По мере исчерпания адресов IPv4, многие операторы связи столкнулись с необходимостью организовывать доступ своих клиентов в сеть с помощью трансляции адресов. В этой статье я расскажу, как можно получить производительность уровня Carrier Grade NAT на commodity серверах.
Тема исчерпания адресного пространства IPv4 уже не нова. В какой-то момент в RIPE появились очереди ожидания (waiting list), затем возникли биржи, на которых торговали блоками адресов и заключались сделки по их аренде. Постепенно операторы связи начали предоставлять услуги доступа в Интернет с помощью трансляции адресов и портов. Кто-то не успел получить достаточно адресов, чтобы выдать «белый» адрес каждому абоненту, а кто-то начал экономить средства, отказавшись от покупки адресов на вторичном рынке. Производители сетевого оборудования поддержали эту идею, т.к. этот функционал обычно требует дополнительных модулей расширения или лицензий. Например, у Juniper в линейке маршрутизаторов MX (кроме последних MX104 и MX204) выполнять NAPT можно на отдельной сервисной карте MS-MIC, на Cisco ASR1k требуется лицензия СGN license, на Cisco ASR9k — отдельный модуль A9K-ISM-100 и лицензия A9K-CGN-LIC к нему. В общем, удовольствие стоит немалых денег.
Задача выполнения NAT не требует специализированных вычислительных ресурсов, ее в состоянии решать процессоры общего назначения, которые установлены, например, в любом домашнем роутере. В масштабах оператора связи эту задачу можно решить используя commodity серверы под управлением FreeBSD (ipfw/pf) или GNU/Linux (iptables). Рассматривать FreeBSD не будем, т.к. я довольно давно отказался от использования этой ОС, так что остановимся на GNU/Linux.
Включить трансляцию адресов совсем не сложно. Для начала необходимо прописать правило в iptables в таблицу nat:
Операционная система загрузит модуль nf_conntrack, который будет следить за всеми активными соединениями и выполнять необходимые преобразования. Тут есть несколько тонкостей. Во-первых, поскольку речь идет о NAT в масштабах оператора связи, то необходимо подкрутить timeout'ы, потому что со значениями по умолчанию размер таблицы трансляций достаточно быстро вырастет до катастрофических значений. Ниже пример настроек, которые я использовал на своих серверах:
И во-вторых, поскольку по умолчанию размер таблицы трансляций не рассчитан на работу в условиях оператора связи, его необходимо увеличить:
Также необходимо увеличить и количество buckets для хэш-таблицы, хранящей все трансляции (это опция модуля nf_conntrack):
После этих нехитрых манипуляций получается вполне работающая конструкция, которая может транслировать большое количество клиентских адресов в пул внешних. Однако, производительность этого решения оставляет желать лучшего. В своих первых попытках использования GNU/Linux для NAT (примерно 2013 год) я смог получить производительность около 7Gbit/s при 0.8Mpps на один сервер (Xeon E5-1650v2). С того времени в сетевом стеке ядра GNU/Linux было сделано много различных оптимизаций, производительность одного сервера на том же железе выросла практически до 18-19 Gbit/s при 1.8-1.9 Mpps (это были предельные значения), но потребность в объеме трафика, обрабатываемого одним сервером, росла намного быстрее. В итоге были выработаны схемы балансировки нагрузки на разные серверы, но всё это увеличило сложность настройки, обслуживания и поддержания качества предоставляемых услуг.
Сейчас модным направлением в программном «перекладывании пакетиков» является использование DPDK и XDP. На эту тему написана куча статей, сделано много разных выступлений, появляются коммерческие продукты (например, СКАТ от VasExperts). Но в условиях ограниченных ресурсов программистов у операторов связи, пилить самостоятельно какое-нибудь «поделие» на базе этих фреймворков довольно проблематично. Эксплуатировать такое решение в дальнейшем будет намного сложнее, в частности, придется разрабатывать инструменты диагностики. Например, штатный tcpdump с DPDK просто так не заработает, да и пакеты, отправленные назад в провода с помощью XDP, он не «увидит». На фоне всех разговоров про новые технологии вывода форвардинга пакетов в user-space, незамеченными остались доклады и статьи Pablo Neira Ayuso, меинтейнера iptables, про разработку flow offloading в nftables. Давайте рассмотрим этот механизм подробнее.
Основная идея заключается в том, что если роутер пропустил пакеты одной сессии в обе стороны потока (TCP сессия перешла в состояние ESTABLISHED), то нет необходимости пропускать последующие пакеты этой сессии через все правила firewall, т.к. все эти проверки всё равно закончатся передачей пакета далее в роутинг. Да и собственно выбор маршрута выполнять не надо — мы уже знаем в какой интерфейс и какому хосту надо переслать пакеты пределах этой сессии. Остается только сохранить эту информацию и использовать ее для маршрутизации на ранней стадии обработки пакета. При выполнении NAT необходимо дополнительно сохранить информацию об изменениях адресов и портов, преобразованных модулем nf_conntrack. Да, конечно, в этом случае перестают работать различные полисеры и другие информационно-статистические правила в iptables, но в рамках задачи отдельного стоящего NAT или, например, бордера — это не так уж важно, потому что сервисы распределены по устройствам.
Чтобы воспользоваться этой функцией нам надо:
Если с первым пунктом всё в принципе понятно, главное не забыть включить модуль в конфигурацию при сборке (CONFIG_NFT_FLOW_OFFLOAD=m), то второй пункт требует пояснений. Правила nftables описываются совсем не так, как в iptables. Документация раскрывает практически все моменты, также есть специальные конверторы правил из iptables в nftables. Поэтому я приведу только пример настройки NAT и flow offload. Небольшая легенда для примера: <i_if>, <o_if> — это сетевые интерфейсы, через которые проходит трафик, реально их может быть больше двух. <pool_addr_start>,<pool_addr_end> — начальный и конечный адрес диапазона «белых» адресов.
Конфигурация NAT очень проста:
С flow offload немного сложнее, но вполне понятно:
Вот, собственно, и вся настройка. Теперь весь TCP/UDP трафик будет попадать в таблицу fastnat и обрабатываться намного быстрее.
Чтобы стало понятно, насколько это «намного быстрее», я приложу скриншот нагрузки на два реальных сервера, с одинаковой начинкой (Xeon E5-1650v2), одинаково настроенных, использующих одно и тоже ядро Linux, но выполняющих NAT в iptables (NAT4) и в nftables (NAT5).
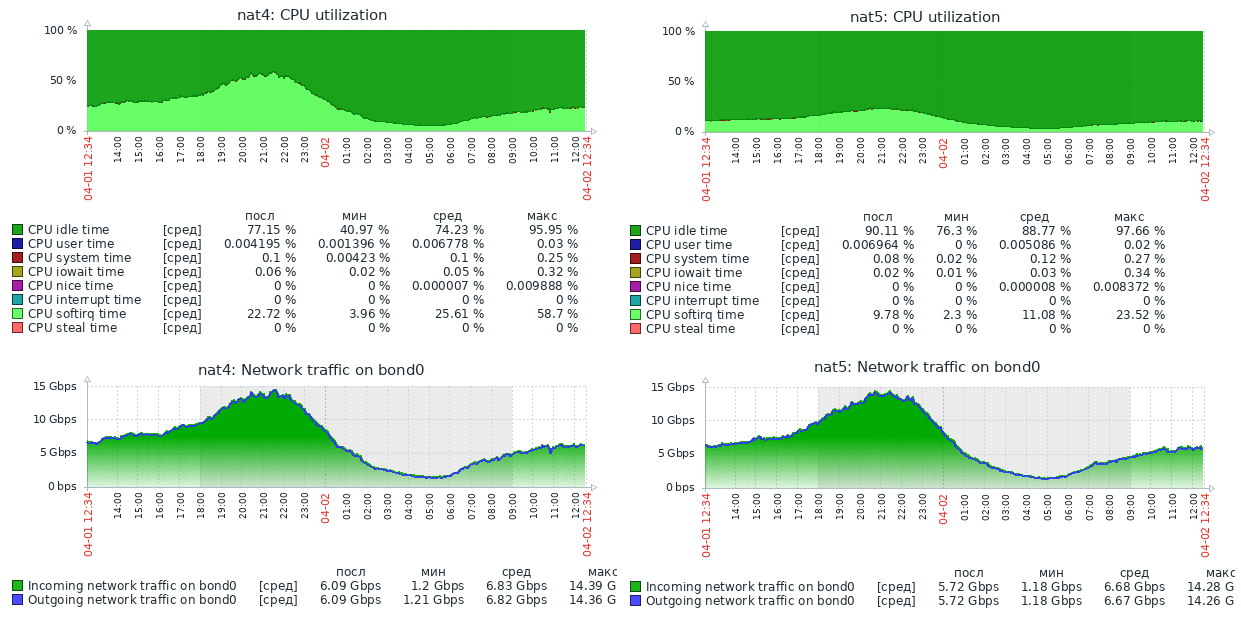
На скриншоте нет графика пакетов в секунду, но в профиле нагрузки этих серверов средний размер пакета в районе 800 байт, поэтому значения доходят до 1.5Mpps. Как видно, запас производительности у сервера с nftables огромный. На текущий момент этот сервер обрабатывает до 30Gbit/s при 3Mpps и явно способен упереться в физическое ограничение сети 40Gbps, имея при этом свободные ресурсы CPU.
Надеюсь, этот материал будет полезен сетевым инженерам, пытающимся улучшить производительность своих серверов.
Немного истории
Тема исчерпания адресного пространства IPv4 уже не нова. В какой-то момент в RIPE появились очереди ожидания (waiting list), затем возникли биржи, на которых торговали блоками адресов и заключались сделки по их аренде. Постепенно операторы связи начали предоставлять услуги доступа в Интернет с помощью трансляции адресов и портов. Кто-то не успел получить достаточно адресов, чтобы выдать «белый» адрес каждому абоненту, а кто-то начал экономить средства, отказавшись от покупки адресов на вторичном рынке. Производители сетевого оборудования поддержали эту идею, т.к. этот функционал обычно требует дополнительных модулей расширения или лицензий. Например, у Juniper в линейке маршрутизаторов MX (кроме последних MX104 и MX204) выполнять NAPT можно на отдельной сервисной карте MS-MIC, на Cisco ASR1k требуется лицензия СGN license, на Cisco ASR9k — отдельный модуль A9K-ISM-100 и лицензия A9K-CGN-LIC к нему. В общем, удовольствие стоит немалых денег.
IPTables
Задача выполнения NAT не требует специализированных вычислительных ресурсов, ее в состоянии решать процессоры общего назначения, которые установлены, например, в любом домашнем роутере. В масштабах оператора связи эту задачу можно решить используя commodity серверы под управлением FreeBSD (ipfw/pf) или GNU/Linux (iptables). Рассматривать FreeBSD не будем, т.к. я довольно давно отказался от использования этой ОС, так что остановимся на GNU/Linux.
Включить трансляцию адресов совсем не сложно. Для начала необходимо прописать правило в iptables в таблицу nat:
iptables -t nat -A POSTROUTING -s 100.64.0.0/10 -j SNAT --to <pool_start_addr>-<pool_end_addr> --persistent
Операционная система загрузит модуль nf_conntrack, который будет следить за всеми активными соединениями и выполнять необходимые преобразования. Тут есть несколько тонкостей. Во-первых, поскольку речь идет о NAT в масштабах оператора связи, то необходимо подкрутить timeout'ы, потому что со значениями по умолчанию размер таблицы трансляций достаточно быстро вырастет до катастрофических значений. Ниже пример настроек, которые я использовал на своих серверах:
net.ipv4.ip_forward = 1 net.ipv4.ip_local_port_range = 8192 65535 net.netfilter.nf_conntrack_generic_timeout = 300 net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 60 net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60 net.netfilter.nf_conntrack_tcp_timeout_established = 600 net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 60 net.netfilter.nf_conntrack_tcp_timeout_close_wait = 45 net.netfilter.nf_conntrack_tcp_timeout_last_ack = 30 net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120 net.netfilter.nf_conntrack_tcp_timeout_close = 10 net.netfilter.nf_conntrack_tcp_timeout_max_retrans = 300 net.netfilter.nf_conntrack_tcp_timeout_unacknowledged = 300 net.netfilter.nf_conntrack_udp_timeout = 30 net.netfilter.nf_conntrack_udp_timeout_stream = 60 net.netfilter.nf_conntrack_icmpv6_timeout = 30 net.netfilter.nf_conntrack_icmp_timeout = 30 net.netfilter.nf_conntrack_events_retry_timeout = 15 net.netfilter.nf_conntrack_checksum=0
И во-вторых, поскольку по умолчанию размер таблицы трансляций не рассчитан на работу в условиях оператора связи, его необходимо увеличить:
net.netfilter.nf_conntrack_max = 3145728
Также необходимо увеличить и количество buckets для хэш-таблицы, хранящей все трансляции (это опция модуля nf_conntrack):
options nf_conntrack hashsize=1572864
После этих нехитрых манипуляций получается вполне работающая конструкция, которая может транслировать большое количество клиентских адресов в пул внешних. Однако, производительность этого решения оставляет желать лучшего. В своих первых попытках использования GNU/Linux для NAT (примерно 2013 год) я смог получить производительность около 7Gbit/s при 0.8Mpps на один сервер (Xeon E5-1650v2). С того времени в сетевом стеке ядра GNU/Linux было сделано много различных оптимизаций, производительность одного сервера на том же железе выросла практически до 18-19 Gbit/s при 1.8-1.9 Mpps (это были предельные значения), но потребность в объеме трафика, обрабатываемого одним сервером, росла намного быстрее. В итоге были выработаны схемы балансировки нагрузки на разные серверы, но всё это увеличило сложность настройки, обслуживания и поддержания качества предоставляемых услуг.
NFTables
Сейчас модным направлением в программном «перекладывании пакетиков» является использование DPDK и XDP. На эту тему написана куча статей, сделано много разных выступлений, появляются коммерческие продукты (например, СКАТ от VasExperts). Но в условиях ограниченных ресурсов программистов у операторов связи, пилить самостоятельно какое-нибудь «поделие» на базе этих фреймворков довольно проблематично. Эксплуатировать такое решение в дальнейшем будет намного сложнее, в частности, придется разрабатывать инструменты диагностики. Например, штатный tcpdump с DPDK просто так не заработает, да и пакеты, отправленные назад в провода с помощью XDP, он не «увидит». На фоне всех разговоров про новые технологии вывода форвардинга пакетов в user-space, незамеченными остались доклады и статьи Pablo Neira Ayuso, меинтейнера iptables, про разработку flow offloading в nftables. Давайте рассмотрим этот механизм подробнее.
Основная идея заключается в том, что если роутер пропустил пакеты одной сессии в обе стороны потока (TCP сессия перешла в состояние ESTABLISHED), то нет необходимости пропускать последующие пакеты этой сессии через все правила firewall, т.к. все эти проверки всё равно закончатся передачей пакета далее в роутинг. Да и собственно выбор маршрута выполнять не надо — мы уже знаем в какой интерфейс и какому хосту надо переслать пакеты пределах этой сессии. Остается только сохранить эту информацию и использовать ее для маршрутизации на ранней стадии обработки пакета. При выполнении NAT необходимо дополнительно сохранить информацию об изменениях адресов и портов, преобразованных модулем nf_conntrack. Да, конечно, в этом случае перестают работать различные полисеры и другие информационно-статистические правила в iptables, но в рамках задачи отдельного стоящего NAT или, например, бордера — это не так уж важно, потому что сервисы распределены по устройствам.
Конфигурация
Чтобы воспользоваться этой функцией нам надо:
- Использовать свежее ядро. Несмотря на то, что сам функционал появился еще в ядре 4.16, довольно долго он было очень «сырой» и регулярно вызывал kernel panic. Стабилизировалось всё примерно в декабре 2019 года, когда вышли LTS ядра 4.19.90 и 5.4.5.
- Переписать правила iptables в формат nftables, используя достаточно свежую версию nftables. Точно работает в версии 0.9.0
Если с первым пунктом всё в принципе понятно, главное не забыть включить модуль в конфигурацию при сборке (CONFIG_NFT_FLOW_OFFLOAD=m), то второй пункт требует пояснений. Правила nftables описываются совсем не так, как в iptables. Документация раскрывает практически все моменты, также есть специальные конверторы правил из iptables в nftables. Поэтому я приведу только пример настройки NAT и flow offload. Небольшая легенда для примера: <i_if>, <o_if> — это сетевые интерфейсы, через которые проходит трафик, реально их может быть больше двух. <pool_addr_start>,<pool_addr_end> — начальный и конечный адрес диапазона «белых» адресов.
Конфигурация NAT очень проста:
#! /usr/sbin/nft -f table nat { chain postrouting { type nat hook postrouting priority 100; oif <o_if> snat to <pool_addr_start>-<pool_addr_end> persistent } }
С flow offload немного сложнее, но вполне понятно:
#! /usr/sbin/nft -f table inet filter { flowtable fastnat { hook ingress priority 0 devices = { <i_if>, <o_if> } } chain forward { type filter hook forward priority 0; policy accept; ip protocol { tcp , udp } flow offload @fastnat; } }
Вот, собственно, и вся настройка. Теперь весь TCP/UDP трафик будет попадать в таблицу fastnat и обрабатываться намного быстрее.
Результаты
Чтобы стало понятно, насколько это «намного быстрее», я приложу скриншот нагрузки на два реальных сервера, с одинаковой начинкой (Xeon E5-1650v2), одинаково настроенных, использующих одно и тоже ядро Linux, но выполняющих NAT в iptables (NAT4) и в nftables (NAT5).
На скриншоте нет графика пакетов в секунду, но в профиле нагрузки этих серверов средний размер пакета в районе 800 байт, поэтому значения доходят до 1.5Mpps. Как видно, запас производительности у сервера с nftables огромный. На текущий момент этот сервер обрабатывает до 30Gbit/s при 3Mpps и явно способен упереться в физическое ограничение сети 40Gbps, имея при этом свободные ресурсы CPU.
Надеюсь, этот материал будет полезен сетевым инженерам, пытающимся улучшить производительность своих серверов.

