В одном из проектов возникла необходимость перевести процессы импорта данных сторонних систем на микросервисную архитектуру. В качестве инструмента выбран Apache NiFi. В качестве первого подопытного выбран импорт ЕГРЮЛ ФНС.
Данные ЕГРЮЛ публикуются в виде XML-файлов, упакованных в ZIP-архивы. Архивы ежедневно выкладывают на ресурс https://ftp.egrul.nalog.ru/ в отдельный каталог для соответствующей даты. Для доступа выдается ключ #PKCS12.
Задача, которую необходимо решить с помощью NiFi — загрузка файлов с ресурса ФНС и подготовка загруженных данных для импорта в наши сервисы. В данной статье описан способ реализации загрузки файлов.
Источник данных
Получение данных из ЕГРЮЛ осуществляется в рамках услуги ФНС «Интеграция и доступ к базам данных ЕГРЮЛ и ЕГРИП». Описание модели взаимодействия представлено здесь.
Так выглядит ресурс ФНС, с которого требуется загрузить файлы.

Каталоги с суффиксом FULL — это выгрузки полного ЕГРЮЛ на начало соответствующего года. Остальные каталоги — это ежедневные обновления в ЕГРЮЛ. Нас интересует загрузка ежедневных обновлений.
Настройка потока в Apache NiFi
Задача потока — собрать список файлов каталога с вчерашней выгрузкой, получить эти файлы и разархивировать их.
Используя процессоры NiFi это можно выполнить цепочкой следующих операций:
- Создать FlowFile, который содержит ссылку на требуемый каталог
- Получить содержимого каталога в виде HTML
- Извлечь из полученного HTML ссылки на файлы, опубликованные в каталоге
- Скачать файлы
- Распаковать файлы

Создание FlowFile
Для создания FlowFile используется процессор GenerateFlowFile.

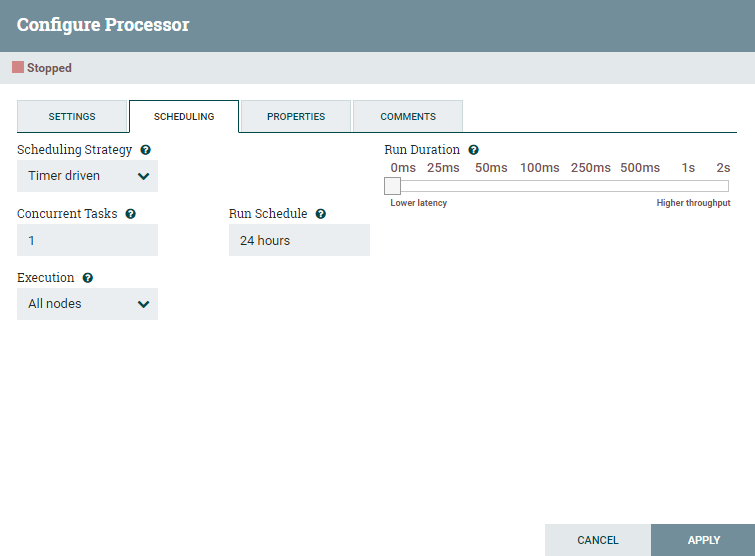
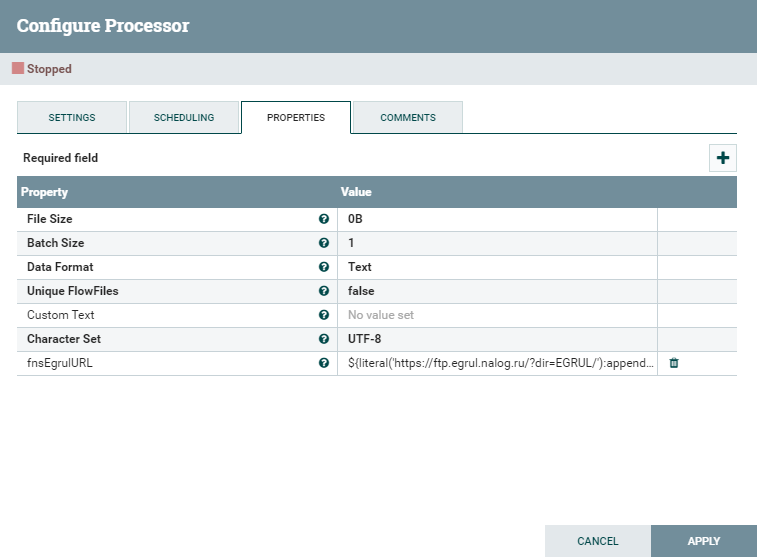
Он запускается каждые 24 часа и создает FlowFile с атрибутом fnsEgrulURL. В атрибут записывается ссылка на каталог с вчерашней выгрузкой вида https://ftp.egrul.nalog.ru/?dir=EGRUL/14.04.2020. Это выполняется с помощью выражения на NiFi Expression Language:
${literal('https://ftp.egrul.nalog.ru/?dir=EGRUL/'):append(${now():toNumber():minus(86400000):format('dd.MM.yyyy')})}
Т.е. берется текущая дата и преобразуется в числовое представление даты. Из него вычитается 86400000 миллисекунд. Результат преобразуется в строковое представление даты в формате dd.MM.yyyy. Полученная дата добавляется к постоянной части ссылки.
На выходе получаемFlowFile следующего вида:

Получение содержимого каталога
Для получения содержимого каталога используется процессор InvokeHTTP. Он выполняет GET-запрос по ссылке на каталог с вчерашней выгрузкой. В ответ процессор получает HTML-код каталога и добавляет этот HTML-код в FlowFile в качестве контента.

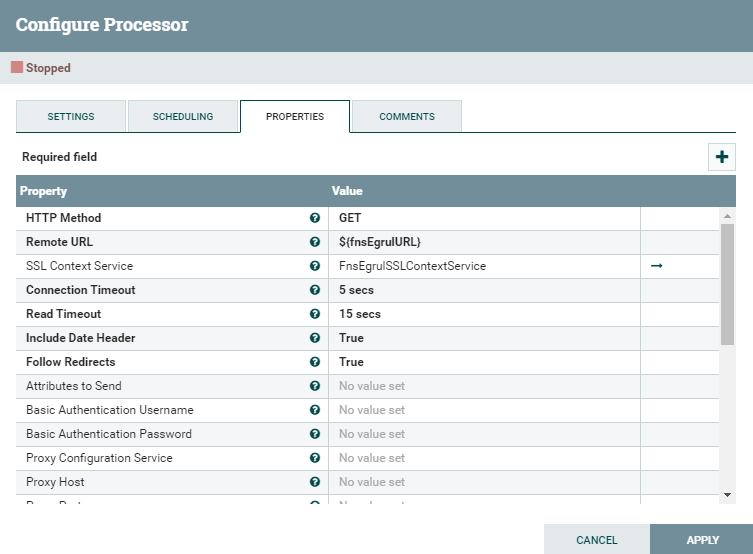
Процессор имеет следующие настройки:
HTTPMethod — указываем метод GET;
Remote URL — указываем, откуда брать URL для отправки запроса. ${fnsEgrulURL} — значение берется из FlowFile из атрибута fnsEgrulURL;
SSL Context Service — необходимо настроить контроллер SSLContextService для организации защищенного соединения, т.к. доступ к ресурсу ФНС осуществляется по HTTPS. Для доступа используется ключ #PKCS12 и доверенные сертификаты.
Процессор добавляет в FlowFile атрибуты, содержащие параметры запроса и ответа, и контент — полученный HTML-код каталога.
Контроллер SSLContextService

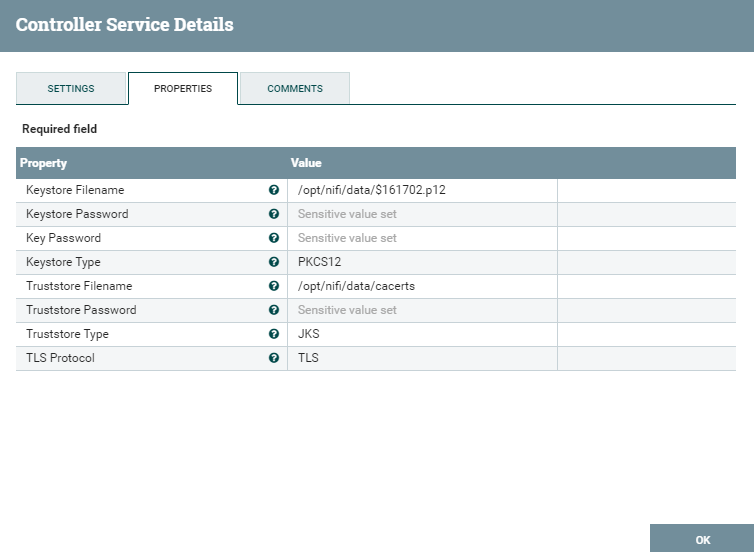
В настройках котроллера SSLContexService необходимо указать путь и пароль к файлу ключа #PKCS12 и путь и пароль к хранилищу доверенных сертификатов, в котором размещен промежуточный сертификат, используемый при взаимодействии с ресурсом ФНС.
В качестве хранилища доверенных сертификатов использовано хранилище cacerts из состава JDK. В него необходимо импортировать промежуточный сертификат. Для получения промежуточного сертификата необходимо открыть страницу https://fns.egrul.nalog.ru в браузере, использовав ключ #PKCS12. В адресной строке нажать иконку защищенного соединения и открыть сертификат.
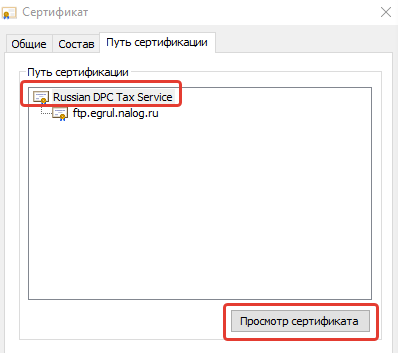
В цепочке сертификата необходимо выбрать сертификат Russian DPC Tax Service и экспортировать его в формате .CER в кодировке DER. Далее необходимо импортировать сертификат из полученного файла в хранилище cacerts c помощью утилиты keytool. Например, так:
C:\Program Files\Java\jdk1.8.0_121\bin> keytool -importcert -keystore "C:\Program Files\Java\jdk1.8.0_121\jre\lib\security\cacerts" -file {Путь к файлу .CER}
Пароль к cacerts по умолчанию — changeit.
Далее файл ключа и cacerts необходимо расположить там, где NiFi будет иметь к ним доступ. Например, в Persistent Volume. Соответствующие пути необходимо указать в параметрах контроллера SSLContextService. Там же для ключа необходимо указать тип PKSC12, а для cacerts — тип JKS.
Получение ссылок на файлы архивов
Получение ссылок на файлы архивов выполняется процессором GetHTMLElement, который извлекает содержимое требуемого HTML-элемента из контента FlowFile-а. В данном случае нам требуется получить ссылки на ZIP-архивы.
<div id="page-content" class="container"> <div id="directory-list-header"> <div class="row"> <div class="col-md-7 col-sm-6 col-xs-10">Файл</div> <div class="col-md-2 col-sm-2 col-xs-2 text-right">Размер</div> <div class="col-md-3 col-sm-4 hidden-xs text-right">Последнее изменение</div> </div> </div> <ul id="directory-listing" class="nav nav-pills nav-stacked"> <li data-name=".." data-href="https://ftp.egrul.nalog.ru/?dir=EGRUL"> <a href="https://ftp.egrul.nalog.ru/?dir=EGRUL" class="clearfix" data-name=".."> <div class="row"> <span class="file-name col-md-7 col-sm-6 col-xs-9"> <i class="fa fa-level-up fa-fw"></i> .. </span> <span class="file-size col-md-2 col-sm-2 col-xs-3 text-right"> - </span> <span class="file-modified col-md-3 col-sm-4 hidden-xs text-right"> 2020-04-05 22:00:00 </span> </div> </a> </li> <li data-name="EGRUL_2020-04-05_1.zip" data-href="EGRUL/05.04.2020/EGRUL_2020-04-05_1.zip"> <a href="EGRUL/05.04.2020/EGRUL_2020-04-05_1.zip" class="clearfix" data-name="EGRUL_2020-04-05_1.zip"> <div class="row"> <span class="file-name col-md-7 col-sm-6 col-xs-9"> <i class="fa fa-file-archive-o fa-fw"></i> EGRUL_2020-04-05_1.zip </span> <span class="file-size col-md-2 col-sm-2 col-xs-3 text-right"> 528.78KB </span> <span class="file-modified col-md-3 col-sm-4 hidden-xs text-right"> 2020-04-05 22:00:24 </span> </div> </a> <a href="javascript:void(0)" class="file-info-button"> <i class="fa fa-info-circle"></i> </a> </li> </ul> </div>
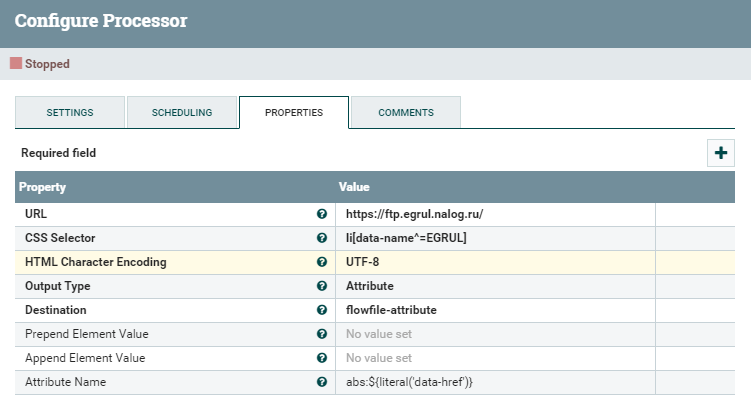
Параметры процессора:
URL — базовый URL обрабатываемой HTML-страницы;
CSS Selector — селектор для выбора интересующего нас элемента. li[data-name^=EGRUL] — элемент li, который содержит атрибут data-name, значение которого начинается с EGRUL;
Output Type — Attribute — данные будут извлечены из атрибута HTML-элемента;
Destination — flowfile-attribute — результат будет помещен в атрибут FlowFile-а (атрибут всегда называется HTMLElement);
Attribute Name — данный параметр описывает, какое значение должно быть получено в результате. abs:${literal('data-href')} — базовый URL (abs:) + значение атрибута data-href для элемента, найденного CSS-селектором.
Для каждого элемента, найденного CSS-селектором будет создан отдельный FlowFile с ссылкой на ZIP-архив в атрибуте HTMLElement.
Получение архивов
Для скачивания архивов используется процессор InvokeHTTP аналогичный тому, что используется для получения HTML-кода каталога. Запрашиваемый URL берется из атрибута HTMLElement, в котором передается ссылка на ZIP-архив. SSLContextService используется тот же самый.

Процессор скачивает ZIP-архив и помещает его в FlowFile в качестве контента.
Распаковка архивов
Для распаковки архивов используется процессор UnpackContent. В параметрах процессора достаточно выбрать только тип архива — ZIP.
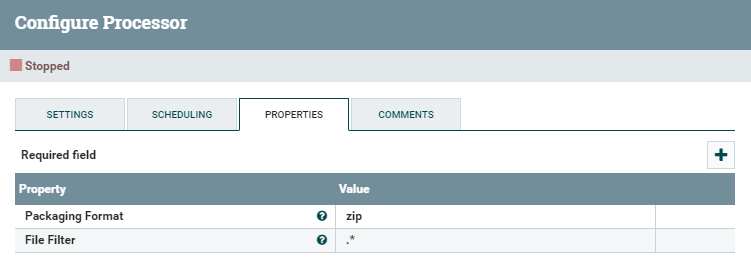
На выходе процессор создает FlowFile для каждого XML-файла, распакованного из ZIP-архива.
Далее...
Далее каждый XML требуется преобразовать в JSON. А из JSON уже в дальнейшем можно будет загрузить данные в SQL или NoSQL хранилище.
О преобразовании XML в JSON и о AVROSchema — в следующей статье.

