Создав более прозрачные нейросети, мы можем начать излишне доверять им. Возможно, стоит изменить методы, при помощи которых они объясняют свою работу.

Апол Эсан однажды на пробу прокатился в робомобиле от Uber. Пассажирам, вместо того, чтобы волноваться по поводу пустого сиденья водителя, предлагалось наблюдать за «успокаивающим» экраном, на котором было показано, как видит дорогу автомобиль: опасности отрисовывались оранжевым и красным, безопасные зоны – тёмно-синим.
Для Эсана, изучающего взаимодействие людей с ИИ в Технологическом институте Джорджии в Атланте, сообщение, которое пытались донести до него, было понятным: «Не беспокойтесь – вот причины, по которым машина ведёт себя именно так». Однако что-то в чуждом изображении улицы не успокаивало, а наоборот, подчёркивало странность происходящего. Эсан задумался: что, если бы робомобиль мог по-настоящему объясниться?
Успех глубокого обучения основан на неуверенном ковырянии в коде: лучшие нейросети подстраивают и адаптируют, чтобы улучшать их дальше, а практические результаты обгоняют их теоретическое понимание. В итоге, подробности того, как работает обученная модель, обычно неизвестны. Мы уже привыкли считать ИИ чёрным ящиком.
И большую часть времени нас это устраивает – когда дело касается таких задач, как игра в го, перевод текста или подборка очередного сериала с Netflix. Но если ИИ используется для помощи в принятии решений в таких областях, как обеспечение правопорядка, медицинская диагностика, робомобили – тогда нам нужно понять, как именно он принимает свои решения, и знать, когда они оказываются неверными.
Людям требуется возможность не согласиться с автоматическим решением или отвергнуть его, говорит Айрис Хоули, специалист по информатике из Уильямсовского колледжа в Уильямстауне, Массачусетс. А без этого люди будут противостоять этой технологии. «Уже сейчас можно наблюдать, как это происходит, в виде реакции людей на системы распознавания лиц», — говорит она.
Эсан входит в небольшую, но растущую группу исследователей, пытающихся улучшить способность ИИ объясняться, и помочь нам заглянуть в чёрный ящик. Цель создания т.н. интерпретируемого или объясняемого ИИ (ИИИ) состоит в том, чтобы помочь людям понять, на каких признаках данных нейросеть реально обучается – и решить, получилась ли итоговая модель точной и непредвзятой.
Одно из решений – создать системы машинного обучения (МО), демонстрирующие внутренности своей работы – т.н. аквариумный ИИ, вместо ИИ в чёрном ящике. «Аквариумные» модели обычно представляют собой кардинально упрощённые версии НС, в которой легче отслеживать то, как отдельные части данных влияют на модель.
«В этом сообществе есть люди, призывающие использовать аквариумные модели в любой ситуации с высокими ставками, — говорит Дженнифер Уортман Вон, специалист по информатике из Microsoft Research. – И в целом я согласна». Простые аквариумные модели могут работать так же хорошо, как и более сложные НС, на определённых типах структурированных данных, типа таблиц или статистики. И в некоторых случаях этого достаточно.
Однако всё зависит от области работы. Если мы хотим обучаться на таких нечётких данных, как изображения или текст, нам не остаётся ничего другого, кроме как использовать глубокие – а значит, непрозрачные – нейросети. Способность таких НС находить осмысленную связь между огромным количеством несопоставимых признаков связана с их сложностью.
И даже тут аквариумное МО может помочь. Одно решение предлагает проходить данные по два раза, обучая несовершенную аквариумную модель в виде отладочного шага, чтобы отловить потенциальные ошибки, которые вам захочется исправить. После чистки данных можно обучать и более точную модель ИИ в чёрном ящике.
Однако такой баланс сложно соблюсти. Слишком большая прозрачность может вызвать информационную перегрузку. В исследовании от 2018 года, где изучалось взаимодействие неподготовленных пользователей с инструментами МО, Вон обнаружила, что прозрачные модели могут на самом деле усложнять поиск и исправление ошибок модели.
Ещё один подход – включать в работу визуализацию, показывающую несколько ключевых свойств модели и лежащие в основе данные. Идея в том, чтобы на глаз определять серьёзные проблемы. К примеру, модель может слишком сильно полагаться на определённые признаки, что может быть сигналом к появлению предвзятости.
Эти инструменты визуализации стали крайне популярными за небольшое время своего существования. Но есть ли от них польза? В первом исследовании такого рода Вон с командой попытались ответить на этот вопрос, а в итоге обнаружили несколько серьёзных проблем.
Команда взяла два популярных интерпретирующих инструмента, дающих обзор модели при помощи графиков и диаграмм, где отмечается, на какие данные в основном обращала внимание МО модель при обучении. Из компании Microsoft наняли одиннадцать профессионалов в области ИИ с разным образованием, должностями и опытом. Они приняли участие в имитации взаимодействия с МО-моделью, обученной на данных по национальному доходу, взятых из переписи населения США 1994 года. Эксперимент был специально разработан для имитации того, как специалисты по работе с данными используют интерпретирующие инструменты при выполнении своих повседневных задач.
Команда обнаружила нечто поразительное. Да, иногда инструменты помогали людям найти недостающие значения в данных. Однако вся эта полезность померкла по сравнению со склонностью к чрезмерному доверию к визуализациям, а также к ошибкам в их понимании. Иногда пользователи даже не могли описать, что именно демонстрируют визуализации. Это приводило к некорректным предположениям касательно набора данных, моделей и самих интерпретирующих инструментов. А также внушило ложную уверенность в инструментах и вызвало энтузиазм в применении данных моделей на практике, хотя участникам иногда казалось, что что-то идёт не так. Что неприятно, это работало, даже когда выходные данные были специально подправлены таким образом, чтобы объяснения работы не имели никакого смысла.
Чтобы подтвердить сделанные открытия, исследователи провели онлайн-опрос среди 200 профессионалов в области МО, привлечённых через списки рассылки и соцсети. Они обнаружили сходную путаницу и необоснованную уверенность.
Что ещё хуже, многие участники опроса готовы были использовать визуализации для принятия решения по внедрению моделей, несмотря на признание того, что они не понимают лежащую в их основе математику. «Особенно удивительно было видеть, как люди оправдывали странности в данных, придумывая объяснения для этого, — говорит Харманпреет Каур из Мичиганского университета, соавтор исследования. – Искажение автоматизации – очень важный не рассмотренный нами фактор».
Ох уж это искажение автоматизации. Иначе говоря, люди склонны доверять компьютерам. И это не новое явление. От автопилотов самолётов до систем проверки правописания, везде, согласно исследованиям, люди часто склонны доверять решениям систем, даже когда те оказываются очевидно неверными. Но когда это происходит с инструментами, специально предназначенными для исправления именно этого явления, у нас появляется ещё большая проблема.
Что можно с этим сделать? Некоторые считают, что часть проблем первой волны ИИИ связана с тем, что в ней доминируют исследователи МО, большая часть которых – это эксперты, использующие ИИ-системы. Тим Миллер из Мельбурнского университета, изучающий использование людьми ИИ-систем: «Это психбольница под управлением психов».
Это и осознал Эсан на заднем сиденье автомобиля Uber без водителя. Понять, что делает автоматизированная система – и увидеть, где она ошибается — будет легче, если она будет объяснять свои действия так, как это делал бы человек. Эсан и его коллега, Марк Ридл, разрабатывают систему МО, которая автоматически генерирует подобные объяснения на естественном языке. В раннем прототипе парочка взяла нейросеть, обучившуюся играть в классическую игру из 1980-х, Frogger, и обучила её давать объяснения перед каждым ходом.
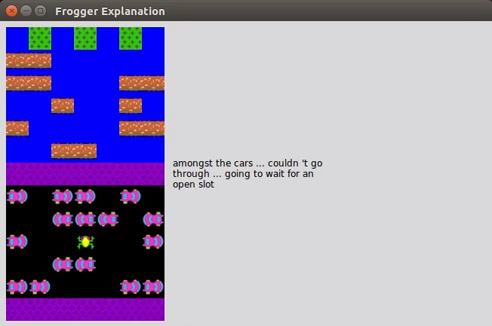
среди машин… не могу пройти… подожду промежутка…
Для этого они показали системе множество примеров того, как люди играют в эту игру, комментируя действия вслух. Затем они взяли нейросеть, переводящую с одного языка на другой, и адаптировали её для перевода игровых действий в объяснения на естественном языке. И теперь, когда НС видит в игре действие, она «переводит» его в объяснение. В итоге получился ИИ, играющий во Frogger, при каждом движении говорящий такие вещи, как «сдвинусь налево, чтобы оказаться сзади синего грузовика».
Работа Эсана и Ридла – это только начало. Во-первых, непонятно, всегда ли МО-система сможет объяснять свои действия на естественном языке. Возьмём AlphaZero от DeepMind, играющую в настольную игру го. Одна из наиболее удивительных особенностей этой программы состоит в том, что она может сделать выигрышный ход, о котором игроки-люди не могли бы и подумать в тот конкретный момент игры. Если бы AlphaZero смогла объяснить свои ходы, было бы это объяснение осмысленным?
Причины могут помочь вне зависимости от того, понимаем мы их или нет, говорит Эсан: «Цель ИИИ с упором на человека – не просто сделать так, чтобы пользователь согласился с тем, что говорит ИИ – но и вызвать размышления». Ридл вспоминает, как смотрел трансляцию матча между ИИ от DeepMind и корейским чемпионом го Ли Седолем. Комментаторы рассуждали о том, что видит и думает AlphaZero. «Но AlphaZero работает не так, — говорит Ридл. – Однако мне казалось, что комментарии были необходимы для понимания происходящего».
И хотя эта новая волна исследователей ИИИ согласна, что если ИИ-системами будет пользоваться больше людей, то эти люди должны с самого начала принимать участие в проектировании – а разным людям требуются разные объяснения. Это подтверждает и новое исследование Хаули и её коллег, в котором они показали, что способность людей понимать интерактивную или статическую визуализацию зависит от их уровня образования. Представьте себе ИИ, диагностирующий рак, говорит Эсан. Хотелось бы, чтобы объяснение, которое он даёт онкологу, отличалось от объяснения для пациента.
В конечном счёте мы хотим, чтобы ИИ мог объясняться не только перед учёными, работающими с данными и докторами, но и перед полицейскими, использующими систему распознавания образов, учителями, использующими аналитические программы в школе, студентами, пытающимися понять работу лент в соцсетях – и перед любым человеком на заднем сиденье робомобиля. «Мы всегда знали, что люди склонны чрезмерно доверять технологиям, и особенно это верно для ИИ-систем, — говорит Ридл. – Чем чаще вы называете систему умной, тем больше люди уверены в том, что она умнее людей».
Объяснения, которые мог бы понять каждый, смогут разрушить эту иллюзию.

