Добрый день,
в продолжение серии статей: первая и вторая об использовании fish eye камеры с Raspberry Pi 3 и ROS я бы хотел рассказать об использовании предобученных Deep Learning моделей для компьютерного зрения с камерой Fish eye на Raspberry Pi 3. Кому интересно, прошу под кат.
Как и в прошлых статьях будем использовать Ubuntu 16.04. Для работы нам будет нужна библиотека Keras. Его можно установить на Ubuntu следуя руководству отсюда.
Перейдем на страницу и нажмем кнопку DOWNLOAD THE CODE! снизу страницы. Вы получите email с исходниками.
Скачаем архив, разархивируем его и перейдем в папку. Для начала запустим скрипт классификации объектов на основе предобученной модели GoogleNet:
Получим такой вывод в терминале

Здесь используется модуль Deep Neural Network (DNN) из OpenCV 3.3. О нем можно прочитать здесь.
Теперь попробуем классификацию объектов с предобученной моделью Squeezenet:

У меня классификация сработала за 0.86 sec.
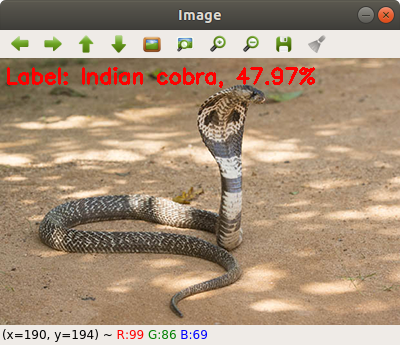
Попробуем теперь на изображении cobra.png:
Вывод:
Теперь попробуем детекцию объектов с Raspberry Pi с fish eye камерой. Перейдем на страницу и нажмем кнопку DOWNLOAD THE CODE! снизу страницы. Вы получите email с исходниками.
Аналогично классификации скачаем, разархивируем, перейдем в папку. Запустим скрипт детекции объектов:
Вывод:
При запуске скрипта мы можем получить такую ошибку:
Чтобы решить проблему откроем файл pi_object_detection.py и закомментируем строку 74:
и раскомментируем строку 75
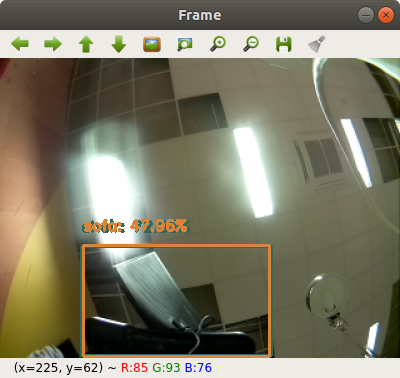
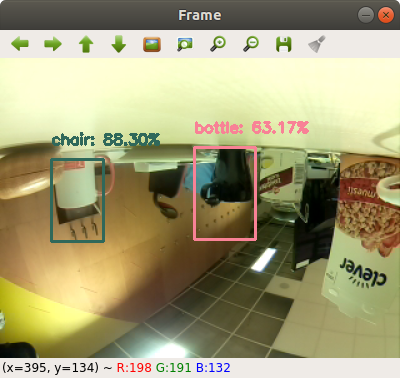
Мы видим, что скрипт обнаруживает некоторые объекты, хотя не все объекты правильно распознает. По моим наблюдениям скрипт выполняет детекцию объектов довольно быстро (к сожалению, fps не удалось зафиксировать).
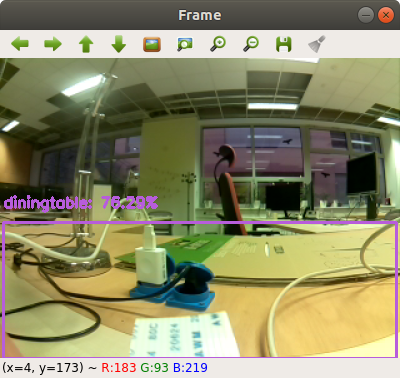
Также можем запустить скрипт real_time_object_detection.py. В случае ошибки повторим процедуру для скрипта pi_object_detection.py: закомментируем строку 38 и раскомментируем строку 39. Результат
На этом пока все. Всем удачи и до новых встреч!
в продолжение серии статей: первая и вторая об использовании fish eye камеры с Raspberry Pi 3 и ROS я бы хотел рассказать об использовании предобученных Deep Learning моделей для компьютерного зрения с камерой Fish eye на Raspberry Pi 3. Кому интересно, прошу под кат.
Классификация изображений
Как и в прошлых статьях будем использовать Ubuntu 16.04. Для работы нам будет нужна библиотека Keras. Его можно установить на Ubuntu следуя руководству отсюда.
Перейдем на страницу и нажмем кнопку DOWNLOAD THE CODE! снизу страницы. Вы получите email с исходниками.
Скачаем архив, разархивируем его и перейдем в папку. Для начала запустим скрипт классификации объектов на основе предобученной модели GoogleNet:
cd pi-deep-learning/ python pi_deep_learning.py --prototxt models/bvlc_googlenet.prototxt \ --model models/bvlc_googlenet.caffemodel --labels synset_words.txt \ --image images/barbershop.png
Получим такой вывод в терминале
[INFO] loading model... [ INFO:0] Initialize OpenCL runtime... [INFO] classification took 1.7103 seconds [INFO] 1. label: barbershop, probability: 0.78055 [INFO] 2. label: barber chair, probability: 0.2194 [INFO] 3. label: rocking chair, probability: 3.4663e-05 [INFO] 4. label: restaurant, probability: 3.7257e-06 [INFO] 5. label: hair spray, probability: 1.4715e-06
Здесь используется модуль Deep Neural Network (DNN) из OpenCV 3.3. О нем можно прочитать здесь.
Теперь попробуем классификацию объектов с предобученной моделью Squeezenet:
python pi_deep_learning.py --prototxt models/squeezenet_v1.0.prototxt \ --model models/squeezenet_v1.0.caffemodel --labels synset_words.txt \ --image images/barbershop.png
[INFO] loading model... [ INFO:0] Initialize OpenCL runtime... [INFO] classification took 0.86275 seconds [INFO] 1. label: barbershop, probability: 0.80578 [INFO] 2. label: barber chair, probability: 0.15124 [INFO] 3. label: half track, probability: 0.0052873 [INFO] 4. label: restaurant, probability: 0.0040124 [INFO] 5. label: desktop computer, probability: 0.0033352
У меня классификация сработала за 0.86 sec.
Попробуем теперь на изображении cobra.png:
python pi_deep_learning.py --prototxt models/squeezenet_v1.0.prototxt \ --model models/squeezenet_v1.0.caffemodel --labels synset_words.txt \ --image images/cobra.png
Вывод:
[INFO] classification took 0.87402 seconds [INFO] 1. label: Indian cobra, probability: 0.47972 [INFO] 2. label: leatherback turtle, probability: 0.16858 [INFO] 3. label: water snake, probability: 0.10558 [INFO] 4. label: common iguana, probability: 0.059227 [INFO] 5. label: sea snake, probability: 0.046393
Детекция объектов
Теперь попробуем детекцию объектов с Raspberry Pi с fish eye камерой. Перейдем на страницу и нажмем кнопку DOWNLOAD THE CODE! снизу страницы. Вы получите email с исходниками.
Аналогично классификации скачаем, разархивируем, перейдем в папку. Запустим скрипт детекции объектов:
python pi_object_detection.py --prototxt MobileNetSSD_deploy.prototxt.txt --model MobileNetSSD_deploy.caffemodel
Вывод:
[INFO] loading model... [INFO] starting process... [INFO] starting video stream... [ INFO:0] Initialize OpenCL runtime... libEGL warning: DRI3: failed to query the version libEGL warning: DRI2: failed to authenticate
При запуске скрипта мы можем получить такую ошибку:
Error: AttributeError: ‘NoneType’ object has no attribute ‘shape’ (comment to post)
Чтобы решить проблему откроем файл pi_object_detection.py и закомментируем строку 74:
vs = VideoStream(src=0).start()
и раскомментируем строку 75
vs = VideoStream(usePiCamera=True).start()
Мы видим, что скрипт обнаруживает некоторые объекты, хотя не все объекты правильно распознает. По моим наблюдениям скрипт выполняет детекцию объектов довольно быстро (к сожалению, fps не удалось зафиксировать).
Также можем запустить скрипт real_time_object_detection.py. В случае ошибки повторим процедуру для скрипта pi_object_detection.py: закомментируем строку 38 и раскомментируем строку 39. Результат
На этом пока все. Всем удачи и до новых встреч!

