Привет!
Калькулятор у нас почему-то ассоциируется с чем-то, что должен написать каждый новичок. Возможно потому, что исторически компьютеры с той целью и создавались, чтобы считать. Но мы будем писать непростой калькулятор, не sympy конечно, но чтобы умел базовые алгебраические операции, типа дифференциирования, симплификации, а также фичи типа компиляции для ускорения вычислений.
Берем оставшиеся с нового года печеньки, и погнали!
Конечно, это не строка. Довольно очевидно, что математическая формула — это либо дерево, либо стек, и здесь мы остановимся на первом. То есть каждая нода, каждый узел этого дерева, это какая-то операция, переменная, либо константа.

Операция — это либо функция, либо оператор, в принципе, примерно одно и то же. Ее дети — аргументы функции (оператора).
Разумеется, реализация может быть любой. Однако идея в том, что если ваше дерево состоит только из узлов и листьев, то они бывают разными. Поэтому я называю эти «штуки» — сущностями. Поэтому верхним классом у нас будет абстрактный класс Entity.
А также будет четыре класса-наследника: NumberEntity, VariableEntity, OperatorEntity, FunctionEntity.
Для начала мы будем строить выражение в коде, то есть
Если объявить пустой класс VariableEntity, то такой код выкинет вам ошибку, мол не знает как умножать и суммировать.
Очень важная и полезная фича большинства языков, позволяя кастомизировать выполнение арифметических операций. Синтаксически реализуется по-разному в зависимости от языка. Например, реализация в C#
Подробнее о переопределении операторов в C#
В репе реализовано тут.
В компилируемых языках типа C# такая штука обычно присутствует и позволяет без дополнительного вызова myvar.ToAnotherType() привести тип, если необходимо. Так, например, было бы удобно писать
Вместо привычного
Подробнее о приведении типов в C#
В репе реализовано на этой строке.
Класс Entity имеет поле Children — это просто список Entity, которые являются аргументами для данной сущности.
Когда у нас вызывается функция или оператор, нам стоит создать новую сущность, и в ее дети положить то, от чего вызывается функция или оператор. К примеру, сумма по идее должна выглядить примерно так:
То есть теперь если у нас есть сущность x и сущность 3, то x+3 вернет сущность оператора суммы с двумя детьми: 3 и x. Так, мы можем строить деревья выражений.
Вызов функции более простой и не такой красивый, как с оператором:
Подвешивание в репе реализовано тут.
Отлично, мы составили дерево выражений.
Здесь все предельно просто. У нас есть Entity — мы проверяем является ли он сам переменной, если да, возвращаем значение, иначе — бежим по детям.
В этом огромном 48-строчном файле реализована столь сложная функция.
Собственно то, ради чего все это. Здесь мы по идее должны добавить в Entity какой-то такой метод
Листик без изменений, а для всего остального у нас кастомное вычисление. Опять же, приведу лишь пример:
Если аргумент — число, то произведем численную функцию, иначе — вернем как было.
Это самая простая единица, число. Над ним можно проводить арифметические операции. По умолчанию оно комплексное. Также у него определены такие операции как Sin, Cos, и некоторые другие.
Если интересно, Number описан тут.
Численно производную посчитать может кто угодно, и такая функция пишется поистине в одну строку:
Но разумеется нам хочется аналитическую производную. Так как у нас уже есть дерево выражений, мы можем рекурсивно заменить каждый узел в соответствии с правилом дифференциирования. Работать оно должно примерно так:

Вот, к примеру, как реализованна сумма в моем коде:
А вот произведение
А вот сам по себе обход:
Это метод Entity. И как видим, что у листа всего два состояния — либо это переменная, по которой мы дифференциируем, тогда ее производная равна 1, либо это константа (число либо VariableEntity), тогда ее производная 0, либо узел, тогда идет отсылка по имени (InvokeDerive обращается к словарю функций, где и находится нужная (например сумма или синус)).
Заметьте, я здесь не оставляю что-то типа dy/dx и сразу говорю, что производная от переменной не по которой мы дифференциируем равна 0. А вот здесь сделано по-другому.
Все дифференциирование описано в одном файле, а больше и не надо.
Упрощение выражения в общем случае в принципе нетривиально. Ну например, какое выражение проще: или
или  ? Но мы придерживаемся каких-то представлений, и на основе них хотим сделать те правила, которые точно упрощают выражение.
? Но мы придерживаемся каких-то представлений, и на основе них хотим сделать те правила, которые точно упрощают выражение.
Можно при каждом Eval писать, что если у нас сумма, а дети — произведения, то переберем четыре варианта, и если где-то что-то равно, вынесем множитель… Но так делать конечно же не хочется. Поэтому можно догадаться до системы правил и паттернов. Итак, что мы хотим? Примерно такой синтаксис:
Вот пример дерева, в котором нашлось поддерево (обведено в зеленый), отвечающее паттерну any1 + const1 * any1 (найденное any1 обведено в оранжевый).

Как видим, иногда нам важно, что одна и та же сущность должна повторяться, например чтобы сократить выражение x + a * x нам необходимо, чтобы и там и там был x, ведь x + a * y уже не сокращается. Поэтому нам нужно сделать алгоритм, который не только проверяет, что дерево соответсвует паттерну, но и
Точка входа выглядит примерно так:
А в tree.PaternMakeMatch мы рекурсивно наполняем словарь ключами и их значениями. Вот пример списка самих паттерных Entity:
Когда мы будем писать any1 * const1 — func1 и так далее, у каждой ноды будет номер — это и есть ключ. Иначе говоря, при заполнении словаря, ключами выступят как раз эти номера: 100, 101, 200, 201, 400… А при постройке дерева мы будем смотреть на значение, соответствующее ключу, и подставлять его.
Реализовано тут.
В статье, к которой я уже обращался, автор решил сделать просто, и отсортировал практически по хешу дерева. Ему удалось сократить a и -a, b + c + b превратить 2b + c. Но мы, конечно, хотим и чтобы (x + y) + x * y — 3 * x сокращалось, и в целом более сложные штуки.
Вообще, то, что мы сделали до этого, паттерны — чудовищно замечательная штука. Она позволит вам сокращать и разность квадратов, и сумму квадрата синуса и косинуса, и другие сложные штуки. Но элементарную пальму, ((((x + 1) + 1) + 1) + 1), она не сократит, ведь здесь главное правило — коммутативность слагаемых. Поэтому первый шаг — вычленить «линейных детей».
Собственно для каждой ноды суммы или разности (и, кстати, произведения/деления) мы хотим получить список слагаемых (множителей).

Это в принципе несложно. Пусть функция LinearChildren(Entity node) возвращает список, тогда мы смотрим на child in node.Children: если child — это не сумма, то result.Add(child), иначе — result.AddRange(LinearChildren(child)).
Не самым красивым образом реализовано тут.
Итак, у нас есть список детей, но что дальше? Допустим, у нас есть sin(x) + x + y + sin(x) + 2 * x. Очевидно, что наш алгоритм получит пять слагаемых. Далее мы хотим сгруппировать по похожести, например, x похож на 2 * x больше, чем на sin(x).
Вот хорошая группировка:

Так как в ней паттерны дальше справятся с преобразованием 2*x + x в 3*x.
То есть мы сначала группируем по некоторому хешу, а затем делаем MultiHang — преобразование n-арного суммирования в бираное.
С одной стороны, и
и  следует поместить в одну группу. С другой стороны, при наличии
следует поместить в одну группу. С другой стороны, при наличии  помещать в одну группу с
помещать в одну группу с  бессмысленно.
бессмысленно.
Поэтому мы реализовываем многоуровневую сортировку. Сначала мы делаем вид, что — одно и то же. Посортировали, успокоились. Потом делаем вид, что можно помещать только с другими . И вот уже наши  и наконец объединились. Реализовано достаточно просто:
и наконец объединились. Реализовано достаточно просто:
Как видим, функция по-любому влияет на сортировку (разумеется, ведь с вообще никак в общем случае не связана). Как и переменная, с
с вообще никак в общем случае не связана). Как и переменная, с  ну никак не получится смешать. А вот константы и операторы учитываются не на всех уровнях. В таком порядке идет сам процесс упрощения
ну никак не получится смешать. А вот константы и операторы учитываются не на всех уровнях. В таком порядке идет сам процесс упрощения
Дерево сортирую тут.
В кавычках — так как не в сам IL код, а лишь в очень быстрый набор инструкций. Но зато очень просто.
Чтобы посчитать значение функции, нам достаточно вызвать подстановку переменной и eval, например
Но это работает медленно, около 1.5 микросекунды на синус.
Чтобы ускорить вычисление, мы делаем вычисление функции на стеке, а именно:
1) Придумываем класс FastExpression, у которого будет список инструкций
2) При компиляции инструкции складываются в стек в обратном порядке, то есть если есть функция x * x + sin(x) + 3, то инструкции будут примерно такими:
Далее при вызове мы прогоняем эти инструкции и возвращаем Number.
Пример выполнения инструкции суммы:
Вызов синуса сократился с 1500нс до 60нс (системный Complex.Sin работает за 30нс).
В репе реализовано тут.
Фух, вроде бы пока все. Хотя рассказать еще есть о чем, но мне кажется объем для одной статьи достаточный. Интересно ли кому-нибудь продолжение? А именно: парсинг из строки, форматирование в латех, определенный интеграл, и прочие плюшки.
Ссылка на репозиторий со всем кодом, а также тестами и самплами.
Спасибо за внимание!
Калькулятор у нас почему-то ассоциируется с чем-то, что должен написать каждый новичок. Возможно потому, что исторически компьютеры с той целью и создавались, чтобы считать. Но мы будем писать непростой калькулятор, не sympy конечно, но чтобы умел базовые алгебраические операции, типа дифференциирования, симплификации, а также фичи типа компиляции для ускорения вычислений.
Меньше воды! О чем статья?
Здесь будет поверхностно о построении выражения, парсинге из строки, подстановки переменной, аналитической производной, численным решении уравнения и определенного интеграла, рендеринг в формат LaTeX, комплексных числах, компиляцией функций, упрощении, раскрытии скобок, и бла бла бла. Вероятно, не в одной статье.
Для тех, кому нужно срочно что-нибудь склонировать, ссылка на репозиторий.
Для тех, кому нужно срочно что-нибудь склонировать, ссылка на репозиторий.
Берем оставшиеся с нового года печеньки, и погнали!
Для кого эта статья?
Я думаю, что статья может быть полезна новичку, но может быть те, кто чуть поопытнее, тоже найдут что-то интересное. Впрочем, я надеюсь написать статью так, чтобы ее можно было читать и не будучи C# программистом вообще.
Сборка выражения
Что такое «выражение»?
Когда я был маленький...
То я конечно хотел написать калькулятор. Что он должен уметь делать? Четыре основные операции, и в принципе куда еще больше. Так, моей задачей было посчитать значение строкового выражения, например «1 + (3 / 4 — (5 + 3 * 1))». Я взял мою любимую дельфи, и написал парсер, который сначала рекурсивно уходил в скобочки, а потом выражение в скобках заменял на значение, а скобки убирал. В принципе, вполне рабочий способ для меня в то время.
Конечно, это не строка. Довольно очевидно, что математическая формула — это либо дерево, либо стек, и здесь мы остановимся на первом. То есть каждая нода, каждый узел этого дерева, это какая-то операция, переменная, либо константа.
Операция — это либо функция, либо оператор, в принципе, примерно одно и то же. Ее дети — аргументы функции (оператора).
Иерархия классов в вашем коде
Разумеется, реализация может быть любой. Однако идея в том, что если ваше дерево состоит только из узлов и листьев, то они бывают разными. Поэтому я называю эти «штуки» — сущностями. Поэтому верхним классом у нас будет абстрактный класс Entity.
Абстрактный?
Как все знают из базового изучения языка, абстрактный класс хорош тем, что с одной стороны обобщает какие-то классы, с другой стороны позволяет разделить логику и поведение некоторых объектов. Объект абстрактного класса нельзя создать, а вот его наследника — можно.
А также будет четыре класса-наследника: NumberEntity, VariableEntity, OperatorEntity, FunctionEntity.
Как построить выражение?
Для начала мы будем строить выражение в коде, то есть
var x = new VariableEntity("x"); var expr = x * x + 3 * x + 12;
Если объявить пустой класс VariableEntity, то такой код выкинет вам ошибку, мол не знает как умножать и суммировать.
Переопределение операторов
Очень важная и полезная фича большинства языков, позволяя кастомизировать выполнение арифметических операций. Синтаксически реализуется по-разному в зависимости от языка. Например, реализация в C#
public static YourClass operator +(YourClass a, YourClass b) { return new YourClass(a.ToString() + b.ToString()); }
Подробнее о переопределении операторов в C#
В репе реализовано тут.
(Не)явное приведение типов
В компилируемых языках типа C# такая штука обычно присутствует и позволяет без дополнительного вызова myvar.ToAnotherType() привести тип, если необходимо. Так, например, было бы удобно писать
NumberEntity myvar = 3;
Вместо привычного
NumberEntity myvar = new NumberEntity(3);
Подробнее о приведении типов в C#
В репе реализовано на этой строке.
Подвешивание
Класс Entity имеет поле Children — это просто список Entity, которые являются аргументами для данной сущности.
Мысли
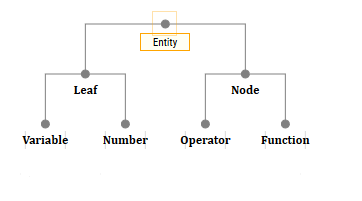
Вообще-то детей могут иметь объекты лишь двух классов: OperatorEntity и FunctionEntity. То есть в принципе можно было бы создать какой-нибудь NodeEntity и у него унаследовать эти два класса, и создать LeafEntity и от него унаследовать VariableEntity и NumberEntity.
Когда у нас вызывается функция или оператор, нам стоит создать новую сущность, и в ее дети положить то, от чего вызывается функция или оператор. К примеру, сумма по идее должна выглядить примерно так:
public static Entity operator +(Entity a, Entity b){ var res = new OperatorEntity("+"); res.Children.Add(a); res.Children.Add(b); return res; }
То есть теперь если у нас есть сущность x и сущность 3, то x+3 вернет сущность оператора суммы с двумя детьми: 3 и x. Так, мы можем строить деревья выражений.
Вызов функции более простой и не такой красивый, как с оператором:
public Entity Sin(Entity a) { var res = new FunctionEntity("sin"); res.Children.Add(a); return res; }
Подвешивание в репе реализовано тут.
Отлично, мы составили дерево выражений.
Подстановка переменной
Здесь все предельно просто. У нас есть Entity — мы проверяем является ли он сам переменной, если да, возвращаем значение, иначе — бежим по детям.
В этом огромном 48-строчном файле реализована столь сложная функция.
Вычисление значения
Собственно то, ради чего все это. Здесь мы по идее должны добавить в Entity какой-то такой метод
public Entity Eval() { if (IsLeaf) { return this; } else return MathFunctions.InvokeEval(Name, Children); }
Листик без изменений, а для всего остального у нас кастомное вычисление. Опять же, приведу лишь пример:
public static Entity Eval(List<Entity> args) { MathFunctions.AssertArgs(args.Count, 1); var r = args[0].Eval(); if (r is NumberEntity) return new NumberEntity(Number.Sin((r as NumberEntity).Value)); else return r.Sin(); }
Если аргумент — число, то произведем численную функцию, иначе — вернем как было.
Number?
Это самая простая единица, число. Над ним можно проводить арифметические операции. По умолчанию оно комплексное. Также у него определены такие операции как Sin, Cos, и некоторые другие.
Если интересно, Number описан тут.
Производная
Численно производную посчитать может кто угодно, и такая функция пишется поистине в одну строку:
public double Derivative(Func<double, double> f, double x) => (f(x + 1.0e-5) - f(x)) * 1.0e+5;
Но разумеется нам хочется аналитическую производную. Так как у нас уже есть дерево выражений, мы можем рекурсивно заменить каждый узел в соответствии с правилом дифференциирования. Работать оно должно примерно так:
Вот, к примеру, как реализованна сумма в моем коде:
public static Entity Derive(List<Entity> args, VariableEntity variable) { MathFunctions.AssertArgs(args.Count, 2); var a = args[0]; var b = args[1]; return a.Derive(variable) + b.Derive(variable); }
А вот произведение
public static Entity Derive(List<Entity> args, VariableEntity variable) { MathFunctions.AssertArgs(args.Count, 2); var a = args[0]; var b = args[1]; return a.Derive(variable) * b + b.Derive(variable) * a; }
А вот сам по себе обход:
public Entity Derive(VariableEntity x) { if (IsLeaf) { if (this is VariableEntity && this.Name == x.Name) return new NumberEntity(1); else return new NumberEntity(0); } else return MathFunctions.InvokeDerive(Name, Children, x); }
Это метод Entity. И как видим, что у листа всего два состояния — либо это переменная, по которой мы дифференциируем, тогда ее производная равна 1, либо это константа (число либо VariableEntity), тогда ее производная 0, либо узел, тогда идет отсылка по имени (InvokeDerive обращается к словарю функций, где и находится нужная (например сумма или синус)).
Заметьте, я здесь не оставляю что-то типа dy/dx и сразу говорю, что производная от переменной не по которой мы дифференциируем равна 0. А вот здесь сделано по-другому.
Все дифференциирование описано в одном файле, а больше и не надо.
Упрощение выражения. Паттерны
Упрощение выражения в общем случае в принципе нетривиально. Ну например, какое выражение проще:
или ? Но мы придерживаемся каких-то представлений, и на основе них хотим сделать те правила, которые точно упрощают выражение. Можно при каждом Eval писать, что если у нас сумма, а дети — произведения, то переберем четыре варианта, и если где-то что-то равно, вынесем множитель… Но так делать конечно же не хочется. Поэтому можно догадаться до системы правил и паттернов. Итак, что мы хотим? Примерно такой синтаксис:
{ any1 / (any2 / any3) -> any1 * any3 / any2 }, { const1 * var1 + const2 * var1 -> (const1 + const2) * var1 }, { any1 + any1 * any2 -> any1 * (Num(1) + any2) },
Вот пример дерева, в котором нашлось поддерево (обведено в зеленый), отвечающее паттерну any1 + const1 * any1 (найденное any1 обведено в оранжевый).
Как видим, иногда нам важно, что одна и та же сущность должна повторяться, например чтобы сократить выражение x + a * x нам необходимо, чтобы и там и там был x, ведь x + a * y уже не сокращается. Поэтому нам нужно сделать алгоритм, который не только проверяет, что дерево соответсвует паттерну, но и
- Проверять, что одинаковые паттерновые Entity соответствуют одинаковым Entity.
- Записывать, что чему соответствует, чтобы потом подставить.
Точка входа выглядит примерно так:
internal Dictionary<int, Entity> EqFits(Entity tree) { var res = new Dictionary<int, Entity>(); if (!tree.PatternMakeMatch(this, res)) return null; else return res; }
А в tree.PaternMakeMatch мы рекурсивно наполняем словарь ключами и их значениями. Вот пример списка самих паттерных Entity:
static readonly Pattern any1 = new Pattern(100, PatType.COMMON); static readonly Pattern any2 = new Pattern(101, PatType.COMMON); static readonly Pattern const1 = new Pattern(200, PatType.NUMBER); static readonly Pattern const2 = new Pattern(201, PatType.NUMBER); static readonly Pattern func1 = new Pattern(400, PatType.FUNCTION);
Когда мы будем писать any1 * const1 — func1 и так далее, у каждой ноды будет номер — это и есть ключ. Иначе говоря, при заполнении словаря, ключами выступят как раз эти номера: 100, 101, 200, 201, 400… А при постройке дерева мы будем смотреть на значение, соответствующее ключу, и подставлять его.
Реализовано тут.
Упрощение. Сортировка дерева
В статье, к которой я уже обращался, автор решил сделать просто, и отсортировал практически по хешу дерева. Ему удалось сократить a и -a, b + c + b превратить 2b + c. Но мы, конечно, хотим и чтобы (x + y) + x * y — 3 * x сокращалось, и в целом более сложные штуки.
Паттерны не работают?
Вообще, то, что мы сделали до этого, паттерны — чудовищно замечательная штука. Она позволит вам сокращать и разность квадратов, и сумму квадрата синуса и косинуса, и другие сложные штуки. Но элементарную пальму, ((((x + 1) + 1) + 1) + 1), она не сократит, ведь здесь главное правило — коммутативность слагаемых. Поэтому первый шаг — вычленить «линейных детей».
«Линейные дети»
Собственно для каждой ноды суммы или разности (и, кстати, произведения/деления) мы хотим получить список слагаемых (множителей).
Это в принципе несложно. Пусть функция LinearChildren(Entity node) возвращает список, тогда мы смотрим на child in node.Children: если child — это не сумма, то result.Add(child), иначе — result.AddRange(LinearChildren(child)).
Не самым красивым образом реализовано тут.
Группировка детей
Итак, у нас есть список детей, но что дальше? Допустим, у нас есть sin(x) + x + y + sin(x) + 2 * x. Очевидно, что наш алгоритм получит пять слагаемых. Далее мы хотим сгруппировать по похожести, например, x похож на 2 * x больше, чем на sin(x).
Вот хорошая группировка:
Так как в ней паттерны дальше справятся с преобразованием 2*x + x в 3*x.
То есть мы сначала группируем по некоторому хешу, а затем делаем MultiHang — преобразование n-арного суммирования в бираное.
Хеш узла
С одной стороны,
и следует поместить в одну группу. С другой стороны, при наличии помещать в одну группу с бессмысленно.Мысли
Если подумать, то  . Хотя мне кажется, это практически не проще, и уж точно не нужно. Да и вообще, упрощение — вещь ни разу неочевидная, и уж это точно не первое, что стоит писать при написании «калькулятора».
. Хотя мне кажется, это практически не проще, и уж точно не нужно. Да и вообще, упрощение — вещь ни разу неочевидная, и уж это точно не первое, что стоит писать при написании «калькулятора».
. Хотя мне кажется, это практически не проще, и уж точно не нужно. Да и вообще, упрощение — вещь ни разу неочевидная, и уж это точно не первое, что стоит писать при написании «калькулятора».Поэтому мы реализовываем многоуровневую сортировку. Сначала мы делаем вид, что
— одно и то же. Посортировали, успокоились. Потом делаем вид, что можно помещать только с другими . И вот уже наши и наконец объединились. Реализовано достаточно просто:internal string Hash(SortLevel level) { if (this is FunctionEntity) return this.Name + "_" + string.Join("_", from child in Children select child.Hash(level)); else if (this is NumberEntity) return level == SortLevel.HIGH_LEVEL ? "" : this.Name + " "; else if (this is VariableEntity) return "v_" + Name; else return (level == SortLevel.LOW_LEVEL ? this.Name + "_" : "") + string.Join("_", from child in Children where child.Hash(level) != "" select child.Hash(level)); }
Как видим, функция по-любому влияет на сортировку (разумеется, ведь
с вообще никак в общем случае не связана). Как и переменная, с ну никак не получится смешать. А вот константы и операторы учитываются не на всех уровнях. В таком порядке идет сам процесс упрощенияpublic Entity Simplify(int level) { // Сначала мы делаем самую простую симплификацю: вычисление значений там, где это возможно, умножение на ноль и т. д. var stage1 = this.InnerSimplify(); Entity res = stage1; for (int i = 0; i < level; i++) { // Этот блок ответственнен за сортировку. Сначала мы группируем что-то типа x и x+1 (переменные и функции), затем что-то типа x-1 и x+1 (переменные, функции и константы), затем что-то типа x+1 и x+1 (учитывается все). switch (i) { case 0: res = res.Sort(SortLevel.HIGH_LEVEL); break; case 2: res = res.Sort(SortLevel.MIDDLE_LEVEL); break; case 4: res = res.Sort(SortLevel.LOW_LEVEL); break; } // Здесь мы заменяем паттерны. res = TreeAnalyzer.Replace(Patterns.CommonRules, res).InnerSimplify(); } return res; }
Мысли
Самая ли это лучшая реализация? Пихните в личные сообщения, может быть будут идеи получше. Я долго думал, как сделать это макимально красиво, хотя по моему мнению, до «красиво» здесь далеко.
Дерево сортирую тут.
«Компиляция» функций
В кавычках — так как не в сам IL код, а лишь в очень быстрый набор инструкций. Но зато очень просто.
Проблема Substitute
Чтобы посчитать значение функции, нам достаточно вызвать подстановку переменной и eval, например
var x = MathS.Var("x"); var expr = x * x + 3; var result = expr.Substitute(x, 5).Eval();
Но это работает медленно, около 1.5 микросекунды на синус.
Инструкции
Чтобы ускорить вычисление, мы делаем вычисление функции на стеке, а именно:
1) Придумываем класс FastExpression, у которого будет список инструкций
2) При компиляции инструкции складываются в стек в обратном порядке, то есть если есть функция x * x + sin(x) + 3, то инструкции будут примерно такими:
PUSHVAR 0 // Подстановка переменной номер 0 - x CALL 6 // Вызов функции номер 6 - синуса PUSHCONST 3 CALL 0 // Вызов функции номер 0 - суммы PUSHVAR 0 PUSHVAR 0 CALL 2 CALL 0
Далее при вызове мы прогоняем эти инструкции и возвращаем Number.
Пример выполнения инструкции суммы:
internal static void Sumf(Stack<Number> stack) { Number n1 = stack.Pop(); Number n2 = stack.Pop(); stack.Push(n1 + n2); }
Вызов синуса сократился с 1500нс до 60нс (системный Complex.Sin работает за 30нс).
В репе реализовано тут.
Фух, вроде бы пока все. Хотя рассказать еще есть о чем, но мне кажется объем для одной статьи достаточный. Интересно ли кому-нибудь продолжение? А именно: парсинг из строки, форматирование в латех, определенный интеграл, и прочие плюшки.
Ссылка на репозиторий со всем кодом, а также тестами и самплами.
Мысли
Вообще-то я продолжаю работать над этим проектом. Распространяется он под MIT (то есть делайте с ним что хотите), и он никогда не станет ни закрытым, ни коммерческим. Более того, если есть идеи для улучшения и вклада — pull-реквесты очень приветствуются.
Спасибо за внимание!
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Делать следующую часть?
77.65%Да, делать132
8.82%Нет, не стоит15
38.82%С Новым Годом!66
Проголосовали 170 пользователей. Воздержались 36 пользователей.

