Кейс компании Appbooster
Полагаю, практически каждый проект, использующий Ruby on Rails и Postgres в качестве основного вооружения на бэкенде находится в перманентной борьбе между скоростью разработки, читаемостью/поддерживаемостью кода и скоростью работы проекта в продакшене. Я расскажу о своем опыте балансирования между этими тремя китами в кейсе, где на входе страдали читаемость и скорость работы, а на выходе получилось сделать то, что до меня безуспешно пытались сделать несколько талантливых инженеров.

Полностью вся история займёт несколько частей. Это первая, где я расскажу о том что такое PMDSC для оптимизации SQL-запросов, поделюсь полезными инструментами измерения эффективности запросов в postgres и напомню об одной полезной старой шпаргалке, которая до сих пор актуальна.
Сейчас, спустя какое-то время, “задним умом” я понимаю, что на входе в этот кейс совершенно не ожидал что у меня всё получится. Поэтому этот пост будет полезен скорее для смелых и не самых опытных разработчиков, чем для супер-сеньоров видавших рельсы с голым SQL.
Мы в Appbooster занимаемся продвижением мобильных приложений. Чтобы легко выдвигать и проверять гипотезы мы разрабатываем несколько своих приложений. Бэкенд большинства из них это Rails API и Postgresql.
Герой этой публикации разрабатывается с конца 2013 года – тогда только-только вышел rails 4.1.0.beta1. С тех пор проект вырос в полноценно нагруженное веб-приложение, которое крутится на нескольких серверах в Amazon EC2 c отдельным инстансом базы данных в Amazon RDS (db.t3.xlarge с 4 vCPU и 16 GB RAM). Пиковые нагрузки доходят до 25k RPM, средняя нагрузка днём 8-10k RPM.
С инстанса базы данных, точнее с её кредитного баланса и началась эта история.

Как работает инстанс Postgres типа “t” в Амазон RDS: если ваша база данных работает со средним потреблением процессорного времени ниже определенного значения, то у вас на счету накапливаются кредиты, которые инстанс может тратить на потребление процессора в часы высокой нагрузки – это позволяет не переплачивать за серверные мощности и справляться с высокой нагрузкой. Более подробно о том за что и сколько платят, используя AWS можно прочитать в статье нашего CTO.
Баланс кредитов в определенный момент исчерпался. Некоторое время этому не придавалось большого значения, потому как баланс кредитов можно пополнять за счет денег – нам это стоило около $20 в месяц, что не очень ощутимо для общих затрат на аренду вычислительных мощностей. В продуктовой разработке принято в первую очередь уделять внимание задачам сформулированным из бизнес требований. Повышенное потребление процессорной мощности сервером базы данных вписывается в технический долг и покрывается небольшими затратами на покупку баланса кредитов.
В один прекрасный день, я написал в ежедневном саммари о том, что очень устал тушить периодически возникающие в разных местах проекта “пожары”. Если так будет продолжаться, то бизнес задачам будет уделять время выгоревший разработчик. В тот же день я подошел к главному менеджеру проектов, объяснил расклад и попросил время на расследование причин периодических пожаров и ремонт. Получив добро, я начал собирать данные из разных систем мониторинга.
Мы используем Newrelic для отслеживания общего времени отклика за сутки. Картина выглядела так:

Желтым на графике выделена часть времени ответа, которую занимает Postgres. Как видно, иногда время ответа доходило до 1000 ms и большую часть времени именно база данных размышляла над ответом. Значит надо смотреть что происходит с SQL запросами.
PMDSC – простая и понятная практика для
Play it!
Measure it!
Draw it!
Suppose it!
Check it!
Пожалуй, самая важная часть всей практики. Когда кто-то произносит фразу «Оптимизация SQL запросов» – это скорее вызывает приступ зевоты и скуку у абсолютного большинства людей. Когда ты произносишь «Детективное расследование и розыск опасных злодеев» – это сильнее вовлекает и настраивает тебя самого на нужный лад. Поэтому важно войти в игру. Мне понравилось играть в детектива. Я представлял себе что проблемы с базой данных либо опасные преступники, либо редкие болезни. А себя представлял в роли Шерлока Холмса, Лейтенанта Коломбо или Доктора Хауса. Выбирай героя на свой вкус и вперед!

Для анализа статистики запросов, я установил PgHero. Это очень удобный способ читать данные из расширения pg_stat_statements для Postgres. Заходим в /queries и смотрим на статистику всех запросов за последние сутки. Сортировка запросов по умолчанию по колонке Total Time – доля общего времени которое база данных обрабатывает запрос – ценный источник в поиске подозреваемых. Average Time – сколько в среднем запрос выполняется. Calls – сколько запросов было за выбранное время. PgHero считает медленными запросы, которые выполнялись более 100 раз за сутки и занимали в среднем более 20 миллисекунд. Список медленных запросов на первой странице, сразу после списка дублирующихся индексов.

Берём первый в списке и смотрим детали запроса, тут же можно посмотреть его explain analyze. Eсли planning time сильно меньше execution time, значит с этим запросом что-то не так и мы концентрируем внимание на этом подозреваемом.
В PgHero есть свой способ визуализации, но мне больше понравилось использовать explain.depesz.com копируя туда данные из explain analyze.
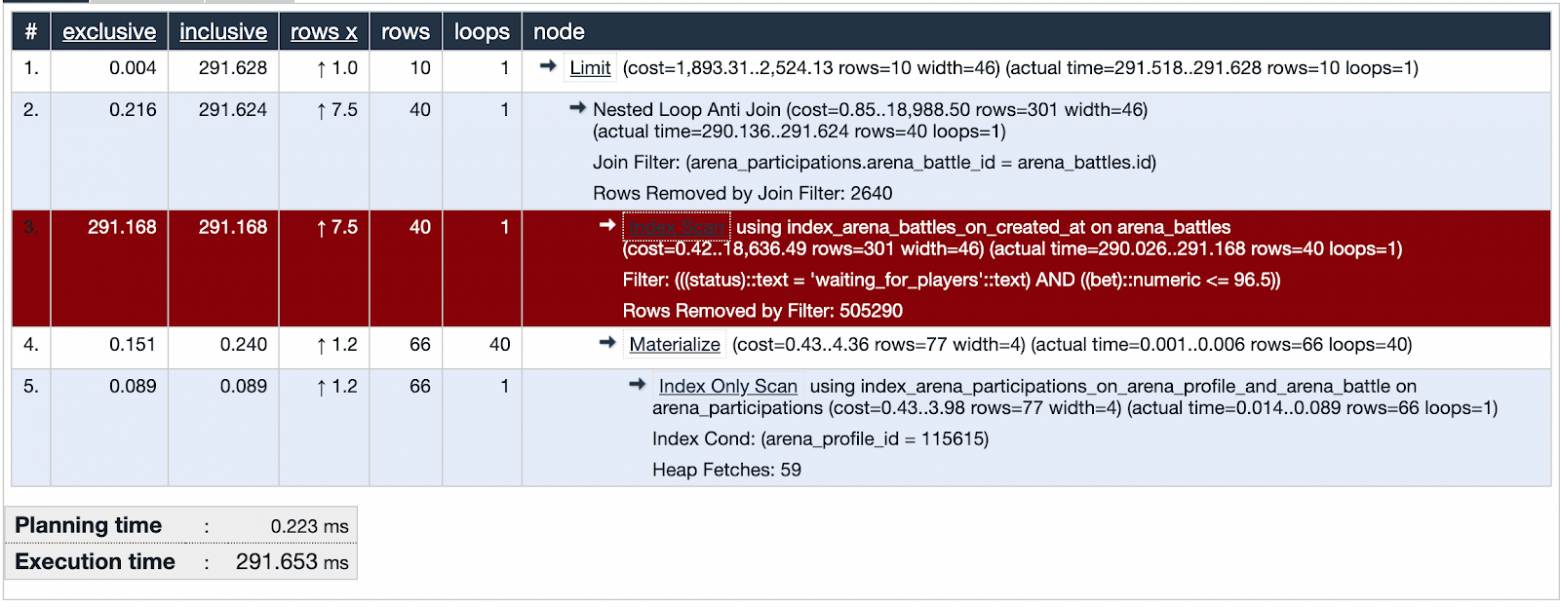
Один из подозреваемых запросов использует Index Scan. На визуализации видно что этот индекс не эффективен и является слабым местом – выделено красным. Отлично! Мы изучили следы подозреваемого и нашли важную улику! Правосудие неизбежно!
Нарисуем множество данных которые используются в проблемной части запроса. Будет полезно сравнить с тем какие данные покрывает индекс.
Немного контекста. Мы тестировали один из способов удержания аудитории в приложении – что-то вроде лотереи, в которой можно выиграть немного внутренней валюты. Делаешь ставку, загадываешь число от 0 до 100 и забираешь весь банк, если твое число оказалось ближе всех к тому что получил генератор случайных чисел. Мы назвали это “Арена”, а розыгрыши назвали “Битвами”.

В базе данных на момент расследования около пятисот тысяч записей о битвах. В проблемной части запроса мы ищем битвы в которых ставка не превышает баланс пользователя и статус битвы – жду игроков. Видим что пересечение множеств (выделено оранжевым) совсем маленькое количество записей.
Индекс, используемый в подозреваемой части запроса покрывает все созданные битвы по полю created_at. Запрос пробегает по 505330 записям из которых выбирает 40, а 505290 отсеивает. Выглядит очень расточительно.
Выдвигаем гипотезу. Что поможет базе данных найти сорок записей из пятисот тысяч? Попробуем сделать индекс который покрывает поле ставка, только для битв со статусом “жду игроков” – паршиал индекс.
Паршиал индекс – существует только для тех записей, которые подходят под условие: поле статус равно “жду_игроков” и индексирует поле ставка – ровно то что в условии запроса. Очень выгодно использовать именно этот индекс: он занимает всего 40 килобайт и не покрывает те битвы которые уже сыграны и не нужны нам для получения выборки. Для сравнения – индекс index_arena_battles_on_created_at, который использовался подозреваемым занимает около 40 Мб, а таблица с битвами около 70 Мб. Этот индекс можно смело удалить, если его не используют другие запросы.
Выкатываем миграцию с новым индексом в продакшен и наблюдаем за тем как изменился отклик эндпоинта с битвами.

На графике видно во сколько мы выкатили миграцию. Вечером 6 декабря время отклика уменьшилось примерно в 10 раз с ~500 ms до ~50ms. Подозреваемый в суде получил статус заключенного и теперь сидит в тюрьме. Отлично!
Спустя несколько дней мы поняли что рано радовались. Похоже, заключенный нашел сообщников, разработал и осуществил план побега.
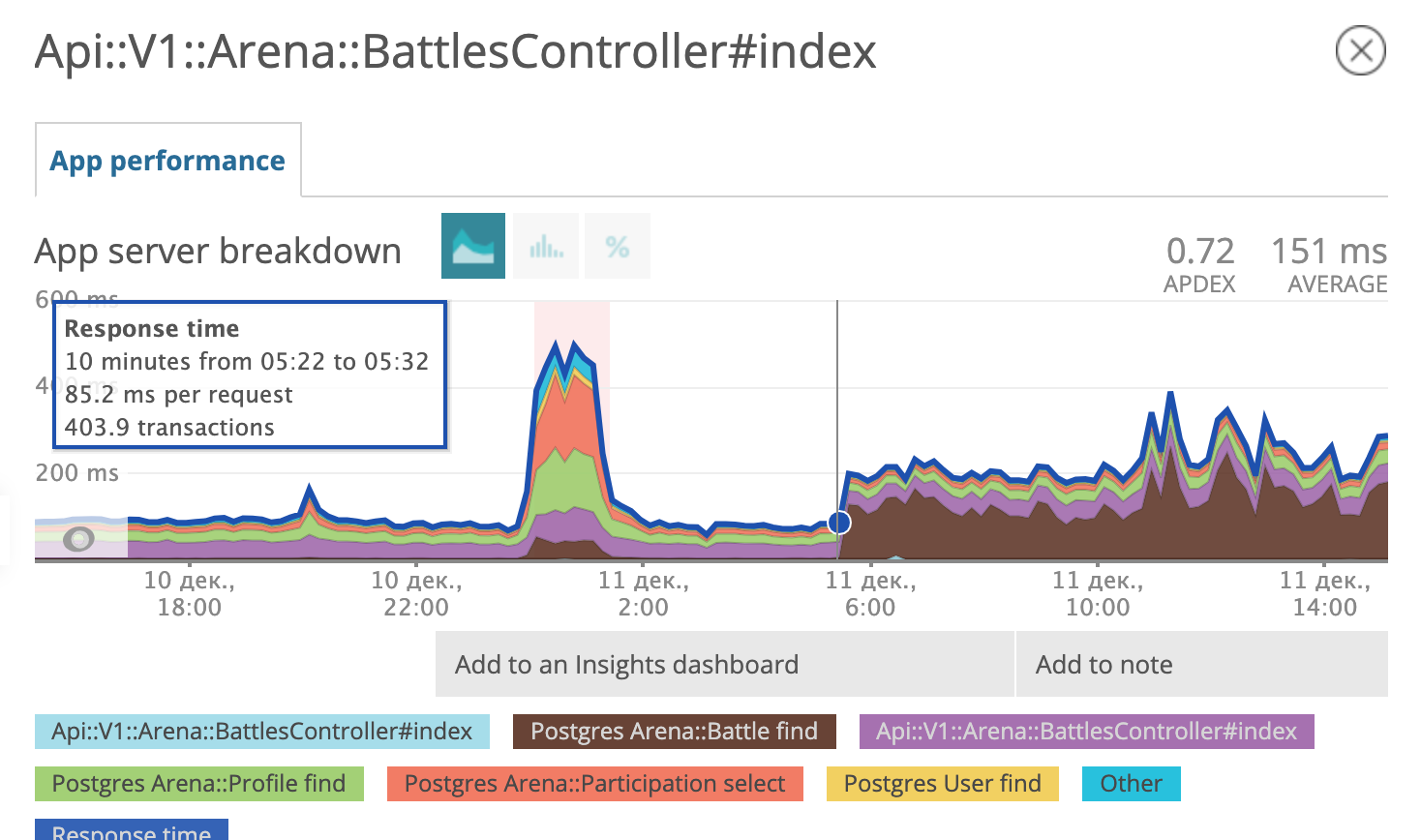
Утром 11 декабря планировщик запросов postgres решил что использовать свежий паршиал индекс, ему больше не выгодно и стал снова использовать старый.
Мы снова на этапе Suppose it! Собираем дифференциальный диагноз, в духе доктора Хауса:
Мы проверили все три гипотезы. Последняя привела нас на след сообщника.
Давай вместе пройдемся по этому SQL. Выбираем все поля битвы из таблицы битв статус которых равен “жду игроков” и ставка меньше или равна некоему числу. Пока все понятно. Следующее слагаемое условия выглядит жутко.
Мы ищем не существующий результат подзапроса. Достань первое поле из таблицы участий в битвах, где идентификатор битвы совпадает и профиль участника принадлежит нашему игроку. Попробую нарисовать множество описанное в подзапросе.
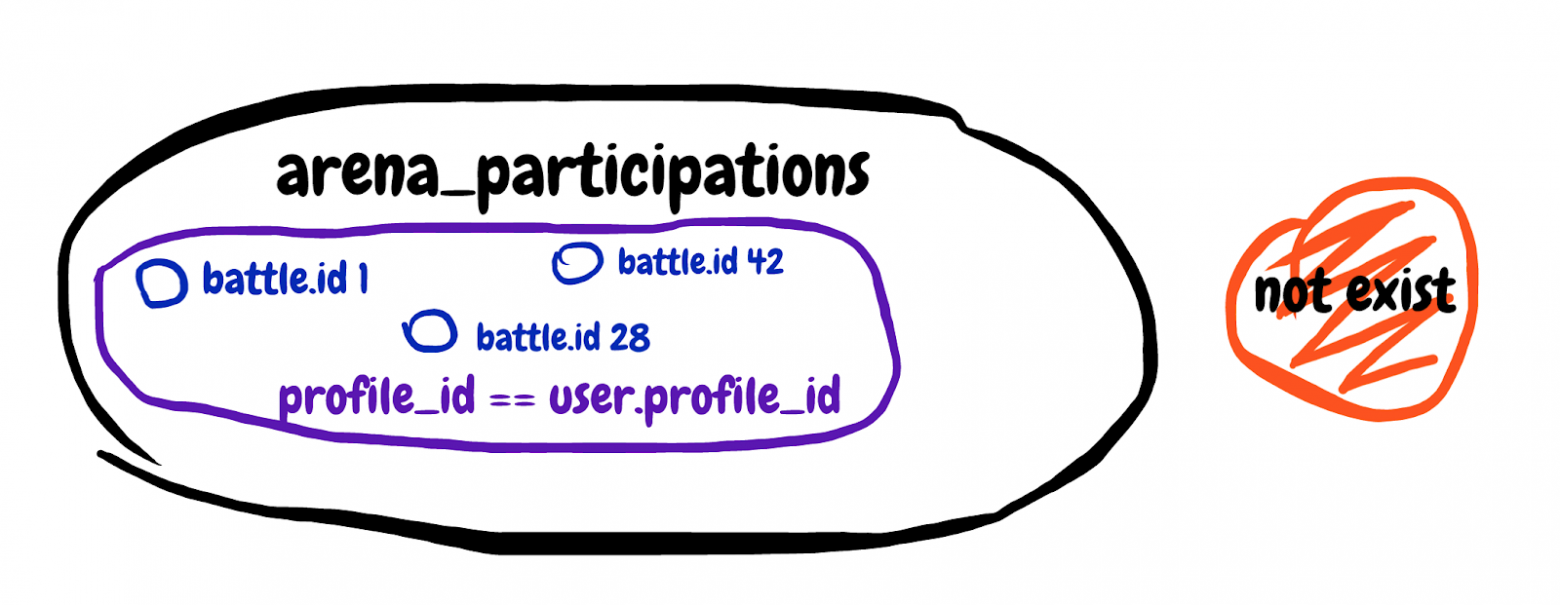
Сложно осмыслить, но в итоге этим подзапросом мы пробовали исключить те битвы в которых игрок уже участвует. Смотрим общий explain запроса и видим Planning time: 0.180 ms, Execution time: 12.119 ms. Мы нашли сообщника!
Настало время моей любимой шпаргалки, которая гуляет по интернетам с 2008 года. Вот она:

Да! Как только в запросе встречается что-то, что должно исключить какое-то количество записей на основе данных из другой таблицы, в памяти должен всплыть этот мем с бородой и кудрями.
На самом деле вот что нам нужно:

Сохрани себе эту картинку, а еще лучше распечатай и повесь в нескольких местах в офисе.
Переписываем подзапрос на LEFT JOIN WHERE B.key IS NULL, получаем:
Исправленный запрос бежит сразу по двум таблицам. Мы присоединили “слева” таблицу с записями участий в битвах пользователя и добавили условие что идентификатор участия не существует. Смотрим explain analyze полученного запроса: Planning time: 0.185 ms, Execution time: 0.337 ms. Отлично! Теперь планировщик запросов не будет сомневаться что ему стоит использовать паршиал индекс, а будет использовать самый быстрый вариант. Сбежавший заключенный и его сообщник приговорены на пожизненное заключение в заведении строгого режима. Сбежать им будет сложнее.
Итог кратко.
Полагаю, практически каждый проект, использующий Ruby on Rails и Postgres в качестве основного вооружения на бэкенде находится в перманентной борьбе между скоростью разработки, читаемостью/поддерживаемостью кода и скоростью работы проекта в продакшене. Я расскажу о своем опыте балансирования между этими тремя китами в кейсе, где на входе страдали читаемость и скорость работы, а на выходе получилось сделать то, что до меня безуспешно пытались сделать несколько талантливых инженеров.
Полностью вся история займёт несколько частей. Это первая, где я расскажу о том что такое PMDSC для оптимизации SQL-запросов, поделюсь полезными инструментами измерения эффективности запросов в postgres и напомню об одной полезной старой шпаргалке, которая до сих пор актуальна.
Сейчас, спустя какое-то время, “задним умом” я понимаю, что на входе в этот кейс совершенно не ожидал что у меня всё получится. Поэтому этот пост будет полезен скорее для смелых и не самых опытных разработчиков, чем для супер-сеньоров видавших рельсы с голым SQL.
Вводные данные
Мы в Appbooster занимаемся продвижением мобильных приложений. Чтобы легко выдвигать и проверять гипотезы мы разрабатываем несколько своих приложений. Бэкенд большинства из них это Rails API и Postgresql.
Герой этой публикации разрабатывается с конца 2013 года – тогда только-только вышел rails 4.1.0.beta1. С тех пор проект вырос в полноценно нагруженное веб-приложение, которое крутится на нескольких серверах в Amazon EC2 c отдельным инстансом базы данных в Amazon RDS (db.t3.xlarge с 4 vCPU и 16 GB RAM). Пиковые нагрузки доходят до 25k RPM, средняя нагрузка днём 8-10k RPM.
С инстанса базы данных, точнее с её кредитного баланса и началась эта история.
Как работает инстанс Postgres типа “t” в Амазон RDS: если ваша база данных работает со средним потреблением процессорного времени ниже определенного значения, то у вас на счету накапливаются кредиты, которые инстанс может тратить на потребление процессора в часы высокой нагрузки – это позволяет не переплачивать за серверные мощности и справляться с высокой нагрузкой. Более подробно о том за что и сколько платят, используя AWS можно прочитать в статье нашего CTO.
Баланс кредитов в определенный момент исчерпался. Некоторое время этому не придавалось большого значения, потому как баланс кредитов можно пополнять за счет денег – нам это стоило около $20 в месяц, что не очень ощутимо для общих затрат на аренду вычислительных мощностей. В продуктовой разработке принято в первую очередь уделять внимание задачам сформулированным из бизнес требований. Повышенное потребление процессорной мощности сервером базы данных вписывается в технический долг и покрывается небольшими затратами на покупку баланса кредитов.
В один прекрасный день, я написал в ежедневном саммари о том, что очень устал тушить периодически возникающие в разных местах проекта “пожары”. Если так будет продолжаться, то бизнес задачам будет уделять время выгоревший разработчик. В тот же день я подошел к главному менеджеру проектов, объяснил расклад и попросил время на расследование причин периодических пожаров и ремонт. Получив добро, я начал собирать данные из разных систем мониторинга.
Мы используем Newrelic для отслеживания общего времени отклика за сутки. Картина выглядела так:
Желтым на графике выделена часть времени ответа, которую занимает Postgres. Как видно, иногда время ответа доходило до 1000 ms и большую часть времени именно база данных размышляла над ответом. Значит надо смотреть что происходит с SQL запросами.
PMDSC – простая и понятная практика для любой скучной работы оптимизации SQL запросов
Play it!
Measure it!
Draw it!
Suppose it!
Check it!
Play it!
Пожалуй, самая важная часть всей практики. Когда кто-то произносит фразу «Оптимизация SQL запросов» – это скорее вызывает приступ зевоты и скуку у абсолютного большинства людей. Когда ты произносишь «Детективное расследование и розыск опасных злодеев» – это сильнее вовлекает и настраивает тебя самого на нужный лад. Поэтому важно войти в игру. Мне понравилось играть в детектива. Я представлял себе что проблемы с базой данных либо опасные преступники, либо редкие болезни. А себя представлял в роли Шерлока Холмса, Лейтенанта Коломбо или Доктора Хауса. Выбирай героя на свой вкус и вперед!
Measure It!
Для анализа статистики запросов, я установил PgHero. Это очень удобный способ читать данные из расширения pg_stat_statements для Postgres. Заходим в /queries и смотрим на статистику всех запросов за последние сутки. Сортировка запросов по умолчанию по колонке Total Time – доля общего времени которое база данных обрабатывает запрос – ценный источник в поиске подозреваемых. Average Time – сколько в среднем запрос выполняется. Calls – сколько запросов было за выбранное время. PgHero считает медленными запросы, которые выполнялись более 100 раз за сутки и занимали в среднем более 20 миллисекунд. Список медленных запросов на первой странице, сразу после списка дублирующихся индексов.
Берём первый в списке и смотрим детали запроса, тут же можно посмотреть его explain analyze. Eсли planning time сильно меньше execution time, значит с этим запросом что-то не так и мы концентрируем внимание на этом подозреваемом.
В PgHero есть свой способ визуализации, но мне больше понравилось использовать explain.depesz.com копируя туда данные из explain analyze.
Один из подозреваемых запросов использует Index Scan. На визуализации видно что этот индекс не эффективен и является слабым местом – выделено красным. Отлично! Мы изучили следы подозреваемого и нашли важную улику! Правосудие неизбежно!
Draw it!
Нарисуем множество данных которые используются в проблемной части запроса. Будет полезно сравнить с тем какие данные покрывает индекс.
Немного контекста. Мы тестировали один из способов удержания аудитории в приложении – что-то вроде лотереи, в которой можно выиграть немного внутренней валюты. Делаешь ставку, загадываешь число от 0 до 100 и забираешь весь банк, если твое число оказалось ближе всех к тому что получил генератор случайных чисел. Мы назвали это “Арена”, а розыгрыши назвали “Битвами”.
В базе данных на момент расследования около пятисот тысяч записей о битвах. В проблемной части запроса мы ищем битвы в которых ставка не превышает баланс пользователя и статус битвы – жду игроков. Видим что пересечение множеств (выделено оранжевым) совсем маленькое количество записей.
Индекс, используемый в подозреваемой части запроса покрывает все созданные битвы по полю created_at. Запрос пробегает по 505330 записям из которых выбирает 40, а 505290 отсеивает. Выглядит очень расточительно.
Suppose it!
Выдвигаем гипотезу. Что поможет базе данных найти сорок записей из пятисот тысяч? Попробуем сделать индекс который покрывает поле ставка, только для битв со статусом “жду игроков” – паршиал индекс.
add_index :arena_battles, :bet, where: "status = 'waiting_for_players'", name: "index_arena_battles_on_bet_partial_status"
Паршиал индекс – существует только для тех записей, которые подходят под условие: поле статус равно “жду_игроков” и индексирует поле ставка – ровно то что в условии запроса. Очень выгодно использовать именно этот индекс: он занимает всего 40 килобайт и не покрывает те битвы которые уже сыграны и не нужны нам для получения выборки. Для сравнения – индекс index_arena_battles_on_created_at, который использовался подозреваемым занимает около 40 Мб, а таблица с битвами около 70 Мб. Этот индекс можно смело удалить, если его не используют другие запросы.
Check it!
Выкатываем миграцию с новым индексом в продакшен и наблюдаем за тем как изменился отклик эндпоинта с битвами.
На графике видно во сколько мы выкатили миграцию. Вечером 6 декабря время отклика уменьшилось примерно в 10 раз с ~500 ms до ~50ms. Подозреваемый в суде получил статус заключенного и теперь сидит в тюрьме. Отлично!
Prison Break
Спустя несколько дней мы поняли что рано радовались. Похоже, заключенный нашел сообщников, разработал и осуществил план побега.
Утром 11 декабря планировщик запросов postgres решил что использовать свежий паршиал индекс, ему больше не выгодно и стал снова использовать старый.
Мы снова на этапе Suppose it! Собираем дифференциальный диагноз, в духе доктора Хауса:
- Возможно, надо оптимизировать настройки postgres;
- может быть, минорно обновить postgres до новой версии (9.6.11 –> 9.6.15);
- а может быть, снова внимательно изучить какой SQL-запрос формирует Рельса?
Мы проверили все три гипотезы. Последняя привела нас на след сообщника.
SELECT "arena_battles".* FROM "arena_battles" WHERE "arena_battles"."status" = 'waiting_for_players' AND (arena_battles.bet <= 98.13) AND (NOT EXISTS ( SELECT 1 FROM arena_participations WHERE arena_battle_id = arena_battles.id AND (arena_profile_id = 46809) )) ORDER BY "arena_battles"."created_at" ASC LIMIT 10 OFFSET 0
Давай вместе пройдемся по этому SQL. Выбираем все поля битвы из таблицы битв статус которых равен “жду игроков” и ставка меньше или равна некоему числу. Пока все понятно. Следующее слагаемое условия выглядит жутко.
NOT EXISTS ( SELECT 1 FROM arena_participations WHERE arena_battle_id = arena_battles.id AND (arena_profile_id = 46809) )
Мы ищем не существующий результат подзапроса. Достань первое поле из таблицы участий в битвах, где идентификатор битвы совпадает и профиль участника принадлежит нашему игроку. Попробую нарисовать множество описанное в подзапросе.
Сложно осмыслить, но в итоге этим подзапросом мы пробовали исключить те битвы в которых игрок уже участвует. Смотрим общий explain запроса и видим Planning time: 0.180 ms, Execution time: 12.119 ms. Мы нашли сообщника!
Настало время моей любимой шпаргалки, которая гуляет по интернетам с 2008 года. Вот она:
Да! Как только в запросе встречается что-то, что должно исключить какое-то количество записей на основе данных из другой таблицы, в памяти должен всплыть этот мем с бородой и кудрями.
На самом деле вот что нам нужно:
Сохрани себе эту картинку, а еще лучше распечатай и повесь в нескольких местах в офисе.
Переписываем подзапрос на LEFT JOIN WHERE B.key IS NULL, получаем:
SELECT "arena_battles".* FROM "arena_battles" LEFT JOIN arena_participations ON arena_participations.arena_battle_id = arena_battles.id AND (arena_participations.arena_profile_id = 46809) WHERE "arena_battles"."status" = 'waiting_for_players' AND (arena_battles.bet <= 98.13) AND (arena_participations.id IS NULL) ORDER BY "arena_battles"."created_at" ASC LIMIT 10 OFFSET 0
Исправленный запрос бежит сразу по двум таблицам. Мы присоединили “слева” таблицу с записями участий в битвах пользователя и добавили условие что идентификатор участия не существует. Смотрим explain analyze полученного запроса: Planning time: 0.185 ms, Execution time: 0.337 ms. Отлично! Теперь планировщик запросов не будет сомневаться что ему стоит использовать паршиал индекс, а будет использовать самый быстрый вариант. Сбежавший заключенный и его сообщник приговорены на пожизненное заключение в заведении строгого режима. Сбежать им будет сложнее.
Итог кратко.
- Используй Newrelic или другой подобный сервис чтобы найти зацепки. Мы поняли что проблема именно в запросах к базе данных именно так.
- Используй практику PMDSC – это работает и в любом случае хорошо вовлекает.
- Используй PgHero чтобы найти подозреваемых и изучать улики в статистике SQL-запросов.
- Используй explain.depesz.com – там удобно читать explain analyze запросов.
- Пробуй рисовать множества данных, когда не понимаешь что именно делает запрос.
- Вспоминай о суровом парне с кудрями в разных местах головы, когда видишь подзапрос который ищет то чего нет в другой таблице.
- Играй в детектива, возможно тебе даже выдадут значок.

