
Недавно я читал книгу «Компьютерные системы: архитектура и программирование. Взгляд программиста». Там, в главе про систему ввода-вывода Unix, авторы упомянули о том, что в конце файла нет особого символа

Если вы читали о системе ввода-вывода Unix/Linux, или экспериментировали с ней, если писали программы на C, которые читают данные из файлов, то это заявление вам, вероятно, покажется совершенно очевидным. Но давайте поближе присмотримся к следующим двум утверждениям, относящимся к тому, что я нашёл в книге:
Что же такое
Почему кто-то говорит или думает, что
Это может выглядеть так:
Или так:
Если заглянуть в справку по
А что такое, вообще, символ? Символ — это самый маленький компонент текста. «A», «a», «B», «b» — всё это — разные символы. У символа есть числовой код, который в стандарте Unicode называют кодовой точкой. Например — латинская буква «A» имеет, в десятичном представлении, код 65. Это можно быстро проверить, воспользовавшись командной строкой интерпретатора Python:
Или можно взглянуть на таблицу ASCII в Unix/Linux:

Выясним, какой код соответствует
Скомпилируем и запустим программу:
У меня эта программа, проверенная на Mac OS и на Ubuntu, сообщает о том, что
Как и ожидалось, символа с кодом
Может,
Возьмём простой текстовый файл, helloworld.txt, и выведем его содержимое в шестнадцатеричном представлении. Для этого можно воспользоваться командой
Как видите, последний символ файла имеет код
Так.
Взглянем на то, как можно обнаруживать состояние
Вот репозиторий с кодом примеров. Приступим к их разбору.
Начнём с почтенного C. Представленная здесь программа является модифицированной версией
Компиляция:
Запуск:
Вот некоторые пояснения, касающиеся вышеприведённого кода:
В Python нет механизма явной проверки на
Запустим программу и взглянём на возвращаемые ей результаты:
Вот более короткая версия этого же примера, написанная на Python 3.8+. Здесь используется оператор := (его называют «оператор walrus» или «моржовый оператор»):
Запустим этот код:
В Go можно явным образом проверить ошибку, возвращённую Read(), на предмет того, не указывает ли она на то, что мы добрались до конца файла:
Запустим программу:
В среде Node.js нет механизма для явной проверки на
Запустим программу:
Как высокоуровневые механизмы ввода-вывода, использованные в вышеприведённых примерах, определяют достижение конца файла? В Linux эти механизмы прямо или косвенно используют системный вызов read(), предоставляемый ядром. Функция (или макрос)
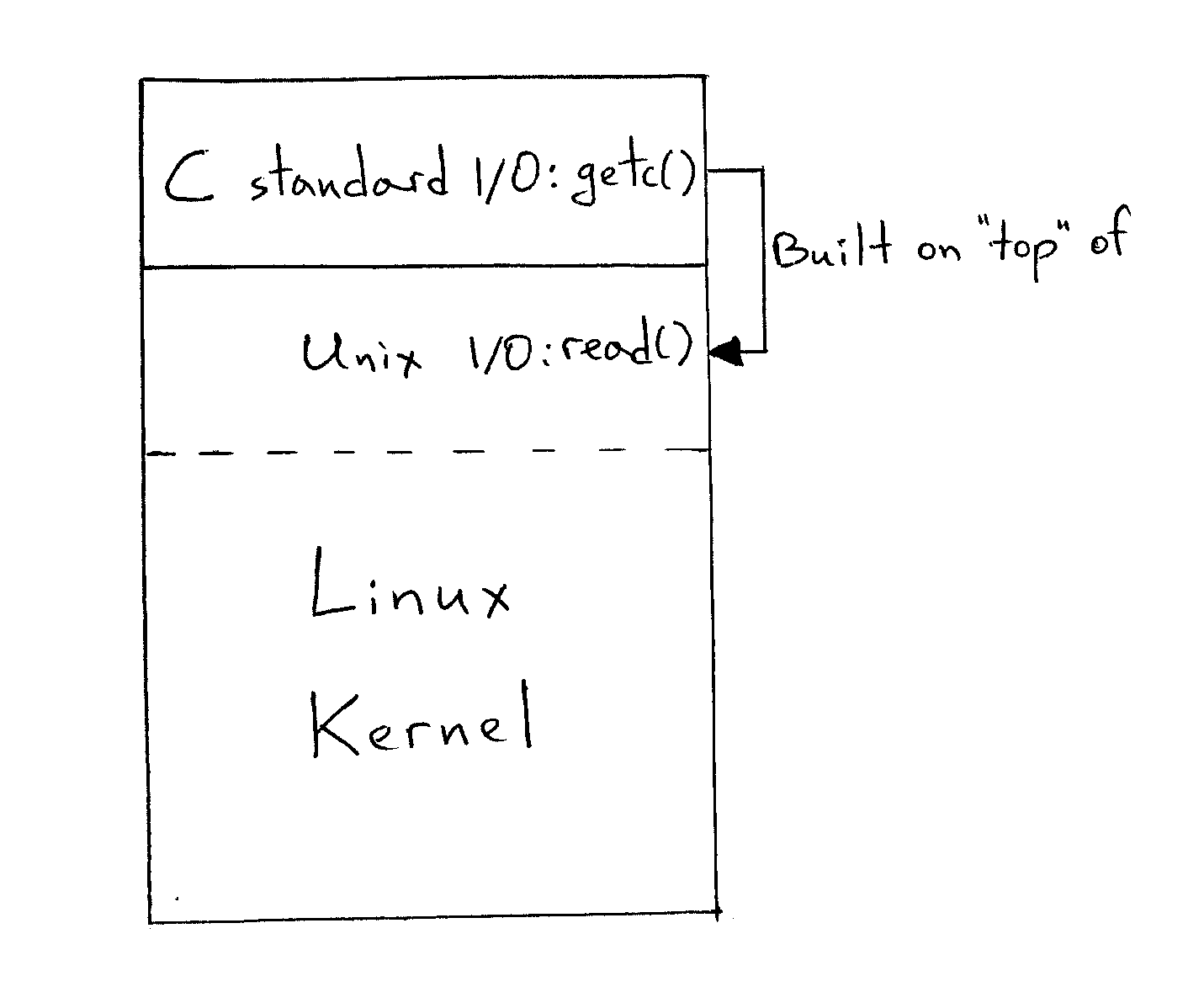
Получается, что функция
Напишем версию
Вот эта программа, написанная на C:
Запустим её:
В этом коде используется тот факт, что функция
Вот та же программа, написанная на Python 3:
Запустим её:
Вот — то же самое, написанное на Python 3.8+:
Запустим и этот код:
Уважаемые читатели! А вы знаете о каких-нибудь более или менее широко распространённых заблуждениях из мира компьютеров?

EOF.Если вы читали о системе ввода-вывода Unix/Linux, или экспериментировали с ней, если писали программы на C, которые читают данные из файлов, то это заявление вам, вероятно, покажется совершенно очевидным. Но давайте поближе присмотримся к следующим двум утверждениям, относящимся к тому, что я нашёл в книге:
EOF— это не символ.- В конце файлов нет некоего особого символа.
Что же такое
EOF?EOF — это не символ
Почему кто-то говорит или думает, что
EOF — это символ? Полагаю, это может быть так из-за того, что в некоторых программах, написанных на C, можно найти код, в котором используется явная проверка на EOF с использованием функций getchar() и getc().Это может выглядеть так:
#include <stdio.h> ... while ((c = getchar()) != EOF) putchar(c);
Или так:
FILE *fp; int c; ... while ((c = getc(fp)) != EOF) putc(c, stdout);
Если заглянуть в справку по
getchar() или getc(), можно узнать, что обе функции считывают следующий символ из потока ввода. Вероятно — именно это является причиной возникновения заблуждения о природе EOF. Но это — лишь мои предположения. Вернёмся к мысли о том, что EOF — это не символ.А что такое, вообще, символ? Символ — это самый маленький компонент текста. «A», «a», «B», «b» — всё это — разные символы. У символа есть числовой код, который в стандарте Unicode называют кодовой точкой. Например — латинская буква «A» имеет, в десятичном представлении, код 65. Это можно быстро проверить, воспользовавшись командной строкой интерпретатора Python:
$python >>> ord('A') 65 >>> chr(65) 'A'
Или можно взглянуть на таблицу ASCII в Unix/Linux:
$ man ascii
Выясним, какой код соответствует
EOF, написав небольшую программу на C. В ANSI C константа EOF определена в stdio.h, она является частью стандартной библиотеки. Обычно в эту константу записано -1. Можете сохранить следующий код в файле printeof.c, скомпилировать его и запустить:#include <stdio.h> int main(int argc, char *argv[]) { printf("EOF value on my system: %d\n", EOF); return 0; }
Скомпилируем и запустим программу:
$ gcc -o printeof printeof.c $ ./printeof EOF value on my system: -1
У меня эта программа, проверенная на Mac OS и на Ubuntu, сообщает о том, что
EOF равняется -1. Есть ли какой-нибудь символ с таким кодом? Тут, опять же, можно проверить коды символов в таблице ASCII, можно взглянуть на таблицу Unicode и узнать о том, в каком диапазоне могут находиться коды символов. Мы же поступим иначе: запустим интерпретатор Python и воспользуемся стандартной функцией chr() для того, чтобы она дала бы нам символ, соответствующий коду -1:$ python >>> chr(-1) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: chr() arg not in range(0x110000)
Как и ожидалось, символа с кодом
-1 не существует. Значит, в итоге, EOF, и правда, символом не является. Переходим теперь ко второму рассматриваемому утверждению.В конце файлов нет некоего особого символа
Может,
EOF — это особенный символ, который можно обнаружить в конце файла? Полагаю, сейчас вы уже знаете ответ. Но давайте тщательно проверим наше предположение.Возьмём простой текстовый файл, helloworld.txt, и выведем его содержимое в шестнадцатеричном представлении. Для этого можно воспользоваться командой
xxd:$ cat helloworld.txt Hello world! $ xxd helloworld.txt 00000000: 4865 6c6c 6f20 776f 726c 6421 0a Hello world!.
Как видите, последний символ файла имеет код
0a. Из таблицы ASCII можно узнать о том, что этот код соответствует символу nl, то есть — символу новой строки. Это можно выяснить и воспользовавшись Python:$ python >>> chr(0x0a) '\n'
Так.
EOF — это не символ, а в конце файлов нет некоего особого символа. Что же такое EOF?Что такое EOF?
EOF (end-of-file) — это состояние, которое может быть обнаружено приложением в ситуации, когда операция чтения файла доходит до его конца.Взглянем на то, как можно обнаруживать состояние
EOF в разных языках программирования при чтении текстового файла с использованием высокоуровневых средств ввода-вывода, предоставляемых этими языками. Для этого напишем очень простую версию cat, которая будет называться mcat. Она побайтно (посимвольно) читает ASCII-текст и в явном виде выполняет проверку на EOF. Программу напишем на следующих языках:- ANSI C
- Python 3
- Go
- JavaScript (Node.js)
Вот репозиторий с кодом примеров. Приступим к их разбору.
ANSI C
Начнём с почтенного C. Представленная здесь программа является модифицированной версией
cat из книги «Язык программирования C»./* mcat.c */ #include <stdio.h> int main(int argc, char *argv[]) { FILE *fp; int c; if ((fp = fopen(*++argv, "r")) == NULL) { printf("mcat: can't open %s\n", *argv); return 1; } while ((c = getc(fp)) != EOF) putc(c, stdout); fclose(fp); return 0; }
Компиляция:
$ gcc -o mcat mcat.c
Запуск:
$ ./mcat helloworld.txt Hello world!
Вот некоторые пояснения, касающиеся вышеприведённого кода:
- Программа открывает файл, переданный ей в виде аргумента командной строки.
- В цикле
whileосуществляется копирование данных из файла в стандартный поток вывода. Данные копируются побайтово, происходит это до тех пор, пока не будет достигнут конец файла. - Когда программа доходит до
EOF, она закрывает файл и завершает работу.
Python 3
В Python нет механизма явной проверки на
EOF, похожего на тот, который имеется в ANSI C. Но если посимвольно читать файл, то можно выявить состояние EOF в том случае, если в переменной, хранящей очередной прочитанный символ, будет пусто:# mcat.py import sys with open(sys.argv[1]) as fin: while True: c = fin.read(1) # читаем максимум 1 символ if c == '': # EOF break print(c, end='')
Запустим программу и взглянём на возвращаемые ей результаты:
$ python mcat.py helloworld.txt Hello world!
Вот более короткая версия этого же примера, написанная на Python 3.8+. Здесь используется оператор := (его называют «оператор walrus» или «моржовый оператор»):
# mcat38.py import sys with open(sys.argv[1]) as fin: while (c := fin.read(1)) != '': # читаем максимум 1 символ до достижения EOF print(c, end='')
Запустим этот код:
$ python3.8 mcat38.py helloworld.txt Hello world!
Go
В Go можно явным образом проверить ошибку, возвращённую Read(), на предмет того, не указывает ли она на то, что мы добрались до конца файла:
// mcat.go package main import ( "fmt" "os" "io" ) func main() { file, err := os.Open(os.Args[1]) if err != nil { fmt.Fprintf(os.Stderr, "mcat: %v\n", err) os.Exit(1) } buffer := make([]byte, 1) // 1-byte buffer for { bytesread, err := file.Read(buffer) if err == io.EOF { break } fmt.Print(string(buffer[:bytesread])) } file.Close() }
Запустим программу:
$ go run mcat.go helloworld.txt Hello world!
JavaScript (Node.js)
В среде Node.js нет механизма для явной проверки на
EOF. Но, когда при достижении конца файла делается попытка ещё что-то прочитать, вызывается событие потока end./* mcat.js */ const fs = require('fs'); const process = require('process'); const fileName = process.argv[2]; var readable = fs.createReadStream(fileName, { encoding: 'utf8', fd: null, }); readable.on('readable', function() { var chunk; while ((chunk = readable.read(1)) !== null) { process.stdout.write(chunk); /* chunk is one byte */ } }); readable.on('end', () => { console.log('\nEOF: There will be no more data.'); });
Запустим программу:
$ node mcat.js helloworld.txt Hello world! EOF: There will be no more data.
Низкоуровневые системные механизмы
Как высокоуровневые механизмы ввода-вывода, использованные в вышеприведённых примерах, определяют достижение конца файла? В Linux эти механизмы прямо или косвенно используют системный вызов read(), предоставляемый ядром. Функция (или макрос)
getc() из C, например, использует системный вызов read() и возвращает EOF в том случае, если read() указывает на возникновение состояния достижения конца файла. В этом случае read() возвращает 0. Если изобразить всё это в виде схемы, то получится следующее:Получается, что функция
getc() основана на read().Напишем версию
cat, названную syscat, используя только системные вызовы Unix. Сделаем мы это не только из интереса, но и из-за того, что это вполне может принести нам какую-то пользу.Вот эта программа, написанная на C:
/* syscat.c */ #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> #include <unistd.h> int main(int argc, char *argv[]) { int fd; char c; fd = open(argv[1], O_RDONLY, 0); while (read(fd, &c, 1) != 0) write(STDOUT_FILENO, &c, 1); return 0; }
Запустим её:
$ gcc -o syscat syscat.c $ ./syscat helloworld.txt Hello world!
В этом коде используется тот факт, что функция
read(), указывая на достижение конца файла, возвращает 0.Вот та же программа, написанная на Python 3:
# syscat.py import sys import os fd = os.open(sys.argv[1], os.O_RDONLY) while True: c = os.read(fd, 1) if not c: # EOF break os.write(sys.stdout.fileno(), c)
Запустим её:
$ python syscat.py helloworld.txt Hello world!
Вот — то же самое, написанное на Python 3.8+:
# syscat38.py import sys import os fd = os.open(sys.argv[1], os.O_RDONLY) while c := os.read(fd, 1): os.write(sys.stdout.fileno(), c)
Запустим и этот код:
$ python3.8 syscat38.py helloworld.txt Hello world!
Итоги
EOF— это не символ.- В конце файлов нет некоего особого символа.
EOF— это состояние, о котором сообщает ядро, и которое может быть обнаружено приложением в том случае, когда операция чтения данных доходит до конца файла.- В ANSI C
EOF— это, опять же, не символ. Это — константа, определённая вstdio.h, в которую обычно записано значение -1. - «Символ»
EOFнельзя найти в таблице ASCII или в Unicode.
Уважаемые читатели! А вы знаете о каких-нибудь более или менее широко распространённых заблуждениях из мира компьютеров?
