Время обработки данных в одном знакомом мне проекте энтерпрайз-хранилища данных с реляционной моделью составляет почти 2,5 часа. Много это или мало?
Заметка описывает эксперимент по созданию маленькой копии энтерпрайз-хранилища данных с сильно ограниченными техническими условиями. А именно, на базе одноплатного компьютера Raspberry Pi.
Модель и архитектура будут упрощёнными, но похожими на энтерпрайз-хранилище. Результатом является оценка возможности использования Raspberry Pi в области обработки и анализа данных.

Роль опытного и сильного игрока будет выполнять машина Exadata Х5 (один юнит) корпорации Оракл.
Процесс обработки данных включает в себя следующие шаги:
Итого, интеграция 350 миллионов записей за 2,5 часа, что эквивалентно 2,3 миллионам записей в минуту или примерно 39 тысячам записей исходных данных в секунду.
В роли экспериментального оппонента будет выступать Raspberry Pi 3 Model B+ с 4х-ядерным процессором 1.4 ГГц.
В качестве хранилища используется sqlite3, чтение файлов происходит с помощью PHP. Файлы и база данных находятся на SD карте размером 32 ГБ класса 10 во строенном ридере. Резервная копия создаётся на флэш диске 64 ГБ, подключённом к USB.
Модель данных в реляционной базе sqlite3 и отчеты описаны в статье о маленьком хранилище.
Исходный файл access.log — 37 МБ с 200 тысячами записей.
Итого, интеграция 200 тысяч записей заняла почти 7 минут, что эквивалентно 28 тысячам записей в минуту или 470 записям исходных данных в секунду. База данных занимает 7,5 МБ; всего 8 SQL запросов для обработки данных.
Файл более активного сайта. Исходный файл access.log — 67 МБ с 290 тысячами записей.
Итого, интеграция 290 тысяч записей заняла чуть больше 12 минут, что эквивалентно 23 тысячам записей в минуту или 380 записям исходных данных в секунду. База данных занимает 22,9 МБ
Для получения данных в виде модели, которая позволит проводить эффективный анализ, необходимы значительные вычислительные и материальные ресурсы, и время в любом случае.
Например, один юнит Экзадаты обходится более чем в 100К. Один Raspberry Pi стоит 60 единиц.
Линейно их нельзя сравнивать, т.к. с увеличением объёмов данных и требований надёжности возникают сложности.
Однако, если представить себе случай, когда тысяча Raspberry Pi работают параллельно, то, исходя из эксперимента, они обработают около 400 тысяч записей исходных данных в секунду.
И если решение для Экзадаты оптимировать до 60 или 100 тысяч записей в секунду, то это ощутимо меньше, чем 400 тысяч. Это подтверждает внутреннее ощущение того, что цены энтерпрайз-решений завышены.
В любом случае, Raspberry Pi отлично справлятся с обработкой данных и реляционными моделями соответствующего масштаба.
Домашний Raspberry Pi был настроен как веб сервер. Этот процесс я опишу в следующей заметке.
Эксперимент с производительностью Raspberry Pi и файлом access.log можно провести самостоятельно по адресу. Модель базы данных (DDL), процедуры загрузки (ETL) и саму базу данных можно там же скачать. Идея состоит в том, чтобы быстро получить представление о состоянии сайта из лога с данными за последние недели.
Изменения
Благодаря комментариям, ошибка в загрузке файла Exadata поправлена и цифры в заметке исправлены. Для чтения используется sqlloader, какой-то жук удалил параметры BINDSIZE и ROWS. По причине неустойчивой загрузки с удалённого накопителя выбран способ conventional вместо direct path, который мог бы увеличить скорость ещё на 30-50%.
Заметка описывает эксперимент по созданию маленькой копии энтерпрайз-хранилища данных с сильно ограниченными техническими условиями. А именно, на базе одноплатного компьютера Raspberry Pi.
Модель и архитектура будут упрощёнными, но похожими на энтерпрайз-хранилище. Результатом является оценка возможности использования Raspberry Pi в области обработки и анализа данных.
№1
Роль опытного и сильного игрока будет выполнять машина Exadata Х5 (один юнит) корпорации Оракл.
Процесс обработки данных включает в себя следующие шаги:
- Чтение из файла 10,3 ГБ — 350 миллионов записей за 90 минут.
- Обработка и очистка данных — 2 SQL запроса и 15 минут (с шифрованием персональных данных 180 минут).
- Загрузка измерений — 10 минут.
- Загрузка таблиц фактов 20 миллионами новых записей — 5 SQL запросов и 35 минут.
Итого, интеграция 350 миллионов записей за 2,5 часа, что эквивалентно 2,3 миллионам записей в минуту или примерно 39 тысячам записей исходных данных в секунду.
№2
В роли экспериментального оппонента будет выступать Raspberry Pi 3 Model B+ с 4х-ядерным процессором 1.4 ГГц.
В качестве хранилища используется sqlite3, чтение файлов происходит с помощью PHP. Файлы и база данных находятся на SD карте размером 32 ГБ класса 10 во строенном ридере. Резервная копия создаётся на флэш диске 64 ГБ, подключённом к USB.
Модель данных в реляционной базе sqlite3 и отчеты описаны в статье о маленьком хранилище.
Модель данных
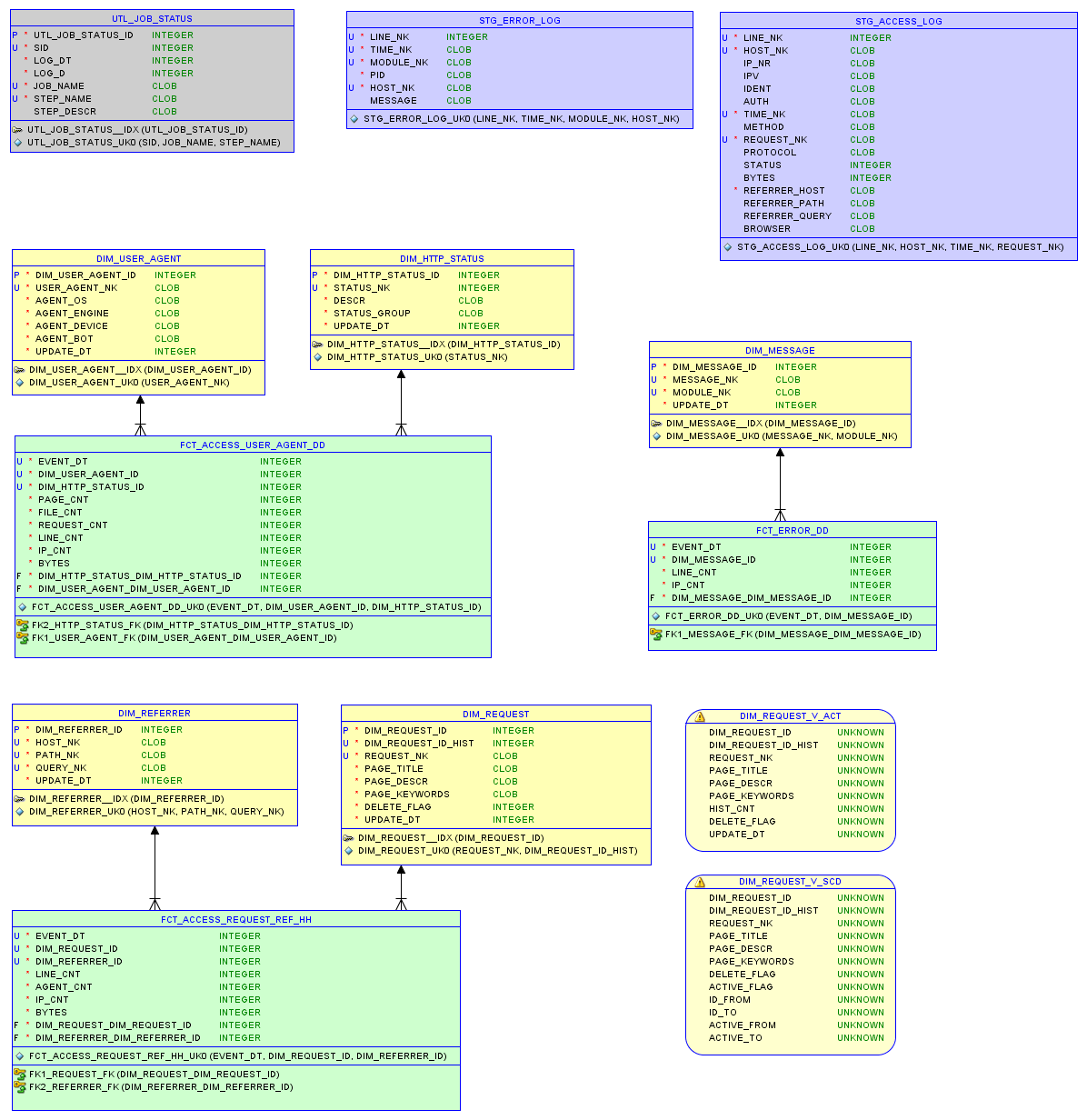
Тест первый
Исходный файл access.log — 37 МБ с 200 тысячами записей.
- Прочитать лог и записать в базу данных заняло 340 секунд.
- Загрузка измерений с 5 тысячами записей длилась 5 секунд.
- Загрузка таблиц фактов 90 тысячами новых записей — 32 секунды.
Итого, интеграция 200 тысяч записей заняла почти 7 минут, что эквивалентно 28 тысячам записей в минуту или 470 записям исходных данных в секунду. База данных занимает 7,5 МБ; всего 8 SQL запросов для обработки данных.
Тест второй
Файл более активного сайта. Исходный файл access.log — 67 МБ с 290 тысячами записей.
- Прочитать лог и записать в базу данных заняло 670 секунд.
- Загрузка измерений с 25 тысячами записей длилась 8 секунд.
- Загрузка таблиц фактов 240 тысячами новых записей — 80 секунд.
Итого, интеграция 290 тысяч записей заняла чуть больше 12 минут, что эквивалентно 23 тысячам записей в минуту или 380 записям исходных данных в секунду. База данных занимает 22,9 МБ
Вывод
Для получения данных в виде модели, которая позволит проводить эффективный анализ, необходимы значительные вычислительные и материальные ресурсы, и время в любом случае.
Например, один юнит Экзадаты обходится более чем в 100К. Один Raspberry Pi стоит 60 единиц.
Линейно их нельзя сравнивать, т.к. с увеличением объёмов данных и требований надёжности возникают сложности.
Однако, если представить себе случай, когда тысяча Raspberry Pi работают параллельно, то, исходя из эксперимента, они обработают около 400 тысяч записей исходных данных в секунду.
И если решение для Экзадаты оптимировать до 60 или 100 тысяч записей в секунду, то это ощутимо меньше, чем 400 тысяч. Это подтверждает внутреннее ощущение того, что цены энтерпрайз-решений завышены.
В любом случае, Raspberry Pi отлично справлятся с обработкой данных и реляционными моделями соответствующего масштаба.
Ссылка
Домашний Raspberry Pi был настроен как веб сервер. Этот процесс я опишу в следующей заметке.
Эксперимент с производительностью Raspberry Pi и файлом access.log можно провести самостоятельно по адресу. Модель базы данных (DDL), процедуры загрузки (ETL) и саму базу данных можно там же скачать. Идея состоит в том, чтобы быстро получить представление о состоянии сайта из лога с данными за последние недели.
Изменения
Благодаря комментариям, ошибка в загрузке файла Exadata поправлена и цифры в заметке исправлены. Для чтения используется sqlloader, какой-то жук удалил параметры BINDSIZE и ROWS. По причине неустойчивой загрузки с удалённого накопителя выбран способ conventional вместо direct path, который мог бы увеличить скорость ещё на 30-50%.

