Привет, Хабр. Хорошие новости: мы успешно завершили краудсорсинговый проект «Открой историю Большого» по оцифровке программ, афиш и фотографий, которые хранятся в музее Большого театра. Итогами делимся на сайте openbolshoi.ru, а в этом посте рассказываем, как технически был организован проект.
О том, почему мы начали заниматься этим проектом и что сделали на первом этапе, можно почитать здесь. А что же было дальше? После первой части проекта мы благодаря ABBYY FineReader PDF и с помощью волонтеров подготовили файлы программ и афиш в формате PDF с вычитанным текстовым слоем и передали их музею Большого театра. Теперь все данные хранятся в электронном виде, и сотрудники используют их, чтобы искать и копировать нужную информацию. Это быстрее и удобнее, чем перебирать документы в шкафах и перепечатывать текст из оригиналов.
Но как узнать больше о представлениях, а также о людях, чьи судьбы тесно связаны с историей театра? Как собрать статистику:
- какие оперы и балеты за 200 лет ставились на сцене театра чаще всего?
- сколько раз Майя Плисецкая, Федор Шаляпин, Екатерина Максимова, Владимир Васильев и другие известные артисты выступали в Большом?
- на каких инструментах и сколько раз играли знаменитые музыканты?
Помогли технологии Natural Language Processing (NLP), разработанные в ABBYY. Сегодня мы расскажем, как на втором этапе проекта алгоритмы извлекли из программ и афиш необходимые сведения, заполнили поля базы данных, а затем 7500 волонтеров проверили и дополнили информацию. А в конце поста читайте, как сейчас создается электронный архив музея с удобным поиском по всем представлениям и персонам.
Второй этап проекта стартовал в июне 2017 года. К этому моменту все PDF-файлы с текстовым слоем, изображения программ и афиш в формате JPEG и документы MS Word c вычитанным текстом мы разместили в файловом хранилище размером 1,5 терабайт. Сервис загрузки данных анализировал базу с документами (PDF, JPEG и MS Word), а затем через наш веб-API загружал PDF по очереди в файловое хранилище станции верификации ABBYY FlexiCapture (FC). Чтобы волонтеры могли быстро открывать документы у себя на компьютере, FC сжимала PDF-файлы, отображала их в черно-белом режиме и преобразовывала в формат PNG с сохранением вычитанного текстового слоя. Качество файлов урезалось на 60%, но волонтерам этого было более чем достаточно, чтобы увеличить мелкий текст, прочесть и понять любые надписи на ценных документах.
После загрузки и предобработки программ и афиш в ABBYY FlexiCapture начиналась одна из самых ответственных частей проекта. Расскажем о ней подробнее.
Где композитор, а где – балет?
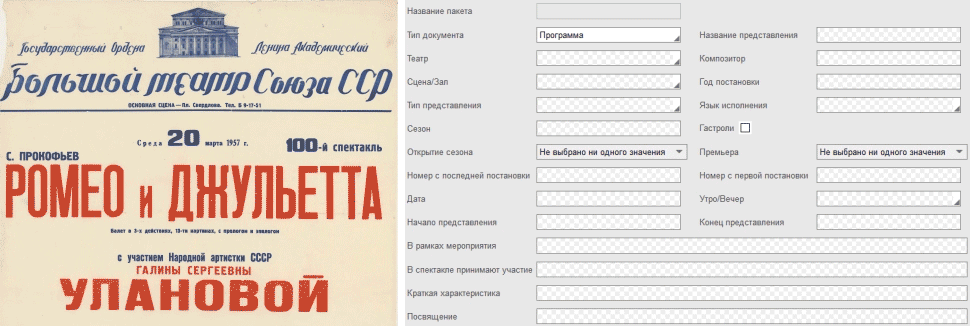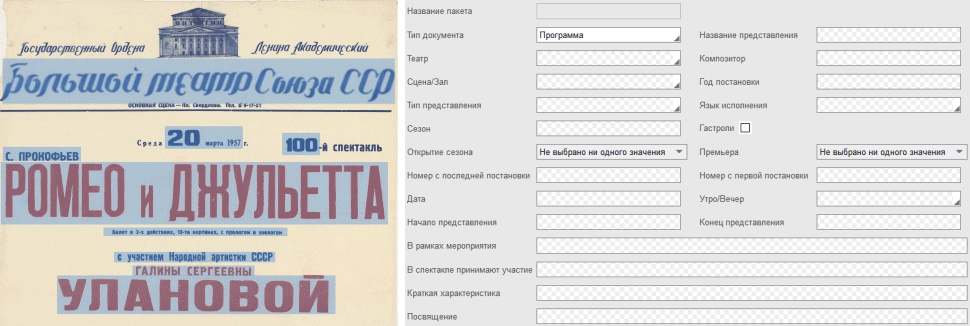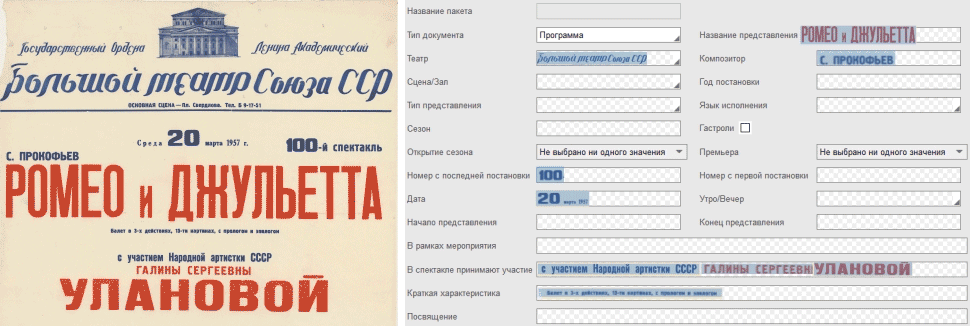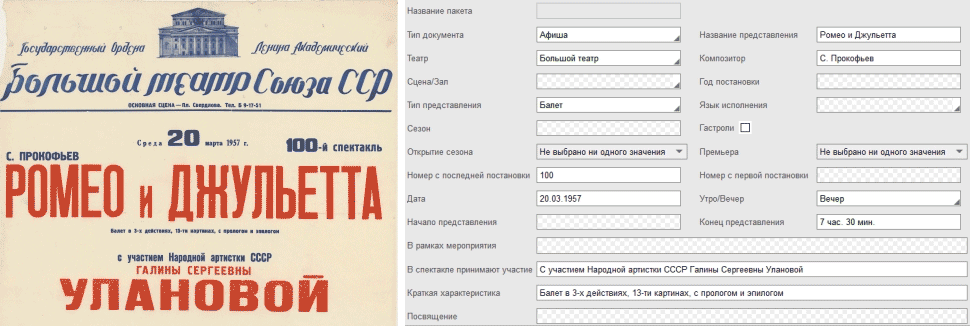
NLP-технологии ABBYY автоматически определяли, о каких участниках представления идет речь, какие роли исполнял каждый из них, на каком музыкальном инструменте играл и т.п. Затем технология самостоятельно вносила эту информацию в поля онлайн-формы. Например, в программе спектакля «Щелкунчик» автоматически определилось, что Е.Н. Ватуля – исполнитель роли Щелкунчика-куклы, А.В. Никонов – исполнитель роли Щелкунчика-принца и т.д.:
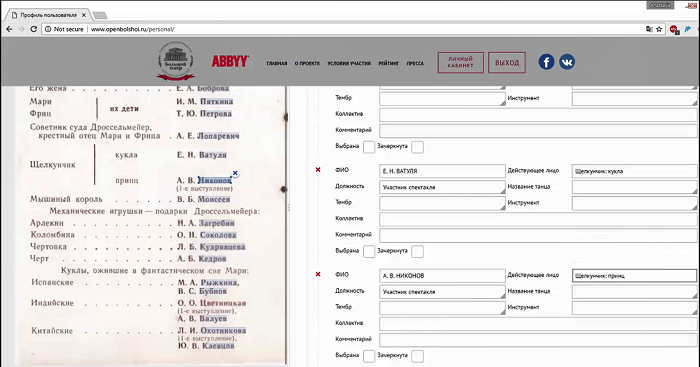
Технологии ABBYY проанализировали проверенный и вычитанный волонтерами текстовый слой и заполнили поля онлайн-формы.
Многие старинные документы отличались по структуре: в одних – использовались художественные шрифты, в других – текст размещался в трех-четырех колонках. На этой афише есть и то, и другое:
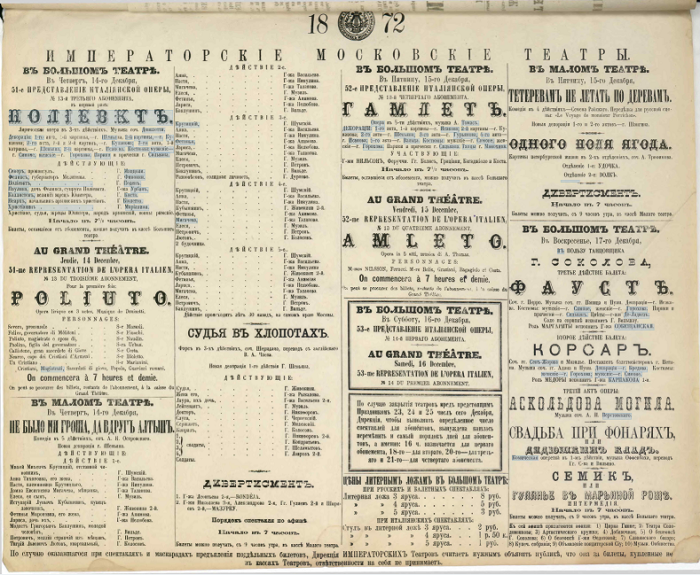
Из-за сложной структуры афиш не все данные могли автоматически попадать в поля онлайн-формы. Поэтому волонтерам (на втором этапе мы называли их «аудиторами») предстояло проверить, дополнить информацию и вычитать ошибки не только в афишах, но и на всякий случай в программах.
Как работали волонтеры
Чтобы работа не казалась участникам слишком сложной и скучной, мы, как и на первом этапе проекта, разделили все документы на небольшие части – пакеты. Один пакет – это одна афиша или программа, в которой могло быть несколько страниц. Всего участникам предстояло проверить около 170 тысяч страниц документов.
Чтобы начать работу, участник регистрировался на сайте openbolshoi.ru и переходил на веб-станцию верификации ABBYY FlexiCapture. В отличие от первого этапа, волонтерам не приходилось скачивать программу себе на компьютер, так как все работало онлайн в веб-приложении (тонком клиенте). Волонтер теперь мог проверять пакеты прямо из дома, на даче, в кафе или из любой точки мира с доступом в интернет.
Личный кабинет аудитора выглядел так (картинка кликабельна):
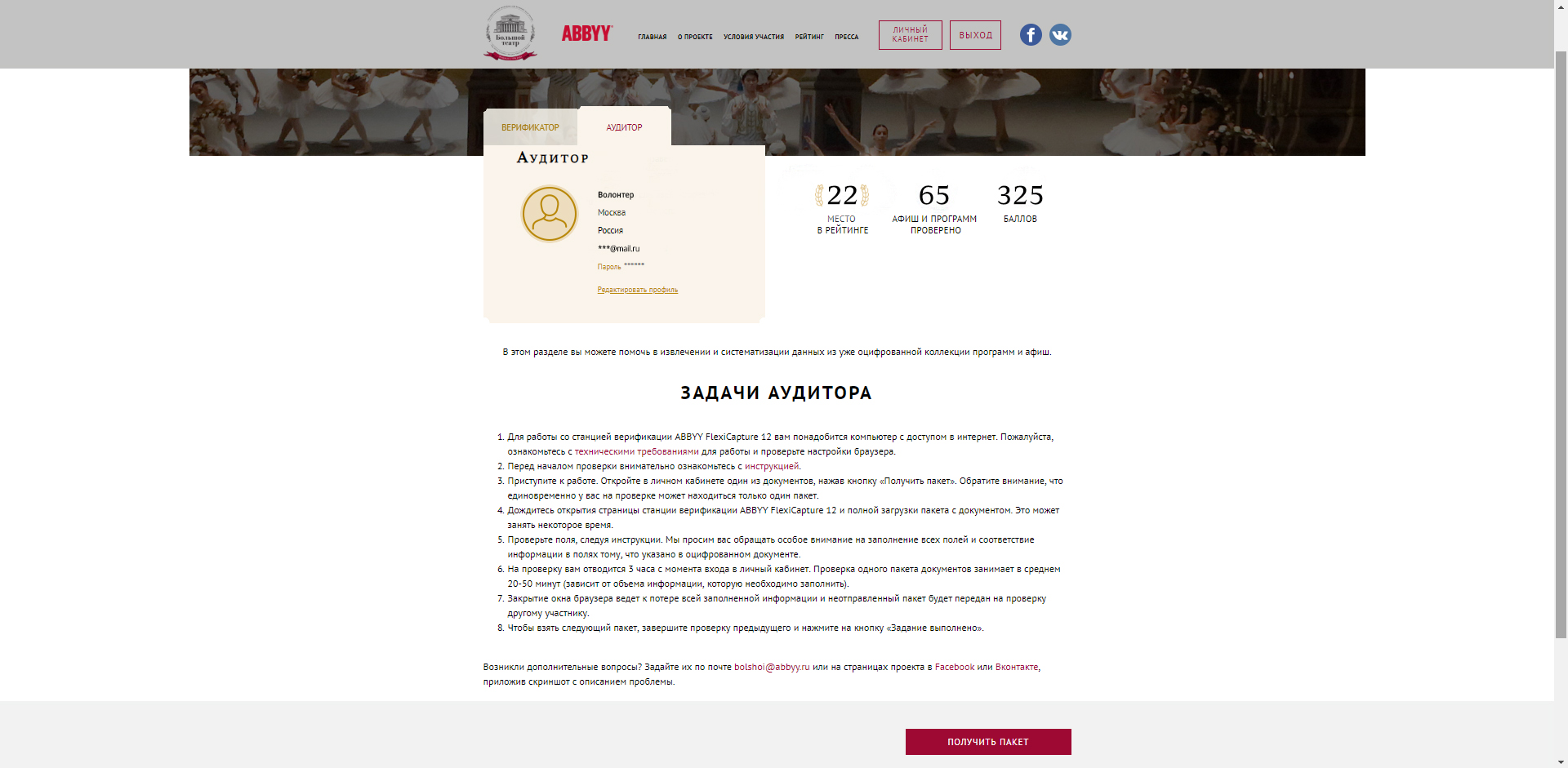
Как участники проекта получали задания
Как мы упоминали выше, перед тем как пакеты попадали к волонтерам, документы по очереди загружались в FC: первый, второй, третий и так далее. Затем они друг за другом обрабатывались с помощью NLP-технологий ABBYY. В таком же порядке формировалась очередь пакетов (заданий), которые потом отправлялись на проверку участникам.
Волонтер мог взять в работу только один пакет из очереди, без возможности выбрать конкретный документ. Он нажимал кнопку «Получить пакет» и перед ним открывался веб-интерфейс станции верификации ABBYY FC. Будем в дальнейшем называть его «онлайн-форма». На видео показываем, как это происходило:
На проверку одного пакета каждому участнику давалось 3 часа. В среднем работа занимала 20-50 минут, хотя на некоторые сложные документы уходило больше времени. Если участник не успевал выполнить задание, то пакет отправлялся обратно в очередь. Чуть ниже расскажем, как это происходило.
Разработка онлайн-формы
Онлайн-форма повторяла шаблон «толстого клиента» ABBYY FC. Чтобы сгенерировать веб-интерфейс, наши разработчики брали XML-описания шаблона и генерировали разметку на HTML5. Важно было соблюсти то же расположение и размер полей, которые были в толстом клиенте.В левой части онлайн-формы располагалось изображение документа, а в правой – поля, которые уже частично были заполнены с помощью технологий ABBYY:
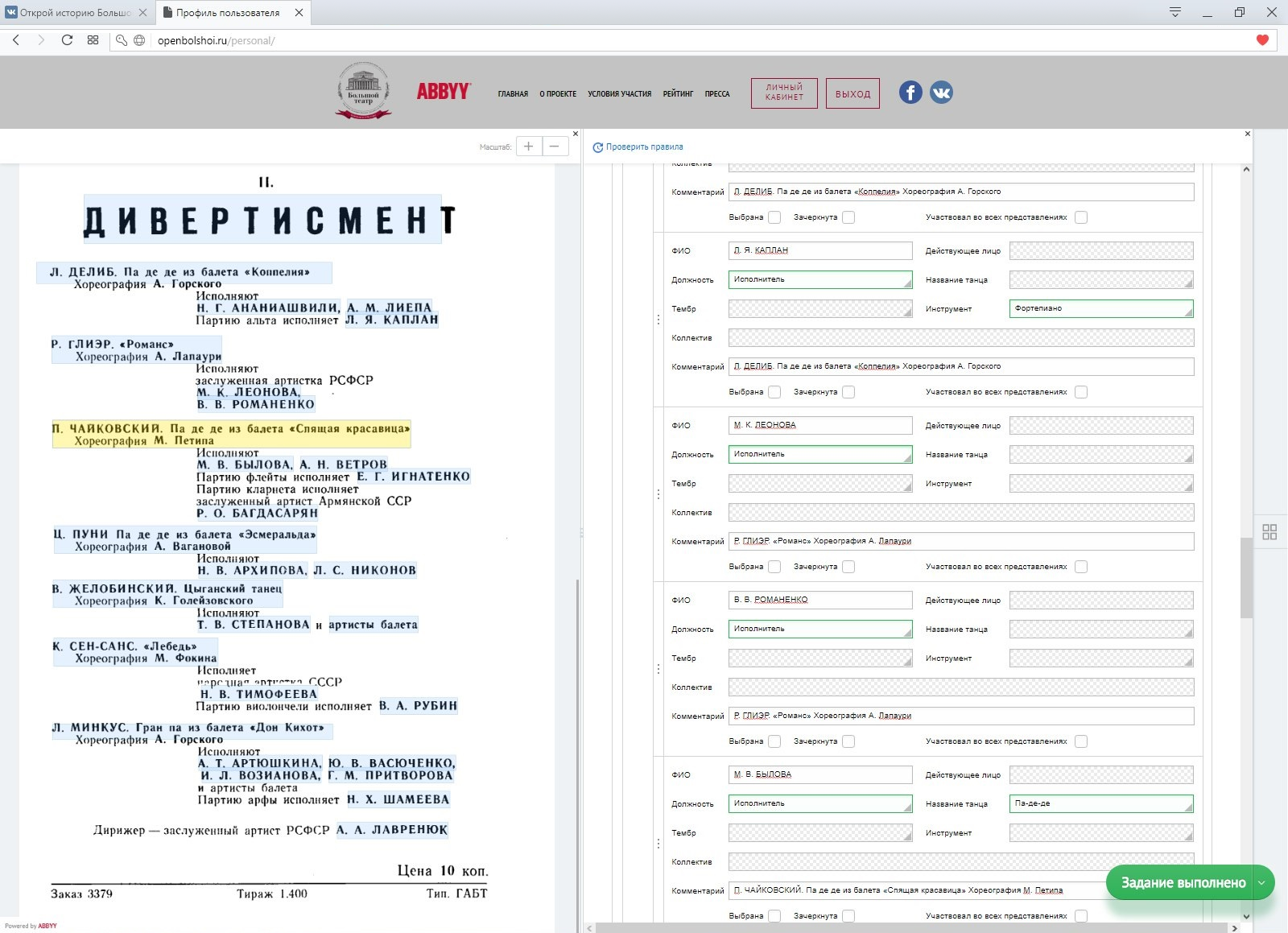
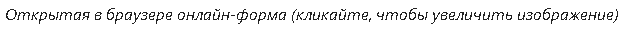
«Открой историю Большого» стал первым крупным проектом, сделанным с помощью новой на тот момент 12-ой версии ABBYY FlexiCapture. Мы использовали бета-версию платформы. Набор полей разработали специально под проект, так чтобы в них было удобно добавлять представления и персоны. В группе проекта «ВКонтакте» волонтеры задавали много вопросов и оставляли просьбы и пожелания разработчикам онлайн-формы. По комментариям от участников проекта мы постоянно улучшали функциональность формы, чтобы сделать работу волонтеров максимально комфортной. Например, в форме появились новые возможности.
Подробнее о них рассказываем под спойлером.
1. Добавление и удаление полей с персонами.

Это удобно, если в спектакле участвует большое количество артистов и всех надо быстро внести в онлайн-форму.
2. Дублирование персон во все представления.
В одной программе может быть несколько концертов, балетов или опер, в которых участвует, например, один дирижер. Чтобы не дублировать информацию, волонтерам было достаточно внести название должности только в первое представление, а затем поставить у каждой персоны галочку «Участвовал во всех представлениях». Поля автоматически дублировались при отправке документа на проверку.

3. Внесение персон с одной и той же ролью.

Это позволило еще быстрее вносить информацию в онлайн-форму. Например, можно сразу добавлять в список всех персон, которые танцуют один и тот же танец, играют одну и ту же роль (например, тритонов) и отличаются только по полю «ФИО». Для этого нужно было заполнить поля только для первой персоны, а для остальных указать ФИО в именительном падеже. При отправке пакета на проверку данные из списка загружались автоматически.

4. Добавление элементов и поиск по букве в выпадающих списках.

Это удобно, если в спектакле участвует большое количество артистов и всех надо быстро внести в онлайн-форму.
2. Дублирование персон во все представления.
В одной программе может быть несколько концертов, балетов или опер, в которых участвует, например, один дирижер. Чтобы не дублировать информацию, волонтерам было достаточно внести название должности только в первое представление, а затем поставить у каждой персоны галочку «Участвовал во всех представлениях». Поля автоматически дублировались при отправке документа на проверку.
3. Внесение персон с одной и той же ролью.
Это позволило еще быстрее вносить информацию в онлайн-форму. Например, можно сразу добавлять в список всех персон, которые танцуют один и тот же танец, играют одну и ту же роль (например, тритонов) и отличаются только по полю «ФИО». Для этого нужно было заполнить поля только для первой персоны, а для остальных указать ФИО в именительном падеже. При отправке пакета на проверку данные из списка загружались автоматически.
4. Добавление элементов и поиск по букве в выпадающих списках.
А теперь самое интересное. Волонтерам не нужно было перепечатывать информацию из программ и афиш. Достаточно было кликнуть на слово (распознанный текстовый слой) или выделить курсором всю фразу, и тогда текст автоматически вставлялся в необходимое поле формы. Это ускоряло работу участников в несколько раз:

Отдѣльная глава про дореволюціонную орѳографію
Во всех документах 19 века и начала 20-го использовалась русская дореформенная орфография с
буквами «i» (и десятеричное), «ѣ» (ять), «ѳ» (фита), непривычным начертанием и стилем изложения. Волонтеры могли вносить информацию как на старом языке, так и на современном русском. После проверки пакета специально разработанный специалистами ABBYY скрипт, написанный на Python, автоматически переводил все на русский язык, чтобы в архив музея Большого театра попадали данные из афиш и программ на современном и всем понятном языке. В скрипте мы использовали словари русского языка и пару десятков правил в виде регулярных выражений.
Несмотря на то что ABBYY FlexiCapture умеет распознавать русскую дореформенную орфографию, в старинных документах с нечеткими или затертыми буквами у платформы получилось распознать не все слова. Иногда вылезали разные ошибки, которые надо было исправлять, например:
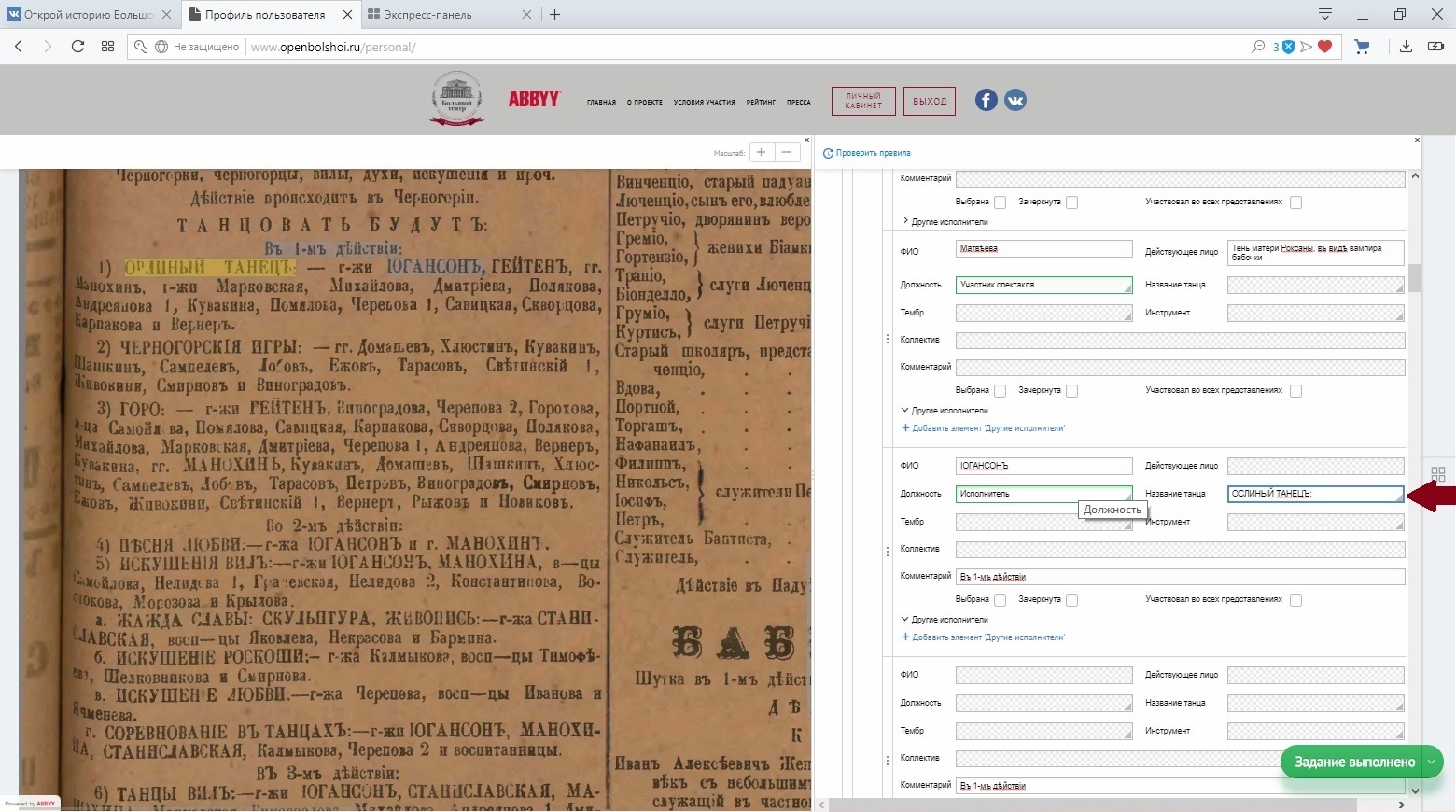
Волонтер начал заполнять форму, и увидел, как технология неправильно распознала словосочетание «Орлиный танец» (кликайте, чтобы увеличить изображение)
Что происходило после проверки пакета
Как только волонтер проверил пакет, он нажимал на кнопку «Задание выполнено», и тогда пакет отправлялся еще на две стадии проверки в Оргкомитет. Проверяющие смотрели, правильно ли заполнены все поля и вся ли информация внесена.
Если участник неправильно заполнил много полей или оставил большую часть формы пустой, проверяющий не принимал работу аудитора
Во время работы волонтеры собирали и присылали нам интересные факты, обнаруженные в исторических документах. Например, рекламные объявления в афишах, списки забытых в театре вещей, анонсы необычных спектаклей и многое другое.
Смотрите подборку с самыми необычными примерами под спойлером.

С начала XIX века в театральных программах размещали информацию не только о предстоящих постановках, но и рекламу. Деньги под залог, элитный алкоголь, услуги зубного врача, лекции для девиц, крем «Атласный» — волонтеры находили и присылали нам немало интересных объявлений. Проект «Открой историю Большого» собрал самые необычные из них, и их опубликовали в фотогалерее газеты «Ведомости».
Волонтеры увлеченно собирали и любопытные сведения о потерянных предметах. С 1872 по 1902 год списки с забытыми в театре вещами можно было обнаружить прямо на афишах. Как выяснилось, в театре случайно оставались резиновые галоши, кофейник, патроны, гильотинка для сигар и многое другое. Самые необычные предметы – в подборке на bigpikcha.ru.

Помимо рекламы и списков различных вещей, в программах можно было обнаружить и представления с непривычными для современных людей названиями. «Разрыв-трава» и «Волшебное кукареку» – это не песни современных панк-групп, а названия реальных спектаклей, на которые ходила столичная публика до революции. Чтобы узнать больше об этих постановках, пройдите тест на портале РИА «Новости».
С начала XIX века в театральных программах размещали информацию не только о предстоящих постановках, но и рекламу. Деньги под залог, элитный алкоголь, услуги зубного врача, лекции для девиц, крем «Атласный» — волонтеры находили и присылали нам немало интересных объявлений. Проект «Открой историю Большого» собрал самые необычные из них, и их опубликовали в фотогалерее газеты «Ведомости».
Волонтеры увлеченно собирали и любопытные сведения о потерянных предметах. С 1872 по 1902 год списки с забытыми в театре вещами можно было обнаружить прямо на афишах. Как выяснилось, в театре случайно оставались резиновые галоши, кофейник, патроны, гильотинка для сигар и многое другое. Самые необычные предметы – в подборке на bigpikcha.ru.

Помимо рекламы и списков различных вещей, в программах можно было обнаружить и представления с непривычными для современных людей названиями. «Разрыв-трава» и «Волшебное кукареку» – это не песни современных панк-групп, а названия реальных спектаклей, на которые ходила столичная публика до революции. Чтобы узнать больше об этих постановках, пройдите тест на портале РИА «Новости».
Как были устроены экспорт и бэкап
Каждую неделю мы делали бэкап пакетов, которые находились на проверке в ABBYY FlexiCapture, и размещали его в хранилище нашего технологического партнера по проекту — NetApp.
Все проверенные пакеты мы отправляли в файловое хранилище размером около 3 терабайт, где программы, афиши с текстовым слоем и их изображения были собраны в папках по годам (1900-1909, 1910-1919 и т.д.). Хранилище было связано с финальной базой данных. Там в виде таблицы находилась информация по каждому представлению, роли или артисту. Данные можно дополнять, изменять, а также вести по ним поиск (картинка кликабельна):
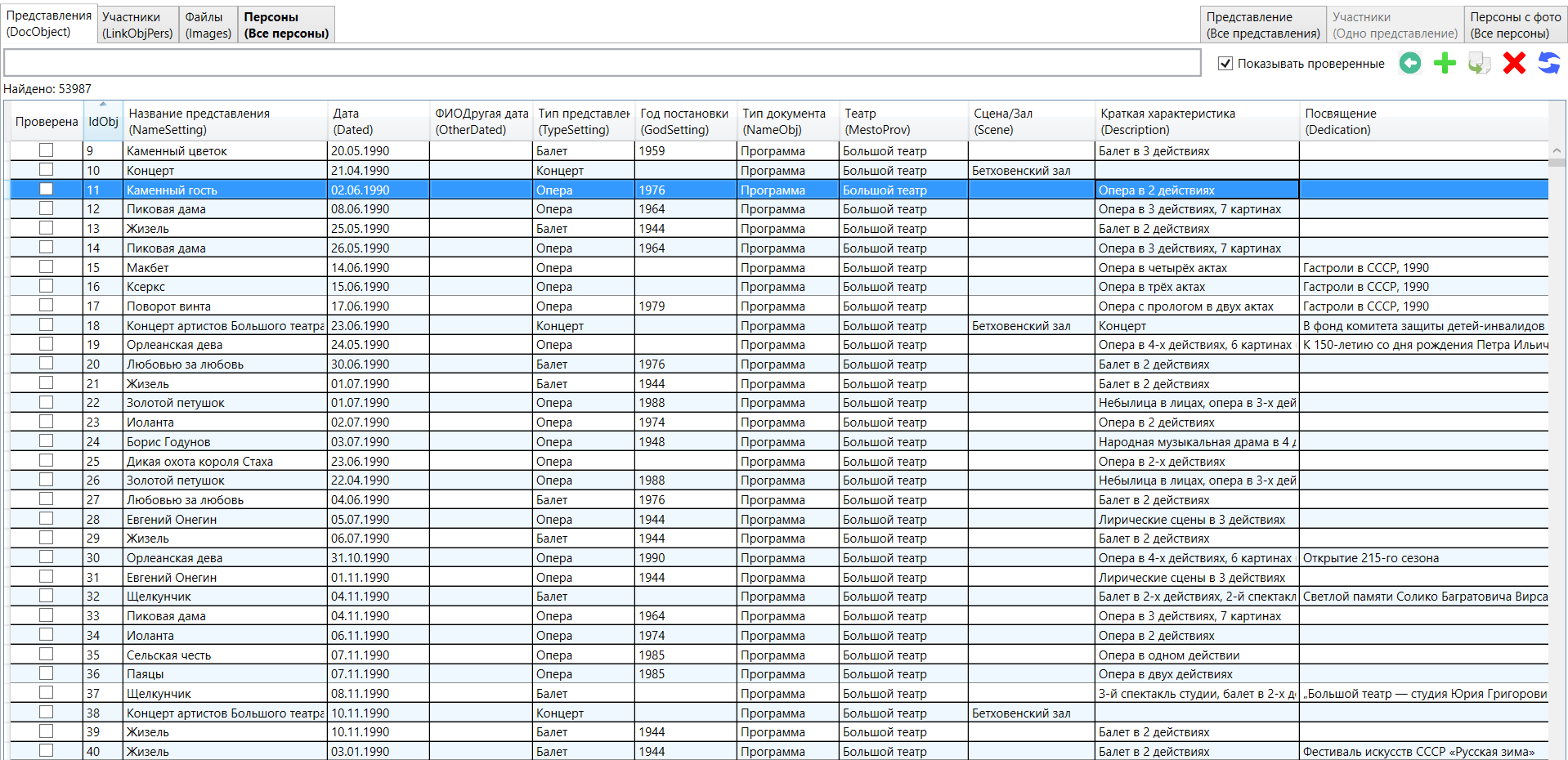
Бэкап финальной базы данных, которая во время второго этапа регулярно пополнялась проверенными пакетами, происходил каждые два дня.
Победители второго этапа
Второй этап проекта завершился в декабре 2018 года. Всего в нем участвовали почти 7500 волонтеров из 60 стран. По нашим подсчетам, каждый день проверкой программ и афиш занимались одновременно 10-15 волонтеров.
Как и во время первого этапа, за каждый проверенный пакет Оргкомитет начислял волонтерам баллы и формировал рейтинг самых активных участников. В финале первые пять из них получили призы – билеты в Большой театр. Первое место заняла Ольга Синельникова, она проверила 5352 программ и афиш. В пятерку победителей также вошли Наталья Клементьева, Михаил Ройтман, Галина Зарина и Валерий Пальчевский – волонтеры из Москвы. Они выбрали интересные им постановки и посетили спектакли «Дон Кихот», «Дон Карлос», «Черевички», «Спартак» и «Дочь фараона».

А что с историческими фотографиями?
В декабре 2018 года мы открыли третий этап проекта – рубрикацию 100 тысяч оцифрованных фотографий. В это время к проекту присоединилось еще более 300 волонтеров. Участники внесли рукописный текст с оборотов фотографий в базу данных: на снимках запечатлены 5650 персон и 927 представлений.
Как создается электронный архив
Финальную базу данных мы передали музею Большого театра. Вся информация из архивов театра о 54 тысячах спектаклей и 75 тысячах персон была загружена на сайт электронного архива, разработанного компанией КАМИС. По мере проверки специалистами музея Большого театра, данные публикуются на специально разработанном поисковом разделе театрального сайта. В результате каждый сможет увидеть программы, афиши, фотографии, эскизы декораций и костюмов и узнать об операх, балетах, концертах и артистах.
На сайте openbolshoi.ru мы собрали статистику об итогах проекта, хронологию спектаклей за 150 лет, а также интересные факты об артистах и их ролях. Читайте и пишите нам, о каких еще исполнителях и знаменитых постановках вы хотели бы узнать.
Что мотивирует нас на такие проекты и что будет дальше?
На протяжении многих лет опыт и технологии ABBYY помогают выполнять важную миссию – сохранять культурное наследие и делать его доступным для широкой публики по всему миру. Например, благодаря нашим интеллектуальным решениям были реализованы десятки социально значимых проектов – от оцифровки полного собрания сочинений Толстого, фондов библиотек в Латвии, Южной Корее, России (на Сахалине) до перевода в электронный вид различных архивов – с записями о погоде в метеорологическом институте Бразилии, с данными о 3 миллионах растений в ботаническом саду Эдинбурга и так далее. Проект «Открой историю Большого» стал еще одним этапом нашего развития в этом направлении.
И, конечно же, не всегда такие задачи возможно выполнить только своими силами. Своим успехом проект «Открой историю Большого» обязан волонтерам. Неравнодушные люди со всего мира из любви к искусству присоединялись к проекту и безвозмездно уделяли личное время проверке сложных программ и афиш. Зато взамен они получали ценный опыт, первыми узнавали из исторических документов о нравах позапрошлых веков, любовались картинами знаменитых театральных художников – А.М. Васнецова, К.А. Коровина и других. И ощущали свою причастность к истории искусства балета и оперы.
Таким образом технологии, которые создает ABBYY, делают жизнь организаций и людей лучше и интереснее. И это, наверное, самая большая мотивация для нас. Мы открыты новым проектам и предложениям. На ваш взгляд, в решении каких еще задач могли бы помочь наши технологии?
Елизавета Титаренко, редактор корпоративного блога ABBYY,
Марина Антропова, ведущий менеджер по специальным проектам ABBYY

