На сегодня среди множества алгоритмов машинного обучения широкое применение получили нейронные сети (НС). Основное преимущество НС перед другими методами машинного обучения состоит в том, что они могут выявить достаточно глубокие, часто неочевидные закономерности в данных. Классической парадигмой среди НС являются полносвязные сети с обратным распространением ошибки.
У полносвязных НС с обратным распространением ошибки имеется много преимуществ, главным среди которых является достаточно высокая точность классификации исходных данных, основанная на «сильном» математическом аппарате, лежащем в основе их функционирования. Но, с другой стороны, есть и недостатки, самым значительным среди которых является склонность к переобучению, когда НС подстраивается под локальные особенности обучающей выборки и утрачивает обобщающую способность. Это снижает эффективность и целесообразность их использования в качестве средства классификации или прогнозирования вне обучающей выборки на произвольных данных.
В данной статье к рассмотрению предлагается вариант полносвязных бинарных НС (в качестве целевого значения сети выступают бинарные переменные) с логической функцией на выходе, в которых отсутствует механизм обратного распространения ошибки. На этапе обучения при формировании весовых коэффициентов нейронов вместо их многократных итерационных расчётов, производимых для каждого обучающего образца, осуществляется однократный случайный выбор коэффициентов, что значительно сокращает время на обучение. Другим фундаментальным преимуществом данного подхода является отсутствие проблемы с переобучением сети.
На рис. приведена структурная схема бинарной случайной логической нейронной сети.

Бинарная случайная НС структурно состоит из трёх последовательных слоёв, пронумерованных по мере прохождения информации от входа к выходу:
- Входной слой: нелинейное преобразование;
- Скрытый слой: случайные нейроны;
- Выходной слой: минимальная ДНФ логическая функция.
Далее производится подробное рассмотрение указанных слоёв.
В первом слое входные данные перед обработкой их нейронами проходят через преобразование, выравнивающее плотность распределения вероятности их значений к равномерному распределению в диапазоне от 0 до 1. Выравнивание производится с помощью применения к каждой переменной входного вектора определённой нелинейной функции, которая выбирается согласно следующей теореме о функции распределения вероятности случайной величины, доказываемой в математической статистике.
Теорема: если случайная величина Х имеет плотность распределения вероятностей f(х), то распределение случайной величины s=F(x) является равномерным в интервале (0,1), где под F(x) понимается функция распределения вероятностей случайной величины Х, т. е. f(х)=dF(x)/dx.

Следовательно, после нелинейного преобразования входной вектор X будет преобразован в вектор S, у которого каждая из его составляющих будет иметь единичный диапазон (0,1) значений с равномерной плотностью распределения вероятностей в нём. Таким образом, исходные вектора X, которые являются точками в некотором N-мерном пространстве, будут переведены в другое N-мерное пространство, где они будут равномерно рассредоточены по всему объёму N-мерного единичного куба, располагающегося в начале координат. Ниже дано изображение для двумерного случая с двумя кластерами точек, разделённых чёткой границей, соответствующих двум разным логическим состояниям.
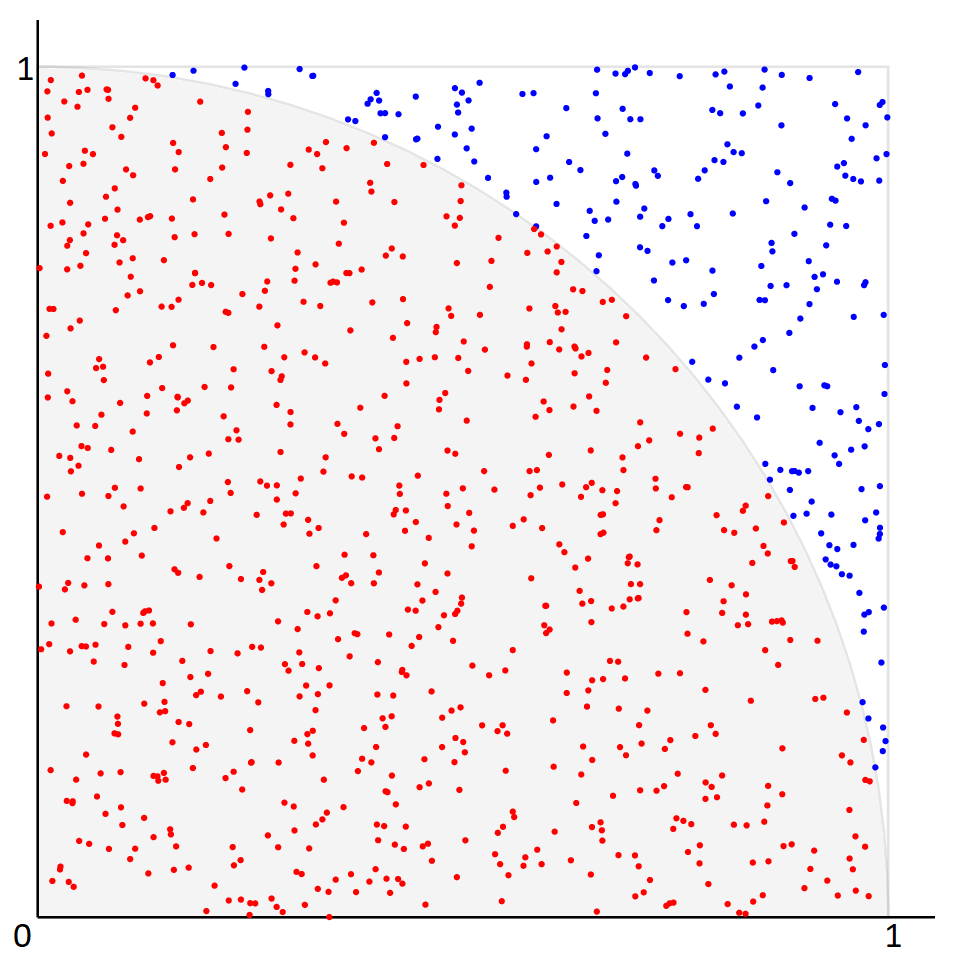
В зависимости от задачи, может быть, одна общая функция F(x) или отдельная под каждую переменную Xi (i=1,2,…,N) входного вектора данных. Тогда в процессе обучения НС для каждой компоненты входных векторов необходимо сформировать своё распределение Fi(x), которое является нелинейной функцией преобразования для соответствующего i-го элемента входных данных. В предложенной ниже реализации производится расчёт функции распределения отдельно для каждой переменной входных векторов. Однако на практике в ряде случае в качестве общей функции достаточно будет даже использовать широко известные сигмоидные функции, например логистическую:
В этом случае, при обучении НС не требуется нахождение N разных функций распределения вероятностей элементов входных векторов X. Требуется подобрать только лишь два параметра: a –крутизна функции; x0 – смещение нуля, что несколько упрощает процесс обучения.
После входного нелинейного преобразования, выровненные входные вектора S поступают на вход скрытого слоя случайных нейронов. По своему смыслу эти нейроны являются N-мерными линейными плоскостями, заданными посредством своих коэффициентов W={w0, w1, w2, w3, …, wN} так, что для любой точки S={s1, s2, s3, …, sN}, принадлежащей плоскости, выполняется условие:

Соответственно, для точек, не лежащих на плоскости, это равенство соблюдаться не будет и знак величины выражения будет определять с какой стороны относительно плоскости находится точка. Собственно именно эту указанную величину и формируют нейроны.
Задать эти плоскости-нейроны можно произвольным способом, но так, чтобы их задающие коэффициенты W удовлетворяли одному единственному требованию:
в N-мерном пространстве плоскости обязательно должны пересекать единичный куб, находящийся в начале координат
Иначе они не будут иметь никакого участия в процессе работы сети. Ниже дано представление результата распределения плоскостей для двумерного случая (плоскости являются прямыми), когда они случайным образом расчерчивают единичную область. Если взять их достаточное количество, то с большой вероятностью они достаточно точно определят границу двух кластеров точек.

Чтобы это требование выполнялось можно использовать задание коэффициентов W плоскости по одной точке, принадлежащей плоскости, и вектору нормали к ней. В этом случае внутри N-мерного единичного куба в начале координат случайно выбирается произвольная точка, заданная своими координатами: a1, a2, a3, …, aN, где случайные числа 0<ai<1. Коэффициенты, задающие плоскость нейрона, тогда будут следующими:

Здесь n1, n2, n3, …, nN – значения вектора нормали к плоскости, являющиеся также весовыми коэффициентами для соответствующих элементов вектора S (это могут быть любые случайные числа с любым знаком, но делать их по модулю слишком большими смысла нет); w0 – коэффициент для постоянного смещения, равного 1. Такое условие легко реализуется даже на самых простых вычислительных устройствах, что делает возможным обучение и работу НС в широком спектре приложений.
Следовательно, никакого обучения нейронов в рассматриваемой НС производить не нужно, т. к. они формируются случайным образом. При этом чем больше таких плоскостей-нейронов, тем более точнее будет результат классификации. Увеличение их количества ограничено только вычислительной сложностью и производительностью вычислительного устройства и не приводит к переобучению сети.
Бинарный выход каждого нейрона будет рассчитываться по формуле:
Значения выходов от M нейронов попадают на вход логической минимальной ДНФ функции от M переменных, которая используется в качестве выходного слоя сети, увязывая бинарные аргументы нейронов, получаемые после функции Sign, с бинарным (логическим) целевым выходом НС. Именно поэтому у этой логической функции столько переменных, сколько имеется нейронов в скрытом слое.
В немалой степени устойчивость сети к переобучению базируется на работе этой логической функции, которая включает только необходимые нейроны, рассматривая их, при этом, в комбинации друг с другом. Большое количество нейронов позволяет рассмотреть границы кластеров с максимально высоким разрешением, а способность логической функции проводить обобщение позволяет использовать предоставленное разрешение с максимальной эффективностью, не скатываясь к переобучению, когда сеть утрачивает обобщающую способность, становясь по своей сути элементом памяти.
В качестве реализации последнего каскада НС используется собственная разработка минимизации логических функций методом Квайна-Мак’Класки при неполном входном наборе данных (https://habr.com/ru/post/424517). Дополнительным преимуществом данной реализации является то, что она позволяет выявлять нейроны, не задействованные в процессе формирования выходного отклика сети. Такими нейронами будут те, у которых во всех дизъюнкциях минимальной ДНФ в соответствующих позициях будет находиться признак «склеенности» «*». Не участвующие нейроны можно удалять из скрытого слоя и заменять их новыми более полезными случайными нейронами.
using System; using System.Collections.Generic; using System.Linq; namespace RndNeuroNet { #region Случайные нейронный сети /// <summary> /// Класс нейронной сети со случайными разделяющими плоскостями /// </summary> public class RandomNeuralNetwork { private DistributionFunc[] pDistributionDataFuncs; private RandomDiscrimBase pNeuroLogicDiscrim; /// <summary> /// Конструктор /// </summary> public RandomNeuralNetwork() { } /// <summary> /// Для классификации двоичных данных /// </summary> /// <param name="pSourceTermsData"></param> /// <param name="pTargetFeature"></param> public void CreateNetwork(double[][] pSourceData, bool[] pTargetFeature, int iFromPos, int iTargetPos, int iWindowSize, int iAmountLogicDiscrims, int iLogicDiscrimsMaxTrainRestarts = 1, int iMaxAmountDistributionPoints = 1000, bool bIsNorming = true) { //Выделение новых массивов double[][] pSrcArray = new double[iTargetPos - iFromPos][]; bool[] pDstArray = new bool[iTargetPos - iFromPos]; for (int i = 0, t = iFromPos; t < iTargetPos; t++, i++) { //Нормирование обучающего вектора pSrcArray[i] = (bIsNorming ? NormingE(pSourceData[t], iWindowSize, iWindowSize) : pSourceData[t]); pDstArray[i] = pTargetFeature[t]; } //Формирование функций распределения случайной величины pDistributionDataFuncs = new DistributionFunc[iWindowSize]; for (int i = 0; i < iWindowSize; i++) { //Исходные данные для преобразования double[] pTrend2Recalc = pSrcArray.Select(p => p != null ? p[i] : 0).ToArray(); //Функция распределения pDistributionDataFuncs[i] = new DistributionFunc(pTrend2Recalc, iMaxAmountDistributionPoints); //Перерасчёт исходных значений через функцию распределения pTrend2Recalc = pDistributionDataFuncs[i].RecalcTrend(pTrend2Recalc); //Установка в данные для обучения for (int t = 0; t < pSrcArray.Length; t++) pSrcArray[t][i] = pTrend2Recalc[t]; } //Формирование НС pNeuroLogicDiscrim = (RandomDiscrimBase)new RandomLogicDiscrim(); pNeuroLogicDiscrim.CreateDiscrim(pSrcArray, pDstArray, 0, pSrcArray.Length, iWindowSize, iAmountLogicDiscrims, iLogicDiscrimsMaxTrainRestarts); } public double CalcResponce(double[] pSourceData, int iWindowSize = 0, bool bIsNorming = true) { //Размер данных if (iWindowSize <= 0) iWindowSize = pSourceData.Length; //Нормировка исходных данных pSourceData = (bIsNorming ? NormingE(pSourceData, iWindowSize, iWindowSize) : pSourceData); //Использование функции распределения for (int i = 0; i < iWindowSize; i++) { pSourceData[i] = pDistributionDataFuncs[i].RecalcTrend(pSourceData[i]); } //Вычисление леса решений return pNeuroLogicDiscrim.GetPrognos(pSourceData, iWindowSize); } /// <summary> /// Нормирование вектора через его среднюю /// </summary> /// <param name="pTrend"></param> /// <param name="iTargetPosition"></param> /// <param name="iVectorSize"></param> /// <returns></returns> public static double[] NormingE(double[] pTrend, int iTargetPosition, int iVectorSize, double[] pResultVector = null, bool bIsMinusOffset = false) { if (pResultVector == null) pResultVector = new double[iVectorSize]; double dNorming = 0; for (int i = 0, t = iTargetPosition - iVectorSize; i < iVectorSize; i++, t++) { dNorming += pTrend[t]; } dNorming /= iVectorSize; double dOffset = (bIsMinusOffset ? 1 : 0); for (int i = 0, t = iTargetPosition - iVectorSize; i < iVectorSize; i++, t++) { pResultVector[i] = (pTrend[t] / dNorming) - dOffset; } return pResultVector; } } /// <summary> /// Класс функции распределения случайной величины /// </summary> public class DistributionFunc { private class DataCont { public int Counter; public double SumSrc; public double ValueP; } private double dAreaMin, dAreaMax; private double[] m_DistributionPoints; //Конструктор по умолчанию public DistributionFunc() { } public DistributionFunc(double[] pTrend, int iMaxAmountDistributionPoints = 1000) { CreateDistribution(pTrend, iMaxAmountDistributionPoints); } //Создание функции распределения public void CreateDistribution(IEnumerable<double> pTrend, int iMaxAmountDistributionPoints = 1000) { dAreaMin = double.MaxValue; dAreaMax = double.MinValue; //Определение размеров динамического диапазона нормированного вектора обучения foreach (double dTrendVal in pTrend) { if (dTrendVal == 0) continue; dAreaMin = Math.Min(dAreaMin, dTrendVal); dAreaMax = Math.Max(dAreaMax, dTrendVal); } //Обработка вектора обучения SortedDictionary<int, DataCont> pDistribution = new SortedDictionary<int, DataCont>(); foreach (double dTrendVal in pTrend) { if (dTrendVal == 0) continue; int iIndex = (int)(((dTrendVal - dAreaMin) / (dAreaMax - dAreaMin)) * iMaxAmountDistributionPoints); DataCont pKeyVal = null; pDistribution.TryGetValue(iIndex, out pKeyVal); if (pKeyVal == null) pDistribution.Add(iIndex, pKeyVal = new DataCont()); pKeyVal.Counter++; pKeyVal.SumSrc += dTrendVal; } //Формирование значений функции распределения double dSumP = 0; foreach (KeyValuePair<int, DataCont> dataValue in pDistribution) { dataValue.Value.SumSrc /= dataValue.Value.Counter; dSumP += (double)dataValue.Value.Counter / (double)pTrend.Count(); dataValue.Value.ValueP = dSumP; } //Формирование массива значений m_DistributionPoints = new double[iMaxAmountDistributionPoints]; for (int iIndex = 0; iIndex < iMaxAmountDistributionPoints; iIndex++) { double dTrendVal; if (pDistribution.Keys.Contains(iIndex)) { dTrendVal = pDistribution[iIndex].ValueP; } else { int iDnIndex = pDistribution.Keys.Max<int>(p => p < iIndex ? p : 0); double dDnVal = pDistribution[iDnIndex].ValueP; int iUpIndex = pDistribution.Keys.Min<int>(p => p > iIndex ? p : int.MaxValue); double dUpVal = pDistribution[iUpIndex].ValueP; dTrendVal = (dUpVal - dDnVal) * ((double)(iIndex - iDnIndex) / (double)(iUpIndex - iDnIndex)) + dDnVal; } m_DistributionPoints[iIndex] = dTrendVal; } } //Перерасчёт значений нормированного вектора обучения, относительно функции распределения public double[] RecalcTrend(double[] pTrend, double[] pNewTrend = null) { if (pNewTrend == null) pNewTrend = new double[pTrend.Length]; for (int t = 0; t < pTrend.Length; t++) { pNewTrend[t] = RecalcTrend(pTrend[t]); } return pNewTrend; } //Перерасчёт значений нормированного вектора обучения, относительно функции распределения public double RecalcTrend(double dTrendVal) { int iIndex = (int)(((dTrendVal - dAreaMin) / (dAreaMax - dAreaMin)) * m_DistributionPoints.Length); if (iIndex < 0) { dTrendVal = 0; } else if (iIndex < m_DistributionPoints.Length) { dTrendVal = m_DistributionPoints[iIndex]; } else { dTrendVal = 1; } return dTrendVal; } } /// <summary> /// Базовый класс для случайной сети /// </summary> public class RandomDiscrimBase { public static int GetTermPoint(double[] pNeuronWeights, double[] pData, int iDataCortegeLength = 0) { double dVal = pNeuronWeights[iDataCortegeLength]; //Свободный член плоскости for (int i = 0; i < iDataCortegeLength; i++) dVal += (pNeuronWeights[i] * pData[i]); return Math.Sign(dVal); } public static int[] GetTermPoint(IList<double[]> pNeuroSurfaces, double[] pData, int iDataCortegeLength = 0) { if (iDataCortegeLength <= 0) iDataCortegeLength = pData.Length; int[] pLogicData = new int[pNeuroSurfaces.Count]; for (int n = 0; n < pNeuroSurfaces.Count; n++) { pLogicData[n] = GetTermPoint(pNeuroSurfaces[n], pData, iDataCortegeLength); } return pLogicData; } /// <summary> /// Подбор разделяющих плоскостей /// </summary> public virtual void CreateDiscrim(double[][] pSrcData, bool[] pDstData, int iFromPos, int iToPos, int iDataCortegeLength, int iAmountLogicDiscrims, int iLogicDiscrimsMaxTrainRestarts) { throw new MissingMethodException("Метод не реализован"); } /// <summary> /// Вычисление прогноза /// В случае бинарных целевых данных возвращает значение в интервале от -1 до +1 /// </summary> public virtual double GetPrognos(double[] pTermPointData, int iDataCortegeLength = -1) { throw new MissingMethodException("Метод не реализован"); } } /// <summary> /// Класс логической функции с набором случайных разделяющих плоскостей /// </summary> public class RandomLogicDiscrim : RandomDiscrimBase { private IList<double[]> pLogicDiscrims = null; public LogicFunc.Quine_McCluskey neuronLogic = null; /// <summary> /// Конструктор /// </summary> public RandomLogicDiscrim() { } /// <summary> /// Подбор разделяющих плоскостей /// </summary> public override void CreateDiscrim(double[][] pSrcArray, bool[] pTargetData, int iFromPos, int iToPos, int iDataCortegeLength, int iAmountLogicDiscrims, int iLogicDiscrimsMaxTrainRestarts) { Random RndFabric = new Random(Environment.TickCount); //Максимальное количество итераций int iMaxCounter = 0; //Подбор эффективных разделяющих плоскостей neuronLogic = null; pLogicDiscrims = new List<double[]>(); do { //Формирование совокупности случайных разделяющих плоскостей //Если кол-во решающих плоскостей меньше, чем iAmountLogicDiscrims, то добавляются случайные while (pLogicDiscrims.Count < iAmountLogicDiscrims) { double[] pNewSurface = new double[iDataCortegeLength + 1]; for (int i = 0; i < iDataCortegeLength; i++) { //Генерируется компонента случайного вектора нормали double dNormal = RndFabric.NextDouble() - 0.5; //Генерируется координата случайной точки, лежащей внутри объёма (0...1) double dPoint = RndFabric.NextDouble(); //Формируется коэффициент плоскости pNewSurface[i] = dNormal; //Формируется свободный член pNewSurface[iDataCortegeLength] -= dNormal * dPoint; } pLogicDiscrims.Add(pNewSurface); } //Обучение логической функции ICollection<byte[]> TermInputUp = new LinkedList<byte[]>(); ICollection<byte[]> TermInputDn = new LinkedList<byte[]>(); for (int t = iFromPos; t < iToPos; t++) { byte[] pSrcData = GetTermPoint(pLogicDiscrims, pSrcArray[t], iDataCortegeLength) .Select(p => (byte)(p > 0 ? 1 : 0)).ToArray(); if (pTargetData[t]) TermInputUp.Add(pSrcData); else TermInputDn.Add(pSrcData); } //Формирование логических нейронов neuronLogic = new LogicFunc.Quine_McCluskey(); neuronLogic.Start(TermInputUp, TermInputDn); //Удаление избыточных решающих плоскостей, т. е. //выбрасывание тех разделяющих плоскостей, которые не имеют никакого влияния if ((iMaxCounter + 1) < iLogicDiscrimsMaxTrainRestarts) { Dictionary<int, int> TermStars = new Dictionary<int, int>(iAmountLogicDiscrims); for (int i = 0; i < iAmountLogicDiscrims; i++) TermStars.Add(i, 0); foreach (byte[] pTerm in neuronLogic.Result.Terms) { for (int i = 0; i < iAmountLogicDiscrims; i++) { if (pTerm[i] != LogicFunc.LogicFunction.cStarSymb) TermStars[i]++; } } foreach (byte[] pTerm in neuronLogic.ResultNeg.Terms) { for (int i = 0; i < iAmountLogicDiscrims; i++) { if (pTerm[i] != LogicFunc.LogicFunction.cStarSymb) TermStars[i]++; } } foreach (KeyValuePair<int, int> p in TermStars) { //Если меньше среднего значения - удаление этой плоскости if (p.Value <= 0) pLogicDiscrims[p.Key] = null; } pLogicDiscrims = pLogicDiscrims.Where(p => p != null).ToList(); } } while ((pLogicDiscrims.Count < iAmountLogicDiscrims) && (iMaxCounter++ < iLogicDiscrimsMaxTrainRestarts)); } /// <summary> /// Вычисление прогноза /// </summary> /// <param name="pTermPointData"></param> /// <returns></returns> public override double GetPrognos(double[] pTermPointData, int iDataCortegeLength = -1) { if (iDataCortegeLength <= 0) iDataCortegeLength = pTermPointData.Length; byte[] pSrcData = GetTermPoint(pLogicDiscrims, pTermPointData, iDataCortegeLength).Select(p => (byte)(p > 0 ? 1 : 0)).ToArray(); int iPrognos = 0; iPrognos += (neuronLogic.Result.Calculate(pSrcData) ? +1 : -1); iPrognos += (neuronLogic.ResultNeg.Calculate(pSrcData) ? -1 : +1); return (iPrognos / 2); } } #endregion } namespace LogicFunc { #region Логические функции /// <summary> /// Базовый класс для логических функций /// </summary> public abstract class LogicFunction { //Символ "склееной" позиции public const byte cStarSymb = 2; //Дизъюнкции или конъюнкции функции public readonly ICollection<byte[]> Terms = new LinkedList<byte[]>(); //Вычисление значения функции public abstract bool Calculate(bool[] X); //Вычисление значения функции public abstract bool Calculate(char[] X); //Вычисление значения функции public abstract bool Calculate(byte[] X); } /// <summary> /// Дизъюнктивная нормальная форма /// </summary> public class DNF : LogicFunction { public static bool Calculate(byte[] X, byte[] term) { bool bResult = true; for (int i = 0; i < term.Length; i++) { if ((term[i] == cStarSymb) || (term[i] == X[i])) continue; bResult = false; break; } return bResult; } public override bool Calculate(byte[] X) { bool bResult = false; foreach (byte[] term in Terms) { bool bTermVal = true; for (int i = 0; i < term.Length; i++) { if ((term[i] >= cStarSymb) || (term[i] == X[i])) continue; bTermVal = false; break; } //bResult |= bTermVal; if (bTermVal) { bResult = true; break; } } return bResult; } public override bool Calculate(char[] X) { bool bResult = false; foreach (byte[] term in Terms) { bool bTermVal = true; for (int i = 0; i < term.Length; i++) { if ((term[i] >= cStarSymb) || (term[i] == (byte)(X[i] == '0' ? 0 : 1))) continue; bTermVal = false; break; } //bResult |= bTermVal; if (bTermVal) { bResult = true; break; } } return bResult; } public override bool Calculate(bool[] X) { bool bResult = false; foreach (byte[] term in Terms) { bool bTermVal = true; for (int i = 0; i < term.Length; i++) { if ((term[i] >= cStarSymb) || ((term[i] != 0) == X[i])) continue; bTermVal = false; break; } //bResult |= bTermVal; if (bTermVal) { bResult = true; break; } } return bResult; } } /// <summary> /// Дерево термов /// </summary> public class TreeFuncTerm { //Корень private readonly object[] rootNode = new object[3]; //Ранг (глубина) дерева private int _rang = 0; public int Rang { get { return _rang; } } //Для работы перечисления узлов private int enumerationPos = 0; private object[][] enumerationBuf; //Терм, который сопоставлен текущему конечному узлу private byte[] enumerationTerm; public byte[] EnumerationTerm { get { return enumerationTerm; } } //Возвращает количество термов в дереве private UInt32 _count = 0; public UInt32 Count { get { return _count; } } //Конструктор public TreeFuncTerm() { Clear(); } //Очистить дерево public void Clear() { _count = 0; _rang = 0; enumerationPos = 0; enumerationBuf = null; enumerationTerm = null; rootNode[0] = rootNode[1] = rootNode[2] = null; } //Инициализировать процесс перебора конечных узлов дерева public bool EnumerationInit() { enumerationPos = 0; enumerationTerm = new byte[_rang]; enumerationTerm[0] = 0; enumerationBuf = new object[_rang][]; enumerationBuf[0] = rootNode; //Вернуть первый конечный узел return EnumerationNextNode(); } //Получить следующий конечный узел дерева public bool EnumerationNextNode() { int iIsNext = (enumerationPos > 0 ? 1 : 0); while (enumerationPos >= 0) { object pNextNode = null; int iSymb = enumerationTerm[enumerationPos] + iIsNext; for (object[] pNodes = enumerationBuf[enumerationPos]; iSymb < 3; iSymb++) { if ((pNextNode = pNodes[iSymb]) != null) break; } if (pNextNode == null) { //Возврат на предыдущий уровень enumerationPos--; iIsNext = 1; } else { enumerationTerm[enumerationPos] = (byte)iSymb; if (pNextNode is byte[]) { //Найден конечный узел return true; } else { //Переход на следующий уровень enumerationPos++; enumerationBuf[enumerationPos] = (object[])pNextNode; enumerationTerm[enumerationPos] = 0; iIsNext = 0; } } } //Конечный узел не найден return false; } //Добавление в дерево нового терма без замены имеющегося public void Add(byte[] term) { _rang = Math.Max(_rang, term.Length); object[] pCurrNode = rootNode; int iTermLength1 = term.Length - 1; for (int i = 0; i < iTermLength1; i++) { byte cSymb = term[i]; object pNextNode = pCurrNode[cSymb]; if (pNextNode == null) { pNextNode = new object[3]; pCurrNode[cSymb] = pNextNode; } pCurrNode = (object[])pNextNode; } object pNewNode = pCurrNode[term[iTermLength1]]; if (pNewNode == null) { pCurrNode[term[iTermLength1]] = term; _count++; } } //Удаление из контейнера конечного узла последовательности public void Remove(byte[] term) { object[] pCurrNode = rootNode; int iTermLength1 = term.Length - 1; for (int i = 0; i < iTermLength1; i++) { pCurrNode = (object[])pCurrNode[term[i]]; if (pCurrNode == null) break; } byte[] pRemovedNode = null; if (pCurrNode != null) { //Сохраняется возвращаемая ссылка на удаляемый узел pRemovedNode = (byte[])pCurrNode[term[iTermLength1]]; if (pRemovedNode != null) { //Стираетсяя ссылка на конечный узел pCurrNode[term[iTermLength1]] = null; //Уменьшается кол-во узлов _count--; } } } //Удаление из контейнера множества конечных узлов public void Remove(IEnumerable<byte[]> RemovedTerms) { if ((RemovedTerms == null) || (RemovedTerms.Count() == 0)) return; foreach (byte[] x1 in RemovedTerms) { //Из-за особенностей работы функции можно сразу вызывать Remove //без предварительного вызова IsContains Remove(x1); } } //Проверка нахождения последовательности в контейнере public bool Contains(byte[] term) { object pCurrNode = rootNode; for (int i = 0; i < term.Length; i++) { pCurrNode = ((object[])pCurrNode)[term[i]]; if (pCurrNode == null) break; } return ((pCurrNode != null) && (pCurrNode is byte[])); } //Проверка присутствия последовательностей в контейнере, //дающих истинное значение для входного терма public bool IsCalculateTrue(byte[] term) { return IsCalculateTrue(rootNode, term, 0); } //рекурсивная версия предыдущей функции private static bool IsCalculateTrue(object[] pCurrNode, byte[] term, int iStartPos) { int iTermLength1 = term.Length - 1; while ((pCurrNode != null) && (iStartPos < iTermLength1)) { byte cSymb = term[iStartPos++]; if (cSymb != LogicFunction.cStarSymb) { pCurrNode = (object[])pCurrNode[cSymb]; } else { if ((pCurrNode[0] != null) && (pCurrNode[1] != null)) { if (IsCalculateTrue((object[])pCurrNode[1], term, iStartPos)) return true; pCurrNode = (object[])pCurrNode[0]; } else { pCurrNode = (object[])(pCurrNode[0] != null ? pCurrNode[0] : pCurrNode[1]); } } } byte[] pEndNode = null; if (pCurrNode != null) { byte cSymb = term[iTermLength1]; if (cSymb != LogicFunction.cStarSymb) { pEndNode = (byte[])pCurrNode[cSymb]; } else { pEndNode = (byte[])(pCurrNode[0] != null ? pCurrNode[0] : pCurrNode[1]); } } return (pEndNode != null); } //Получение всех последовательностей в контейнере, //дающих истинное значение для входного терма public void GetAllCalculateTrueTerms(byte[] term, ICollection<byte[]> pAllCalculateTrueTermsList) { pAllCalculateTrueTermsList.Clear(); GetAllCalculateTrueTerms(rootNode, term, 0, pAllCalculateTrueTermsList); } //рекурсивная версия предыдущей функции private static void GetAllCalculateTrueTerms(object[] pCurrNode, byte[] term, int iStartPos, ICollection<byte[]> pAllCalculateTrueTermsList) { int iTermLength1 = term.Length - 1; while ((pCurrNode != null) && (iStartPos < iTermLength1)) { byte cSymb = term[iStartPos++]; if (cSymb != LogicFunction.cStarSymb) { pCurrNode = (object[])pCurrNode[cSymb]; } else { if ((pCurrNode[0] != null) && (pCurrNode[1] != null)) { GetAllCalculateTrueTerms((object[])pCurrNode[1], term, iStartPos, pAllCalculateTrueTermsList); pCurrNode = (object[])pCurrNode[0]; } else { pCurrNode = (object[])(pCurrNode[0] != null ? pCurrNode[0] : pCurrNode[1]); } } } if (pCurrNode != null) { byte cSymb = term[iTermLength1]; if (cSymb != LogicFunction.cStarSymb) { byte[] pEndNode = (byte[])pCurrNode[cSymb]; if (pEndNode != null) pAllCalculateTrueTermsList.Add(pEndNode); } else { if (pCurrNode[0] != null) pAllCalculateTrueTermsList.Add((byte[])pCurrNode[0]); if (pCurrNode[1] != null) pAllCalculateTrueTermsList.Add((byte[])pCurrNode[1]); } } } } /// <summary> /// Минимизация логической функции методом Квайна---Мак-Класки /// </summary> public class Quine_McCluskey { //Решение по положительным термам private readonly DNF _result = new DNF(); public DNF Result { get { return _result; } } //Решение по негативным термам private readonly DNF _resultNeg = new DNF(); public DNF ResultNeg { get { return _resultNeg; } } //Склеивание строк с одним различием private static void Skleivanie(TreeFuncTerm X1Tree, TreeFuncTerm X2Tree, TreeFuncTerm NegativTree, TreeFuncTerm InpNegTerms, TreeFuncTerm AllOutTerms) { bool IsVirtSkleivOn = ((NegativTree != null) && (InpNegTerms != null) && (InpNegTerms.Count != 0)); for (bool bIsNode = X1Tree.EnumerationInit(); bIsNode; bIsNode = X1Tree.EnumerationNextNode()) { bool bIsSkleiv = false; byte[] pCurrTerm = X1Tree.EnumerationTerm; for (int iPos = 0; iPos < pCurrTerm.Length; iPos++) { byte cSymbSav = pCurrTerm[iPos]; if (cSymbSav == LogicFunction.cStarSymb) continue; //Склеивание двух термов с одним различием pCurrTerm[iPos] = (byte)(1 - cSymbSav); if (X1Tree.Contains(pCurrTerm)) { bIsSkleiv = true; if (cSymbSav == 0) { pCurrTerm[iPos] = LogicFunction.cStarSymb; //Метка склеивания X2Tree.Add(pCurrTerm); } } //или склеивание с виртуальной термой, которой нет в NegativTree else if (IsVirtSkleivOn && !NegativTree.Contains(pCurrTerm)) { pCurrTerm[iPos] = LogicFunction.cStarSymb; //Метка склеивания if (!InpNegTerms.IsCalculateTrue(pCurrTerm)) { bIsSkleiv = true; X2Tree.Add(pCurrTerm); } } pCurrTerm[iPos] = cSymbSav; } //Добавление на выход тех термов, которые ни с кем не склеились if (!bIsSkleiv && (AllOutTerms != null)) AllOutTerms.Add(pCurrTerm); } } //Удаление дубликатов термов из входного списка //В выходное дерево добавляются только уникальные термы private static void DeleteDublicatingTerms( IEnumerable<byte[]> InX1, TreeFuncTerm OutX2Tree) { OutX2Tree.Clear(); foreach (byte[] x1 in InX1) OutX2Tree.Add(x1); } // Отбрасывание избыточных терм с помощью алгоритма приближенного решения задачи о покрытии. // Покрытие, близкое к кратчайшему, даёт следующий алгоритм преобразования таблицы покрытий (ТП), // основанный на методе “минимальный столбец–максимальная строка” // (http://www.studfiles.ru/preview/5175815/page:4/) private static void ReduceRedundancyTerms(TreeFuncTerm AllOutputTerms, TreeFuncTerm AllInputTerms, ICollection<byte[]> ResultTerms) { //Подготовка результирующего контейнера ResultTerms.Clear(); //Контейнер для соответствия конечного терма к списку первичных термов, которые его образовали Dictionary<byte[], HashSet<byte[]>> Outputs2Inputs = new Dictionary<byte[], HashSet<byte[]>>(); //Контейнер для соответствия первичных входных терм к тем выходным, которые их покрывают Dictionary<byte[], HashSet<byte[]>> Inputs2Outputs = new Dictionary<byte[], HashSet<byte[]>>(); //Сбор статистики об покрытии выходными термами входных for (bool bIsNode = AllOutputTerms.EnumerationInit(); bIsNode; bIsNode = AllOutputTerms.EnumerationNextNode()) { byte[] outTerm = (byte[])AllOutputTerms.EnumerationTerm.Clone(); //Контейнер входных термов, которые покрывает данный выходной терм term HashSet<byte[]> InpTermsLst = new HashSet<byte[]>(); AllInputTerms.GetAllCalculateTrueTerms(outTerm, InpTermsLst); Outputs2Inputs.Add(outTerm, InpTermsLst); foreach (byte[] inputTerm in InpTermsLst) { if (!Inputs2Outputs.ContainsKey(inputTerm)) Inputs2Outputs.Add(inputTerm, new HashSet<byte[]>()); Inputs2Outputs[inputTerm].Add(outTerm); } } //Сортировка словаря исходных термов по возрастанию кол-ва их покрытий выходными Inputs2Outputs = Inputs2Outputs.OrderBy(p => p.Value.Count).ToDictionary(p => p.Key, v => v.Value); //Перебор всех входных термов, отсортированных по кол-ву покрывавших их выходных while (Inputs2Outputs.Count > 0) { byte[] outTerm = Inputs2Outputs.First().Value.OrderByDescending(q => Outputs2Inputs[q].Count()).First(); ResultTerms.Add(outTerm); foreach (byte[] inTerm in Outputs2Inputs[outTerm].ToArray()) { foreach (byte[] outTerm2Del in Inputs2Outputs[inTerm]) Outputs2Inputs[outTerm2Del].Remove(inTerm); Inputs2Outputs.Remove(inTerm); } } } //Нахождение минимальной логической функции public static void LogicFuncMinimize( IEnumerable<byte[]> PositivTerms, ICollection<byte[]> OutPos, IEnumerable<byte[]> NegativTerms, ICollection<byte[]> OutNeg) { TreeFuncTerm InpPosTerms = new TreeFuncTerm(); DeleteDublicatingTerms(PositivTerms, InpPosTerms); int iTotalLevels = InpPosTerms.Rang; if (iTotalLevels <= 0) return; TreeFuncTerm OutPosTerms = new TreeFuncTerm(); TreeFuncTerm OutNegTerms = null; TreeFuncTerm InpNegTerms = null; if ((NegativTerms != null) && (NegativTerms.Count() != 0)) { InpNegTerms = new TreeFuncTerm(); DeleteDublicatingTerms(NegativTerms, InpNegTerms); OutNegTerms = new TreeFuncTerm(); //Проверка наличия и удаление одинаковых данных в обеих последовательностях for (bool bIsNode = InpPosTerms.EnumerationInit(); bIsNode; bIsNode = InpPosTerms.EnumerationNextNode()) { if (!InpNegTerms.Contains(InpPosTerms.EnumerationTerm)) continue; //Подсчитывается кол-во входных термов в X1 и в NegativTerms int iPos_Count = PositivTerms.Count(p => Enumerable.SequenceEqual(p, InpPosTerms.EnumerationTerm)); int iNeg_Count = NegativTerms.Count(p => Enumerable.SequenceEqual(p, InpPosTerms.EnumerationTerm)); if (iPos_Count > iNeg_Count) { InpNegTerms.Remove(InpPosTerms.EnumerationTerm); } else if (iPos_Count < iNeg_Count) { InpPosTerms.Remove(InpPosTerms.EnumerationTerm); } else //if (iX1_Count == iNeg_Count) { InpPosTerms.Remove(InpPosTerms.EnumerationTerm); InpNegTerms.Remove(InpPosTerms.EnumerationTerm); } } } //Исходные деревья TreeFuncTerm X1PositivTree = InpPosTerms; TreeFuncTerm X1NegativTree = InpNegTerms; int iLevelCounter = 0; //Повтор до тех пор пока будут оставаться термы while ((X1PositivTree.Count != 0) && (iLevelCounter < iTotalLevels)) { TreeFuncTerm X2PositivTree = new TreeFuncTerm(); Skleivanie(X1PositivTree, X2PositivTree, X1NegativTree, InpNegTerms, OutPosTerms); if ((X1NegativTree != null) && (X1NegativTree.Count != 0)) { TreeFuncTerm X2NegativTree = new TreeFuncTerm(); Skleivanie(X1NegativTree, X2NegativTree, X1PositivTree, InpPosTerms, OutNegTerms); //Очистка поискового дерева if (iLevelCounter > 0) X1NegativTree.Clear(); X1NegativTree = X2NegativTree; } //Очистка поискового дерева if (iLevelCounter > 0) X1PositivTree.Clear(); X1PositivTree = X2PositivTree; iLevelCounter++; GC.Collect(); } if (OutPosTerms.Count > 0) { //Удаляется терм, содержащий во всех позициях cStarSymb OutPosTerms.Remove(Enumerable.Repeat(LogicFunction.cStarSymb, iTotalLevels).ToArray()); } //Выбор оптимального набора терм ReduceRedundancyTerms(OutPosTerms, InpPosTerms, OutPos); if ((OutNeg != null) && (OutNegTerms != null)) { if (OutNegTerms.Count > 0) { //Удаляется терм, содержащий во всех позициях cStarSymb OutNegTerms.Remove(Enumerable.Repeat(LogicFunction.cStarSymb, iTotalLevels).ToArray()); } //Выбор оптимального набора терм ReduceRedundancyTerms(OutNegTerms, InpNegTerms, OutNeg); } } //Запуск метода public void Start(IEnumerable<byte[]> TermsInput) { LogicFuncMinimize(TermsInput, _result.Terms, null, null); } //Запуск метода public void Start(IEnumerable<byte[]> TermsInput, IEnumerable<byte[]> NegativTerms) { LogicFuncMinimize(TermsInput, _result.Terms, NegativTerms, _resultNeg.Terms); } //Запуск метода public void Start(IEnumerable<char[]> TermsInput) { Start(TermsInput.Select(t => t.Select(p => (byte)(p == '0' ? 0 : 1)).ToArray())); } //Запуск метода public void Start(IEnumerable<char[]> TermsInput, IEnumerable<char[]> NegativTerms) { Start(TermsInput.Select(t => t.Select(p => (byte)(p == '0' ? 0 : 1)).ToArray()), NegativTerms.Select(t => t.Select(p => (byte)(p == '0' ? 0 : 1)).ToArray())); } //Запуск метода public void Start(IEnumerable<bool[]> TermsInput) { Start(TermsInput.Select(t => t.Select(p => (byte)(p ? 1 : 0)).ToArray())); } //Запуск метода public void Start(IEnumerable<bool[]> TermsInput, IEnumerable<bool[]> NegativTerms) { Start(TermsInput.Select(t => t.Select(p => (byte)(p ? 1 : 0)).ToArray()), NegativTerms.Select(t => t.Select(p => (byte)(p ? 1 : 0)).ToArray())); } } #endregion }
Для проверки работы алгоритма формируется псевдо-случайная последовательность определённой длины в виде суммы заданного количества гармоник со случайными частотами, фазами и амплитудами. Эта последовательность разделяется на две равные части, первая из которых используется как обучающая, а вторая часть является тестовой. В качестве исходных данных для обучения и тестирования на каждой позиции t выборки используются N предыдущих её элементов X(t-j) (j=1,2,…,N), а в качестве целевого бинарного признака значение функции Sign(X(t)-X(t-1)). После обучения сети на первой половине последовательности, формируется отчёт о правильности её работы на этой обучающей выборке. Далее производится работа обученной сети на тестовой выборке, т. е. второй половине последовательности, после чего формируется аналогичный отчёт о правильности её работы. Нейронная сеть работает хорошо, если отчёты по своим прогнозам значений Sign(X(t)-X(t-1)) примерно совпадают. Если на тестовой выборке сеть показывает плохой результат, то это означает, что псевдо-случайная последовательность имеет действительно случайные характеристики и НС не обнаруживает связи между обучающей и тестовой выборками, т. е. каких-либо закономерностей нет.
public static void TestRandomNeuralNetwork() { //Параметр: длина всей последовательности const int iTrendSize = 2000; //Параметр: длина тестовой последовательности const int iTestTrendSize = 1000; //Параметр: длина окна предистории const int iWindowSize = 10; //Частота гармоники однокомпонентного тренда const int iOmega = 100; //Кол-во гармоник многокомпонентного тренда const int iHarmonics = 5; //Величина минимальной амплитуды отдельной гармоники const int iMinAmpl = 50; //Величина максимальной амплитуды отдельной гармоники const int iMaxAmpl = 100; //Величина отношения шум/сигнал const double dNoise2SignalRatio = 0; //Параметр: количество решающих плоскостей const int iAmountLogicDiscrims = 20; //Параметр: максимальное кол-во точек апроксимации функции распределения const int iMaxAmountDistributionPoints = 1000; //Параметр: максимальное кол-во рестартов тренировки разделяющих плоскостей const int iLogicDiscrimsMaxTrainRestarts = 1; //Длина тренда для обучения int iPrepTrendLength = iTrendSize - iTestTrendSize; double[] pTrend = new double[iTrendSize]; //Формирование тренда-гармоники //for (int t = 0; t < iTrendSize; t++) pTrend[t] = Math.Sin((t * Math.PI) / iOmega) + 200; //Формирование многокомпонентного тренда int[] pFreq = new int[iHarmonics]; int[] pPhase = new int[iHarmonics]; double[] pAmpl = new double[iHarmonics]; //Для генерации случ. чисел Random RndFabric = new Random(Environment.TickCount); for (int h = 0; h < iHarmonics; h++) { pFreq[h] = RndFabric.Next(iOmega/*iPrepTrendLength*/) + 1; pPhase[h] = RndFabric.Next(iPrepTrendLength); pAmpl[h] = RndFabric.NextDouble(); } double iMinValue = double.MaxValue, iMaxValue = 0; for (int t = 0; t < iTrendSize; t++) { double dValue = 0; //iMinAmpl + ((iMaxAmpl - iMinAmpl) * RndFabric.NextDouble()); for (int h = 0; h < iHarmonics; h++) { dValue += ((pAmpl[h] * (iMaxAmpl - iMinAmpl)) + iMinAmpl) * Math.Sin(((t + pPhase[h]) * Math.PI) / pFreq[h]); } pTrend[t] = dValue; iMinValue = Math.Min(iMinValue, dValue); iMaxValue = Math.Max(iMaxValue, dValue); } //Добавление шума if (dNoise2SignalRatio > 0) { double dNoiseAmp = (iMaxValue - iMinValue) * dNoise2SignalRatio; for (int t = 0; t < iTrendSize; t++) { pTrend[t] += dNoiseAmp * 2.0 * (RndFabric.NextDouble() - 0.5); iMinValue = Math.Min(iMinValue, pTrend[t]); } } //Смещение тренда, чтобы все значения были положительными if (iMinValue < 0) { for (int t = 0; t < iTrendSize; t++) pTrend[t] -= iMinValue; } //Массивы для обучения double[][] pSourceTrendData = new double[iTrendSize][]; bool[] pTargetFeature = new bool[iTrendSize]; //Формирование данных for (int t = iWindowSize; t < iTrendSize; t++) { //Исходные данные double[] pNormData = new double[iWindowSize]; for (int i = 0; i < iWindowSize; i++) pNormData[i] = pTrend[t - iWindowSize + i]; pSourceTrendData[t] = pNormData; //Предсказание следующей позиции pTargetFeature[t] = (pTrend[t] >= pTrend[t - 1]); } DateTime dtStartDt = DateTime.Now; RndNeuroNet.RandomNeuralNetwork randomNeuralNetwork = new RndNeuroNet.RandomNeuralNetwork(); randomNeuralNetwork.CreateNetwork(pSourceTrendData, pTargetFeature, iWindowSize, iPrepTrendLength, iWindowSize, iAmountLogicDiscrims, //iClustersAmount, iClustersRestart, iLogicDiscrimsMaxTrainRestarts, iMaxAmountDistributionPoints); //Интервал времени работы TimeSpan tsTime = (DateTime.Now - dtStartDt); //Проверка работы функции на обучающем участке int iUpGapCounterTrain = 0, iDnGapCounterTrain = 0, iSuccessCounterTrain = 0, iErrorCounterTrain = 0, iIgnoreCounterTrain = 0; for (int t = iWindowSize; t < iPrepTrendLength; t++) { double dPrognos = randomNeuralNetwork.CalcResponce(pSourceTrendData[t]); if (dPrognos == 0) { iIgnoreCounterTrain++; } else { if (((pTargetFeature[t] ? +1 : -1) * dPrognos) > 0) { iSuccessCounterTrain++; } else { iErrorCounterTrain++; } } //Счётчики GAP-ов и Максимальные оценки if (pTargetFeature[t]) { iUpGapCounterTrain++; } else { iDnGapCounterTrain++; } } //Проверка работы функции на тестовом участке int iUpGapCounterTest = 0, iDnGapCounterTest = 0, iSuccessCounterTest = 0, iErrorCounterTest = 0, iIgnoreCounterTest = 0; for (int t = iPrepTrendLength; t < iTrendSize; t++) { double dPrognos = randomNeuralNetwork.CalcResponce(pSourceTrendData[t]); if (dPrognos == 0) { iIgnoreCounterTest++; } else { if (((pTargetFeature[t] ? +1 : -1) * dPrognos) > 0) { iSuccessCounterTest++; } else { iErrorCounterTest++; } } //Счётчики GAP-ов и Максимальные оценки if (pTargetFeature[t]) { iUpGapCounterTest++; } else { iDnGapCounterTest++; } } //Сообщение Console.WriteLine("Кол-во примеров на повышение на обучении = " + iUpGapCounterTrain + Environment.NewLine + "Кол-во примеров на понижение на обучении = " + iDnGapCounterTrain + Environment.NewLine + "Кол-во успешных предсказаний на обучении = " + iSuccessCounterTrain + Environment.NewLine + "Кол-во ошибочных предсказаний на обучении = " + iErrorCounterTrain + Environment.NewLine + "Кол-во пропущенных предсказаний на обучении = " + iIgnoreCounterTrain + Environment.NewLine + "Кол-во примеров на повышение на тесте = " + iUpGapCounterTest + Environment.NewLine + "Кол-во примеров на понижение на тесте = " + iDnGapCounterTest + Environment.NewLine + "Кол-во успешных предсказаний на тесте = " + iSuccessCounterTest + Environment.NewLine + "Кол-во ошибочных предсказаний на тесте = " + iErrorCounterTest + Environment.NewLine + "Кол-во пропущенных предсказаний на тесте = " + iIgnoreCounterTest + Environment.NewLine + "Время работы = " + (int)tsTime.TotalMinutes + " мин. " + tsTime.Seconds + " сек." ); Console.WriteLine("Press Enter to exit ..."); Console.ReadLine(); }
Как итог проверки качества работы НС, необходимо отметить, что по точности классификации предложенный вид случайных НС не превосходит классические с обратным распространением ошибок. Но они имеют перед ними, по крайней мере, три конкурентных преимущества:
- Они не склонны к переобучению;
- Расчёт коэффициентов нейронов скрытого слоя прост и не требует вычислительно ёмких итерационных процедур;
- Они более просты для понимания, т. к. в их основе лежит более простая математическая основа, где «трудно в чём-то ошибиться».
В качестве недостатка НС необходимо отметить её большие требования к величине доступной оперативной памяти и значительному времени, затрачиваемому при обучении. Их основным потребителем является алгоритм минимизации логических функций методом Квайна-Мак’Класки, т. е. 3-й выходной слой. Но есть возможность несколько сгладить этот недостаток путём каскадирования нескольких логических функций. В остальном же данная НС зарекомендовала себя надёжным средством для прогнозирования и классификации бинарных данных.

