Звонки через интернет стали неотъемлемой частью жизни миллионов людей – так они упрощают свой рабочий процесс и связываются со своими близкими. Для передачи звонка по интернету данные звонков разбиваются на небольшие куски под названием «пакеты». Пакеты идут по сети от отправителя к получателю, где собираются обратно для получения непрерывного видео- и аудиопотока. Однако часто пакеты приходят к получателю не в том порядке и не в то время – это обычно называют джиттером (дрожанием) – или вовсе теряются. Такие проблемы понижают качество звонков, поскольку получателю приходится пытаться заполнить промежутки, причем это серьёзно влияет как на аудио, так и на видео. К примеру, 99% звонков через Google Duo сталкиваются с потерями пакетов, чрезмерным джиттером или задержками сети. Из них 20% звонков теряют более 3% данных по аудио из-за проблем с сетью, а 10% звонков теряют более 8% данных.

Упрощённая диаграмма сетевых проблем
Для того чтобы сделать общение в реальном времени надёжнее, приходится как-то разбираться с необходимыми, но не дошедшими до адресата пакетами. К примеру, если не выдавать непрерывный аудиосигнал, то будут слышны перерывы и заикания, однако нельзя назвать идеальным решением попытку повторять один и тот же сигнал снова и снова – это приведёт к появлению артефактов и уменьшит общее качество звонка. Технология обработки ситуации с отсутствием пакетов называется «сокрытием потери пакетов» (packet loss concealment, PLC). Модуль PLC получателя отвечает за создание аудио (или видео), заполняющего перерывы, возникшие из-за потерь пакетов, сильного джиттера или проблем сети – проблем, в любом случае приводящих к отсутствию необходимых данных.
Чтобы разобраться с этими проблемами с аудио, мы внедрили в Duo новую PLC-систему под названием WaveNetEQ. Это генеративная модель на основе технологии WaveRNN от компании DeepMind, обученная на крупном корпусе речевых данных реалистично дополнять речевые сегменты. Она способна полностью синтезировать звуковой сигнал отсутствующих фрагментов речи. Поскольку звонки в Duo подвергаются сквозному шифрованию, всю обработку приходится вести на самом устройстве. Модель WaveNetEQ работает достаточно быстро для телефона, и при этом обеспечивает отличное качество аудио и более естественно звучащую PLC по сравнению с другими имеющимися системами.
Как и многие другие программы связи на основе веба, Duo основан на проекте WebRTC с открытым кодом. Чтобы скрыть последствия потери пакетов, компонент системы NetEQ использует методы обработки сигнала, анализирующие речь и выдающие непрерывное её продолжение – это хорошо работает для небольших потерь (до 20 мс), однако начинает плохо звучать, когда потеря пакетов приводит к разрывам в связи в 60 мс или дольше. В таких случаях речь становится похожа на повторяющуюся речь робота – этот характерный звук, к сожалению, хорошо знаком многим любителям звонить через интернет.
Чтобы улучшить качество обработки потери пакетов, мы заменили NetEQ PLC на изменённый вариант WaveRNN. Это рекуррентная нейросеть, предназначенная для синтеза речи, состоящая из двух частей – авторегрессивной и кондиционной нейросетей. Авторегрессивная нейросеть отвечает за непрерывность сигнала и выдаёт краткосрочную и среднесрочную структуру речи. В процессе её работы каждый сгенерированный фрагмент зависит от предыдущих результатов работы сети. Кондиционная нейросеть влияет на авторегрессивную так, чтобы та выдавала аудиосигнал, соответствующий более медленным входящим данным.
Однако WaveRNN, как и её предшественницу WaveNet, создавали, нацеливаясь на преобразование текста в речь (text-to-speech, TTS). Поскольку WaveRNN — это TTS-модель, ей выдаётся информация о том, что нужно сказать и как именно. Кондиционная сеть напрямую получает эту информацию на вход в виде составляющих слова фонем и особенностей просодии (такой нетекстовой информации, как высота звуков или интонация). В каком-то смысле кондиционная сеть способна «заглядывать в будущее», а потом перенаправлять авторегрессивную сеть по направлению к соответствующим ему звукам. В случае с PLC-системой и общением в реальном времени такого контекста у нас не будет.
Для создания функциональной PLC-системы нужно как извлекать контекст из текущей речи (т.е., из прошлого), так и генерировать приемлемый звук для её продолжения. Наше решение, WaveNetEQ, делает одновременно и то и другое. Оно использует авторегрессивную сеть, продолжающую звучание речи в случае потери пакетов, и кондиционную нейросеть, моделирующую долговременные признаки, вроде характеристик голоса. На вход кондиционной нейросети подаётся спектрограмма предыдущего аудиосигнала, из которой извлекается ограниченный объём информации, описывающий просодию и текстовое содержание. Эта концентрированная информация скармливается в авторегрессивную нейросеть, комбинирующую её с недавним аудио для предсказания следующего звукового фрагмента.
Это немного отличается от процедуры, которой мы придерживались во время обучения WaveNetEQ. Тогда авторегрессивная нейросеть получала реальный образец звука в качестве входных данных для следующего шага, вместо того, чтобы использовать предыдущий образец. В таком процессе, известном, как обучение с навязыванием [teacher forcing] гарантируется, что модель обучится ценной информации даже на ранних стадиях обучения, когда её предсказания имеют низкое качество. Когда модель полностью обучена и используется в аудио- или видеозвонках, обучение с навязыванием используется только для «разогрева» модели на первом образце, а после этого она уже получает на вход собственный выход.

Архитектура WaveNetEQ. Во время работы авторегрессивной нейросети мы «разогреваем» её при помощи обучения с навязыванием. После этого она уже получает на вход собственный выход. Мел-частотная спектрограмма от длинных участков аудио используется в качестве входных данных для кондиционной нейросети.
Эту модель применяют к аудиоданным в буфере джиттера Duo. Когда после потери пакетов связь возобновляется и продолжает поступать реальный аудиосигнал, мы аккуратно объединяем синтетический и реальный аудиопотоки. Чтобы лучше всего составить эти два сигнала, модель генерирует чуть больше выходных данных, чем нужно, а потом производит плавный монтажный переход из одного в другой. Это делает переход гладким и практически бесшумным.
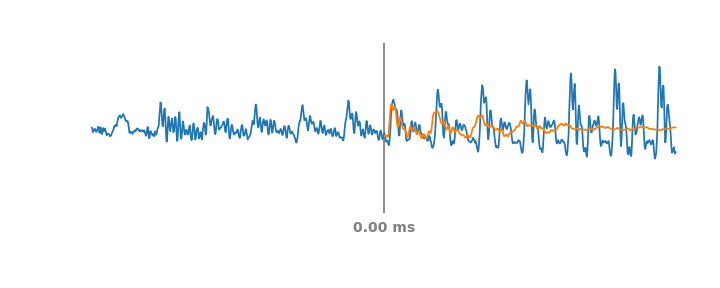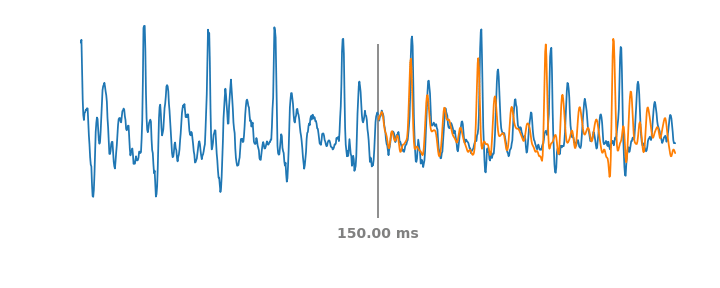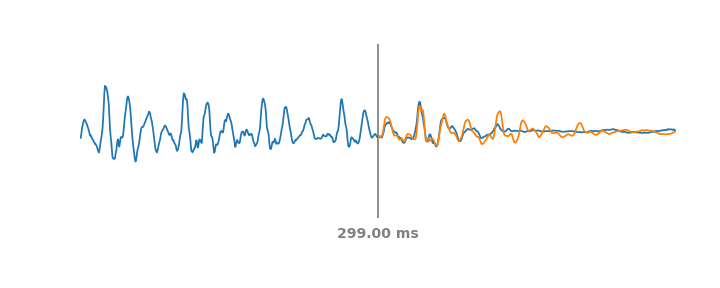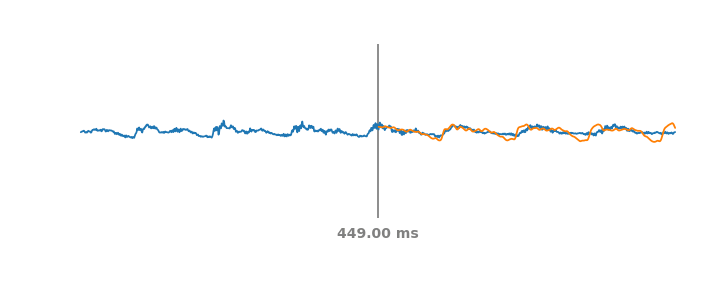
Симуляция PLC-событий в аудиопотоке на скользящем окне в 60 мс. Голубая линия – реальное аудио, включая прошлые и будущие части PLC. На каждом такте оранжевая линия представляет синтетическое аудио, которое предсказала бы система WaveNetEQ, если бы звук обрезался по вертикальной серой линии.
Потеря пакетов длительностью в 60 мс
[Прим. перев.: примеры аудио такие корявые на вид, поскольку в редакторе Хабра не предусмотрена возможность встраивания аудиофайлов. Так выглядят mp4 с одним аудио, без картинки.]
NetEQ
WaveNetEQ
NetEQ
WaveNetEQ
Потеря пакетов длительностью в 120 мс
NetEQ
WaveNetEQ
NetEQ
WaveNetEQ
Один из важных факторов, который стоит учитывать в PLC – это способность нейросети адаптироваться к переменным входящим сигналам, например, при наличии нескольких говорящих человек или при изменении фонового шума. Чтобы гарантировать надёжность модели для широкого спектра пользователей, мы обучили WaveNetEQ на наборе речевых данных, взятых у более чем 100 различных человек, говорящих на 48 разных языках. Это позволило модели обучиться общим характеристикам человеческой речи, а не особенностям конкретного языка. Чтобы обеспечить работу WaveNetEQ в случае наличия шума на фоне, когда вы, к примеру, отвечаете на звонок, будучи в поезде или в кафе, мы дополняем данные, смешивая их с фоновым шумом из обширной базы.
И хотя наша модель способна обучиться правдоподобно продолжать вашу речь, это работает только на небольших временных промежутках – она способна заканчивать слоги, но не может предсказывать слова. В случае с потерей пакетов на больших временных промежутках, мы постепенно уменьшаем громкость, и по прошествии 120 мс модель выдаёт только тишину. Также для обеспечения того, чтобы модель не выдавала ложных слогов, мы изучили образцы звуков от WaveNetEQ и NetEQ при помощи Google Cloud Speech-to-Text API и обнаружили, что модель практически не меняет процент ошибок в полученном тексте, то есть, количество ошибок, возникающих во время распознавания речи. Мы экспериментировали с WaveNetEQ в Duo, и её использование положительно сказалось на качестве звонков и пользовательском восприятии. WaveNetEQ уже работает во всех звонках Duo на телефонах Pixel 4, и сейчас мы разворачиваем её на других телефонах.
Упрощённая диаграмма сетевых проблем
Для того чтобы сделать общение в реальном времени надёжнее, приходится как-то разбираться с необходимыми, но не дошедшими до адресата пакетами. К примеру, если не выдавать непрерывный аудиосигнал, то будут слышны перерывы и заикания, однако нельзя назвать идеальным решением попытку повторять один и тот же сигнал снова и снова – это приведёт к появлению артефактов и уменьшит общее качество звонка. Технология обработки ситуации с отсутствием пакетов называется «сокрытием потери пакетов» (packet loss concealment, PLC). Модуль PLC получателя отвечает за создание аудио (или видео), заполняющего перерывы, возникшие из-за потерь пакетов, сильного джиттера или проблем сети – проблем, в любом случае приводящих к отсутствию необходимых данных.
Чтобы разобраться с этими проблемами с аудио, мы внедрили в Duo новую PLC-систему под названием WaveNetEQ. Это генеративная модель на основе технологии WaveRNN от компании DeepMind, обученная на крупном корпусе речевых данных реалистично дополнять речевые сегменты. Она способна полностью синтезировать звуковой сигнал отсутствующих фрагментов речи. Поскольку звонки в Duo подвергаются сквозному шифрованию, всю обработку приходится вести на самом устройстве. Модель WaveNetEQ работает достаточно быстро для телефона, и при этом обеспечивает отличное качество аудио и более естественно звучащую PLC по сравнению с другими имеющимися системами.
Новая PLC-система для Duo
Как и многие другие программы связи на основе веба, Duo основан на проекте WebRTC с открытым кодом. Чтобы скрыть последствия потери пакетов, компонент системы NetEQ использует методы обработки сигнала, анализирующие речь и выдающие непрерывное её продолжение – это хорошо работает для небольших потерь (до 20 мс), однако начинает плохо звучать, когда потеря пакетов приводит к разрывам в связи в 60 мс или дольше. В таких случаях речь становится похожа на повторяющуюся речь робота – этот характерный звук, к сожалению, хорошо знаком многим любителям звонить через интернет.
Чтобы улучшить качество обработки потери пакетов, мы заменили NetEQ PLC на изменённый вариант WaveRNN. Это рекуррентная нейросеть, предназначенная для синтеза речи, состоящая из двух частей – авторегрессивной и кондиционной нейросетей. Авторегрессивная нейросеть отвечает за непрерывность сигнала и выдаёт краткосрочную и среднесрочную структуру речи. В процессе её работы каждый сгенерированный фрагмент зависит от предыдущих результатов работы сети. Кондиционная нейросеть влияет на авторегрессивную так, чтобы та выдавала аудиосигнал, соответствующий более медленным входящим данным.
Однако WaveRNN, как и её предшественницу WaveNet, создавали, нацеливаясь на преобразование текста в речь (text-to-speech, TTS). Поскольку WaveRNN — это TTS-модель, ей выдаётся информация о том, что нужно сказать и как именно. Кондиционная сеть напрямую получает эту информацию на вход в виде составляющих слова фонем и особенностей просодии (такой нетекстовой информации, как высота звуков или интонация). В каком-то смысле кондиционная сеть способна «заглядывать в будущее», а потом перенаправлять авторегрессивную сеть по направлению к соответствующим ему звукам. В случае с PLC-системой и общением в реальном времени такого контекста у нас не будет.
Для создания функциональной PLC-системы нужно как извлекать контекст из текущей речи (т.е., из прошлого), так и генерировать приемлемый звук для её продолжения. Наше решение, WaveNetEQ, делает одновременно и то и другое. Оно использует авторегрессивную сеть, продолжающую звучание речи в случае потери пакетов, и кондиционную нейросеть, моделирующую долговременные признаки, вроде характеристик голоса. На вход кондиционной нейросети подаётся спектрограмма предыдущего аудиосигнала, из которой извлекается ограниченный объём информации, описывающий просодию и текстовое содержание. Эта концентрированная информация скармливается в авторегрессивную нейросеть, комбинирующую её с недавним аудио для предсказания следующего звукового фрагмента.
Это немного отличается от процедуры, которой мы придерживались во время обучения WaveNetEQ. Тогда авторегрессивная нейросеть получала реальный образец звука в качестве входных данных для следующего шага, вместо того, чтобы использовать предыдущий образец. В таком процессе, известном, как обучение с навязыванием [teacher forcing] гарантируется, что модель обучится ценной информации даже на ранних стадиях обучения, когда её предсказания имеют низкое качество. Когда модель полностью обучена и используется в аудио- или видеозвонках, обучение с навязыванием используется только для «разогрева» модели на первом образце, а после этого она уже получает на вход собственный выход.
Архитектура WaveNetEQ. Во время работы авторегрессивной нейросети мы «разогреваем» её при помощи обучения с навязыванием. После этого она уже получает на вход собственный выход. Мел-частотная спектрограмма от длинных участков аудио используется в качестве входных данных для кондиционной нейросети.
Эту модель применяют к аудиоданным в буфере джиттера Duo. Когда после потери пакетов связь возобновляется и продолжает поступать реальный аудиосигнал, мы аккуратно объединяем синтетический и реальный аудиопотоки. Чтобы лучше всего составить эти два сигнала, модель генерирует чуть больше выходных данных, чем нужно, а потом производит плавный монтажный переход из одного в другой. Это делает переход гладким и практически бесшумным.
Симуляция PLC-событий в аудиопотоке на скользящем окне в 60 мс. Голубая линия – реальное аудио, включая прошлые и будущие части PLC. На каждом такте оранжевая линия представляет синтетическое аудио, которое предсказала бы система WaveNetEQ, если бы звук обрезался по вертикальной серой линии.
Потеря пакетов длительностью в 60 мс
[Прим. перев.: примеры аудио такие корявые на вид, поскольку в редакторе Хабра не предусмотрена возможность встраивания аудиофайлов. Так выглядят mp4 с одним аудио, без картинки.]
NetEQ
WaveNetEQ
NetEQ
WaveNetEQ
Потеря пакетов длительностью в 120 мс
NetEQ
WaveNetEQ
NetEQ
WaveNetEQ
Гарантируем надёжность
Один из важных факторов, который стоит учитывать в PLC – это способность нейросети адаптироваться к переменным входящим сигналам, например, при наличии нескольких говорящих человек или при изменении фонового шума. Чтобы гарантировать надёжность модели для широкого спектра пользователей, мы обучили WaveNetEQ на наборе речевых данных, взятых у более чем 100 различных человек, говорящих на 48 разных языках. Это позволило модели обучиться общим характеристикам человеческой речи, а не особенностям конкретного языка. Чтобы обеспечить работу WaveNetEQ в случае наличия шума на фоне, когда вы, к примеру, отвечаете на звонок, будучи в поезде или в кафе, мы дополняем данные, смешивая их с фоновым шумом из обширной базы.
И хотя наша модель способна обучиться правдоподобно продолжать вашу речь, это работает только на небольших временных промежутках – она способна заканчивать слоги, но не может предсказывать слова. В случае с потерей пакетов на больших временных промежутках, мы постепенно уменьшаем громкость, и по прошествии 120 мс модель выдаёт только тишину. Также для обеспечения того, чтобы модель не выдавала ложных слогов, мы изучили образцы звуков от WaveNetEQ и NetEQ при помощи Google Cloud Speech-to-Text API и обнаружили, что модель практически не меняет процент ошибок в полученном тексте, то есть, количество ошибок, возникающих во время распознавания речи. Мы экспериментировали с WaveNetEQ в Duo, и её использование положительно сказалось на качестве звонков и пользовательском восприятии. WaveNetEQ уже работает во всех звонках Duo на телефонах Pixel 4, и сейчас мы разворачиваем её на других телефонах.

