
Привет, недавно мне попалась интересная задачка настроить хранилище для бэкапа большого количества блочных устройств.
Каждую неделю мы выполняем резервное копирование всех виртуальных машин в нашем облаке, таким образом нужно уметь обслуживать тысячи резервных копий и делать это максимально быстро и эфективно.
К сожалению стандартные конфигурации RAID5, RAID6 в данном случае нам не подхотят в виду того что процесс восстановления на таких больших дисках как наши будет мучительно долгим и скорее всего не закончится никогда.
Рассмотрим какие есть альтернативы :
Erasure Coding — Аналог RAID5, RAID6, но с настраиваемым уровнем четности. При этом резервирование выполняется не поблочно а для каждого объекта отдельно. Наиболее простой способ попробовать erasure coding — это развернуть minio.
DRAID — это на данный момент ещё не выпущенная возможность ZFS. В отличие от RAIDZ DRAID имеет распределённый parity block и при восстановлении задействует сразу все диски массива, благодаря чему лучше переживает отказы дисков и быстрее восстанавливается после сбоя.


В распоряжении имеется сервер Fujitsu Primergy RX300 S7 c процессором Intel Xeon CPU E5-2650L 0 @ 1.80GHz, девятью планками оперативной памяти Samsung DDR3-1333 8Gb PC3L-10600R ECC Registered (M393B1K70DH0-YH9), дисковая полка Supermicro SuperChassis 847E26-RJBOD1, подключённая через Dual LSI SAS2X36 Expander и 45 дисков Seagage ST6000NM0115-1YZ110 по 6TB каждый.
Прежде чем что-то решить нам сначала нужно должным образом всё протестировать.
Для этого я подготовился и провёл тестирование различных конфигураций. Для этого я использовал minio, который выступал в качестве S3-бэкенда и запускал его в разных режимах с разным количеством таргетов.
В основном тестировался кейс minio в erasure coding vs software raid с тем же количеством дисков и parity дисков, а это: RAID6, RAIDZ2 и DRAID2.
Для справки: когда вы запускаете minio с одним-лишь таргетом, то minio работает в режиме S3-гейтвея отдавая вашу локальную файловую систему в виде S3-хранилища. В случае же если вы запустите minio с указанием нескольких таргетов, то автоматически включится режим Erasure Coding, который будет размазывать данные между вашими таргетами с предоставлением отказоустойчивости.
По умолчанию minio делит таргеты на группы по 16 дисков, где на каждую группу приходится по 2 parity. Т.е. одновременно из строя могут выйти два диска без потери данных.
Для тестирования производительности я использовал 16 дисков по 6TB каждый и писал на них небольшие объекты размером в 1MB, это максимально точно описывало нашу будущую нагрузку, так как все современные инструменты для бэкапа делят данные на блоки в несколько мегабайт и пишут их таким образом.
Для проведения бэнчмарка использовалась утилита s3bench запускаемая на удаленном сервере и отправляющая в minio десятки тысяч таких объектов в сотню потоков. После чего таким же образом пыталась запросить их обратно.
Результаты бэнчмарка приведены в следующей таблице:

Как мы видим, minio в режиме собственного erasure coding работает значительно хуже на запись, чем minio запущенный поверх программного RAID6, RAIDZ2 и DRAID2 в тойже конфигурации.
Отдельно меня попросили потестировать minio на ext4 vs XFS. Удивительно, но для моего типа нагрузки XFS оказалась значительно медленнее чем ext4.
В первую порцию тестов Mdadm показал превосходство над ZFS, но позже gmelikov подсказал, что можно улучшить производительность ZFS установив следующие опции:
xattr=sa atime=off recordsize=1M
и после этого тесты с ZFS стали намного лучше.
Также можно заметить что DRAID не даёт особого выигрыша в производительности перед RAIDZ, но в теории должен быть намного безопаснее.
В последних двух тестах я также попытался вынести метаданные (special) и ZIL (log) на зеркало из SSD. Но вынесение метаданных не дало особого выигрыша в скорости записи, а при выносе ZIL мои SSDSC2KI128G8 упёрлись в потолок со 100% утилизацией, так что я считаю данный тест проваленым. Я не исключаю, что если бы у меня были более быстрые SSD-диски, то возможно это могло бы сильно улучшить мои результаты, но, к сожалению, у меня их не оказалось.
В итоге я решил остановиться на использовании DRAID и не смотря на свой альфа статус, он является наиболее быстрым и эфективным решением для хранения в нашем случае.
ВНИМАНИЕ: Мы используем DRAID для краткосрочных оперативных резервных копий, мы можем позволить себе краткосрочную потерю данных, но ваш случай может отличаться, используйте его на свой страх и риск!
Я создал простой DRAID2 в конфигурации c тремя группами и двумя distributed spares:
# zpool status data pool: data state: ONLINE scan: none requested config: NAME STATE READ WRITE CKSUM data ONLINE 0 0 0 draid2:3g:2s-0 ONLINE 0 0 0 sdy ONLINE 0 0 0 sdam ONLINE 0 0 0 sdf ONLINE 0 0 0 sdau ONLINE 0 0 0 sdab ONLINE 0 0 0 sdo ONLINE 0 0 0 sdw ONLINE 0 0 0 sdak ONLINE 0 0 0 sdd ONLINE 0 0 0 sdas ONLINE 0 0 0 sdm ONLINE 0 0 0 sdu ONLINE 0 0 0 sdai ONLINE 0 0 0 sdaq ONLINE 0 0 0 sdk ONLINE 0 0 0 sds ONLINE 0 0 0 sdag ONLINE 0 0 0 sdi ONLINE 0 0 0 sdq ONLINE 0 0 0 sdae ONLINE 0 0 0 sdz ONLINE 0 0 0 sdan ONLINE 0 0 0 sdg ONLINE 0 0 0 sdac ONLINE 0 0 0 sdx ONLINE 0 0 0 sdal ONLINE 0 0 0 sde ONLINE 0 0 0 sdat ONLINE 0 0 0 sdaa ONLINE 0 0 0 sdn ONLINE 0 0 0 sdv ONLINE 0 0 0 sdaj ONLINE 0 0 0 sdc ONLINE 0 0 0 sdar ONLINE 0 0 0 sdl ONLINE 0 0 0 sdt ONLINE 0 0 0 sdah ONLINE 0 0 0 sdap ONLINE 0 0 0 sdj ONLINE 0 0 0 sdr ONLINE 0 0 0 sdaf ONLINE 0 0 0 sdao ONLINE 0 0 0 sdh ONLINE 0 0 0 sdp ONLINE 0 0 0 sdad ONLINE 0 0 0 spares s0-draid2:3g:2s-0 AVAIL s1-draid2:3g:2s-0 AVAIL errors: No known data errors
Хорошо, с хранилищем разобрались, теперь о том чем будем бэкапить. Здесь сразу хочется рассказать о трёх решениях которые мне удалось попробовать, а это:
Benji Backup — форк Backy2, специализированное решение для бэкапа блочных устройств, имеет тесную интеграцию с Ceph. Умеет забирать diff'ы между снапшотами и формировать из них инкрементальный бэкап. Поддерживает большое количество бэкенодов хранения, среди которых есть как локальный так и S3. Требует отдельной базы данных для хранения хэш-таблицы дедупликации. Из минусов: написан на python, имеет немного неотзывчивый cli.
Borg Backup — форк Attic, давно известное и проверенное средство для резервного копирования, умеет бэкапировать данные и хорошо дедуплицирует их. Умеет сохранять бэкапы как локально так и на удалённый сервер посредством scp. Умеет бэкапить блочные устройства если запущен с флагом --special, из минусов: при создании бэкапа репозиторий полностью блокируется, поэтому под каждую виртуалку рекомендуется создавать отдельный репозиторий, в принципе это не проблема, благо создаются они очень легко.
Restic — активно развивающийся проект, написан на go, достаточно быстр и поддерживает большое количество бэкендов для хранения, среди которых есть как локальное хранилище, так и scp, S3 и многое другое. Отдельно хочется заметить, что есть специально созданный rest-server для restic, который позволяет наиболее быстро экспортировать хранилище для использования удалённо. Из всех вышеперечисленных мне понравилось больше всего. Умеет бэкапить из stdin. Заметных минусов почти не имеет, но есть несколько особенностей:
Во первых, я попробовал его использовать в режиме общего репозитория для всех виртуалок (как Benji) и это даже неплохо работало, но операции восстанавления занимали весьма продолжительное время, т.к. каждый раз перед восстановлением restic пытается прочитать метаданные всех бэкапов. Данная проблема легко решилась как и с borg, созданием отдельного репозитория под каждую виртуалку. Этот подход оказался весьма эффективным также и для управлениями резервными копиями. Обособленные репозитории могут иметь отдельный пароль для доступа к данным, а так же мы можем не бояться того, что глобальный репо может как-нибудь сломается. Спавнить новые репозитории можно также просто как и в borg backup.
В любом случае дедупликация производится только относительно предыдущей версии бэкапа, предыдущий бэкап определяется по path для указанного бэкапа, так что если вы бэкапите разные объекты из stdin в общий репозиторий, не забудьте указать опцию
--stdin-filename, либо явно каждый раз указывать опцию--parent.
Во вторых, восстановление в stdout занимает значительно больше времени чем восстановление на файловую систему в виду своей паралельности. В будущем планируется добавить более тесную поддержку бэкапов для блочных устройств.
В третьих, на данный момент рекомендуется использовать версию из master, т.к. версия 0.9.6 имеет баг с долгим восстановлением больших файлов.
Чтобы протестировать эффективность бэкапа и скорость записи / восстановления из резервной копии, я создал отдельный репозиторий и попробовал забэкапить небольшой образ виртуальной машины (21 GB). Было выполнено два бэкапа без изменения оригинала, используя каждое из перечисленных решений, чтобы проверить насколько быстрее/медленнее копируются дедуплицированные данные.
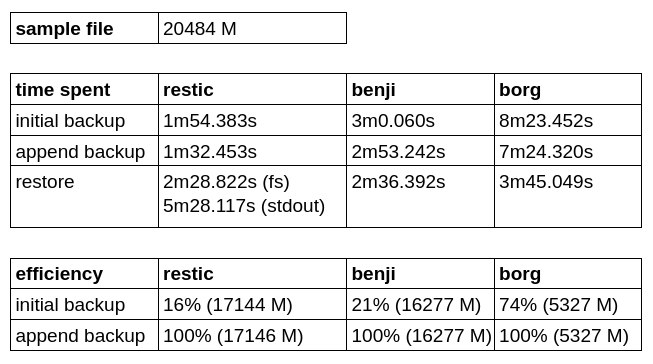
Как мы можем заметить Borg Backup имеет наилучший коэфициент эфективности начального резервной копии, но проигрывает по скорости как записи так и восставления.
Restic оказался быстрее Benji Backup, но дольше восстанавливает в stdout, а писать напрямую в блочное устройство он, к сожалению, пока не умеет.
Взвесив все за и все против я решил остановиться на restic с rest-server как на наиболее удобном и перспективном решении для бэкапа.

В данном скринкасте вы можете видеть как 10-гигабитный канал полностью утилизируется при нескольких, одновременно запущенных, операциях бэкапа. Стоит заметить что утилизация дисков при этом не поднимается выше 30%.
Полученным решением я оказался более чем доволен!

