Привет, Хабр!
Данные — это ценнейший актив компании. Об этом заявляет чуть ли не каждая компания с цифровым уклоном. С этим сложно спорить: без обсуждения подходов управления, хранения и обработки данных сейчас не проходит ни одна крупная IT-конференция.
Данные к нам поступают снаружи, также они формируются внутри компании, а если говорить о данных телеком-компании, то это для внутренних сотрудников кладезь информации о клиенте, его интересах, привычках, месторасположении. При грамотном профилировании и сегментации рекламные предложения выстреливают наиболее эффективно. Однако, на практике не все так радужно. Те данные, которые хранят компании, могут быть безнадежно устаревшими, избыточными, повторяющимися, либо об их существовании никому не известно, кроме узкого круга пользователей. ¯\_(ツ)_/¯

Одним словом, данными нужно эффективно управлять – только в таком случае они станут активом, приносящим бизнесу реальную пользу и прибыль. К сожалению, для решения вопросов управления данными нужно преодолеть довольно много сложностей. Обусловлены они в основном как историческим наследием в виде «зоопарков» систем, так и отсутствием единых процессов и подходов к управлению ими. Но что означает «управлять данными»?
Именно мы об это мы и поговорим под катом, а также о том, как нам помог opensource-стек.
Концепция стратегического управления данными Data Governance (DG) уже достаточно известна на российском рынке, и цели, достигаемые бизнесом в результате ее внедрения, понятны и четко декларированы. Наша компания не стала исключением и поставила перед собой задачу внедрения концепции управления данными.
Итак, с чего мы начали? Для начала мы сформировали для себя ключевые цели:
На сегодняшний день на рынке программного обеспечения представлено с десяток инструментов класса DataGovernance.
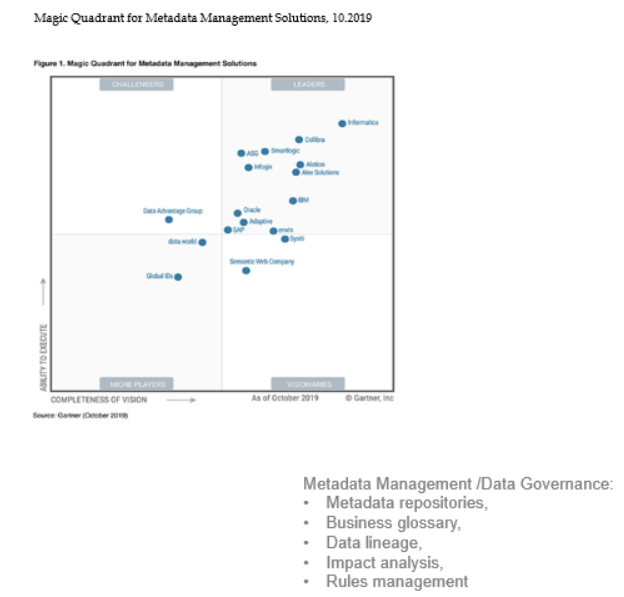
Но после детального анализа и изучения решений мы зафиксировали для себя ряд критичных замечаний:
Озвученные выше критерии и рекомендации в части импортозамещения софта для российских компаний убедили нас пойти в сторону собственной разработки на opensource-стеке. В качестве платформы выбрали Django – бесплатный и свободный фреймворк, написанный на Python. И таким образом мы выделили для себя ключевые модули, которые будут способствовать озвученным выше целям:

По результатам внутренних исследований в крупных компаниях, решая задачи, связанные с данными, сотрудники тратят 40—80% времени на их поиск. Поэтому мы поставили перед собой задачу сделать открытой информацию о существующих отчётах, которые ранее были доступны только заказчикам. Тем самым мы сокращаем время на формирование новой отчётности и обеспечиваем демократизацию данных.
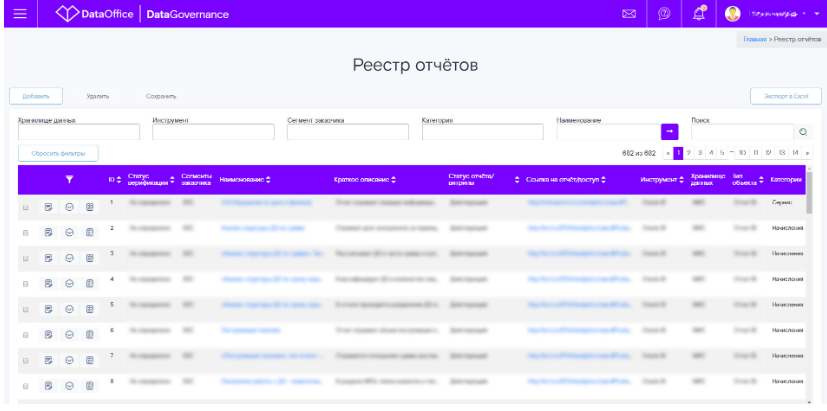
Реестр отчётов стал единым окном отчётности для внутренних пользователей из различных регионов, департаментов, подразделений. В нем консолидирована информация по инфосервисам, созданным в нескольких корпоративных хранилищах компании, а их в Ростелекоме немало.
Но реестр — это не просто сухой список разработанных отчётов. Для каждого отчёта мы предоставляем информацию, необходимую пользователю для самостоятельного знакомства с ним:
По отчётам доступна аналитика уровня используемости, и отчёты попадают в топ списка на основании аналитики логов по количеству уникальных пользователей. И это не все. Помимо общих характеристик мы предусмотрели и детальное описание атрибутного состава отчётов с примерами значений и методикой расчетов. Подобная детализация уже сразу дает пользователю ответ, полезен для него отчёт или нет.
Разработка этого модуля стала важным шагом в части демократизации данных и значительно сократила время поиска требуемой информации. Кроме сокращения времени поиска, снизилось и количество обращений к команде сопровождения на предоставление консультаций. Нельзя не отметить еще один полезный результат, которого мы добились, разработав единый реестр отчётов – предотвращение разработки дублирующих отчётов для разных структурных единиц.
Все вы знаете, что даже в рамках одной и той же компании бизнес говорит на разных языках. Да, используют одни и те же термины, но понимают под ними совсем разные вещи. Решить данную проблему призван бизнес-глоссарий.
Для нас бизнес-глоссарий — не просто справочник с описанием терминов и методологией расчета. Это полноценная среда разработки, согласования и утверждения терминологии, построения взаимосвязей терминов с другими информационными активами компании. Перед тем как попасть в бизнес-глоссарий, термин должен пройти все этапы согласования с бизнес-заказчиками и центром качества данных. Только после этого он становится доступным для использования.
Как я уже написал выше, уникальность данного инструмента в том, что он позволяет проводить связи от уровня бизнес-термина до конкретных пользовательских отчётов, в которых он используется, а также до уровня физических объектов баз данных.
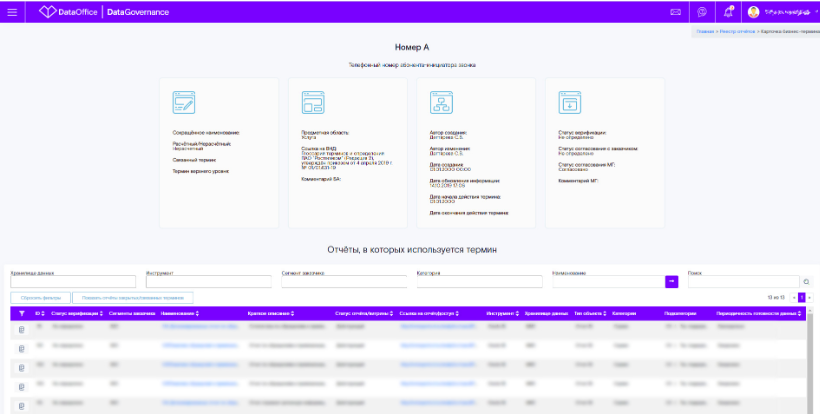
Это стало возможным посредством использования идентификаторов терминов глоссария в детальном описании отчётов из реестра и описании физических объектов баз данных.
Сейчас в Глоссарии определено и согласовано уже более 4000 терминов. Его использование упрощает и ускоряет обработку поступающих запросов на изменение в информационных системах компании. Если требуемый показатель уже реализован в каком-либо отчёте, то пользователь сразу увидит набор готовых отчётов, где этот показатель использован, и сможет принять решение об эффективном повторном использовании имеющейся функциональности или о её минимальной доработке, не инициируя новых запросов на разработку нового отчёта.
Вы спросите, что это за модули? Мало просто внедрить Реестр отчёта и Глоссарий, необходимо ещё приземлить все бизнес-термины на физическую модель баз данных. Тем самым мы смогли завершить процесс формирования жизненного цикла данных от систем источников до BI-визуализации через все слои хранилища данных. Иными словами — построить DataLineage.
Мы разработали интерфейс, в основе которого лежал используемый ранее в компании формат описания правил и логики трансформации данных. Посредством интерфейса заводится всё та же информация, что и раньше, но обязательным условием стало определение идентификатора термина из бизнес-глоссария. Так мы и выстраиваем связь между бизнес- и физическими слоями.
Кому это нужно? Чем не устроил старый формат, с которым работали несколько лет? Насколько увеличились трудозатраты на формирование требований? С такими вопросами нам приходилось сталкиваться в процессе внедрения инструмента. Здесь ответы достаточно просты – это нужно всем нам, дата-офису нашей компании и нашим пользователям.
Действительно, сотрудникам пришлось перестраиваться, поначалу это привело к незначительным увеличениям трудозатрат на подготовку документации, но с этим вопросом мы разобрались. Практика, выявление и оптимизация проблемных мест сделали свое дело. Мы добились главного — повысили качество разрабатываемых требований. Обязательные для заполнения поля, унифицированные справочники, маски ввода, встроенные проверки – всё это позволило в разы повысить качество описаний трансформаций. Мы ушли от практики передачи скриптов в виде требований на разработку, расшарили знания, которые были доступны только команде, занимающейся разработкой. Сформированная база метаданных сокращает в разы время на проведение регресс-анализа, обеспечивает возможность оперативной оценки влияния изменений на любом из слоев ИТ-ландшафта (отчёты витрины, агрегаты, источники).
А причём здесь обычные пользователи отчётов, какие плюсы для них? Благодаря возможности построения DataLineage наши пользователи, даже далекие от SQL и других языков программирования, оперативно получают информацию об источниках и объектах, на основе которых формируется тот или иной отчёт.
Всё, о чём мы говорили выше в части обеспечения прозрачности данных, не важно без понимания того, что данные, которые мы отдаём пользователям, — корректные. Один из важных модулей нашей концепции Data Governance — модуль контроля качества данных.
На текущем этапе это каталог проверок по выборочным сущностям. Ближайшая цель по развитию продукта – это расширение перечня проверок и интеграция с реестром отчётов.
Что это даст и кому? Для конечного пользователя реестра будет доступна информация о плановых и фактических датах готовности отчёта, результаты отработанных проверок с динамикой, сведения по загруженным в отчёт источникам.
Для нас интегрированный в рабочие процессы модуль качества данных это:
Безусловно, это первые шаги в выстраивании полноценного процесса управления данными. Но мы уверены, что, только целенаправленно занимаясь этой работой, активно внедряя инструменты DataGovernance в рабочий процесс, мы обеспечим нашим клиентам информативность, высокий уровень доверия к данным, прозрачность их получения и повысим скорость вывода новой функциональности.
Команда DataOffice
Данные — это ценнейший актив компании. Об этом заявляет чуть ли не каждая компания с цифровым уклоном. С этим сложно спорить: без обсуждения подходов управления, хранения и обработки данных сейчас не проходит ни одна крупная IT-конференция.
Данные к нам поступают снаружи, также они формируются внутри компании, а если говорить о данных телеком-компании, то это для внутренних сотрудников кладезь информации о клиенте, его интересах, привычках, месторасположении. При грамотном профилировании и сегментации рекламные предложения выстреливают наиболее эффективно. Однако, на практике не все так радужно. Те данные, которые хранят компании, могут быть безнадежно устаревшими, избыточными, повторяющимися, либо об их существовании никому не известно, кроме узкого круга пользователей. ¯\_(ツ)_/¯
Одним словом, данными нужно эффективно управлять – только в таком случае они станут активом, приносящим бизнесу реальную пользу и прибыль. К сожалению, для решения вопросов управления данными нужно преодолеть довольно много сложностей. Обусловлены они в основном как историческим наследием в виде «зоопарков» систем, так и отсутствием единых процессов и подходов к управлению ими. Но что означает «управлять данными»?
Именно мы об это мы и поговорим под катом, а также о том, как нам помог opensource-стек.
Концепция стратегического управления данными Data Governance (DG) уже достаточно известна на российском рынке, и цели, достигаемые бизнесом в результате ее внедрения, понятны и четко декларированы. Наша компания не стала исключением и поставила перед собой задачу внедрения концепции управления данными.
Итак, с чего мы начали? Для начала мы сформировали для себя ключевые цели:
- Обеспечить доступность наших данных.
- Обеспечить прозрачность жизненного цикла данных.
- Дать пользователям компании согласованные непротиворечивые данные.
- Дать пользователям компании проверенные данные.
На сегодняшний день на рынке программного обеспечения представлено с десяток инструментов класса DataGovernance.
Но после детального анализа и изучения решений мы зафиксировали для себя ряд критичных замечаний:
- Большинство производителей предлагают комплексный набор решений, который для нас является избыточным и дублирует уже существующую функциональность. Плюс дорогая с точки зрения ресурсов интеграция в текущий ИТ-ландшафт.
- Функциональность и интерфейс предназначены для технологов, а не конечных бизнес-пользователей.
- Низкая приживаемость продуктов и отсутствие успешных внедрений на российском рынке.
- Высокая стоимость программного обеспечения и дальнейшего сопровождения.
Озвученные выше критерии и рекомендации в части импортозамещения софта для российских компаний убедили нас пойти в сторону собственной разработки на opensource-стеке. В качестве платформы выбрали Django – бесплатный и свободный фреймворк, написанный на Python. И таким образом мы выделили для себя ключевые модули, которые будут способствовать озвученным выше целям:
- Реестр отчётов.
- Бизнес-глоссарий.
- Модуль описания технических трансформаций.
- Модуль описания жизненного цикла данных от источника до BI-инструмента.
- Модуль контроля качества данных.
Реестр отчётов
По результатам внутренних исследований в крупных компаниях, решая задачи, связанные с данными, сотрудники тратят 40—80% времени на их поиск. Поэтому мы поставили перед собой задачу сделать открытой информацию о существующих отчётах, которые ранее были доступны только заказчикам. Тем самым мы сокращаем время на формирование новой отчётности и обеспечиваем демократизацию данных.
Реестр отчётов стал единым окном отчётности для внутренних пользователей из различных регионов, департаментов, подразделений. В нем консолидирована информация по инфосервисам, созданным в нескольких корпоративных хранилищах компании, а их в Ростелекоме немало.
Но реестр — это не просто сухой список разработанных отчётов. Для каждого отчёта мы предоставляем информацию, необходимую пользователю для самостоятельного знакомства с ним:
- краткое описание отчёта;
- глубина доступности данных;
- сегмент заказчика;
- инструмент визуализации;
- наименование корпоративного хранилища;
- бизнес-функциональные требования;
- ссылка на отчёт;
- ссылка на заявку на доступ;
- статус реализации.
По отчётам доступна аналитика уровня используемости, и отчёты попадают в топ списка на основании аналитики логов по количеству уникальных пользователей. И это не все. Помимо общих характеристик мы предусмотрели и детальное описание атрибутного состава отчётов с примерами значений и методикой расчетов. Подобная детализация уже сразу дает пользователю ответ, полезен для него отчёт или нет.
Разработка этого модуля стала важным шагом в части демократизации данных и значительно сократила время поиска требуемой информации. Кроме сокращения времени поиска, снизилось и количество обращений к команде сопровождения на предоставление консультаций. Нельзя не отметить еще один полезный результат, которого мы добились, разработав единый реестр отчётов – предотвращение разработки дублирующих отчётов для разных структурных единиц.
Бизнес-глоссарий
Все вы знаете, что даже в рамках одной и той же компании бизнес говорит на разных языках. Да, используют одни и те же термины, но понимают под ними совсем разные вещи. Решить данную проблему призван бизнес-глоссарий.
Для нас бизнес-глоссарий — не просто справочник с описанием терминов и методологией расчета. Это полноценная среда разработки, согласования и утверждения терминологии, построения взаимосвязей терминов с другими информационными активами компании. Перед тем как попасть в бизнес-глоссарий, термин должен пройти все этапы согласования с бизнес-заказчиками и центром качества данных. Только после этого он становится доступным для использования.
Как я уже написал выше, уникальность данного инструмента в том, что он позволяет проводить связи от уровня бизнес-термина до конкретных пользовательских отчётов, в которых он используется, а также до уровня физических объектов баз данных.
Это стало возможным посредством использования идентификаторов терминов глоссария в детальном описании отчётов из реестра и описании физических объектов баз данных.
Сейчас в Глоссарии определено и согласовано уже более 4000 терминов. Его использование упрощает и ускоряет обработку поступающих запросов на изменение в информационных системах компании. Если требуемый показатель уже реализован в каком-либо отчёте, то пользователь сразу увидит набор готовых отчётов, где этот показатель использован, и сможет принять решение об эффективном повторном использовании имеющейся функциональности или о её минимальной доработке, не инициируя новых запросов на разработку нового отчёта.
Модуль описания технических трансформаций и DataLineage
Вы спросите, что это за модули? Мало просто внедрить Реестр отчёта и Глоссарий, необходимо ещё приземлить все бизнес-термины на физическую модель баз данных. Тем самым мы смогли завершить процесс формирования жизненного цикла данных от систем источников до BI-визуализации через все слои хранилища данных. Иными словами — построить DataLineage.
Мы разработали интерфейс, в основе которого лежал используемый ранее в компании формат описания правил и логики трансформации данных. Посредством интерфейса заводится всё та же информация, что и раньше, но обязательным условием стало определение идентификатора термина из бизнес-глоссария. Так мы и выстраиваем связь между бизнес- и физическими слоями.
Кому это нужно? Чем не устроил старый формат, с которым работали несколько лет? Насколько увеличились трудозатраты на формирование требований? С такими вопросами нам приходилось сталкиваться в процессе внедрения инструмента. Здесь ответы достаточно просты – это нужно всем нам, дата-офису нашей компании и нашим пользователям.
Действительно, сотрудникам пришлось перестраиваться, поначалу это привело к незначительным увеличениям трудозатрат на подготовку документации, но с этим вопросом мы разобрались. Практика, выявление и оптимизация проблемных мест сделали свое дело. Мы добились главного — повысили качество разрабатываемых требований. Обязательные для заполнения поля, унифицированные справочники, маски ввода, встроенные проверки – всё это позволило в разы повысить качество описаний трансформаций. Мы ушли от практики передачи скриптов в виде требований на разработку, расшарили знания, которые были доступны только команде, занимающейся разработкой. Сформированная база метаданных сокращает в разы время на проведение регресс-анализа, обеспечивает возможность оперативной оценки влияния изменений на любом из слоев ИТ-ландшафта (отчёты витрины, агрегаты, источники).
А причём здесь обычные пользователи отчётов, какие плюсы для них? Благодаря возможности построения DataLineage наши пользователи, даже далекие от SQL и других языков программирования, оперативно получают информацию об источниках и объектах, на основе которых формируется тот или иной отчёт.
Модуль контроля качества данных
Всё, о чём мы говорили выше в части обеспечения прозрачности данных, не важно без понимания того, что данные, которые мы отдаём пользователям, — корректные. Один из важных модулей нашей концепции Data Governance — модуль контроля качества данных.
На текущем этапе это каталог проверок по выборочным сущностям. Ближайшая цель по развитию продукта – это расширение перечня проверок и интеграция с реестром отчётов.
Что это даст и кому? Для конечного пользователя реестра будет доступна информация о плановых и фактических датах готовности отчёта, результаты отработанных проверок с динамикой, сведения по загруженным в отчёт источникам.
Для нас интегрированный в рабочие процессы модуль качества данных это:
- Оперативное формирования ожидания заказчиков.
- Принятие решений по дальнейшему использованию данных.
- Получение предварительного набора проблемных точек на начальных этапах работ для разработки регулярных контролей качества.
Безусловно, это первые шаги в выстраивании полноценного процесса управления данными. Но мы уверены, что, только целенаправленно занимаясь этой работой, активно внедряя инструменты DataGovernance в рабочий процесс, мы обеспечим нашим клиентам информативность, высокий уровень доверия к данным, прозрачность их получения и повысим скорость вывода новой функциональности.
Команда DataOffice

