Привет, Хабр! Это второй пост в серии из трех частей, которая даст представление о механике и семантике работы планировщика в Go. Этот пост посвящен планировщику Go.
В первой части этого цикла я объяснил аспекты планировщика операционной системы, которые, на мой взгляд, важны для понимания и оценки семантики планировщика Go. В этом посте я объясню на семантическом уровне, как работает планировщик Go. Планировщик Go — сложная система, и мелкие механические детали не важны. Важно иметь хорошую модель того, как все работает и ведет себя. Это позволит вам принимать лучшие инженерные решения.
Когда ваша программа Go запускается, ей присваивается логический процессор (P) для каждого виртуального ядра, определенного на хост-машине. Если у вас есть процессор с несколькими аппаратными потоками на физическое ядро (Hyper-Threading), каждый аппаратный поток будет представлен вашей программе, как виртуальное ядро. Чтобы лучше понять это, взгляните на системный отчет для моего MacBook Pro.

Вы можете видеть, что у меня один процессор с 4 физическими ядрами. В этом отчете не раскрывается количество аппаратных потоков на каждое физическое ядро. Процессор Intel Core i7 имеет технологию Hyper-Threading, что означает, что на физическое ядро приходится 2 аппаратных потока. Это сообщит программе Go, что доступно 8 виртуальных ядер для параллельного выполнения потоков ОС. Чтобы проверить это, рассмотрим следующую программу:
Когда я запускаю эту программу на своем компьютере, результатом вызова функции NumCPU() будет значение 8. Любая программа Go, которую я запускаю на своем компьютере, получит 8(P).
Каждому P назначается поток ОС (M). Этот поток по-прежнему управляется ОС, и ОС по-прежнему отвечает за размещение потока в ядре для выполнения. Это означает, что когда я запускаю на своем компьютере программу Go, у меня есть 8 доступных потоков для выполнения моей работы, каждый из которых индивидуально связан с P.
Каждой программе Go также дается начальный Goroutine (G). Goroutine — это, по сути, Coroutine, но это Go, поэтому мы заменяем букву C на G и получаем слово Goroutine. Вы можете думать о Goroutines как о потоках уровня приложения, и они во многом похожи на потоки ОС. Так же, как потоки ОС включаются и выключаются ядром, контекстные программы включаются и выключаются контекстом.
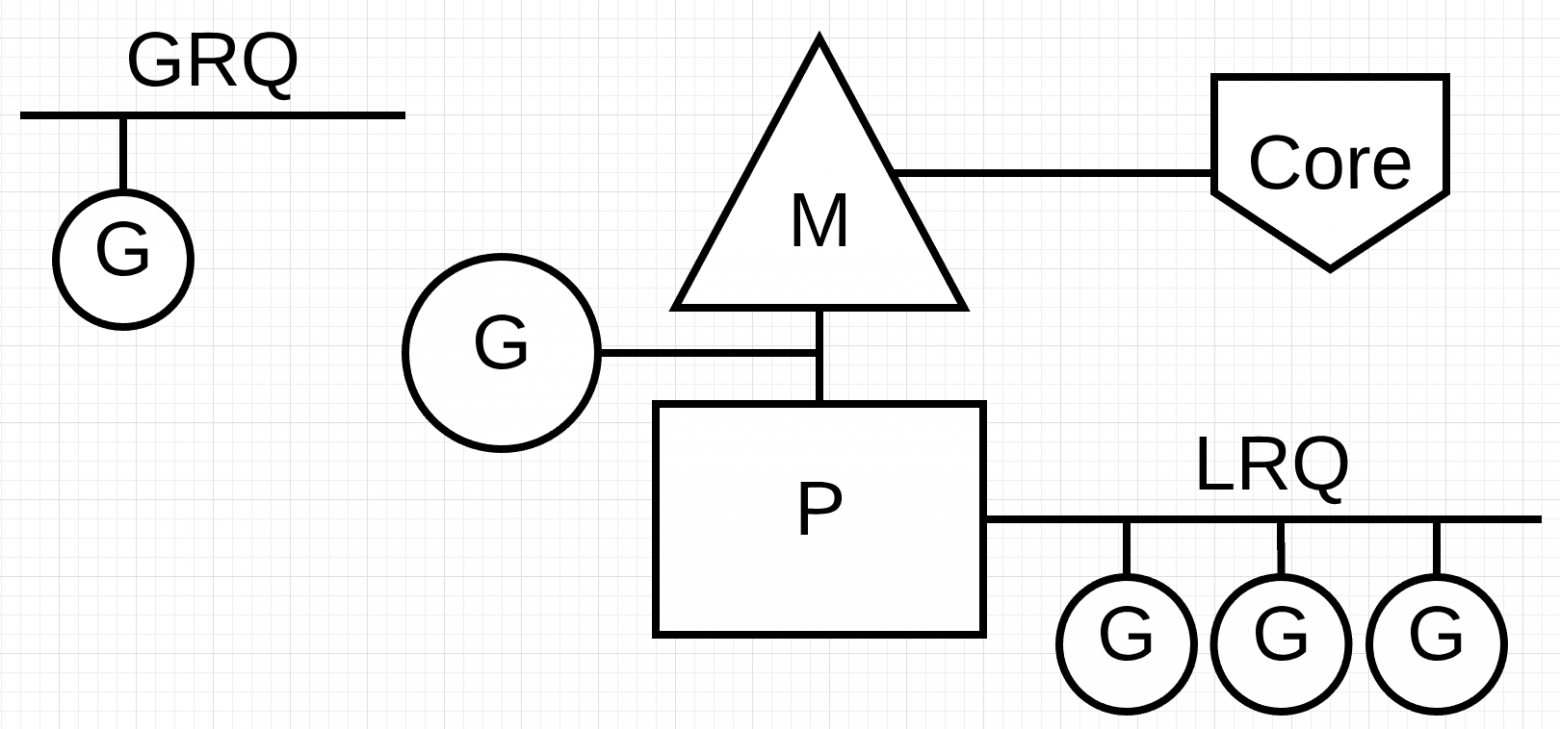
Последний пазл — это очереди на выполнение. В планировщике Go есть две разные очереди выполнения: глобальная очередь выполнения (GRQ) и локальная очередь выполнения (LRQ). Каждому P присваивается LRQ, который управляет горутинами, назначенными для выполнения в контексте P. Эти горутины по очереди включаются и выключаются из контекста M, назначенного для этого P. GRQ предназначен для горутин, которые не были назначены для P. Существует процесс, чтобы переместить горутины из GRQ в LRQ, который мы обсудим позже.
На рисунке представлено изображение всех этих компонентов вместе.
Как мы уже говорили в первом посте, планировщик ОС является вытесняющим планировщиком. По сути, это означает, что вы не можете предсказать, что планировщик собирается делать в любой момент времени. Ядро принимает решения и все недетерминировано. Приложения, работающие поверх операционной системы, не контролируют то, что происходит внутри ядра с планированием, если они не используют примитивы синхронизации, такие как атомарные инструкции и вызовы мьютекса.
Планировщик Go является частью среды исполнения Go, а среда исполнения Go встроена в ваше приложение. Это означает, что планировщик Go работает в пользовательском пространстве над ядром. Текущая реализация планировщика Go является не вытесняющим, а взаимодействующим планировщиком. Быть кооперативным планировщиком означает, что планировщику нужны четко определенные события в пространстве пользователя, которые происходят в безопасных точках кода для принятия решений по планированию.
Что хорошо в кооперативном планировщике Go, так это то, что он выглядит и чувствует себя упреждающим. Вы не можете предсказать, что собирается делать планировщик Go. Это связано с тем, что принятие решений для этого планировщика зависит не от разработчиков, а от времени выполнения Go. Важно думать о планировщике Go как об упреждающем планировщике, и, поскольку планировщик недетерминирован, это не слишком сложно.
Точно так же, как потоки, у горутин есть те же три состояния высокого уровня. Они определяют роль, которую планировщик Go играет с любой горутиной. Горутина может находиться в одном из трех состояний: Ожидание, Готовность или Выполнение.
Ожидание: это означает, что горутина остановлена и ждет чего-то, чтобы продолжить. Это может происходить по таким причинам, как ожидание операционной системы (системные вызовы) или синхронизация вызовов (атомарные и мьютексные операции). Эти типы задержек являются основной причиной плохой производительности.
Готовность: это означает, что горутина хочет получить время, чтобы выполнить назначенные инструкции. Если у вас много горутин, которым нужно время, то горутине придется ждать дольше, чтобы получить время. Кроме того, индивидуальное количество времени, которое получает любая горутина, сокращено, поскольку больше горутин конкурируют за время. Этот тип задержки планирования также может быть причиной плохой производительности.
Выполнение: это означает, что горутина была помещена в M и выполняет свои инструкции. Работа, связанная с приложением, завершена. Это то, что все хотят.
Планировщик Go требует четко определенных событий в пространстве пользователя, которые происходят в безопасных точках кода, для переключения контекста. Эти события и безопасные точки проявляются в вызовах функций. Вызовы функций имеют решающее значение для работоспособности планировщика Go. Если вы выполняете какие-либо узкие циклы, которые не выполняют вызовы функций, вы будете вызывать задержки в планировщике и сборке мусора. Крайне важно, чтобы вызовы функций происходили в разумные сроки.
Существует четыре класса событий, которые происходят в ваших программах Go, которые позволяют планировщику принимать решения по планированию. Это не значит, что это всегда будет происходить на одном из этих событий. Это означает, что планировщик получает возможность.
Использование ключевого слова go
Ключевое слово go — это то, как вы создаете горутину. Как только создается новая горутина, она дает планировщику возможность принять решение о планировании.
Cборщик мусора (GC)
Так как GC работает с собственным набором горутин, эти горутины нуждаются во времени на М для запуска. Это заставляет GC создавать много хаоса в планировании. Тем не менее, планировщик очень умен в том, что делает горутина, и он будет использовать это для принятия решений. Одним из разумных решений является переключение контекста на горутину, которая хочет обратиться к системному ресурсу, и никто больше кроме нее, во время сборки мусора. Когда GC работает, принимается много решений по планированию.
Системные вызовы
Если горутина делает системный вызов, который заставит ее заблокировать M, планировщик может переключать контекст на другую горутину, на тот же M.
Синхронизация
Если вызов атомарной операции, мьютекса или канала вызовет блокировку горутины, планировщик может переключить контекст для запуска новой горутины. Как только горутина может работать снова, она может быть поставлена в очередь и в конечном итоге переключиться обратно на M.
Когда операционная система, на которой вы работаете, имеет возможность обрабатывать системный вызов асинхронно, то, что называется network poller, может использоваться для более эффективной обработки системного вызова. Это достигается с помощью kqueue (MacOS), epoll (Linux) или iocp (Windows) в этих соответствующих ОС.
Сетевые системные вызовы могут обрабатываться асинхронно многими операционными системами, которые мы используем сегодня. Именно здесь network poller показывает себя, поскольку его основное назначение — обработка сетевых операций. Используя network poller для сетевых системных вызовов, планировщик может запретить горутинам блокировать M при выполнении этих системных вызовов. Это помогает держать M доступным для выполнения других горутин в LRQ P без необходимости создавать новые M. Это помогает уменьшить нагрузку планирования в ОС.
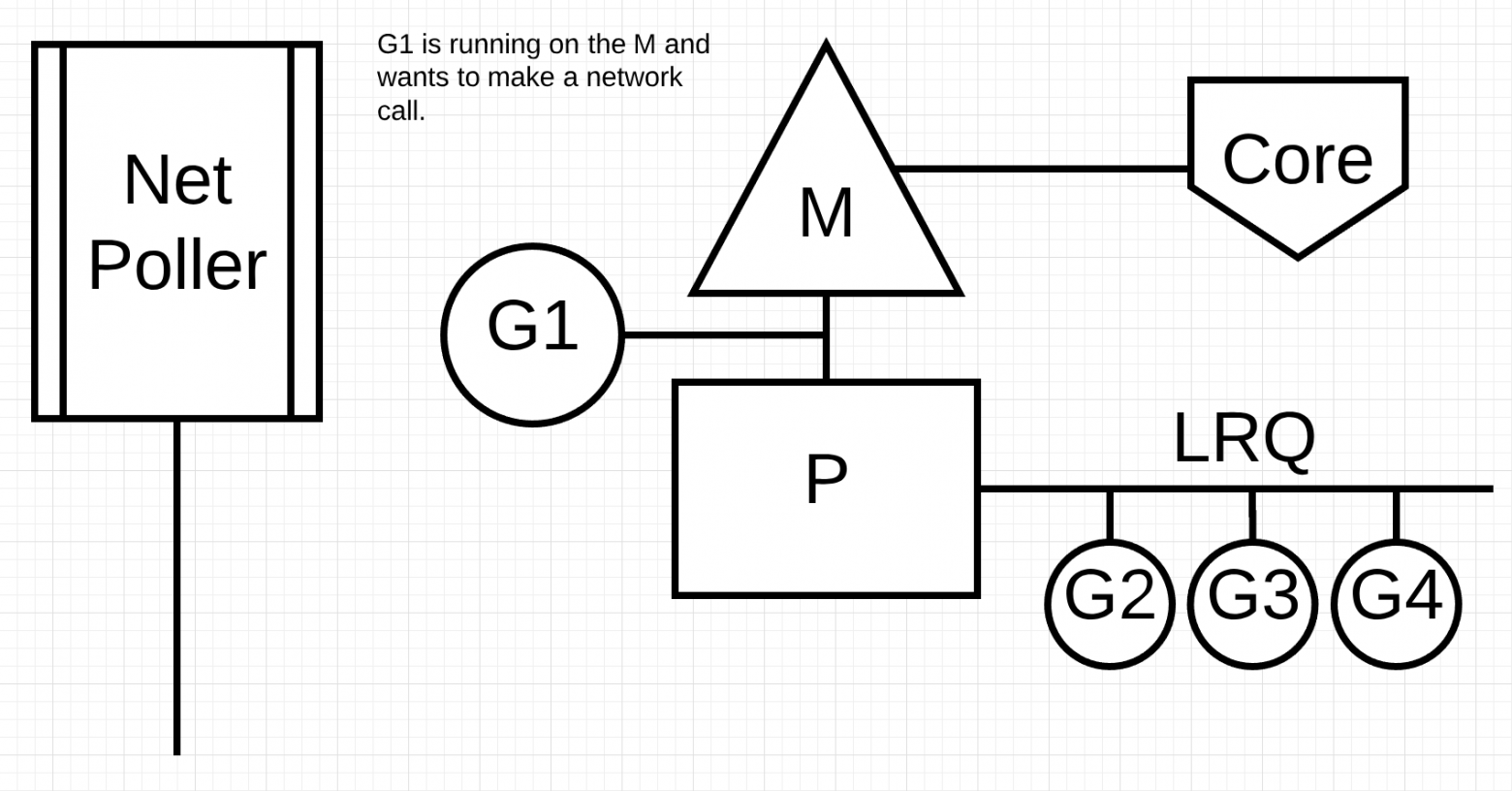
Лучший способ увидеть, как это работает — просмотреть пример. На рисунке показана наша базовая схема планирования. Горутина-1 выполняется на M, и еще 3 Горутины ждут в LRQ, чтобы получить свое время на M. Network poller бездействует, и ему нечего делать.
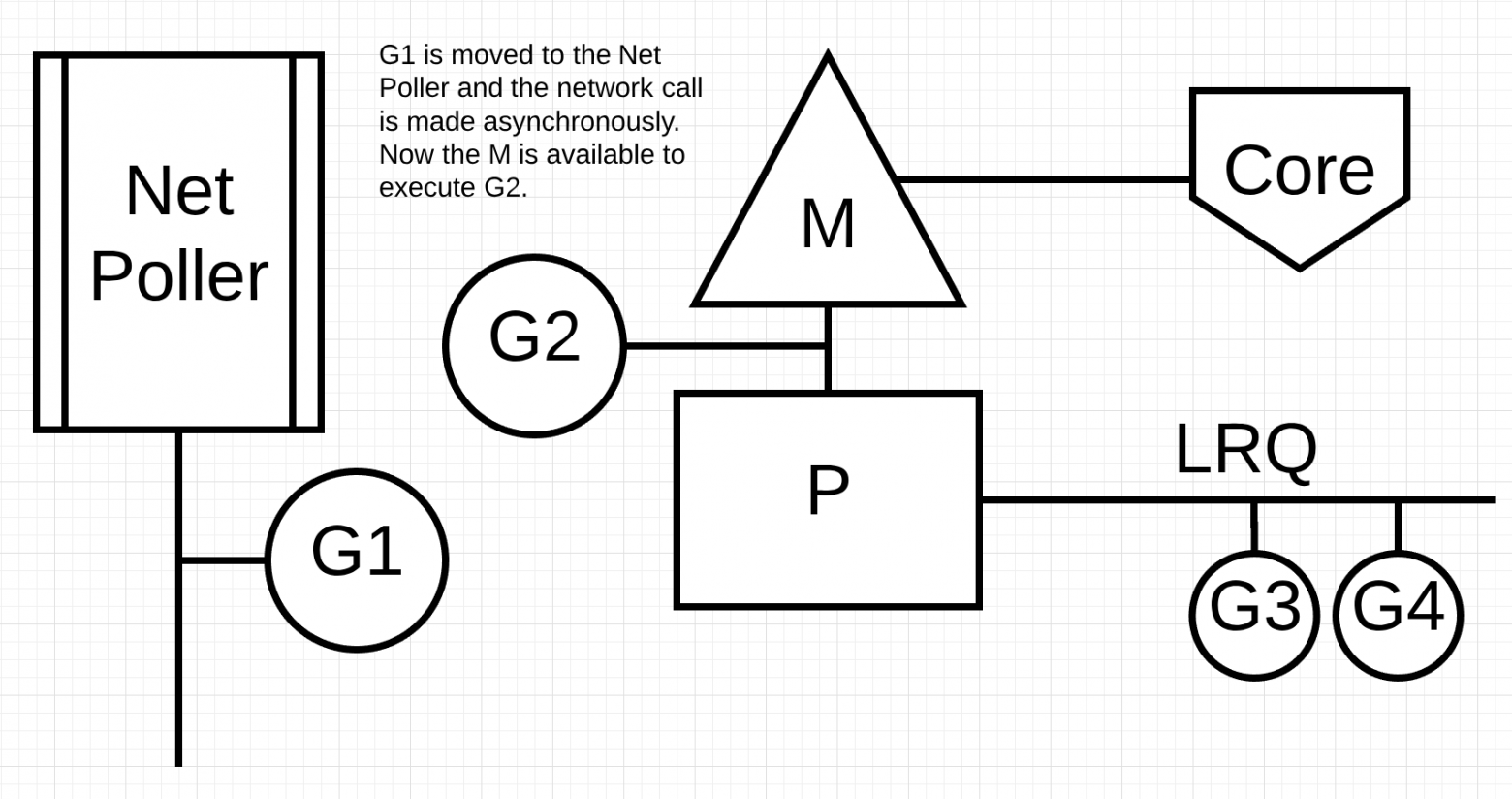
На следующем рисунке Горутина-1 (G1) хочет выполнить сетевой системный вызов, поэтому G1 перемещается в Network poller и обрабатывается как асинхронный сетевой системный вызов. Как только G1 перемещена в Network poller, M теперь доступен для выполнения другой горутины из LRQ. В этом случае Горутина-2 переключается на M.
На следующем рисунке системный сетевой вызов завершается асинхронным сетевым вызовом, и G1 перемещается обратно в LRQ для P. После того, как G1 может быть переключен обратно на M, код, связанный с Go, за который он отвечает может выполнить снова. Большой выигрыш в том, что для выполнения сетевых системных вызовов не требуется никаких дополнительных Ms. У Network poller есть поток ОС, и он обрабатывает через event loop.
Что происходит, когда горутина хочет сделать системный вызов, который не может быть выполнен асинхронно? В этом случае Network poller не может быть использован, и горутина, выполняющая системный вызов, заблокирует M. Это плохо, но не существует способа предотвратить это. Одним из примеров системного вызова, который не может быть выполнен асинхронно, являются системные вызовы на основе файлов. Если вы используете CGO, могут быть другие ситуации, когда вызов C-функций также блокирует M.
Далее на рисунке планировщик может определить, что G1 вызвал блокировку М. В этот момент планировщик отсоединяет M1 от P с блокирующим G1, все еще прикрепленным. Затем планировщик вводит новый M2 для обслуживания P. В этот момент G2 может быть выбрана из LRQ и включена в контекст M2. Если M уже существует из-за предыдущего обмена, этот переход происходит быстрее, чем необходимость создания нового M.
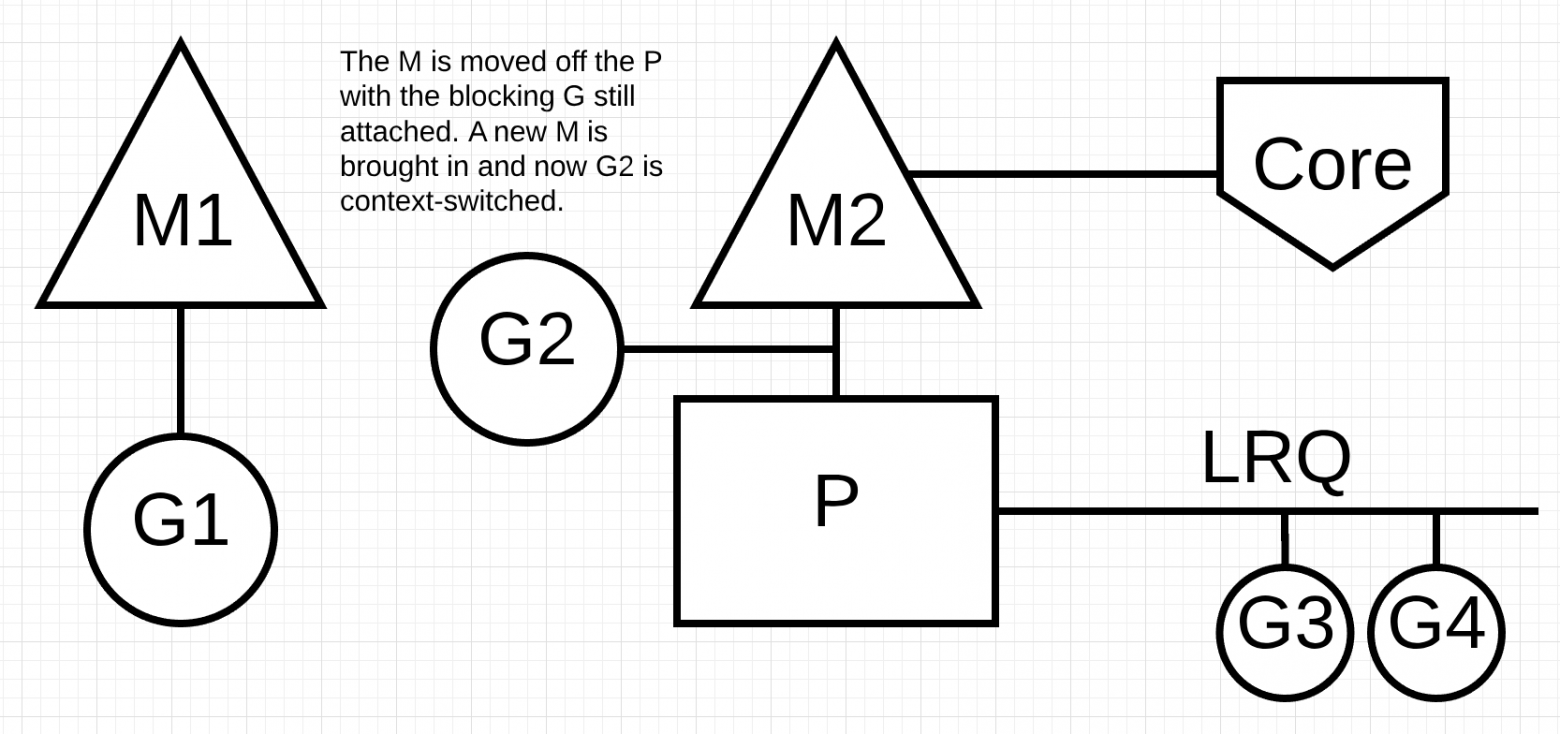
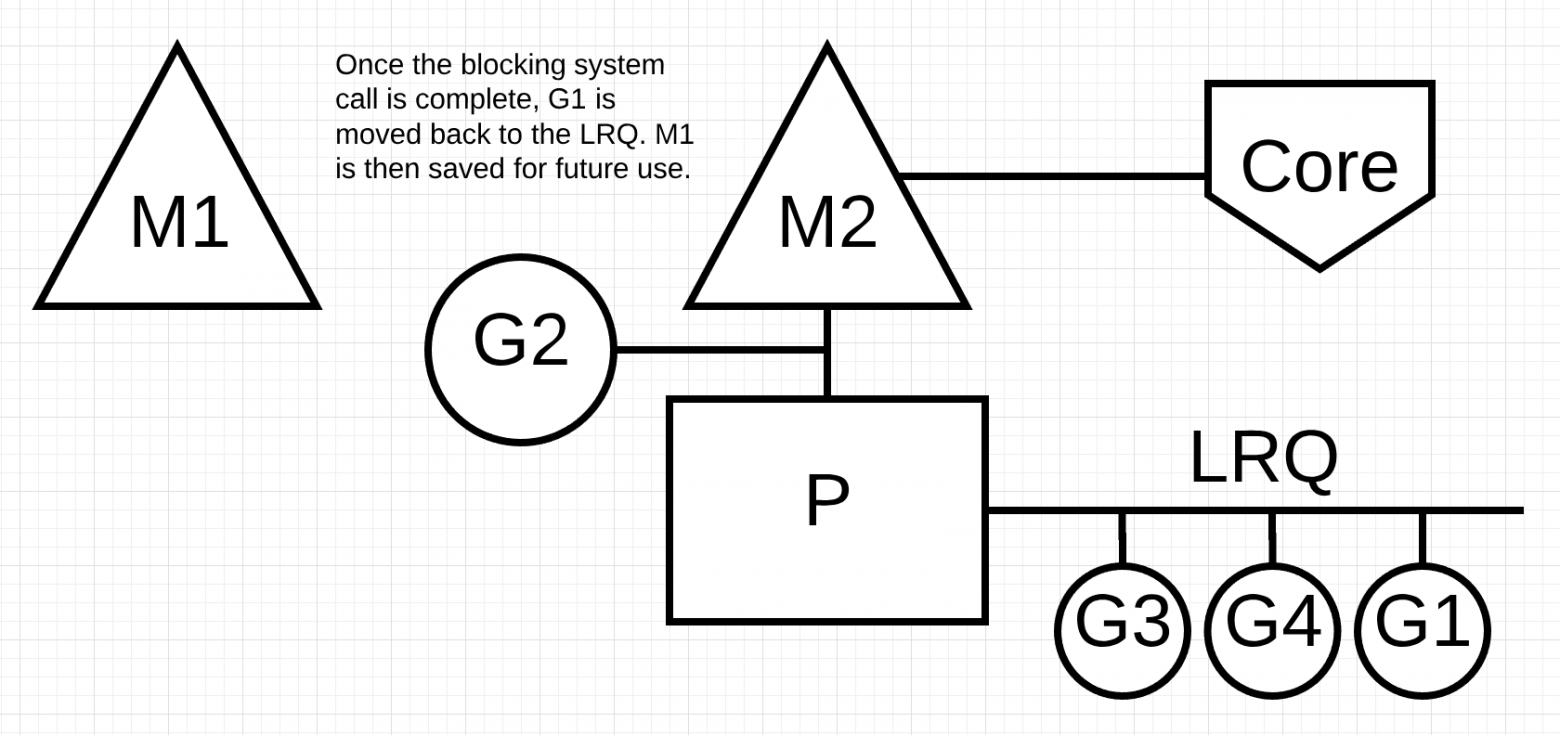
Следующим шагом завершается системный вызов блокировки, выполненный G1. В этот момент G1 может вернуться в LRQ и снова обслуживаться P. M1 затем уходит в сторону для будущего использования, если этот сценарий должен повториться.
Другим аспектом планировщика является то, что это планировщик «кражи горутин». Это помогает в нескольких областях поддерживать эффективное планирование. Во-первых, последнее, что вам нужно, это M перейти в состояние ожидания, потому что, как только это произойдет, ОС переключит M из ядра с помощью контекста. Это означает, что P не может выполнить какую-либо работу, даже если есть Goroutine в работоспособном состоянии, пока M не переключится обратно на ядро. «Кража горутин» также помогает сбалансировать временные интервалы между всеми P, чтобы работа распределялась лучше и выполнялась более эффективно.
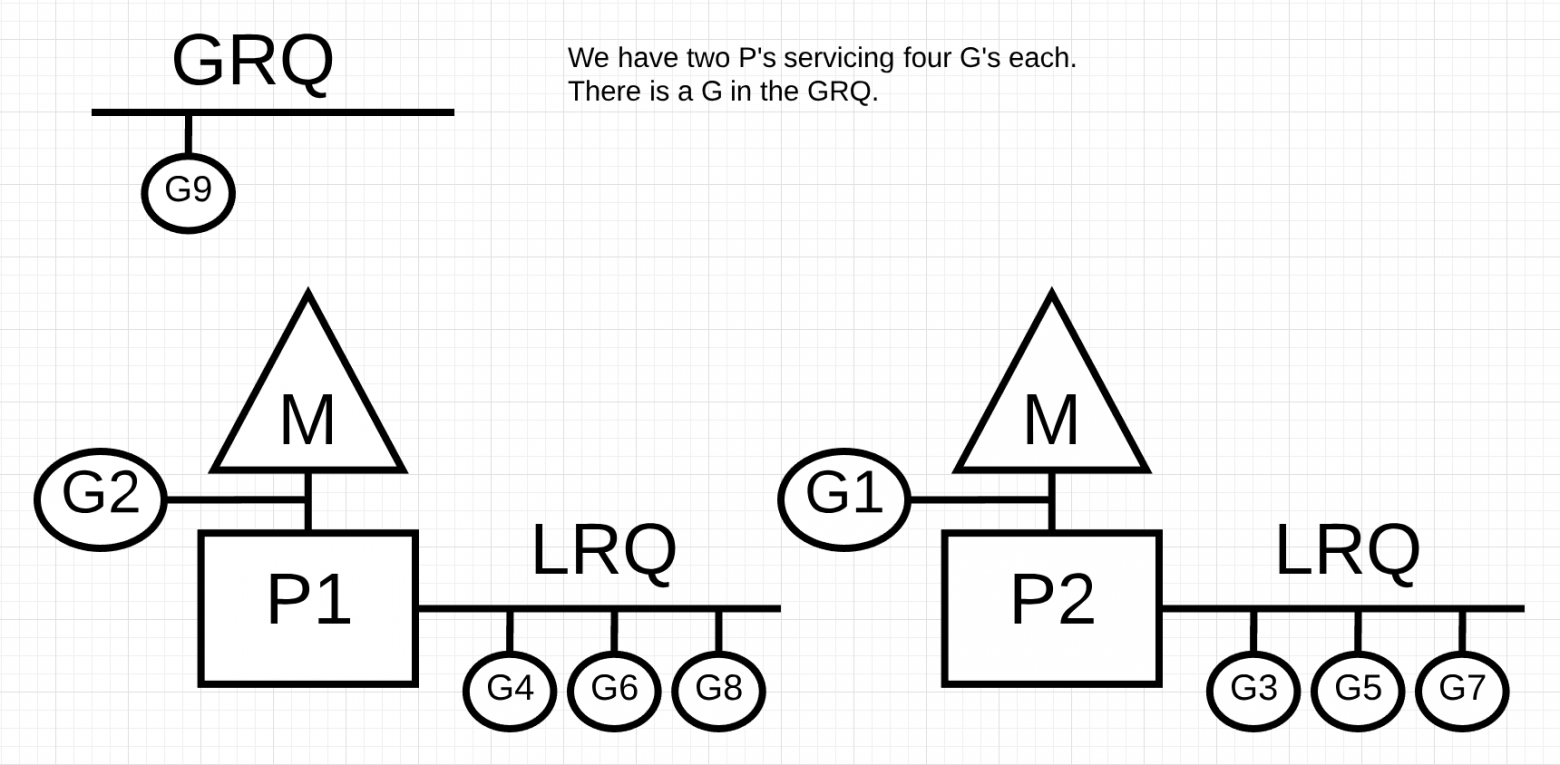
На рисунке у нас есть многопоточная программа Go с двумя P, обслуживающими четыре G каждый и один G в GRQ. Что произойдет, если один из P быстро обслуживает все свои G?
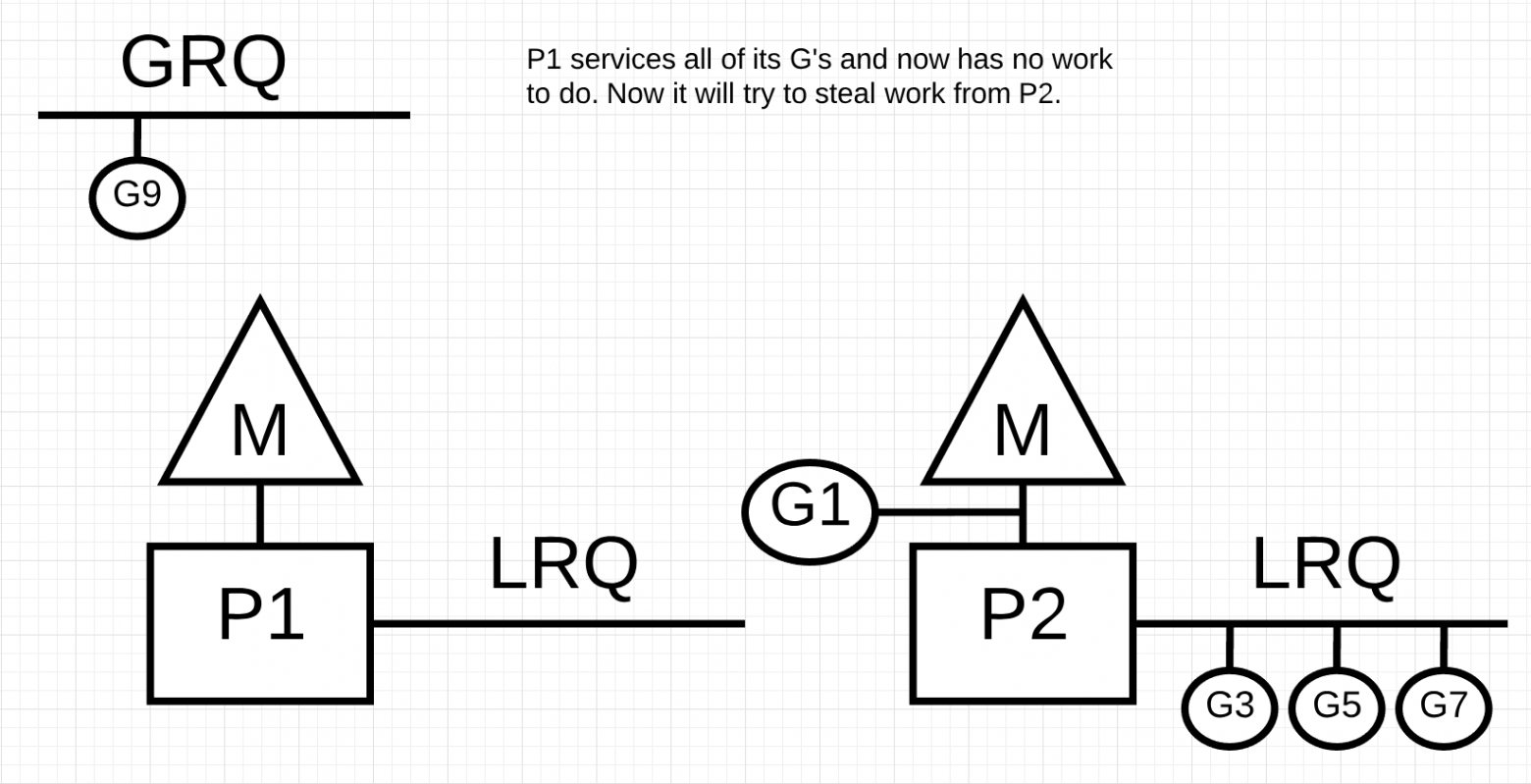
Далее у P1 больше нет горутин для выполнения. Но есть горутины в работоспособном состоянии, как в LRQ для P2, так и в GRQ. Это момент, когда P1 нужно украсть горутину.
Правила кражи горутины следующие. Весь код можно посмотреть в исходниках runtime.
Таким образом, основываясь на этих правилах, P1 должен проверить P2 на наличие горутин в своем LRQ и взять половину того, что он найдет.
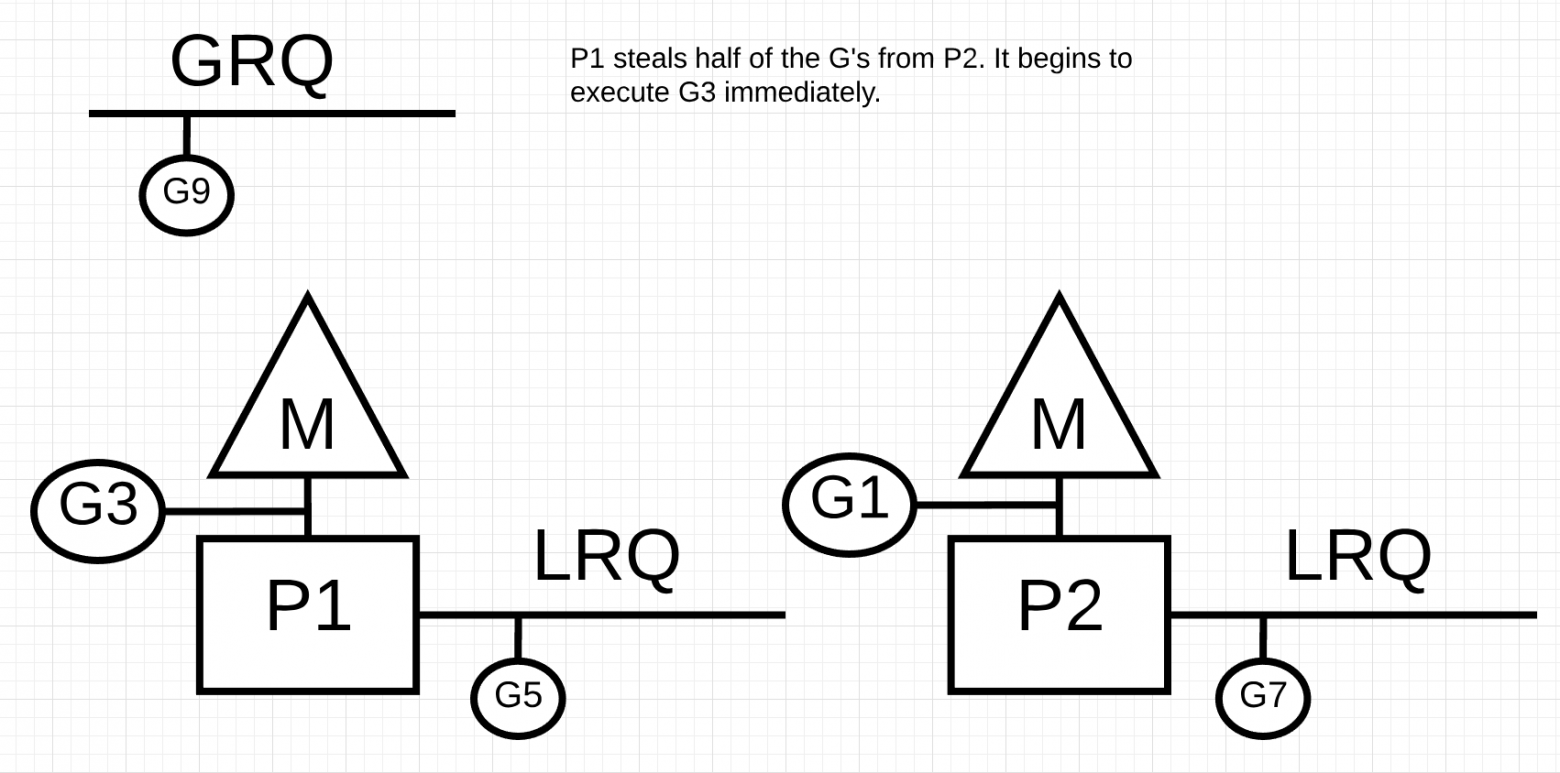
Что произойдет, если P2 завершит обслуживание всех своих программ и у P1 ничего не останется в LRQ?
P2 завершил всю свою работу и теперь должен украсть горутины. Во-первых, он будет смотреть на LRQ P1, но не найдет никаких Goroutines. Далее он будет смотреть на GRQ. Там он найдет G9.
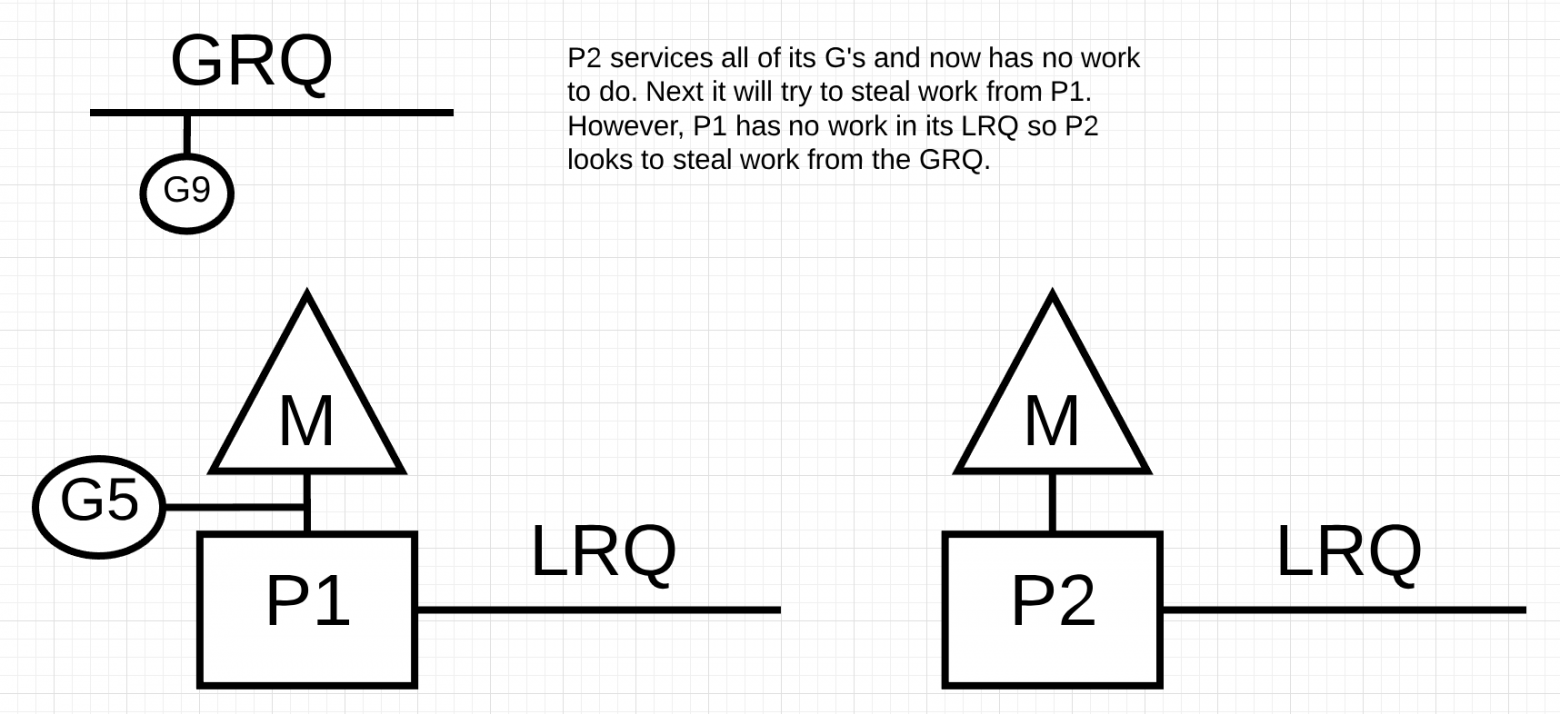
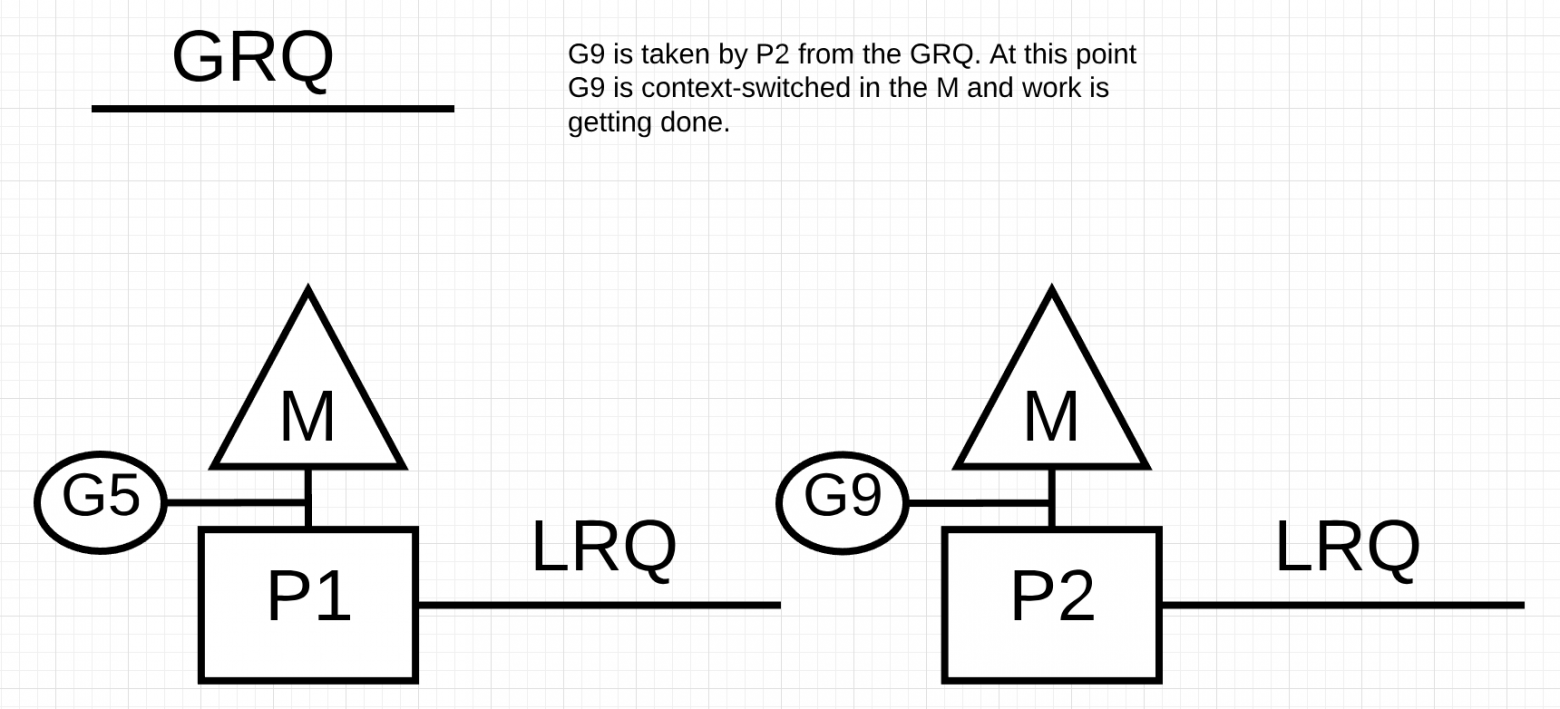
P2 крадет G9 из GRQ и начинает выполнять работу. Что хорошо во всей этой краже, так это то, что она позволяет M оставаться занятой и не бездействовать.
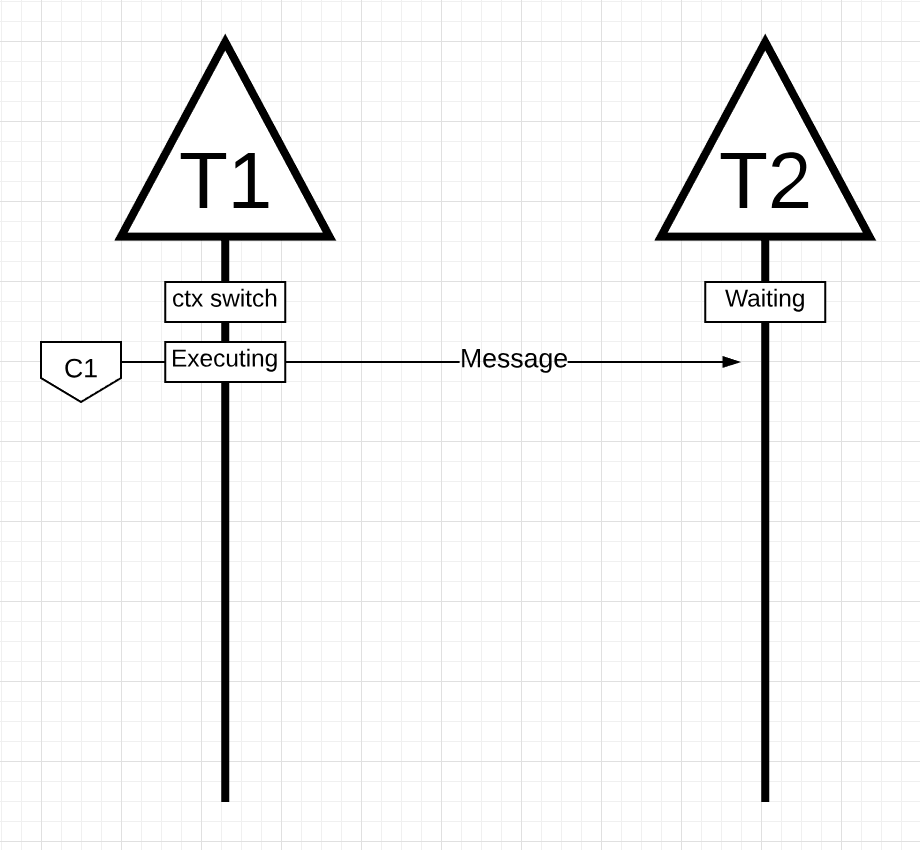
Имея механику и семантику, я хочу показать вам, как все это объединяется, чтобы планировщик Go мог выполнять больше работы с течением времени. Представьте себе многопоточное приложение, написанное на C, в котором программа управляет двумя потоками ОС, которые передают сообщения друг другу. На рисунке есть 2 потока, которые передают сообщение туда и обратно. Поток 1 получает context-switched core 1 и теперь выполняется, что позволяет потоку 1 отправить свое сообщение потоку 2.
Далее, когда поток 1 заканчивает отправку сообщения, теперь ему нужно дождаться ответа. Это приведет к тому, что поток 1 будет отключен от контекста ядра 1 и переведен в состояние ожидания. Как только поток 2 получает уведомление о сообщении, он переходит в работоспособное состояние. Теперь ОС может выполнять переключение контекста и запускать поток 2 на ядре, которое оказывается ядром 2. Затем поток 2 обрабатывает сообщение и отправляет новое сообщение обратно в поток 1.
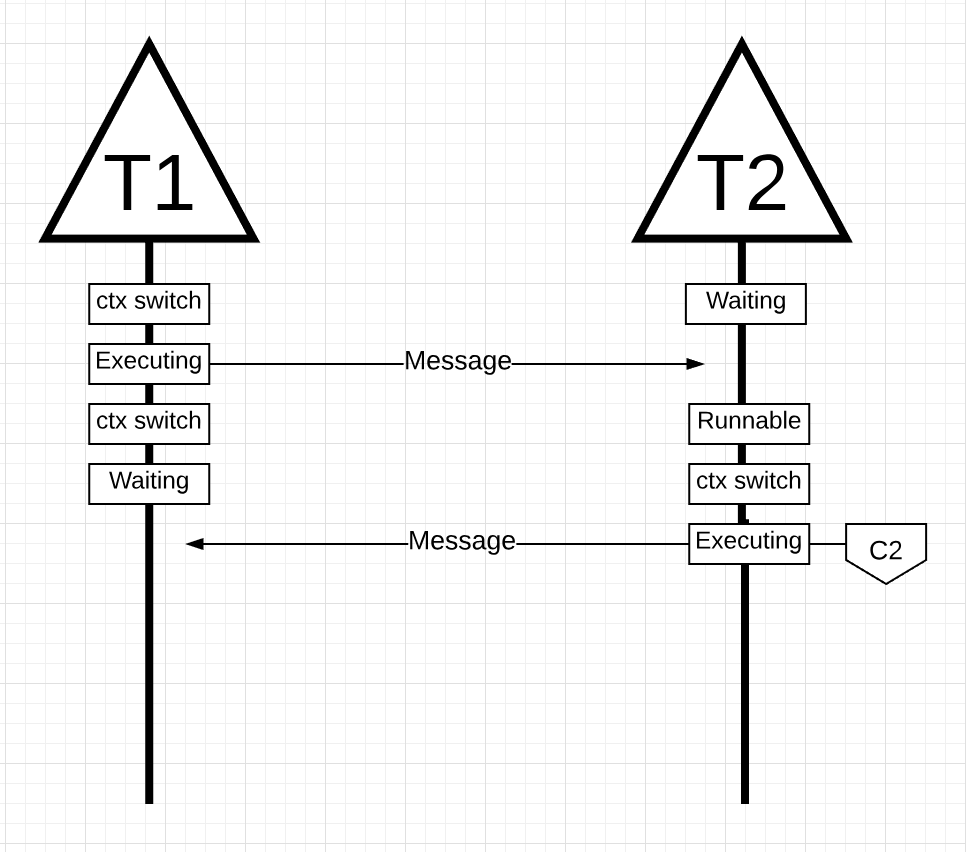
Далее поток снова переключается в контекст, когда сообщение от потока 2 принимается потоком 1. Теперь поток 2 переключается из состояния выполнения в состояние ожидания, а поток 1 переключается из состояния ожидания в состояние готовности и, наконец, возвращается в состояние выполнения, что позволяет ему обрабатывать и отправлять новое сообщение обратно. Все эти переключения контекста и изменения состояния требуют времени для выполнения, что ограничивает скорость выполнения работы. Поскольку каждое переключение контекста влечет за собой задержку ~ 1000 наносекунд, и мы надеемся, что аппаратное обеспечение выполняет 12 инструкций в наносекунду, вы смотрите на 12 000 инструкций, более или менее не выполняющихся во время этих переключений контекста. Так как эти потоки также пересекаются между различными ядрами, вероятность возникновения дополнительной задержки cache-line misses также высока.
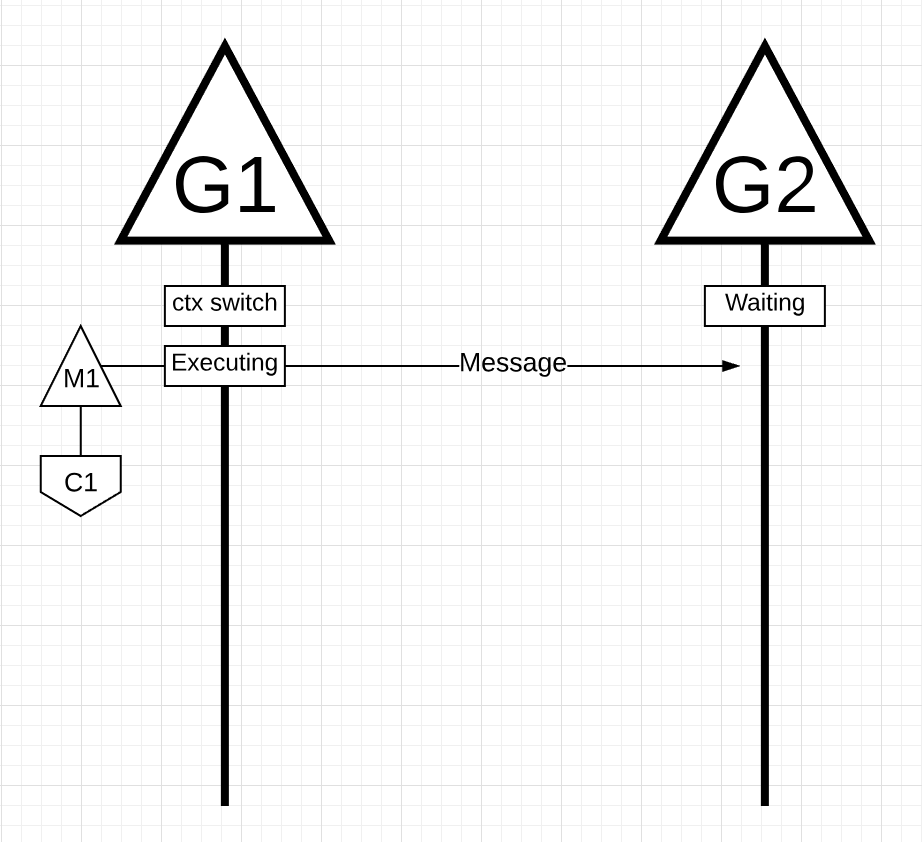
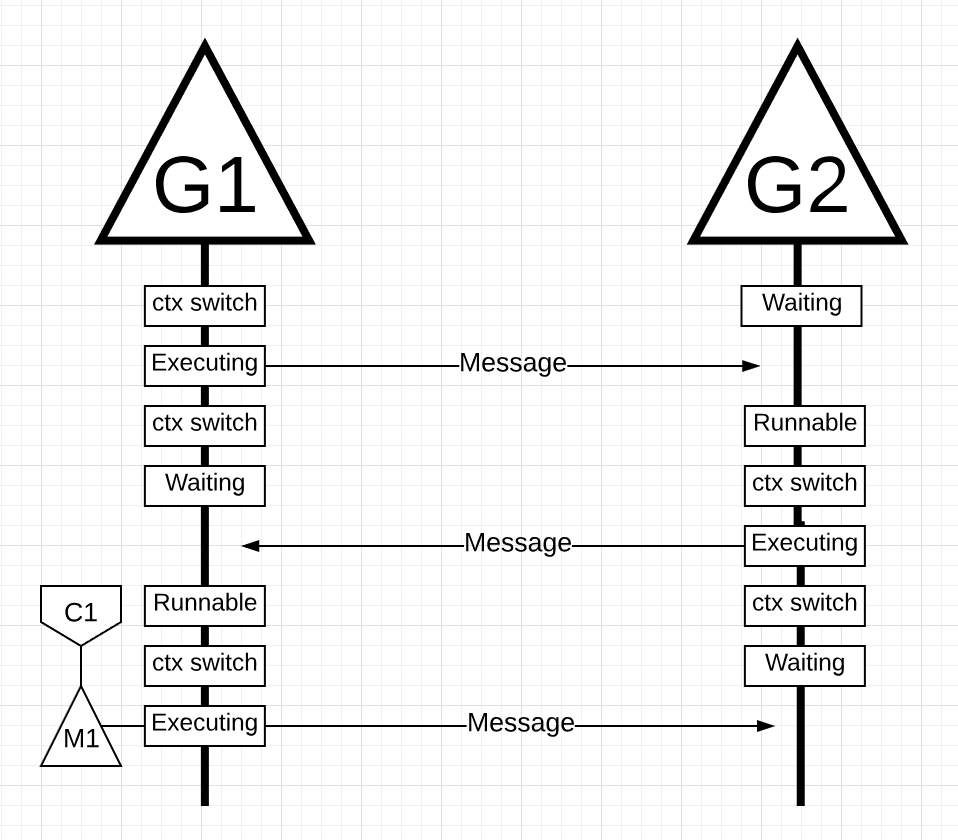
На рисунке есть две горутины, которые находятся в гармонии друг с другом, передавая сообщение туда-сюда. G1 получает переключение контекста M1, который работает на Core 1, что позволяет G1 выполнять свою работу.
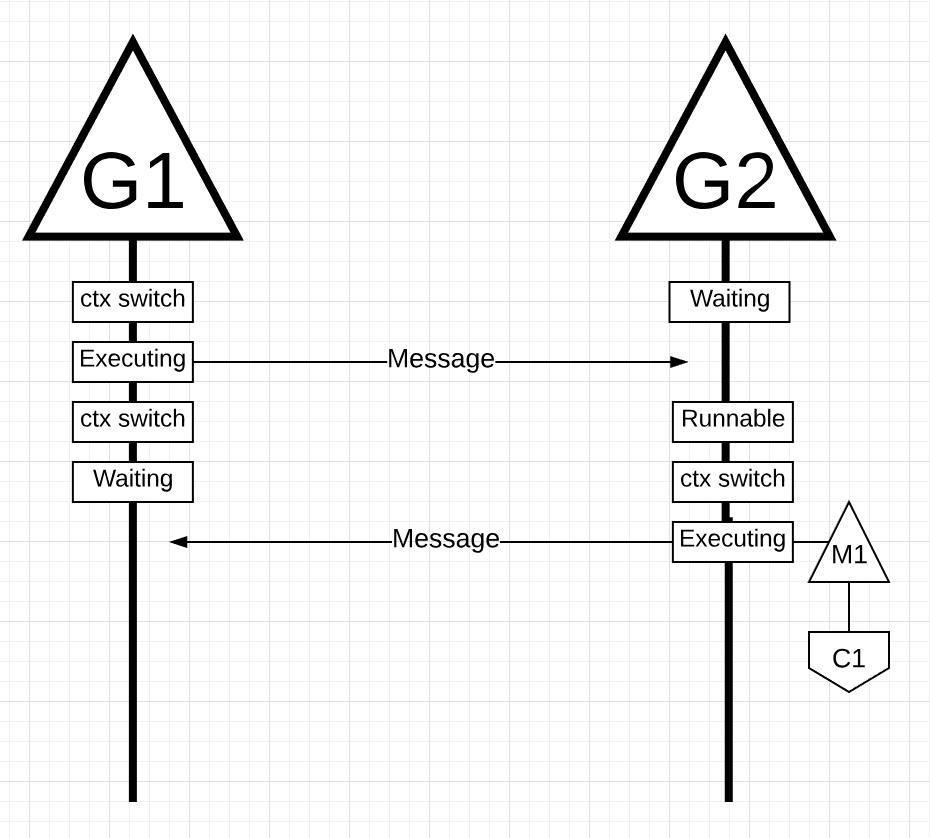
Далее, когда G1 заканчивает отправку сообщения, теперь ему нужно дождаться ответа. Это приведет к тому, что G1 будет отключен от контекста M1 и переведен в состояние ожидания. Как только G2 уведомляется о сообщении, оно переходит в работоспособное состояние. Теперь планировщик Go может выполнять переключение контекста и запускать G2 на M1, который все еще работает на Core 1. Затем G2 обрабатывает сообщение и отправляет новое сообщение обратно в G1.
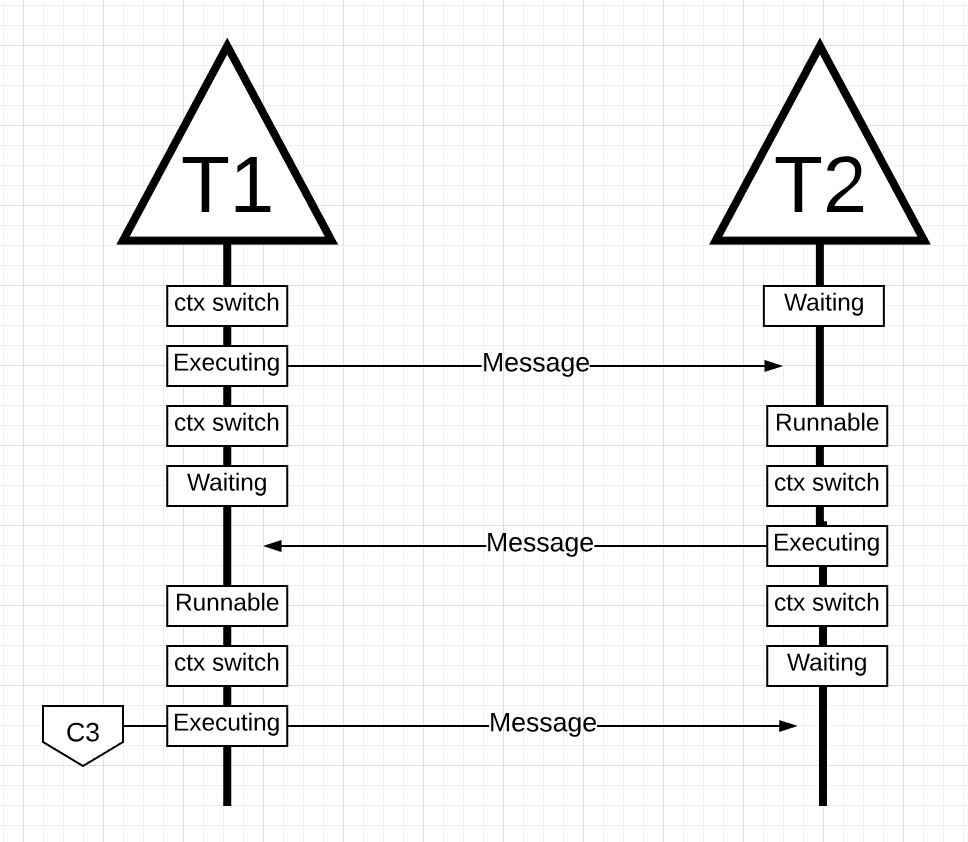
Cледующим шагом все снова переключается, когда сообщение, отправленное G2, принимается G1. Теперь контекст G2 переключается из состояния выполнения в состояние ожидания, а контекст G1 переключается из состояния ожидания в состояние выполнения и, наконец, обратно в состояние выполнения, что позволяет ему обрабатывать и отправлять новое сообщение обратно.
Вещи на поверхности, кажется, не отличаются. Все те же изменения контекста и изменения состояния происходят независимо от того, используете ли вы Потоки или Горутины. Однако существует большая разница между использованием Потоков и Горутин, которая может быть неочевидна на первый взгляд.
В случае использования горутин одни и те же потоки ОС и ядро используются для всей обработки. Это означает, что с точки зрения ОС Поток ОС никогда не переходит в состояние ожидания; ни разу. В результате все те инструкции, которые мы потеряли при переключении контекста, при использовании потоков, не теряются при использовании горутин.
По сути, Go превратил работу IO / Blocking в работу с привязкой к процессору на уровне ОС. Поскольку все переключение контекста происходит на уровне приложения, мы не теряем те же самые ~ 12 тыс. инструкций (в среднем) на переключение контекста, которые мы теряли при использовании потоков. В Go те же переключатели контекста стоят вам ~ 200 наносекунд или ~ 2,4 тыс. команд. Планировщик также помогает повысить эффективность строк кэширования и NUMA. Вот почему нам не нужно больше потоков, чем у нас есть виртуальные ядра. В Go можно со временем выполнять больше работы, потому что планировщик Go пытается использовать меньше потоков и делать больше на каждом потоке, что помогает снизить нагрузку на ОС и оборудование.
Планировщик Go действительно удивителен тем, как он учитывает тонкости работы ОС и оборудования. Возможность превратить работу ввода-вывода / блокировки в работу с процессором с привязкой к процессору на уровне операционной системы — это то, где мы получаем большой выигрыш в использовании большей мощности процессора с течением времени. Вот почему вам не нужно больше потоков ОС, чем у вас есть виртуальные ядра. Вы можете разумно ожидать, что вся ваша работа будет выполнена (с привязкой к процессору и вводу-выводу / блокировкам) с одним потоком ОС на виртуальное ядро. Это возможно для сетевых приложений и других приложений, которым не нужны системные вызовы, блокирующие потоки ОС.
Как разработчик, вы все равно должны понимать, что делает ваше приложение с точки зрения типа работы. Вы не можете создавать неограниченное количество горутин и ожидать потрясающую производительность. Меньше — всегда больше, но с пониманием этой семантики Go-планировщика вы можете принимать лучшие инженерные решения.
В первой части этого цикла я объяснил аспекты планировщика операционной системы, которые, на мой взгляд, важны для понимания и оценки семантики планировщика Go. В этом посте я объясню на семантическом уровне, как работает планировщик Go. Планировщик Go — сложная система, и мелкие механические детали не важны. Важно иметь хорошую модель того, как все работает и ведет себя. Это позволит вам принимать лучшие инженерные решения.
Ваша программа запускается
Когда ваша программа Go запускается, ей присваивается логический процессор (P) для каждого виртуального ядра, определенного на хост-машине. Если у вас есть процессор с несколькими аппаратными потоками на физическое ядро (Hyper-Threading), каждый аппаратный поток будет представлен вашей программе, как виртуальное ядро. Чтобы лучше понять это, взгляните на системный отчет для моего MacBook Pro.
Вы можете видеть, что у меня один процессор с 4 физическими ядрами. В этом отчете не раскрывается количество аппаратных потоков на каждое физическое ядро. Процессор Intel Core i7 имеет технологию Hyper-Threading, что означает, что на физическое ядро приходится 2 аппаратных потока. Это сообщит программе Go, что доступно 8 виртуальных ядер для параллельного выполнения потоков ОС. Чтобы проверить это, рассмотрим следующую программу:
package main import ( "fmt" "runtime" ) func main() { // NumCPU returns the number of logical // CPUs usable by the current process. fmt.Println(runtime.NumCPU()) }
Когда я запускаю эту программу на своем компьютере, результатом вызова функции NumCPU() будет значение 8. Любая программа Go, которую я запускаю на своем компьютере, получит 8(P).
Каждому P назначается поток ОС (M). Этот поток по-прежнему управляется ОС, и ОС по-прежнему отвечает за размещение потока в ядре для выполнения. Это означает, что когда я запускаю на своем компьютере программу Go, у меня есть 8 доступных потоков для выполнения моей работы, каждый из которых индивидуально связан с P.
Каждой программе Go также дается начальный Goroutine (G). Goroutine — это, по сути, Coroutine, но это Go, поэтому мы заменяем букву C на G и получаем слово Goroutine. Вы можете думать о Goroutines как о потоках уровня приложения, и они во многом похожи на потоки ОС. Так же, как потоки ОС включаются и выключаются ядром, контекстные программы включаются и выключаются контекстом.
Последний пазл — это очереди на выполнение. В планировщике Go есть две разные очереди выполнения: глобальная очередь выполнения (GRQ) и локальная очередь выполнения (LRQ). Каждому P присваивается LRQ, который управляет горутинами, назначенными для выполнения в контексте P. Эти горутины по очереди включаются и выключаются из контекста M, назначенного для этого P. GRQ предназначен для горутин, которые не были назначены для P. Существует процесс, чтобы переместить горутины из GRQ в LRQ, который мы обсудим позже.
На рисунке представлено изображение всех этих компонентов вместе.
Кооперативный планировщик
Как мы уже говорили в первом посте, планировщик ОС является вытесняющим планировщиком. По сути, это означает, что вы не можете предсказать, что планировщик собирается делать в любой момент времени. Ядро принимает решения и все недетерминировано. Приложения, работающие поверх операционной системы, не контролируют то, что происходит внутри ядра с планированием, если они не используют примитивы синхронизации, такие как атомарные инструкции и вызовы мьютекса.
Планировщик Go является частью среды исполнения Go, а среда исполнения Go встроена в ваше приложение. Это означает, что планировщик Go работает в пользовательском пространстве над ядром. Текущая реализация планировщика Go является не вытесняющим, а взаимодействующим планировщиком. Быть кооперативным планировщиком означает, что планировщику нужны четко определенные события в пространстве пользователя, которые происходят в безопасных точках кода для принятия решений по планированию.
Что хорошо в кооперативном планировщике Go, так это то, что он выглядит и чувствует себя упреждающим. Вы не можете предсказать, что собирается делать планировщик Go. Это связано с тем, что принятие решений для этого планировщика зависит не от разработчиков, а от времени выполнения Go. Важно думать о планировщике Go как об упреждающем планировщике, и, поскольку планировщик недетерминирован, это не слишком сложно.
Состояния Горутин
Точно так же, как потоки, у горутин есть те же три состояния высокого уровня. Они определяют роль, которую планировщик Go играет с любой горутиной. Горутина может находиться в одном из трех состояний: Ожидание, Готовность или Выполнение.
Ожидание: это означает, что горутина остановлена и ждет чего-то, чтобы продолжить. Это может происходить по таким причинам, как ожидание операционной системы (системные вызовы) или синхронизация вызовов (атомарные и мьютексные операции). Эти типы задержек являются основной причиной плохой производительности.
Готовность: это означает, что горутина хочет получить время, чтобы выполнить назначенные инструкции. Если у вас много горутин, которым нужно время, то горутине придется ждать дольше, чтобы получить время. Кроме того, индивидуальное количество времени, которое получает любая горутина, сокращено, поскольку больше горутин конкурируют за время. Этот тип задержки планирования также может быть причиной плохой производительности.
Выполнение: это означает, что горутина была помещена в M и выполняет свои инструкции. Работа, связанная с приложением, завершена. Это то, что все хотят.
Переключение контекста
Планировщик Go требует четко определенных событий в пространстве пользователя, которые происходят в безопасных точках кода, для переключения контекста. Эти события и безопасные точки проявляются в вызовах функций. Вызовы функций имеют решающее значение для работоспособности планировщика Go. Если вы выполняете какие-либо узкие циклы, которые не выполняют вызовы функций, вы будете вызывать задержки в планировщике и сборке мусора. Крайне важно, чтобы вызовы функций происходили в разумные сроки.
Существует четыре класса событий, которые происходят в ваших программах Go, которые позволяют планировщику принимать решения по планированию. Это не значит, что это всегда будет происходить на одном из этих событий. Это означает, что планировщик получает возможность.
- Использование ключевого слова go
- Cборщик мусора
- Системные вызовы
- Синхронизация
Использование ключевого слова go
Ключевое слово go — это то, как вы создаете горутину. Как только создается новая горутина, она дает планировщику возможность принять решение о планировании.
Cборщик мусора (GC)
Так как GC работает с собственным набором горутин, эти горутины нуждаются во времени на М для запуска. Это заставляет GC создавать много хаоса в планировании. Тем не менее, планировщик очень умен в том, что делает горутина, и он будет использовать это для принятия решений. Одним из разумных решений является переключение контекста на горутину, которая хочет обратиться к системному ресурсу, и никто больше кроме нее, во время сборки мусора. Когда GC работает, принимается много решений по планированию.
Системные вызовы
Если горутина делает системный вызов, который заставит ее заблокировать M, планировщик может переключать контекст на другую горутину, на тот же M.
Синхронизация
Если вызов атомарной операции, мьютекса или канала вызовет блокировку горутины, планировщик может переключить контекст для запуска новой горутины. Как только горутина может работать снова, она может быть поставлена в очередь и в конечном итоге переключиться обратно на M.
Асинхронные системные вызовы
Когда операционная система, на которой вы работаете, имеет возможность обрабатывать системный вызов асинхронно, то, что называется network poller, может использоваться для более эффективной обработки системного вызова. Это достигается с помощью kqueue (MacOS), epoll (Linux) или iocp (Windows) в этих соответствующих ОС.
Сетевые системные вызовы могут обрабатываться асинхронно многими операционными системами, которые мы используем сегодня. Именно здесь network poller показывает себя, поскольку его основное назначение — обработка сетевых операций. Используя network poller для сетевых системных вызовов, планировщик может запретить горутинам блокировать M при выполнении этих системных вызовов. Это помогает держать M доступным для выполнения других горутин в LRQ P без необходимости создавать новые M. Это помогает уменьшить нагрузку планирования в ОС.
Лучший способ увидеть, как это работает — просмотреть пример. На рисунке показана наша базовая схема планирования. Горутина-1 выполняется на M, и еще 3 Горутины ждут в LRQ, чтобы получить свое время на M. Network poller бездействует, и ему нечего делать.
На следующем рисунке Горутина-1 (G1) хочет выполнить сетевой системный вызов, поэтому G1 перемещается в Network poller и обрабатывается как асинхронный сетевой системный вызов. Как только G1 перемещена в Network poller, M теперь доступен для выполнения другой горутины из LRQ. В этом случае Горутина-2 переключается на M.
На следующем рисунке системный сетевой вызов завершается асинхронным сетевым вызовом, и G1 перемещается обратно в LRQ для P. После того, как G1 может быть переключен обратно на M, код, связанный с Go, за который он отвечает может выполнить снова. Большой выигрыш в том, что для выполнения сетевых системных вызовов не требуется никаких дополнительных Ms. У Network poller есть поток ОС, и он обрабатывает через event loop.
Синхронные системные вызовы
Что происходит, когда горутина хочет сделать системный вызов, который не может быть выполнен асинхронно? В этом случае Network poller не может быть использован, и горутина, выполняющая системный вызов, заблокирует M. Это плохо, но не существует способа предотвратить это. Одним из примеров системного вызова, который не может быть выполнен асинхронно, являются системные вызовы на основе файлов. Если вы используете CGO, могут быть другие ситуации, когда вызов C-функций также блокирует M.
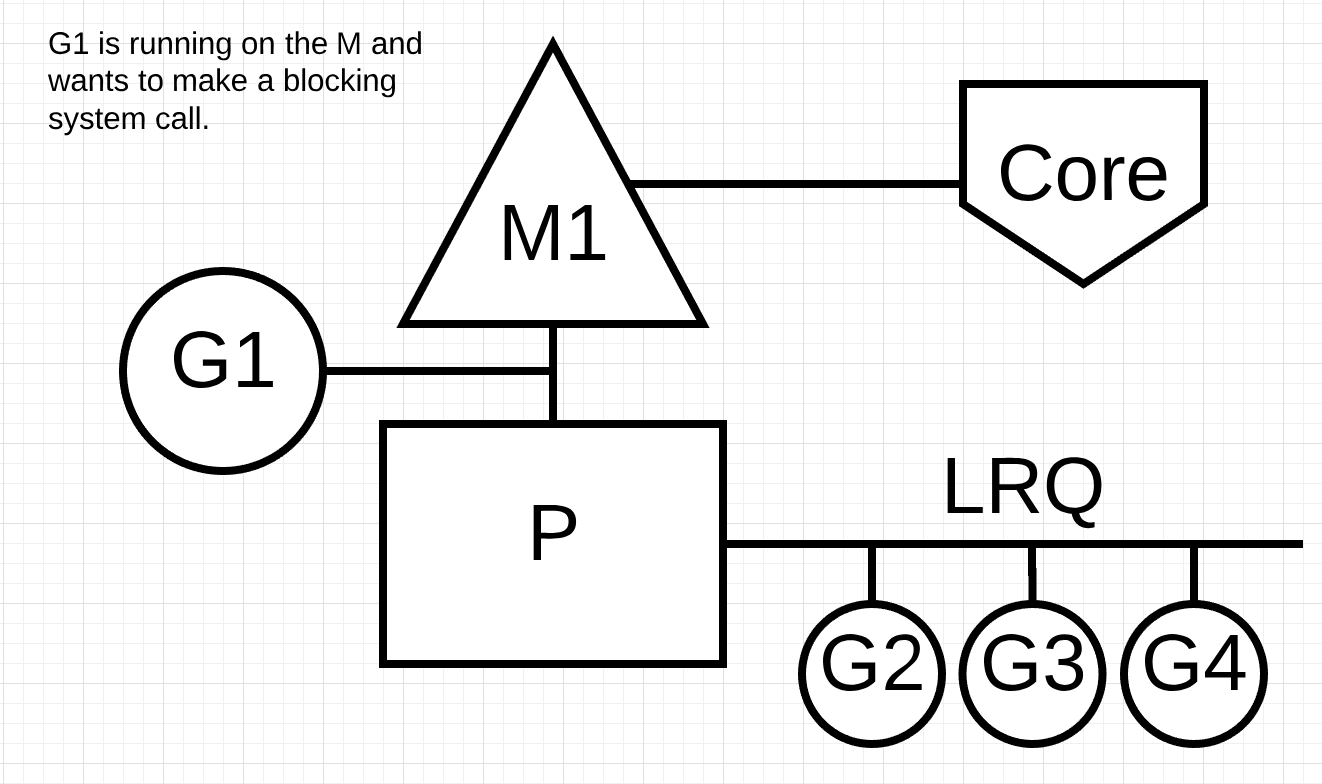
Операционная система Windows может выполнять асинхронные системные вызовы на основе файлов. Технически при работе в Windows можно использовать Network poller.Давайте посмотрим, что происходит с синхронным системным вызовом (например, файловым вводом / выводом), который приведет к блокировке М. На рисунке показана наша базовая диаграмма планирования, но на этот раз G1 собирается сделать синхронный системный вызов, который заблокирует M1.
Далее на рисунке планировщик может определить, что G1 вызвал блокировку М. В этот момент планировщик отсоединяет M1 от P с блокирующим G1, все еще прикрепленным. Затем планировщик вводит новый M2 для обслуживания P. В этот момент G2 может быть выбрана из LRQ и включена в контекст M2. Если M уже существует из-за предыдущего обмена, этот переход происходит быстрее, чем необходимость создания нового M.
Следующим шагом завершается системный вызов блокировки, выполненный G1. В этот момент G1 может вернуться в LRQ и снова обслуживаться P. M1 затем уходит в сторону для будущего использования, если этот сценарий должен повториться.
Work Stealing
Другим аспектом планировщика является то, что это планировщик «кражи горутин». Это помогает в нескольких областях поддерживать эффективное планирование. Во-первых, последнее, что вам нужно, это M перейти в состояние ожидания, потому что, как только это произойдет, ОС переключит M из ядра с помощью контекста. Это означает, что P не может выполнить какую-либо работу, даже если есть Goroutine в работоспособном состоянии, пока M не переключится обратно на ядро. «Кража горутин» также помогает сбалансировать временные интервалы между всеми P, чтобы работа распределялась лучше и выполнялась более эффективно.
На рисунке у нас есть многопоточная программа Go с двумя P, обслуживающими четыре G каждый и один G в GRQ. Что произойдет, если один из P быстро обслуживает все свои G?
Далее у P1 больше нет горутин для выполнения. Но есть горутины в работоспособном состоянии, как в LRQ для P2, так и в GRQ. Это момент, когда P1 нужно украсть горутину.
Правила кражи горутины следующие. Весь код можно посмотреть в исходниках runtime.
runtime.schedule() { // only 1/61 of the time, check the global runnable queue for a G. // if not found, check the local queue. // if not found, // try to steal from other Ps. // if not, check the global runnable queue. // if not found, poll network. }
Таким образом, основываясь на этих правилах, P1 должен проверить P2 на наличие горутин в своем LRQ и взять половину того, что он найдет.
Что произойдет, если P2 завершит обслуживание всех своих программ и у P1 ничего не останется в LRQ?
P2 завершил всю свою работу и теперь должен украсть горутины. Во-первых, он будет смотреть на LRQ P1, но не найдет никаких Goroutines. Далее он будет смотреть на GRQ. Там он найдет G9.
P2 крадет G9 из GRQ и начинает выполнять работу. Что хорошо во всей этой краже, так это то, что она позволяет M оставаться занятой и не бездействовать.
Практический пример
Имея механику и семантику, я хочу показать вам, как все это объединяется, чтобы планировщик Go мог выполнять больше работы с течением времени. Представьте себе многопоточное приложение, написанное на C, в котором программа управляет двумя потоками ОС, которые передают сообщения друг другу. На рисунке есть 2 потока, которые передают сообщение туда и обратно. Поток 1 получает context-switched core 1 и теперь выполняется, что позволяет потоку 1 отправить свое сообщение потоку 2.
Далее, когда поток 1 заканчивает отправку сообщения, теперь ему нужно дождаться ответа. Это приведет к тому, что поток 1 будет отключен от контекста ядра 1 и переведен в состояние ожидания. Как только поток 2 получает уведомление о сообщении, он переходит в работоспособное состояние. Теперь ОС может выполнять переключение контекста и запускать поток 2 на ядре, которое оказывается ядром 2. Затем поток 2 обрабатывает сообщение и отправляет новое сообщение обратно в поток 1.
Далее поток снова переключается в контекст, когда сообщение от потока 2 принимается потоком 1. Теперь поток 2 переключается из состояния выполнения в состояние ожидания, а поток 1 переключается из состояния ожидания в состояние готовности и, наконец, возвращается в состояние выполнения, что позволяет ему обрабатывать и отправлять новое сообщение обратно. Все эти переключения контекста и изменения состояния требуют времени для выполнения, что ограничивает скорость выполнения работы. Поскольку каждое переключение контекста влечет за собой задержку ~ 1000 наносекунд, и мы надеемся, что аппаратное обеспечение выполняет 12 инструкций в наносекунду, вы смотрите на 12 000 инструкций, более или менее не выполняющихся во время этих переключений контекста. Так как эти потоки также пересекаются между различными ядрами, вероятность возникновения дополнительной задержки cache-line misses также высока.
На рисунке есть две горутины, которые находятся в гармонии друг с другом, передавая сообщение туда-сюда. G1 получает переключение контекста M1, который работает на Core 1, что позволяет G1 выполнять свою работу.
Далее, когда G1 заканчивает отправку сообщения, теперь ему нужно дождаться ответа. Это приведет к тому, что G1 будет отключен от контекста M1 и переведен в состояние ожидания. Как только G2 уведомляется о сообщении, оно переходит в работоспособное состояние. Теперь планировщик Go может выполнять переключение контекста и запускать G2 на M1, который все еще работает на Core 1. Затем G2 обрабатывает сообщение и отправляет новое сообщение обратно в G1.
Cледующим шагом все снова переключается, когда сообщение, отправленное G2, принимается G1. Теперь контекст G2 переключается из состояния выполнения в состояние ожидания, а контекст G1 переключается из состояния ожидания в состояние выполнения и, наконец, обратно в состояние выполнения, что позволяет ему обрабатывать и отправлять новое сообщение обратно.
Вещи на поверхности, кажется, не отличаются. Все те же изменения контекста и изменения состояния происходят независимо от того, используете ли вы Потоки или Горутины. Однако существует большая разница между использованием Потоков и Горутин, которая может быть неочевидна на первый взгляд.
В случае использования горутин одни и те же потоки ОС и ядро используются для всей обработки. Это означает, что с точки зрения ОС Поток ОС никогда не переходит в состояние ожидания; ни разу. В результате все те инструкции, которые мы потеряли при переключении контекста, при использовании потоков, не теряются при использовании горутин.
По сути, Go превратил работу IO / Blocking в работу с привязкой к процессору на уровне ОС. Поскольку все переключение контекста происходит на уровне приложения, мы не теряем те же самые ~ 12 тыс. инструкций (в среднем) на переключение контекста, которые мы теряли при использовании потоков. В Go те же переключатели контекста стоят вам ~ 200 наносекунд или ~ 2,4 тыс. команд. Планировщик также помогает повысить эффективность строк кэширования и NUMA. Вот почему нам не нужно больше потоков, чем у нас есть виртуальные ядра. В Go можно со временем выполнять больше работы, потому что планировщик Go пытается использовать меньше потоков и делать больше на каждом потоке, что помогает снизить нагрузку на ОС и оборудование.
Вывод
Планировщик Go действительно удивителен тем, как он учитывает тонкости работы ОС и оборудования. Возможность превратить работу ввода-вывода / блокировки в работу с процессором с привязкой к процессору на уровне операционной системы — это то, где мы получаем большой выигрыш в использовании большей мощности процессора с течением времени. Вот почему вам не нужно больше потоков ОС, чем у вас есть виртуальные ядра. Вы можете разумно ожидать, что вся ваша работа будет выполнена (с привязкой к процессору и вводу-выводу / блокировкам) с одним потоком ОС на виртуальное ядро. Это возможно для сетевых приложений и других приложений, которым не нужны системные вызовы, блокирующие потоки ОС.
Как разработчик, вы все равно должны понимать, что делает ваше приложение с точки зрения типа работы. Вы не можете создавать неограниченное количество горутин и ожидать потрясающую производительность. Меньше — всегда больше, но с пониманием этой семантики Go-планировщика вы можете принимать лучшие инженерные решения.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
У P1 в LRQ закончились горутины, но есть готовые горутины в P2 LRQ и в GRQ. Откуда P1 возьмет горутины?
18.37%Из глобальной очереди GRQ72
81.63%Из локальной очереди P2 LRQ320
Проголосовали 392 пользователя. Воздержались 20 пользователей.

