
пример работы First Order Motion Model
Можно ли из одной фотографии сделать целый фильм? А записав движения одного человека, заменить его на другого в видео? Безусловно, ответ на эти вопросы, крайне важен для таких сфер как кинематограф, фотография, разработка компьютерных игр. Решением может стать цифровая обработка фотографии с помощью специализированного ПО. Задача, о которой идет речь, среди специалистов в этой области называется задачей автоматического синтеза видео или анимации изображения.
Для получения ожидаемого результата существующие подходы объединяют объекты, извлеченные из исходного изображения, и движения, которые могут поставляться в виде отдельного видео – «донора».
Сейчас, в большинстве сфер, анимация изображений осуществляется с помощью инструментов компьютерной графики. Для этого подхода требуются дополнительные знания об объекте, который мы хотим анимировать — обычно необходима его 3D модель (как сейчас это работает в кино индустрии можно почитать здесь). Большинство последних решений рассматриваемой задачи основывается на глубоком обучении моделей, в основе которых лежат генеративно-состязательные нейросети (GAN) и вариационные автоэнкодеры (VAE). Данные модели обычно используют предобученные модули для поиска ключевых точек объектов на изображении. Главная проблема такого подхода — данные модули способны распознавать только объекты, на которых они были обучены.
Как же решить описанную задачу для произвольных объектов, находящихся в кадре? Один из способов предложен в статье «First Order Motion Model for Image Animation». Авторы предлагают свою модель нейросети — First Order Motion Model, которая решает задачу анимации изображения без предобучения на анимируемом объекте. Обучившись на множестве видеороликов, изображающих объекты одной категории (например, лица, человеческие тела), разработанная авторами сеть позволяет анимировать все объекты, относящиеся к данной категории.
Подробнее разберемся как это работает…
Особенности решения
Для моделирования сложных движений используется набор энкодеров ключевых элементов объекта, обученных без учителя и локальные аффинные преобразования.
Для исключения из рассмотрения частей объекта, не видных на исходном изображении, применяется маска перекрытия (occlusion map). Так как эти части отсутствуют на изображении они должны быть сгенерированы нейросетью самостоятельно. Авторы также расширяют функцию эквивариантных потерь, используемую для обучения детектора ключевых точек, с целью улучшения оценки афинных преобразований.
Общая схема
Фреймворк состоит из двух основных модулей: модуля оценки движения и модуля генерации изображения. Модуль оценки движения предназначен для предсказания поля движения из кадра
 видео в исходное изображение
видео в исходное изображение  . Поле движения позже используется для выравнивания ключевых точек объектов из кадра
. Поле движения позже используется для выравнивания ключевых точек объектов из кадра  в соответствие с позой этих объектов в кадре
в соответствие с позой этих объектов в кадре  .
.

На вход детектору ключевых точек подаётся изображение и кадр из видео. Этот детектор извлекает представление движения первого порядка, состоящего из разреженных ключевых точек и локальных аффинных преобразований относительно абстрактного кадра (системы отсчета)  . Сеть переноса движения использует такое представление движения для создания обратного оптического потока
. Сеть переноса движения использует такое представление движения для создания обратного оптического потока  из в и карту перекрытия
из в и карту перекрытия  . Исходное изображение и выходные данные сети переноса движения используются модулем генерации изображения для визуализации целевого изображения.
. Исходное изображение и выходные данные сети переноса движения используются модулем генерации изображения для визуализации целевого изображения.
Далее рассмотрим особенности данного решения более подробно.
Локальные аффинные преобразования для приближения движения
Модуль оценки движения оценивает обратный оптический поток  от движущегося кадра до исходного кадра . Авторы аппроксимируют разложением в ряд Тейлора в окрестности ключевых точек. Предполагается, что существует абстрактный кадр (система отсчета), поэтому оценка выражается через оценки
от движущегося кадра до исходного кадра . Авторы аппроксимируют разложением в ряд Тейлора в окрестности ключевых точек. Предполагается, что существует абстрактный кадр (система отсчета), поэтому оценка выражается через оценки  и
и  . Более того, учитывая кадр результата
. Более того, учитывая кадр результата  , мы оцениваем каждое преобразование
, мы оцениваем каждое преобразование  в окрестности обученных ключевых точек. Рассмотрим разложение в ряд Тейлора в
в окрестности обученных ключевых точек. Рассмотрим разложение в ряд Тейлора в  ключевых точках
ключевых точках  , где обозначают координаты ключевых точек в .
, где обозначают координаты ключевых точек в .
Получаем:
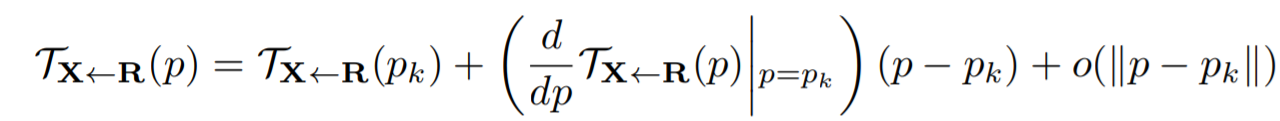
Чтобы оценить  , предполагаем, что локально биективен в окрестности каждой ключевой точки.
, предполагаем, что локально биективен в окрестности каждой ключевой точки.
Итого:

Предсказатель ключевых точек выдает  и
и  . Авторы используют стандартную архитектуру U-Net, которая оценивает тепловых карт, по одной для каждой ключевой точки.
. Авторы используют стандартную архитектуру U-Net, которая оценивает тепловых карт, по одной для каждой ключевой точки.
Последний слой декодера использует softmax для предсказания тепловых карт, которые могут интерпретироваться как карты достоверности обнаружения ключевых точек.
Авторы используют сверточную нейросеть  для оценки с помощью
для оценки с помощью  в ключевых точках (здесь координаты ключевых точек обозначили через
в ключевых точках (здесь координаты ключевых точек обозначили через  ), и исходный кадр . Важно, что параметры , такие как края или текстура, выровнены попиксельно в соответствии с , а не с . Для того чтобы входные данные были уже выровнены с , мы деформируем исходные кадры и получаем преобразованных изображений
), и исходный кадр . Важно, что параметры , такие как края или текстура, выровнены попиксельно в соответствии с , а не с . Для того чтобы входные данные были уже выровнены с , мы деформируем исходные кадры и получаем преобразованных изображений  (
( ), каждое из которых выровнено относительно в окрестности ключевой точки. Тепловые карты и преобразованные изображения
), каждое из которых выровнено относительно в окрестности ключевой точки. Тепловые карты и преобразованные изображения  объединяются и обрабатываются в U-Net.
объединяются и обрабатываются в U-Net.
 выражается формулой:
выражается формулой:

Здесь  — маска для выделения окрестности контрольной точки для которой происходит это преобразование (
— маска для выделения окрестности контрольной точки для которой происходит это преобразование ( — для добавления фона) и
— для добавления фона) и  выражается формулой:
выражается формулой:
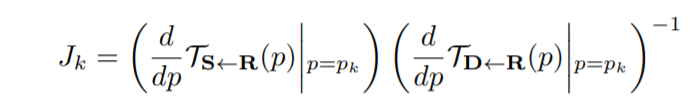
Генерация изображения
Напомню, что исходное изображение не выровнено попиксельно с создаваемым изображением  . Чтобы справиться с этим, авторы используют стратегию деформации объекта. После двух down-sampling блоков мы получаем карту объектов
. Чтобы справиться с этим, авторы используют стратегию деформации объекта. После двух down-sampling блоков мы получаем карту объектов  . Затем мы деформируем
. Затем мы деформируем  в соответствии c . При наличии перекрытий в , оптического потока может быть недостаточно для генерации . Здесь вводится понятие — карта перекрытий
в соответствии c . При наличии перекрытий в , оптического потока может быть недостаточно для генерации . Здесь вводится понятие — карта перекрытий ![$\hat{\mathcal{O}}_{\mathrm{S \leftarrow D}} \in [0, 1]^{H' \times W'}$](https://habrastorage.org/getpro/habr/formulas/27c/0b8/0e9/27c0b80e9dd34d918f05ba833cb496bb.svg) , чтобы пометить области карты объектов, которые должны быть дорисованы, потому что они отсутствуют на изображении . Новая карта объектов выглядит так:
, чтобы пометить области карты объектов, которые должны быть дорисованы, потому что они отсутствуют на изображении . Новая карта объектов выглядит так:

где  означает операцию обратной деформации, а
означает операцию обратной деформации, а  — произведение Адамара (поразрядное логическое умножение соответствующих членов двух последовательностей равной длины).
— произведение Адамара (поразрядное логическое умножение соответствующих членов двух последовательностей равной длины).
Мы оцениваем маску перекрытия с помощью разреженного представления ключевых точек, добавляя канал к конечному слою сети переноса движения.  подается в последующие слои модуля генерации изображения, чтобы визуализировать получаемый кадр.
подается в последующие слои модуля генерации изображения, чтобы визуализировать получаемый кадр.
Функции потерь
Сеть тренируется непрерывно, комбинируя несколько функций потерь. Используется reconstruction loss, основанная на перцептивной функции потерь Джонсона. В качестве ключевой функции потерь для движений в кадре применяется пред-обученная сеть VGG-19. Формула reconstruction loss представлена ниже:

— восстановленный кадр, — кадр с исходным движением,  — i-ый элемент канала, извлеченный из конкретного слоя VGG-19,
— i-ый элемент канала, извлеченный из конкретного слоя VGG-19,  — количество каналов элементов в этом слое.
— количество каналов элементов в этом слое.
Наложение ограничения эквивариантности
Предсказатель ключевых точек не требует каких-либо знаний о ключевых точек во время обучения. Это может привести к нестабильным результатам. Ограничение эквивариантности является одним из наиболее важных факторов, определяющих нахождение ключевых точек без учителя. Это заставляет модель прогнозировать ключевые точки, которые не противоречат известным геометрическим преобразованиям. Поскольку модуль оценки движения не только предсказывает ключевые точки, но также и Якобианы, мы расширяем функцию потерь эквивариантности, чтобы дополнительно включить в нее ограничения на Якобианы.
Авторы предполагают, что изображение претерпевает пространственную деформацию  , которая может быть как аффинным преобразованием, так и thin plane spline. После этой деформации мы получаем новое изображение
, которая может быть как аффинным преобразованием, так и thin plane spline. После этой деформации мы получаем новое изображение  . Применяя расширенную оценку движения к обоим изображениям, получаем набор локальных аппроксимаций для и
. Применяя расширенную оценку движения к обоим изображениям, получаем набор локальных аппроксимаций для и
 . Cтандартное ограничение эквивариантности записывается так:
. Cтандартное ограничение эквивариантности записывается так:

После разложения в ряд Тейлора обеих частей уравнения мы получаем следующие ограничения (здесь  — единичная квадратная матрица):
— единичная квадратная матрица):
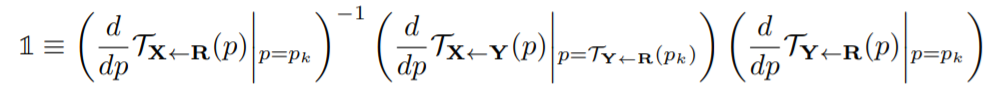
Для ограничения положений ключевых точек используется функция  . Авторы используют равные веса при объединении функций потерь во всех экспериментах, так как модель не чувствительна к относительным весам reconstruction loss и 2х эквивариантных функций потерь.
. Авторы используют равные веса при объединении функций потерь во всех экспериментах, так как модель не чувствительна к относительным весам reconstruction loss и 2х эквивариантных функций потерь.
Анимация
Для анимации объекта из исходного кадра  с помощью кадров видео
с помощью кадров видео  каждый кадр
каждый кадр  самостоятельно обрабатывается, чтобы получить
самостоятельно обрабатывается, чтобы получить  . Для этого в кадр передается относительное движение между
. Для этого в кадр передается относительное движение между  и . То есть, мы применяем преобразование
и . То есть, мы применяем преобразование  в окрестности каждой точки
в окрестности каждой точки  :
:
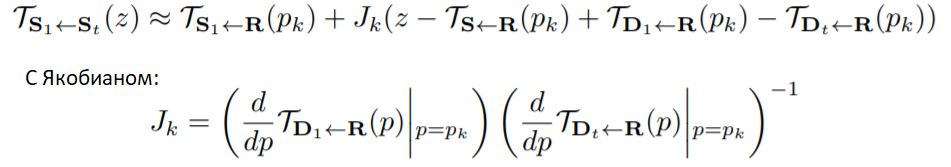
Важно заметить, что в связи с этим возникает ограничение — объекты на кадрах и должны иметь похожие позы.
Модель ставит рекорды!
Модель обучалась и тестировалась на 4 различных наборах данных:
- VoxCeleb — датасет лиц из 22496 видео, взятых из YouTube;
- UvA-Nemo — датасет для анализа лиц, состоящий из 1240 видео;
- BAIR robot pushing — датасет, состоящий из видео, собранных роботизированной рукой Сойера, которая кладет разные предметы на стол. В нем 42880 обучающих и 128 тестовых видео.
- 280 TaiChi видео из YouTube.
Результаты работы сравнивались с X2Face и Monkey-Net, так как они являются единственными существующими решениями для анимации изображений без предварительного моделирования.

Как видно из таблицы, First Order Motion модель превосходит другие подходы по всем показателям.
Долгожданные примеры


А теперь попробуйте сами! Это совсем просто, все подготовлено здесь.

