Добрый день.
Меня зовут Игорь Хапов. Я руководитель разработки в Научно-техническом центре IBM. И сегодня я хотел бы вам помочь окунуться в мир периферийных вычислений, или edge computing, как его ещё называют. Я расскажу о том, что же такое edge computing и как он может повлиять на наш с вами мир. Также хотелось бы пояснить различия между edge computing и fog computing, какие преимущества даёт этот подход. В статье я также описал референсную архитектуру приложения на edge computing. И под конец немного расскажу о проекте с открытым исходным кодом Open Horizon, который совсем недавно присоединился к Linux Foundation.

Что же такое edge computing
Согласно определению Гартнера, edge computing — это подвид распределенных вычислений, в котором обработка информации происходит в непосредственной близости к месту, где данные были получены и будут потребляться. Это основное отличие edge computing от облачных вычислений, при которых информация собирается и обрабатывается в публичных или частных датацентрах. Основным отличием от локальных вычислений является то, что обычно edge computing — это часть большей системы, которая включает в себя сбор статистики, централизованное управление и удаленное обновление приложений на edge устройствах.
Что же такое edge устройство? Многие считают, что edge computing — это когда приложение работает на Raspberry Pi или других микрокомпьютерах. На самом деле edge computing может быть и на мобильных устройствах, персональных ноутбуках, умных камерах и других устройствах, на которых можно запустить приложение по обработке данных.
В целом, когда я изучал этот вопрос, у меня сложилось впечатление, что тема недооценена и что многие, пытаясь решить задачи edge computing, изобретают свой велосипед и применяют подходы, используемые при облачных вычислениях. Также достаточно часто происходит путаница в терминах IoT, edge computing и fog computing. Попробуем с этим разобраться.
Edge computing и IoT
Довольно часто звучит вопрос — "Чем же отличается edge computing от IoT". IoT можно назвать дедушкой edge computing. IoT — это множество устройств, связанных между собой, и способных передавать информацию друг другу. А edge computing это скорее подход к организации вычислений и управлению edge устройствами. Как вы отлично понимаете, любое приложение необходимо обновлять, мониторить и осуществлять прочие обслуживающие функции. В результате edge computing подразумевает использование определенных подходов и фреймворков, о которых я расскажу чуть позже.
edge computing vs fog computing
Когда я однажды рассказал коллеге про edge computing, он ответил — ”так это же fog computing”. Давайте попробуем разобраться, в чём же разница. С одной стороны, edge computing и fog computing часто используются как синонимы, однако fog computing, или "туманные вычисления", все-таки немного отличаются.
И edge computing, и fog computing — это вычисления, которые находятся в непосредственной близости к получаемым данным. Различие заключается в том, что при туманных вычислениях обработка осуществляется на устройствах, которые постоянно подключены к сети. В edge computing вычисления осуществляются как на сенсорах, умных устройствах – без передачи на уровень gateway, так и на уровне gateway и на микрокластерах.
Для меня было открытием, что edge computing может работать в кластерах Kubernetes или OpenShift. Оказывается, что существует достаточно много задач, где кроме оконечных устройств необходимо выполнять обработку информации в локальном кластере и передавать в централизованные дата центры только результирующие данные. И такие вычисления — тоже edge computing.
Преимущества и недостатки edge computing
При выборе технологий для своего проекта я в первую очередь основываюсь на двух критериях — "Что я от этого получу?" и "Какие проблемы я от этого получу?".
Начнём с преимуществ:
- Во-первых, это снижение количества трафика, передаваемого по сети, за счет обработки информации на самом устройстве и передачи только результирующих данных. Особенно виден эффект при использовании edge computing при обработке видеопотока и большого количества фотографий, а также при работе с несжатым звуком.
- Во-вторых, это уменьшение задержек, если необходимо оперативно отреагировать на те или иные результаты обработки данных.
- Для многих систем также важно, чтобы персональные данные не выходили из определённого контура. С введением электронных медицинских карт данное требование является крайне актуальным на сегодняшний день.
- Возможность для устройства быть независимым, определённое время работать без доступа к центральным серверам также повышают отказоустойчивость системы. А централизованный сбор результирующей информации защищает от потери данных при отказе edge-устройства.
Хотя, конечно, проектируя систему с edge computing, не стоит забывать, что как и любую другую технологию её стоит использовать в зависимости от требований к системе, которую вам необходимо реализовать.
Среди недостатков edge computing можно выделить следующие:
- Крайне тяжело обеспечить гарантию отказоусточивости для всех edge-устройств.
- Устройства могут иметь различные платформы и версии OS, для чего, вероятно, потребуется создавать несколько версий сервисов (например, для x86 и ARM).
- Для управления большим количеством устройств потребуется платформа, решающая технические задачи edge computing.
С одной стороны, последний пункт является наиболее критичным, но, к счастью, консорциум Linux Foundation Edge (LF EDGE) включает в себя всё больше и больше проектов с открытым исходным кодом, а их зрелость стремительно растет.
Принципы компании IBM при создании платформы edge computing
Компания IBM, являясь одним из лидеров в области гибридных облаков, использует определённые принципы при разработке решений для edge computing:
- Развивать инновации (Drive Innovation)
- Обеспечить безопасность данных (Secure data)
- Управлять в масштабе (Manage at scale)
- Открытость исходного кода (Open Source)
IBM применяет эти принципы при декомпозиции задачи построения фреймворка edge computing.
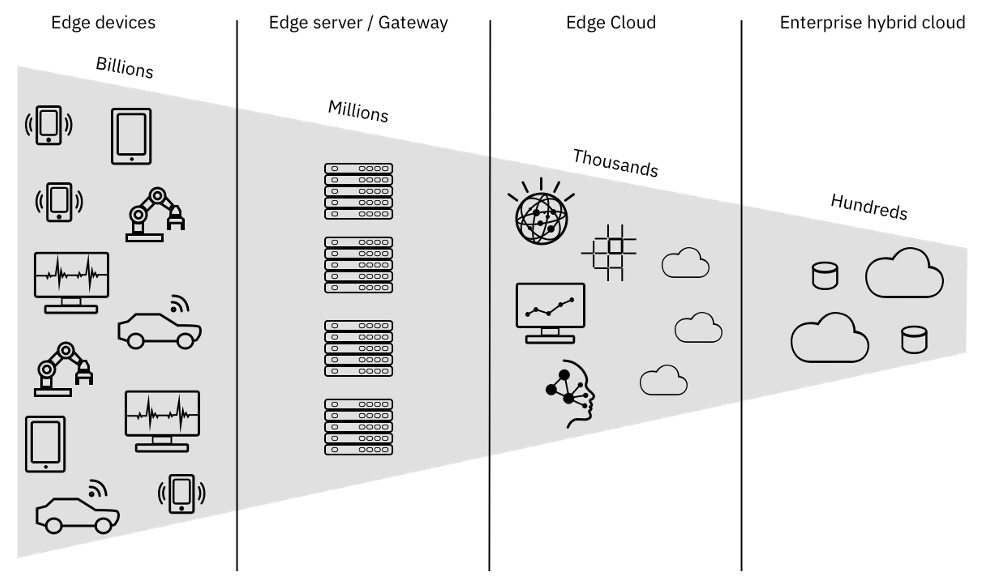
Как вы можете видеть, всё решение разбито на 4 сегмента использова��ия:
- Edge-устройства
- Edge-сервера или шлюзы
- Edge-облако
- Гибридное облако в частном или публичном дата центре
Помимо основных принципов и подходов, IBM разработала референсную архитектуру для решений, основанных на edge computing. Референсная архитектура — это шаблон, показывающий основные элементы системы и детализированный настолько, чтобы иметь возможность адаптировать его под конкретное решение для заказчика. Давайте рассмотрим такую архитектуру более подробно.
Референсная архитектура edge computing
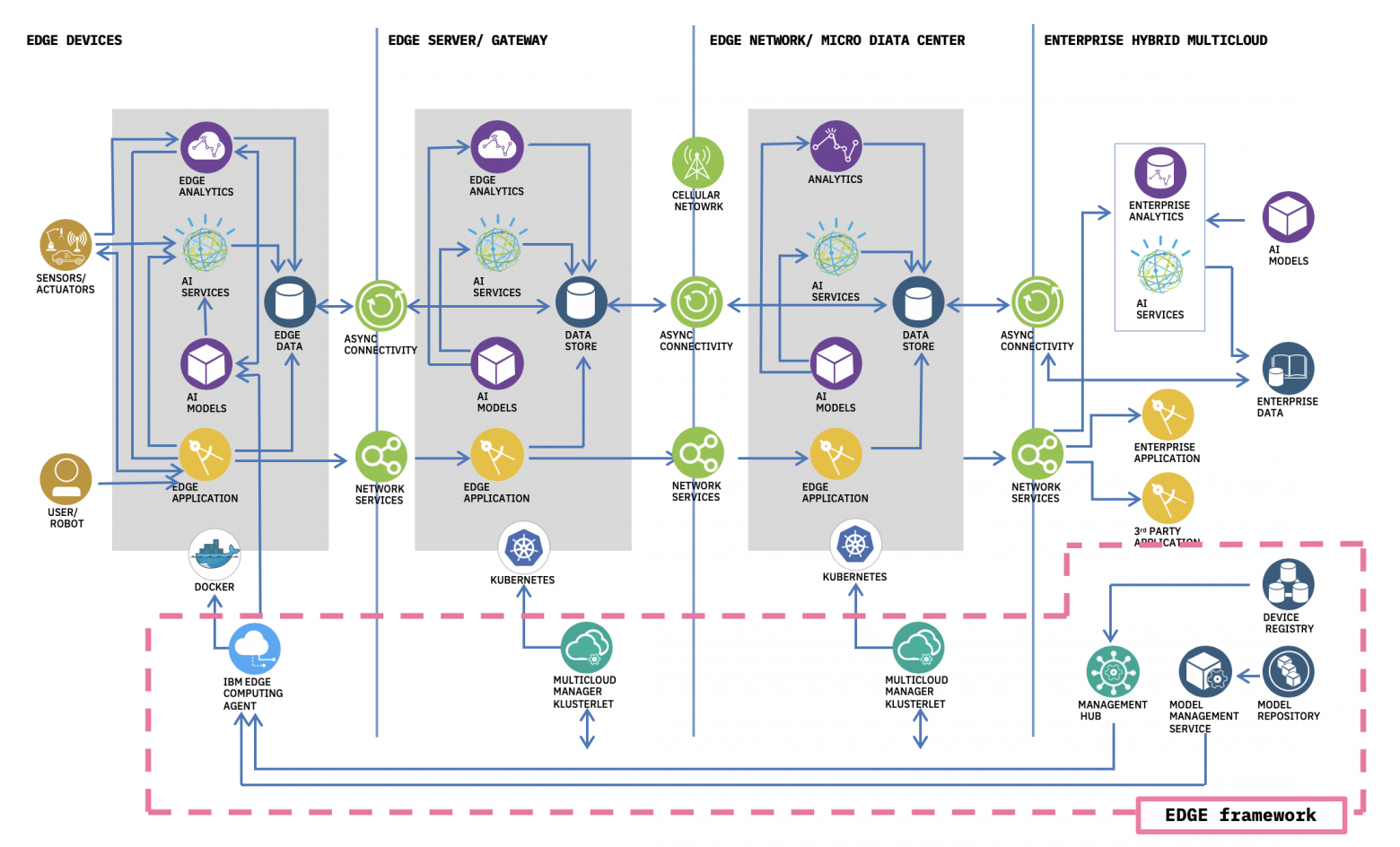
Edge devices
В первую очередь, у нас есть какое-либо встроенное или дискретное edge-устройство, к которому подключены сенсоры, датчики или управляющие механизмы, например, для координации движения роборуки. Из сервисов/данных на таком устройстве могут находиться:
- Модель обработки данных, например, предобученная ML-модель
- Сервис аналитики, который является средой исполнения модели
- Пользовательский интерфейс для отображения результатов или инициирования аналитики
- Легковесная база данных для хранения промежуточных результатов и кеширования на случай сбоя связи с центральным сервером
- Любые другие сервисы в зависимости от решаемых на данном устройстве задач
Hybrid multicloud
Если мы говорим об использовании ML-модели, которая будет запускаться на десятках или тысячах устройств, то нам необходимо облако, которое сможет отвечать за обучение такой модели, обработку статистики, отображение сводной информации (правая часть архитектуры).
Edge server and Edge micro data center
Как мы уже говорили, можно встретить промежуточные (близкие) кластеры обработки данных на уровне шлюзов или микро-датацентров с установленной поддержкой кластерных технологий.
Edge framework
Когда мы осознаем, что есть необходимость в управлении большим количеством сервисов на тысячах устройств и сотнями приложений в разных кластерах, наступает понимание, что надо бы использовать какой-то фреймворк для управления всем этим зоопарком и синхронизации между устройствами.
Именно наличие данного фреймворка раскрывает преимущества edge computing перед разнородными разнесёнными вычислениями.
Как мы видим, кроме центральной части по управлению сервисами и моделями в данном фреймворке присутствуют агенты, обеспечивающие контроль за управлением жизненным циклом сервисов на устройствах/кластерах на каждом из уровней использования.
Open Horizon и IBM Edge Application Manager
Именно для решения задач в области edge computing IBM разработала и выложила в open-source проект Open Horizon. Если вы помните, один из принципов, которые IBM заложила в edge computing – все компоненты должны быть основаны на open source технологиях. В мае 2020 года проект Open Horizon вошел в Linux Foundation Edge — Международный фонд open-source технологий для созданий edge-решений. Также Open Horizon является ядром нового продукта от RedHat и IBM — IBM Edge Application Manager, решения для управления приложениями на всех устройствах edge computing: от Raspberry Pi до промежуточных кластеров обработки данных.

Несмотря на то, что проект Open Horizon вошел в консорциум только в мае, он уже достаточно давно развивается как open-source проект. И мы в Научно-техническом центре IBM не только успели его попробовать, но и довести свое решение до промышленного использования. О том, как мы разрабатывали проект с использованием edge computing, и что у нас получилось — будет отдельная статья, которая выйдет в ближайшие несколько недель.
Сценарии использования
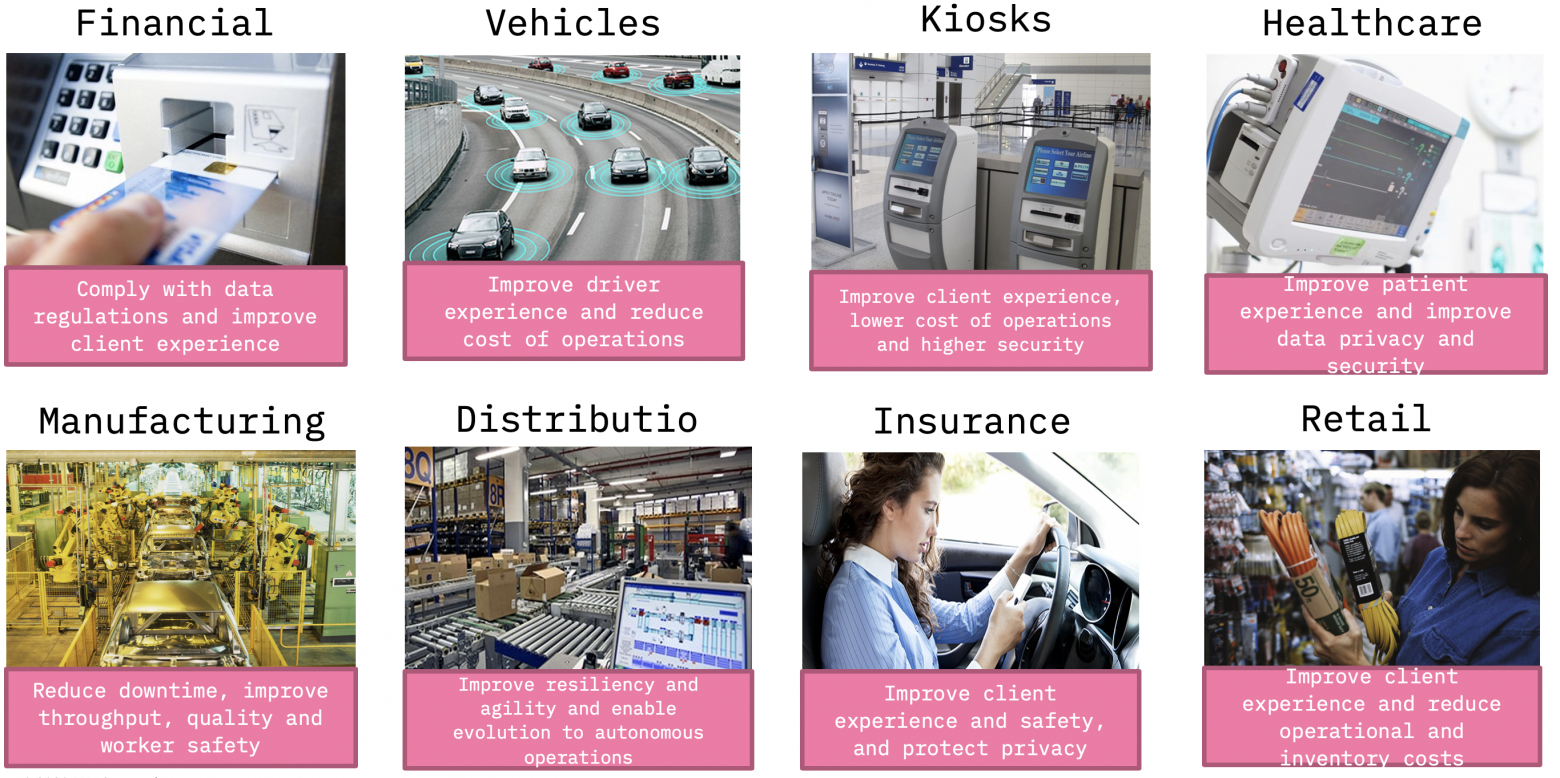
С одной стороны, edge computing framework — это специализированное решение для определённого круга задач, но оно нашло применение во многих индустриях.
В своё время, когда я изучал работу московских камер “Стрелка”, я понял, что это в чистом виде edge computing, с вычислениями "прямо на столбе" и промежуточной обработкой данных в раздельных вычислительных кластерах у различных ведомств.
Сценарии нашлись в финансовом секторе, в продажах при самообслуживании, в медицине и секторе страхования, торговле и конечно при производстве. Именно в создании решения для автоматизации и оценки качества произведённого оборудования, основанного на edge computing, мне с коллегами из Научно-технического центра IBM и посчастливилось принять участие. И на своем опыте попробовать, как создаются решения edge computing.
Если Вас заинтересовала данная тематика, следите за обновлениями в хабраблоге компании IBM и смотрите видео в разделе Ссылки. Наши зарубежные коллеги к настоящему моменту уже осветили многие технические вопросы и описали, какие сценарии уже работают и применяются в различных отраслях.
Ссылки
- github репозиторий Open Horizon
- Linux Foundation Edge — сайт open-source консорциума LF EDGE
- хороший блог про архитектуру Open Horizon и примеры
- что такое edge computing — Rob High, IBM Fellow
- будущее edge computing — интервью с Rob High
- IBM Edge Application Manager — Sai Vennam, IBM Developer advocate

