использоваться при грумминге бэклога, но это уже требует работы по сценарию, описанному в предыдущем разделе, когда после первичного структурирования требований дальнейшая разработка будет вестись полным циклом посредством (или хотя бы с учётом) StoryMapper.
Ещё один побочный вариант использования, который прижился в нашей практике. На самом деле, это современная и модная тема — тестировать прямо в продуктиве, почему нет. Ведь ошибки нет-нет да и проберутся. Особенно это актуально становится в том случае, если IT-деятельность не является профильной для компании и разработка вынесена на outsource, в частности — это интернет-магазины малой и средней руки.
Как мы себе это видим. Простой вариант: из множества функциональных тестов выделяется некое подмножество немодифицирующих базу данных тестов, проверяющих фронтенд. Второй вариант: выделяются сценарии, проверяющие бизнес-логику, при этом сессия, в которой стартует проверка, запускается в тестовом спец-режиме, где модификация данных не отражается на базе данных, не портит статистику и не участвует в обмене с учётными системами. Когда этот набор сценариев составлен, он подвязывается к расписанию и с заданной периодичностью выполняется непосредственно на продуктиве. Результат выполнения всё также отражается в StoryMapper и Allure, но важнее то, что если в этом тестовом наборе будут ошибки — то заинтересованные в бизнесе лица будут получать уведомление на почту, и таким образом, в онлайне смогут ориентироваться в том, как очередной релиз его поставщиков IT-услуг ломает его основной инструмент ведения бизнеса.
Если в шаги сценариев заложить проверку длительности их выполнения, и в случае нарушения контрольного времени останавливать выполнения сценариев с ошибкой, то данные сценарии будут отражать нефункциональные требования по быстродействию. Соответственно, если изменения в коде, повышение нагрузки, деградация производительности хостинга повлияли на быстродействие продукта, то человек финансово-заинтересованный в работоспособности будет об этом извещён.
Итак, для того чтобы организовать мониторинг продуктива, нужно подготовить:
Повторюсь, что на сегодняшний день StoryMapper находится в состоянии MVP. Тем не менее, он позволил провести «эксперименты на людях», которые, на мой взгляд, завершились более, чем успешно. Ну и на выходе, конечно же, пришёл тот самый «аппетит во время еды». Вот далеко неполный список того, что хотелось бы добавить в инструмент:
Я предвижу такой риск, что инструмент внутреннего использования может начать довлеть над методикой и концепцией, и мы станем заниматься самоедством и рефлексией вместо того, чтобы генерировать интересные идеи и совершенствовать процесс разработки. Поэтому в ближайшем будущем у нас в планах выдать доступ к инструменту ограниченным тиражом, чтобы вдохновиться обратной связью и пересмотреть те самые направления развития.
Я не ожидаю прям такого взрывного интереса к поднятым здесь темам (хотя термин хабраэффект мне знаком), поэтому если вдруг кому стало интересно и захотелось пощупать инструмент руками, пообщаться на тему эволюции и верификации требований (что более интересно!) — стучитесь к нам в telegram, договориться можно обо всём.
В нашей компании мы достаточно много времени уделяем работе с требованиями. По мере обретения опыта мы стали осознавать, что инструменты, обычно используемые при разработке программных продуктов, приводят нас к состоянию, когда мы не можем утверждать, что реализовали именно то, что хотел от нас заказчик. Именно потому, что в какой-то момент происходит отрыв (gap) первоначально собранных требований от их программной реализации и последующих тестов.
Грань эта находится где-то между требованиями, записанными в Confluence и задачами на их реализацию в Jira. Другая грань проходит между тест-кейсами в инструменте для тестирования и теми же требованиями в Confluence, с оглядкой на код привязанный к задачам в Jira. Отсутствие внятных ответов на вопросы: «зачем/почему мы это реализовали именно так» или «всё ли мы сделали, что хотел от нас заказчик» — вызывали у нас живое беспокойство.
И вот в какой-то момент нам показалось, что концепция «документация — это код» (documentation as code) позволит найти ответы на эти вопросы. Концепция «документация — это код» предполагает, что мы храним требования, архитектурные решения, пользовательские инструкции в виде простых текстовых файлов, которые поддаются версионированию посредством применения систем (D)VCS-класса, макеты входных-выходных данных в идеале также должны храниться в плоском текстовом виде. Реальные «читабельные» документы (так же как и исполняемые модули) будут появляться в результате сборки проекта. В этом случае техническая документация будет развиваться вместе с развитием всего проекта на единых принципах версионирования кода, что позволит ей удовлетворять критериям сквозной прослеживаемости, верифицируемости и актуальности. Также данный подход нативно решает задачу организации так называемых «основных версий требований» (baselines), которая для многих систем управления требованиями становится реальной проблемой. В частности, в Confluence эту задачу рекомендуется решать путём создания копии изначального пространства, в котором велись требования, при этом всякая связь и наследственность требований теряется. Собственно, полевым исследованиям данной концепции в нашей компании и посвящена эта статья.
Предпосылки
Что на наш взгляд останавливает широкое применение этой концепции в массах — это убогость инструментария для наглядного представления и управления требованиями в плоском текстовом виде. Имеется в виду, что плоские текстовые файлы не покажешь Product Owner, чтобы он увидел в них Project Scope, текстовые файлы не выведешь на страничку презентации для стейкхолдеров, в них нет графиков, диаграмм и картинок на этапе редактирования — а это уже отвращает бизнес-аналитиков, которые по сути должны генерировать контент. И только разработчики довольны и кричат: «кул! только хардкор! больше коммитов!» и прочую ересь.
Есть ещё один достаточно тонкий момент. Апологеты концепции «документация — это код» почему-то уверены, что как только документация ляжет рядом с кодом в репозиторий — это приведёт к обязательной её адаптации и синхронизации с изменениями в коде, что позволит поддерживать её в актуальном состоянии (п. 1.2.1). Но на наш взгляд — этот момент так и останется вопросом дисциплины, ведь никто не мешает менять код, а документацию не менять. То есть актуальность документации при такой реализации концепции отдаётся на откуп менеджменту процесса разработки, где обязательным шагом перед релизом будет «проверять актуальность документации». В таком случае «документация — это код» недалеко уходит от вордовских файликов, если не учитывать некоторой автоматизации в вопросах компоновки результирующих документов.
Ну так вот да — во-первых, «неудобно, ненаглядно, сухо», во-вторых — технические фишки «прикрывают тряпочкой» проблему актуализации документации. Существует расхожий стереотип: «мы по аджайлу — а в аджайле документация не нужна!». Это мягко говоря не совсем так. Мне нравится опровергать это заблуждение, приводя сравнение подходов Use Case и User Story из отличной книжки Карла Вигерса «Разработка требований к ПО» [4]. Если мы относим подходы разработки, основанные на User Stories, к методике Agile, то Вигерс так формулирует эволюцию требований, основанных на User Stories:
Пользовательская история→ (дискуссии)→ Уточненная пользовательская история (с критериями приёмки)→ (дискуссии)→ Приёмочные тесты(стр. 169, рис. 8-1). Таким образом, выходной документацией в результате эволюции начальных требований в проектах гибкой разработки являются приёмочные тесты. На сегодняшний день достаточно распространённой техникой организации приёмочного тестирования является использование сценариев тестирования, написанных на языке Gherkin [5], хранящихся в так называемых feature-файлах (простых, текстовых).
Стало быть, для того чтобы поддержать реализацию концепции «документация — это код» в проектах гибкой разработки нужен инструмент, который позволит сопровождать эволюцию требований от формата User Story до приёмочных тестов, которые в результате своего удачного выполнения сгенерируют актуальную документацию. К сожалению, на сегодняшний день инструмента, который бы в полной мере поддерживал этот процесс (или хотя бы постулировал своё стремление его поддержать) не существует.
Архитектура инструмента для исследования концепции
Итак, инструмента нет, а концепцию исследовать хочется. От безысходности нам пришлось его разработать. Если бы такой инструмент (назовём его условно StoryMapper) уже существовал, то какая бы у него была архитектура, чтобы ненавязчиво, с минимальным напряжением встроиться в уже существующую экосистему процесса разработки? Если это уже отстроенный процесс разработки, то в нём наверняка уже был бы запущен контур CI/CD, и несомненно использовалась бы система контроля версий, скорее всего git-based. В таком случае ниже приводится схема, на которой обозначено место StoryMapper в процессе разработки:
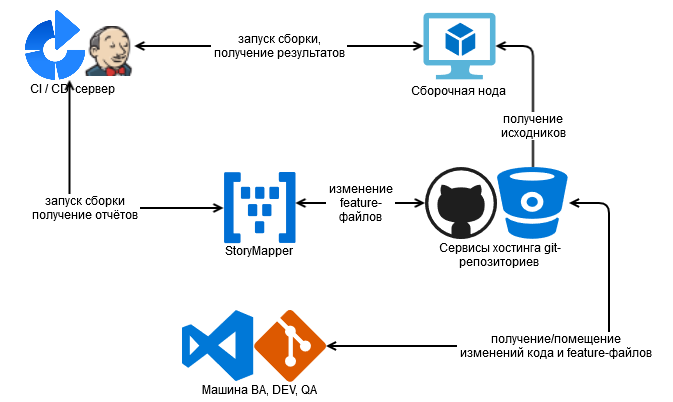
Рис. 1 Место инструмента StoryMapper в структуре процесса разработки
Таким образом, StoryMapper напрямую будет взаимодействовать с сервисами хостинга git-репозиториев и с контуром CI/CD. Интеграция с сервисами git-хостинга нужна, чтобы получить текущую коллекцию feature-файлов (если она имеется), а также поместить обратно в репозиторий результаты внесения изменений в feature-файлы, сервисные файлы, касающиеся структуризации документации, примеры входных-выходных данных и т. д. Взаимодействие с контуром CI/CD необходимо, чтобы иметь возможность запускать сборку сценарного тестирования (вручную или по расписанию), и для последующего получения результатов тестирования — чтобы соотнести их с с соответствующими feature-файлами (таким образом будет происходить верификация и проверка на актуальность документации).
Надо понимать, что StoryMapper едва ли должен претендовать на звание «yet another Gherkin-editor». Да, базовая возможность редактировать feature-файлы должна быть заложена, но мы отчётливо осознаём, что если BA или QA сделали свой выбор в пользу VSC, Sublime, Notepad++ или даже vi (почему нет?) — то переубедить их работать с требованиями только в StoryMapper задача не то чтобы неблагодарная, скорее некорректная. Поэтому мы предполагаем, что должна быть заложена возможность разнопланового использования StoryMapper, в частности: разработка фич в любимом редакторе, а StoryMapper используется для структурирования уже готовых feature-файлов. Подробнее об этом в разделе о направлениях исследования.
Минимально необходимые функциональные возможности
Поскольку StoryMapper на сегодняшний день находится в состоянии MVP, то вот те самые минимальные требования, которые мы к нему предъявляли, чтобы им можно было реально начать пользоваться:
- Git-based story mapping;
- Gherkin-editor;
- Запуск сборки сценарного тестирования (вручную и по расписанию);
- Отражение результатов сценарного тестирования на карте пользовательских историй.
Я не буду подробно останавливаться на функционале инструмента, поскольку тема данной статьи — это ход операции, а не скальпель хирурга.
Направления исследования
Основная мысль такая: если применяя концепцию «документация — это код», не идти от требований заказчика, а писать какую-то произвольную документацию по мере написания кода, то такая документация умрёт и станет неактуальной также быстро, как и вариант с файликами в формате MS Word. Поэтому мы хотели продумать и исследовать вариант использования концепции применительно к полному циклу разработки. С другой стороны, нас интересовал и переходный момент, когда у команды не используется концепция «документация — это код», но есть желание её применять — как действовать в таком случае?
Итак, StoryMapper — это инструмент, он не регламентирует единственно верный вариант использования. Напротив, каждый потенциальный пользователь может увидеть свои варианты применения инструмента. Мы же сосредоточились на трёх основных направлениях:
- Гибкая разработка: от карты историй до приёмочных тестов;
- Структурирование и визуализация коллекции feature-файлов;
- Мониторинг продуктива.
Ниже я подробно опишу, каких результатов мы достигли по каждому направлению.
Гибкая разработка: от карты историй до приёмочных тестов
Данное направление предполагает разработку нового продукта или доработку уже существующего. Работы по этому направлению проходили под кодовым названием «BDDSM»: как объединение техники Story Mapping и методики разработки BDD. Так и прижилось.
Итак, для начала создаётся git-репозиторий для feature файлов, в нём выделяется ветка для взаимодействия со StoryMapper. В StoryMapper создаётся проект, его подключают бизнес-аналитикам, которые будут работать на проекте. Общаясь со стейкхолдерами, бизнес-аналитики начинают формировать общее видение продукта и закрепляют его в виде скелета карты пользовательских историй [1,2], сначала набросок первого уровня UF:

Рис. 6 Верхний уровень скелета карты пользовательских историй (кликабельно)
А потом постепенно наполняя и второй уровень пользовательских активностей:
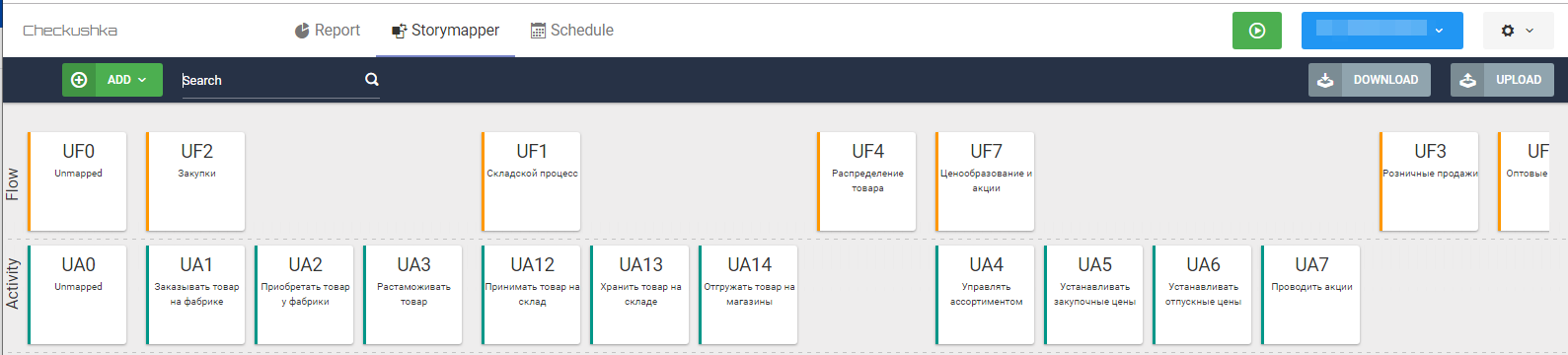
Рис. 7 Второй уровень скелета карты пользовательских историй
Поскольку каждая карточка — это текстовый файл, то или на этапе сбора требований (если карта составляется по ходу общения с пользователем), или на этапе пост-обработки проведенных интервью результаты общения переносятся непосредственно в карточки UF и UA. Это является базой для дальнейшей декомпозиции требований до уровня пользовательский историй.
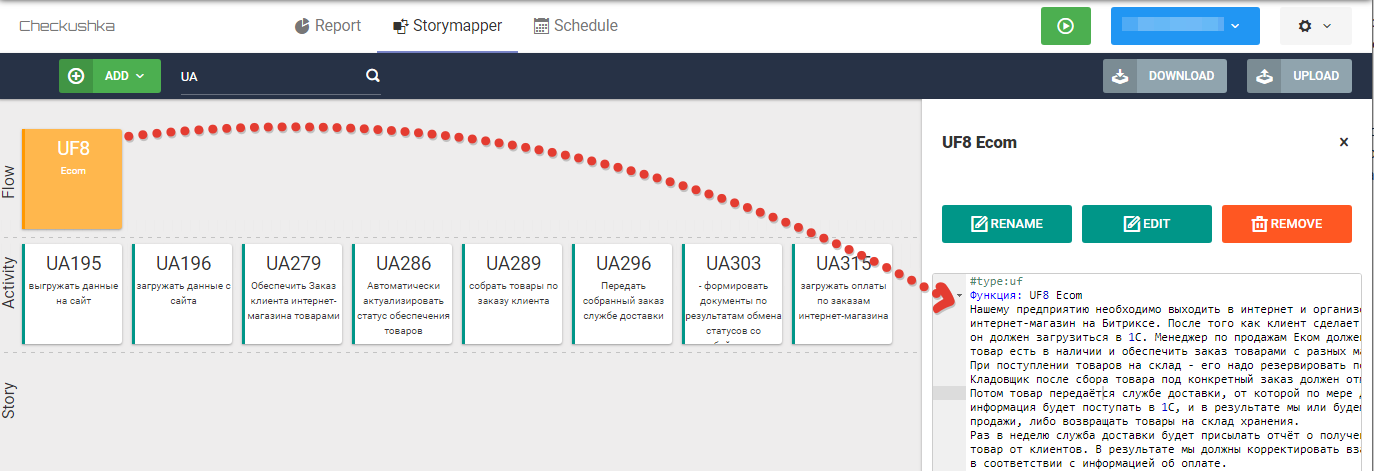
Рис. 8 Свободный текст с описанием требований, соответствующий синтаксису Gherkin, на уровне UF
Далее бизнес-аналитики осознают, каким образом декомпозировать пользовательские активности до пользовательских историй, и формируют в StoryMapper третий уровень карты — US. Выделение US сопряжено с формулировкой критериев приёмки, то есть если «ты как кто-то хочешь что-то», то как мы проверим постфактум, что ты это получил [3]. Критерии приёмки для начала могут также фиксироваться в US в виде плоского текста.
После того, как критерии приёмки устоялись и согласованы со стейкхолдерами, бизнес-аналитики оформляют их в виде сценариев на языке Gherkin. Фактически перед каждым критерием приёмки дописывается текст «Сценарий: КП-№», что превращает абстрактную доселе пользовательскую историю в feature-файл.
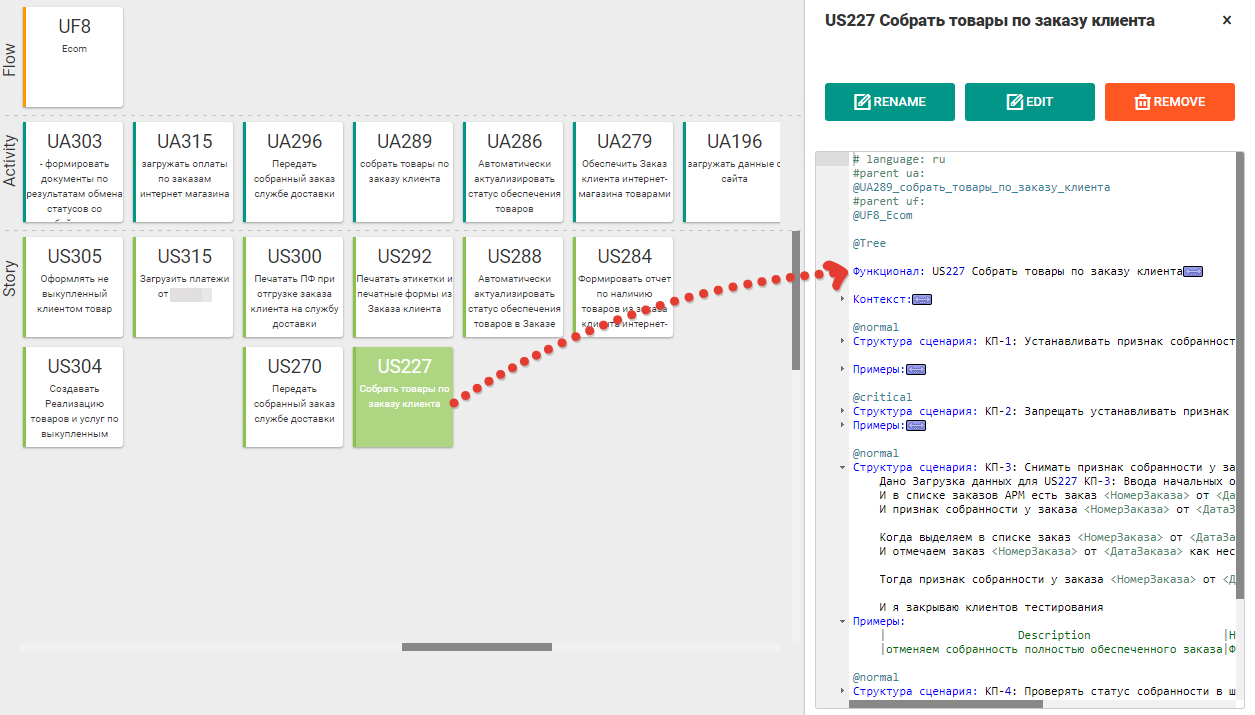
Рис. 8.1 Критерии приёмки пользовательской истории в виде сценариев на Gherkin
После этого каждый сценарий расшифровывается несколькими укрупнёнными шагами, которые раскрывают, как именно конкретный критерий приёмки будет проверяться. Далее эти шаги либо программируются разработчиками, либо набираются из библиотеки шагов используемого фреймворка Gherkin и выносятся в экспортные сценарии.
Параллельно с этим организуется тестовый стенд, на котором сервер сборок будет прогонять функциональные тесты и до поры ждать, когда будут готовы US со сценариями. По мере готовности продукта и сценариев, реализующих критерии приёмки, сервер сборок начинает выдавать отчёты в формате Allure и Cucumber и отправлять их в StoryMapper, который в свою очередь проецирует результат сборки в формате Cucumber на карту пользовательских историй:
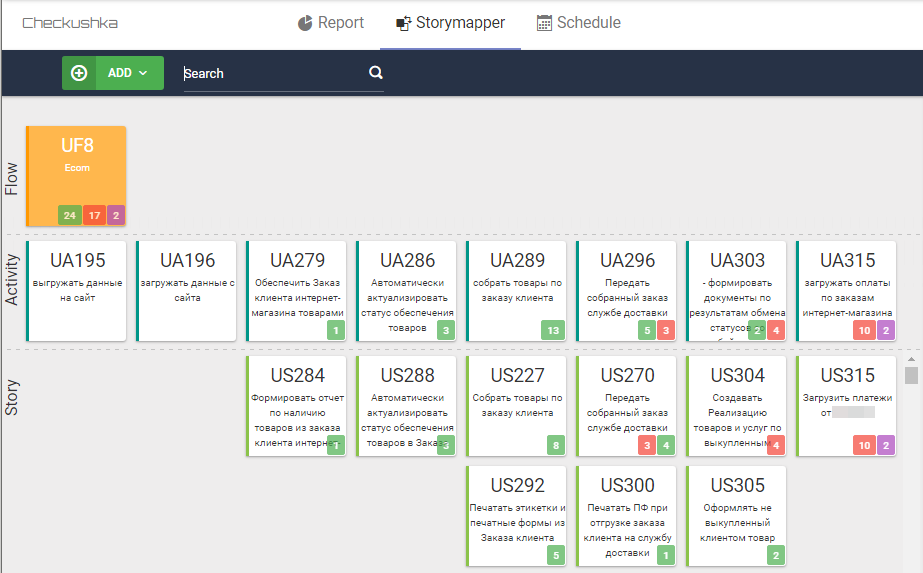
Рис. 9 Карта пользовательских историй с результатами выполнения сценариев
При этом StoryMapper обеспечивает три уровня понимания готовности продукта: UF — это верхний уровень, который показывает количество правильно работающих сценариев (удовлетворяющих критериям приёмки), работающих с ошибками, и ещё неготовых. То есть фактически верхний уровень является индикатором готовности продукта и показателем того, сколько ещё осталось сделать (это уровень product owner). Нижние уровни позволяют разобраться с тем, в каких именно пользовательских активностях есть трудности, и куда нужно приложить усилия, чтобы приблизить продукт к завершению (это уровень скрам-мастеров в большей степени и product owner в меньшей). Нижний уровень US — это уровень, на котором взаимодействуют бизнес-аналитики, разработчики и QA, совместными усилиями разрабатывая именно тот продукт, который от них ожидают стейкхолдеры.
Также в одном из завершающих шагов сборочной линии производится создание автодокументации. Подробнее об этом можно почитать у коллег. Это не единственный вариант, мы планируем подключить в наш инструмент пакет Pickles — стандарт де-факто в мире «живой документации».
Структурирование и визуализация коллекции feature-файлов
Работая в этом направлении, мы рассматривали такой кейс. Команда разработчиков на волне хайпа вокруг темы BDD, функционального тестирования и промышленных стандартов разработки взялась писать feature-файлы. И прорываясь сквозь тернии, накопила в репозитории достаточно большую коллекцию. Однако, когда у тебя в коллекции 10 файлов — то отчёт в формате Allure ещё даёт какую-то достоверную картину состояния продукта. Но если количество feature-файлов измеряется десятками, а иногда и сотнями, то рано или поздно тебе захочется их как-то структурировать. Первое, что приходит в голову — это разложить их по тематическим папочками. А по каким? По стейкхолдерам, по метаданным, по подсистемам? Это далеко не праздные вопросы. А если потом окажется, что feature-файлы писались изначально как Бог на душу положит, и в нём есть сценарии относящиеся сразу к нескольким папкам, то тогда как?
Итак, данный вариант использования предполагает желание навести порядок в своей документации, чтобы из состояния «фичи отдельно, документация отдельно» перейти к «документации — это код». Когда такой репозиторий подключается в StoryMapper, то все feature-файлы попадают в первую колонку под UF0 и UA0. Следующий шаг в деле структурирования — это составление скелета структуры. В StoryMapper — это всё те же UF и UA, но никто не настаивает на рассмотрении их только в таком ракурсе. Их можно рассматривать просто как 2 уровня иерархии, под которыми существует возможность разместить до того неструктурированные feature-файлы. После того, как структура задана, feature-файлы из первой колонки растаскиваются под соответствующие UA. Несомненно этот процесс вызывает приступ рефлексии и рефакторинга фич, потому что по мере перетаскивания становится понятной вся та глубина хаоса, которая имела место быть в ходе их первоначального написания. Иногда достаточно перенести сценарий из одного файла в другой, иногда разбить один большой файл на несколько, чтобы восстановить семантическую связность, а иногда и просто выбросить на помойку, потому что в репозитории завалялись древние неисполняемые рукописи.
Если сборочная линия уже была настроена (ну а раз репозиторий feature-файлов есть, то они должны где-то собираться), то в ней нужно добавить шаг по отправке результатов сборки в StoryMapper. В конечном результате будет получена последняя картинка из предыдущего раздела (рис. 9): структурированные feature-файлы с отметками о результатах выполнения их сценариев.
Как пользоваться такой картинкой? Её можно показывать руководящему составу, с тем чтобы отчитываться о результатах работы команды и демонстрировать степень готовности/качества продукта. Может использоваться командой при проведении ретроспективы, чтобы подкорректировать DoD либо ещё как-то подкорректировать процесс. Может использоваться при грумминге бэклога, но это уже требует работы по сценарию, описанному в предыдущем разделе, когда после первичного структурирования требований дальнейшая разработка будет вестись полным циклом посредством (или хотя бы с учётом) StoryMapper.
Мониторинг продуктива
Ещё один побочный вариант использования, который прижился в нашей практике. На самом деле, это современная и модная тема — тестировать прямо в продуктиве, почему нет. Ведь ошибки нет-нет да и проберутся. Особенно это актуально становится в том случае, если IT-деятельность не является профильной для компании и разработка вынесена на outsource, в частности — это интернет-магазины малой и средней руки.
Как мы себе это видим. Простой вариант: из множества функциональных тестов выделяется некое подмножество немодифицирующих базу данных тестов, проверяющих фронтенд. Второй вариант: выделяются сценарии, проверяющие бизнес-логику, при этом сессия, в которой стартует проверка, запускается в тестовом спец-режиме, где модификация данных не отражается на базе данных, не портит статистику и не участвует в обмене с учётными системами. Когда этот набор сценариев составлен, он подвязывается к расписанию и с заданной периодичностью выполняется непосредственно на продуктиве. Результат выполнения всё также отражается в StoryMapper и Allure, но важнее то, что если в этом тестовом наборе будут ошибки — то заинтересованные в бизнесе лица будут получать уведомление на почту, и таким образом, в онлайне смогут ориентироваться в том, как очередной релиз его поставщиков IT-услуг ломает его основной инструмент ведения бизнеса.
Если в шаги сценариев заложить проверку длительности их выполнения, и в случае нарушения контрольного времени останавливать выполнения сценариев с ошибкой, то данные сценарии будут отражать нефункциональные требования по быстродействию. Соответственно, если изменения в коде, повышение нагрузки, деградация производительности хостинга повлияли на быстродействие продукта, то человек финансово-заинтересованный в работоспособности будет об этом извещён.
Итак, для того чтобы организовать мониторинг продуктива, нужно подготовить:
- репозиторий с набором сценариев, адаптированных для продуктива;
- сборочную линию, обеспечивающую выполнение сценариев в продуктиве, с настроенным хуком для запуска;
- StoryMapper с подключенным репозиторием и настроенным хуком для получения результатов тестирования;
- настроенное в StoryMapper расписание запусков и уведомление об ошибках.
Направления развития
Повторюсь, что на сегодняшний день StoryMapper находится в состоянии MVP. Тем не менее, он позволил провести «эксперименты на людях», которые, на мой взгляд, завершились более, чем успешно. Ну и на выходе, конечно же, пришёл тот самый «аппетит во время еды». Вот далеко неполный список того, что хотелось бы добавить в инструмент:
- отображение в инструменте той самой «живой документации», которая должна быть конечным результатом в концепции «документация — это код»;
- обсуждение сценариев между участниками проекта (комментарии, коллаборация etc. );
- экспорт/импорт карты пользовательских историй в/из Excel;
- какая-то интеграция с Jira (но тут больше вопросов, чем ответов).
Я предвижу такой риск, что инструмент внутреннего использования может начать довлеть над методикой и концепцией, и мы станем заниматься самоедством и рефлексией вместо того, чтобы генерировать интересные идеи и совершенствовать процесс разработки. Поэтому в ближайшем будущем у нас в планах выдать доступ к инструменту ограниченным тиражом, чтобы вдохновиться обратной связью и пересмотреть те самые направления развития.
Как можно попробовать
Я не ожидаю прям такого взрывного интереса к поднятым здесь темам (хотя термин хабраэффект мне знаком), поэтому если вдруг кому стало интересно и захотелось пощупать инструмент руками, пообщаться на тему эволюции и верификации требований (что более интересно!) — стучитесь к нам в telegram, договориться можно обо всём.
Список литературы и ссылки
- Джефф Паттон, Пользовательские истории. Искусство гибкой разработки ПО, Спб., Питер, 2017.
- Майк Кон, Пользовательские истории. Гибкая разработка программного обеспечения, М.-Спб.-К, Вильямс, 2012.
- Gojko Adjic, Specification by Example, NY, Manning Publication, 2011.
- Карл Вигерс, Джой Битти, Разработка требований к программному обеспечению, М.: Русская редакция; СПб.: БХВ-Петербург, 2014.
- Вводная статья о BDD Дэна Норта «What's in a story»
- Информация о концепции «Документация — это код» в сообществе «Write the docs»
- Реализация концепции «Документация — это код» в проекте "docToolchain"

