Python понимает все популярные форматы файлов. Кроме того, у каждой библиотеки есть свой, «теплый ламповый», формат. Синтаксис, разумеется, у каждого формата сугубо индивидуален. Я собрал все функции для работы с файлами разных форматов на один лист A4, с приложением в виде примера использования в jupyter notebook.

Я условно разделил форматы на три блока по способу использования. Как известно, файлы нужны для обмена информацией: между людьми, между программами (первый блок), между компьютером и сетью (второй) и «save game» – между одной и той же программой в разные моменты времени (третий блок).
Вкратце о каждом блоке:
1) Универсальные форматы:
2) «Сетевые» форматы:
3) Нативные питоновские форматы:
Сам сheatsheet:
– в формате pdf
– в формате png: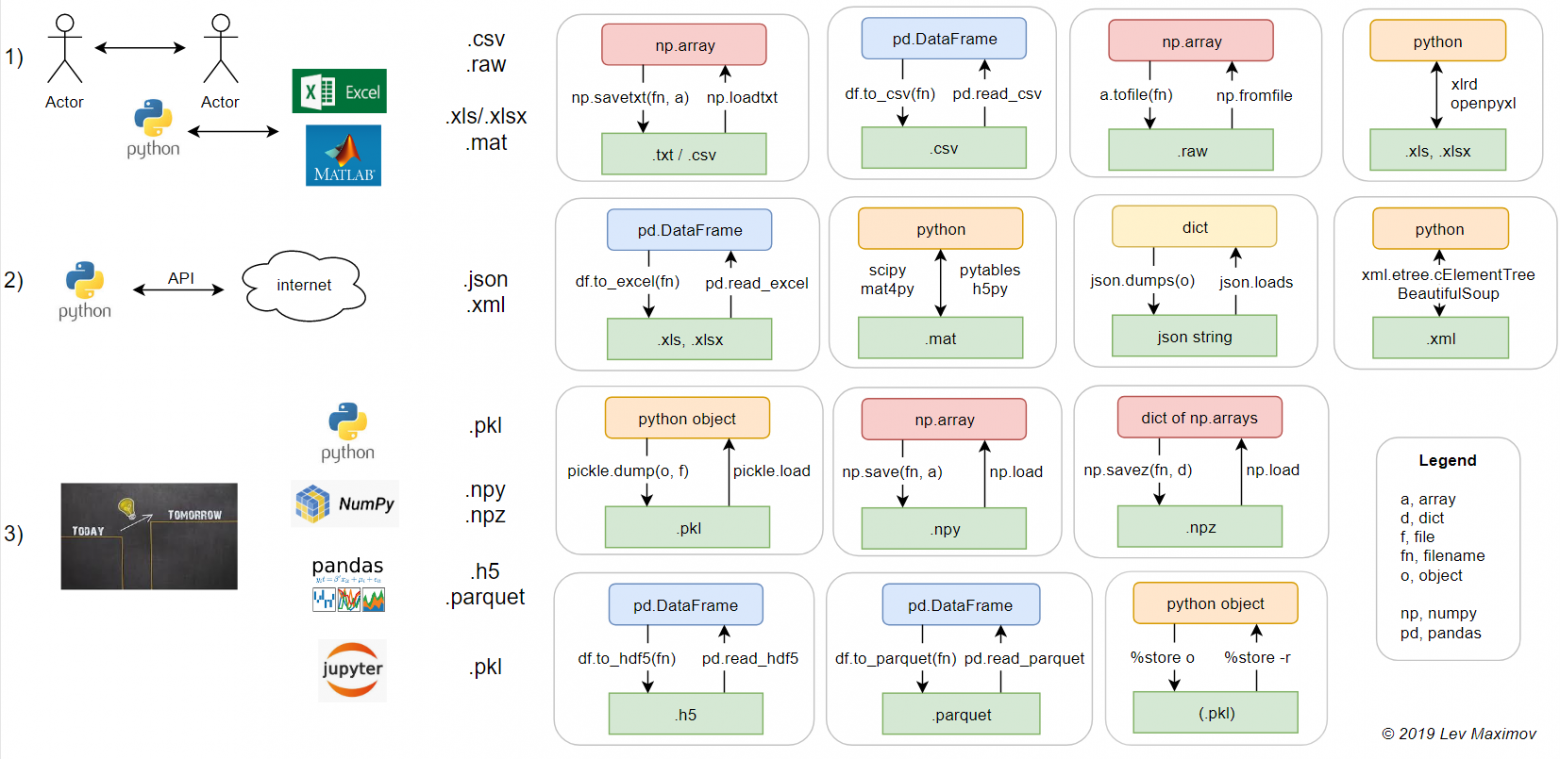
Пример использования всех функций с диаграммы: html с оглавлением и ipynb-исходником
Я условно разделил форматы на три блока по способу использования. Как известно, файлы нужны для обмена информацией: между людьми, между программами (первый блок), между компьютером и сетью (второй) и «save game» – между одной и той же программой в разные моменты времени (третий блок).
Вкратце о каждом блоке:
1) Универсальные форматы:
- .csv – текстовый, значения, разделённые по идее запятыми (comma separated), но например, русский эксель предпочитает разделять точками с запятыми, поскольку в русской локали запятая уже используется – в качестве десятичного разделителя;
- .raw – бинарный формат для тех, кто не любит форматы файлов. Тип данных и, если данные многомерные, соответствующие размеры должны передаваться отдельно, в файле только сами данные;
- .xls/.xlsx – старый бинарный (ограничение в 65k строк) и новый xml’ный форматы экселя;
- .mat – это на самом деле тоже два формата (оба бинарные): старый проприетарный и новый на основе hdf5. Питон умеет работать с обоими (через библиотеки).
2) «Сетевые» форматы:
- .json – текстовый, выглядит как словарь в питоне, но кавычки можно использовать только двойные;
- .xml – текстовый, похож на html.
3) Нативные питоновские форматы:
- .pkl – бинарный формат, в него умеют сохраняться все встроенные питоновские объекты. Пользовательские классы тоже умеют, а если питон сохраняет как-то не так, можно ему помочь через магические методы. Поддерживает дописывание в конец существующего файла (appending).
- .npy и .npz – в numpy аж целых два своих формата (оба бинарные). Появились как реакция на потерю обратной совместимости у pkl в момент перехода python v2->v3. Накладные расходы минимальные (~ на 100 байт больше, чем соответствующий raw; pkl, впрочем, немногим больше: на ~150 байт больше raw). В .npy можно сохранить только один массив, а в npz – сразу несколько, причём достать их оттуда впоследствии можно по имени.
- .h5 – бинарный формат hdf5. Примечателен тем, что в нем можно хранить целую иерархическую структуру данных, это практически файловая система в одном файле. Кроме того, его можно открыть в matlab без конвертации. Минусы:
a) небольшие файлы занимают неоправданно много места (например, 300 байт pkl vs 3.1 Мb у h5),
b) много багов,
c) есть дописывание в существующий файл, но если при этом случится ошибка (а так бывает), данные из него достать будет проблематично.
Здесь детальный разбор плюсов и минусов hdf5, вкратце – хороший формат для обмена данными, плохой – для использования в качестве файловой системы (например, нельзя стереть массив, только скопировать файл без него). - .parquet – бинарный формат для big data. Apache Parquet не является нативным питоновским форматом, но неплохо интегрирован в pandas. Можно сжимать/разжимать «на лету» (rle, gzip, dictionary encoding); сжимает чуть лучше Apache Avro. В отличие от avro, где данные хранятся построчно (как бы C order), в parquet данные хранятся столбец-за-столбцом (как бы fortran order). Благодаря этому можно эффективно работать с таблицами с большим количеством столбцов.
- в jupyter решили не изобретать велосипед –%store сохраняет в формат .pkl, только почему-то без расширения.
Сам сheatsheet:
– в формате pdf
– в формате png:
Пример использования всех функций с диаграммы: html с оглавлением и ipynb-исходником

