Добрый день уважаемые читатели! Поводом для написания данной публикации послужил вебинар, который я посмотрел на Youtube. Он был посвящен когортному анализу продаж. Автор использовал для работы с данными платформу Power BI Desktop. Ссылку на указанное видео приводить не буду, чтобы эта статья не была расценена как реклама, но по ходу повествования постараюсь делать спойлеры к первоисточнику, чтобы лучше объяснять логику собственного решения. Данный вебинар натолкнул меня на идею, что интересно было бы повторить возможности формул DAХ функциями библиотеки Pandas.
Два момента, на которых хочу заострить внимание. Во-первых, данный материал рассчитан на начинающих аналитиков, которые только делают свои первые шаги в применении языка программирования Python. Идеальный вариант, если читатели обзорно знакомы с платформой для BI-аналитики Power BI. Во-вторых, так как источником вдохновения послужили расчеты DAX, я буду по мере возможности «копировать» алгоритмы автора, при этом неизбежно произойдет отход от основных парадигм программирования.
Со вступительным словом все. В путь!
Проводить все расчеты мы будем в среде JupyterLab. С ноутбуком решения можно ознакомиться по адресу (ссылка).
Загрузка данных в Power BI осуществляется посредством инструмента Power Query (по сути, это визуальный редактор, который генерирует запросы на языке M). При разработке следует придерживаться следующего правила: вся предобработка данных должна производиться с помощью Power Query, а расчет метрик – Power Pivot. Так как наша основная библиотека Pandas, то сразу же задействуем ее возможности.
Строки кода мы будем тестировать на время выполнения, чтобы в дальнейшем установить самые времязатратные участки. Для задания полного пути к считываемому файлу задействуем библиотеку os. Для упрощения процесса разработки ноутбука можно обойтись и без нее. Сам датасет составлен рандомно. Всего в файле формата CSV 1048575 строк. Чтение данных с помощью функции read_csv() обычно не представляет трудностей. Достаточно правильно указать разделитель столбцов и столбец с датами, если такой имеется в массиве. Если информация выгружалась с какими-то «особенностями», то может потребоваться настройка дополнительных параметров, например, указание кодировки для каждой колонки.
В кейсе будет часто применяться функция head(), чтобы визуально следить за ходом трансформации данных. Всех ошибок отсечь не получиться, но вот явные огрехи можно будет исправить на месте.
После загрузки данных в модель автор вебинара сортирует массив данных. Это делается для того, чтобы добавить вспомогательный столбец с индексами. В нашем случае данный столбец использоваться не будет, но вот данные также отсортируем, чтобы удобнее контролировать правильность вычисления полей в таблицах.
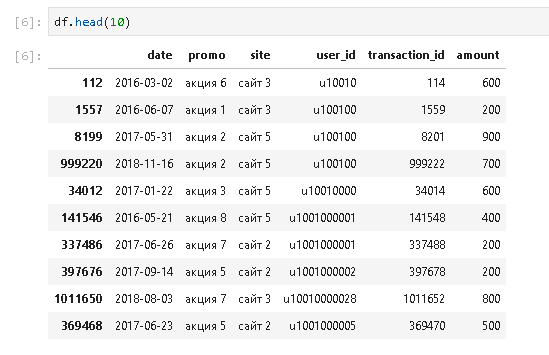
На следующем шаге в решении на платформе Power BI предлагается создать вспомогательную таблицу, данные из которой будут подтягиваться в основной массив. Создание таблицы осуществляется посредством функции SUMMARIZE(). Она создает сводную таблицу с агрегированными итогами по выбранным группам:
В библиотеке Pandas имеется ее аналог – функция groupby(). Чтобы применить groupby() достаточно указать необходимый датафрейм, группируемые столбцы, в конце перечислить столбцы, для которых будет применяться агрегирующие функции. Полученный результат приводим к формату обычного датафрейма функцией reset_index(). В заключение переименовываем поля.
Помимо метрики «дата первой покупки» рассчитано количество транзакций по клиенту и общая сумма покупок клиента за весь период. Измерения не нашли своего применения в ноутбуке, но убирать их не будем.
Возвращаемся к вебинару. Рассчитывается новая метрика «год-месяц первой покупки». Формула DAX:
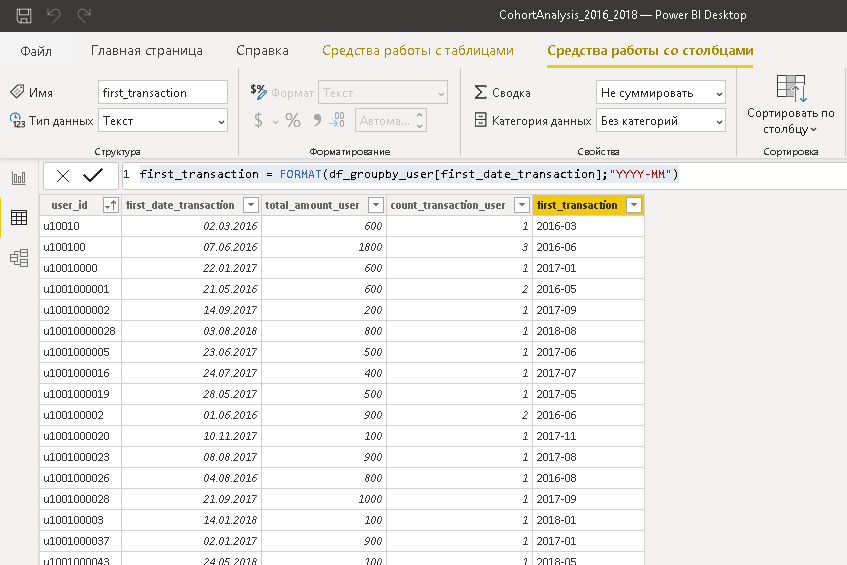
В Python применяется синтаксическая конструкция dt.strftime('%Y-%m'). Подробное объяснение, как она работает, вы найдете в интернет-публикациях, касающихся работы с датой и временем в Python. На данном шаге важно другое. Обратите внимание на время выполнения операции.
Совсем не pandas-ное быстродействие (24,8 сек.). Строка кода медленнее всех предыдущих.
Этот кусок листинга становиться первым кандидатом на возможный рефакторинг.
Настало время вновь возвратиться к вебинару. Там происходит объединение таблиц по ключевому полю. После чего необходимые поля подтягиваются в основную таблицу с помощью функции RELATED(). В Pandas такой функции нет. Но есть merge(), join(), concat(). В данном случае лучше всего применить первый вариант.
После того как данные с датой первой транзакции попали в основную таблицу, можно рассчитать дельту. Применяем конструкцию apply(lambda x:…), чтобы наглядно продемонстрировать насколько это ресурсоемкий процесс (39,7 сек.). Вот еще один кандидат на переписывание кода.
В основной таблице уже есть дельта по дням, поэтому можно поделить данные столбца на когорты. Принцип: 0 (то есть первая продажа клиенту) – когорта 0; значения больше 0, но меньше или равно 30 это 30; значения больше 30, но меньше или равно 90 это 90 и т.д. Для этих целей в DAX можно применить функцию CEILING(). Она выполняет округление числа в большую сторону до ближайшего целого, кратно значению из второго параметра.
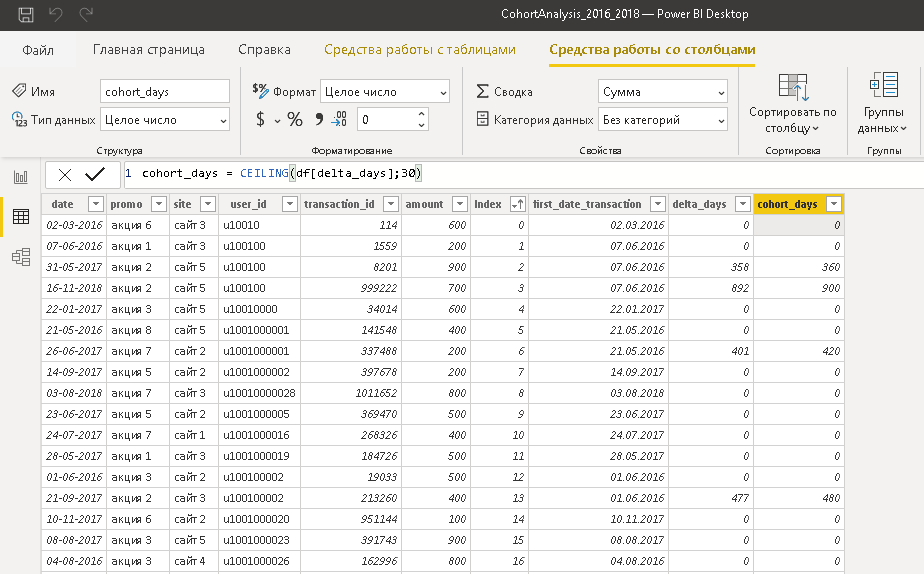
В Python я не нашел подобной математической функции, хотя планировал ее обнаружить в модуле math (возможно плохо искал). Поэтому пришлось пойти обходным путем и применить функцию cut(). После разнесения данных на когорты, числовым значениям 0 сопоставилось NaN. Решить эту проблему, применив функцию fillna(), здесь не получиться, так как мы имеем дело с категориальными данными. Сначала нужно добавить новое значение в категории. В конце данного листинга кода меняем тип данных на int. Это сделано для того, чтобы в дальнейшем при построении сводной таблицы по датафрейму новая когорта не оказалась в конце ряда значений.
С помощью функции pivot_table() мы получаем искомую сводную таблицу. У нас получись довольно много когорт, поэтому результат не может целиком отобразиться на экране. Чтобы избежать этого при решении реального кейса можно взять для анализа меньший временной промежуток или укрупнить диапазоны значений самих когорт.
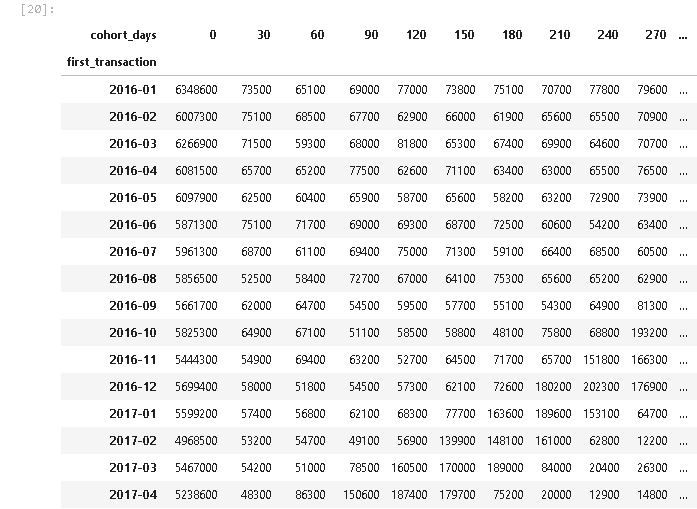
В Power BI для построения такой визуализации нужно применить инструмент «Матрица».

Следующий этап — построение графика. Нюанс ситуации состоит в том, что нам необходима сумма нарастающим итогом. В Power BI достаточно выбрать необходимый пункт меню 'Быстрые меры' и автоматически будет сгенерирована необходимая формула DAX. С библиотекой Pandas ситуация чуть сложнее. Подвергнем двойной последовательной группировке уже имеющийся датафрейм и применим функцию cumsum(). Так как полученный результат будет еще использоваться, то для построения графика сделаем копию датафрейма. Аккумулированные значения продаж получились довольно большие, поэтому разделим значения на 1000000 и округлим полученный результат до двух цифр после запятой.
Задействуем возможности библиотеки для построения графика. Строится диаграмма буквально одной строчкой кода, но результат не впечатляет. Данный график явно проигрывает визуализациям на любой платформе BI. Можно подключить библиотеку Plotly и поколдовать с надстройками, но это уже совсем другие трудозатраты по сравнению с подходом, продемонстрированным в видео.

Сделаем краткие выводы.
В плане расчетов библиотека Pandas вполне может подменить Power Pivot (DAX).
Целесообразность такой замены остается за скобками разговора.
DAX, как и функции библиотеки Python, хорошо справляются с операциями, проводимыми над целыми полями таблицы.
В плане скорости, простоты и удобства разработки визуализаций Power BI превосходит Pandas. На мой взгляд встроенные графики (равно как и создаваемые с помощью библиотек matplotlib, seaborn) уместно применять в двух случаях: экспресс-анализ ряда данных на наличие выбросов, локальных минимумов/максимумов или подготовка слайдов для презентации. Разработку графических управленческих панелей лучше отдать на откуп BI-решениям.
На этом все. Всем здоровья, удачи и профессиональных успехов!
Два момента, на которых хочу заострить внимание. Во-первых, данный материал рассчитан на начинающих аналитиков, которые только делают свои первые шаги в применении языка программирования Python. Идеальный вариант, если читатели обзорно знакомы с платформой для BI-аналитики Power BI. Во-вторых, так как источником вдохновения послужили расчеты DAX, я буду по мере возможности «копировать» алгоритмы автора, при этом неизбежно произойдет отход от основных парадигм программирования.
Со вступительным словом все. В путь!
Проводить все расчеты мы будем в среде JupyterLab. С ноутбуком решения можно ознакомиться по адресу (ссылка).
Загрузка данных в Power BI осуществляется посредством инструмента Power Query (по сути, это визуальный редактор, который генерирует запросы на языке M). При разработке следует придерживаться следующего правила: вся предобработка данных должна производиться с помощью Power Query, а расчет метрик – Power Pivot. Так как наша основная библиотека Pandas, то сразу же задействуем ее возможности.
%%time #Укажем путь к исходнику path_to_data = "C:/Users/Pavel/Documents/Demo/" #Загружаем данные df = pd.read_csv(os.path.join(path_to_data, "СohortAnalysis_2016_2018.csv"), sep=";", parse_dates=["date"], dayfirst=True)
Строки кода мы будем тестировать на время выполнения, чтобы в дальнейшем установить самые времязатратные участки. Для задания полного пути к считываемому файлу задействуем библиотеку os. Для упрощения процесса разработки ноутбука можно обойтись и без нее. Сам датасет составлен рандомно. Всего в файле формата CSV 1048575 строк. Чтение данных с помощью функции read_csv() обычно не представляет трудностей. Достаточно правильно указать разделитель столбцов и столбец с датами, если такой имеется в массиве. Если информация выгружалась с какими-то «особенностями», то может потребоваться настройка дополнительных параметров, например, указание кодировки для каждой колонки.
В кейсе будет часто применяться функция head(), чтобы визуально следить за ходом трансформации данных. Всех ошибок отсечь не получиться, но вот явные огрехи можно будет исправить на месте.
После загрузки данных в модель автор вебинара сортирует массив данных. Это делается для того, чтобы добавить вспомогательный столбец с индексами. В нашем случае данный столбец использоваться не будет, но вот данные также отсортируем, чтобы удобнее контролировать правильность вычисления полей в таблицах.
%%time #Отфильтруем массив так, чтобы визуально контролировать правильно дальнейших действий df.sort_values(["user_id","date"], inplace = True)
На следующем шаге в решении на платформе Power BI предлагается создать вспомогательную таблицу, данные из которой будут подтягиваться в основной массив. Создание таблицы осуществляется посредством функции SUMMARIZE(). Она создает сводную таблицу с агрегированными итогами по выбранным группам:
df_groupby_user = SUMMARIZE(df;df[user_id];"first_date_transaction";MIN(df[date]);"total_amount_user";SUM(df[amount]);"count_transaction_user";COUNT(df[amount]))В библиотеке Pandas имеется ее аналог – функция groupby(). Чтобы применить groupby() достаточно указать необходимый датафрейм, группируемые столбцы, в конце перечислить столбцы, для которых будет применяться агрегирующие функции. Полученный результат приводим к формату обычного датафрейма функцией reset_index(). В заключение переименовываем поля.
%%time #Построим вспомогательную таблицу путем группировки по полю user_id. df_groupby_user = df.groupby(by = ["user_id"]).agg({"date": "min", "amount": ["sum","count"]}) df_groupby_user.reset_index(inplace = True) #Переименуем столбцы new_columns = ["user_id","first_date_transaction", "total_amount_user","count_transaction_user"] df_groupby_user.columns = new_columns
Помимо метрики «дата первой покупки» рассчитано количество транзакций по клиенту и общая сумма покупок клиента за весь период. Измерения не нашли своего применения в ноутбуке, но убирать их не будем.
Возвращаемся к вебинару. Рассчитывается новая метрика «год-месяц первой покупки». Формула DAX:
first_transaction = FORMAT(df_groupby_user[first_date_transaction];"YYYY-MM")В Python применяется синтаксическая конструкция dt.strftime('%Y-%m'). Подробное объяснение, как она работает, вы найдете в интернет-публикациях, касающихся работы с датой и временем в Python. На данном шаге важно другое. Обратите внимание на время выполнения операции.
Совсем не pandas-ное быстродействие (24,8 сек.). Строка кода медленнее всех предыдущих.
Этот кусок листинга становиться первым кандидатом на возможный рефакторинг.
%%time #Добавим столбец ГОД-МЕСЯЦ df_groupby_user["first_transaction"] = df_groupby_user["first_date_transaction"].dt.strftime('%Y-%m')
Настало время вновь возвратиться к вебинару. Там происходит объединение таблиц по ключевому полю. После чего необходимые поля подтягиваются в основную таблицу с помощью функции RELATED(). В Pandas такой функции нет. Но есть merge(), join(), concat(). В данном случае лучше всего применить первый вариант.
%%time #Объединим таблицы df_final = pd.merge(df, df_groupby_user, how = "left", on = "user_id")
После того как данные с датой первой транзакции попали в основную таблицу, можно рассчитать дельту. Применяем конструкцию apply(lambda x:…), чтобы наглядно продемонстрировать насколько это ресурсоемкий процесс (39,7 сек.). Вот еще один кандидат на переписывание кода.
%%time # Рассчитаем показатель "количество дней с первой транзакции" df_final["delta_days"] = df_final["date"] - df_final["first_date_transaction"] df_final["delta_days"] = df_final["delta_days"].apply(lambda x: x.days)
В основной таблице уже есть дельта по дням, поэтому можно поделить данные столбца на когорты. Принцип: 0 (то есть первая продажа клиенту) – когорта 0; значения больше 0, но меньше или равно 30 это 30; значения больше 30, но меньше или равно 90 это 90 и т.д. Для этих целей в DAX можно применить функцию CEILING(). Она выполняет округление числа в большую сторону до ближайшего целого, кратно значению из второго параметра.
В Python я не нашел подобной математической функции, хотя планировал ее обнаружить в модуле math (возможно плохо искал). Поэтому пришлось пойти обходным путем и применить функцию cut(). После разнесения данных на когорты, числовым значениям 0 сопоставилось NaN. Решить эту проблему, применив функцию fillna(), здесь не получиться, так как мы имеем дело с категориальными данными. Сначала нужно добавить новое значение в категории. В конце данного листинга кода меняем тип данных на int. Это сделано для того, чтобы в дальнейшем при построении сводной таблицы по датафрейму новая когорта не оказалась в конце ряда значений.
%%time # Выделяем когорты. cut_labels_days = [x for x in range (30, 1230, 30)] cut_bins_days = [x for x in range (0, 1230, 30)] df_final["cohort_days"] = pd.cut(df_final["delta_days"], bins = cut_bins_days, labels=cut_labels_days, right = True) %%time #Заменяем нулевые значения в категориальных данных. Просто променить fillna здесь не получиться! df_final["cohort_days"] = df_final["cohort_days"].cat.add_categories([0]) df_final["cohort_days"].fillna(0, inplace = True) %%time #Заменяем нулевые значения в категориальных данных. Просто применить fillna здесь не получиться! df_final["cohort_days"] = df_final["cohort_days"].cat.add_categories([0]) df_final["cohort_days"].fillna(0, inplace = True) #Уходим от категориального типа данных. Если оставить данный тип, то "0" в сводной таблице будет отображаться в самом конце, а по условию задачи # он должен выводиться первым. df_final["cohort_days"] = df_final["cohort_days"].astype(int)
С помощью функции pivot_table() мы получаем искомую сводную таблицу. У нас получись довольно много когорт, поэтому результат не может целиком отобразиться на экране. Чтобы избежать этого при решении реального кейса можно взять для анализа меньший временной промежуток или укрупнить диапазоны значений самих когорт.
%%time #Построим сводную таблицу df_pivot_table = pd.pivot_table(df_final, values=["amount"], index=["first_transaction"], columns=["cohort_days"], aggfunc=np.sum, fill_value = 0)
В Power BI для построения такой визуализации нужно применить инструмент «Матрица».
Следующий этап — построение графика. Нюанс ситуации состоит в том, что нам необходима сумма нарастающим итогом. В Power BI достаточно выбрать необходимый пункт меню 'Быстрые меры' и автоматически будет сгенерирована необходимая формула DAX. С библиотекой Pandas ситуация чуть сложнее. Подвергнем двойной последовательной группировке уже имеющийся датафрейм и применим функцию cumsum(). Так как полученный результат будет еще использоваться, то для построения графика сделаем копию датафрейма. Аккумулированные значения продаж получились довольно большие, поэтому разделим значения на 1000000 и округлим полученный результат до двух цифр после запятой.
%%time #Подсчитываем накопительный итог по столбцу amount df_pivot_table_cumsum = df_final.groupby(by = ["first_transaction","cohort_days"]).agg({"amount": ["sum"]}).groupby(level=0).cumsum().reset_index() df_pivot_table_cumsum.columns = ["first_transaction","cohort_days","cumsum_amount"] %%time #Создадим копию таблицы для построения графика df_pivot_table_cumsum_chart = copy.deepcopy(df_pivot_table_cumsum) #Приведем числовые данные к миллионам рублей, чтобы упростить читаемость значений на оси Y. df_pivot_table_cumsum_chart["cumsum_amount"]=round(df_pivot_table_cumsum_chart["cumsum_amount"]/1000000, 2)
Задействуем возможности библиотеки для построения графика. Строится диаграмма буквально одной строчкой кода, но результат не впечатляет. Данный график явно проигрывает визуализациям на любой платформе BI. Можно подключить библиотеку Plotly и поколдовать с надстройками, но это уже совсем другие трудозатраты по сравнению с подходом, продемонстрированным в видео.
%%time df_pivot_table_cumsum_chart.pivot(index="cohort_days", columns="first_transaction", values="cumsum_amount").plot(figsize = (15,11))
Сделаем краткие выводы.
В плане расчетов библиотека Pandas вполне может подменить Power Pivot (DAX).
Целесообразность такой замены остается за скобками разговора.
DAX, как и функции библиотеки Python, хорошо справляются с операциями, проводимыми над целыми полями таблицы.
В плане скорости, простоты и удобства разработки визуализаций Power BI превосходит Pandas. На мой взгляд встроенные графики (равно как и создаваемые с помощью библиотек matplotlib, seaborn) уместно применять в двух случаях: экспресс-анализ ряда данных на наличие выбросов, локальных минимумов/максимумов или подготовка слайдов для презентации. Разработку графических управленческих панелей лучше отдать на откуп BI-решениям.
На этом все. Всем здоровья, удачи и профессиональных успехов!

