Это вторая часть статьи про numba. В первой было историческое введение и краткая инструкция по эксплуатации numba. Здесь я привожу слегка модифицированный код задачи из статьи про хаскелл «Быстрее, чем C++; медленнее, чем PHP» (там сравнивается производительность реализаций одного алгоритма на разных языках/компиляторах) с более детальными бенчмарками, графиками и пояснениями. Сразу оговорюсь, что я видел статью Ох уж этот медленный C/C++ и, скорее всего, если внести в код на си эти правки, картина несколько изменится, но даже в этом случае то, что питон способен превысить скорость си хотя бы в таком варианте, само по себе является примечательным.

Заменил питоновский список на numpy-массив (и, соответственно, v0[:] на v0.copy(), потому что в numpy a[:] возвращает view вместо копирования).
Чтобы понять характер поведения быстродействия сделал «развёртку» по количеству элементов в массиве.
В питоновском коде заменил time.monotonic на time.perf_counter, поскольку он точнее (1us против 1ms у monotonic).
Поскольку в numba используется jit-компиляция, эта самая компиляция должна когда-то происходить. По умолчанию она происходит при первом вызове функции и неизбежно влияет на результаты бенчмарков (правда, если берётся мин время из трёх запусков этого можно не заметить), а также сильно ощущается в практическом использовании. Есть несколько способов борьбы с этим явлением:
1) кэшировать результаты компиляции на диск:
@njit(cache=True) def lev_dist(s1: AnyStr, s2: AnyStr) -> int:
тогда компиляция произойдёт при первом вызове программы, а при последующих будет подтягиваться с диска.
2) указывать сигнатуру
Компиляция будет происходить в момент, когда питон парсит определение функции, и первый запуск будет уже быстрым.
В оригинале передаётся строка (точнее, bytes), но поддержка строк добавлена недавно, поэтому сигнатура достаточно монструозная (см. ниже). Обычно сигнатуры пишутся попроще:
@njit(nb.int64(nb.uint8[:], nb.uint8[:])) def lev_dist(s1, s2):
но тогда придётся заранее преобразовать bytes в numpy-массив:
s1_py = [int(x) for x in b"a" * 15000] s1 = np.array(s1_py, dtype=np.uint8)
или
s1 = np.full(15000, ord('a'), dtype=np.uint8)
А можно оставить bytes как есть и указать сигнатуру вот в таком виде:
@njit(nb.int64(nb.bytes(nb.uint8, nb.1d, nb.C), nb.bytes(nb.uint8, nb.1d, nb.C))) def lev_dist(s1: AnyStr, s2: AnyStr) -> int:
Скорость выполнения для bytes и numpy-массива из uint8 (в данном случае) одинаковая.
3) подогревать кэш
s1 = b"a" * 15 # 15 вместо 15000 s2 = s1 s3 = b"b" * 15 exec_time = -clock() print(lev_dist(s1, s2)) print(lev_dist(s1, s3)) exec_time += clock() print(f"Finished in {exec_time:.3f}s", file=sys.stderr)
Тогда компиляция произойдёт на первом вызове, а второй уже будет быстрым.
#!/usr/bin/env python3 import sys import time from numba import njit import numpy as np, numba as nb from time import perf_counter as clock @njit(nb.int64(nb.uint8[::1], nb.uint8[::1])) def lev_dist(s1, s2): m = len(s1) n = len(s2) # Edge cases. if m == 0: return n elif n == 0: return m v0 = np.arange(n + 1) v1 = v0.copy() for i, c1 in enumerate(s1): v1[0] = i + 1 for j, c2 in enumerate(s2): subst_cost = v0[j] if c1 == c2 else (v0[j] + 1) del_cost = v0[j + 1] + 1 ins_cost = v1[j] + 1 min_cost = min(subst_cost, del_cost, ins_cost) v1[j + 1] = min_cost v0, v1 = v1, v0 return v0[n] if __name__ == "__main__": fout = open('py.txt', 'w') for n in 1000, 2000, 5000, 10000, 15000, 20000, 25000: s1 = np.full(n, ord('a'), dtype=np.uint8) s2 = s1 s3 = np.full(n, ord('b'), dtype=np.uint8) exec_time = -clock() print(lev_dist(s1, s2)) print(lev_dist(s1, s3)) exec_time += clock() print(f'{n} {exec_time:.6f}', file=fout)
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <time.h> static long lev_dist (const char *s1, unsigned long m, const char *s2, unsigned long n) { // unsigned long m, n; unsigned long i, j; long *v0, *v1; long ret, *temp; /* Edge cases. */ if (m == 0) { return n; } else if (n == 0) { return m; } v0 = malloc (sizeof (long) * (n + 1)); v1 = malloc (sizeof (long) * (n + 1)); if (v0 == NULL || v1 == NULL) { fprintf (stderr, "failed to allocate memory\n"); exit (-1); } for (i = 0; i <= n; ++i) { v0[i] = i; } memcpy (v1, v0, sizeof(long) * (n + 1)); for (i = 0; i < m; ++i) { v1[0] = i + 1; for (j = 0; j < n; ++j) { const long subst_cost = (s1[i] == s2[j]) ? v0[j] : (v0[j] + 1); const long del_cost = v0[j + 1] + 1; const long ins_cost = v1[j] + 1; #if !defined(__GNUC__) || defined(__llvm__) if (subst_cost < del_cost) { v1[j + 1] = subst_cost; } else { v1[j + 1] = del_cost; } #else v1[j + 1] = (subst_cost < del_cost) ? subst_cost : del_cost; #endif if (ins_cost < v1[j + 1]) { v1[j + 1] = ins_cost; } } temp = v0; v0 = v1; v1 = temp; } ret = v0[n]; free (v0); free (v1); return ret; } int main () { char s1[25001], s2[25001], s3[25001]; int lengths[] = {1000, 2000, 5000, 10000, 15000, 20000, 25000}; FILE *fout; fopen_s(&fout, "c.txt", "w"); for(int j = 0; j < sizeof(lengths)/sizeof(lengths[0]); j++){ int len = lengths[j]; int i; clock_t start_time, exec_time; for (i = 0; i < len; ++i) { s1[i] = 'a'; s2[i] = 'a'; s3[i] = 'b'; } s1[len] = s2[len] = s3[len] = '\0'; start_time = clock (); printf ("%ld\n", lev_dist (s1, len, s2, len)); printf ("%ld\n", lev_dist (s1, len, s3, len)); exec_time = clock () - start_time; fprintf(fout, "%d %.6f\n", len, ((double) exec_time) / CLOCKS_PER_SEC); fprintf (stderr, "Finished in %.3fs\n", ((double) exec_time) / CLOCKS_PER_SEC); } return 0; }
Сравнение проводил под windows (windows 10 x64, python 3.7.3, numba 0.45.1, clang 9.0.0, intel m5-6y54 skylake): и под linux (debian 4.9.30, python 3.7.4, numba 0.45.1, clang 9.0.0).
По x размер массива, по y время в секундах.
Windows, линейный масштаб:

Windows, логарифмический масштаб:

Linux, линейный масштаб:
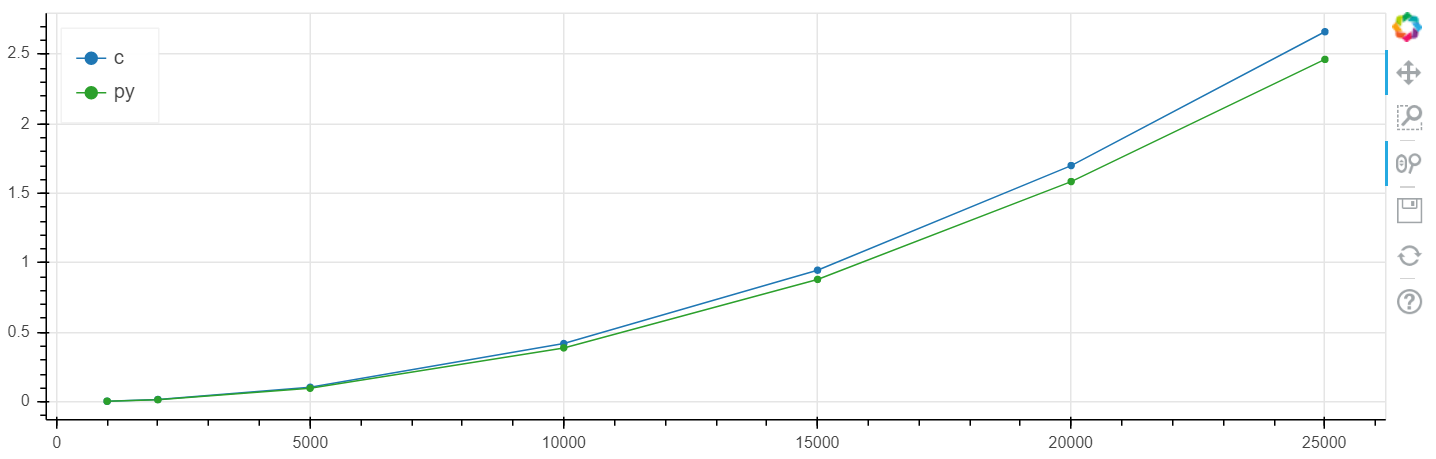
Linux, логарифмический масштаб

На данной задаче получился прирост в скорости по сравнению с clang на уровне нескольких процентов, что в общем-то выше статистической ошибки.
Я неоднократно проводил это сравнение на разных задачах и, как правило, если numba может что-то разогнать, она это разгоняет до скорости, в пределах погрешности совпадающей со скоростью C (без использования ассемблерных вставок).
Повторюсь, что если внести в код на С правки из Ох уж этот медленный C/C++ ситуация может измениться.
Буду рад услышать вопросы и предложения в комментариях.
P.S. При указании сигнатуры массивов лучше задать явно способ чередования строк/столбцов:
чтобы numba не раздумывала 'C' (си) это или 'A'(автораспознавание си/фортран) — почему-то это влияет на быстродействие даже для одномерных массивов, для этого есть вот такой оригинальный синтаксис: uint8[:,:] это 'A' (автоопределение), nb.uint8[:, ::1] – это 'C' (си), np.uint8[::1, :] – это 'F' (фортран).
@njit(nb.int64(nb.uint8[::1], nb.uint8[::1])) def lev_dist(s1, s2):

