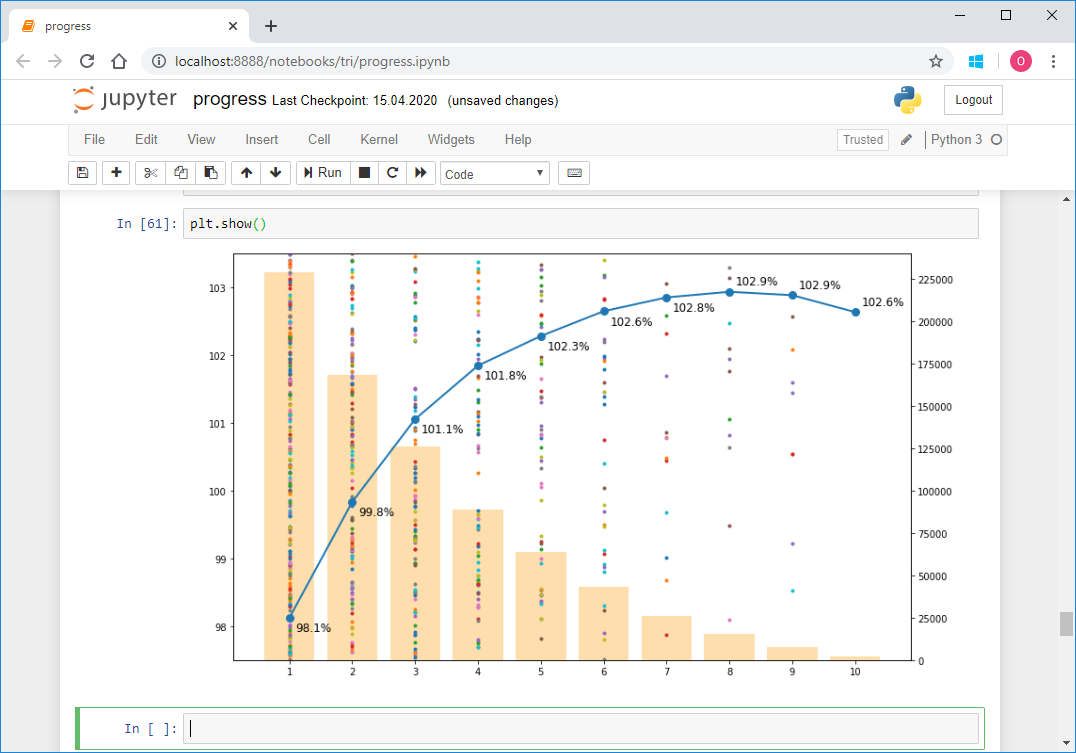
Последние пару лет в свободное время занимаюсь триатлоном. Этот вид спорта очень популярен во многих странах мира, в особенности в США, Австралии и Европе. В настоящее время набирает стремительную популярность в России и странах СНГ. Речь идет о вовлечении любителей, не профессионалов. В отличие от просто плавания в бассейне, катания на велосипеде и пробежек по утрам, триатлон подразумевает участие в соревнованиях и системной подготовке к ним, даже не будучи профессионалом. Наверняка среди ваших знакомых уже есть по крайней мере один “железный человек” или тот, кто планирует им стать. Массовость, разнообразие дистанций и условий, три вида спорта в одном – все это располагает к образованию большого количества данных. Каждый год в мире проходит несколько сотен соревнований по триатлону, в которых участвует несколько сотен тысяч желающих. Соревнования проводятся силами нескольких организаторов. Каждый из них, естественно, публикует результаты у себя. Но для спортсменов из России и некоторых стран СНГ, команда tristats.ru собирает все результаты в одном месте – на своем одноименном сайте. Это делает очень удобным поиск результатов, как своих, так и своих друзей и соперников, или даже своих кумиров. Но для меня это дало еще и возможность сделать анализ большого количества результатов программно. Результаты опубликованы на трилайфе: почитать. (К сожалению этот портал закрылся, поэтому выложил статью на Яндекс.Диск — посмотреть)
Это был мой первый проект подобного рода, потому как лишь недавно я начал заниматься анализом данных в принципе, а также использовать python. Поэтому хочу рассказать вам о техническом исполнении этой работы, тем более что в процессе то и дело всплывали различные нюансы, требующие иногда особого подхода. Здесь будет про скраппинг, парсинг, приведение типов и форматов, восстановление неполных данных, формирование репрезентативной выборки, визуализацию, векторизацию и даже параллельные вычисления.
Объем получился большой, поэтому я разбил все на пять частей, чтобы можно было дозировать информацию и запомнить, откуда начать после перерыва.
Перед тем как двинуться дальше, лучше сначала прочитать мою статью с результатами исследования, потому как здесь по сути описана кухня по ее созданию. Это займет 10-15 минут.
Прочитали? Тогда поехали!
Часть 1. Скраппинг и парсинг
Дано: Сайт tristats.ru. На нем два вида таблиц, которые нас интересуют. Это собственно сводная таблица всех гонок и протокол результатов каждой из них.


Задачей номер один было получить эти данные программно и сохранить их для дальнейшей обработки. Так получилось, что я был на тот момент плохо знаком с веб технологиями и поэтому не знал сразу как это сделать. Начал соответственно с того, что знал – посмотреть код страницы. Это можно сделать использую правую кнопку мыши или клавишу F12.
Меню в Chrome содержит два пункта Просмотр кода страницы и Посмотреть код. Не самое очевидное разделение. Естественно, они дают разные результаты. Тот, что Посмотреть код, как раз и есть то же самое, что и F12 — непосредственно текстовое html-представление того, что отображено в браузере, поэлементно.

В свою очередь Просмотр кода страницы выдает исходный код страницы. Тоже html, но никаких данных там нет, только названия скриптов JS, которые их выгружают. Ну ладно.
Теперь надо понять, как с помощью python сохранить код каждой страницы в виде отдельного текстового файла. Пробую так:
import requests r = requests.get(url='http://tristats.ru/') print(r.content)
И получаю… исходный код. Но мне то нужен результат его исполнения. Поизучав, поискав и поспрашивав, я понял, что мне нужен инструмент для автоматизации действий браузера, например — selenium. Его я и поставил. А также ChromeDriver для работы с Google Chrome. Далее использовал его следующим образом:
from selenium import webdriver from selenium.webdriver.chrome.service import Service service = Service(r'C:\ChromeDriver\chromedriver.exe') service.start() driver = webdriver.Remote(service.service_url) driver.get('http://www.tristats.ru/') print(driver.page_source) driver.quit()
Этот код запускает окно браузера и открывает в нем страницу по заданному url. В результате получаем html код уже с вожделенными данными. Но есть одна загвоздка. В полученном результате только 100 записей, а всего гонок почти 2000. Как же так? Дело в том, что изначально в браузере отображаются лишь первые 100 записей, и только если прокрутить до самого низа страницы, загружаются следующие 100, и так далее. Стало быть, надо реализовать прокрутку программно. Для этого воспользуемся командой:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
И при каждом прокручивании будем проверять, изменился ли код загруженной страницы или нет. Если он не изменился, для надежности проверим несколько раз, например 10, то значит страница загружена целиком и можно остановиться. Между прокрутками установим таймаут в одну секунду, чтобы страница успела загрузиться. (Даже если не успеет, у нас есть запас – еще девять секунд).
А полностью код будет выглядеть так:
from selenium import webdriver from selenium.webdriver.chrome.service import Service import time service = Service(r'C:\ChromeDriver\chromedriver.exe') service.start() driver = webdriver.Remote(service.service_url) driver.get('http://www.tristats.ru/') prev_html = '' scroll_attempt = 0 while scroll_attempt < 10: driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(1) if prev_html == driver.page_source: scroll_attempt += 1 else: prev_html = driver.page_source scroll_attempt = 0 with open(r'D:\tri\summary.txt', 'w') as f: f.write(prev_html) driver.quit()
Итак, у нас есть html файл со сводной таблицей всех гонок. Нужно его распарсить. Для этого используем библиотеку lxml.
from lxml import html
Сначала находим все строки таблицы. Чтобы определить признак строки, просто смотрим html файл в текстовом редакторе.
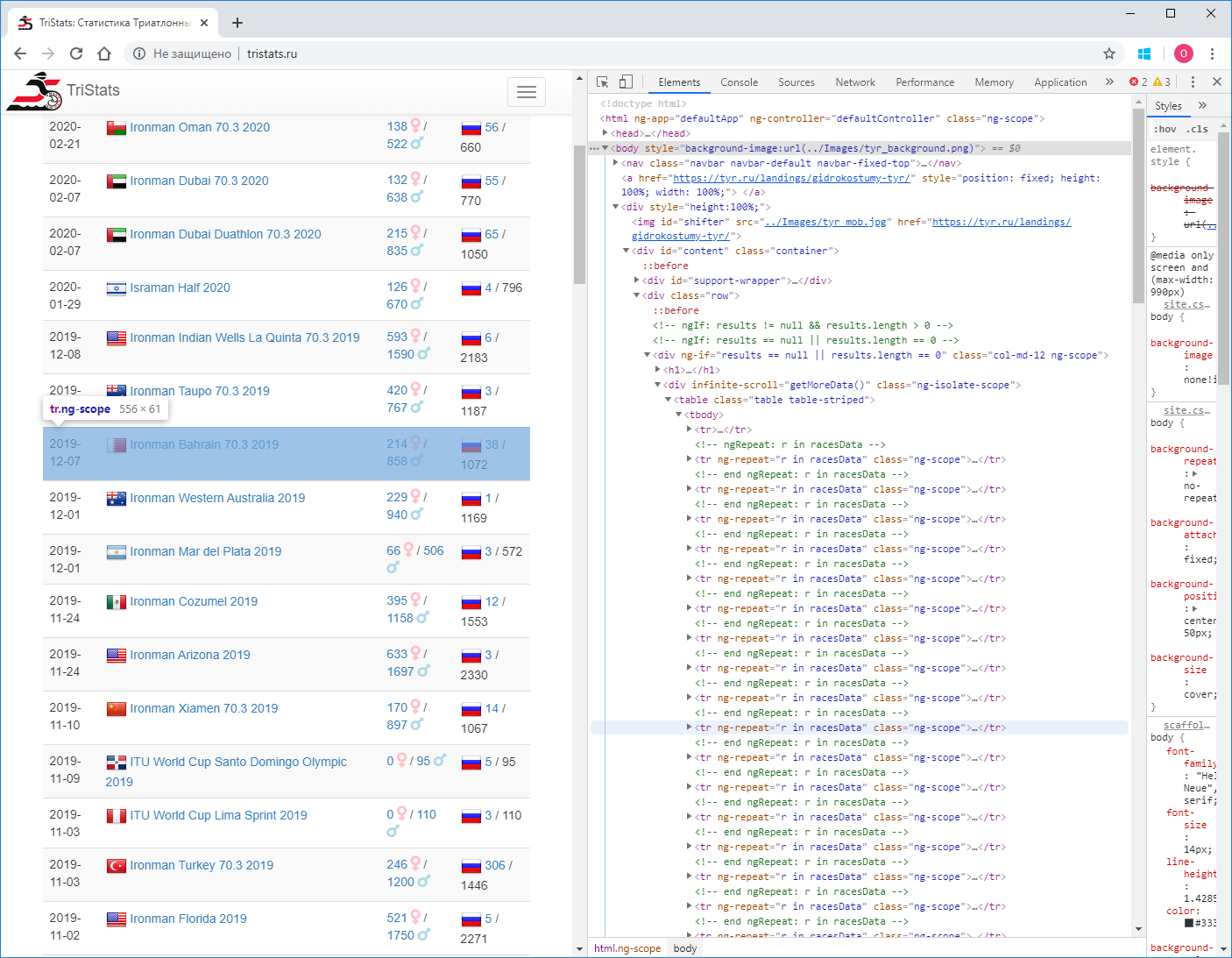
Это может быть, например, «tr ng-repeat=’r in racesData’ class=’ng-scope’» или какой – то фрагмент, который больше не встречается ни в каких тегах.
with open(r'D:\tri\summary.txt', 'r') as f: sum_html = f.read() tree = html.fromstring(sum_html) rows = tree.findall(".//*[@ng-repeat='r in racesData']")
затем заводим pandas dataframe и каждый элемент каждой строки таблица записываем в этот датафрейм.
import pandas as pd rs = pd.DataFrame(columns=['date','name','link','males','females','rus','total'], index=range(len(rows))) #rs – races summary
Для того, чтобы разобраться, где спрятан каждый конкретный элемент, нужно просто посмотреть на html код одного из элементов наших rows в том же текстовом редакторе.
<tr ng-repeat="r in racesData" class="ng-scope"> <td class="ng-binding">2015-04-26</td> <td> <img src="/Images/flags/24/USA.png" class="flag"> <a href="/rus/result/ironman/texas/half/2015" target="_self" class="ng-binding">Ironman Texas 70.3 2015</a> </td> <td> <a href="/rus/result/ironman/texas/half/2015?sex=F" target="_self" class="ng-binding">605</a> <i class="fas fa-venus fa-lg" style="color:Pink"></i> / <a href="/rus/result/ironman/texas/half/2015?sex=M" target="_self" class="ng-binding">1539</a> <i class="fas fa-mars fa-lg" style="color:LightBlue"></i> </td> <td class="ng-binding"> <img src="/Images/flags/24/rus.png" class="flag"> <!-- ngIf: r.CountryCount == 0 --> <!-- ngIf: r.CountryCount > 0 --><a ng-if="r.CountryCount > 0" href="/rus/result/ironman/texas/half/2015?country=rus" target="_self" class="ng-binding ng-scope">2</a> <!-- end ngIf: r.CountryCount > 0 --> / 2144 </td> </tr>
Здесь проще всего захардкодить навигацию по дочерним элементам, их не так много.
for i in range(len(rows)): rs.loc[i,'date'] = rows[i].getchildren()[0].text.strip() rs.loc[i,'name'] = rows[i].getchildren()[1].getchildren()[1].text.strip() rs.loc[i,'link'] = rows[i].getchildren()[1].getchildren()[1].attrib['href'].strip() rs.loc[i,'males'] = rows[i].getchildren()[2].getchildren()[2].text.strip() rs.loc[i,'females'] = rows[i].getchildren()[2].getchildren()[0].text.strip() rs.loc[i,'rus'] = rows[i].getchildren()[3].getchildren()[3].text.strip() rs.loc[i,'total'] = rows[i].getchildren()[3].text_content().split('/')[1].strip()
Вот что получилось в итоге:
date
event
link
males
females
rus
total
0
2020-07-02
Ironman Dubai Duathlon 70.3 2020
/rus/result/ironman/dubai-duathlon/half/2020
835
215
65
1050
1
2020-02-07
Ironman Dubai 70.3 2020
/rus/result/ironman/dubai/half/2020
638
132
55
770
2
2020-01-29
Israman Half 2020
/rus/result/israman/israman/half/2020
670
126
4
796
3
2019-12-08
Ironman Indian Wells La Quinta 70.3 2019
/rus/result/ironman/indian-wells-la-quinta/hal...
1590
593
6
2183
4
2019-12-07
Ironman Taupo 70.3 2019
/rus/result/ironman/taupo/half/2019
767
420
3
1187
...
...
...
...
...
...
...
...
1917
1994-07-02
ITU European Championship Eichstatt Olympic 1994
/rus/result/itu/european-championship-eichstat...
61
0
2
61
1918
1993-09-04
Challenge Almere-Amsterdam Long 1993
/rus/result/challenge/almere-amsterdam/full/1993
795
32
1
827
1919
1993-07-04
ITU European Cup Echternach Olympic 1993
/rus/result/itu/european-cup-echternach/olympi...
60
0
2
60
1920
1992-09-12
ITU World Championship Huntsville Olympic 1992
/rus/result/itu/world-championship-huntsville/...
317
0
3
317
1921
1990-09-15
ITU World Championship Orlando Olympic 1990
/rus/result/itu/world-championship-orlando/oly...
286
0
5
28
Сохраняем этот датафрейм в файл. Я использую pickle, но это может быть csv, или что-то еще.
import pickle as pkl with open(r'D:\tri\summary.pkl', 'wb') as f: pkl.dump(df,f)
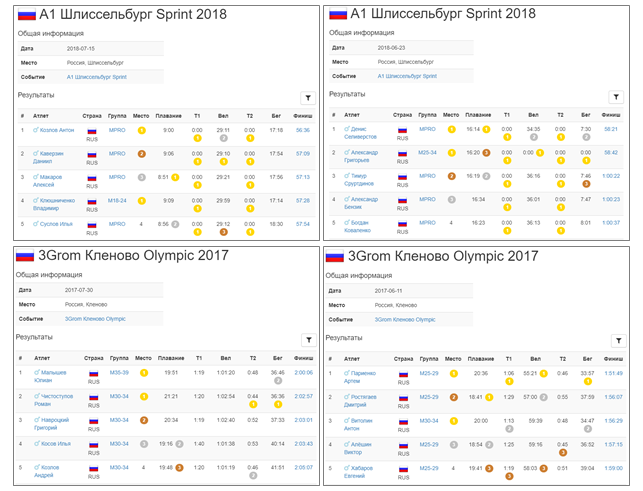
На данном этапе все данные имеют строковый тип. Конвертировать будем позже. Самое главное, что нам сейчас нужно, это ссылки. Их будем использовать для скраппинга протоколов всех гонок. Делаем его по образу и подобию того, как это было сделано для сводной таблицы. В цикле по всем гонкам для каждой будем открывать страницу по ссылке, прокручивать и получать код страницы. В сводной таблице у нас есть информация по общему количеству участников в гонке – total, будем ее использовать для того, чтобы понять до какого момента нужно продолжать скроллить. Для этого будем прямо в процессе скраппинга каждой страницы определять количество записей в таблице и сравнивать его с ожидаемым значением total. Как только оно будет равно, значит мы доскроллили до конца и можно переходить к следующей гонке. Так же поставим таймаут – 60 сек. Ели за это время мы не добираемся до total, переходим к следующей гонке. Код страницы будем сохранять в файл. Будем сохранять файлы всех гонок в одной папке, а называть их по имени гонок, то есть по значению в колонке event в сводной таблице. Чтобы не было конфликта имен, нужно чтобы все гонки имели разные названия в сводной таблице. Проверим это:
df[df.duplicated(subset = 'event', keep=False)]
date
event
link
males
females
rus
total
450
2018-07-15
A1 Шлиссельбург Sprint 2018
/rus/result/a1/шлиccельбург/sprint/2018-07-15
43
15
47
58
483
2018-06-23
A1 Шлиссельбург Sprint 2018
/rus/result/a1/шлиccельбург/sprint/2018-06-23
61
15
76
76
670
2017-07-30
3Grom Кленово Olympic 2017
/rus/result/3grom/кленово/olympic/2017-07-30
249
44
293
293
752
2017-06-11
3Grom Кленово Olympic 2017
/rus/result/3grom/кленово/olympic/2017-06-11
251
28
279
279
date
event
link
males
females
rus
total
450
2018-07-15
A1 Шлиссельбург Sprint 7 2018
/rus/result/a1/шлиccельбург/sprint/2018-07-15
43
15
47
58
483
2018-06-23
A1 Шлиссельбург Sprint 6 2018
/rus/result/a1/шлиccельбург/sprint/2018-06-23
61
15
76
76
670
2017-07-30
3Grom Кленово Olympic 7 2017
/rus/result/3grom/кленово/olympic/2017-07-30
249
44
293
293
752
2017-06-11
3Grom Кленово Olympic 6 2017
/rus/result/3grom/кленово/olympic/2017-06-11
251
28
279
27
service.start() driver = webdriver.Remote(service.service_url) timeout = 60 for index, row in df.iterrows(): try: driver.get('http://www.tristats.ru' + row['link']) start = time.time() while True: driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(1) race_html = driver.page_source tree = html.fromstring(race_html) race_rows = tree.findall(".//*[@ng-repeat='r in resultsData']") if len(race_rows) == int(row['total']): break if time.time() - start > timeout: print('timeout') break with open(os.path.join(r'D:\tri\races', row['event'] + '.txt'), 'w') as f: f.write(race_html) except: traceback.print_exc() time.sleep(1) driver.quit()
Это долгий процесс. Но когда все настроено и этот тяжелый механизм начинает вращение, один за другим добавляя файлики с данными, наступает чувство приятного волнения. В минуту загружается всего примерно по три протокола, очень медленно. Оставил крутиться на ночь. На все понадобилось около 10 часов. К утру была закачана бoльшая часть протоколов. Как это обычно бывает при работе с сетью, на нескольких случился сбой. Быстро докачал их повторной попыткой.
Итак, мы имеем 1 922 файла общим объемом почти 3 GB. Круто! Но обработка почти 300 гонок закончилась таймаутом. В чем же дело? Выборочно проверяем, оказывается, что действительно значение total из сводной таблицы и количество записей в протоколе гонки, которые мы проверяли, могут не совпадать. Это печально, потому что непонятно в чем причина такого расхождения. То ли это из-за того, что не все финишируют, то ли какой-то баг в базе. В общем первый сигнал о неидеальности данных. В любом случае, проверяем те, в которых количество записей равняется 100 или 0, это самые подозрительные кандидаты. Таких оказалось восемь. Закачиваем их заново под пристальным контролем. Кстати, в двух из них реально по 100 записей.
Ну что ж, все данные у нас. Переходим к парсингу. Опять же в цикле будем пробегать по каждой гонке, читать файл и сохранять содержимое в pandas DataFrame. Эти датафреймы объединим в dict, в котором ключами будут названия гонок – то есть значения event из сводной таблицы или названия файлов с html кодом страниц гонок, они совпадают.
rd = {} #rd – race details for e in rs['event']: place = [] ... sex = [], name=..., country, group, place_in_group, swim, t1, bike, t2, run result = [] with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r') race_html = f.read() tree = html.fromstring(race_html) rows = tree.findall(".//*[@ng-repeat='r in resultsData']") for j in range(len(rows)): row = rows[j] parts = row.text_content().split('\n') parts = [r.strip() for r in parts if r.strip() != ''] place.append(parts[0]) if len([a for a in row.findall('.//i')]) > 0: sex.append([a for a in row.findall('.//i')][0].attrib['ng-if'][10:-1]) else: sex.append('') name.append(parts[1]) if len(parts) > 10: country.append(parts[2].strip()) k=0 else: country.append('') k=1 group.append(parts[3-k]) ... place_in_group.append(...), swim.append ..., t1, bike, t2, run result.append(parts[10-k]) race = pd.DataFrame() race['place'] = place ... race['sex'] = sex, race['name'] = ..., 'country', 'group', 'place_in_group', 'swim', ' t1', 'bike', 't2', 'run' race['result'] = result rd[e] = race with open(r'D:\tri\details.pkl', 'wb') as f: pkl.dump(rd,f)
place
sex
name
country
group
place in group
swim
t1
bike
t2
run
result
0
1
M
Reed, Tim
AUS
MPRO
1
24:34
1:07
2:13:46
1:49
1:23:17
4:04:33
1
2
M
Van Berkel, Tim
AUS
MPRO
2
24:34
1:05
2:13:47
1:53
1:27:17
4:08:36
2
3
M
Baldwin, Nicholas
SEY
MPRO
3
26:31
0:59
2:14:06
1:54
1:25:36
4:09:06
3
4
M
Polizzi, Alexander
AUS
MPRO
4
23:21
1:12
2:14:53
1:54
1:31:16
4:12:36
4
5
M
Chang, Chia-Hao
TWN
M18-24
1
25:18
1:34
2:23:38
2:13
1:29:01
4:21:44
5
6
M
Rondy, Guillaume
FRA
M35-39
1
27:51
1:26
2:21:53
2:29
1:35:19
4:28:58
6
7
F
Steffen, Caroline
SUI
FPRO
1
26:52
1:01
2:24:54
2:10
1:34:17
4:29:14
7
8
M
Betten, Sam
AUS
MPRO
5
23:30
1:26
2:18:24
1:57
1:45:07
4:30:24
8
9
M
Gallot, Simon
FRA
M30-34
1
27:50
1:33
2:20:15
2:13
1:45:22
4:37:13
...
...
...
...
...
...
...
...
...
...
...
...
...
524
525
M
Santos, Alfredo
PHI
M65-69
2
50:42
4:23
3:52:10
10:32
3:36:11
8:33:58
525
526
F
Escober, Eula
PHI
F18-24
5
47:07
3:50
4:43:44
3:41
2:59:45
8:38:07
526
527
M
Belen, Virgilio Jr.
PHI
M45-49
76
47:05
5:49
3:48:18
11:21
3:46:06
8:38:39
527
528
M
Kunimoto, Kilhak
GUM
M70-74
2
40:32
2:50
3:53:37
6:45
4:01:36
8:45:20
528
529
M
Sumicad, Siegfred
PHI
M50-54
54
59:10
4:38
4:11:55
6:35
3:23:45
8:46:03
529
530
M
Gomez, Paul
PHI
M45-49
77
50:02
6:29
4:07:58
7:24
3:41:41
8:53:34
530
531
M
Ramos, John Raymund
PHI
M25-29
26
43:44
3:04
4:21:13
5:56
3:45:10
8:59:07
531
532
F
De Guzman, Clouie Anne
PHI
F30-34
9
52:29
3:16
4:03:02
7:01
3:56:39
9:02:27
532
533
F
Samson, Maria Dolores
PHI
F45-49
17
48:56
4:21
4:16:34
6:26
3:47:06
9:03:23
533
534
M
Salazar, Richard
PHI
M40-44
107
42:19
4:02
4:30:36
6:39
3:39:51
9:03:27
for index, row in rs.iterrows(): e = row['event'] with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r') as f: race_html = f.read() tree = html.fromstring(race_html) header_elem = [tb for tb in tree.findall('.//tbody') if tb.getchildren()[0].getchildren()[0].text == 'Дата'][0] location = header_elem.getchildren()[1].getchildren()[1].text.strip() rs.loc[index, 'loc'] = location
event
date
loc
male
female
rus
total
link
0
Ironman Dubai Duathlon 70.3 2020
2020-07-02
Dubai, United Arab Emirates
835
215
65
1050
...
1
Ironman Dubai 70.3 2020
2020-02-07
Dubai, United Arab Emirates
638
132
55
770
...
2
Israman Half 2020
2020-01-29
Israel, Eilat
670
126
4
796
...
3
Ironman Indian Wells La Quinta 70.3 2019
2019-12-08
Indian Wells/La Quinta, California, USA
1590
593
6
2183
...
4
Ironman Taupo 70.3 2019
2019-12-07
New Zealand
767
420
3
1187
...
5
Ironman Bahrain 70.3 2019
2019-12-07
Manama, Bahrain
858
214
38
1072
...
6
Ironman Western Australia 2019
2019-12-01
Busselton, Western Australia
940
229
1
1169
...
7
Ironman Mar del Plata 2019
2019-12-01
Mar del Plata, Argentina
506
66
3
572
...
8
Ironman Cozumel 2019
2019-11-24
Cozumel, Mexico
1158
395
12
1553
...
9
Ironman Arizona 2019
2019-11-24
Tempe, Arizona, USA
1697
633
3
2330
...
10
Ironman Xiamen 70.3 2019
2019-11-10
Xiamen, China
897
170
14
1067
...
with open(r'D:\tri\summary1.pkl', 'wb') as f: pkl.dump(df,f)
Часть 2. Приведение типов и форматирование
Итак, мы скачали все данные и поместили их в датафреймы. Однако все значения имеют тип str. Это относится и к дате, и к результатам, и к локации, и ко всем остальным параметрам. Необходимо привести все параметры к соответствующим типам.
Начнем со сводной таблицы.
event
date
loc
male
female
rus
total
link
0
Ironman Dubai Duathlon 70.3 2020
2020-07-02
Dubai, United Arab Emirates
835
215
65
1050
...
1
Ironman Dubai 70.3 2020
2020-02-07
Dubai, United Arab Emirates
638
132
55
770
...
2
Israman Half 2020
2020-01-29
Israel, Eilat
670
126
4
796
...
3
Ironman Indian Wells La Quinta 70.3 2019
2019-12-08
Indian Wells/La Quinta, California, USA
1590
593
6
2183
...
4
Ironman Taupo 70.3 2019
2019-12-07
New Zealand
767
420
3
1187
...
5
Ironman Bahrain 70.3 2019
2019-12-07
Manama, Bahrain
858
214
38
1072
...
6
Ironman Western Australia 2019
2019-12-01
Busselton, Western Australia
940
229
1
1169
...
7
Ironman Mar del Plata 2019
2019-12-01
Mar del Plata, Argentina
506
66
3
572
...
8
Ironman Cozumel 2019
2019-11-24
Cozumel, Mexico
1158
395
12
1553
...
9
Ironman Arizona 2019
2019-11-24
Tempe, Arizona, USA
1697
633
3
2330
...
10
Ironman Xiamen 70.3 2019
2019-11-10
Xiamen, China
897
170
14
1067
...
...
...
...
...
...
...
...
...
...
Дата и время
event, loc и link оставим как есть. date конвертируем в pandas datetime следующим образом:
rs['date'] = pd.to_datetime(rs['date'])
Остальные приводим к целочисленному типу:
cols = ['males', 'females', 'rus', 'total'] rs[cols] = rs[cols].astype(int)
Все прошло гладко, никаких ошибок не возникло. Значит все OK — cохраняемся:
with open(r'D:\tri\summary2.pkl', 'wb') as f: pkl.dump(rs, f)
Теперь датафреймы гонок. Поскольку все гонки удобнее и быстрее обрабатывать разом, а не по одной, соберем их в один большой датафрейм ar (сокращение от all records) с помощью метода concat.
ar = pd.concat(rd)
ar содержит 1 416 365 записей.
Теперь конвертируем place и place in group в целочисленное значение.
ar[['place', 'place in group']] = ar[['place', 'place in group']].astype(int))
Далее, обработаем колонки с временными значениями. Будем приводить их в типу Timedelta из pandas. Но чтобы конвертация прошла успешно, нужно правильно подготовить данные. Можно видеть, что некоторые значения, которые меньше часа идут без указания того самого часка.
place
sex
name
country
group
place in group
swim
t1
bike
t2
run
result
0
1
M
Dejan Patrcevic
CRO
M40-44
1
29:03
2:50
2:09:17
1:37
1:22:06
4:04:51
1
2
M
Lukas Krpec
CZE
M35-39
1
29:00
2:40
2:07:01
1:48
1:25:48
4:06:15
2
3
M
Marin Koceic
CRO
M40-44
2
27:34
2:09
2:12:13
1:30
1:27:19
4:10:44
for col in ['swim', 't1', 'bike', 't2', 'run', 'result']: strlen = ar[col].str.len() ar.loc[strlen==5, col] = '0:' + ar.loc[strlen==5, col] ar.loc[strlen==4, col] = '0:0' + ar.loc[strlen==4, col]
Теперь времена, все еще оставаясь строками, выглядят так:
place
sex
name
country
group
place in group
swim
t1
bike
t2
run
result
0
1
M
Dejan Patrcevic
CRO
M40-44
1
0:29:03
0:02:50
2:09:17
0:01:37
1:22:06
4:04:51
1
2
M
Lukas Krpec
CZE
M35-39
1
0:29:00
0:02:40
2:07:01
0:01:48
1:25:48
4:06:15
2
3
M
Marin Koceic
CRO
M40-44
2
0:27:34
0:02:09
2:12:13
0:01:30
1:27:19
4:10:44
for col in ['swim', 't1', 'bike', 't2', 'run', 'result']: ar[col] = pd.to_timedelta(ar[col])
Пол
Идем дальше. Проверим что в колонке sex есть только значения M и F:
ar['sex'].unique()
Out: ['M', 'F', '']
На самом деле там еще пустая строка, то есть пол не указан. Посмотрим сколько таких случаев:
len(ar[ar['sex'] == ''])
Out: 2538
Не так много — хорошо. В дальнейшем мы попытаемся еще уменьшить это значение. А пока оставим колонку sex как есть в виде строк. Сохраним результат, перед тем как перейти к более серьезным и рискованным преобразованиям. Для того, чтобы сохранять преемственность между файлами, преобразуем объединенный датафрейм ar обратно в словарь датафреймов rd:
for event in ar.index.get_level_values(0).unique(): rd[event] = ar.loc[event] with open(r'D:\tri\details1.pkl', 'wb') as f: pkl.dump(rd,f)
Кстати, за счет преобразования типов некоторых колонок размеры файлов уменьшились с 367 KB до 295 KB для сводной таблицы и с 251 MB до 168 MB для протоколов гонок.
Код страны
Теперь посмотрим страну.
ar['country'].unique()
Out: ['CRO', 'CZE', 'SLO', 'SRB', 'BUL', 'SVK', 'SWE', 'BIH', 'POL', 'MK', 'ROU', 'GRE', 'FRA', 'HUN', 'NOR', 'AUT', 'MNE', 'GBR', 'RUS', 'UAE', 'USA', 'GER', 'URU', 'CRC', 'ITA', 'DEN', 'TUR', 'SUI', 'MEX', 'BLR', 'EST', 'NED', 'AUS', 'BGI', 'BEL', 'ESP', 'POR', 'UKR', 'CAN', 'IRL', 'JPN', 'HKG', 'JEY', 'SGP', 'BRA', 'QAT', 'LUX', 'RSA', 'NZL', 'LAT', 'PHI', 'KSA', 'SEY', 'MAS', 'OMA', 'ARG', 'ECU', 'THA', 'JOR', 'BRN', 'CIV', 'FIN', 'IRN', 'BER', 'LBA', 'KUW', 'LTU', 'SRI', 'HON', 'INA', 'LBN', 'PAN', 'EGY', 'MLT', 'WAL', 'ISL', 'CYP', 'DOM', 'IND', 'VIE', 'MRI', 'AZE', 'MLD', 'LIE', 'VEN', 'ALG', 'SYR', 'MAR', 'KZK', 'PER', 'COL', 'IRQ', 'PAK', 'CZK', 'KAZ', 'CHN', 'NEP', 'ISR', 'MKD', 'FRO', 'BAN', 'ARU', 'CPV', 'ALB', 'BIZ', 'TPE', 'KGZ', 'BNN', 'CUB', 'SNG', 'VTN', 'THI', 'PRG', 'KOR', 'RE', 'TW', 'VN', 'MOL', 'FRE', 'AND', 'MDV', 'GUA', 'MON', 'ARM', 'F.I.TRI.', 'BAHREIN', 'SUECIA', 'REPUBLICA CHECA', 'BRASIL', 'CHI', 'MDA', 'TUN', 'NDL', 'Danish(Dane)', 'Welsh', 'Austrian', 'Unknown', 'AFG', 'Argentinean', 'Pitcairn', 'South African', 'Greenland', 'ESTADOS UNIDOS', 'LUXEMBURGO', 'SUDAFRICA', 'NUEVA ZELANDA', 'RUMANIA', 'PM', 'BAH', 'LTV', 'ESA', 'LAB', 'GIB', 'GUT', 'SAR', 'ita', 'aut', 'ger', 'esp', 'gbr', 'hun', 'den', 'usa', 'sui', 'slo', 'cze', 'svk', 'fra', 'fin', 'isr', 'irn', 'irl', 'bel', 'ned', 'sco', 'pol', 'SMR', 'mex', 'STEEL T BG', 'KINO MANA', 'IVB', 'TCH', 'SCO', 'KEN', 'BAS', 'ZIM', 'Joe', 'PUR', 'SWZ', 'Mark', 'WLS', 'MYA', 'BOT', 'REU', 'NAM', 'NCL', 'BOL', 'GGY', 'ISV', 'TWN', 'GUM', 'FIJ', 'COK', 'NGR', 'IRI', 'GAB', 'ANT', 'GEO', 'COG', 'sue', 'SUD', 'BAR', 'CAY', 'BO', 'VE', 'AX', 'MD', 'PAR', 'UM', 'SEN', 'NIG', 'RWA', 'YEM', 'PLE', 'GHA', 'ITU', 'UZB', 'MGL', 'MAC', 'DMA', 'TAH', 'TTO', 'AHO', 'JAM', 'SKN', 'GRN', 'PRK', 'NFK', 'SOL', 'Sandy', 'SAM', 'PNG', 'SGS', 'Suchy, Jorg', 'SOG', 'GEQ', 'BVT', 'DJI', 'CHA', 'ANG', 'YUG', 'IOT', 'HAI', 'SJM', 'CUW', 'BHU', 'ERI', 'FLK', 'HMD', 'GUF', 'ESH', 'sandy', 'UMI', 'selsmark, 'Alise', 'Eddie', '31/3, Colin', 'CC', 'Индия', 'Ирландия', 'Армения', 'Болгария', 'Сербия', 'Республика Беларусь', 'Великобритания', 'Франция', 'Гондурас', 'Коста-Рика', 'Азербайджан', 'GRL', 'UGA', 'VAT', 'ETH', 'ASA', 'PYF', 'ATA', 'ALA', 'MTQ', 'ZZ', 'CXR', 'AIA', 'TJK', 'GUY', 'KR', 'PF', 'BN', 'MO', 'LA', 'CAM', 'NCA', 'ZAM', 'MAD', 'TOG', 'VIR', 'ATF', 'VAN', 'SLE', 'GLP', 'SCG', 'LAO', 'IMN', 'BUR', 'IR', 'SY', 'CMR', 'GBS', 'SUR', 'MOZ', 'BLM', 'MSR', 'CAF', 'BEN', 'COD', 'CCK', 'TUV', 'TGA', 'GI', 'XKX', 'NRU', 'NC', 'LBR', 'TAN', 'VIN', 'SSD', 'GP', 'PS', 'IM', 'JE', '', 'MLI', 'FSM', 'LCA', 'GMB', 'MHL', 'NH', 'FL', 'CT', 'UT', 'AQ', 'Korea', 'Taiwan', 'NewCaledonia', 'Czech Republic', 'PLW', 'BRU', 'RUN', 'NIU', 'KIR', 'SOM', 'TKM', 'SPM', 'BDI', 'COM', 'TCA', 'SHN', 'DO2', 'DCF', 'PCN', 'MNP', 'MYT', 'SXM', 'MAF', 'GUI', 'AN', 'Slovak republic', 'Channel Islands', 'Reunion', 'Wales', 'Scotland', 'ica', 'WLF', 'D', 'F', 'I', 'B', 'L', 'E', 'A', 'S', 'N', 'H', 'R', 'NU', 'BES', 'Bavaria', 'TLS', 'J', 'TKL', 'Tirol"', 'P', '?????', 'EU', 'ES-IB', 'ES-CT', 'КГЫ', 'SOO', 'LZE', 'Могилёв', 'Гомель', 'Минск', 'Самара', 'Гродно', 'Москва']
412 уникальных значений.
В основном страна обозначается трехзначным буквенным кодом в верхнем регистре. Но как видно, далеко не всегда. На самом деле существует международный стандарт ISO 3166, в котором для всех стран, включая даже те, которых уже не существует, прописаны соответствующие трехзначные и двузначные коды. Для python одну из реализаций этого стандарта можно найти в пакете pycountry. Вот как он работает:
import pycountry as pyco pyco.countries.get(alpha_3 = 'RUS')
Out: Country(alpha_2='RU', alpha_3='RUS', name='Russian Federation', numeric='643')
Таким образом проверим все трехзначные коды, приведя к верхнему регистру, которые дают отклик в countries.get(…) и historic_countries.get(…):
valid_a3 = [c for c in ar['country'].unique() if pyco.countries.get(alpha_3 = c.upper()) != None or pyco.historic_countries.get(alpha_3 = c.upper()) != None])
Таких оказалось 190 из 412. То есть меньше половины.
Для остальных 222 (их список обозначим tofix) сделаем словарь соответствия fix, в котором ключом будет оригинальное название, а значением трехзначный код по стандарту ISO.
tofix = list(set(ar['country'].unique()) - set(valid_a3))
В первую очередь проверим двузначные коды с помощью pycountry.countries.get(alpha_2 = …), приведя к верхнему регистру:
for icc in tofix: #icc -invalid country code if pyco.countries.get(alpha_2 = icc.upper()) != None: fix[icc] = pyco.countries.get(alpha_2 = icc.upper()).alpha_3 else: if pyco.historic_countries.get(alpha_2 = icc.upper()) != None: fix[icc] = pyco.historic_countries.get(alpha_2 = icc.upper()).alpha_3
Затем полные имена через pycountry.countries.get(name = …), pycountry.countries.get(common_name = …), приведя их к форме str.title():
for icc in tofix: if pyco.countries.get(common_name = icc.title()) != None: fix[icc] = pyco.countries.get(common_name = icc.title()).alpha_3 else: if pyco.countries.get(name = icc.title()) != None: fix[icc] = pyco.countries.get(name = icc.title()).alpha_3 else: if pyco.historic_countries.get(name = icc.title()) != None: fix[icc] = pyco.historic_countries.get(name = icc.title()).alpha_3
Таким образом сокращаем число нераспознанных значений до 190. Все еще достаточно много:
['URU', '', 'PAR', 'SUECIA', 'KUW', 'South African', 'Гомель', 'Austrian', 'ISV', 'H', 'SCO', 'ES-CT', Гондурас', 'GUI', 'BOT', 'SEY', 'BIZ', 'LAB', 'PUR', 'Республика Беларусь', 'Scotland', 'Азербайджан', 'Минск', 'TCH', 'TGA', 'UT', 'BAH', 'GEQ', 'NEP', 'TAH', 'ica', 'FRE', 'E', 'TOG', 'MYA', 'Болгария', 'Danish (Dane)', 'SAM', 'TPE', 'MON', 'ger', 'Unknown', 'sui', 'R', 'SUI', 'A', 'GRN', 'KZK', 'Wales', 'Москва', 'GBS', 'ESA', 'Bavaria', 'Czech Republic', '31/3, Colin', 'SOL', 'SKN', 'Франция', 'MGL', 'XKX', 'WLS', 'MOL', 'FIJ', 'CAY', 'ES-IB', 'BER', 'PLE', 'MRI', 'B', 'KSA', 'Великобритания', 'Гродно', 'LAT', 'GRE', 'ARU', 'КГЫ', 'THI', 'NGR', 'MAD', 'SOG', 'MLD', '?????', 'AHO', 'sco', 'UAE', 'RUMANIA', 'CRO', 'RSA', 'NUEVA ZELANDA', 'KINO MANA', 'PHI', 'sue', 'Tirol"', 'IRI', 'POR', 'CZK', 'SAR', 'D', 'BRASIL', 'DCF', 'HAI', 'ned', 'N', 'BAHREIN', 'VTN', 'EU', 'CAM', 'Mark', 'BUL', 'Welsh', 'VIN', 'HON', 'ESTADOS UNIDOS', 'I', 'GUA', 'OMA', 'CRC', 'PRG', 'NIG', 'BHU', 'Joe', 'GER', 'RUN', 'ALG', 'Сербия', 'Channel Islands', 'Reunion', 'REPUBLICA CHECA', 'slo', 'ANG', 'NewCaledonia', 'GUT', 'VIE', 'ASA', 'BAR', 'SRI', 'L', 'Могилёв', 'J', 'BAS', 'LUXEMBURGO', 'S', 'CHI', 'SNG', 'BNN', 'den', 'F.I.TRI.', 'STEEL T BG', 'NCA', 'Slovak republic', 'MAS', 'LZE', 'Коста-Рика', 'F', 'BRU', 'Армения', 'LBA', 'NDL', 'DEN', 'IVB', 'BAN', 'Sandy', 'ZAM', 'sandy', 'Korea', 'SOO', 'BGI', 'Индия', 'LTV', 'selsmark, Alise', 'TAN', 'NED', 'Самара', 'Suchy, Jorg', 'SLO', 'SUDAFRICA', 'ZIM', 'Eddie', 'INA', 'Ирландия', 'SUD', 'VAN', 'FL', 'P', 'ITU', 'ZZ', 'Argentinean', 'CHA', 'DO2', 'WAL']
Можно заметить, что среди них все еще много трехзначных кодов, но это не ISO. Что же тогда? Оказывается, что существует еще один стандарт – олимпийский. К сожалению, его реализация не включена в pycountry и приходится искать что-то еще. Решение нашлось в виде csv файла на datahub.io. Поместим содержимое этого файла в pandas DataFrame под названием cdf.
official name
short name
iso2
iso3
ioc
0
NaN
Taiwan
TW
TWN
TPE
1
Afghanistan
Afghanistan
AF
AFG
AFG
2
Albania
Albania
AL
ALB
ALB
3
Algeria
Algeria
DZ
DZA
ALG
4
American Samoa
American Samoa
AS
ASM
ASA
5
Andorra
Andorra
AD
AND
AND
6
Angola
Angola
AO
AGO
ANG
7
Anguilla
Anguilla
AI
AIA
AIA
8
Antarctica
Antarctica
AQ
ATA
NaN
9
Antigua and Barbuda
Antigua & Barbuda
AG
ATG
ANT
10
Argentina
Argentina
AR
ARG
ARG
len(([x for x in tofix if x.upper() in list(cdf['ioc'])]))
Out: 82
Среди трехзначных кодов из tofix нашлось 82 соответствующих IOC. Добавим их в наш словарь соответствия.
for icc in tofix: if icc.upper() in list(cdf['ioc']): ind = cdf[cdf['ioc'] == icc.upper()].index[0] fix[icc] = cdf.loc[ind, 'iso3']
Осталось 108 необработанных значений. Их добиваем вручную, иногда обращаясь за помощью в Google.
{'BGI': 'BRB', 'WAL': 'GBR', 'MLD': 'MDA', 'KZK': 'KAZ', 'CZK': 'CZE', 'BNN': 'BEN', 'SNG': 'SGP', 'VTN': 'VNM', 'THI': 'THA', 'PRG': 'PRT', 'MOL': 'MDA', 'FRE': 'FRA', 'F.I.TRI.': 'ITA', 'BAHREIN': 'BHR', 'SUECIA': 'SWE', 'REPUBLICA CHECA': 'CZE', 'BRASIL': 'BRA', 'NDL': 'NLD', 'Danish (Dane)': 'DNK', 'Welsh': 'GBR', 'Austrian': 'AUT', 'Argentinean': 'ARG', 'South African': 'ZAF', 'ESTADOS UNIDOS': 'USA', 'LUXEMBURGO': 'LUX', 'SUDAFRICA': 'ZAF', 'NUEVA ZELANDA': 'NZL', 'RUMANIA': 'ROU', 'sco': 'GBR', 'SCO': 'GBR', 'WLS': 'GBR', 'Индия': 'IND', 'Ирландия': 'IRL', 'Армения': 'ARM', 'Болгария': 'BGR', 'Сербия': 'SRB', 'Республика Беларусь': 'BLR', 'Великобритания': 'GBR', 'Франция': 'FRA', 'Гондурас': 'HND', 'Коста-Рика': 'CRI', 'Азербайджан': 'AZE', 'Korea': 'KOR', 'NewCaledonia': 'FRA', 'Czech Republic': 'CZE', 'Slovak republic': 'SVK', 'Channel Islands': 'FRA', 'Reunion': 'FRA', 'Wales': 'GBR', 'Scotland': 'GBR', 'Bavaria': 'DEU', 'Tirol"': 'AUT', 'КГЫ': 'KGZ', 'Могилёв': 'BLR', 'Гомель': 'BLR', 'Минск': 'BLR', 'Самара': 'RUS', 'Гродно': 'BLR', 'Москва': 'RUS'}
Но даже ручное управление не решает проблему полностью. Остается 49 значений, которые уже невозможно интерпретировать. Вероятно, большая часть из этих значений – просто ошибки в данных.
unfixed = [x for x in tofix if x not in fix.keys()]
Out: ['', 'H', 'ES-CT', 'LAB', 'TCH', 'UT', 'TAH', 'ica', 'E', 'Unknown', 'R', 'A', '31/3, Colin', 'XKX', 'ES-IB','B','SOG','?????','KINO MANA','sue','SAR','D', 'DCF', 'N', 'EU', 'Mark', 'I', 'Joe', 'RUN', 'GUT', 'L', 'J', 'BAS', 'S', 'STEEL T BG', 'LZE', 'F', 'Sandy', 'DO2', 'sandy', 'SOO', 'LTV', 'selsmark, Alise', 'Suchy, Jorg' 'Eddie', 'FL', 'P', 'ITU', 'ZZ']
У этих ключей в словаре соответствия значением будет пустая строка.
for cc in unfixed: fix[cc] = ''
Напоследок добавим в словарь соответствия коды, которые являются валидными, но записаны в нижнем регистре.
for cc in valid_a3: if cc.upper() != cc: fix[cc] = cc.upper()
Теперь пришло время применить найденные замены. Чтобы сохранить начальные данные для дальнейшего сравнения копируем колонку country в country raw. Затем используя созданный словарь соответствия исправляем в колонке country значения, которые не соответствуют ISO.
for cc in fix: ind = ar[ar['country'] == cc].index ar.loc[ind,'country'] = fix[cc]
Здесь, конечно, не обойтись без векторизации, в таблице почти полтора миллиона строк. Но по словарю делаем цикл, а как иначе? Проверяем, сколько записей изменено:
len(ar[ar['country'] != ar['country raw']])
Out: 315955
то есть более 20% от общего количества.
ar[ar['country'] != ar['country raw']].sample(10)
place
sex
name
country
group
place in group
...
country raw
285
286
M
Albaek, Mads Orla
DNK
M30-34
63
...
DEN
1288
1289
M
Benthien, Andreas
DEU
M40-44
198
...
GER
490
491
M
Lontok, Joselito
PHL
M50-54
18
...
PHI
145
146
M
Mathiasen, Keld
DNK
M45-49
16
...
DEN
445
446
M
Palm, Francois
ZAF
M25-29
48
...
RSA
152
153
M
Muller, Johannes
DEU
M35-39
19
...
GER
764
765
F
Woscher Sylvia
DEU
F55-59
8
...
GER
2182
2183
M
Kojellis, Holger
DEU
M40-44
258
...
GER
1293
1294
M
Zweer, Waldemar
DEU
M25-29
117
...
GER
747
748
M
Petersen, Mathias
DNK
M25-29
79
...
DE
len(ar[ar['country'] == ''])
Out: 3221
Таково количество записей без страны или со страной неформата. Количество уникальных стран сократилось с 412 до 250. Вот они:
['', 'ABW', 'AFG', 'AGO', 'AIA', 'ALA', 'ALB', 'AND', 'ANT', 'ARE', 'ARG', 'ARM', 'ASM', 'ATA', 'ATF', 'AUS', 'AUT', 'AZE', 'BDI', 'BEL', 'BEN', 'BES', 'BGD', 'BGR', 'BHR', 'BHS', 'BIH', 'BLM', 'BLR', 'BLZ', 'BMU', 'BOL', 'BRA', 'BRB', 'BRN', 'BTN', 'BUR', 'BVT', 'BWA', 'CAF', 'CAN', 'CCK', 'CHE', 'CHL', 'CHN', 'CIV', 'CMR', 'COD', 'COG', 'COK', 'COL', 'COM', 'CPV', 'CRI', 'CTE', 'CUB', 'CUW', 'CXR', 'CYM', 'CYP', 'CZE', 'DEU', 'DJI', 'DMA', 'DNK', 'DOM', 'DZA', 'ECU', 'EGY', 'ERI', 'ESH', 'ESP', 'EST', 'ETH', 'FIN', 'FJI', 'FLK', 'FRA', 'FRO', 'FSM', 'GAB', 'GBR', 'GEO', 'GGY', 'GHA', 'GIB', 'GIN', 'GLP', 'GMB', 'GNB', 'GNQ', 'GRC', 'GRD', 'GRL', 'GTM', 'GUF', 'GUM', 'GUY', 'HKG', 'HMD', 'HND', 'HRV', 'HTI', 'HUN', 'IDN', 'IMN', 'IND', 'IOT', 'IRL', 'IRN', 'IRQ', 'ISL', 'ISR', 'ITA', 'JAM', 'JEY', 'JOR', 'JPN', 'KAZ', 'KEN', 'KGZ', 'KHM', 'KIR', 'KNA', 'KOR', 'KWT', 'LAO', 'LBN', 'LBR', 'LBY', 'LCA', 'LIE', 'LKA', 'LTU', 'LUX', 'LVA', 'MAC', 'MAF', 'MAR', 'MCO', 'MDA', 'MDG', 'MDV', 'MEX', 'MHL', 'MKD', 'MLI', 'MLT', 'MMR', 'MNE', 'MNG', 'MNP', 'MOZ', 'MSR', 'MTQ', 'MUS', 'MYS', 'MYT', 'NAM', 'NCL', 'NER', 'NFK', 'NGA', 'NHB', 'NIC', 'NIU', 'NLD', 'NOR', 'NPL', 'NRU', 'NZL', 'OMN', 'PAK', 'PAN', 'PCN', 'PER', 'PHL', 'PLW', 'PNG', 'POL', 'PRI', 'PRK', 'PRT', 'PRY', 'PSE', 'PYF', 'QAT', 'REU', 'ROU', 'RUS', 'RWA', 'SAU', 'SCG', 'SDN', 'SEN', 'SGP', 'SGS', 'SHN', 'SJM', 'SLB', 'SLE', 'SLV', 'SMR', 'SOM', 'SPM', 'SRB', 'SSD', 'SUR', 'SVK', 'SVN', 'SWE', 'SWZ', 'SXM', 'SYC', 'SYR', 'TCA', 'TCD', 'TGO', 'THA', 'TJK', 'TKL', 'TKM', 'TLS', 'TON', 'TTO', 'TUN', 'TUR', 'TUV', 'TWN', 'TZA', 'UGA', 'UKR', 'UMI', 'URY', 'USA', 'UZB', 'VAT', 'VCT', 'VEN', 'VGB', 'VIR', 'VNM', 'VUT', 'WLF', 'WSM', 'YEM', 'YUG', 'ZAF', 'ZMB', 'ZWE']
Теперь никаких отклонений. Сохраняем результат в новый файл details2.pkl, предварительно преобразовав объединенный датафрейм обратно в словарь датафреймов, как это было сделано ранее.
Локация
Теперь вспомним, что упоминание о странах также есть и в сводной таблице, в колонке loc.
event
date
loc
males
females
rus
total
link
0
Ironman Dubai Duathlon 70.3 2020
2020-07-02
Dubai, United Arab Emirates
835
215
65
1050
…
1
Ironman Dubai 70.3 2020
2020-02-07
Dubai, United Arab Emirates
638
132
55
770
…
2
Israman Half 2020
2020-01-29
Israel, Eilat
670
126
4
796
…
3
Ironman Indian Wells La Quinta 70.3 2019
2019-12-08
Indian Wells/La Quinta, California, USA
1590
593
6
2183
…
4
Ironman Taupo 70.3 2019
2019-12-07
New Zealand
767
420
3
1187
…
5
Ironman Bahrain 70.3 2019
2019-12-07
Manama, Bahrain
858
214
38
1072
…
6
Ironman Western Australia 2019
2019-12-01
Busselton, Western Australia
940
229
1
1169
…
7
Ironman Mar del Plata 2019
2019-12-01
Mar del Plata, Argentina
506
66
3
572
…
8
Ironman Cozumel 2019
2019-11-24
Cozumel, Mexico
1158
395
12
1553
…
9
Ironman Arizona 2019
2019-11-24
Tempe, Arizona, USA
1697
633
3
2330
…
Но и тут нашелся подходящий инструмент. Это geopy, а именно geolocator Nominatim. Работает вот так:
from geopy.geocoders import Nominatim geolocator = Nominatim(user_agent='triathlon results researcher') geolocator.geocode('Бирюзовая Катунь, Алтай, Россия', language='en')
Out: Location(Бирюзовая Катунь, Ая – Бирюзовая Катунь, Айский сельсовет, Altaysky District, Altai Krai, Siberian Federal District, Russia, (51.78897945, 85.73956296106752, 0.0))
По запросу в произвольной форме выдает структурированный ответ – адрес и координаты. Если задать язык, как здесь – английский, то что сможет — переведет. Нам в первую очередь нужно стандартное название страны для последующего перевода в код ISO. Оно как раз стоит на последнем месте в свойстве address. Поскольку geolocator каждый раз отправляет запрос на сервер, процесс этот не быстрый и для 500 записей занимает несколько минут. К тому же бывает, что ответ не приходит. В этом случае иногда помогает повторный запрос. В моем с первого раза ответ не пришел на 130 запросов. Большую часть из них удалось обработать двумя повторными попытками. Однако 34 названия обработать не так и не удалось даже несколькими дальнейшими повторными попытками. Вот они:
['Tongyeong, Korea, Korea, South', 'Constanta, Mamaia, Romania, Romania', 'Weihai, China, China', 'д. Толвинка, Брянская обл.', 'Odaiba Marin Park, Tokyo, Japan, Japan', 'Sweden, Smaland, Kalmar', 'Cholpon-Ata city, Resort Center "Kapriz", Kyrgyzstan', 'Luxembourg, Region Moselle, Moselle', 'Chita Peninsula, Japan', 'Kraichgau Region, Germany', 'Jintang, Chengdu, Sichuan Province, China, China', 'Madrid, Spain, Spain', 'North American Pro Championship, St. George, Utah, USA', 'Milan Idroscalo Linate, Italy', 'Dexing, Jiangxi Province, China, China', 'Mooloolaba, Australia, Australia', 'Nathan Benderson Park (NBP), 5851 Nathan Benderson Circle, Sarasota, FL 34235., United States', 'Strathclyde Country Park, North Lanarkshire, Glasgow, Great Britain', 'Quijing, China', 'United States of America , Hawaii, Kohala Coast', 'Buffalo City, East London, South Africa', 'Spain, Vall de Cardener', 'Россия, пос. Метлино Озерский городской округ', 'Asian TriClub Championship, Hefei, China', 'Taizhou, Jiangsu Province, China, China', 'Россия, Москва, СЦП «Крылатское»', 'Buffalo, Gallagher Beach, Furhmann Blvd, United States', 'North American Pro Championship | St. George, Utah, USA', 'Weihai, Shandong, China, China', 'Tarzo - Revine Lago, Italy', 'Lausanee, Switzerland', 'Queenstown, New Zealand, New Zealand', 'Makuhari, Japan, Japan', 'Szombathlely, Hungary']
Видно, что во многих присутствует двойное упоминание страны, и это на самом деле мешает. В общем пришлось вручную обработать эти оставшиеся названия и для всех были получены стандартные адреса. Далее из этих адресов я выделил страну и записал эту страну в новую колонку в сводной таблице. Поскольку, как я уже сказал работа с geopy не быстрая, я решил сразу сохранить координаты локации – широту и долготу. Они пригодятся позже для визуализации на карте.
event
date
loc
country
latitude
longitude
...
0
Ironman Dubai Duathlon 70.3 2020
2020-07-02
Dubai, United Arab Emirates
United Arab Emirates
25.0657
55.1713
...
1
Ironman Dubai 70.3 2020
2020-02-07
Dubai, United Arab Emirates
United Arab Emirates
25.0657
55.1713
...
2
Israman Half 2020
2020-01-29
Israel, Eilat
Israel
29.5569
34.9498
...
3
Ironman Indian Wells La Quinta 70.3 2019
2019-12-08
Indian Wells/La Quinta, California, USA
United States of America
33.7238
-116.305
...
4
Ironman Taupo 70.3 2019
2019-12-07
New Zealand
New Zealand
-41.5001
172.834
...
5
Ironman Bahrain 70.3 2019
2019-12-07
Manama, Bahrain
Bahrain
26.2235
50.5822
...
6
Ironman Western Australia 2019
2019-12-01
Busselton, Western Australia
Australia
-33.6445
115.349
...
7
Ironman Mar del Plata 2019
2019-12-01
Mar del Plata, Argentina
Argentina
-37.9977
-57.5483
...
8
Ironman Cozumel 2019
2019-11-24
Cozumel, Mexico
Mexico
20.4318
-86.9203
...
9
Ironman Arizona 2019
2019-11-24
Tempe, Arizona, USA
United States of America
33.4255
-111.94
...
10
Ironman Xiamen 70.3 2019
2019-11-10
Xiamen, China
China
24.4758
118.075
...
event
date
loc
country
latitude
longitude
...
0
Ironman Dubai Duathlon 70.3 2020
2020-07-02
Dubai, United Arab Emirates
ARE
25.0657
55.1713
...
1
Ironman Dubai 70.3 2020
2020-02-07
Dubai, United Arab Emirates
ARE
25.0657
55.1713
...
2
Israman Half 2020
2020-01-29
Israel, Eilat
ISR
29.5569
34.9498
...
3
Ironman Indian Wells La Quinta 70.3 2019
2019-12-08
Indian Wells/La Quinta, California, USA
USA
33.7238
-116.305
...
4
Ironman Taupo 70.3 2019
2019-12-07
New Zealand
NZL
-41.5001
172.834
...
5
Ironman Bahrain 70.3 2019
2019-12-07
Manama, Bahrain
BHR
26.2235
50.5822
...
6
Ironman Western Australia 2019
2019-12-01
Busselton, Western Australia
AUS
-33.6445
115.349
...
7
Ironman Mar del Plata 2019
2019-12-01
Mar del Plata, Argentina
ARG
-37.9977
-57.5483
...
8
Ironman Cozumel 2019
2019-11-24
Cozumel, Mexico
MEX
20.4318
-86.9203
...
9
Ironman Arizona 2019
2019-11-24
Tempe, Arizona, USA
USA
33.4255
-111.94
...
10
Ironman Xiamen 70.3 2019
2019-11-10
Xiamen, China
CHN
24.4758
118.075
...
Дистанция
Еще одно важное действие, которое нужно сделать на сводной таблице – для каждой гонки определить дистанцию. Это пригодится нам для вычисления скоростей в дальнейшем. В триатлоне существует четыре основных дистанции – спринт, олимпийская, полужелезная и железная. Можно видеть, что в названиях гонок как правило есть указание на дистанцию – это Слова Sprint, Olympic, Half, Full. Помимо этого, у разных организаторов свои обозначения дистанций. Половинка у Ironman, например, обозначается как 70.3 – по количеству миль в дистанции, олимпийская – 5150 по числу километров (51.5), а железная может обозначаться как Full или, вообще, как отсутствие пояснений – например Ironman Arizona 2019. Ironman – он и есть железный! У Challenge железная дистанция обозначается как Long, а полужелезная – как Middle. Наш российский IronStar обозначает полную как 226, а половинку как 113 – по числу километров, но обычно слова Full и Half тоже присутствуют. Теперь применим все эти знания и пометим все гонки в соответствии с ключевыми словами, присутствующими в названиях.
sprints = rs.loc[[i for i in rs.index if 'sprint' in rs.loc[i, 'event'].lower()]] olympics1 = rs.loc[[i for i in rs.index if 'olympic' in rs.loc[i, 'event'].lower()]] olympics2 = rs.loc[[i for i in rs.index if '5150' in rs.loc[i, 'event'].lower()]] olympics = pd.concat([olympics1, olympics2]) #… и так далее rsd = pd.concat([sprints, olympics, halfs, fulls])
В rsd получилось 1 925 записей, то есть на три больше, чем общее число гонок, значит какие-то попали под два критерия. Посмотрим на них:
rsd[rsd.duplicated(keep=False)]['event'].sort_index()
event
date
loc
country
latitude
longitude
...
38
Temiradam 113 Half 2019
2019-09-22
Казахстан, Актау
KAZ
43.6521
51.158
...
38
Temiradam 113 Half 2019
2019-09-22
Казахстан, Актау
KAZ
43.6521
51.158
...
65
Triway Olympic Sprint 2019
2019-09-08
Россия, Ростов-на-Дону
RUS
47.2214
39.7114
...
65
Triway Olympic Sprint 2019
2019-09-08
Россия, Ростов-на-Дону
RUS
47.2214
39.7114
...
82
Ironman Dun Laoghaire Full Swim 70.3 2019
2019-08-25
Ireland, Dun Laoghaire
IRL
53.2923
-6.13601
...
82
Ironman Dun Laoghaire Full Swim 70.3 2019
2019-08-25
Ireland, Dun Laoghaire
IRL
53.2923
-6.13601
...
place
sex
name
country
group
place in group
swim
t1
bike
t2
run
result
0
1
M
Хисматуллин Роман
RUS
MМужчины
1
00:12:21
00:00:31
00:34:13
00:00:25
00:21:49
01:09:19
1
2
M
Диков Александр
RUS
MМужчины
2
00:12:21
00:00:28
00:34:15
00:00:26
00:23:07
01:10:38
2
3
M
Горлов Дмитрий
RUS
MМужчины
3
00:14:20
00:00:37
00:35:48
00:00:34
00:22:16
01:13:35
olympics.drop(65)
Точно так же поступим с пересекающимися Ironman Dun Laoghaire Full Swim 70.3 2019
place
sex
name
country
group
place in group
swim
t1
bike
t2
run
result
0
1
M
Brownlee, Alistair
GBR
MPRO
1
00:23:19
00:02:18
02:21:19
00:01:55
01:11:42
04:00:33
1
2
M
Smales, Elliot
GBR
MPRO
2
00:24:47
00:02:09
02:29:26
00:01:48
01:12:47
04:10:57
2
3
M
Bowden, Adam
GBR
MPRO
3
00:23:24
00:02:18
02:32:09
00:02:06
01:13:49
04:13:46
fulls.drop(85)
Теперь запишем информацию о дистанции в основной датафрейм и посмотрим, что получилось:
rs['dist'] = '' rs.loc[sprints.index,'dist'] = 'sprint' rs.loc[olympics.index,'dist'] = 'olympic' rs.loc[halfs.index,'dist'] = 'half' rs.loc[fulls.index,'dist'] = 'full' rs.sample(10)
event
place
sex
name
country
group
place in group
...
country raw
group raw
...
566
M
Vladimir Kozar
SVK
M40-44
8
...
SVK
MOpen 40-44
...
8
M
HANNES COOL
BEL
MPRO
11
...
BEL
MPRO M
...
445
F
Ileana Sodani
USA
F45-49
4
...
USA
F45-49 F
...
227
F
JARLINSKA Bozena
POL
F45-49
2
...
POL
FK45-49
...
440
F
Celine Orrigoni
FRA
F40-44
6
...
FRA
F40-44 F
...
325
M
Vladimir Eckert
SVK
M40-44
6
...
SVK
MOpen 40-44
...
139
F
ATRASZKIEWICZ Magda
POL
F40-44
2
...
POL
FK40-44
...
18
M
Marijn de Jonge
NLD
MPRO
18
...
NED
Mpro
...
574
M
Luca Andalo
ITA
M40-44
9
...
ITA
MOpen 40-44
...
67
M
URBANKIEWICZ Aleksandra
POL
M35-39
1
...
POL
MK35-39
len(rs[rs['dist'] == ''])
Out: 0
И проверим наши проблемные, двусмысленные:
rs.loc[[38,65,82],['event','dist']]
event
dist
38
Temiradam 113 Half 2019
half
65
Triway Olympic Sprint 2019
sprint
82
Ironman Dun Laoghaire Full Swim 70.3 2019
half
pkl.dump(rs, open(r'D:\tri\summary5.pkl', 'wb'))
Возрастные группы
Теперь вернемся к протоколам гонок.
Мы уже проанализировали пол, страну и результаты участника, и привели их к стандартному виду. Но еще остались еще две графы – группа и, собственно, само имя. Начнем с групп. В триатлоне принято делить участников по возрастным группам. Также часто выделяется группа профессионалов. По сути, зачет идет в каждой такой группе отдельно — награждаются первые три места в каждой группе. По группам же идет квалификационный отбор на чемпионаты, например, на Кону.
Объединим все записи и посмотрим какие вообще группы существуют.
rd = pkl.load(open(r'D:\tri\details2.pkl', 'rb')) ar = pd.concat(rd) ar['group'].unique()
Оказалось, что групп огромное количество – 581. Сотня случайно выбранных выглядит так:
['MSenior', 'FAmat.', 'M20', 'M65-59', 'F25-29', 'F18-22', 'M75-59', 'MPro', 'F24', 'MCORP M', 'F21-30', 'MSenior 4', 'M40-50', 'FAWAD', 'M16-29', 'MK40-49', 'F65-70', 'F65-70', 'M12-15', 'MK18-29', 'MМ50up', 'FSEMIFINAL 2 PRO', 'F16', 'MWhite', 'MOpen 25-29', 'FПараатлет', 'MPT TRI-2', 'M16-24', 'FQUALIFIER 1 PRO', 'F15-17', 'FSEMIFINAL 2 JUNIOR', 'FOpen 60-64', 'M75-80', 'F60-69', 'FJUNIOR A', 'F17-18', 'FAWAD BLIND', 'M75-79', 'M18-29', 'MJUN19-23', 'M60-up', 'M70', 'MPTS5', 'F35-40', "M'S PT1", 'M50-54', 'F65-69', 'F17-20', 'MP4', 'M16-29', 'F18up', 'MJU', 'MPT4', 'MPT TRI-3', 'MU24-39', 'MK35-39', 'F18-20', "M'S", 'F50-55', 'M75-80', 'MXTRI', 'F40-45', 'MJUNIOR B', 'F15', 'F18-19', 'M20-29', 'MAWAD PC4', 'M30-37', 'F21-30', 'Mpro', 'MSEMIFINAL 1 JUNIOR', 'M25-34', 'MAmat.', 'FAWAD PC5', 'FA', 'F50-60', 'FSenior 1', 'M80-84', 'FK45-49', 'F75-79', 'M<23', 'MPTS3', 'M70-75', 'M50-60', 'FQUALIFIER 3 PRO', 'M9', 'F31-40', 'MJUN16-19', 'F18-19', 'M PARA', 'F35-44', 'MParaathlete', 'F18-34', 'FA', 'FAWAD PC2', 'FAll Ages', 'M PARA', 'F31-40', 'MM85', 'M25-39']
Посмотрим какие из них самые многочисленные:
ar['group'].value_counts()[:30]
Out:
M40-44 199157
M35-39 183738
M45-49 166796
M30-34 154732
M50-54 107307
M25-29 88980
M55-59 50659
F40-44 48036
F35-39 47414
F30-34 45838
F45-49 39618
MPRO 38445
F25-29 31718
F50-54 26253
M18-24 24534
FPRO 23810
M60-64 20773
M 12799
F55-59 12470
M65-69 8039
F18-24 7772
MJUNIOR 6605
F60-64 5067
M20-24 4580
FJUNIOR 4105
M30-39 3964
M40-49 3319
F 3306
M70-74 3072
F20-24 2522
Можно видеть, что это группы по пять лет, отдельно для мужчин и отдельно для женщин, а также профессиональные группы MPRO и FPRO.
Итак, нашим стандартом будет:
ag = ['MPRO', 'M18-24', 'M25-29', 'M30-34', 'M35-39', 'M40-44', 'M45-49', 'M50-54', 'M55-59', 'M60-64', 'M65-69', 'M70-74', 'M75-79', 'M80-84', 'M85-90', 'FPRO', 'F18-24', 'F25-29', 'F30-34', 'F35-39', 'F40-44', 'F45-49', 'F50-54', 'F55-59', 'F60-64', 'F65-69', 'F70-74', 'F75-79', 'F80-84', 'F85-90'] #ag – age group
Этим множеством покрывается почти 95% всех финишеров.
Разумеется, нам не удастся привести к этому стандарту вообще все группы. Но мы поищем те, что похожи на них и приведем хотя бы часть. Предварительно приведем к верхнему регистру и удалим пробелы. Вот что нашлось:
['F25-29F', 'F30-34F', 'F30-34-34', 'F35-39F', 'F40-44F', 'F45-49F', 'F50-54F', 'F55-59F', 'FAG:FPRO', 'FK30-34', 'FK35-39', 'FK40-44', 'FK45-49', 'FOPEN50-54', 'FOPEN60-64', 'MAG:MPRO', 'MK30-34', 'MK30-39', 'MK35-39', 'MK40-44', 'MK40-49', 'MK50-59', 'MМ40-44', 'MM85-89', 'MOPEN25-29', 'MOPEN30-34', 'MOPEN35-39', 'MOPEN40-44', 'MOPEN45-49', 'MOPEN50-54', 'MOPEN70-74', 'MPRO:', 'MPROM', 'M0-44"']
Преобразуем их к нашим стандартным.
fix = { 'F25-29F': 'F25-29', 'F30-34F' : 'F30-34', 'F30-34-34': 'F30-34', 'F35-39F': 'F35-39', 'F40-44F': 'F40-44', 'F45-49F': 'F45-49', 'F50-54F': 'F50-54', 'F55-59F': 'F55-59', 'FAG:FPRO': 'FPRO', 'FK30-34': 'F30-34', 'FK35-39': 'F35-39', 'FK40-44': 'F40-44', 'FK45-49': 'F45-49', 'FOPEN50-54': 'F50-54', 'FOPEN60-64': 'F60-64', 'MAG:MPRO': 'MPRO', 'MK30-34': 'M30-34', 'MK30-39': 'M30-39', 'MK35-39': 'M35-39', 'MK40-44': 'M40-44', 'MK40-49': 'M40-49', 'MK50-59': 'M50-59', 'MМ40-44': 'M40-44', 'MM85-89': 'M85-89', 'MOPEN25-29': 'M25-29', 'MOPEN30-34': 'M30-34', 'MOPEN35-39': 'M35-39', 'MOPEN40-44': 'M40-44', 'MOPEN45-49': 'M45-49', 'MOPEN50-54': 'M50-54', 'MOPEN70-74': 'M70- 74', 'MPRO:' :'MPRO', 'MPROM': 'MPRO', 'M0-44"' : 'M40-44'}
Применим теперь наше преобразование к основному датафрейму ar, но предварительно сохраним изначальные значения group в новою колонку group raw.
ar['group raw'] = ar['group']
В колонке group оставим только те значения, которые соответствуют нашему стандарту.
Теперь можно оценить наши старания:
len(ar[(ar['group'] != ar['group raw'])&(ar['group']!='')])
Out: 273
Совсем немного на уровне полутора миллионов. Но ведь не узнаешь, пока не попробуешь.
Выборочные 10 выглядят так:
event
place
sex
name
country
group
place in group
...
country raw
group raw
...
566
M
Vladimir Kozar
SVK
M40-44
8
...
SVK
MOpen 40-44
...
8
M
HANNES COOL
BEL
MPRO
11
...
BEL
MPRO M
...
445
F
Ileana Sodani
USA
F45-49
4
...
USA
F45-49 F
...
227
F
JARLINSKA Bozena
POL
F45-49
2
...
POL
FK45-49
...
440
F
Celine Orrigoni
FRA
F40-44
6
...
FRA
F40-44 F
...
325
M
Vladimir Eckert
SVK
M40-44
6
...
SVK
MOpen 40-44
...
139
F
ATRASZKIEWICZ Magda
POL
F40-44
2
...
POL
FK40-44
...
18
M
Marijn de Jonge
NLD
MPRO
18
...
NED
Mpro
...
574
M
Luca Andalo
ITA
M40-44
9
...
ITA
MOpen 40-44
...
67
M
URBANKIEWICZ Aleksandra
POL
M35-39
1
...
POL
MK35-39
pkl.dump(rd, open(r'D:\tri\details3.pkl', 'wb'))
Имя
Теперь займемся именами. Посмотрим выборочно 100 имен с разных гонок:
list(ar['name'].sample(100))
Out: ['Case, Christine', 'Van der westhuizen, Wouter', 'Grace, Scott', 'Sader, Markus', 'Schuller, Gunnar', 'Juul-Andersen, Jeppe', 'Nelson, Matthew', 'Забугина Валерия Геннадьевна', 'Westman, Pehr', 'Becker, Christoph', 'Bolton, Jarrad', 'Coto, Ricardo', 'Davies, Luke', 'Daniltchev, Alexandre', 'Escobar Labastida, Emmanuelle', 'Idzikowski, Jacek', 'Fairaislova Iveta', 'Fisher, Kulani', 'Didenko, Viktor', 'Osborne, Jane', 'Kadralinov, Zhalgas', 'Perkins, Chad', 'Caddell, Martha', 'Lynaire PARISH', 'Busing, Lynn', 'Nikitin, Evgeny', 'ANSON MONZON, ROBERTO', 'Kaub, Bernd', 'Bank, Morten', 'Kennedy, Ian', 'Kahl, Stephen', 'Vossough, Andreas', 'Gale, Karen', 'Mullally, Kristin', 'Alex FRASER', 'Dierkes, Manuela', 'Gillett, David', 'Green, Erica', 'Cunnew, Elliott', 'Sukk, Gaspar', 'Markina Veronika', 'Thomas KVARICS', 'Wu, Lewen', 'Van Enk, W.J.J', 'Escobar, Rosario', 'Healey, Pat', 'Scheef, Heike', 'Ancheta, Marlon', 'Heck, Andreas', 'Vargas Iii, Raul', 'Seferoglou, Maria', 'chris GUZMAN', 'Casey, Timothy', 'Olshanikov Konstantin', 'Rasmus Nerrand', 'Lehmann Bence', 'Amacker, Kirby', 'Parks, Chris', 'Tom, Troy', 'Karlsson, Ulf', 'Halfkann, Dorothee', 'Szabo, Gergely', 'Antipov Mikhail', 'Von Alvensleben, Alvo', 'Gruber, Peter', 'Leblanc, Jean-Philippe', 'Bouchard, Jean-Francois', 'Marchiotto MASSIMO', 'Green, Molly', 'Alder, Christoph', 'Morris, Huw', 'Deceur, Marc', 'Queenan, Derek', 'Krause, Carolin', 'Cockings, Antony', 'Ziehmer Chris', 'Stiene, John', 'Chmet Daniela', 'Chris RIORDAN', 'Wintle, Mel', 'Борисёнок Павел', 'GASPARINI CHRISTIAN', 'Westbrook, Christohper', 'Martens, Wim', 'Papson, Chris', 'Burdess, Shaun', 'Proctor, Shane', 'Cruzinha, Pedro', 'Hamard, Jacques', 'Petersen, Brett', 'Sahyoun, Sebastien', "O'Connell, Keith", 'Symoshenko, Zhan', 'Luternauer, Jan', 'Coronado, Basil', 'Smith, Alex', 'Dittberner, Felix', 'N?sman, Henrik', 'King, Malisa', 'PUHLMANN Andre']
Все сложно. Встречаются самые разные варианты записей: Имя Фамилия, Фамилия Имя, Фамилия, Имя, ФАМИЛИЯ, Имя и т. д. То есть разный порядок, разный регистр, где-то есть разделитель — запятая. Так же существует немало протоколов, в которых идет кириллица. Там тоже нет единообразия, и могут встречаться такие форматы: “Фамилия Имя”, “Имя Фамилия”, “Имя Отчество Фамилия”, “Фамилия Имя Отчество”. Хотя на самом деле отчество встречается и в латинском написании. И здесь, кстати, встает еще одна проблема – транслитерация. Еще надо отметить, что даже там, где отчества нет, запись может не ограничиваться двумя словами. Например, у латиноамериканцев имя плюс фамилия обычно состоят из трех или четырех слов. У голландцев бывает приставка Van, у китайцев и корейцев тоже составные имена обычно из трех слов. В общем, надо как-то распутать весь этот ребус и по максимуму стандартизировить. Как правило внутри одной гонки формат имени одинаков для всех, но даже здесь встречаются ошибки, которые мы, однако, обрабатывать не будем. Начнем с того, что сохраним существующие значения в новой колонке name raw:
ar['name raw'] = ar['name']
Абсолютное большинство протоколов на латинице, поэтому первым делом я хотел бы сделать транслит. Посмотрим, какие вообще символы могут входить в имя участника.
set( ''.join(ar['name'].unique()))
Out: [' ', '!', '"', '#', '&', "'", '(', ')', '*', '+', ',', '-', '.', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '?', '@', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '[', '\\', ']', '^', '_', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', 'µ', '¶', '·', '»', 'Ё', 'І', 'А', 'Б', 'В', 'Г', 'Д', 'Е', 'Ж', 'З', 'И', 'Й', 'К', 'Л', 'М', 'Н', 'О', 'П', 'Р', 'С', 'Т', 'У', 'Ф', 'Х', 'Ц', 'Ч', 'Ш', 'Щ', 'Ы', 'Ь', 'Э', 'Ю', 'Я', 'а', 'б', 'в', 'г', 'д', 'е', 'ж', 'з', 'и', 'й', 'к', 'л', 'м', 'н', 'о', 'п', 'р', 'с', 'т', 'у', 'ф', 'х', 'ц', 'ч', 'ш', 'щ', 'ъ', 'ы', 'ь', 'э', 'ю', 'я', 'ё', 'є', 'і', 'ў', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
Чего тут только нет! Помимо собственно букв и пробелов, еще куча разных диковинных символов. Из них допустимыми, то есть присутствующими не по ошибке, можно считать точку ‘.’, дефис ‘-’ и апостроф “’”. Помимо этого, было замечено что во многих немецких и норвежских именах и фамилиях присутствует знак вопроса ‘?’. Они, судя по всему, заменяют здесь символы из расширенной латиницы – ‘?’, ‘a’, ‘o’, ‘u’,? и др. Вот примеры:
Pierre-Alexandre Petit, Jean-louis Lafontaine, Faris Al-Sultan, Jean-Francois Evrard, Paul O'Mahony, Aidan O'Farrell, John O'Neill, Nick D'Alton, Ward D'Hulster, Hans P.J. Cami, Luis E. Benavides, Maximo Jr. Rueda, Prof. Dr. Tim-Nicolas Korf, Dr. Boris Scharlowsk, Eberhard Gro?mann, Magdalena Wei?, Gro?er Axel, Meyer-Szary Krystian, Morten Halkj?r, RASMUSSEN S?ren Balle
Запятая, хоть и встречается очень часто, является всего лишь разделителем, принятым на определенных гонках, поэтому тоже попадет в разряд недопустимых. Цифры тоже не должны появляться в именах.
bs = [s for s in symbols if not (s.isalpha() or s in " . - ' ? ,")] #bs – bad symbols bs
Out: ['!', '"', '#', '&', '(', ')', '*', '+', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '@', '[', '\\', ']', '^', '_', '`', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', '¶', '·', '»', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
Временно уберем все эти символы, чтобы узнать в скольких записях они присутствуют:
for s in bs: ar['name'] = ar['name'].str.replace(s, '') corr = ar[ar['name'] != ar['name raw']]
Таких записей 2 184, то есть всего 0.15% от общего количества – очень мало. Взглянем выборочно на 100 из них:
list(corr['name raw'].sample(100))
Out: ['Scha¶ffl, Ga?nter', 'Howard, Brian &', 'Chapiewski, Guilherme (Gc)', 'Derkach 1svd_mail_ru', 'Parker H1 Lauren', 'Leal le?n, Yaneri', 'TencA, David', 'Cortas La?pez, Alejandro', 'Strid, Bja¶rn', '(Crutchfield) Horan, Katie', 'Vigneron, Jean-Michel.Vigneron@gmail.Com', 'МОШКОВ\xa0Иван', 'Telahr, J†rgen', 'St”rmer, Melanie', 'Nagai B1 Keiji', 'Rinc?n, Mariano', 'Arkalaki, Angela (Evangelia)', 'Barbaro B1 Bonin Anna G:Charlotte', 'Ra?esch, Ja¶rg', "CAVAZZI NICCOLO\\'", 'D„nzel, Thomas', 'Ziska, Steffen (Gerhard)', 'Kobilica B1 Alen', 'Mittelholcz, Bala', 'Jimanez Aguilar, Juan Antonio', 'Achenza H1 Giovanni', 'Reppe H2 Christiane', 'Filipovic B2 Lazar', 'Machuca Ka?hnel, Ruban Alejandro', 'Gellert (Silberprinz), Christian', 'Smith (Guide), Matt', 'Lenatz H1 Benjamin', 'Da¶llinger, Christian', 'Mc Carthy B1 Patrick Donnacha G:Bryan', 'Fa¶llmer, Chris', 'Warner (Rivera), Lisa', 'Wang, Ruijia (Ray)', 'Mc Carthy B1 Donnacha', 'Jones, Nige (Paddy)', 'Sch”ler, Christoph', 'НЕДОШИТОВ\xa0Дмитрий', 'Holthaus, Adelhard (Allard)', 'Mi;Arro, Ana', 'Dr: Koch Stefan', 'МОШКОВ\xa0Юрий', 'ЦУБЕРА\xa0Максим', 'Ziska, Steffen (Gerhard)', 'Albarraca\xadn Gonza?lez, Juan Francisco', 'Ha¶fling, Imke', 'Johnston, Eddie (Edwin)', 'Mulcahy, Bob (James)', 'Gottschalk, Bj”rn', 'ГУЩИН\xa0Дмитрий', 'Gretsch H2 Kendall', 'Scorse, Christopher (Chris)', 'Kiel‚basa, Pawel', 'Kalan, Magnus', 'Roderick "eric" SIMBULAN', 'Russell;, Mark', 'ROPES AND GRAY TEAM 3', 'Andrade, H?¦CTOR DANIEL', 'Landmann H2 Joshua', 'Reyes Rodra\xadguez, Aithami', 'Ziska, Steffen (Gerhard)', 'Ziska, Steffen (Gerhard)', 'Heuza, Pierre', 'Snyder B1 Riley Brad G:Colin', 'Feldmann, Ja¶rg', 'Beveridge H1 Nic', 'FAGES`, perrine', 'Frank", Dieter', 'Saarema¤el, Indrek', 'Betancort Morales, Arida–y', 'Ridderberg, Marie_Louise', 'ЗАЙЦЕВ\xa0Андрей', 'Ka¶nig, Johannes', 'W Van(der Klugt', 'Ziska, Steffen (Gerhard)', 'Johnson, Nick26', 'Heinz JOHNER03', 'Ga¶rg, Andra', 'Maruo B2 Atsuko', 'Moral Pedrero H1 Eva Maria', 'КУТАСОВ\xa0Сергей', 'MATUS SANTIAGO Osc1r', 'Stenbrink, Bja¶rn', 'Wangkhan, Sm1.Thaworn', 'Pullerits, Ta¶nu', 'Clausner, 8588294149', 'Castro Miranda, Josa Ignacio', 'La¶fgren, Pontuz', 'Brown, Jann ( Janine )', 'Ziska, Steffen (Gerhard)', 'Koay, Sa¶ren', 'Ba¶hm, Heiko', 'Oleksiuk B2 Vita', 'G Van(de Grift', 'Scha¶neborn, Guido', 'Mandez, A?lvaro', 'Garca\xada Fla?rez, Daniel']
В итоге, после долгих исследований, было решено: все буквенные символы, а также пробел, дефис, апостроф и знак вопроса оставить как есть, запятую, точку и символ ‘\xa0’ заменить на пробелы, а все остальные символы заменить на пустую строку, то есть просто удалить.
ar['name'] = ar['name raw'] for s in symbols: if s.isalpha() or s in " - ? '": continue if s in ".,\xa0": ar['name'] = ar['name'].str.replace(s, ' ') else: ar['name'] = ar['name'].str.replace(s, '')
Затем избавимся от лишних пробелов:
ar['name'] = ar['name'].str.split().str.join(' ') ar['name'] = ar['name'].str.strip() # на всякий случай
Посмотрим, что получилось:
ar.loc[corr.index].sample(10)
place
sex
name
country
...
name raw
63
64
M
Curzillat B MARANO Annouck GJulie
FRA
...
Curzillat B1 MARANO Annouck G:Julie
425
426
M
Naranjo Quintero Cndido
ESP
...
Naranjo Quintero, C‡ndido
1347
1348
F
Chang Margaret Peggy
USA
...
Chang, Margaret (Peggy)
790
791
M
Gonzalez Ruben
PRI
...
Gonzalez`, Ruben
1562
1563
M
Garcia Hernandez Elias
MEX
...
Garcia Hernandez/, Elias
50
51
M
Reppe H Christiane
DEU
...
Reppe H2 Christiane
528
529
M
Ho Shihken
TWN
...
Ho, Shih—ken
819
820
M
Elmously A R Abdelrahman
EGY
...
Elmously, A.R. (Abdelrahman)
249
250
F
boyer Isabelle
THA
...
`boyer, Isabelle
744
745
M
Garcaa Morales Pedro Luciano
ESP
...
Garca¬a Morales, Pedro Luciano
qmon = ar[(ar['name'].str.replace('?', '').str.strip() == '')&(ar['name']!='')] #qmon – question mark only names
Таких 3 429. Выглядит это примерно так:
place
sex
name
country
group
place in group
...
country raw
group raw
name raw
818
819
M
???? ???
JPN
M45-49
177
...
JPN
M45-49
????, ???
1101
1102
M
?? ??
JPN
M50-54
159
...
JPN
M50-54
??, ??
162
163
M
? ??
CHN
M30-34
22
...
CHN
M30-34
?, ??
1271
1272
F
???? ????
JPN
F50-54
15
...
JPN
F50-54
????, ????
552
553
M
??? ??
JPN
M25-29
30
...
JPN
M25-29
???, ??
423
424
M
??? ????
JPN
M55-59
24
...
JPN
M55-59
???, ????
936
937
F
?? ??
JPN
F50-54
7
...
JPN
F50-54
??, ??
244
245
M
? ??
KOR
M50-54
30
...
KOR
M50-54
?, ??
627
628
M
? ?
CHN
M40-44
94
...
CHN
M40-44
?, ?
194
195
M
?????? ?????
RUS
188
...
RUS
M
?????? ?????
ar.loc[qmon.index, 'name'] = ''
Всего записей, где имя – пустая строка получилось 3 454. Не так много — переживем. Теперь, когда мы избавились от ненужных символов, можно перейти к транслитерации. Для этого сперва приведем все к нижнему регистру, чтобы не делать двойную работу.
ar['name'] = ar['name'].str.lower()
Далее создаем словарик:
trans = {'а':'a', 'б':'b', 'в':'v', 'г':'g', 'д':'d', 'е':'e', 'ё':'e', 'ж':'zh', 'з':'z', 'и':'i', 'й':'y', 'к':'k', 'л':'l', 'м':'m', 'н':'n', 'о':'o', 'п':'p', 'р':'r', 'с':'s', 'т':'t', 'у':'u', 'ф':'f', 'х':'kh', 'ц':'ts', 'ч':'ch', 'ш':'sh', 'щ':'shch', 'ь':'', 'ы':'y', 'ъ':'', 'э':'e', 'ю':'yu', 'я':'ya', 'є':'e', 'і': 'i','ў':'w','µ':'m'}
В него также попали буквы из так называемой расширенной кириллицы — 'є', 'і', 'ў', которые используются в белорусском и украинском языках, а также греческая буква 'µ'. Применяем преобразование:
for s in trans: ar['name'] = ar['name'].str.replace(s, trans[s])
Теперь из рабочего нижнего регистра переведем все в привычный формат, где имя и фамилия начинаются с большой буквы:
ar['name'] = ar['name'].str.title()
Посмотрим, что получилось.
ar[ar['name raw'].str.lower().str[0].isin(trans.keys())].sample(10)
place
sex
name
...
country raw
name raw
99
100
M
Nikolay Golovkin
...
RUS
Николай Головкин
95
96
M
Maksim Vasilevich Chubakov
...
RUS
Максим Васильевич Чубаков
325
326
F
Ganieva Aygul
...
RUS
Ганиева Айгуль
661
662
M
Maksut Nizamutdinov
...
RUS
Максут Низамутдинов
356
357
F
Kolobanova Svetlana
...
RUS
Колобанова Светлана
117
118
M
Guskov Vladislav
...
RUS
Гуськов Владислав
351
352
M
Kolesnikov Dmitriy
...
RUS
Колесников Дмитрий
92
93
M
Kuznetsov Oleg
...
RUS
Кузнецов Олег
50
51
M
Khoraykin Maksim
...
RUS
Хорайкин Максим
6
7
M
Brylev Aleksey
...
RUS
Брылев Алексей
set( ''.join(ar['name'].unique()))
Out: [' ', "'", '-', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J','K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
Все правильно. В итоге исправления коснулись 1 253 882 или 89% записей, количество уникальных имен снизилось с 660 207 до 599 186, то есть на 61 тысячу или почти на 10 %. Здорово! Cохраняем в новый файл, предварительно переведя объединение записей ar обратно в словарь протоколов rd.
pkl.dump(rd, open(r'D:\tri\details4.pkl', 'wb'))
Теперь надо восстановить порядок. То есть что бы все записи имели вид – Имя Фамилия или Фамилия Имя. Какой именно – предстоит определить. Правда помимо имени и фамилии в некоторых протоколах записаны еще и отчества. И может так получиться, что один и тот же человек в разных протоколах записан по-разному – где-то с отчеством, где-то без. Это будет мешать его идентифицировать, поэтому попробуем удалить отчества. Отчества у мужчин обычно имеют окончание «вич», а у женщин — «вна». Но есть и исключения. Например – Ильич, Ильинична, Никитич, Никитична. Правда таких исключений очень мало. Как уже было отмечено формат имен в рамках одного протокола можно считать постоянным. Поэтому, чтобы избавиться от отчеств, нужно найти гонки, в которых они присутствуют. Для этого надо найти суммарное количество фрагментов «vich» и «vna» в колонке name и сравнить их с общим количеством записей в каждом протоколе. Если эти числа близки, значит отчество есть, а иначе нет. Искать строгое соответствие неразумно, т.к. даже в гонках, где записывают отчества могут принимать участие, например, иностранцы, и их запишут без него. Случается и так, что у участник забыл или не захотел указывать свое отчество. С другой стороны, есть ведь и фамилии оканчивающиеся на «vich», их много в Белоруссии, и других странах с языками славянской группы. К тому же мы сделали транслит. Можно было заняться этим анализом до транслитерации, но тогда есть шанс упустить протокол, в котором есть отчества, но изначально он уже на латинице. Так что все нормально.
Итак, будем искать все протоколы, в которых число фрагментов «vich» и «vna» в колонке name больше 50% от общего числа записей в протоколе.
wp = {} #wp – with patronymic for e in rd: nvich = (''.join(rd[e]['name'])).count('vich') nvna = (''.join(rd[e]['name'])).count('vna') if nvich + nvna > 0.5*len(rd[e]): wp[e] = rd[e]
Таких протоколов 29. Вот один из них:
place
sex
name
country
...
name raw
0
1
M
Yaroslav Stanislavovich Pavlishchev
RUS
...
Ярослав Станиславович Павлищев
1
2
M
Vladimir Vasilevich Perezhigin
RUS
...
Владимир Васильевич Пережигин
2
3
M
Vladislav Evgenevich Litvinchuk
RUS
...
Владислав Евгеньевич Литвинчук
3
4
M
Sergey Gennadevich Gavrilenko
RUS
...
Сергей Геннадьевич Гавриленко
4
5
M
Ivan Markovich Markin
RUS
...
Иван Маркович Маркин
5
6
M
Nikolay Evgenevich Sokolov
RUS
...
Nikolay Evgenevich Sokolov
6
7
M
Aram Pavlovich Kukhtiev
RUS
...
Арам Павлович Кухтиев
7
8
M
Andrey Anatolevich Andreev
RUS
...
Андрей Анатольевич Андреев
8
9
M
Denis Valerevich Bulgakov
RUS
...
Денис Валерьевич Булгаков
9
10
M
Aleksandr Ivanovich Kuts
RUS
...
Александр Иванович Куць
Движемся дальше. Будем обрабатывать только записи с тремя составляющими, то есть те, где есть (предположительно) фамилия, имя, отчество.
sum_n3w = 0 # sum name of 3 words sum_nnot3w = 0 # sum name not of 3 words for e in wp: sum_n3w += len([n for n in wp[e]['name'] if len(n.split()) == 3]) sum_nnot3w += len(wp[e]) - n3w
Таких записей большинство – 86 %. Теперь те, в которых три составляющих разделим на колонки name0, name1, name2:
for e in wp: ind3 = [i for i in rd[e].index if len(rd[e].loc[i,'name'].split()) == 3] rd[e]['name0'] = '' rd[e]['name1'] = '' rd[e]['name2'] = '' rd[e].loc[ind3, 'name0'] = rd[e].loc[ind3,'name'].str.split().str[0] rd[e].loc[ind3, 'name1'] = rd[e].loc[ind3,'name'].str.split().str[1] rd[e].loc[ind3, 'name2'] = rd[e].loc[ind3,'name'].str.split().str[2]
Вот как теперь выглядит один из протоколов:
name
name0
name1
name2
...
name raw
0
Lekomtsev Denis Nikolaevich
Lekomtsev
Denis
Nikolaevich
...
Лекомцев Денис Николаевич
1
Ivanov Andrey Aleksandrovich
Ivanov
Andrey
Aleksandrovich
...
Иванов Андрей Александрович
2
Ivanov Evgeniy Vasilevich
Ivanov
Evgeniy
Vasilevich
...
Иванов Евгений Васильевич
3
Setepov Vladislav
...
Сетепов Владислав
4
Mishanin Sergey Yurevich
Mishanin
Sergey
Yurevich
...
Мишанин Сергей Юрьевич
5
Baranov Andrey Aleksandrovich
Baranov
Andrey
Aleksandrovich
...
Баранов Андрей Александрович
6
Nakaryakov Dmitriy Valerevich
Nakaryakov
Dmitriy
Valerevich
...
Накаряков Дмитрий Валерьевич
7
Tretyakov Dmitriy Valentinovich
Tretyakov
Dmitriy
Valentinovich
...
Третьяков Дмитрий Валентинович
8
Kuznetsov Stanislav Vladimirovich
Kuznetsov
Stanislav
Vladimirovich
...
Кузнецов Станислав Владимирович
9
Dubrovin Maksim Sergeevich
Dubrovin
Maksim
Sergeevich
...
Дубровин Максим Сергеевич
10
Karpov Anatoliy Sergeevich
Karpov
Anatoliy
Sergeevich
...
Карпов Анатолий Сергеевич
for e in wp: n1=(''.join(rd[e]['name1'])).count('vich')+(''.join(rd[e]['name1'])).count('vna') n2=(''.join(rd[e]['name2'])).count('vich')+(''.join(rd[e]['name2'])).count('vna') if (n1 > n2): rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name2'] else: rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name1']
name
name0
name1
name2
new name
name raw
0
Gorik Pavel Vladimirovich
Gorik
Pavel
Vladimirovich
Gorik Pavel
Горик Павел Владимирович
1
Korobov Oleg Anatolevich
Korobov
Oleg
Anatolevich
Korobov Oleg
Коробов Олег Анатольевич
2
Pavlishchev Yaroslav Stanislavovich
Pavlishchev
Yaroslav
Stanislavovich
Pavlishchev Yaroslav
Павлищев Ярослав Станиславович
3
Fedorov Nikolay Nikolaevich
Fedorov
Nikolay
Nikolaevich
Fedorov Nikolay
Фёдоров Николай Николаевич
4
Medvedev Andrey Aleksandrovich
Medvedev
Andrey
Aleksandrovich
Medvedev Andrey
Медведев Андрей Александрович
5
Popov Sergey Eduardovich
Popov
Sergey
Eduardovich
Popov Sergey
Попов Сергей Эдуардович
6
Dumchev Andrey Viktorovich
Dumchev
Andrey
Viktorovich
Dumchev Andrey
Думчев Андрей Викторович
7
Trusov Mikhail Vladimirovich
Trusov
Mikhail
Vladimirovich
Trusov Mikhail
Трусов Михаил Владимирович
8
Demichev Yuriy Anatolevich
Demichev
Yuriy
Anatolevich
Demichev Yuriy
Демичев Юрий Анатольевич
9
Pushkin Boris Sergeevich
Pushkin
Boris
Sergeevich
Pushkin Boris
Пушкин Борис Сергеевич
10
Lando Aleksandr Borisovich
Lando
Aleksandr
Borisovich
Lando Aleksandr
Ландо Александр Борисович
for e in wp: ind = rd[e][rd[e]['new name'].str.strip() != ''].index rd[e].loc[ind, 'name'] = rd[e].loc[ind, 'new name'] rd[e] = rd[e].drop(columns = ['name0','name1','name2','new name'])
place
sex
name
country
...
name raw
0
1
M
Yaroslav Pavlishchev
RUS
...
Ярослав Станиславович Павлищев
1
2
M
Vladimir Perezhigin
RUS
...
Владимир Васильевич Пережигин
2
3
M
Vladislav Litvinchuk
RUS
...
Владислав Евгеньевич Литвинчук
3
4
M
Sergey Gavrilenko
RUS
...
Сергей Геннадьевич Гавриленко
4
5
M
Ivan Markin
RUS
...
Иван Маркович Маркин
5
6
M
Nikolay Sokolov
RUS
...
Nikolay Evgenevich Sokolov
6
7
M
Aram Kukhtiev
RUS
...
Арам Павлович Кухтиев
7
8
M
Andrey Andreev
RUS
...
Андрей Анатольевич Андреев
8
9
M
Denis Bulgakov
RUS
...
Денис Валерьевич Булгаков
9
10
M
Aleksandr Kuts
RUS
...
Александр Иванович Куць
10
11
M
Aleksandr Lando
RUS
...
Александр Борисович Ландо
pkl.dump(rd, open(r'D:\tri\details5.pkl', 'wb'))
Теперь нужно привести имена к одному порядку. То есть нужно чтобы во всех протоколах сначала шло имя потом фамилия, или наоборот – сначала фамилия, потом имя, тоже во всех протоколах. Зависит от того каких больше, сейчас мы это выясним. Ситуация слегка осложняется тем, что полное имя может состоять более чем из двух слов даже после того, как мы убрали отчества.
ar['nwin'] = ar['name'].str.count(' ') + 1 # nwin – number of words in name ar.loc[ar['name'] == '','nwin'] = 0 100*ar['nwin'].value_counts()/len(ar)
Количество слов в имени Количество записей Доля записей (%)
Количество слов в имени
Количество записей
Доля записей (%)
2
1285270
90.74426
3
102220
7.217066
4
22420
1.582925
0
3454
0.243864
5
2385
0.168389
6
469
0.033113
1
80
0.005648
7
57
0.004024
8
5
0.000353
10
4
0.000282
9
1
0.000071
ar[ar['nwin'] >= 3]['country'].value_counts()[:12]
Out:
ESP 28435
MEX 10561
USA 7608
DNK 7178
BRA 6321
NLD 5748
DEU 4310
PHL 3941
ZAF 3862
ITA 3691
BEL 3596
FRA 3323
Что ж, на первом месте это Испания, на втором – Мексика, испаноязычная страна, дальше США, где тоже исторически очень много латиноамериканцев. Бразилия и Филиппины – тоже испанские (и португальские) имена. Дания, Нидерланды, Германия, ЮАР, Италия, Бельгия и Франция – другое дело, там просто иногда идет какая-нибудь приставка к фамилии, поэтому и слов становится больше, чем два. Во всех этих случаях, однако, обычно само имя состоит из одного слова, а фамилия из двух, трех. Конечно, из этого правила есть исключения, но их мы уже не будем обрабатывать. Для начала для каждого протокола нужно определить, какой там все-таки порядок: имя-фамилия или наоборот. Как это сделать? Мне пришла в голову следующая идея: во-первых, разнообразие фамилий обычно гораздо больше, чем разнообразие имен. Так должно даже в рамках одного протокола. Во-вторых, длина имени обычно меньше, чем длина фамилии (даже для несоставных фамилий). Воспользуемся комбинацией этих критериев, чтобы определить предварительный порядок.
Выделим первое и последнее слово в полном имени:
ar['new name'] = ar['name'] ind = ar[ar['nwin'] < 2].index ar.loc[ind, 'new name'] = '. .' # фиктивная запись, чтобы применить str.split() для всей колонки ar['wfin'] = ar['new name'].str.split().str[0] #fwin – first word in name ar['lwin'] = ar['new name'].str.split().str[-1]#lfin – last word in name
Преобразуем объединенный датафрейм ar обратно в словарь rd, для того чтобы новые колонки nwin, ns0, ns попали в датафрейм каждой гонки. Далее определим количество протоколов с порядком “Имя Фамилия” и количество протоколов с обратным порядком согласно нашему критерию. Будем рассматривать только записи, где полное имя состоит из двух слов. Заодно сохраним имя (first name) в новой колонке:
name_surname = {} surname_name = {} for e in rd: d = rd[e][rd[e]['nwin'] == 2] if len(d['fwin'].unique()) < len(d['lwin'].unique()) and len(''.join(d['fwin'])) < len(''.join(d['lwin'])): name_surname[e] = d rd[e]['first name'] = rd[e]['fwin'] if len(d['fwin'].unique()) > len(d['lwin'].unique()) and len(''.join(d['fwin'])) > len(''.join(d['lwin'])): surname_name[e] = d rd[e]['first name'] = rd[e]['lwin']
Получилось следующее: порядок Имя Фамилия – 244 протокола, порядок Фамилия Имя – 1 508 протоколов.
Соответственно будем приводить к тому формату, который встречается чаще. Сумма получилась меньше, чем общее количество, потому что мы проверяли на выполнение двух критериев одновременно, да еще и со строгим неравенством. Остались протоколы, в которых выполняется только один из критериев, или возможно, но маловероятно имеет место равенство. Но это совершенно неважно, так как формат определен.
Теперь, полагая, что мы определили порядок с достаточно высокой точностью, не забывая при этом что не со стопроцентной, воспользуемся этой информацией. Найдем самые популярные имена из колонки first name:
vc = ar['first name'].value_counts()
возьмем те, что встречались более ста раз:
pfn=vc[vc>100] #pfn – popular first names
таких оказалось 1 673. Вот первые сто из них, расположены по убыванию популярности:
['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Patrick', 'Scott', 'Kevin', 'Stefan', 'Jason', 'Eric', 'Christopher', 'Alexander', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Andrea', 'Jonathan', 'Markus', 'Marco', 'Adam', 'Ryan', 'Jan', 'Tom', 'Marc', 'Carlos', 'Jennifer', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Sarah', 'Alex', 'Jose', 'Andrey', 'Benjamin', 'Sebastian', 'Ian', 'Anthony', 'Ben', 'Oliver', 'Antonio', 'Ivan', 'Sean', 'Manuel', 'Matthias', 'Nicolas', 'Dan', 'Craig', 'Dmitriy', 'Laura', 'Luis', 'Lisa', 'Kim', 'Anna', 'Nick', 'Rob', 'Maria', 'Greg', 'Aleksey', 'Javier', 'Michelle', 'Andre', 'Mario', 'Joseph', 'Christoph', 'Justin', 'Jim', 'Gary', 'Erik', 'Andy', 'Joe', 'Alberto', 'Roberto', 'Jens', 'Tobias', 'Lee', 'Nicholas', 'Dave', 'Tony', 'Olivier', 'Philippe']
Теперь, используя это список, будем пробегать по всем протоколам и сравнивать, где больше совпадений – в первом слове из имени или в последнем. Будем рассматривать только имена, состоящие из двух слов. Если совпадений больше с последним словом, значит порядок правильный, если с первым, значит обратный. Причем здесь мы уже более уверены, значит можно использовать эти знания, и к начальному списку популярных имен с каждым проходом будем добавлять список имен их очередного протокола. Предварительно отсортируем протоколы по частоте появления имен из начального списка, чтобы избежать случайных ошибок и подготовить более обширный список к тем протоколам, в которых совпадений мало, и которые будут обрабатываться ближе к концу цикла.
sbpn = pd.DataFrame(columns = ['event', 'num pop names'], index=range(len(rd))) # sbpn - sorted by popular names for i in range(len(rd)): e = list(rd.keys())[i] sbpn.loc[i, 'event'] = e sbpn.loc[i, 'num pop names'] = len(set(pfn).intersection(rd[e]['first name'])) sbnp=sbnp.sort_values(by = 'num pop names',ascending=False) sbnp = sbnp.reset_index(drop=True)
event
num pop names
0
Ironman World Championship 70.3 2016
811
1
Ironman World Championship 2019
781
2
Ironman World Championship 70.3 2015
778
3
Ironman Mallorca 70.3 2014
776
4
Ironman World Championship 2018
766
5
Challenge Roth Long 2019
759
...
...
...
1917
Challenge Gran Canaria Olympic 2019
0
1918
Challenge Gran Canaria Middle 2017
0
1919
Challenge Forte Village-Sardinia Sprint 2017
0
1920
ITU European Cup Kuopio Sprint 2007
0
1921
ITU World Cup Madeira Olympic 2002
0
tofix = [] for i in range(len(rd)): e = sbpn.loc[i, 'event'] if len(set(list(rd[e]['fwin'])).intersection(pfn)) > len(set(list(rd[e]['lwin'])).intersection(pfn)): tofix.append(e) pfn = list(set(pfn + list(rd[e]['fwin']))) else: pfn = list(set(pfn + list(rd[e]['lwin'])))
Нашлось 235 протоколов. То есть примерно столько же, сколько получилось в первом приближении (244). Для уверенности выборочно просмотрел первые три записи из каждого, убедился, что все правильно. Также проверил, что первый этап сортировки дал 36 ложных записей из класса Имя Фамилия и 2 ложный из класса Фамилия Имя. Просмотрел по три первых записи из каждого, действительно, второй этап сработал отлично. Теперь, собственно, осталось исправить те протоколы, где обнаружен неправильный порядок:
for e in tofix: ind = rd[e][rd[e]['nwin'] > 1].index rd[e].loc[ind,'name'] = rd[e].loc[ind,'name'].str.split(n=1).str[1] + ' ' + rd[e].loc[ind,'name'].str.split(n=1).str[0]
Здесь в сплите мы ограничили количество кусков с помощью параметра n. Логика такая: имя – это одно слово, первое в полном имени. Все остальное – фамилия (может состоять из нескольких слов). Просто меняем их местами.
Теперь избавляемся от ненужных колонок и сохраняемся:
for e in rd: rd[e] = rd[e].drop(columns = ['new name', 'first name', 'fwin','lwin', 'nwin']) pkl.dump(rd, open(r'D:\tri\details6.pkl', 'wb'))
Проверяем результат. Случайная десятка исправленных записей:
place
sex
name
country
group
...
name raw
188
189
M
Azhel Dmitriy
BLR
...
Дмитрий Ажель
96
97
M
Bostina Cristian
ROU
...
Cristian Bostina
1757
1758
M
Lowe Jonathan
AUS
M30-34
...
Jonathan LOWE
599
600
M
Baerwald Manuel
DEU
...
Manuel BAERWALD
657
658
M
Krumdieck Ralf
DEU
...
Ralf KRUMDIECK
354
355
F
Knapp Samantha
USA
F30-34
...
Samantha Knapp
375
376
M
Rintalaulaja Mika
FIN
M40-44
...
Mika Rintalaulaja
1304
1305
M
Dee Jim
USA
M50-54
...
Jim DEE
178
179
M
Halibert Greg
FRA
...
GREG HALIBERT
2740
2741
F
Comia Marissa
USA
F45-49
...
Marissa COMIA
Часть 3. Восстановление неполных данных
Теперь перейдем к восстановлению пропущенных данных. А такие есть.
Страна
Начнем со страны. Найдем все записи, в которых не указана страна:
arnc = ar[ar['country'] == ''] #arnc – all records with no country
Их 3 221. Вот случайные 10 из них:
event
place
sex
name
country
group
...
country raw
...
1633
M
Guerrero Pla Angel
M30-34
...
E
...
258
M
Bellm Mathias
M35-39
...
D
...
655
M
Moratto Alessio
M40-44
...
I
...
1317
M
Solari Jean-Jacques
M50-54
...
TAH
...
1311
F
Duranel Isabelle
F40-44
...
F
...
1012
M
Endler Maximilian
M40-44
...
D
...
284
M
Schreiner Jorg
M40-44
...
D
...
14
M
Butturini Jacopo
...
ITU
...
204
M
Lindner Thomas
M40-44
...
D
...
1168
M
Gramke Peter
M45-49
...
D
nnc = arnc['name'].unique() #nnc - names with no country
Уникальных имен среди записей без страны – 3 051. Посмотрим, можно ли сократить это число.
Дело в том, что в триатлоне люди редко ограничиваются лишь одной гонкой, обычно участвуют в соревнованиях периодически, несколько раз за сезон, из года в год, постоянно тренируясь. Поэтому для многих имен в данных наверняка есть больше одной записи. Чтобы восстановить информацию о стране, попробуем найти записи с таким же именем среди тех, в которых страна указана.
arwc = ar[ar['country'] != ''] #arwc – all records with country nwc = arwc['name'].unique() #nwc – names with country tofix = set(nnc).intersection(nwc)
Out: ['Kleber-Schad Ute Cathrin', 'Sellner Peter', 'Pfeiffer Christian', 'Scholl Thomas', 'Petersohn Sandra', 'Marchand Kurt', 'Janneck Britta', 'Angheben Riccardo', 'Thiele Yvonne', 'Kie?Wetter Martin', 'Schymik Gerhard', 'Clark Donald', 'Berod Brigitte', 'Theile Markus', 'Giuliattini Burbui Margherita', 'Wehrum Alexander', 'Kenny Oisin', 'Schwieger Peter', 'Grosse Bianca', 'Schafter Carsten', 'Breck Dirk', 'Mautes Christoph', 'Herrmann Andreas', 'Gilbert Kai', 'Steger Peter', 'Jirouskova Jana', 'Jehrke Michael', 'Valentine David', 'Reis Michael', 'Wanka Michael', 'Schomburg Jonas', 'Giehl Caprice', 'Zinser Carsten', 'Schumann Marcus', 'Magoni Livio', 'Lauden Yann', 'Mayer Dieter', 'Krisa Stefan', 'Haberecht Bernd', 'Schneider Achim', 'Gibanel Curto Antonio', 'Miranda Antonio', 'Juarez Pedro', 'Prelle Gerrit', 'Wuste Kay', 'Bullock Graeme', 'Hahner Martin', 'Kahl Maik', 'Schubnell Frank', 'Hastenteufel Marco', …]
Таких оказалось 2 236, то есть почти три четверти. Теперь для каждого имени из этого списка нужно определить страну по тем записям, где она есть. Но бывает так, что одно и то же имя встречается в нескольких записях и в них разные страны. Это или тезки, или, может быть, человек переехал. Поэтому сначала обработаем те, где все однозначно.
fix = {} for n in tofix: nr = arwc[arwc['name'] == n] if len(nr['country'].unique()) == 1: fix[n] = nr['country'].iloc[0]
Cделал в цикле. Но, честно говоря, отрабатывает долго – примерно три минуты. Если бы записей было на порядок больше, то пришлось бы, наверное, придумывать векторную реализацию. Нашлось 2 013 записей, или 90% от потенциально возможных.
Имена, для которых в разных записях могут встречаться разные страны, возьмем ту страну, которая встречается чаще всего.
if n not in fix: nr = arwc[arwc['name'] == n] vc = nr['country'].value_counts() if vc[0] > vc[1]: fix[n] = vc.index[0]
Таким образом были найдены соответствия для 2 208 имен или 99% от всех потенциально возможных.
{'Kleber-Schad Ute Cathrin': 'DEU', 'Sellner Peter': 'AUT', 'Pfeiffer Christian': 'AUT', 'Scholl Thomas': 'DEU', 'Petersohn Sandra': 'DEU', 'Marchand Kurt': 'BEL', 'Janneck Britta': 'DEU', 'Angheben Riccardo': 'ITA', 'Thiele Yvonne': 'DEU', 'Kie?Wetter Martin': 'DEU', 'Clark Donald': 'GBR', 'Berod Brigitte': 'FRA', 'Theile Markus': 'DEU', 'Giuliattini Burbui Margherita': 'ITA', 'Wehrum Alexander': 'DEU', 'Kenny Oisin': 'IRL', 'Schwieger Peter': 'DEU', 'Schafter Carsten': 'DEU', 'Breck Dirk': 'DEU', 'Mautes Christoph': 'DEU', 'Herrmann Andreas': 'DEU', 'Gilbert Kai': 'DEU', 'Steger Peter': 'AUT', 'Jirouskova Jana': 'CZE', 'Jehrke Michael': 'DEU', 'Wanka Michael': 'DEU', 'Giehl Caprice': 'DEU', 'Zinser Carsten': 'DEU', 'Schumann Marcus': 'DEU', 'Magoni Livio': 'ITA', 'Lauden Yann': 'FRA', 'Mayer Dieter': 'DEU', 'Krisa Stefan': 'DEU', 'Haberecht Bernd': 'DEU', 'Schneider Achim': 'DEU', 'Gibanel Curto Antonio': 'ESP', 'Juarez Pedro': 'ESP', 'Prelle Gerrit': 'DEU', 'Wuste Kay': 'DEU', 'Bullock Graeme': 'GBR', 'Hahner Martin': 'DEU', 'Kahl Maik': 'DEU', 'Schubnell Frank': 'DEU', 'Hastenteufel Marco': 'DEU', 'Tedde Roberto': 'ITA', 'Minervini Domenico': 'ITA', 'Respondek Markus': 'DEU', 'Kramer Arne': 'DEU', 'Schreck Alex': 'DEU', 'Bichler Matthias': 'DEU', …}
Применим эти соответствия:
for n in fix: ind = arnc[arnc['name'] == n].index ar.loc[ind, 'country'] = fix[n]
event
place
sex
name
country
group
...
country raw
...
1633
M
Guerrero Pla Angel
ESP
M30-34
...
E
...
258
M
Bellm Mathias
DEU
M35-39
...
D
...
655
M
Moratto Alessio
ITA
M40-44
...
I
...
1317
M
Solari Jean-Jacques
PYF
M50-54
...
TAH
...
1311
F
Duranel Isabelle
FRA
F40-44
...
F
...
1012
M
Endler Maximilian
DEU
M40-44
...
D
...
284
M
Schreiner Jorg
DEU
M40-44
...
D
...
14
M
Butturini Jacopo
HRV
...
ITU
...
204
M
Lindner Thomas
DEU
M40-44
...
D
...
1168
M
Gramke Peter
DEU
M45-49
...
D
Далее как обычно, переводим объединенный датафрейм ar обратно в словарь rd и сохраняем.
pkl.dump(rd, open(r'D:\tri\details7.pkl', 'wb'))
Пол
Так же, как и в случае со странами есть записи, в которых не указан пол участника.
ar[ar['sex'] == '']
Таких 2 538. Относительно немного, но снова попытаемся сделать еще меньше. Сохраним исходные значения в новой колонке.
ar['sex raw'] =ar['sex']
В отличие от стран, где мы восстанавливали информацию по имени из других протоколов, здесь все немного сложнее. Дело в том, что в данных полно ошибок и существует немало имен (всего 2 101), которые встречаются с пометками обоих полов.
arws = ar[(ar['sex'] != '')&(ar['name'] != '')] #arws – all records with sex snds = arws[arws.duplicated(subset='name',keep=False)]#snds–single name different sex snds = snds.drop_duplicates(subset=['name','sex'], keep = 'first') snds = snds.sort_values(by='name') snds = snds[snds.duplicated(subset = 'name', keep=False)] snds
event
place
sex
name
country
group
...
country raw
group raw
sex raw
...
428
F
Aagaard Ida
NOR
F40-44
...
NOR
F40-44
F
...
718
M
Aagaard Ida
NOR
M40-44
...
NOR
M40-44
M
740
M
Aarekol Tove Aase
NOR
M50-54
...
NOR
M50-54
M
...
520
F
Aarekol Tove Aase
NOR
F50-54
...
NOR
F50-54
F
...
665
F
Aaroy Torunn
NOR
F40-44
...
NOR
F40-44
F
...
1591
M
Aaroy Torunn
NOR
M40-44
...
NOR
M40-44
M
...
70
M
Aberg Cobo Dolores
ARG
FPRO
...
ARG
FPRO
M
...
1258
F
Aberg Cobo Dolores
ARG
F30-34
...
ARG
F30-34
F
...
1909
F
Aboulfaida Zineb
MAR
F35-39
...
MAR
F35-39
F
...
340
M
Aboulfaida Zineb
MAR
M35-39
...
MAR
M35-39
M
...
63
F
Abram Felicity
AUS
FPRO
...
AUS
FPRO
F
...
38
M
Abram Felicity
AUS
FJUNIOR
...
AUS
FJUNIOR
M
...
134
M
Abramowski Jannicke
DEU
FPRO
...
GER
FPRO
M
...
323
F
Abramowski Jannicke
DEU
F25-29
...
GER
F25-29
F
...
21
M
Abrosimova Anastasia
RUS
FPRO
...
RUS
FPRO
M
...
177
F
Abrosimova Anastasia
RUS
FPRO
...
RUS
FPRO
F
...
188
M
Abysova Irina
RUS
FPRO
...
RUS
FPRO
M
...
60
F
Abysova Irina
RUS
FPRO
...
RUS
FPRO
F
...
312
M
Acaron Fabiola
PRI
FJUNIOR
...
PUR
FJUNIOR
M
...
294
F
Acaron Fabiola
PRI
F45-49
...
PUR
F45-49
F
...
1500
M
Achampong Benjamin
GBR
M35-39
...
GBR
M35-39
M
...
749
F
Achampong Benjamin
GBR
M35-39
...
GBR
M35-39
F
rss = [rd[e] for e in rd if len(rd[e][rd[e]['sex'] != '']['sex'].unique()) == 1] #rss – races with single sex
Всего их 633. Казалось бы, это вполне возможно, просто протокол отдельно по женщинам, отдельно по мужчинам. Но дело в том, что почти во всех этих протоколах встречаются возрастные группы обоих полов (мужские возрастные группы начинаются с буквы M, женские – с буквы F). Например:
'ITU World Cup Tiszaujvaros Olympic 2002'
place
sex
name
country
group
...
country raw
group raw
name raw
76
M
Dederko Ewa
POL
FPRO
...
POL
FPRO
Dederko Ewa
84
M
Chenevier Giunia
ITA
FPRO
...
ITA
FPRO
Chenevier Giunia
36
M
O'Grady Graham
NZL
MPRO
...
NZL
MPRO
O'Grady Graham
23
M
Danek Michal
CZE
MPRO
...
CZE
MPRO
Danek Michal
74
M
Peon Carole
FRA
FPRO
...
FRA
FPRO
Peon Carole
48
M
Hechenblaickner Daniel
AUT
MPRO
...
AUT
MPRO
Hechenblaickner Daniel
70
M
Blatchford Liz
GBR
FPRO
...
GBR
FPRO
Blatchford Liz
1
M
Walton Craig
AUS
MPRO
...
AUS
MPRO
Walton Craig
20
M
Hobor Peter
HUN
MPRO
...
HUN
MPRO
Hobor Peter
56
M
Kaldau Szabolcs
HUN
MPRO
...
HUN
MPRO
Kaldau Szabolcs
Ожидается, что название возрастной группы начинается с буквы M для мужчин и с буквы F для женщин. В предыдущих двух примерах, несмотря на ошибки в колонке sex, название группы все еще, вроде бы, верно описывало пол участника. На основании нескольких выборочных примеров, делаем предположение, что группа указана верно, а пол может быть указан ошибочно. Найдем все записи, где первая буква в названии группы не соответствует полу. Будем брать начальное название группы group raw, так как при стандартизации многие записи остались без группы, но нам сейчас нужна только первая буква, так что стандарт не важен. ar['grflc'] = ar['group raw'].str.upper().str[0] #grflc – group raw first letter capital grncs = ar[(ar['grflc'].isin(['M','F']))&(ar['sex']!=ar['grflc'])] #grncs – group raw not consistent with sex
Таких записей 26 161. Немало. Что ж, исправим пол в соответствии с названием возрастной группы:
ar.loc[grncs.index, 'sex'] = grncs['grflc']
Посмотрим на результат:
event
place
sex
name
country
group
...
country raw
group raw
sex raw
grflc
...
59
F
Ueda Ai
JPN
FPRO
...
JPN
FPRO
M
F
...
50
F
Zemanova Lenka
CZE
FPRO
...
CZE
FPRO
M
F
...
83
F
Spearing Kyleigh
USA
FPRO
...
USA
FPRO
M
F
...
63
F
Abysova Irina
RUS
FPRO
...
RUS
FPRO
M
F
...
57
F
Knapp Anja
DEU
FPRO
...
GER
FPRO
M
F
...
68
M
Matthews Andrew
GBR
M30-34
...
GBR
M30-34
F
M
...
46
F
Rappaport Summer
USA
FPRO
...
USA
FPRO
M
F
...
60
F
Reid Aileen
IRL
FPRO
...
IRL
FPRO
M
F
...
142
F
Mcdowall Edwina
GBR
F45-49
...
GBR
F45-49
F
...
141
M
O'Bray Luke
GBR
M30-34
...
GBR
M30-34
M
ar[(ar['sex'] == '')&(ar['name'] != '')]
Оказывается, ровно одна!
event
place
sex
name
country
group
...
country raw
group raw
sex raw
grflc
London Triathlon Olympic 2019
672
Stather Emily
GBR
...
GBR
unknown
U
Что ж, группа действительно не указана, но, судя по всему, это женщина. Эмили – женское имя, к тому же эта участница (или ее тезка) финишировала годом ранее, и в том протоколе пол и группа указаны.
event
place
sex
name
country
group
...
country raw
group raw
sex raw
grflc
Ironman Staffordshire 70.3 2018
1859
F
Stather Emily
GBR
F40-44
...
GBR
F40-44
F
F
Восстановим здесь вручную* и пойдем дальше.
ar.loc[arns.index, 'sex'] = 'F'
Теперь все записи с полом.
*Вообще, так делать, конечно, неправильно – при повторных прогонах если изменится что-то в цепочке до этого, например в конвертации имени, тогда записей без пола может оказаться больше одной, и не все они будут женскими, возникнет ошибка. Поэтому нужно либо вставлять тяжелую логику для поиска участника с таким же именем и с указанием пола в других протоколах, как для восстановления страны, и как-то ее тестировать, либо, чтобы излишне не усложнять, к этой логике добавить проверку, что запись найдена только одна и имя такое-то, иначе выдавать исключение, которое остановит выполнение всего ноутбука, можно будет заметить отклонение от плана и вмешаться.
if len(arns) == 1 and arns['name'].iloc[0] == 'Stather Emily': ar.loc[arns.index, 'sex'] = 'F' else: raise Exception('Different scenario!')
Казалось бы, на этом можно и успокоиться. Но дело в том, что исправления основаны на предположении, что группа указана верно. И это действительно так. Почти всегда. Почти. Все-таки несколько нестыковок были случайно замечены, поэтому попробуем теперь определить их все, ну или как можно больше. Как уже упоминалось, в первом примере насторожило именно то, что пол не соответствовал имени исходя из собственных представлений о мужских и женских именах.
Найдем все имена у мужских и женских записей. Здесь под именем понимается именно имя, а не полное имя, то есть без фамилии, то, что по-английски называется first name.
ar['fn'] = ar['name'].str.split().str[-1] #fn – first name mfn = list(ar[ar['sex'] == 'M']['fn'].unique()) #mfn – male first names
Всего в списке 32 508 мужских имен. Вот 50 самых популярных:
['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Kevin', 'Patrick', 'Scott', 'Stefan', 'Jason', 'Eric', 'Alexander', 'Christopher', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Jonathan', 'Marco', 'Markus', 'Adam', 'Ryan', 'Tom', 'Jan', 'Marc', 'Carlos', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Andrey', 'Benjamin', 'Jose']
ffn = list(ar[ar['sex'] == 'F']['fn'].unique()) #ffn – female first names
Женских меньше – 14 423. Cамые популярные:
['Jennifer', 'Sarah', 'Laura', 'Lisa', 'Anna', 'Michelle', 'Maria', 'Andrea', 'Nicole', 'Jessica', 'Julie', 'Elizabeth', 'Stephanie', 'Karen', 'Christine', 'Amy', 'Rebecca', 'Susan', 'Rachel', 'Anne', 'Heather', 'Kelly', 'Barbara', 'Claudia', 'Amanda', 'Sandra', 'Julia', 'Lauren', 'Melissa', 'Emma', 'Sara', 'Katie', 'Melanie', 'Kim', 'Caroline', 'Erin', 'Kate', 'Linda', 'Mary', 'Alexandra', 'Christina', 'Emily', 'Angela', 'Catherine', 'Claire', 'Elena', 'Patricia', 'Charlotte', 'Megan', 'Daniela']
Хорошо, вроде выглядит логично. Посмотрим есть ли пересечения.
mffn = set(mfn).intersection(ffn) #mffn – male-female first names
Есть. И их 2 811. Посмотрим на них более пристально. Для начала, узнаем сколько записей с этими именами:
armfn = ar[ar['fn'].isin(mffn)] #armfn – all records with male-female names
Их 725 562. То есть половина! Это удивительно! Всего уникальных имен почти 37 000, но у половины записей в общей сложности только 2 800. Посмотрим, что это за имена, какие из них самые популярные. Для этого создадим новый датафрейм, где эти имена будут индексами:
df = pd.DataFrame(armfn['fn'].value_counts()) df = df.rename(columns={'fn':'total'})
Вычислим, сколько мужских и женских записей с каждым из них.
df['M'] = armfn[armfn['sex'] == 'M']['fn'].value_counts() df['F'] = armfn[armfn['sex'] == 'F']['fn'].value_counts()
total
M
F
Michael
20648
20638
10
David
18493
18485
8
Thomas
12746
12740
6
John
11634
11632
2
Daniel
11045
11041
4
Mark
10968
10965
3
Peter
10692
10691
1
Paul
9616
9614
2
Christian
8863
8859
4
Robert
8666
8664
2
...
...
...
...
Посмотрим на женские имена.
df.sort_values(by = 'F', ascending=False)
total
M
F
Jennifer
3652
3
3649
Sarah
3288
4
3284
Laura
2636
3
2633
Lisa
2618
2
2616
Anna
2563
10
2553
Michelle
2373
1
2372
Maria
2555
386
2169
Andrea
4323
2235
2088
Nicole
2025
6
2019
Julie
1938
2
1936
...
...
...
...
На самом деле не стоит забывать, что мы исследуем данные людей из очень разных стран, можно сказать, по всему миру. В разных культурах одно и то же имя может использоваться совершенно по-разному. Вот пример. Karen — одно из популярных женских имен из нашего списка, но с другой стороны есть имя Карéн, которое в транслите будет писаться так же, но носят его исключительно мужчины. К счастью, существует пакет, которых хранит всю эту мировую мудрость. Называется gender-guesser.
Работает он так:
import gender_guesser.detector as gg d = gg.Detector() d.get_gender(u'Oleg')
Out: 'male'
d.get_gender(u'Evgeniya')
Out: 'female'
Все классно. Но если проверить имя Andrea, то он тоже выдает female, что не совсем верно. Правда здесь есть выход. Если взглянуть, на свойство names у детектора, то там становится видно всю неоднозначность.
d.names['Andrea']
Out: {'female': ' 4 4 3 4788 64 579 34 1 7 ',
'mostly_female': '5 6 7 ',
'male': ' 7 '}
Ага, то есть get_gender выдает просто самый вероятный вариант, но на самом деле все может быть гораздо сложнее. Проверим другие имена:
d.names['Maria']
Out: {'female': '686 6 A 85986 A BA 3B98A75457 6 ',
'mostly_female': ' BBC A 678A9 '}
d.names['Oleg']
Out: {'male': ' 6 2 99894737 3 '}
То есть в списке names каждому имени соответствует одна или несколько пар ключ-значение, где ключ – это пол: male, female, mostly_male, mostly_female, andy, а значение – список значений соответствующих стране: 1,2,3 … 9ABC... Страны такие:
d.COUNTRIES
Out: ['great_britain', 'ireland', 'usa', 'italy', 'malta', 'portugal', 'spain', 'france', 'belgium', 'luxembourg', 'the_netherlands', 'east_frisia', 'germany', 'austria', 'swiss', 'iceland', 'denmark', 'norway', 'sweden', 'finland', 'estonia', 'latvia', 'lithuania', 'poland', 'czech_republic', 'slovakia', 'hungary', 'romania', 'bulgaria', 'bosniaand', 'croatia', 'kosovo', 'macedonia', 'montenegro', 'serbia', 'slovenia', 'albania', 'greece', 'russia', 'belarus', 'moldova', 'ukraine', 'armenia', 'azerbaijan', 'georgia', 'the_stans', 'turkey', 'arabia', 'israel', 'china', 'india', 'japan', 'korea', 'vietnam', 'other_countries']
Я до конца не понял, что конкретно обозначают цифро-буквенные значения или их отсутствие в списке. Но это было и не важно, так как я решил ограничиться использованием только тех имен, что имеют однозначное толкование. То есть для которых есть только одна пара ключ-значение и ключ – это либо male, либо female. Для каждого имени из нашего датафрейма, запишем его интерпретацию gender-guesser:
df['sex from gg'] = '' for n in df.index: if n in list(d.names.keys()): options = list(d.names[n].keys()) if len(options) == 1 and options[0] == 'male': df.loc[n, 'sex from gg'] = 'M' if len(options) == 1 and options[0] == 'female': df.loc[n, 'sex from gg'] = 'F'
Получилось 1 150 имен. Вот самые популярные из них, которые уже рассматривались выше:
total
M
F
sex from gg
Michael
20648
20638
10
M
David
18493
18485
8
M
Thomas
12746
12740
6
M
John
11634
11632
2
M
Daniel
11045
11041
4
M
Mark
10968
10965
3
M
Peter
10692
10691
1
M
Paul
9616
9614
2
M
Christian
8863
8859
4
Robert
8666
8664
2
M
total
M
F
sex from gg
Jennifer
3652
3
3649
F
Sarah
3288
4
3284
F
Laura
2636
3
2633
F
Lisa
2618
2
2616
F
Anna
2563
10
2553
F
Michelle
2373
1
2372
F
Maria
2555
386
2169
Andrea
4323
2235
2088
Nicole
2025
6
2019
F
Julie
1938
2
1936
all_names = ar['fn'].unique() male_names = [] female_names = [] for n in all_names: if n in list(d.names.keys()): options = list(d.names[n].keys()) if len(options) == 1: if options[0] == 'male': male_names.append(n) if options[0] == 'female': female_names.append(n)
Найдено 7 091 мужских имен и 5 054 женских. Применяем преобразование:
tofixm = ar[ar['fn'].isin(male_names)] ar.loc[tofixm.index, 'sex'] = 'M' tofixf = ar[ar['fn'].isin(female_names)] ar.loc[tofixf.index, 'sex'] = 'F'
Смотрим результат:
ar[ar['sex']!=ar['sex raw']]
Исправлено 30 352 записи (вместе с исправлением по названию группы). Как обычно, 10 случайных:
event
place
sex
name
country
group
...
country raw
group raw
sex raw
grflc
...
37
F
Pilz Christiane
DEU
FPRO
...
GER
FPRO
M
F
...
92
F
Brault Sarah-Anne
CAN
FPRO
...
CAN
FPRO
M
F
...
96
F
Murphy Susanna
IRL
FPRO
...
IRL
FPRO
M
F
...
105
F
Spoelder Romy
NLD
...
NED
FJUNIOR
M
F
...
424
M
Watson Tom
GBR
M40-44
...
GBR
M40-44
F
M
...
81
F
Morel Charlotte
FRA
...
FRA
FJUNIOR
M
F
...
65
F
Selekhova Olga
RUS
...
RUS
FU23
M
F
...
166
F
Keat Rebekah
AUS
...
AUS
FJUNIOR
M
F
...
119
F
Eim Nina
DEU
...
GER
FQUAL…
M
F
...
73
F
Sukhoruchenkova Evgenia
RUS
FPRO
...
RUS
FPRO
M
F
ar['gfl'] = ar['group'].str[0] gncws = ar[(ar['sex'] != ar['gfl']) & (ar['group']!='')]
4 248 записи. Заменяем первую букву:
ar.loc[gncws.index, 'group'] = ar.loc[gncws.index, 'sex'] + ar.loc[gncws.index, 'group'].str[1:].index, 'sex']
event
place
sex
name
country
group
...
country raw
group raw
sex raw
...
803
F
Kenney Joelle
USA
F35-39
...
USA
M35-39
M
...
1432
M
Holmberg Henriette Gorm
DNK
M45-49
...
DEN
F45-49
F
...
503
M
Tai Oy Leen
MYS
M40-44
...
MAS
F40-44
F
...
236
F
Dissanayake Aruna
LKA
F25-29
...
SRI
M25-29
M
...
1349
F
Delos Reyes Joshua Rafaelle
PHL
F18-24
...
PHI
M18-24
M
...
543
F
Vandekendelaere Janique
BEL
F50-54
...
BEL
M50-54
M
...
1029
M
Provost Shaun
USA
M25-29
...
USA
F25-29
F
...
303
F
Torrens Vadell Macia
ESP
F30-34
...
ESP
M30-34
M
...
1338
F
Suarez Renan
BOL
F35-39
...
BOL
M35-39
M
...
502
F
Everlo Linda
NLD
F30-34
...
NED
M30-34
M
На этом с восстановлением пола все. Удаляем рабочие колонки, переводим в словарь и сохраняемся.
pkl.dump(rd, open(r'D:\tri\details8.pkl', 'wb'))
На этом вообще все, с восстановлением неполных данных.
Обновление сводки
Осталось обновить сводную таблицу уточненными данными по количеству мужчин и женщин, и др.
rs['total raw'] = rs['total'] rs['males raw'] = rs['males'] rs['females raw'] = rs['females'] rs['rus raw'] = rs['rus'] for i in rs.index: e = rs.loc[i,'event'] rs.loc[i,'total'] = len(rd[e]) rs.loc[i,'males'] = len(rd[e][rd[e]['sex'] == 'M']) rs.loc[i,'females'] = len(rd[e][rd[e]['sex'] == 'F']) rs.loc[i,'rus'] = len(rd[e][rd[e]['country'] == 'RUS']) len(rs[rs['total'] != rs['total raw']])
Out: 288
len(rs[rs['males'] != rs['males raw']])
Out:962
len(rs[rs['females'] != rs['females raw']])
Out: 836
len(rs[rs['rus'] != rs['rus raw']])
Out: 8
pkl.dump(rs, open(r'D:\tri\summary6.pkl', 'wb'))
Часть 4. Выборка
Сейчас триатлон очень популярен. За сезон проходит множество открытых соревнований, в которых принимает участие огромное количество атлетов, в основном любителей. Но так было не всегда. В наших данных есть записи начиная с 1990 года. Пролистывая tristats.ru я заметил, что гонок значительно больше в последние годы, и очень мало в первые. Но теперь, когда наши данные подготовлены, можно посмотреть на это более внимательно.
Десятилетний период
Подсчитаем количество гонок и финишеров в каждом году:
rs['year'] = pd.DatetimeIndex(rs['date']).year years = range(rs['year'].min(),rs['year'].max()) rsy = pd.DataFrame(columns = ['races', 'finishers', 'rus', 'RUS'], index = years) #rsy – races summary by year for y in rsy.index: rsy.loc[y,'races'] = len(rs[rs['year'] == y]) rsy.loc[y,'finishers'] = sum(rs[rs['year'] == y]['total']) rsy.loc[y,'rus'] = sum(rs[rs['year'] == y]['rus']) rsy.loc[y,'RUS'] = len(rs[(rs['year'] == y)&(rs['country'] == 'RUS')])
year
races
finishers
rus
RUS
1990
1
286
5
0
1991
0
0
0
0
1992
1
317
3
0
1993
2
887
3
0
1994
2
128
3
0
1995
3
731
7
0
1996
3
776
6
0
1997
3
403
11
0
1998
4
583
21
0
1999
10
1106
26
0
2000
10
1231
29
0
2001
11
1992
32
0
2002
21
2249
100
0
2003
30
3152
158
0
2004
19
5488
128
1
2005
16
3024
244
1
2006
29
6210
369
1
2007
44
12153
444
1
2008
43
13830
369
1
2009
49
27047
478
1
2010
47
26528
366
1
2011
77
45412
848
5
2012
96
75590
1055
4
2013
98
86617
2165
9
2014
135
138018
3188
11
2015
164
172375
4846
15
2016
192
178630
7541
27
2017
238
185473
8825
42
2018
278
203031
10954
54
2019
293
220901
13354
59
Вот как это выглядит на графике:
Видно, что количества гонок и участников в начале периода и в конце просто несоизмеримы. Значительное увеличение общего числа гонок начинается с 2011 года, тогда же возрастает и количество стартов в России. При этом рост количества участников можно наблюдать еще в 2009 году. Это может говорить о возросшем интересе среди участников, то есть возросшем спросе, за которым спустя два года возросло предложение, то есть количество стартов. Однако не стоит забывать, что данные могут быть не полными и какие-то, а возможно и многие гонки в них отсутствуют. В том числе из-за того, что проект по сбору этих данных начался только в 2010 году, что тоже может объяснять значительный скачок на графике именно в этот момент. В том числе поэтому, для дальнейшего анализа я решил взять последние 10 лет. Это достаточно длинный период, для того чтобы отследить какие-то тренды за несколько лет, при этом достаточно короткий чтобы туда не попали, в основном, профессиональные соревнования из 90-х и начала 2000-х.
rs = rs[(rs['year']>=2010)&(rs['year']<= 2019)]

В выбранный период, кстати, попало 84% гонок и 94% финишеров.
Любительские старты
Итак, подавляющее большинство участников выбранных стартов — это атлеты-любители, поэтому хорошую статистику можно получить именно по ним. Честно говоря, это и представляло основной интерес для меня, так как сам участвую в таких стартах, но по уровню очень далек от олимпийских чемпионов. Однако, профессиональные соревнования очевидно тоже проходили и в выбранный период. Чтобы не смешивать показатели по любительским и профессиональным гонкам, было решено убрать из рассмотрения последние. Как их определить? По скоростям. Вычислим их. На одном из начальных этапов подготовки данных мы уже определили какой тип дистанции был на каждой гонке – спринт, олимпийская, половинка, железная. Для каждой из них четко определен километраж этапов – плавательного, вело и бегового. Это 0.75+20+5 для спринта, 1.5+40+10 для олимпийской, 1.9+90+21.1 для половинки и 3.8+180+42.2 для железной. Конечно, по факту, для любого типа реальные цифры могут разниться от гонки к гонке условно до одного процента, но информации об этом нету, так что будем считать, что все было точно.
rs['km'] = '' rs.loc[rs['dist'] == 'sprint', 'km'] = 0.75+20+5 rs.loc[rs['dist'] == 'olympic', 'km'] = 1.5+40+10 rs.loc[rs['dist'] == 'half', 'km'] = 1.9+90+21.1 rs.loc[rs['dist'] == 'full', 'km'] = 3.8+180+42.2
Вычислим среднюю и максимальную скорости на каждой гонке. Под максимальной здесь понимается средняя скорость атлета, занявшего первое место.
for index, row in rs.iterrows(): e = row['event'] rd[e]['th'] = pd.TimedeltaIndex(rd[e]['result']).seconds/3600 rd[e]['v'] = rs.loc[i, 'km'] / rd[e]['th'] for index, row in rs.iterrows(): e = row['event'] rs.loc[index,'vmax'] = rd[e]['v'].max() rs.loc[index,'vavg'] = rd[e]['v'].mean()

Что ж, можно видеть, что основная масса скоростей собрались кучно примерно между 15 км/ч и 30 км/ч, но есть определенное количество совершенно «космических» значений. Отсортируем по средней скорости и посмотрим, сколько их:
rs = rs.sort_values(by='vavg')

Здесь мы изменили шкалу и можно оценить диапазон более точно. Для средних скоростей это примерно от 17 км/ч до 27 км/ч, для максимальных – от 18 км/ч до 32 км/ч. Плюс есть «хвосты» с очень низкими и очень высокими средними скоростями. Низкие скорости скорее всего соответствуют экстремальным соревнованиям типа Norseman, а высокие могут быть в случае с отмененным плаванием, где вместо спринта был суперспринт, или просто ошибочные данные. Еще один важный момент – плавная ступенька в районе 1200 по оси Х, и более высокие значения средней скорости после нее. Там же можно видеть значительно меньшую разницу между средними и максимальным скоростями, чем в первых двух третях графика. Судя по всему, это профессиональные соревнования. Чтобы выделить их более явно, вычислим отношение максимальной скорости к средней. На профессиональных соревнованиях, где нет случайных людей и у всех участников очень высокий уровень физической подготовки, это соотношение должно быть минимальным.
rs['vmdbva'] = rs['vmax']/rs['vavg'] #vmdbva - v max divided by v avg rs = rs.sort_values(by='vmdbva')
На этом графике первая четверть выделяется очень четко: отношение максимальной скорости к средней небольшое, высокая средняя скорость, малое количество участников. Это профессиональные соревнования. Ступенька на зеленой кривой находится где-то в районе 1.2. Оставим в нашей выборке только записи со значением отношения больше 1.2.
rs = rs[rs['vmdbva'] > 1.2]
Так же уберем записи со нетипичными низкими и высокими скоростями. В статье What are the triathlon “world records” for each distance? опубликованы рекордные времена прохождения разных дистанций на 2019 год. Если пересчитать их на средние скорости, то можно увидеть, что она не может быть выше 33 км/ч даже у самых быстрых. Так что будем считать протоколы, где средние скорости получаются выше, невалидными и уберем их из рассмотрения.
rs = rs[(rs['vavg'] > 17)&(rs['vmax'] < 33)]
Вот, что осталось:


Теперь все выглядит достаточно однородно и не вызывает вопросов. В результате всего этого отбора мы потеряли 777 из 1922 протоколов, или 40%. При этом общее количество финишеров сократилось не так сильно – всего на 13%.
Итак, осталось 1 145 гонок с 1 231 772 финишерами. Эта выборка и стала материалом для моего анализа и визуализации.
Часть 5. Анализ и визуализация
В этой работе собственно анализ и визуализация были самыми простыми частями. Верхушкой айсберга, подводной частью которого была как раз подготовка данных. Анализ, по сути, представлял собой простые арифметические операции над pandas Series, вычисление средних, фильтрацию – все это делается элементарными средствами pandas и в приведенном выше коде полно примеров. Визуализация в свою очередь, в основном делалась с помощью наистандартнейшего matplotlib. Использовались plot, bar, pie. Кое-где, правда, пришлось повозиться с подписями осей, в случае дат и пиктограмм, но это не то, чтобы тянет на развернутое описание здесь. Единственное, про что, наверное, стоит рассказать, это представление геоданных. Как минимум, это не matplotlib.
Геоданные
По каждой гонке у нас есть информация о месте ее проведения. В самом начале с помощью geopy мы вычислили координаты для каждой локации. Многие гонки проводятся ежегодно в одном и том же месте.
event
date
country
latitude
longitude
loc
…
0
Ironman Indian Wells La Quinta 70.3 2019
2019-12-08
USA
33.7238
-116.305
Indian Wells/La Quinta, California, USA
…
1
Ironman Taupo 70.3 2019
2019-12-07
NZL
-41.5001
172.834
New Zealand
…
2
Ironman Western Australia 2019
2019-12-01
AUS
-33.6445
115.349
Busselton, Western Australia
…
3
Ironman Mar del Plata 2019
2019-12-01
ARG
-37.9977
-57.5483
Mar del Plata, Argentina
…
4
Ironman Cozumel 2019
2019-11-24
MEX
20.4318
-86.9203
Cozumel, Mexico
…
5
Ironman Arizona 2019
2019-11-24
USA
33.4255
-111.94
Tempe, Arizona, USA
…
6
Ironman Xiamen 70.3 2019
2019-11-10
CHN
24.4758
118.075
Xiamen, China
…
7
Ironman Turkey 70.3 2019
2019-11-03
TUR
36.8633
31.0578
Belek, Antalya, Turkey
…
8
Ironman Florida 2019
2019-11-02
USA
30.1766
-85.8055
Panama City Beach, Florida, USA
…
9
Ironman Marrakech 70.3 2019
2019-10-27
MAR
31.6258
-7.98916
Marrakech, Morocco
…
10
Ironman Waco 70.3 2019
2019-10-27
USA
31.5493
-97.1467
Waco, Texas, USA
…
Очень удобный инструмент для визуализации геоданных в python – это folium. Вот как он работает:
import folium m = folium.Map() folium.Marker(['55.7522200', '37.6155600'], popup='Москва').add_to(m)
И получаем интерактивную карту прямо в юпитер ноутбуке.
Теперь, к нашим данным. Для начала заведем новую колонку из комбинации наших координат:
rs['coords'] = rs['latitude'].astype(str) + ', ' + rs['longitude'].astype(str)
Уникальных координат coords получается 291. А уникальных локаций loc – 324, значит какие-то названия немного различаются, при этом соответствуют одной и той же точке. Это не страшно, мы будем считать уникальность по coords. Подсчитаем сколько событий прошло за все время в каждой локации (с уникальными координатами):
vc = rs['coords'].value_counts() vc
Out:
43.7009358, 7.2683912 22
43.5854823, 39.723109 20
29.03970805, -13.636291 16
47.3723941, 8.5423328 16
59.3110918, 24.420907 15
51.0834196, 10.4234469 15
54.7585694, 38.8818137 14
20.4317585, -86.9202745 13
52.3727598, 4.8936041 12
41.6132925, 2.6576102 12
... ...
Теперь создадим карту, и добавим на нее маркеры в виде кругов, радиус которых будет зависеть от количества проведенных на локации событий. К маркерам добавим всплывающие таблички с названием локации.
m = folium.Map(location=[25,10], zoom_start=2) for c in rs['coords'].unique(): row = [r[1] for r in rs.iterrows() if r[1]['coords'] == c][0] folium.Circle([row['latitude'], row['longitude']], popup=(row['location']+'\n('+str(vc[c])+' races)'), radius = 10000*int(vc[c]), color='darkorange', fill=True, stroke=True, weight=1).add_to(m)
Готово. Можно посмотреть результат:

Прогресс участников
На самом деле, помимо геданных работа над еще одним графиком тоже была нетривиальной. Это график прогресса участников, самый последний. Вот он:
Разберем его, заодно приведу код для отрисовки, как пример использования matplotlib:
fig = plt.figure() fig.set_size_inches(10, 6) ax = fig.add_axes([0,0,1,1]) b = ax.bar(exp,numrecs, color = 'navajowhite') ax1 = ax.twinx() for i in range(len(exp_samp)): ax1.plot(exp_samp[i], vproc_samp[i], '.') p, = ax1.plot(exp, vpm, 'o-',markersize=8, linewidth=2, color='C0') for i in range(len(exp)): if i < len(exp)-1 and (vpm[i] < vpm[i+1]): ax1.text(x = exp[i]+0.1, y = vpm[i]-0.2, s = '{0:3.1f}%'.format(vpm[i]),size=12) else: ax1.text(x = exp[i]+0.1, y = vpm[i]+0.1, s = '{0:3.1f}%'.format(vpm[i]),size=12) ax.legend((b,p), ('Количество данных', 'Скорость'),loc='center right') ax.set_xlabel('Соревновательный опыт в годах') ax.set_ylabel('Записи') ax1.set_ylabel('% от средней скорости на гонке') ax.set_xticks(np.arange(1, 11, step=1)) ax.set_yticks(np.arange(0, 230000, step=25000)) ax1.set_ylim(97.5,103.5) ax.yaxis.set_label_position("right") ax.yaxis.tick_right() ax1.yaxis.set_label_position("left") ax1.yaxis.tick_left() plt.show()
Теперь о том, как вычислялись данные для него. Для начала нужно было выбрать имена участников, которые финишировали хотя бы в двух гонках, причем в разных календарных годах, и при этом не являются профессионалами.
Сперва для каждого протокола заполним новую колонку date, где будет указана дата гонки. Так же нам понадобится год из этой даты, сделаем колонку year. Так как мы собираемся анализировать скорость каждого атлета относительно средней скорости на гонке, сразу вычислим эту скорость в новой колонке vproc – скорость в процентах от средней.
for index, row in rs.iterrows(): e = row['event'] rd[e]['date'] = row['date'] rd[e]['year'] = row['year'] rd[e]['vproc'] = 100 * rd[e]['v'] / rd[e]['v'].mean()
Вот, как теперь выглядят протоколы:
'Чемпионат самарской области Sprint 2019'
place
sex
name
country
...
th
v
date
year
vproc
0
1
M
Shalev Aleksey
RUS
...
1.161944
22.161128
2019-09-14
2019
130.666668
1
2
M
Nikolaev Artem
RUS
...
1.228611
20.958625
2019-09-14
2019
123.576458
2
3
M
Kuchierskiy Aleksandr
RUS
...
1.255556
20.508850
2019-09-14
2019
120.924485
3
4
F
Korchagina Mariya
RUS
...
1.297222
19.850107
2019-09-14
2019
117.040401
4
5
M
Solodov Ivan
RUS
...
1.298056
19.837364
2019-09-14
2019
116.965263
5
6
M
Bukin Sergey
RUS
...
1.300278
19.803461
2019-09-14
2019
116.765365
6
7
M
Lavrentev Dmitriy
RUS
...
1.300278
19.803461
2019-09-14
2019
116.765365
7
8
M
Dolgov Petr
RUS
...
1.321667
19.482976
2019-09-14
2019
114.875719
8
9
M
Bezruchenko Mikhailn
RUS
...
1.345000
19.144981
2019-09-14
2019
112.882832
9
10
M
Ryazantsev Dmitriy
RUS
...
1.359444
18.941561
2019-09-14
2019
111.683423
10
11
M
Ibragimov Ramil
RUS
...
1.376389
18.708375
2019-09-14
2019
110.308511
Далее объединим все протоколы в один датафрейм.
ar = pd.concat(rd)
Для каждого участника оставим только одну запись в каждом календарном году:
ar1 = ar.drop_duplicates(subset = ['name','year'], keep='first')
Далее из всех уникальных имен этих записей найдем те, которые встречаются минимум дважды:
nvc = ar1['name'].value_counts() names = list(nvc[nvc > 1].index)
таких 219 890. Удалим из этого списка имена про-атлетов:
pro_names = ar[ar['group'].isin(['MPRO','FPRO'])]['name'].unique() names = list(set(names) - set(pro_names))
А также имена атлетов, начавших выступать до 2010 года. Для этого загрузим данные, которые были сохранены до того, как мы произвели выборку за последние 10 лет. Поместим их в объекты rsa (races summary all) и rda (race details all).
rdo = {} for e in rda: if rsa[rsa['event'] == e]['year'].iloc[0] < 2010: rdo[e] = rda[e] aro = pd.concat(rdo) old_names = aro['name'].unique() names = list(set(names) - set(old_names))
И напоследок найдем имена, которые встречаются более одного раза в один и тот же день. Таким образом минимизируем присутствие полных тезок в нашей выборке.
namesakes = ar[ar.duplicated(subset = ['name','date'], keep = False)]['name'].unique() names = list(set(names) - set(namesakes))
Итак, осталось 198 075 имен. Из всего датасета выделяем только записи с найденными именами:
ars = ar[ar['name'].isin(names)] #ars – all recоrds selected
Теперь для каждой записи нужно определить какому году в карьере атлета она соответствует – первому, второму, третьему, или десятому. Делаем цикл по всем именам и вычисляем.
ars['exp'] = '' #exp – experience, counted in years of racing, starts from 1. for n in names: ind = ars[ars['name'] == n].index yos = ars.loc[ind, 'year'].min() #yos – year of start ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1
Вот пример того, что получилось:
event
place
sex
name
country
group
…
th
v
date
year
vproc
exp
…
633
M
Golovin Sergey
RUS
M40-44
…
5.356111
21.097397
2014-08-31
2014
106.036879
1
…
302
M
Golovin Sergey
RUS
M40-44
…
11.236389
20.113223
2015-08-30
2015
108.231254
2
…
522
M
Golovin Sergey
RUS
M40-44
…
10.402778
21.724967
2016-07-17
2016
111.265107
3
…
25
M
Golovin Sergey
RUS
M40-44
…
10.910833
20.713358
2017-09-23
2017
112.953644
4
…
23
M
Golovin Sergey
RUS
M40-44
…
4.700000
24.042553
2017-06-03
2017
120.565211
4
…
42
M
Golovin Sergey
RUS
M40-44
…
4.599167
24.569668
2018-06-17
2018
124.579862
5
…
90
M
Golovin Sergey
NOR
…
14.069167
16.063496
2018-08-04
2018
100.001834
5
…
86
M
Golovin Sergey
RUS
M45-49
…
9.820556
23.012955
2019-08-03
2019
118.375766
6
Судя по всему, тезки все-таки остались. Это ожидаемо, но не страшно, так как мы будем все усреднять, а их должно быть не так много. Далее строим массивы для графика:
exp = [] vpm = [] #vpm – v proc mean numrecs = [] #number of records for x in range(ars['exp'].min(), ars['exp'].max() + 1): exp.append(x) vpm.append(ars[ars['exp'] == x]['vproc'].mean()) numrecs.append(len(ars[ars['exp'] == x]))
Все, основа есть:

Теперь чтобы украсить его точками, соответсвующими конкретным результатам, выберем 1000 случайных имен и построим массивы с результатами для них.
names_samp = random.sample(names,1000) ars_samp = ars[ars['name'].isin(names_samp)] ars_samp = ars_samp.reset_index(drop = True) exp_samp = [] vproc_samp = [] for n in names_samp: nr = ars_samp[ars_samp['name'] == n] nr = nr.sort_values('exp') exp_samp.append(list(nr['exp'])) vproc_samp.append(list(nr['vproc']))
Добавляем цикл для построения графиков из этой случайной выборки.
for i in range(len(exp_samp)): ax1.plot(exp_samp[i], vproc_samp[i], '.')
Теперь все готово:

В целом, несложно. Но есть одна проблема. Для вычисления опыта exp в цикле всем именам, которых почти 200 тысяч, требуется восемь часов. Приходилось отлаживать алгоритм на небольших выборках, а потом запускать расчет на ночь. В принципе один раз так можно сделать, но, если обнаруживается какая-то ошибка или, что-то хочется поменять, и нужно пересчитать заново, это начинает напрягать. И вот, когда я уже вечером собирался опубликовать отчет, выяснилось, что снова надо пересчитать все заново. Ждать до утра не входило в мои планы, и я стал искать способ сделать расчет быстрее. Решил распараллелить.
Нашел где-то способ сделать это с помощью multiprocessing. Для того чтобы работало на Windows, нужны было основную логику каждой параллельной задачи поместить в отдельный workers.py файл:
import pickle as pkl def worker(args): names = args[0] ars=args[1] num=args[2] ars = ars.sort_values(by='name') ars = ars.reset_index(drop=True) for n in names: ind = ars[ars['name'] == n].index yos = ars.loc[ind, 'year'].min() ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1 with open(r'D:\tri\par\prog' + str(num) + '.pkl', 'wb') as f: pkl.dump(ars,f)
В процедуру передается порция имен names, часть датафрейма ar только с этими именами, и порядковый номер параллельной задачи — num. Вычисления записываются в датафрейм и, в конце, датафрейм записывается в файл. В ноутбуке, который вызывает это worker, соответственно, подготавливаем аргументы:
num_proc = 8 #number of processors args = [] for i in range(num_proc): step = int(len(names_samp)/num_proc) + 1 names_i = names_samp[i*step:min((i+1)*step, len(names_samp))] ars_i = ars[ars['name'].isin(names_i)] args.append([names_i, ars_i, i])
Запускаем параллельные вычисления:
from multiprocessing import Pool import workers if __name__ == '__main__': p=Pool(processes = num_proc) p.map(workers.worker,args)
И по окончании считываем результаты из файлов и собираем кусочки обратно в целый датафрейм:
ars=pd.DataFrame(columns = ars.columns) for i in range(num_proc): with open(r'D:\tri\par\prog'+str(i)+'.pkl', 'rb') as f: arsi = pkl.load(f) print(len(arsi)) ars = pd.concat([ars, arsi])
Таким образом удалось получить ускорение в 40 раз, и вместо 8 часов завершить расчет за 11 минут и опубликовать отчет тем же вечером. Заодно узнал, как распараллеливать на python, думаю еще пригодится. Здесь ускорение оказалось еще больше, чем просто в 8 раз по количеству ядер, за счет того, что в каждой задаче использовался маленький датафрейм, по которому поиск быстрее. В принципе таким образом можно было ускорить и последовательные вычисления, но вопрос — как до этого догадаться?
Однако, я не мог успокоиться и даже после публикации постоянно думал о том, как сделать расчет, используя векторизацию, то есть операции над целым колонками датафрейма pandas Series. Такие вычисления на порядок быстрее любых распараллеленных циклов, хоть на суперкластере. И придумал. Оказывается, чтобы для каждого имени найти год начала карьеры, нужно наоборот – для каждого года найти участников, которые в нем начинали. Для этого нужно сначала определить все имена для первого года из нашей выборки, это 2010. Соответственно все записи с этими именами обрабатываем, применяя этот год. Далее берем следующий год – 2011.
Опять находим все имена с записями в этом году, но берем из них только необработанные, то есть те, которые не встречались в 2010 и обрабатываем, их применяя 2011 год. И так далее все остальные года. Тоже цикл, но уже не двести тысяч итераций, а всего девять.
for y in range(ars['year'].min(),ars['year'].max()): arsynp = ars[(ars['exp'] == '') & (ars['year'] == y)] #arsynp - all records selected for year not processed namesy = arsynp['name'].unique() ind = ars[ars['name'].isin(namesy)].index ars.loc[ind, 'exp'] = ars.loc[ind,'year'] - y + 1
Этот цикл отрабатывает буквально за пару секунд. Да и код получился гораздо лаконичнее.
Заключение
Ну вот, наконец-то, большая работа завершена. Для меня это был, по сути, первый проект такого рода. Когда я брался за него, основной целью было поупражняться в использовании питона и его библиотек. Эта задача выполнена с лихвой. Да и сами результаты получились вполне презентабельные. Какие выводы я сделал для себя по завершении?
Первое: Данные неидеальны. Это, наверное, справедливо практически для любой задачи по анализу. Даже если они вполне структурированы, а ведь часто бывает и по-другому, нужно быть готовым повозиться с ними, перед тем как приступить вычислению характеристик и к поиску трендов – найти ошибки, выбросы, отклонения от стандартов и т. д.
Второе: Любая задача имеет решение. Это больше похоже на лозунг, но часто так и есть. Просто это решение может быть не таким очевидным и кроется не в самих данных, а так сказать, outside of the box. Как пример – обработка имен участников, описанная выше, или скраппинг сайта.
Третье: Знание предметной области исключительно важно. Это позволит более качественно подготовить данные, убрав заведомо невалидные или нестандартные, избежать ошибок при интерпретации, задействовать информацию, отсутствующую в данных, например, дистанции в этом проекте, представить результаты в виде, принятом в сообществе, при этом избежать глупых, неверных выводов.
Четвертое: Для работы в python существует богатейший набор инструментов. Иногда кажется, что стоит о чем-то подумать, начинаешь искать – оно уже есть. Это просто здорово! Огромная благодарность создателям за этот вклад, в особенности за инструменты, которые пригодились мне здесь: это selenium для скраппинга, pycountry для определения кода страны по стандарту ISO, country codes (datahub) – для олимпийских кодов, geopy – для определения координат по адресу, folium – для визуализации геоданных, gender-guesser – для анализа имен, multiprocessing – для параллельных вычислений, matplotlib, numpy, и конечно pandas – без него вообще никуда.
Пятое: Векторизация – наше все. Крайне важно уметь пользоваться встроенными средствами pandas, это очень эффективно. Полагаю, в большинстве случаев, когда количество записей измеряется начиная с десятков тысяч, этот навык становится просто необходимым.
Шестое: обрабатывать данные вручную – плохая идея. Нужно стараться минимизировать любое ручное вмешательство – во-первых, это не масштабируется, то есть при увеличении количества данных в несколько раз время на обработку вручную увеличится до неприемлемых значений, во-вторых, будет плохая повторяемость – что-то забудешь, где-то ошибешься. Все только программно, если, что-то при этом выпадает из общего стандарта для программного решения, ну ничего страшного, можно пожертвовать какой-то частью данных, плюсов все равно будет больше.
Седьмое: Код нужно содержать в рабочем состоянии. Казалось бы, что может быть очевиднее! На самом деле, если речь идет о коде для собственного использования, целью которого является публикация результатов работы этого кода, тут все не так строго. Я работал в Юпитер Ноутбуках, а это среда, на мой взгляд, как раз не располагает к созданию цельных программных продуктов. Она настроена на построчный, покусочный запуск, в этом есть свои плюсы – это быстро: разработка, отладка и исполнение одновременно. Но часто слишком велик соблазн просто отредактировать какую-нибудь строку и быстро получить новый результат, вместо того чтобы сделать дубликат или обернуть в def. Конечно, такого соблазна нужно избегать. К хорошему коду, даже “для себя”, надо стремиться, как минимум потому, что даже для одной работы по анализу запуск делается множество раз, и вложения времени вначале, обязательно окупятся в дальнейшем. А еще можно добавлять тесты, даже в ноутбуках, в виде проверок критических параметров и выбрасывания исключений – очень полезно.
Восьмое: Сохраняться чаще. На каждом шаге я сохранял новую версию файла. Всего их получилось порядка 10. Это удобно, так как при обнаружении ошибки помогает быстрее определить на каком этапе она возникла. Плюс я сохранял исходные данные в колонках с пометкой raw — это позволяет очень быстро проверять результат и видеть расхождение.
Девятое: Нужно соизмерять вложения времени и результат. Местами я очень долго возился над восстановлением данных, которые образуют доли процента от общего количества. По сути, в этом не было никакого смысла, нужно было просто выкинуть их, и все. И я бы так и сделал, будь это коммерческий проект, а не аутотренинг. Это позволило бы получить результат гораздо быстрее. Здесь работает принцип Парето – 80% результата достигается за 20% времени.
И последнее: работа над подобными проектами очень здорово расширяет кругозор. Волей-неволей узнаешь, что-то новое – например, названия диковинных стран — типа островов Питкэрн, то, что по стандарту ISO код Швейцарии – CHE, от латинского “Confoederatio Helvetica”, что такое испанское имя, ну и собственно о самом триатлоне – рекорды, их обладатели, места гонок, история событий и так далее.
Пожалуй, достаточно. На этом все. Спасибо всем, кто дочитал до конца!

