
Стековые машины используются в большом множестве современных языков программирования. Они просты для понимания и при этом достаточно эффективны. Хотите попробовать одну такую в действии?
Все вы, наверное, слышали, что 1С-ники жалуются на свою систему, считая язык 1С недостаточно низкоуровневым, скучным и т.п. Все они с тоской поглядывают в сторону "настоящих" языков программирования. Так вот, господа, они неправы. В системе 1С есть места, где можно размять программерский мозг и получить удовольствие от низкоуровневой техники. Предлагаю вам погрузиться в недра виртуальной машины 1С и понять, как она работает. Там есть свой "ассемблер" и сегодня мы будем писать на нем рабочий код для 1С. Заходите под кат, будет весело!
Стековые виртуальные машины
Мир все больше и больше захватывают динамические языки программирования. От "честных" нативных языков в строю остался, пожалуй, только Си (с плюсами и без). Это если брать промышленный мейнстрим. Все популярные языки так или иначе имеют прослойку в виде "исполняющей среды" или "виртуальной машины", которая обеспечивает выполнение кода на той или иной архитектуре железа. И подавляющее большинство этих "виртуальных машин" являются стековыми, т.е. реализуют обработку операций с помощью такой известной в компьютерном мире структуры, как "стек".
Ремарка для тех, кто забыл
Стек (Stack) в переводе с английского означает "стопка". Когда мы кладем в стопку (скажем, книг) какую-то новую книжку, то она оказывается сверху. Убирать из стопки книги мы можем только сверху вниз. Т.е. последняя добавленная книжка снимается из стопки самой первой. Это тот самый принцип "LIFO" — last in/first out. Обратной ситуацией является очередь (в магазине). Кто первый встал — того и тапки.
Java, Python, C# и 1С — все они используют стековые машины для выполнения своего кода. Рискну предположить, что node.js — тоже, но это неточно, а гуглить мне лень. 95% вероятности, что это так и есть. про JIT я скромно умолчу, это ведь опция, неправда ли? :)
Если совсем спускаться в академические точности, то есть язык, а есть исполняющая среда. Так вот, язык — это лишь спецификация и, вообще-то, текст. Он не выполняется, он в блокноте написан. А вот то, что выполняет написанное — это может быть как стековым, так и нет. Поэтому нельзя сказать что Java — это стековый язык. Стековым бывает то, что выполняет язык. Так, например, для Java есть общепринятая машина JVM — она стековая. А в Андроидах используется (или использовалась) регистровая машина Dalvik. Ходят слухи, что ее оттуда выпилили, но я не проверял. Язык — один, машин может быть несколько. Но, как правило, этим можно пренебречь, поскольку все равно у каждого упомянутого языка есть всего одна (реже несколько) реализующих машин и почти все они, скорее всего, будут стековыми.
У языка 1С тоже есть несколько реализаций. Первая — сама 1С, вторая — например, 1Script. Есть еще несколько, чуть менее известных.
Стековая машина
Устроена стековая машина невероятно просто. Я разбирал ее устройство на Хабре еще в 2014 году, поэтому здесь просто коротенько напомню.
Итак, вот есть у вас выражение А = 1 + 1; как оно выполняется стековой машиной?
PushConst 1 PushConst 1 Add LoadVar A
Поместить в стек операнд-константу 1 (2 раза), затем выполнить операцию Add.
Операция Add извлекает свои аргументы из стека (2 штуки) и складывает. Результат кладет обратно на стек. Операция LoadVar берет переданную переменную А и загружает в нее то, что лежит на стеке (в данном случае — результат сложения).
Этот простой алгоритм позволяет эффективно вычислять цепочки выражений. Например, операция А = 1+1+2 будет выглядеть вот так:
PushConst 1 ; поместили константу на стек PushConst 1 ; поместили константу на стек Add ; забрали 2 аргумента из стека (1 и еще 1), сложили, поместили в стек результат PushConst 2 ; поместили константу на стек Add ; забрали 2 аргумента из стека (2 и еще 2), сложили, поместили в стек результат LoadVar A ; забрали из стека то, что там лежало (4) и загрузили в переменную А.
Каждая машина имеет свой набор операций, не обязательно такой, как здесь, но принцип у всех общий: операции по очереди кладут что-то на стек или извлекают что-то из стека.
Операции, выполняемые виртуальной машиной, принято называть "байт-кодом". Это такой "ассемблер" для стековой машины.
Как увидеть байт-код машины 1С
По умолчанию, если вы в 1С сохраняете какой-либо модуль, он сохраняется в чистом виде, так, как вы его написали. Однако, если поставить на модуль пароль или удалить модуль из поставки, то системе потребуется как-то все-таки узнать — что выполнять. Поэтому, система при сохранении компилирует ваш код 1С в байт-код и сохраняет уже его. Например, если вы поставите пароль на модуль внешней обработки, то в файл epf ляжет скомпилированный байткод. Его можно посмотреть утилитами семейства v8unpack.
Какой же хакер без подходящих инструментов
Давайте посмотрим на байткод 1С. Права на описанные инструменты принадлежат их авторам, как и всяческие респекты от меня и сообщества.
Для начала нам потребуется распаковщик файлов epf. Самый простой способ, это установить его через chocolatey
choco install v8unpack --version 3.0.41 --source https://www.myget.org/F/onescript/api/v2
Тем, у кого нет chocolatey (эй, чуваки, как вы без него живете?) можно скачать по прямой ссылке https://github.com/e8tools/v8unpack/releases/download/v.3.0.40/v8unpack.exe но не забудьте потом exe прописать в PATH, чтобы было удобнее запускать.
Итак, возьмем любую внешнюю обработку 1С, модуль которой не скрыт паролем, и посмотрим на нее изнутри.
v8unpack -P КакаяТоОбработка.epf content
Будет создан каталог content, а в нем размещено содержимое внутренних файлов контейнера 1С (кому интересно — формат контейнера описан вот здесь: https://infostart.ru/public/250142/)
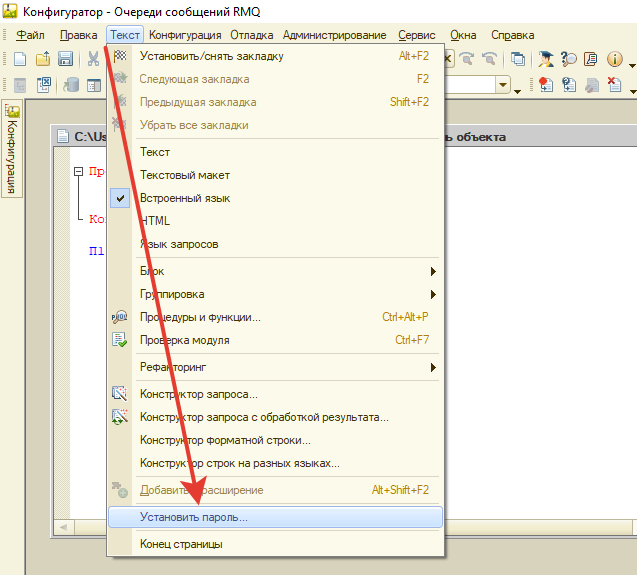
Итак, в этом контейнере нас интересует каталог "<какой-то-GUID>.0", а в нем файлы "info" и "text". Файл "text" это просто текст модуля, а файл инфо это служебный файл, с которым мы еще поработаем. Теперь удалим каталог content и закроем модуль нашей обработки паролем. Откройте редактирование модуля в конфигураторе и в меню "Текст" выберите пункт "Установить пароль". Теперь, при попытке редактирования модуля Конфигуратор будет спрашивать пароль.
Отлично, а что же на уровне внутренних файлов? Сохраним запароленную обработку, удалим каталог content от предыдущего запуска и повторим команду
v8unpack -P КакаяТоОбработка.epf content
посмотрим в каталог с GUID.0 ого, появился файлик image, а в файле text — какая-то абракадабра. Платформа зашифровала содержимое модуля, его действительно не видно, но ей же надо как-то выполнять алгоритмы, верно? Для этого она перед шифрованием скомпилировала код 1С в байт-код виртуальной машины и записала его в файл image. Посмотрим на него:

Это — ассемблер 1С. Именно его выполняет платформа, когда считает всем зарплату. И знаете, что самое интересное? Мы можем напрямую писать код на этом ассемблере, не прибегая к услугам компилятора! Слабо? Я же говорил, что будет весело!
А зачем это нужно?
Ну, во-первых, это просто прикольно, это позволит вам лучше понимать устройство вашей системы и понять, как работают современные управляемые языки программирования. Это позволит вам прокачать навык хардкорного программиста и просить более высокую зарплату.
Во-вторых, вы наверняка знаете, что байт-код 1С очень легко декомпилируется обратно в скриптовый код, вплоть до сохранения имен переменных и процедур. Существуют даже обфускаторы 1С-кода, которые портят код, так чтобы он плохо читался после декомпиляции. На "ассемблере 1С" можно написать код таким образом, что он вообще не будет декомпилироваться. Позже я покажу, как написать работоспособный код, который платформа будет выполнять, но для которого просто не существует соответствующих ему синтаксических конструкций в языке 1С. Декомпилятору будет просто нечего выдать на выходе. Здорово, правда?
Я против воровства результатов чужого труда. Если вы пользуетесь декомпилятором, то скорее всего, вы не хотите платить автору, т.е. просто хотите украсть его работу. Это некрасиво. Поэтому, я не буду приводить ссылки на декомпилятор 1С в сети. Более того, каждый раз, когда в сети (чаще на Мисте) вы видите вопрос про "как декомпилировать обработку", "как снять пароль с 1С" — обязательно напишите автору вопроса, что он говнюк и мелкий воришка.
Далее, я также против и обфускаторов. Толку от них мало, их результат все равно декомпилируется и восстанавливается. С помощью написания алгоритма на уровне байт-кода можно создать супер-обфускатор, который неподвластен имеющимся на рынке 1С декомпиляторам. Вопрос взлома станет дороже покупки, что и требовалось обеспечить.
И еще: я не буду рассказывать, как именно построить такой обфускатор (я против, помните), но дам пару намеков, которые могут сработать, если вы захотите создать таковой.
Ну че, поехали?
Я написал несложный редактор байт-кода 1С, который можно взять на гитхабе. Именно он-то и станет нашим основным инструментов в этом развлечении.
Создайте любую внешнюю обработку с зашифрованным модулем, распакуйте ее с помощью v8unpack и в "Ассемблере" откройте файл "image", который мы рассмотрели чуть раньше.
Тут пока все будет не очень понятно, поэтому, давайте разбираться, как работает виртуальная машина 1С.
Раздел "Операции"
Основной код модуля описан в виде потока операций (команд). Каждая команда имеет числовой номер — код операции. Сокращенно его называют ОпКод (OpCode), этот термин можно встретить в специальной литературе. Каждая команда, помимо опкода имеет один числовой аргумент. Трактовка аргумента зависит от опкода. Каждая команда, получая на вход свой аргумент сама принимает решение, что с ним делать. Некоторые команды не имеют аргумента (ничего не делают со своим аргументом). Итак, запомнили, каждая команда — это два числа: опкод и аргумент операции.
Какие же бывают ОпКоды? В машине 1С их 128, но большую часть составляют встроенные функции типа Лев, НачалоКвартала и им подобные. Низкоуровневых операций существенно меньше.
Раздел "Константы"
С константами вообще классно. Любая ЭВМ должна иметь где-то прошитый набор констант, чтобы понимать что один — это один, а ноль — это ноль. В моем военном прошлом я изучал и работал со старой советской ЭВМ и там был даже специальный блок "ЗУ Констант", хранивший побитовые представления основных констант. Т.е. чтобы прибавить к чему-либо единицу, машина должна понимать, а как вообще выглядит единица с точки зрения включенных/выключенных электронных регистров памяти. Помимо единицы и нуля там же хранилась Пи, таблица синусов/косинусов и всякое такое. Полагаю, современные устройства тоже имеют нечто подобное внутри ПЗУ.
Ну это было лирическое отступление. Наша машина хотя и работает поверх железной, тем не менее, тоже нуждается в термине "Константы". Когда вы в коде пишете "А = 2" компилятор 1С записывает эту двойку в специальный раздел модуля. Туда же попадают литералы дат и строк. При выполнении есть специальная команда "Взять константу за номером таким-то и поместить в стек".
Раздел "Переменные"
Операторы языка 1С (как и любого другого языка) оперируют переменными. В переменную можно положить какое-нибудь значение (например константу). Переменные бывают экспортными, локальными и глобальными. Информацию о переменных компилятор также складирует в специальный раздел. Глобальные переменные модуля хранятся в глобальном разделе "Переменные", Каждый метод (процедура или функция) имеет свой отдельный блок переменных, в котором хранятся переменные относящиеся к конкретному методу.

Как кодить-то?
Кодить в такой парадигме довольно увлекательно. По сути — очень похоже на настоящий ассемблер, только вместо регистров — один стек, на который складываютя и из которого вынимаются операнды. Давайте попробуем сложить 2 числа на байткоде 1С.
Запишем в раздел констант числовую константу 2. Она будет иметь номер 0 в списке констант.
Сложение чисел 2 и 2 будет выглядеть следующим образом:
LdConst 0 LdConst 0 Add 0
Готово! Следите за руками: Все опкоды, которые кладут что-либо на стек, я по традиции обозначил префиксом Ld от слова "Load". Этой традиции много лет, даже Терминатор в своем будущем соблюдал канон и пользовался этим сокращением в своей прошивке.
Команда LdConst имеет аргумент, который указывает на номер константы в списке констант (мы помним, что там по адресу 0 лежит двойка). Команда смотрит в свой аргумент, достает двойку по заданному адресу и кладет ее в стек. В стеке один элемент — двойка.
Вторая команда делает то же самое, в стеке 2 элемента (и оба — двойки)
Третья команда — это операция сложения. Она не нуждается в аргументе, так как оба ее операнда должны лежать в стеке, но поскольку совсем без аргумента нельзя, то в байткоде у Add будет просто 0. Операция сложения извлекает 2 элемента из стека и складывает их по правилам языка 1С (с учетом типа значения самого левого аргумента).
Результат сложения кладется обратно на стек, таким образом получается как бы "возврат" из функции сложения.
Таким образом, для выполнения операции нужно заранее наполнить стек нужным количеством операндов, в нужном порядке.
Превед, Мир!
По традиции, изучение нового языка или технологии проще всего начать с демонстрационной программы "Hello World".
Откройте обработку "Ассемблер" и на закладке "Процедуры" введите строку следующего содержания:
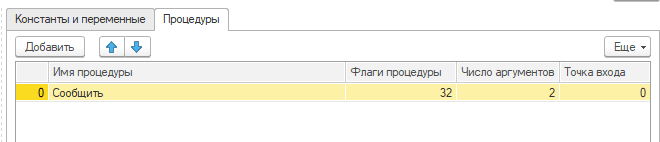
В поле "Флаги процедуры" можно нажать на кнопку выбора с "калькулятором" и посмотреть, что означают флаги.
Далее, на закладке "Константы и переменные" заведите строку
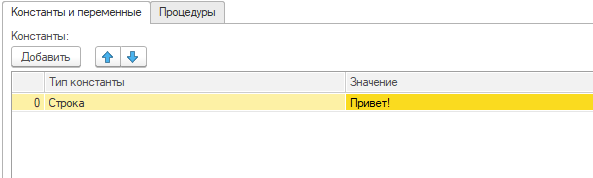
А теперь, наберите в поле "Операции" следующий код:
LdConst 0 ArgNum 1 CallLoc 0 End 0
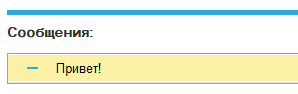
и нажмите кнопку "Запустить". Моргнет, фыркнет-пшикнет и результат будет выведен в окно сообщений
А чо это было?
При нажатии кнопки "Запустить" за кадром ваш код был записан в "скобочном формате" и с помощью v8unpack упакован во временную внешнюю обработку. Эта обработка была запущена штатным 1С-овским образом и выдала результат. Полная спецификация байткода доступна по кнопке "Справка по командам" в обработке "Ассемблер". Далее будут рассмотрены основные моменты работы с байткодом.
Работа с переменными
Рассмотрим работу с переменными. Пока пусть будут только глобальные переменные. Вот такой фрагмент кода
А = 8; Б = А + 2; М = Б - А;
При трансляции из него получится следующее: во-первых, в раздел констант попадут константы 8 и 2 в порядке их "встречи" компилятором. Восьмерка получит номер 0, а двойка — номер 1. Далее, в раздел переменных попадут переменные А, Б и М. Опять же номера будут присвоены по порядку попадания в поле зрения компилятора.
Константы
| Номер | Тип | Значение |
|---|---|---|
| 0 | Число | 8 |
| 1 | Число | 2 |
Переменные
| Номер | Имя | Признаки |
|---|---|---|
| 0 | А | Глобальная |
| 1 | Б | Глобальная |
| 2 | М | Глобальная |
Для работы с глобальными переменными используется опкод LdVar. Он помещает на стек переменную с номером, переданным в аргументе команды. Вот код программы, выполняющий указанную логику:
LineNum 1 ; маркер строки исходника LdVar 0 ; загрузить на стек переменную 0 (А) LdConst 0 ; загрузить на стек константу 0 (равную 8) Assign ; присваивание - снять со стека правую и левую части, присвоить. LineNum 2 ; маркер строки исходника LdVar 1 ; загрузить на стек переменную 1 (Б) LdVar 0 ; загрузить на стек переменную 0 (А) LdConst 1 ; загрузить на стек константу 1 (равную 2) Add ; сложить 2 значения на стеке, результат положить в стек (А+2) Assign ; присваивание - снять со стека правую и левую части, присвоить (Б = (А+2)). LineNum 3 ; маркер строки LdVar 2 ; поместить переменную 2 (М) LdVar 1 ; поместить переменную 1 (Б) LdVar 0 ; поместить переменную 0 (А) Sub; вычитание. Снять 2 значения, результат положить Assign; присваивание М = (Б-А) End; конец блока кода
Видите, все довольно просто, хотя, наверняка, возникли вопросы. Например, что делает оператор LineNum? Очень просто, он привязывает байткод к строкам исходного кода, чтобы при возникновении исключения можно было бы выдать номер строки, в которой произошла ошибка. Без этого оператора машина не узнает какой набор опкодов какой строке исходника принадлежит. Кстати, весьма вероятно, что народный способ "писать код в одну строку, чтобы было быстрее" происходит именно отсюда. Если весь код написать в одну строку, то мы сократим число вызовов LineNum. Однако, сопровождение такого кода превращается в ад, и я бы отрывал руки тем, кто так пишет для корпоративного продакшена.
Вызовы методов
Вызовы обрабатываются чуть сложнее. Во-первых, в модуле существует таблица методов, в дополнение к константам и переменным. Во вторых в методы могут передаваться аргументы (обязательные и необязательные) и возвращаться значения. Вот набор операций для работы с методами:
| ОпКод | Пояснение |
|---|---|
| ArgNum | Кладет на стек число, показывающее сколько параметров было положено в стек для вызова метода (число переданных параметров) |
| CallLoc | Вызов локальной функции по номеру из таблицы методов |
| CallProc | Вызов метода объекта, как процедуры |
| CallFunc | Вызов метода объекта, как функции (с возвратом значения) |
| Ret | Запоминание результата функции (не на стеке) |
| LdRet | Положить результат последнего метода на стек |
Давайте попробуем вызвать метод. Пусть в таблице методов существует запись про метод "МояФункция" с одним параметром. Пусть эта запись имеет номер 0.
Для краткости, я опущу операции LineNum. С помощью обработки "Ассемблер" вы всегда сможете посмотреть в каких местах 1С добавляет этот оператор.
LdConst 0; поместим на стек какую-нибудь константу ArgNum 1; указываем сколько аргументов надо будет снять со стека при вызове метода CallLoc 0; вызов метода с номером 0.
При вызове метода машина снимает со стека число значений, заданное оператором ArgNum. Это число показывает — сколько значений надо снять со стека и распределить по параметрам метода. Эта механика необходима потому, что у нас могут быть необязательные параметры в методах. Тогда при вызове метода с неполным числом параметров машина должна знать, сколько реальных значений засунуто в стек при вызове.
Обработка возвратов
Мы можем вызвать любой метод, как процедуру (игнорируя возвращаемое значение), а можем вызвать, как функцию — присваивая куда-то результат. Вспомним оператор Assign, рассмотренный ранее. Он извлекает из стека 2 аргумента. Чтобы присваивание возвращаемого значения сработало требуется поместить результат функции на стек. Это делает оператор LdRet. При этом, сама функция не знает, будут использовать ее результат или нет. Поэтому компилятор всегда компилирует тело функции одинаково, вызывая оператор Ret, который кладет результат функции в некое временное хранилище. Если значение из этого хранилища извлекут методом LdRet — хорошо. А если нет, значит оно не понадобилось. Просто и элегантно. Я при разработке 1Script не додумался про временное хранилище и мне пришлось городить довольно муторную механику "отброса" неиспользованных результатов Возврата со стека.
Более сложные случаи
Код, выполняющийся линейно, мы разобрали. Давайте посмотрим на ветвления и циклы. Для начала изучим самый простой оператор, обеспечивающий ветвление. Это Jmp. Он просто переводит выполнение на команду, номер которой передан в Jmp аргументом. С помощью джампов можно строить очень запутанный код и декомпиляция его может превратиться в ад. Если вы пишете обфускатор, то не сможете выполнить такую обфускацию, портя код исключительно на уровне исходника 1С. А в байт-коде — сколько душе угодно, была бы фантазия.
Сокращенные вычисления логических выражений
Я думаю, вы знаете, что 1С использует сокращенные вычисления логических выражений. Этот термин означает, что при вычислении выражения "А и Б" выражение Б может вообще не выполняться, если результат А — ложь. Если А = Ложь, то и все "А и Б" равно ложь и нет смысла вычислять Б. Например:
Если ТипЗнч(Переменная) = Тип("Структура") И Переменная.Свойство = 2 Тогда
имеются 2 части логического выражения: проверка типа И обращение к свойству. В 1С такая конструкция безопасна именно благодаря сокращенному вычислению. Если тип переменнной не структура, то левая часть И будет равна Ложь, а значит и все выражение будет равно Ложь. Правая часть И вообще не будет выполнена, а значит обращение к свойству "НЕ структуры" не произойдет.
Аналогично с ИЛИ, только наоборот. Если левая часть равна Истина, то правую часть вычислять нет смысла. Для реализации этой логики существуют 2 ОпКода — And и Or соответственно. Аргументом операции идет число, показывающее на какой адрес команды перейти, если сработает сокращенное вычисление.
Например, для "И" если операнд на вершине стека Ложь, то происходит переход по адресу, указанному в аргументе опкода, т.е. пропуск вычисления второго операнда, т.к. от него уже ничего не зависит. Из стека при этом значение не удаляется (результатом операции является Ложь). Иначе, если на вершине стека Истина, из стека удаляется значение и перехода не происходит, т.е. вычисляется второй операнд, результат которого полностью определяет результат всей операции).
Есть еще 2 команды условных переходов: JmpTrue и JmpFalse. Аргументом опкода идет адрес (номер команды), на который надо перейти, а переход выполняется только тогда, когда на стеке находится Истина или Ложь соответственно. Причем, оператор JmpTrue 1С никогда не использует при компиляции исходника. Т.е. декомпилировать байткод, использующий JmpTrue, будет намного сложнее, т.к. в синтаксисе языка 1С отсутствует соответствующая ему конструкция (trollface) Кстати, 1Script тоже никогда не использует JmpTrue и в его байткоде такая операция совсем не предусмотрена.
Условия
Как же выглядят условия? Пусть есть константа 0 со значением 1, пусть есть переменная А с номером 0 и значением 1
0: LdVar 0 ; кладем на стек значение А 1: LdConst 0 ; кладем на стек значение 1 2: Cmp ; сравниваем (оператор кладет результат сравнения на стек) 3: JmpFalse 6 ; перейти на команду 6, если на стеке Ложь 4: внутри IF ; не выполняется 5: внутри IF ; не выполняется 6: продолжение кода… ; выполняется
Если условие не выполнено — идет переход на конкретный адрес. Если выполнено — просто идет выполнение дальше и заходит в блок условия.
Циклы
Циклов у нас 3 вида: "Пока", "Для… По" и "Для Каждого… Из". Причем для "Пока" вообще не требуется дополнительных опкодов, он целиком реализуется на джампах.
Для цикла "Для… По" используется отдельный стек "временных переменных", который хранит значения, обеспечивающие работу цикла. Так, во временный стек кладется конечное значение итерации цикла, и при каждом проходе текущее значение инкрементируется и сравнивается с временным. Сравнение выполняется оператором Gte (больше-или-равно) и уже знакомым нам JmpFalse если счетчик цикла стал больше или равен конечному значению цикла. Приводить байткод не буду, это домашнее задание для тех кто захочет разобраться с обработкой "Ассемблер".
Цикл с итератором "Для Каждого Из"
С итератором все вообще интересно. Итератор — это такой объект, который отвечает за обход коллекции и выдает очередной ее элемент при вызове условного метода Next()
Для получения итератора используется опкоды Iter, Next и неявная служебная переменная, которую компилятор создает в блоке переменных. Плюс, используется стек временных переменных и… зачем так сложно, я так и не понял, цикл с итератором в 1Скрипт сделан, на мой взгляд, попроще.
Попробуем разобраться. Вот фрагмент кода Внимание, потребуется включить мозг, рекомендуется налить кофе:
Функция А(Арг) Для Каждого Элемент Из Арг Цикл Элемент.Метод(); КонецЦикла; КонецФункции
Для начала, в блок переменных у нас попадет "Арг" с номером 0, и "Элемент" с номером 1. Потом, внезапно, у нас в блоке переменных появится переменная "0Элемент", которую добавит компилятор. Вам говорили, что имя переменной не может начинаться с цифры? Забудьте, это все вранье :)
А что же дальше? Дальше вот что, сначала на стеке временных переменных будет создана новая переменная и размещена в основном стеке:
PutTmp ; создаем пустую переменную LdTmp ; кладем пустую переменную в стек
затем на стек будет помещена итерируемая коллекция (она лежит в переменной 0)
LdLoc 0 ; помещаем Арг на стек
затем, будет вызвана операция получения итератора, который также ляжет на стек.
Iter ; взять со стека значение Арг и получить от него объект-итератор. Assign ;присваивание итератора в Tmp
Вот полный листинг указанной функции, лучше сверяться с ним при дальнейшем чтении:
| Адрес | Операция | Аргумент | Описание |
|---|---|---|---|
| 0 | LineNum | 4 | Начало строки кода. Номер строки в исходном модуле |
| 1 | PutTmp | 0 | Создать на стеке временных переменных временную переменную |
| 2 | LdTmp | 0 | Загрузить в стек временную переменную из стека временных переменных |
| 3 | LdLoc | 0 | Загрузить в стек локальную переменную. Индекс переменной во внутреннем блоке Var |
| 4 | Iter | 0 | Получить из коллекции выборку |
| 5 | Assign | 0 | Операция = (присвоение) |
| 6 | LineNum | 4 | Начало строки кода.Номер строки в исходном модуле |
| 7 | LdLoc | 2 | Загрузить в стек локальную переменную.Индекс переменной во внутреннем блоке Var |
| 8 | LdTmp | 0 | Загрузить в стек временную переменную из стека временных переменных |
| 9 | Assign | 0 | Операция = (присвоение) |
| 10 | LdLoc | 2 | Загрузить в стек локальную переменную. Индекс переменной во внутреннем блоке Var |
| 11 | Next | 0 | Получить из выборки очередной элемент коллекции. Этот элемент попадает в переменную, которая была на вершине стека, а в стек вместо этой переменной помещается результат успешности (Истина — получили очередной элемент, Ложь — нет) |
| 12 | JmpFalse | 26 | Переход, если Ложь. Индекс шага в блоке Cmd |
| 13 | LdLoc | 1 | Загрузить в стек локальную переменную. Индекс переменной во внутреннем блоке Var |
| 14 | LdLoc | 2 | Загрузить в стек локальную переменную. Индекс переменной во внутреннем блоке Var |
| 15 | Assign | 0 | Операция = (присвоение) |
| 16 | LdLoc | 2 | Загрузить в стек локальную переменную. Индекс переменной во внутреннем блоке Var |
| 17 | LdUndef | 0 | Загрузить на стек Неопределено |
| 18 | Assign | 0 | Операция = (присвоение) |
| 19 | LineNum | 5 | Начало строки кода. Номер строки в исходном модуле |
| 20 | LdLoc | 1 | Загрузить в стек локальную переменную. Индекс переменной во внутреннем блоке Var |
| 21 | ArgNum | 0 | Указание количества используемых параметров в следующем вызове (метода, функции). Количество параметров, используемых в следующем вызове. После вызова, параметры убираются из стека, а метод (если следующим идет именно вызов метода) применяется к следующему элементу стека (который тоже убирается) |
| 22 | CallProc | 0 | Выполнение метода .<Имя метода>() (являющегося процедурой, т.е. без возврата значения). Индекс константного значения в Const, являющегося именем метода |
| 23 | LineNum | 5 | Начало строки кода. Номер строки в исходном модуле |
| 24 | LineNum | 6 | Начало строки кода. Номер строки в исходном модуле |
| 25 | Jmp | 6 | Переход на заданный шаг. Индекс шага в блоке Cmd |
| 26 | PopTmp | 1 | Удалить из стека временных переменных временную переменную 1? (возможно, это кол-во выталкиваемых значений) |
| 27 | LdLoc | 2 | Загрузить в стек локальную переменную. Индекс переменной во внутреннем блоке Var |
| 28 | LdUndef | 0 | Загрузить на стек Неопределено |
| 29 | Assign | 0 | Операция = (присвоение) |
| 30 | LdLoc | 2 | Загрузить в стек локальную переменную. Индекс переменной во внутреннем блоке Var |
| 31 | LdUndef | 0 | Загрузить на стек Неопределено |
| 32 | Assign | 0 | Операция = (присвоение) |
| 33 | LineNum | 8 | Начало строки кода. Номер строки в исходном модуле |
| 34 | End | 0 | Конец блока (процедуры, модуля) |
| 35 | End | 0 | Конец блока (процедуры, модуля) |
| 36 | End | 0 | Конец блока (процедуры, модуля) |
Мы находимся на адресе 5. Оператор Assign, берет со стека 2 аргумента — временную переменную и объект итератор. Итератор попадает во временную переменную.
Дальше идет последовательность операций:
LdLoc 2 ; загрузили на стек волшебную переменную 0Элемент LdTmp 0 ; загрузили на стек итератор Assign; записали итератор в переменную 0Элемент LdLoc 2; опять загрузили 0Элемент на стек Next; вызвали получение очередного элемента из переменной на стеке JmpFalse 26 ; если это конец коллекции - переход на адрес очистки состояния цикла.
Следует подробнее остановиться на операторе Next. Он извлекает из итератора очередной элемент и записывает его в переменную, которая была на стеке в этот момент (0Элемент), эта переменная извлекается из стека, а на стек кладется значение Истина, если элемент был получен, или Ложь, если коллекция кончилась. Идущий следом JmpFalse съедает этот флаг и выполняет переход согласно логике цикла.
Итак, после операции JmpFalse у нас в переменной 0Элемент лежит значение элемента, во временном стеке лежит итератор. Зачем нужна чехарда с перекладыванием итератора из временных переменных в 0Элемент, а потом результата итератора опять в 0Элемент — я не понял. Можно же воспользоваться сразу переменной Элемент и складывать значение в нее…
Наконец-то можно приступить к телу цикла. Адреса 19-23 это тело цикла. Адрес 25 — Jmp на верхушку цикла, адрес 26 и далее — выход из цикла и чистка всех временных сущностей.
Особенно интересны операции с 27-й по 32-ю. Это очистка переменной 0Элемент, которая выполняется почему-то 2 раза. Наверное, если с первого раза присваивание Неопределено не сработало, то надо сделать еще одну попыточку… Кажется, мы имеем +3 ненужных операции на каждом цикле с итератором, помимо магии с 0Элемент в начале цикла. А может в этом есть тайный смысл, который я недопостиг, как знать…
Для сравнения, тот же самый код в 1Script выглядит следующим образом:
0 :(LineNum 3) 1 :(PushLoc 0) 2 :(PushIterator 0) 3 :(LineNum 3) 4 :(IteratorNext 0) 5 :(JmpFalse 12) 6 :(LoadLoc 1) 7 :(LineNum 4) 8 :(PushLoc 1) 9 :(ArgNum 0) 10 :(ResolveMethodProc 0) 11 :(Jmp 3) 12 :(StopIterator 0) 13 :(PushConst 1) 14 :(Return 0)
Имеем 15 операций байткода вместо 37. Такое сравнение нельзя считать корректным, т.к. не столько количество опкодов влияет на скорость, сколько время выполнение каждого конкретного опкода. И нельзя сказать, что циклы 1Script заведомо быстрее циклов 1С. Но байткод получился намного понятнее и прозрачнее.
Хардкор для сильных духом
Ну что же, мы разобрали линейное выполнение, условия, циклы. Что еще там бывает при выполнении кода? А бывают, товарищи, исключения. Это такая штука, которая требует отдельного разговора.
Что такое исключение? Это, в первую очередь, прерывание текущего потока исполнения и переход либо вверх по стеку вызовов, либо в блок "Исключение" оператора "Попытка".
Во-первых стоит разобраться с тем, как 1С выполняет возврат из метода. Она применяет опкод BlckEnd сразу за которым идет Jmp на конец тела метода. По всей видимости, BlckEnd — это какой-то специализированный оператор очистки конца блока. При выходе из тела процедуры аргумент опкода BlckEnd всегда равен 0.
Чуть сложнее обстоит дело с Попыткой. При выходе из блока "Попытка" тоже исполняется операция BlckEnd, но в качестве аргумента передается номер вложенности блока Попытка относительно тела метода.
Попытка // 1 Попытка // 2 Попытка // 3 Возврат 2; // BlckEnd 3
Т.е. "возврат" просто из тела процедуры — это BlckEnd 0, а "возврат" из Попытки — это BlckEnd <номер вложенности блока попытки>. Да, под словом "блок Попытка" я понимаю именно тот блок, который находится между словами Попытка и Исключение, т.е. я имею в виду "безошибочную" часть конструкции "Попытка Исключение".
Разбор конструкции Попытка-Исключение
Блок обработки ошибок открывается опкодом BeginTry, аргументом которого идет адрес начала блока Исключение. Т.е. при возникновении ошибки будет переход на тело обработчика. Далее, идет собственно код тела Попытка, а в его конце будет стоять BlckEnd <номер> и Jmp за пределы оператора КонецПопытки;
Рассмотрим байткод для следующего модуля:
Функция А() Попытка ; Исключение ; КонецПопытки; КонецФункции
байткод
0: BeginTry 4 ;Индекс шага в блоке Cmd раздела Исключение 1: LineNum 6 ;Номер строки в исходном модуле 2:BlckEnd 1 ;Окончания блока Попытка номер 1 3:Jmp 6 ;Переход за строку КонецПопытки 4:LineNum 6 ;Начало строки кода:Номер строки в исходном модуле 5:EndTry 0 ;КонецПопытки (конец блока Исключение) 6:LineNum 7 ;Начало строки кода:Номер строки в исходном модуле 7:End 0 ;Конец блока (процедуры, модуля) 8:End 0 ;Конец блока (процедуры, модуля) 9:End 0 ;Конец блока (процедуры, модуля)
Здесь все довольно прозрачно. Блок Попытка открывается оператором BeginTry и указанием адреса, куда перейти, если вдруг что случится (начало блока Исключение).
Далее идет тело блока (здесь отсутствует), а в конце оператор очистки BlckEnd и прыжок за пределы обработчика ошибок (адреса 2-3). Блок Исключение завершается оператором EndTry.
Стоит оговориться, что обработчики исключений это всегда сложно и медленно, даже в этих ваших сиплюсплюсах. Компиляторы вынуждены генерировать кучу вспомогательных команд для обеспечения привычной нам логики ловли исключений.
Самая вкуснятина
Ну а как же все это применить на практике? Как создать работоспособную обработку, написанную на чистом байткоде? Для этого, в обработке "Ассемблер" есть кнопка "Сохранить". Она позволяет сохранить в файл image весь код и описания констант-процедур, который вы введете в обработке, а затем с помощью v8unpack собрать готовый epf.
Сейчас мы сделаем одну интересную вещь, которую вы вряд ли увидите в другой ситуации.
Смотрите какая штука: у каждой коллекции есть итератор. Итератор это полноценный объект и размещается в том же самом стеке, что и другие переменные. Это значит, что с ним можно работать как с обычным (не-системным) значением, так ведь? Например, можно цикл "Для Каждого" переделать в примерно такой вариант:
Итератор = Массив.ПолучитьИтератор(); Пока Итератор.Следующий() Цикл Сообщить(Итератор.Значение); КонецЦикла;
Представьте, что написали обфускатор, который все циклы "Для Каждого" превращает в "Пока-Следующий()". Декомпилировать такой код обратно в синтаксис 1С будет затруднительно, поскольку в синтаксисе 1С в принципе нет конструкций, позволяющих работать с итераторами напрямую!
Давайте проверим эту гипотезу. Откройте обработку "Ассемблер" и в разделе "Переменные" заведите любую переменную. Далее, в разделе константы заведите строковую константу со значением "Массив" — это будет имя типа который нам нужен. А в коде введите следующее:
| Код | Пояснение | Читает со стека | Кладет на стек |
|---|---|---|---|
| LdVar 0 | загрузили переменную-приемник | Переменную | |
| ArgNum 0 | в конструктор не будем передавать аргументов (ноль) | ||
| New 0 | Вызвали конструктор типа, имя которого указано в константе 0 | Массив | |
| Assign | Присвоили массив в переменную на стеке | Правую часть присваивания и левую часть присваивания | Ничего |
| LdVar 0 | Кладем на стек переменную с массивом | Массив | |
| Iter | Получаем итератор | Массив | Итератор |
| ТипЗнч | проверим тип того, что лежит на стеке | аргумент ТипЗнч | Тип |
| ArgNum 1 | Число аргументов, которые будем передавать в Сообщить | ||
| CallLoc 0 | Вызовем процедуру Сообщить | Тип | |
| End | Корректный выход |
А теперь сохранитесь на всякий случай и нажмите кнопку "Запустить". У меня выводится слово "Итератор". Поняли что мы сделали? Мы сделали, чтобы операция "Сообщить(ТипЗнч(М))" выдавало слово "Итератор". Поищите-ка такой тип в синтакс-помощнике. Нету? А он — есть!
Об этой фишке мне рассказал Сергей Батанов (dmpas), я просто пересказал ее здесь, а все респекты за этот трюк должны идти ему :)
Disclaimer
Следует отдавать себе отчет в том, что вы действительно работаете на низком уровне системы, в котором не предусматривается присутствие пользователя. Если вы ошибетесь при вводе команд, будете работать не с теми адресами или значениями стека, то клиент 1С у вас будет аварийно завершаться. Это нормально, здесь за вас никто ничего контролировать и перепроверять не будет. Сама обработка "Ассемблер" тоже поставляется в образовательных целях. Она не является универсальным удобным редактором, там довольно мало проверок и подсказок по заполнению таблиц. Мне важно показать саму возможность управления байткодом. Ровно по этой же причине, код внутри обработки "Ассемблер" написан с нарушением почти всех мыслимых стандартов кодирования, просьба это учитывать.
К чему я это все
1С — это сложная и многослойная система и изучать ее — крайне интересно. А чем лучше вы знаете работу своей системы — тем эффективнее можете ее использовать. Сегодня мы рассмотрели, как работает виртуальная машина языка 1С и, надеюсь, расширили наш технический кругозор. Ну и кроме того, получили в свои руки игрушку-конструктор, ведь играться с ассемблером довольно весело!
Творческих вам успехов!


{kind=link}