Считанные дни остаются до старта нового потока по курсу “MS SQL Server разработчик”. В преддверии старта курса продолжаем делиться с вами полезным материалом.
За годы работы с SQL Server я обнаружила, что есть несколько тем, которые часто игнорируются. Их что боятся, думают, что они сложные или что они не такие важные. Также есть мнение, что эти знания не нужны, так как SQL Server "все делает за меня". Я слышала это об индексах. Я слышала это о статистике.

Итак, давайте поговорим, почему статистика важна и почему знание о том, что она важна, поможет вам существенно повлиять на производительность ваших запросов.
Есть несколько случаев, когда статистика обрабатывается автоматически:
- SQL Server автоматически создает статистику для индексов
- SQL Server автоматически создает статистику для столбцов, когда ему требуется больше информации для оптимизации запроса
- ВАЖНО! Это происходит только тогда, когда включен параметр базы данных auto_create_statistics. Этот параметр включен по умолчанию во всех версиях и редакциях SQL Server. Однако иногда встречаются рекомендации его выключить. Я категорически против этого.
- SQL Server автоматически обновляет статистику для индексов и столбцов, когда она становится “неактуальной”, если это необходимо для оптимизации запроса.
- ВАЖНО! Это происходит только тогда, когда включен параметр базы данных auto_update_statistics. Этот параметр включен по умолчанию во всех версиях и редакциях SQL Server. Иногда также встречаются рекомендации его выключить. Обычно я против этого. Узнать больше об автоматическом обновлении вы можете в статье (англ.) Updating SQL Server Statistics Part I – Automatic Updates, а про ручное обновление статистики (но с помощью более избирательного подхода) в статье Updating SQL Server Statistics Part II – Scheduled Updates.
Однако, важно знать, что, хотя статистика обрабатывается автоматически, этот процесс н�� всегда работает так хорошо как вы ожидаете. Для действительно эффективной оптимизации SQL Server’у нужны определенные шаблоны и наборы данных. Для понимания этого, я хочу немного поговорить о доступе к данным и о процессе оптимизации.
Доступ к данным
Обычно, когда вы отправляете запрос к SQL Server для получения данных, вы пишете код на Transact-SQL в виде простого SELECT или, возможно, в виде хранимой процедуры (да, есть и другие варианты). Однако главное в том, что вы говорите какой набор данных вы хотите получить, а не описываете то, как эти данные должны быть извлечены. Как же SQL Server “доберется“ до данных?
Обработка данных
В получении и обработке данных SQL Server’у помогает статистика. Статистика предоставляет информацию о том, какой объем данных нужно будет обработать при выполнении запроса. Если нужно будет обработать небольшой объем данных, то обработка может быть проще (возможно, другим способом), чем если бы запрос обрабатывал миллионы строк.
В частности, SQL Server использует оптимизатор запросов на основе стоимости (cost based). Существуют и другие варианты оптимизации, но сегодня, чаще всего, используются оптимизаторы, основанные на стоимости. Почему? Оптимизаторы, основанные на стоимости, используют информацию о запрашиваемых данных, чтобы сформировать более эффективные, оптимальные и целенаправленные планы, с учетом информации об этих данных. Как правило, этот процесс работает хорошо. Хотя с планами, которые сохраняются для последующих выполнений (кэшированные планы), могут быть проблемы. Тем не менее, в других способах оптимизации есть еще более серьезные недостатки.
ВАЖНО! Я здесь не говорю о кеше планов… Я говорю о начальном процессе оптимизации и о том, как SQL Server определяет, какой объем данных ему надо будет получить. Последующее выполнение кэшированного плана может привести к дополнительным проблемам с ним (известными как parameter sniffing). Об этом много написано в других статьях.
Чтобы объяснить оптимизацию на основе стоимости, позвольте мне рассказать о других видах оптимизации. Это поможет понять преимущества стоимостной оптимизации.
Оптимизация на уровне синтаксиса
SQL Server может обработать запрос, используя только его текст и не тратить время на поиск наилучшего порядка обработки таблиц. Оптимизатор может просто соединить (join) ваши таблицы в том порядке, в котором вы их указали во FROM. Хотя для того чтобы начать выполнять запрос не требуется никаких затрат, но выполнение самого запроса может быть далеко не оптимальным. В общем случае, соединение больших таблиц с маленькими менее оптимально, чем соединение маленьких таблиц с большими. Давайте посмотрим на эти два примера:
USE [WideWorldImporters];
GO
SET STATISTICS IO ON;
GO
SELECT [so].*, [li].*
FROM [sales].[Orders] AS [so]
JOIN [sales].[OrderLines] AS [li] ON [so].[OrderID] = [li].[OrderID]
WHERE [so].[CustomerID] = 832 AND [so].[SalespersonPersonID] = 2
OPTION (FORCE ORDER);
GO
SELECT [so].*, [li].*
FROM [sales].[OrderLines] AS [li]
JOIN [sales].[Orders] AS [so] ON [so].[OrderID] = [li].[OrderID]
WHERE [so].[CustomerID] = 832 AND [so].[SalespersonPersonID] = 2
OPTION (FORCE ORDER);
GOСравните стоимости планов. Второй запрос значительно дороже.
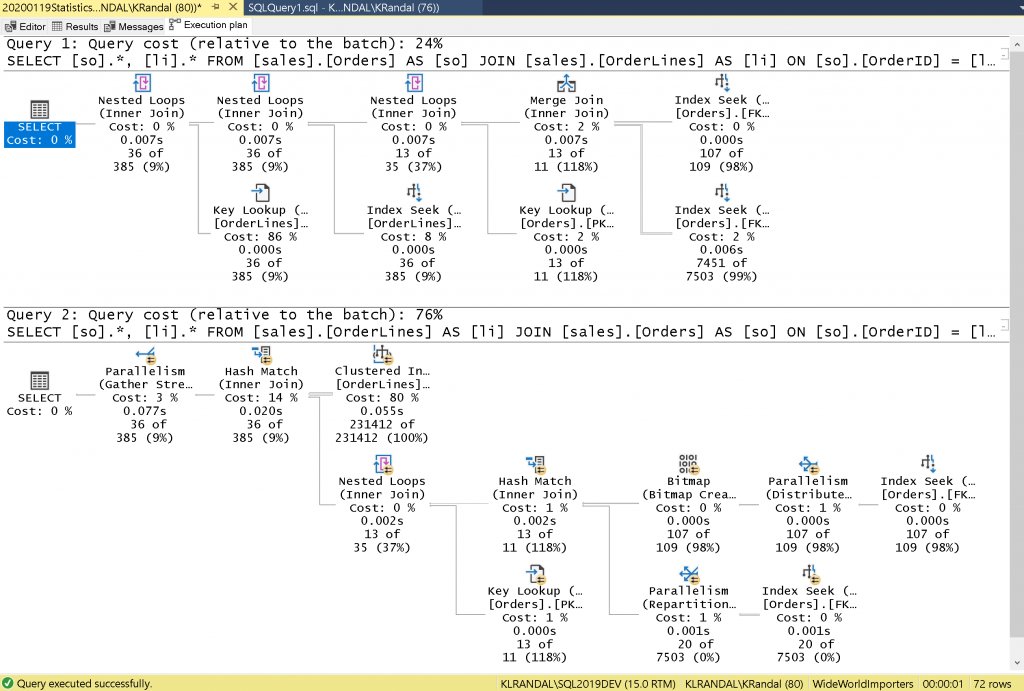
Стоимость од��наковых запросов с FORCE ORDER с разным порядком соединения.
Да, это чрезмерное упрощение способов оптимизации соединения, но дело в том, что вы вряд ли укажете самостоятельно оптимальный порядок таблиц во FROM. Хорошая новость в том, что если у вас есть проблемы с производительностью, то вы можете применить такие оптимизации, как соединение таблиц в указанном порядке (см. пример выше). Есть много других хинтов (hint), которые вы можете использовать:
- QUERY Hints (принудительное использование уровня параллелизма [MAXDOP], оптимизация запроса для быстрого получения первых строк, а не всего набора данных с помощью FAST n и т.д.)
- TABLE Hints (принудительное использование индекса [INDEX], поиска в индексе [FORCESEEK] и т.д.)
- JOIN Hints (принудительное использование типа соединения LOOP / MERGE / HASH)
Надо сказать, что использование хинтов всегда должно быть последним способом оптимизации. Следует попробовать другие способы оптимизации, прежде чем использовать хинты. Применяя их, вы не позволяете SQL Server оптимизировать ваши запросы при добавлении или изменении индексов, при добавлении или изменении статистики и при обновлении SQL Server. Конечно, если только вы не задокументировали используемые хинты и не протестировали их, чтобы убедиться, что они останутся полезными для вашего запроса после выполнения заданий по обслуживанию БД, модификации данных и обновлений SQL Server. Честно говоря, �� не вижу, чтобы это делалось так часто, как хотелось бы. Большинство хинтов добавляются так, как будто они всегда будут работать отлично, и остаются в запросе до тех пор, пока не возникнут серьезные проблемы.
Всегда важно посмотреть, на другие способы улучшения производительности, прежде чем применять хинты. Да, легко поставить хинт сейчас, но время, которое вы потратите на поиск других решений, может окупиться сполна в долгосрочной перспективе.
Для проблем с конкретным запросом с его конкретными значениями стоит посмотреть:
- Является ли статистика точной/актуальной? Исправит ли обновление статистики проблему?
- Статистика основана на частичной выборке? Исправит ли FULLSCAN проблему?
- Можете ли вы переписать запрос и улучшить план?
- Есть ли плохие условия поиска? Столбцы всегда должны находиться с одной стороны выражения:
- Так хорошо:
MonthlySalary > expression / 12 - Так плохо:
MonthlySalary * 12 > expression
- Так хорошо:
- Есть ли проблемы с транзитивностью, с которыми вы можете помочь SQL Server’у? Это интересный вопрос, и он становится все более проблематичным с возрастанием количества таблиц. Добавление, казалось бы, избыточного условия может помочь оптимизатору увидеть то, чего он не учел в исходном запросе (см. дополнительное условие
AND t2.colX = 12ниже в WHERE):
- Есть ли плохие условия поиска? Столбцы всегда должны находиться с одной стороны выражения:
FROM table2 AS t1
JOIN table2 AS t2 ON t1.colX = t2.colX
WHERE t1.colX = 12 AND t2.colX = 12
- Иногда простой переход от соединения к подзапросу или от подзапроса к соединению исправляет проблему (нет, одно не всегда лучше другого, но иногда переписывание может помочь оптимизатору).
- Иногда использование производных (derived) таблиц (подзапросов в FROM (...) AS J1) может помочь оптимизатору более оптимально соединить таблицы.
- Есть ли у вас условия OR? Можете ли вы переписать их через UNION или UNION ALL для получения такого же результата (это самое главное) с лучшим планом выполнения? Будьте осторожны, семантически это разные запросы. Вам нужно хорошо понимать различие между всеми ими.
- OR удаляет дубликаты строк (на основе ID строки)
- UNION удаляет дубликаты на основе столбцов, указанных в SELECT
- UNION ALL объединяет множества (что может быть намного быстрее, чем удаление дубликатов), но это может быть (а может и не быть) проблемой:
- иногда дубликатов нет (вы должны знать свои данные)
- иногда допустимо вернуть дубликаты (вы должны знать ваших пользователей / аудиторию / приложение)
Это совсем небольшой список, но он может помочь вам повысить производительность без использования хинтов. Это значит, что при последующих изменениях в данных, индексах, статистике, в версии SQL Server, оптимизатор сможет учитывать эти изменения!
Но все-таки здорово, что хинты есть, и если мы действительно нуждаемся в них, то можем ими воспользоваться. Бывают ситуации, когда оптимизатор может не быть в состоянии придумать эффективный план. Для этих случаев можно воспользоваться хинтами. Так что да, мне нравится, что они есть. Я просто не хочу, чтобы вы использовали их, пока не определите, истинную причину проблемы.
Так что, да, вы можете добиться оптимизации на уровне синтаксиса… если вам это нужно.
Оптимизация с использованием правил (эвристика)
Я упоминала, что оптимизация на основе стоимости требует статистики. Но что, если у вас нет статистики?
На это также можно посмотреть с другой стороны — почему SQL Server не может просто использовать "набор правил" для быстрой оптимизации запросов без необходимости просматривать/анализировать информацию о ваших данных? Разве это не было бы быстрее? SQL Server может делать так, но часто это бывает не самое лучшее решение. Для демонстрации этого надо запретить SQL Server при обработке запроса использовать статистику. Я могу показать пример, когда это действительно работает хорошо, и гораздо больше примеров, когда работает плохо.
Эвристика — это правила. Простые, статичные, фиксированные правила. Тот факт, что они простые, является их преимуществом. Не нужно смотреть на данные. Делается простая и быстрая оценка запроса на основе предикатов. Например, “меньше” и “больше” имеют внутреннее правило “30%”. Проще говоря, когда вы запускаете запрос с предикатом “больше” или “меньше” и нет информации о данных (статистики), SQL Server будет использовать правило, которое говорит, что условию будут соответствовать 30% данных. Оптимизатор будет использовать это в своих оценках и придумает план, соответствующий этому правилу.
Чтобы это "заработало", нужно сначала отключить auto_create_statistics и проверить существующие индексы и статистику:
USE [WideWorldImporters];
GO
ALTER DATABASE [WideWorldImporters]
SET AUTO_CREATE_STATISTICS OFF;
GO
EXEC sp_helpindex '[sales].[Customers]';
EXEC sp_helpstats '[sales].[Customers]', 'all';
GOПосмотрите sp_helpindex и sp_helpstats. В базе данных WideWorldImporters в таблице Customers на столбце DeliveryPostalCode по умолчанию нет индексов и статистики. Если вы добавили что-то самостоятельно (или SQL Server создал автоматически), то следует их удалить перед выполнением следующих примеров.
Для первого запроса мы поставим ZipCode, равный 90248 и используем предикат “меньше”. Посмотрим как SQL Server оценит количество строк без использования статистики и возможности ее автоматического создания.

SELECT [c1].[CustomerID],
[c1].[CustomerName],
[c1].[PostalCityID],
[c1].[DeliveryPostalCode]
FROM [sales].[Customers] AS [c1]
WHERE [c1].[DeliveryPostalCode] < '90248';Столбцы без статистики будут использовать эвристику.
Если не найти «идеальное» значение, то большую часть времени эти правила будут неправильными!
Для первого запроса оценка работает хорошо (30% от 663 = 198,9), так как фактическое количество строк для запроса составляет 197. Один важный момент, на который стоит обратить внимание — это предупреждение рядом с таблицей Customers и около самого левого оператора SELECT. Оно говорит нам о том, что здесь что-то не так. Хотя, оценка количества строк «правильная».
Для второго запроса мы возьмем значение ZipCode равное 90003. Запрос точно такой же, за исключением значения ZipCode. Как сейчас SQL Server оценит количество строк?
SELECT [c1].[CustomerID],
[c1].[CustomerName],
[c1].[PostalCityID],
[c1].[DeliveryPostalCode]
FROM [sales].[Customers] AS [c1]
WHERE [c1].[DeliveryPostalCode] < '90003';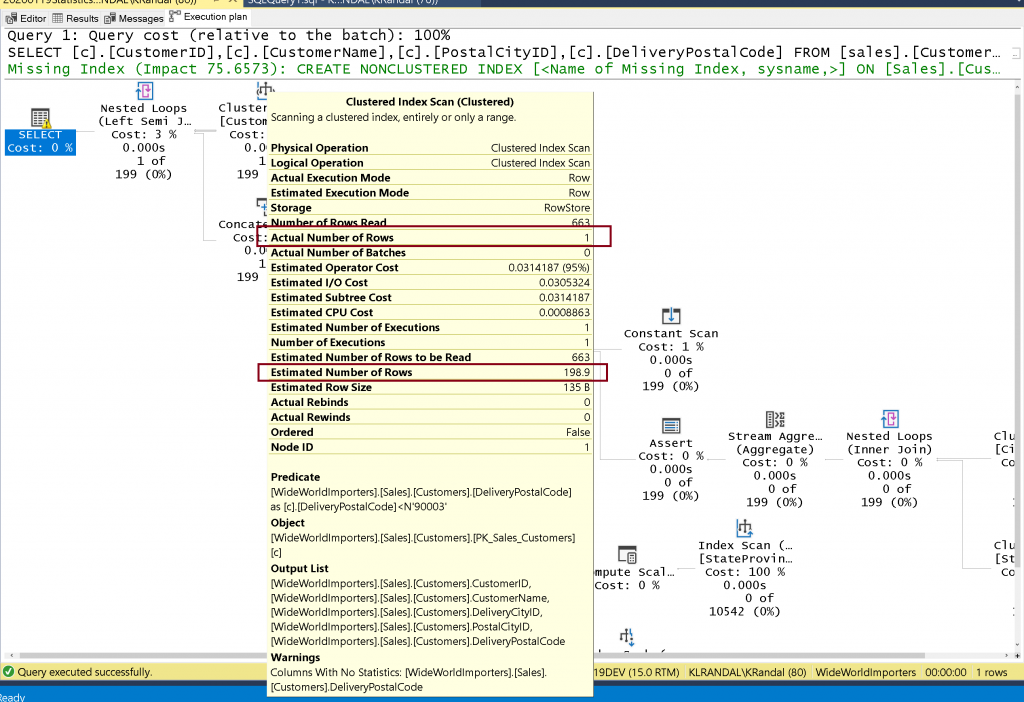
Столбцы без статистики используют эвристику (простые правила). Часто они сильно ошибаются!
Для второго запроса оценка также равна 198,9, а фактически строк только 1. Почему? Потому что без статистики эвристика для “меньше” (и “больше”) составляет 30%. Тридцать процентов от 663 — это 198,9. Конкретное значение меняется при модификации данных, но процент остается постоянным 30%.
Если этот запрос будет более сложным (с соединениями и/или дополнительными предикатами), то наличие некорректной информации — это уже проблема для последующих шагов оптимизации. Да, время от времени вам может везти с эвристиками, но это маловероятно. Более того эвристика для BETWEEN и “равно” отличается от значений для “меньше” и “больше” (равной равна 30%). На самом деле, некоторые из них даже меняются в зависимости от используемой вами модели оценки кардинальности (например, для “равно”). А меня, вообще, это должно беспокоить? На самом деле, нет! В действительности я никогда не хочу их использовать.
Итак, SQL Server может использовать оптимизацию на основе правил… но только тогда, когда у него нет лучшей информации.
Я не хочу эвристику! Я хочу статистику!
Статистика — это одно из немногих мест в SQL Server, которой не может быть мало. Нет, я не говорю о том, чтобы создавать статистику для каждого столбца таблицы, но есть некоторые случаи, когда можно предварительно создать статистику. Но это тема для отдельной статьи.
Итак, почему статистика так важна для стоимостной оптимизации?
Оптимизация на основе стоимости
Что же на самом деле делает оптимизация на основе стоимости? Если кратко, то SQL Server быстро получает приблизительную оценку того, сколько данных будет обработано. Затем, используя эту информацию, он оценивает стоимость различных алгоритмов, которые могут быть использованы для доступа к данным. После этого, основываясь на “стоимости” этих алгоритмов, SQL Server выбирает тот, который, по его расчетам, является наименее дороги. Затем он его компилирует и выполняет.
Это звучит здорово, но есть много факторов, когда это может работать не так хорошо, как хотелось бы. Самое главное, что базовая информация, используемая для выполнения оценки (статистика), может быть некорректной:
- Статистика может быть устаревшей
- Статистика может быть не точной из-за ограниченной выборки
- Статистика может быть не точной из-за размера таблицы и ограничений того, что храниться в ней.
Некоторые спросят меня — может ли SQL Server иметь более подробную статистику (более подробные гистограммы и т.п.)? Да, может. Но тогда процесс чтения / доступа к этой, все большей и большей, статистике будет становиться все дороже (и занимать больше времени, больше кеша и т. д.). Что, в свою очередь, сделает процесс оптимизации более дорогим. Это сложная проблема. Везде есть плюсы и минусы, компромиссы. На самом деле, все не так просто, как “подробные гистограммы”.
Наконец, в процессе оптимизации нельзя проанализировать все возможные комбинации планов. Это сделало бы сам процесс оптимизации настолько дорогим, что это было бы непозволительно!
Итог
Лучший способ думать о процессе оптимизации — это как найти “хороший план быстро”. Иначе процесс оптимизации стал бы настолько сложным и затянулся бы настолько, что не достиг бы своей цели!
Итак, почему статистика очень важна:
- Она используется на всем протяжении процесса стоимостной оптимизации (а вы хотите оптимизацию на основе стоимости)
- Она должна присутствовать, иначе вы будете вынуждены использовать эвристику
- как правило, я настоятельно рекомендую включить параметр auto_create_statistics, если вы его выключили
- Она должна быть актуальной, чтобы давать более точные оценки (ее важно обновлять и некоторая статистика может больше нуждаться в вашей «помощи», чем другая, чтобы оставаться актуальной)
- Ей может понадобиться дополнительная помощь (с тем, как она обновляется, когда обновляется, или с дополнительной статистикой)
СТАТИСТИКА — КЛЮЧ К ЛУЧШЕЙ ОПТИМИЗАЦИИ И, СЛЕДОВАТЕЛЬНО, ЛУЧШЕЙ ПРОИЗВОДИТЕЛЬНОСТИ (но это все еще пока далеко от идеала!)
Я надеюсь, что эта статья мотивирует вас изучить больше о статистике. Статистика в SQL Server на самом деле проще, чем вы думаете и, очевидно, она очень, очень важна!
Довольно старая, но все еще полезная статья — Statistics Used by the Query Optimizer in Microsoft SQL Server 2008
Узнать подробнее о курсе можно в записи дня открытых дверей.

