Darknet YOLOv4 быстрее и точнее, чем real-time нейронные сети Google TensorFlow EfficientDet и FaceBook Pytorch/Detectron RetinaNet/MaskRCNN.
Эта же статья на medium: medium
Код: github.com/AlexeyAB/darknet
Статья: arxiv.org/abs/2004.10934
Обсуждение YOLOv4-tiny 1770 FPS: www.reddit.com/r/MachineLearning/comments/hu7lyt/p_yolov4tiny_speed_1770_fps_tensorrtbatch4
Обсуждение: www.reddit.com/r/MachineLearning/comments/gydxzd/p_yolov4_the_most_accurate_realtime_neural

Мы покажем некоторые нюансы сравнения и использования нейронных сетей для обнаружения объектов.
Нашей целью было разработать алгоритм обнаружения объектов для использования в реальных продуктах, а не только двигать науку вперед. Точность нейросети YOLOv4 (608x608) – 43.5% AP / 65.7% AP50 Microsoft-COCO-testdev.
62 FPS – YOLOv4 (608x608 batch=1) on Tesla V100 – by using Darknet-framework
400 FPS – YOLOv4 (320x320 batch=4) on RTX 2080 Ti – by using TensorRT+tkDNN
32 FPS – YOLOv4 (416x416 batch=1) on Jetson AGX Xavier – by using TensorRT+tkDNN

Наша нейронная сеть YOLOv4 и наш собственный DL-фреймворк Darknet (C/C++/CUDA) лучше по скорости FPS и точности AP50:95 и AP50 на датасете Microsoft COCO, чем DL-фреймворки и нейронные-сети: Google TensorFlow EfficientDet, FaceBook Detectron RetinaNet/MaskRCNN, PyTorch Yolov3-ASFF, и многие другие… YOLOv4 достигает точности 43.5% AP / 65.7% AP50 на тесте Microsoft COCO при скорости 62 FPS TitanV или 34 FPS RTX 2070. В отличии от других современных детекторов, YOLOv4 может обучить любой, у кого есть игровая видеокарта nVidia с 8-16 GB VRAM. Теперь не только крупные компании могут обучать нейронную сеть на сотнях GPU / TPU для использования больших размеров mini-batch для достижения более высокой точности, поэтому мы возвращаем контроль над искусственным интеллектом обычным пользователям, потому что для YOLOv4 большая мини-партия не требуется, можно ограничиться размером 2 – 8.
YOLOV4- оптимальная для использования real-time, т.к. сеть лежит на кривой оптимальности по Парето на графике AP(accuracy) / FPS(speed).

Графики точности (AP) и скорости (FPS) множества нейронных сетей для обнаружения объектов замеренных на видеокартах GPU TitanV/TeslaV100, TitanXP/TeslaP100, TitanX/TeslaM40 для двух основных индикаторов точности AP50:95 и AP50
Для честного сравнения мы берём данные из статей и сравниваем только на GPU с одинаковой архитектурой.
У большинства практических задач есть минимально необходимые требования к детекторам – это минимально допустимые точность и скорость. Обычно минимально допустимая скорость от 30 FPS (кадров в секунду) и выше для real-time систем.
Как видно из графиков, в Real-time системах с FPS 30 и более:
Т.е. YOLOv4 требует в 5 раза более дешевое оборудование и при этом точнее, чем EfficientDet-D2 (Google-TensorFlow). Можно использовать EfficientDet-D0 (Google-TensorFlow) тогда стоимость оборудования будет одинаковая, но точность будет на 10% AP ниже.
Кроме того, некоторые промышленные системы имеют ограничения по тепловыделению или по использованию пассивной системы охлаждения – в этом случае вы не сможете использовать TitanV даже имея деньги.
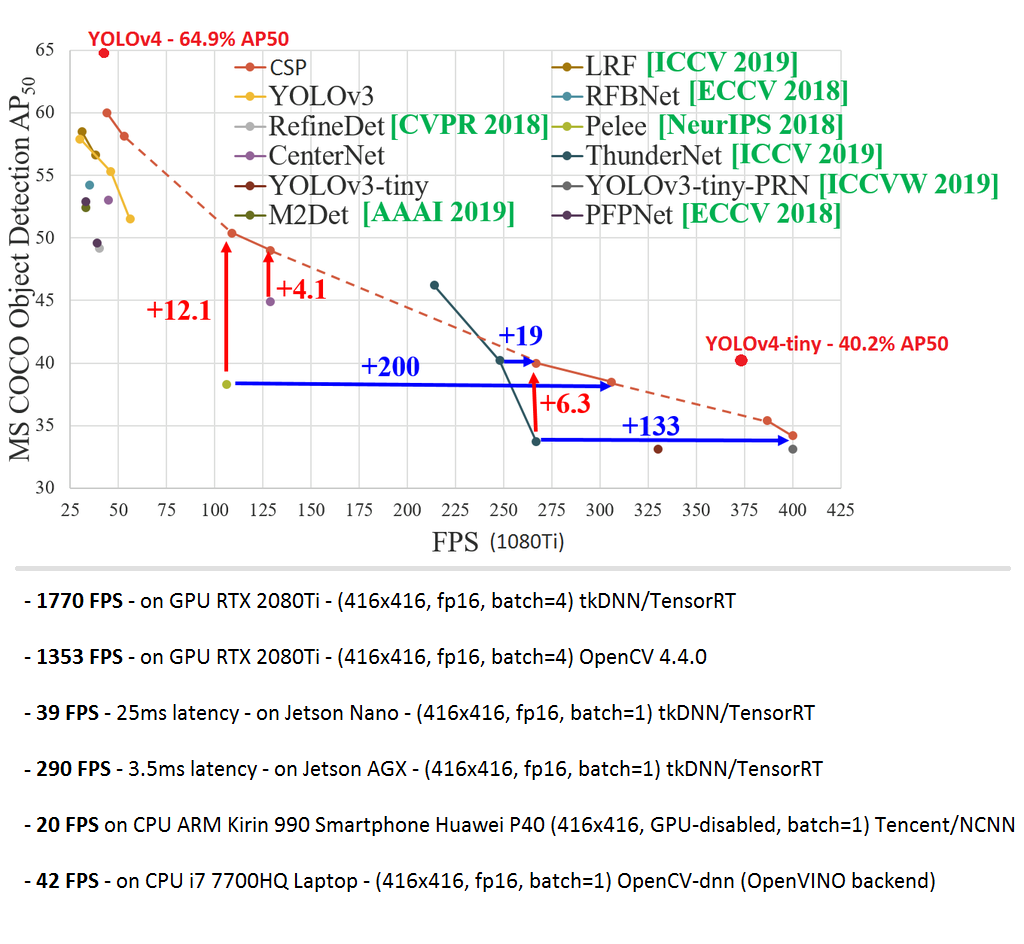
При использовании YOLOv4 (416x416) на GPU RTX 2080 Ti с использованием TensorRT+tkDNN мы достигаем скорость в 2x раза больше, а при использовании batch=4 в 3x-4x раза больше – для честного сравнения мы не приводим эти результаты в статье на arxiv.org:

Нейронная сеть YOLOv4 (416x416) FP16 (Tensor Cores) batch=1 достигает 32 FPS на вычислителе nVidia Jetson AGX Xavier при использовании библиотеки TensorRT+tkDNN: github.com/ceccocats/tkDNN
Чуть меньшую скорость дает библиотека OpenCV-dnn скомпилированная с CUDA: docs.opencv.org/master/da/d9d/tutorial_dnn_yolo.html
Так же вышла модель YOLOv4-tiny с экстремально высокой скоростью 370 FPS на GPU 1080ti, или 16 FPS на Jetson Nano (max_N, 416x416, batch=1, Darknet-framework). Со скоростью до 1000 FPS используя OpenCV / tkDNN-TensorRT: github.com/AlexeyAB/darknet/issues/6067
Обсуждение на: Reddit
Иногда скорость (FPS) некоторых нейронных сетей в статьях указывается при использовании высокого batch size или при тестировании на специализированном программном обеспечении (TensorRT), которое оптимизирует сеть и показывает повышенное значение FPS. Сравнение одних сетей на TRT с другими сетями без TRT не является честным. Использование высокого batch size увеличивает FPS, но также увеличивает задержку (а не уменьшает её) по сравнению с batch=1. Если сеть с batch=1 показывает 40 FPS, а с batch=32 показывает 60 FPS, то задержка будет 25ms для batch=1, и ~500ms для batch=32, т.к. будут обрабатываться только ~2 пакета (по 32 изображения) в секунду, из-за этого использование batch=32 неприемлемо во многих промышленных системах. Поэтому мы сравнивали на графиках результаты только c batch=1 и без использования TensorRT.
Любой процесс может управляться либо людьми, либо компьютерами. Когда компьютерная система действует с большим запаздыванием из-за малой скорости и совершает слишком много ошибок, то ей нельзя доверить полное управление действиями, в этом случае процессом управляет человек, а компьютерная система только дает подсказки – это рекомендательная система – человек работает, а система только подсказывает где были совершены ошибки. Когда же система работает быстро и с высокой точностью, такая система может управлять процессом самостоятельно, а человек только присматривает за ней. Поэтому всегда важны и точность, и скорость системы. Если вам кажется, что 120 FPS для YOLOv4 416x416 это слишком много для вашей задачи, и лучше взять алгоритм медленнее и точнее, то скорее всего в реальных задачах вы будете использовать что-то слабее, чем Tesla V100 250 Watt, например, RTX 2060/Jetson-Xavier 30-80 Watt, в этом случае вы получите 30 FPS на YOLOv4 416x416, а другие нейронные сети по 1-15 FPS или вообще не запустятся.
Вы должны обучать EfficientDet с размером mini-batch = 128 на нескольких GPU Tesla V100 32GB, в то время как YOLOv4 была обучена всего на одной GPU Tesla V100 32GB с mini-batch = 8 = batch/subdivisions, и может быть обучена на обычной игровой видеокарте 8-16GB GPU-VRAM.
Следующий нюанс, трудность обучения нейронной сети для обнаружения собственных объектов. Сколько бы времени вы не обучали другие сети на одной GPU 1080 Ti, вы не получите заявленной точности, показанной на графике выше. Большинство сетей (EfficientDet, ASFF, …) надо обучать на 4 – 128 GPUs (с большим размером mini-batch используя syncBN) и надо обучать каждый раз заново для каждого разрешения сети, без выполнения обоих условий невозможно достичь заявленной ими точности AP или AP50.

Вы можете видеть зависимость точности обнаружения объектов от размера минибатча в других детекторах, т.е. используя 128 видеокарт вместо 8 видеокарт и скорость обучения в 10 раз выше и конечная точность на 1.5 AP выше – MegDet: A Large Mini-Batch Object Detector arxiv.org/abs/1711.07240
Yolo ASFF: arxiv.org/abs/1911.09516
EfficientDet: arxiv.org/abs/1911.09070
cloud.google.com/tpu/docs/types-zones#europe
Вы должны использовать 512 GB TPU/GPU-RAM чтобы обучить модель EfficientDet с Synchronized batch normalization при batch=128, в то время как для обучения YOLOv4 использовался mini-batch=8 и только 32 GB GPU-RAM. Несмотря на это, YOLOv4 быстрее/точнее публичных сетей, хотя обучена только 1 раз с разрешением 512x512 на 1 GPU (Tesla V100 32GB / 16GB). При этом использование меньшего размера mini-batch size и GPU-VRAM не приводит к такой драматической потери точности, как в других нейронных сетях:
Источник: arxiv.org/abs/2004.10934
Так что вы можете обучать искусственный интеллект локально на своем ПК, вместо загрузки датасета в облако – это гарантирует защиту ваших персональных данных и делает обучение искусственного интеллекта доступным каждому.
Нашу сеть достаточно обучить один раз с network resolution 512x512, и затем можно использовать с разными network resolutions в диапазоне: [416x416 – 512x512 – 608x608].
Большинство же других моделей требуется обучать каждый раз отдельно для каждого network resolution, из-за этого обучение занимает в разы больше времени.
Всегда можно найти изображение, на котором один алгоритм будет работать плохо, а другой алгоритм будет работать хорошо, и наоборот. Поэтому для тестирования алгоритмов обнаружения используется большой набор из ~20 000 изображений и 80 различных типов объектов — MSCOCO test-dev dataset.
Чтобы алгоритм не пытался просто запомнить хэш каждого изображения и координаты на нем (overfitting), точность обнаружения объектов всегда проверяется на изображениях и метках, которые алгоритм не видел во время обучения – это гарантирует, что алгоритм сможет обнаруживать объекты на изображениях/видео, которые он никогда не видел.
Чтобы никто не мог совершить ошибку в расчете точности, в открытом доступе есть только тестовые изображения test-dev, на которых вы производите обнаружение, а результаты отправляете на CodaLab evaluation server, на котором программа сама сравнивает ваши результаты с тестовыми аннотациями, которые никому не доступны.
MSCOCO dataset состоит из 3-ех частей
При разработке YOLOv4 мне приходилось самому разрабатывать и нейронную сеть YOLOv4 и фреймворк Darknet на C/C++/CUDA. Т.к. в Darknet нет автоматического дифференцирования и автоматического выполнения chain-rule, то все градиенты приходится реализовывать вручную на CUDA C++. С другой стороны, мы можем отходить от строгого следования chain-rule, изменять backpropagation и пробовать очень нетривиальные вещи для повышения стабильности обучения и точности.
Обнаружение объектов с помощью обученных моделей YOLOv4 встроено в библиотеку OpenCV-dnn github.com/opencv/opencv/issues/17148 так что вы можете использовать YOLOv4 напрямую из OpenCV без использования фреймворка Darknet. Библиотека OpenCV поддерживает выполнение нейронных сетей на CPU, GPU (nVidia GPU), VPU (Intel Myriad X). Подробнее: docs.opencv.org/master/da/d9d/tutorial_dnn_yolo.html
OpenCV (dnn) framework:
Darknet framework:
tkDNN+TensorRT — Максимальная скорость обнаружения объектов используя YOLOv4: TensorRT + tkDNN github.com/ceccocats/tkDNN
Tencent-NCNN (C/C++/GLSL) — Максимальная скорость обнаружения объектов на Смартфонах (iOS / Android) используя YOLOv4 без каких-либо дополнительных библиотек или любых зависимостей: github.com/Tencent/ncnn
Использование YOLOv4 может быть расширено до обнаружения 3D-Rotated-Bboxes или ключевых точек / facial landmarks, например:
* 3D-Rotated-Bboxes: github.com/maudzung/Complex-YOLOv4-Pytorch

* Key-points / facial-landmarks: github.com/ouyanghuiyu/darknet_face_with_landmark

Эта же статья на medium: medium
Код: github.com/AlexeyAB/darknet
Статья: arxiv.org/abs/2004.10934
Обсуждение YOLOv4-tiny 1770 FPS: www.reddit.com/r/MachineLearning/comments/hu7lyt/p_yolov4tiny_speed_1770_fps_tensorrtbatch4
Обсуждение: www.reddit.com/r/MachineLearning/comments/gydxzd/p_yolov4_the_most_accurate_realtime_neural
Мы покажем некоторые нюансы сравнения и использования нейронных сетей для обнаружения объектов.
Нашей целью было разработать алгоритм обнаружения объектов для использования в реальных продуктах, а не только двигать науку вперед. Точность нейросети YOLOv4 (608x608) – 43.5% AP / 65.7% AP50 Microsoft-COCO-testdev.
62 FPS – YOLOv4 (608x608 batch=1) on Tesla V100 – by using Darknet-framework
400 FPS – YOLOv4 (320x320 batch=4) on RTX 2080 Ti – by using TensorRT+tkDNN
32 FPS – YOLOv4 (416x416 batch=1) on Jetson AGX Xavier – by using TensorRT+tkDNN
Для начала несколько полезных ссылок
- Подробное описание фич использованных в YOLOv4 можете прочитать в этой статье: medium.com/@jonathan_hui/yolov4-c9901eaa8e61
- Полная структура YOLOv4: https://netron.app/?url=https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolo.cfg
- Пошаговая инструкция компиляции и использования YOLOv4 на GPU в облаке Google-cloud используя Jupyter Notebook – вам просто нужно перейти по ссылке, нажать кнопку сверху-слева «Copy to Drive», а затем последовательно нажимать стрелочки в квадратных скобках [ ] – вы увидите все команды, которые выполняются, их результаты, а на Шаге 5 изображение с обнаруженными объектами:
Как скомпилировать и запустить Обнаружение объектов в облаке бесплатно:
- colab: colab.research.google.com/drive/12QusaaRj_lUwCGDvQNfICpa7kA7_a2dE
- video: www.youtube.com/watch?v=mKAEGSxwOAY
Как скомпилировать и запустить Обучение в облаке бесплатно:
- colab: colab.research.google.com/drive/1_GdoqCJWXsChrOiY8sZMr_zbr_fH-0Fg?usp=sharing
- video: youtu.be/mmj3nxGT2YQ
- Как использовать Darknet на своем компьютере:
— как установить Darknet YOLOv4
— как запустить Darknet YOLOv4
Сравнение различных нейронных сетей
Наша нейронная сеть YOLOv4 и наш собственный DL-фреймворк Darknet (C/C++/CUDA) лучше по скорости FPS и точности AP50:95 и AP50 на датасете Microsoft COCO, чем DL-фреймворки и нейронные-сети: Google TensorFlow EfficientDet, FaceBook Detectron RetinaNet/MaskRCNN, PyTorch Yolov3-ASFF, и многие другие… YOLOv4 достигает точности 43.5% AP / 65.7% AP50 на тесте Microsoft COCO при скорости 62 FPS TitanV или 34 FPS RTX 2070. В отличии от других современных детекторов, YOLOv4 может обучить любой, у кого есть игровая видеокарта nVidia с 8-16 GB VRAM. Теперь не только крупные компании могут обучать нейронную сеть на сотнях GPU / TPU для использования больших размеров mini-batch для достижения более высокой точности, поэтому мы возвращаем контроль над искусственным интеллектом обычным пользователям, потому что для YOLOv4 большая мини-партия не требуется, можно ограничиться размером 2 – 8.
YOLOV4- оптимальная для использования real-time, т.к. сеть лежит на кривой оптимальности по Парето на графике AP(accuracy) / FPS(speed).
Графики точности (AP) и скорости (FPS) множества нейронных сетей для обнаружения объектов замеренных на видеокартах GPU TitanV/TeslaV100, TitanXP/TeslaP100, TitanX/TeslaM40 для двух основных индикаторов точности AP50:95 и AP50
Для честного сравнения мы берём данные из статей и сравниваем только на GPU с одинаковой архитектурой.
У большинства практических задач есть минимально необходимые требования к детекторам – это минимально допустимые точность и скорость. Обычно минимально допустимая скорость от 30 FPS (кадров в секунду) и выше для real-time систем.
Как видно из графиков, в Real-time системах с FPS 30 и более:
- для YOLOv4-608 необходимо использовать RTX 2070 за 450$ (34 FPS) с точностью 43.5% AP / 65.7% AP50
- для EfficientDet-D2 необходимо использовать TitanV за 2250$ (42 FPS) с точностью 43.0% AP / 62.3% AP50
- для EfficientDet-D0 необходимо использовать RTX 2070 за 450$ (34 FPS) с точностью 33.8% AP / 52.2% AP50
Т.е. YOLOv4 требует в 5 раза более дешевое оборудование и при этом точнее, чем EfficientDet-D2 (Google-TensorFlow). Можно использовать EfficientDet-D0 (Google-TensorFlow) тогда стоимость оборудования будет одинаковая, но точность будет на 10% AP ниже.
Кроме того, некоторые промышленные системы имеют ограничения по тепловыделению или по использованию пассивной системы охлаждения – в этом случае вы не сможете использовать TitanV даже имея деньги.
При использовании YOLOv4 (416x416) на GPU RTX 2080 Ti с использованием TensorRT+tkDNN мы достигаем скорость в 2x раза больше, а при использовании batch=4 в 3x-4x раза больше – для честного сравнения мы не приводим эти результаты в статье на arxiv.org:
Нейронная сеть YOLOv4 (416x416) FP16 (Tensor Cores) batch=1 достигает 32 FPS на вычислителе nVidia Jetson AGX Xavier при использовании библиотеки TensorRT+tkDNN: github.com/ceccocats/tkDNN
Чуть меньшую скорость дает библиотека OpenCV-dnn скомпилированная с CUDA: docs.opencv.org/master/da/d9d/tutorial_dnn_yolo.html
Так же вышла модель YOLOv4-tiny с экстремально высокой скоростью 370 FPS на GPU 1080ti, или 16 FPS на Jetson Nano (max_N, 416x416, batch=1, Darknet-framework). Со скоростью до 1000 FPS используя OpenCV / tkDNN-TensorRT: github.com/AlexeyAB/darknet/issues/6067
Обсуждение на: Reddit
Иногда скорость (FPS) некоторых нейронных сетей в статьях указывается при использовании высокого batch size или при тестировании на специализированном программном обеспечении (TensorRT), которое оптимизирует сеть и показывает повышенное значение FPS. Сравнение одних сетей на TRT с другими сетями без TRT не является честным. Использование высокого batch size увеличивает FPS, но также увеличивает задержку (а не уменьшает её) по сравнению с batch=1. Если сеть с batch=1 показывает 40 FPS, а с batch=32 показывает 60 FPS, то задержка будет 25ms для batch=1, и ~500ms для batch=32, т.к. будут обрабатываться только ~2 пакета (по 32 изображения) в секунду, из-за этого использование batch=32 неприемлемо во многих промышленных системах. Поэтому мы сравнивали на графиках результаты только c batch=1 и без использования TensorRT.
Любой процесс может управляться либо людьми, либо компьютерами. Когда компьютерная система действует с большим запаздыванием из-за малой скорости и совершает слишком много ошибок, то ей нельзя доверить полное управление действиями, в этом случае процессом управляет человек, а компьютерная система только дает подсказки – это рекомендательная система – человек работает, а система только подсказывает где были совершены ошибки. Когда же система работает быстро и с высокой точностью, такая система может управлять процессом самостоятельно, а человек только присматривает за ней. Поэтому всегда важны и точность, и скорость системы. Если вам кажется, что 120 FPS для YOLOv4 416x416 это слишком много для вашей задачи, и лучше взять алгоритм медленнее и точнее, то скорее всего в реальных задачах вы будете использовать что-то слабее, чем Tesla V100 250 Watt, например, RTX 2060/Jetson-Xavier 30-80 Watt, в этом случае вы получите 30 FPS на YOLOv4 416x416, а другие нейронные сети по 1-15 FPS или вообще не запустятся.
Особенности обучения различных нейронных сетей
Вы должны обучать EfficientDet с размером mini-batch = 128 на нескольких GPU Tesla V100 32GB, в то время как YOLOv4 была обучена всего на одной GPU Tesla V100 32GB с mini-batch = 8 = batch/subdivisions, и может быть обучена на обычной игровой видеокарте 8-16GB GPU-VRAM.
Следующий нюанс, трудность обучения нейронной сети для обнаружения собственных объектов. Сколько бы времени вы не обучали другие сети на одной GPU 1080 Ti, вы не получите заявленной точности, показанной на графике выше. Большинство сетей (EfficientDet, ASFF, …) надо обучать на 4 – 128 GPUs (с большим размером mini-batch используя syncBN) и надо обучать каждый раз заново для каждого разрешения сети, без выполнения обоих условий невозможно достичь заявленной ими точности AP или AP50.
Вы можете видеть зависимость точности обнаружения объектов от размера минибатча в других детекторах, т.е. используя 128 видеокарт вместо 8 видеокарт и скорость обучения в 10 раз выше и конечная точность на 1.5 AP выше – MegDet: A Large Mini-Batch Object Detector arxiv.org/abs/1711.07240
Yolo ASFF: arxiv.org/abs/1911.09516
Following [43], we introduce a bag of tricks in the training process, such as the mixup algorithm [12], the cosine [26] learning rate schedule, and the synchronized batch normalization technique [30].
EfficientDet: arxiv.org/abs/1911.09070
Synchronized batch normalization is added after every convolution with batch norm decay 0.99 and epsilon 1e-3.
Each model is trained 300 epochs with batch total size 128 on 32 TPUv3 cores.
cloud.google.com/tpu/docs/types-zones#europe
v3-32 TPU type (v3) – 32 TPU v3 cores – 512 GiB Total TPU memory
Вы должны использовать 512 GB TPU/GPU-RAM чтобы обучить модель EfficientDet с Synchronized batch normalization при batch=128, в то время как для обучения YOLOv4 использовался mini-batch=8 и только 32 GB GPU-RAM. Несмотря на это, YOLOv4 быстрее/точнее публичных сетей, хотя обучена только 1 раз с разрешением 512x512 на 1 GPU (Tesla V100 32GB / 16GB). При этом использование меньшего размера mini-batch size и GPU-VRAM не приводит к такой драматической потери точности, как в других нейронных сетях:
Источник: arxiv.org/abs/2004.10934
Так что вы можете обучать искусственный интеллект локально на своем ПК, вместо загрузки датасета в облако – это гарантирует защиту ваших персональных данных и делает обучение искусственного интеллекта доступным каждому.
Нашу сеть достаточно обучить один раз с network resolution 512x512, и затем можно использовать с разными network resolutions в диапазоне: [416x416 – 512x512 – 608x608].
Большинство же других моделей требуется обучать каждый раз отдельно для каждого network resolution, из-за этого обучение занимает в разы больше времени.
Особенности измерения точности алгоритмов обнаружения объектов
Всегда можно найти изображение, на котором один алгоритм будет работать плохо, а другой алгоритм будет работать хорошо, и наоборот. Поэтому для тестирования алгоритмов обнаружения используется большой набор из ~20 000 изображений и 80 различных типов объектов — MSCOCO test-dev dataset.
Чтобы алгоритм не пытался просто запомнить хэш каждого изображения и координаты на нем (overfitting), точность обнаружения объектов всегда проверяется на изображениях и метках, которые алгоритм не видел во время обучения – это гарантирует, что алгоритм сможет обнаруживать объекты на изображениях/видео, которые он никогда не видел.
Чтобы никто не мог совершить ошибку в расчете точности, в открытом доступе есть только тестовые изображения test-dev, на которых вы производите обнаружение, а результаты отправляете на CodaLab evaluation server, на котором программа сама сравнивает ваши результаты с тестовыми аннотациями, которые никому не доступны.
MSCOCO dataset состоит из 3-ех частей
- Обучающий набор: 120 000 изображений и json-файл с координатами каждого объекта
- Валидационный набор: 5 000 изображений и json-файл с координатами каждого объекта
- Тестовый набор: 41 000 jpg-изображений без координат объектов (часть из этих изображений используется для определения точности в задачах: Object Detection, Instance Segmentation, Keypoints, ...)
Особенности разработки YOLOv4
При разработке YOLOv4 мне приходилось самому разрабатывать и нейронную сеть YOLOv4 и фреймворк Darknet на C/C++/CUDA. Т.к. в Darknet нет автоматического дифференцирования и автоматического выполнения chain-rule, то все градиенты приходится реализовывать вручную на CUDA C++. С другой стороны, мы можем отходить от строгого следования chain-rule, изменять backpropagation и пробовать очень нетривиальные вещи для повышения стабильности обучения и точности.
Дополнительные выводы при создании нейронных сетей
- Не всегда лучшая сеть для классификации объектов будет лучшей в качестве backbone для сети, используемой для обнаружения объектов
- Использование weights обученных с фичами, которые увеличили точность в классификации, может негативно сказаться на точности детектора (на некоторых сетях)
- Не все фичи заявленные в различных исследованиях улучшают точность сети
- Не все фичи совместимы между собой и некоторые комбинации фич зачастую уменьшают точность сети при использовании совместно.
- Не всегда сеть с более низким BFLOPS будет быстрее, даже если BFLOPS меньше в десятки раз
- Сети для обнаружения объектов требуют более высокого разрешения сети для обнаружения множества объектов разного размера и их точного местоположения, это требует более высокого receptive field для покрытия увеличенного разрешения сети, а значит требуется больше слоев со stride=2 и/или conv3x3, и больший размер weights (filters) для запоминания большего числа деталей объектов.
Использование и обучение YOLOv4
Обнаружение объектов с помощью обученных моделей YOLOv4 встроено в библиотеку OpenCV-dnn github.com/opencv/opencv/issues/17148 так что вы можете использовать YOLOv4 напрямую из OpenCV без использования фреймворка Darknet. Библиотека OpenCV поддерживает выполнение нейронных сетей на CPU, GPU (nVidia GPU), VPU (Intel Myriad X). Подробнее: docs.opencv.org/master/da/d9d/tutorial_dnn_yolo.html
OpenCV (dnn) framework:
- Пример на C++: github.com/opencv/opencv/blob/master/samples/dnn/object_detection.cpp
- Пример на Python: github.com/opencv/opencv/blob/master/samples/dnn/object_detection.py
Darknet framework:
- Инструкция по использованию YOLOv4 для обнаружения объектов: github.com/AlexeyAB/darknet#how-to-use-on-the-command-line
- Инструкция по обучению нейронной сети для обнаружения собственных объектов: github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects
- Инструкция по обучению классификатора CSPDarknet53 на датасете ILSVRC2012 (ImageNet): github.com/AlexeyAB/darknet/wiki/Train-Classifier-on-ImageNet-(ILSVRC2012)
- Инструкция по обучению YOLOv4 на датасете MS COCO: github.com/AlexeyAB/darknet/wiki/Train-Detector-on-MS-COCO-(trainvalno5k-2014)-dataset
tkDNN+TensorRT — Максимальная скорость обнаружения объектов используя YOLOv4: TensorRT + tkDNN github.com/ceccocats/tkDNN
- 300 FPS – YOLOv4 (416x416 batch=4) on RTX 2080 Ti
- 32 FPS – YOLOv4 (416x416 batch=1) on Jetson AGX Xavier
Tencent-NCNN (C/C++/GLSL) — Максимальная скорость обнаружения объектов на Смартфонах (iOS / Android) используя YOLOv4 без каких-либо дополнительных библиотек или любых зависимостей: github.com/Tencent/ncnn
Использование YOLOv4 может быть расширено до обнаружения 3D-Rotated-Bboxes или ключевых точек / facial landmarks, например:
* 3D-Rotated-Bboxes: github.com/maudzung/Complex-YOLOv4-Pytorch
* Key-points / facial-landmarks: github.com/ouyanghuiyu/darknet_face_with_landmark

