Расшифровка доклада 2020 года Брюса Момжиана "Unlocking the Postgres Lock Manager".

(Примечание: Все SQL запросы из слайдов вы можете получить по этой ссылке: http://momjian.us/main/writings/pgsql/locking.sql)
Привет! Замечательно снова быть здесь в России. Я прошу прощение, что я не смог приехать в прошлом году, но в этом году у Ивана и у меня большие планы. Я, надеюсь, что буду здесь гораздо чаще. Я обожаю приезжать в Россию. Я буду посещать Тюмень, Тверь. Я очень рад, что мне удастся побывать в этих городах.
Меня зовут Брюс Момжиан. Я работаю в EnterpriseDB и работаю с Postgres более 23 лет. Я живу в Филадельфии, в США. Путешествую примерно 90 дней в году. И посещаю порядка 40 конференций. Мой веб сайт, который содержит слайды, которые я вам буду сейчас показывать. Поэтому после конференции вы можете с моего личного сайта их скачать. Там также содержатся около 30 презентаций. А также есть видео и большое количество записей в блоге, более 500. Это достаточно содержательный ресурс. И если вам интересен этот материал, то я вас приглашаю им воспользоваться.
Я раньше был преподавателем, профессором до того, как начал работать с Postgres. И я очень рад, что мне удастся сейчас рассказать вам то, что я собираюсь вам рассказать. Это одна из самых интересных моих презентаций. И эта презентация содержит 110 слайдов. Говорить мы начнем с простых вещей, а к концу доклад станет все сложнее и сложнее, и станет достаточно сложным.
Это довольно неприятная беседа. Блокировка – это не самый популярный предмет. Мы хотим, чтобы это куда-то исчезло. Это как ходить к стоматологу.

- Блокировка является проблемой для большого количества людей, которые работают в базах данных и у которых работают одновременно несколько процессов. Им необходима блокировка. Т. е. сегодня я вам дам базовые знания по блокировке.
- Идентификаторы транзакций. Это довольно скучная часть презентации, но их необходимо понять.
- Далее мы поговорим о типах блокировки. Это достаточно механическая часть.
- И далее мы приведем некоторые примеры блокировок. И это будет достаточно сложно для восприятия.

Давайте поговорим о блокировках.

Терминология у нас достаточно сложная. Сколько из вас знают, откуда этот отрывок? Два человека. Это из игры, которая называется «Колоссальное приключение в пещере». Это было текстовая компьютерная игра в 80-ых годах, мне кажется. Там надо было зайти в пещеру, в лабиринт и текст менялся, но при этом содержание было примерно одинаковое каждый раз. Вот так я помню эту игру.

И здесь мы видим наименование блокировок, которые пришли к нам из Oracle. Мы используем их.

Здесь мы видим термины, которые меня смущают. Например, SHARE UPDATE ECXLUSIVE. Далее SHARE RAW ECXLUSIVE. Честно говоря, эти названия не очень понятны. Мы постараемся их более детально рассмотреть. Некоторые содержать слово «share», которое значит – отделиться. Некоторые содержат слово «exclusive» — эксклюзивный. В некоторых содержатся оба эти слова. Я бы хотел начать с того, как эти блокировки работают.

И также очень важно слово «доступ» — access. И слова «row» — строка. Т. е. распределение доступа, распределение строк.

Еще одна проблема, которую необходимо понять в Postgres, я, к сожалению, не смогу рассказать об ней в своем выступлении, это MVCC. У меня есть отдельная презентация по этой теме на моем веб-сайте. И если вы думаете, что эта презентация сложная, то MVCC – это, наверное, моя самая сложная. И если вам интересно, то можете посмотреть ее на сайте. Посмотреть можете видео.

Еще один момент, который нам необходимо понять – это идентификаторы транзакции. Многие транзакции не могут работать без уникальных идентификаторов. И здесь у нас идет пояснение того, что такое транзакция. В Postgres есть две системы нумерации транзакций. Я знаю, это не очень красивое решение.

Также имейте в виду, что слайды будут достаточно сложные для восприятия, поэтому на то, что выделено красным цветом, именно на это надо обратить внимание.
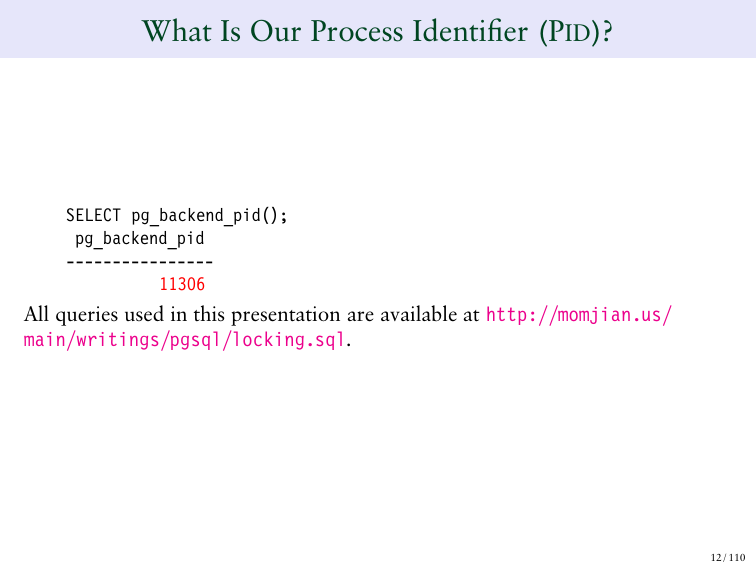
http://momjian.us/main/writings/pgsql/locking.sql
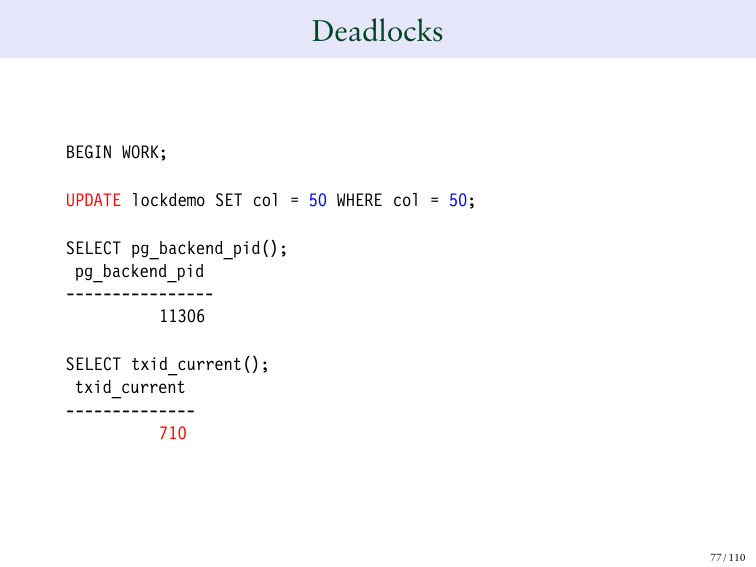
Смотрим. Красным цветом выделен номер транзакции. Здесь показана функция SELECT pg_back. Она возвращает мою транзакцию и ID этой транзакции.
Еще один момент, если вам нравится эта презентация и вы хотите запустить ее в своей базе данных, то вы можете пройти по этой ссылке, выделенной розовым цветом, и скачать SQL для этой презентации. И можете просто запустить ее в вашем PSQL и вся презентация окажется у вас на экране незамедлительно. Она не будет содержать цветов, но по крайней мере мы сможете ее увидеть.

В данном случае мы видим ID транзакции. Это номер, который мы ей присвоили. И есть еще один тип ID транзакции в Postgres, который называется виртуальный ID транзакция
И мы должны понять это. Это очень важно, иначе мы не сможем понять блокировку в Postgres.
Виртуальный ID транзакция – это ID транзакции, которая не содержит постоянных значений. Например, если я запускаю команду SELECT, то я, скорее всего, не буду менять базу данных, я ничего не буду блокировать. Поэтому, когда мы запускаем простой SELECT, мы не даем этой транзакции постоянный ID. Мы там даем ей только виртуальный ID.
И это повышает производительность Postgres, улучшает возможности для очистки, поэтому виртуальный ID транзакции состоит из двух чисел. Первое число перед слэшем – это ID бэкенда. А справа мы видим просто счетчик.

Поэтому если запускаю запрос, то он говорит, что ID бэкенд – 2.

А если я запускаю серию таких транзакций, то мы видим, что счетчик каждый раз увеличивается, когда я запускаю запрос. Например, когда я запускаю запрос 2/10, 2/11, 2/12 и т. д.

Имейте в виду, что здесь есть две колонки. Слева мы видим виртуальный ID транзакции – 2/12. А справа у нас постоянный ID транзакции. И это поле пустое. И эта транзакция не модифицирует базу данных. Поэтому я не присваиваю ей постоянный ID транзакции.

Как только я запускаю команду анализировать ( (ANALYZE)), то тот же самый запрос выдает мне постоянный ID транзакции. Посмотрите, как у нас это изменилось. Раньше у меня не было этого ID, теперь появился.

Итак, здесь еще один запрос, еще одна транзакция. Виртуальный номер транзакции – 2/13. И если я попрошу постоянный ID транзакции, то, когда я запущу запрос, я его получу.

Итак, еще раз. У нас есть виртуальный ID транзакции и постоянный ID транзакции. Просто поймите этот момент, чтобы понять поведение Postgres.

Мы переходим к третьему разделу. Здесь мы просто пройдем через различные типы блокировок в Postgres. Это не очень интересно. Последний раздел будет гораздо интересней. Но мы должны рассмотреть базовые вещи, потому иначе мы не поймем того, что будет дальше.
Мы пройдем через этот раздел, мы посмотрим на каждый тип блокировок. И я вам покажу примеры, как они устанавливаются, как они работают, покажу вам некоторые запросы, которые можно использовать, чтобы посмотреть, как работает блокировка в Postgres.

Чтобы создать запрос и посмотреть, что происходит в Postgres, нам нужно выпустить запрос в system view. В данном случае красным цветом у нас выделен pg_lock. Pg_lock – это системная таблица, которая говорит нам, какие блокировки сейчас используются в Postgres.
Тем не менее мне очень сложно показать вам pg_lock сам по себе, потому что это довольно сложно. Поэтому я создал view, который показывает pg_locks. И он также выполняет для меня некоторую работу, которая позволяет мне лучше понять. Т. е. он исключает мои блокировки, мою собственную сессию и т. д. Это просто стандартный SQL и он позволяет лучше вам показать, что происходит.

Еще одна проблема в том, что этот view очень широкий, поэтому мне приходится создать второй – lockview2.
 И он показывает мне еще колонки из таблицы. И еще один, который показывает мне остальные колонки. Это достаточно сложно, поэтому я постарался представить это как можно проще.
И он показывает мне еще колонки из таблицы. И еще один, который показывает мне остальные колонки. Это достаточно сложно, поэтому я постарался представить это как можно проще.

Итак, мы создали таблицу, которая называется Lockdemo. И мы создали там одну строку. Это наша образцовая таблица. И мы будем создавать разделы, чтобы просто показать вам примеры блокировок.

Итак, одна строка, одна колонка. Первый тип блокировки называется ACCESS SHARE. Это наименее запрещающая блокировка. Это означает, что она практически не конфликтует с остальными блокировками.
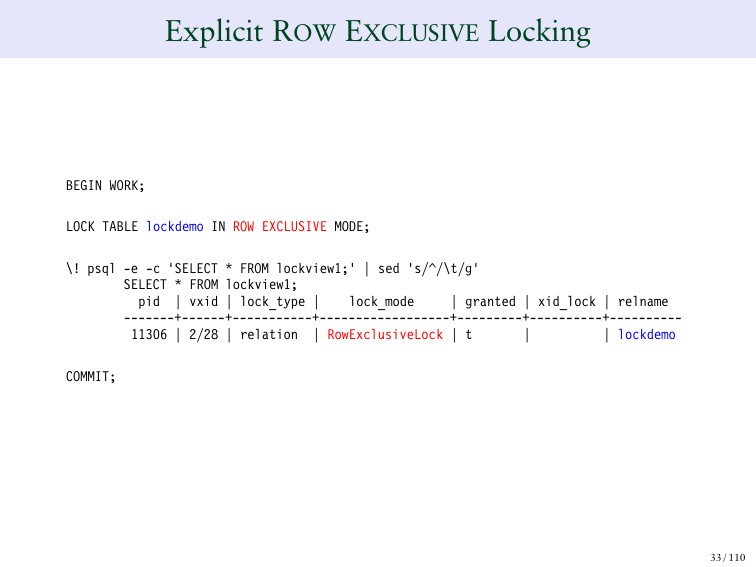
И если мы хотим эксплицитно определить блокировку, мы запускаем команду «lock table». И она явно заблокирует, т. е. в режиме ACCESS SHARE мы запускаем lock table. И если я запущу PSQL в фоновом режиме, то я запускаю таким образом вторую сессию из моей первой сессии. Т. е. что я сделаю здесь? Я перехожу к другой сессии и говорю ей «покажи мне lockview для данного запроса». И здесь у меня AccessShareLock в этой таблице. Это как раз то, что я запрашивал. И он говорит, что блокировка была присвоена. Очень просто.

Далее, если мы смотрим во вторую колонку, то там ничего нет. Они пустые.

И если я запускаю команду «SELECT», то это имплицитный (явный) способ запросить AccessShareLock. Поэтому я выпускаю свою таблицу и запускаю запрос, и запрос возвращает несколько строк. И в одной из строк мы видим AccessShareLock. Таким образом SELECT вызывает AccessShareLock в таблице. И он не конфликтует практически ни с чем, потому что это блокировка низкого уровня.
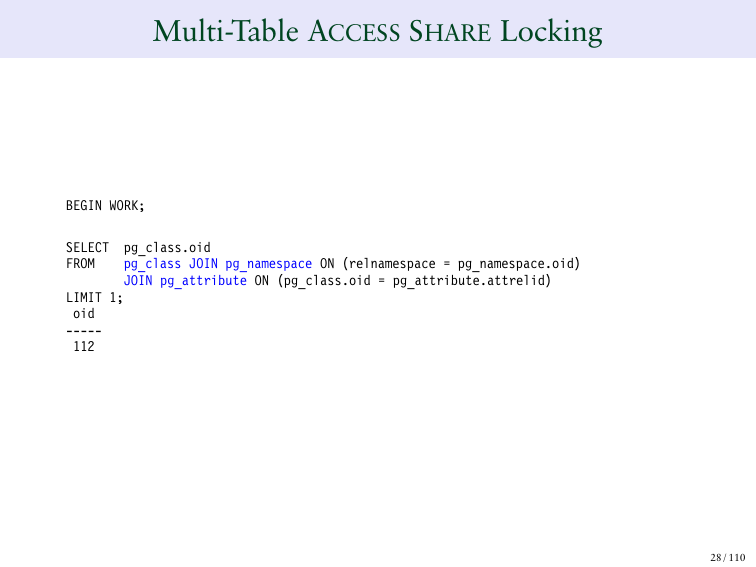
Что если я запущу SELECT и у меня будет три разных таблиц? Ранее я запускал только одну таблицу, теперь я запускаю три: pg_class, pg_namespace и pg_attribute.
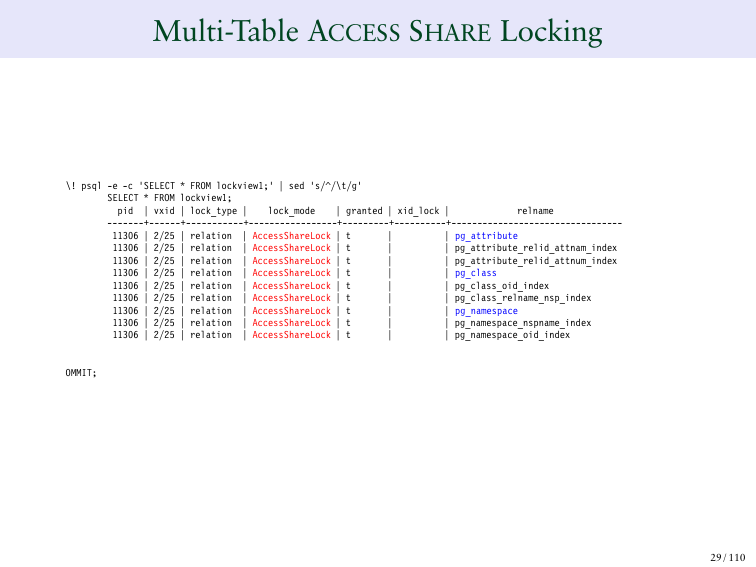
И теперь, когда я смотрю на запрос, я вижу 9 AccessShareLocks в трех таблицах. Почему? Синим цветом выделено три таблицы: pg_attribute, pg_class, pg_namespace. Но вы также можете видеть, что все индексы, которые определены через эти таблицы, также имеют AccessShareLock.
И это блокировка, которая практически не конфликтует с другими. А все, что она делает, это просто не дает нам сбросить таблицу, пока мы ее выбираем. Это имеет смысл. Т. е. если мы выбираем таблицу, она в этот момент исчезает, то это неправильно, поэтому AccessShare – это блокировка низкого уровня, которая говорит нам "не удаляйте эту таблицу, пока я работаю". По сути, это все, что она делает.

ROW SHARE – это блокировка немного отличается.

Возьмем пример. SELECT ROW SHARE способ блокировки каждой строки по отдельности. Таким образом никто не может удалить их или изменить их, пока мы их смотрим.
 Итак, то, что делает SHARE LOCK? Мы видим, что ID транзакции 681 для SELECT’а. И это интересно. Что у нас здесь произошло? Первый раз мы видим номер в поле «Lock». Мы берем ID транзакции, и он говорит, что блокирует ее в эксклюзивном режиме. Все, что он делает, он говорит, что у меня есть строка, которая технически заблокирована где-то в таблице. Но не говорит, где конкретно. Чуть позже мы более подробно это рассмотрим.
Итак, то, что делает SHARE LOCK? Мы видим, что ID транзакции 681 для SELECT’а. И это интересно. Что у нас здесь произошло? Первый раз мы видим номер в поле «Lock». Мы берем ID транзакции, и он говорит, что блокирует ее в эксклюзивном режиме. Все, что он делает, он говорит, что у меня есть строка, которая технически заблокирована где-то в таблице. Но не говорит, где конкретно. Чуть позже мы более подробно это рассмотрим.
Здесь мы говорим, что блокировка используется нами.
Итак, эксклюзивная блокировка эксплицитно(явно) говорит, что она эксклюзивная. И также если вы удаляете строку в этой таблице, то это и произойдет, как вы можете видеть.

SHARE EXCLUSIVE – это более длинная блокировка.

Это (ANALYZE) команда анализатора, которая будет использоваться.
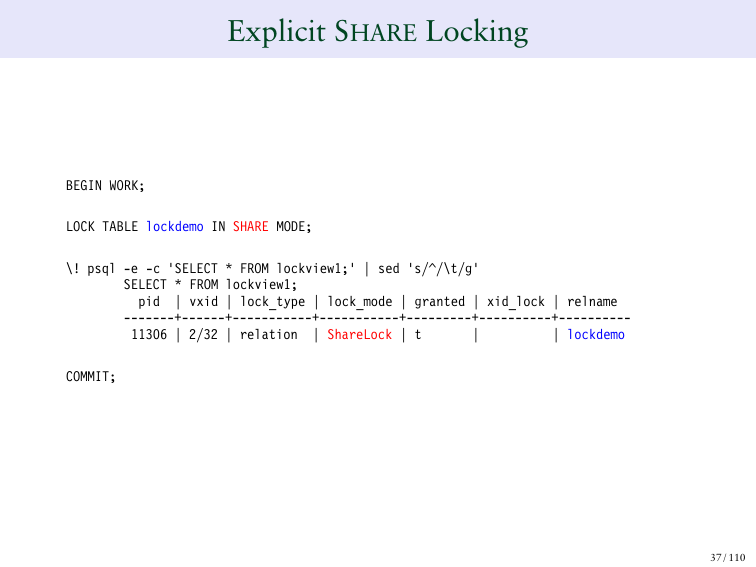
SHARE LOCK – вы можете эксплицитно заблокировать в режиме share.
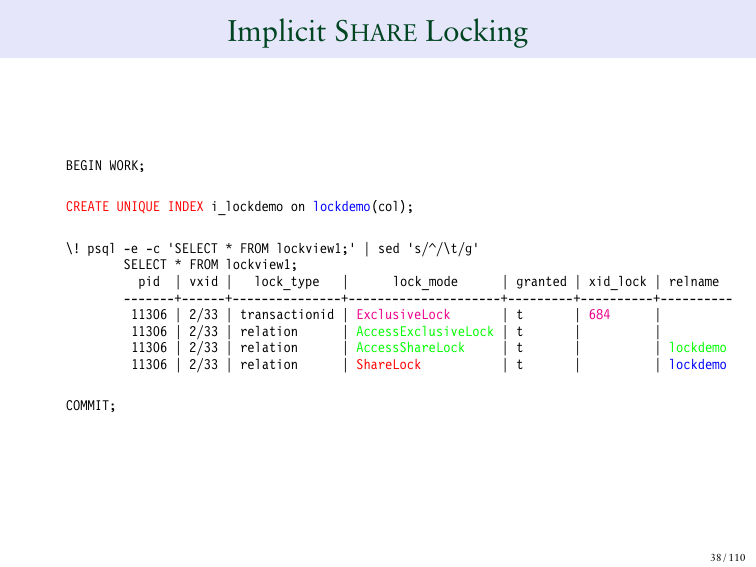
Вы можете также создать уникальный индекс. И там вы можете увидеть SHARE LOCK, который является их частью. И он блокирует таблицу и устанавливает на нее блокировку SHARE LOCK.
По умолчанию SHARE LOCK на таблице означает, что другие люди могут читать таблицу, но никто не может ее модифицировать. И именно это происходит, когда вы создаете уникальный индекс.
Если я создаю уникальный concurrently индекс, то у меня будет другой тип блокировки, потому что, как вы помните, использование concurrently индексов снижает требование к блокировке. И если я использую нормальную блокировку, нормальный индекс, то я таким образом предотвращу запись в индекс таблицы во время его создания. Если я использую concurrently индекс, то мне надо использовать другой тип блокировки.
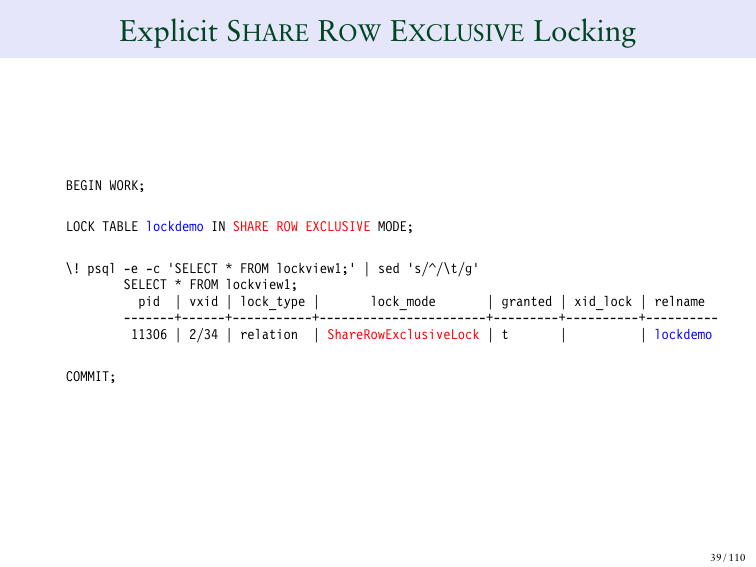
SHARE ROW EXCLUSIVE – опять ее можно задать эксплицитно (явно).

Или можем создать правило, т. е. взять какой-то определенный случай, при котором она будет использоваться.
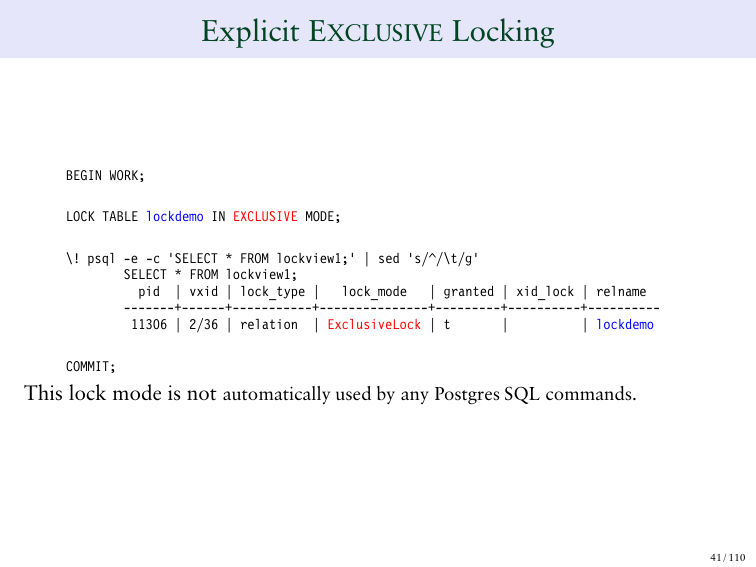
EXCLUSIVE блокировка означает, что никто другой менять таблицу не сможет.
Здесь мы видим различные типы блокировок.
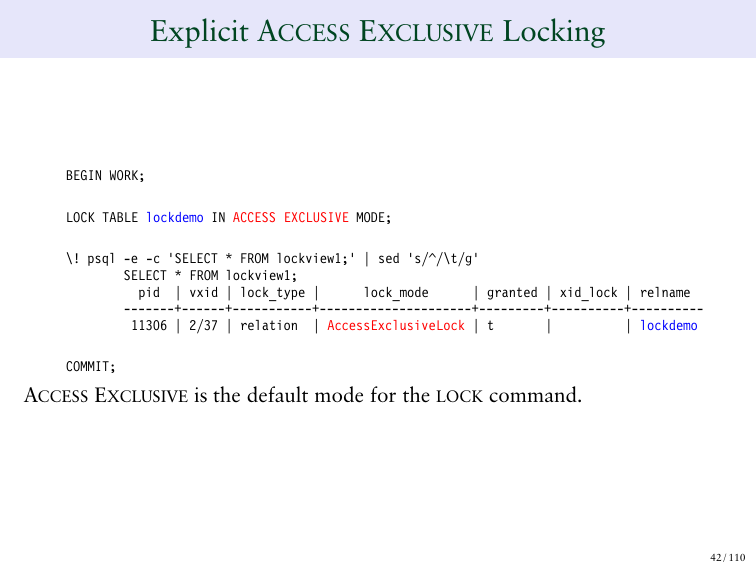
ACCESS EXCLUSIVE, например, это команда блокировки. Например, если вы делаете CLUSTER table, то это будет означать, что никто не сможет записывать туда. И она блокирует не только саму таблицу, но и индексы также.

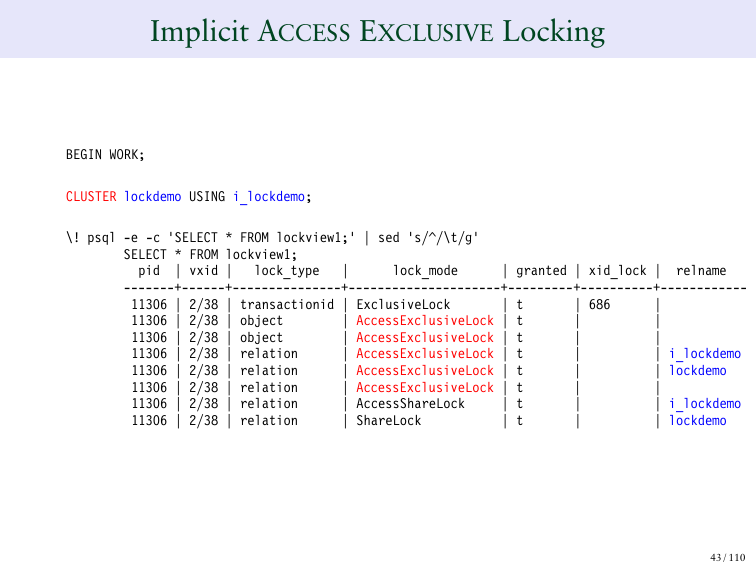
Это вторая страница блокировки ACCESS EXCLUSIVE, где мы видим конкретно, что она блокирует в таблице. Она блокирует отдельные строки таблицы, что достаточно интересно.
Это вся базовая информация, которую я хотел дать. Мы говорили о блокировках, об ID транзакций, говорили о виртуальных ID транзакций, о постоянных ID транзакций.

И теперь мы пройдемся по примерам блокировок. Это самая интересная часть. Мы посмотрим очень интересные случаи. И моя задача в этой презентации – дать вам лучшее представление о том, что Postgres на самом деле делает, когда он пытается блокировать те или иные вещи. Мне кажется, что он очень хорошо умеет блокировать отдельные части.
Давайте рассмотрим определенные примеры.

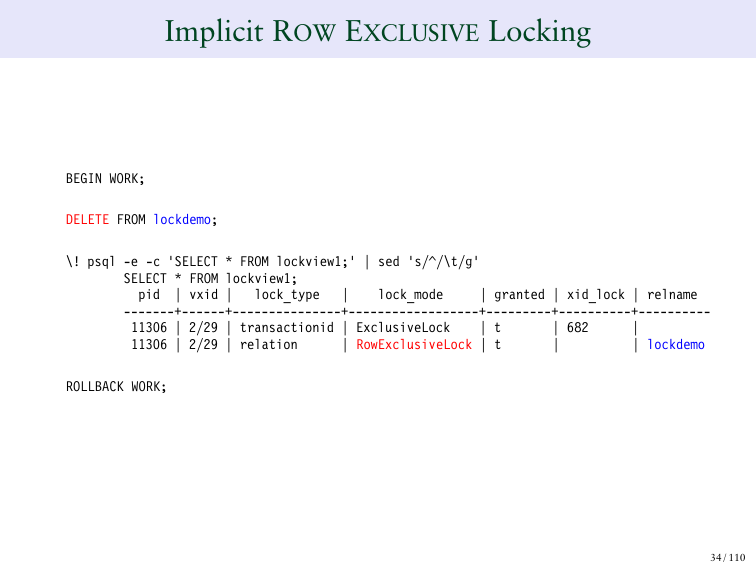
Мы начнем с таблиц и с одной строки в таблице. Когда я вставляю что-то, у меня отображается ExclusiveLock, ID транзакции и ExclusiveLock на таблице.

А что будет, если я вставлю еще два ряда? И теперь в нашей таблице три ряда. И я вставил один ряд и получил вот это на выходе. И если я вставляю еще два ряда, что здесь странного? Здесь есть странность, потому что я добавил три ряда к этой таблице, но у меня все еще два ряда в таблице блокировки. И это, по сути, основополагающее поведение Postgres.
Многие думаю, что если в базе данных, вы блокируете 100 рядов, то вам будет необходимо создать 100 вводов блокировок. Если я буду блокировать сразу 1 000 рядов, то тогда мне нужна будет 1 000 таких запросов. И если мне нужно миллион или миллиард заблокировать. Но если мы так будем делать, то это будет не очень хорошо работать. Если вы использовали систему, которая создает вводы блокировки для каждого отдельного ряда, то вы видите, что это сложно. Потому что вам нужно определить сразу таблицу блокировки, которая может переполниться, но Postgres так не делает.
И на этом слайде очень важно, что здесь явно демонстрируется, что есть еще одна система, которая работает внутри MVCC, которая блокирует отдельные строки. Поэтому, когда вы блокируете миллиарды рядов, то Postgres не создает миллиард отдельных команд на блокировку. И это очень хорошо сказывается на производительности.

А как насчет обновления? Я сейчас обновляю ряд, и вы можете заметить, что он сразу выполнил две разные операции. Он одновременно заблокировал таблицу, но он также заблокировал индекс. И ему нужно было блокировать индекс, потому что есть уникальные ограничения на этой таблице. И мы хотим убедиться, что никто его не меняет, поэтому мы его блокируем.

А что будет, если я хочу обновить два ряда? И мы видим, что он ведет себя также. Мы проводим в два раза больше обновлений, но точно такое же количество строчек блокировки.
Если вам интересно, как Postgres это делает, вам нужно послушать мои выступления по MVCC, чтобы узнать, как Postgres внутренне маркирует эти строки, которые он меняет. И у Postgres есть способ, при помощи которого он это делает, но он это не делает на уровне блокировки таблиц, он делает на более низком и на более эффективном уровне.

А если я хочу что-то удалить? Если я удаляю, например, один ряд и у меня все еще есть мои два вводных у блокировки, и даже если я захочу удалить их все, то они все равно там присутствуют.

И, например, я хочу вставить 1 000 строчек, а потом или удалить, или добавить 1 000 строчек, то те индивидуальные строки, которые я добавляю или меняю, они не записываются здесь. Они записываются на более низком уровне внутри самого ряда. И во время выступления по MVCC я говорил об этом в деталях. Но очень важно, когда вы анализируете блокировки, убедиться, что у вас блокировка на уровне таблицы и что здесь вы не видите, как ведется запись отдельных рядов.

А как насчет эксплицитной блокировки?

Если я нажму «обновить», то у меня есть два заблокированных ряда. И если выделю их все и нажму «обновить везде», то у меня все равно остаются две записи блокировки.

Мы не создаем отдельные записи на каждый отдельный ряд. Потому что тогда падает производительность, там может быть этого слишком много. И мы можем оказаться в неприятной ситуации.

И тоже самое, если мы делаем shared, мы можем делать на все 30 раз.

Мы восстанавливаем нашу таблицу, все удаляем, потом снова вставляем один ряд.
Еще один вид поведения, который вы видите в Postgres, это очень хорошо известное и желаемое поведение – это то, что вы можете проводить update или select. И вы можете это делать одновременно. И select не блокируют update и тоже самое в обратную сторону. Мы говорим читающему не блокировать того, кто пишет, а тот, кто пишет, не блокировал читателя.
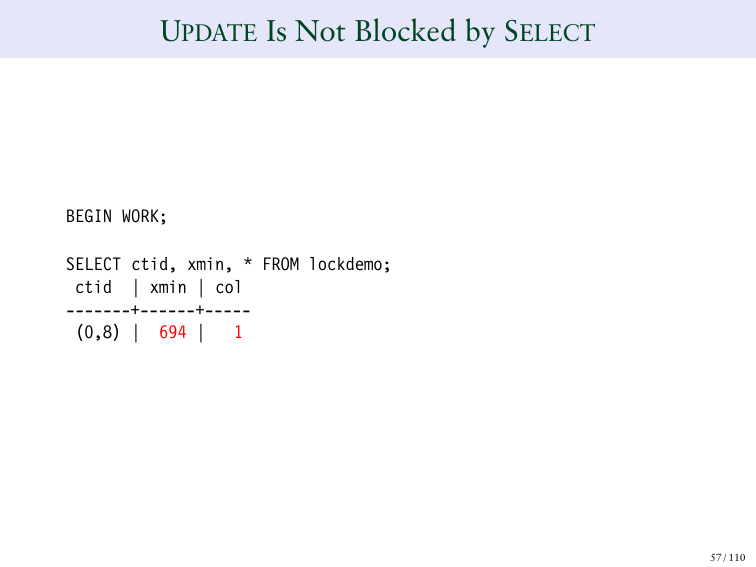
Я вам покажу пример этого. Я сделаю сейчас выбор. Мы потом сделаем INSERT. И вы потом сможете увидеть – 694. Вы сможете увидеть ID транзакции, которая провела эту вставку. И это то, как это работает.

И если я сейчас посмотрю на свой бэкенд ID, то он стал – 695.

И я могу увидеть, что 695 появляется в моей таблице.
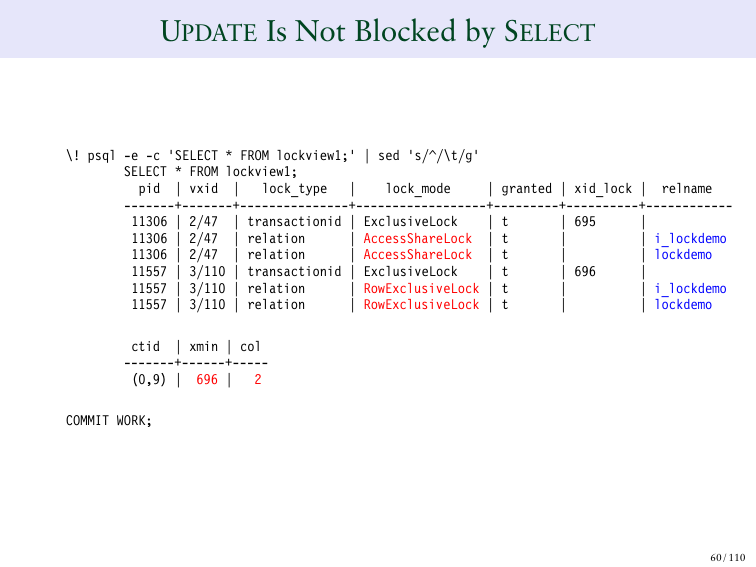
И если я провожу обновление здесь вот так, то я получаю другой кейс. В этом случае 695 – эксклюзивная блокировка, а у update такое же поведение, но между ними не возникает конфликта, что достаточно необычно.
И вы можете заметить, что на верху – это ShareLock, а внизу – это ExclusiveLock. И обе транзакции получились.
И нужно послушать мое выступление в MVCC, чтобы понять, как это происходит. Но это иллюстрация того, что вы можете делать это одновременно, т. е. одновременно делать SELECT и UPDATE.

Давайте мы сбросим и еще раз сделаем одну операцию.

Если вы попробуете запустить одновременно два update на одном и том же ряду, то оно заблокируется. И помните, я говорил, что читающий не блокирует писателя, а писатель читателя, но один писатель блокирует другого писателя. Т. е. мы не можем делать так, чтобы два человека одновременно обновляли один и тот же ряд. Нужно ждать, пока один из них закончит.

И для того, чтобы это проиллюстрировать я посмотрю на Lockdemo таблицу. И мы посмотрим на один ряд. На транзакцию 698.
Мы это обновили до 2-х. 699 – это первое обновление. И оно прошло успешно или оно находится в ожидающей транзакции и ожидает, когда мы подтвердим или отменим.

Но посмотрите на другое – 2/51 – это наша первая транзакция, наша первая сессия. 3/112 – это второй запрос, который появился сверху и который поменял это значение на 3. И если вы заметете, то верхний заблокировал сам себя, который 699. Но 3/112 не предоставили блокировку. В колонке Lock_mode написано, что он ожидает. Он ожидает 699. И если вы посмотрите, где 699, он выше. И что сделала первая сессия? Она создала эксклюзивную блокировку на своем собственном транзакционном ID. Это то, как Postgres это делает. Он блокирует собственный транзакционный ID. И если вы хотите ждать, пока кто-то подтвердит или отменит, то нужно ждать, пока есть ожидающаяся транзакция. И поэтому мы можем увидеть странную строчку.
Давайте посмотрим еще раз. Слева мы видим наше процессинговое ID. Во второй колонке мы видим наш виртуальный ID транзакции, а в третьей видим lock_type. Что это означает? По сути, она говорит, что блокирует транзакционный ID. Но заметьте, что во всех рядах внизу написано relation. И поэтому у вас два вида блокировки в таблице. Есть блокировка relation. А также есть блокировка transactionid, где вы мы блокируете самостоятельно, это именно то, что происходит на первом ряду или в самом низу, где transationid, где мы ожидаем, чтобы 699 закончил свою операцию.
Я смотрю, что здесь получается. И здесь одновременно происходят две вещи. Вы смотрите на блокировку по транзакционному ID в первом ряду, которая блокирует сама себя. И она блокирует сама себя, чтобы заставить людей ждать.
Если вы посмотрите на 6-ую строчку, то та же запись, что и первая. И поэтому транзакция 699 блокируется. 700 тоже самоблокируется. И потом в нижнем ряду вы увидите, что мы ждем, когда 699 закончит свою операцию.

И в lock_type, tuple вы видите числа.
Вы можете увидеть, что это 0/10. И это номер страницы, и также offset этого конкретного ряда.
И вы видите, что становится 0/11, когда мы обновляем.
Но на самом деле – это 0/10, потому что происходит ожидание этой операции. У нас есть возможность посмотреть, что это тот ряд, который я жду, чтобы подтвердить.

Как только мы его подтвердили и нажали commit, и когда обновление закончилось, это то, что мы получаем снова. Транзакция 700 – это единственная блокировка, она больше никого не ждет, потому что ее закоммитили. Она просто ждет, чтобы транзакция завершилась. Как только 699 заканчивается, мы больше ничего не ждем. И теперь транзакция 700 говорит, что все хорошо, что все блокировки, которые нужны, у нее есть во всех разрешенных таблицах.

И чтобы еще усложнить все это дело, мы создаем еще один view, который в этот раз нам предоставит иерархию. Я не ожидаю, что вы поймете этот запрос. Но это даст нам более ясный вид того, что происходит.

Это рекурсивный вид, у которого также есть еще одна секция. И оно потом снова возвращает все вместе. Давайте использовать это.

Что, если мы сделаем три одновременных обновления и скажем, что ряд сейчас равен трем. И мы поменяем 3 на 4.

И вот мы видим 4. И транзакционный ID 702.

И затем я поменяю 4 на 5. А 5 на 6, а 6 на 7. И я выстраиваю в очередь ряд людей, которые будут ожидать того, чтобы эта одна транзакция закончилась.
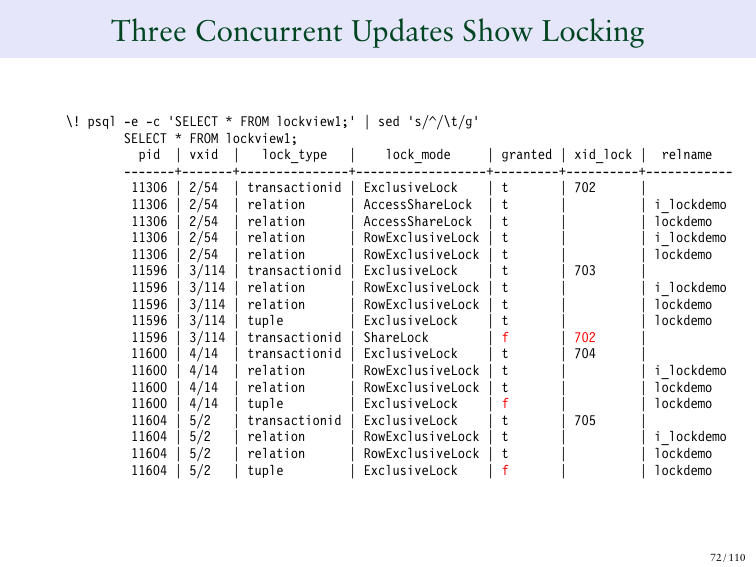
И все становится понятным. Какой первый ряд? Это 702. Это транзакционный ID, который изначально задал это значение. А что у меня написано в колонке Granted? У меня есть отметки f. Это те мои обновления, которые (5, 6, 7) не могут быть одобрены, потому что мы ждем, чтобы транзакционный ID 702 закончился. Там у нас есть блокировка транзакционного ID. И получается 5 транзакционных блокировок ID.
И если вы посмотрите на 704, на 705, то там еще ничего не написано, потому что они еще не знают, что происходит. Они просто пишут, что без понятия, что происходит. И они просто уйдут в сон, потому что они ждут, пока кто-то закончит и их разбудят, когда появится возможность поменять ряд.

Это то, как это выглядит. Понятно, что они все ждут 12-ую строчку.
Это то, что мы видели вот здесь. Вот 0/12.

Итак, как только первая транзакция одобрена, то вы можете здесь увидеть, как работает иерархия. И теперь становится все ясно. Они все становятся чистыми. И они на самом деле все еще в ожидании.

Вот, что происходит. 702 коммитется. И теперь 703 получает эту блокировку ряда, а потом 704 начинает ждать, когда 703 закоммитется. И 705 тоже этого ждет. И когда все это завершается, то они сами себя зачищают. И я хотел бы указать на то, что все выстраиваются в очередь. И это очень похоже на ситуацию с пробкой, когда все ожидают первую машину. Первая машина остановилась, и все выстраиваются в длинную линию. Потом она двигается, потом следующая машина может проехать вперед и получить свою блокировку и т. д.
И если вам это показалось недостаточно сложным, то мы сейчас поговорим с вами о deadlocks. Я не знаю, кто из вас с ними сталкивался. Это достаточно распространенная проблема в системах баз данных. Но deadlocks – это тот случай, когда одна сессия ожидает, чтобы что-то выполнила другая сессия. А в этот момент другая сессия ожидает, чтобы первая сессия выполнила что-то.
И, например, если Иван говорит: «Дай мне что-нибудь», а я говорю: «Нет, я тебе это дам только, если ты мне дашь что-то другое». А он говорит: «Нет, я не дам тебе это, если ты мне не дашь». И мы получаемся в ситуации мертвой блокировки. Я уверен, что Иван так не сделает, но вы понимаете смысл, что у нас два человека хотят что-то получить и они не готовы это отдать, пока другой человек им не отдаст, то что они хотят. И тут нет решения.
И, по сути, вашей базе данных нужно это выявлять. И затем необходимо удалять или закрывать одну из сессий, потому что в обратном случае они там останутся навсегда. И мы это видим в базах данных, мы это видим в операционных системах. И во всех местах, где у нас есть параллельные процессы, такое может быть.
И мы поставим сейчас две deadlocks. Мы поставим 50 и 80. В первый ряд я проведу обновление с 50 на 50. У меня получится номер транзакции 710.

И затем я поменяю 80 на 81, и 50 на 51.
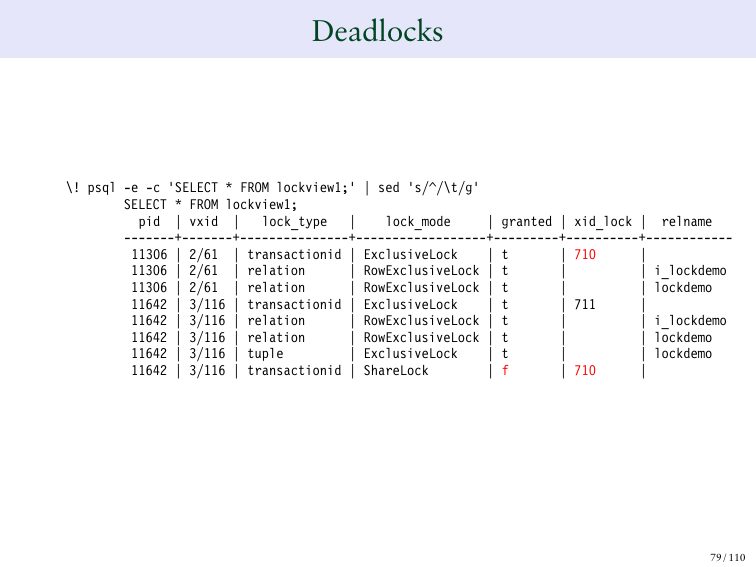
И вот, как это будет выглядеть. И поэтому у 710 есть блокировка ряда, а 711 ожидает подтверждение. Мы видели это, когда обновляли. 710 – является владельцем нашего ряда. А 711 ожидает, чтобы 710 закончил транзакцию.
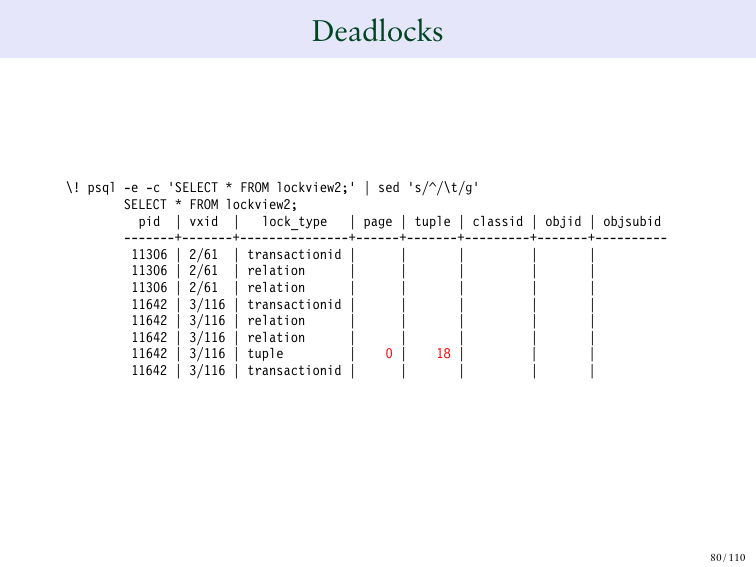
И там даже написано на каком именно ряде у нас происходит deadlocks. И вот где это начинает становится странным.
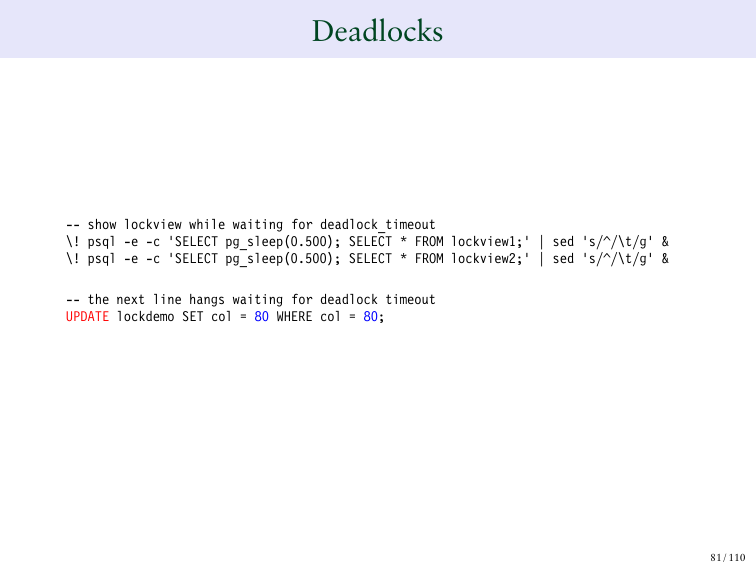
Теперь мы обновляем 80 на 80.
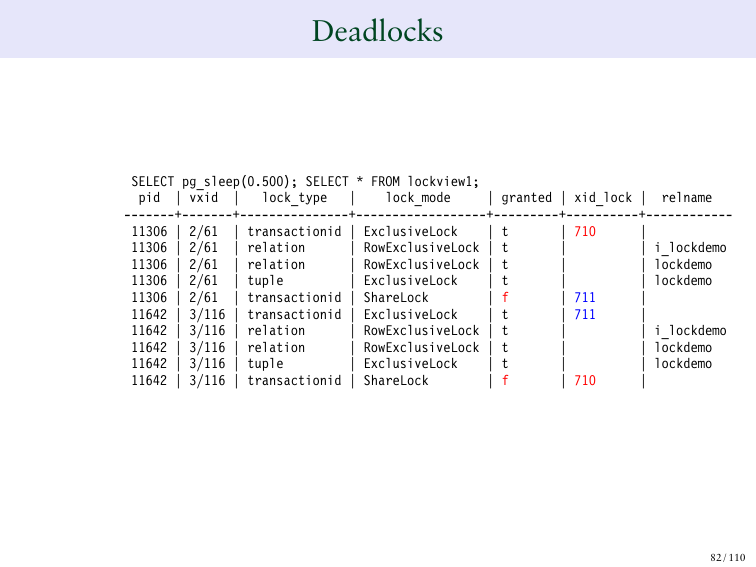
И вот, где начинается deadlocks. 710 ожидает отклика от 711, а 711 ожидает 710. И это нехорошо кончится. И из этого нет выхода. И они будут ожидать отклика друг от друга.
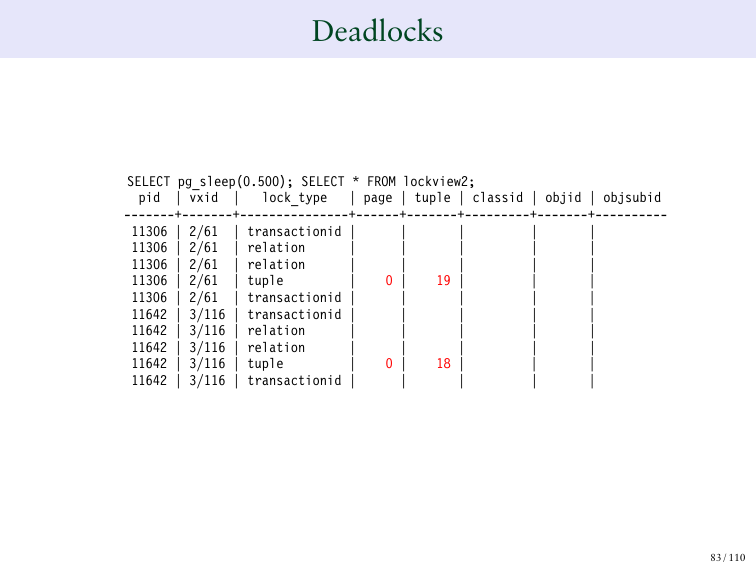
И это просто все начнет задерживать. И мы этого не хотим.

И в Postgres есть способы замечать, когда это происходит. И когда это происходит, то вы получаете вот такую ошибку. И из этого ясно, что такой-то процесс ожидает SHARE LOCK’а от другого процесса, т. е. который блокируется 711 процессом. А тот процесс ожидал, чтобы был дан SHARE LOCK на такой-то транзакционный ID и был заблокированный таким-то процессом. Поэтому тут ситуация мертвой блокировки.

А бывает ли трехсторонний deadlocks? Возможно ли это? Да.

Мы вбиваем эти числа в таблицу. Мы меняем 40 на 40, мы делаем блокировку.

Меняем 60 на 61, 80 на 81.

А затем мы меняем 80, а затем – бум!
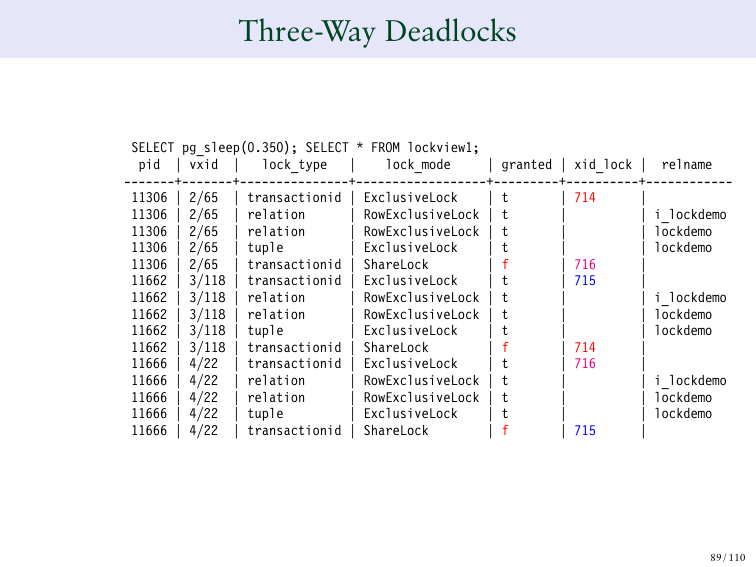
И 714 теперь ожидает 715. 716-ый 715-го ожидает. И с этим уже ничего не сделать.

Здесь уже не два человека, здесь уже три человека. Я хочу что-то от тебя, этот хочет что-то от третьего человека, а третий человек хочет что-то от меня. И мы получаемся в трехстороннем ожидании, потому что мы все ждем, пока другой человек завершит то, что он должен сделать.

И Postgres знает на каком ряду это происходит. И поэтому он выдаст вам следующее сообщение, которое показывает, что у вас есть проблема, где три вводных блокируют друг друга. И здесь нет ограничений. Это может быть в случае, где 20 записей блокируют друг друга.

Следующая проблема – это serializable.

Если специальная serializable блокировка.

И возвращаемся к 719. У него вполне нормальная выдача.

И вы можете нажать, чтобы сделать транзакцию из serializable.

И вы понимаете, что у вас теперь есть другой вид блокировки SA – это означает serializable.

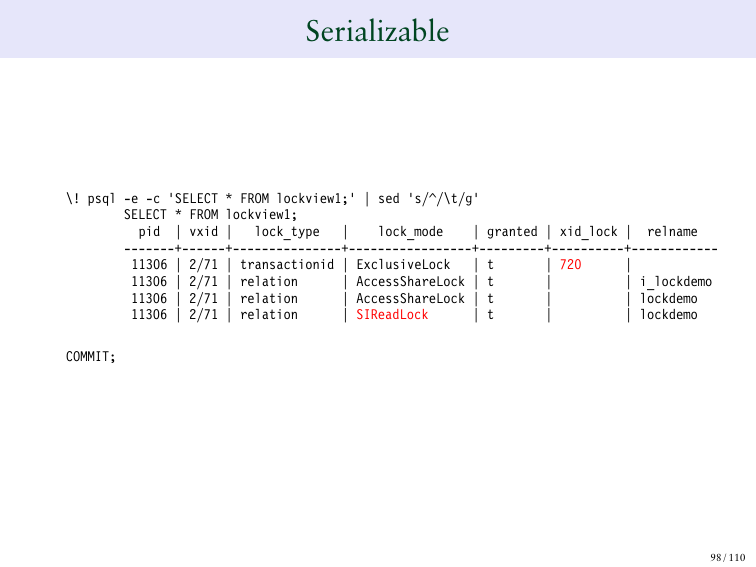
И поэтому у нас есть новый вид блокировки, который называется SARieadLock, который является серийной блокировкой и позволяет вводить серийники.

И также вы можете вставлять уникальные индексы.

В этой таблице у нас есть уникальные индексы.

Поэтому, если я сюда введу число 2, поэтому у меня есть 2. Но в самом вверху я вставляю еще одно 2. И вы можете видеть, что у 721-го эксклюзивная блокировка. Но теперь 722 ожидает, чтобы 721 завершил свою операцию, потому что он не может вставить 2 до тех пор, пока не знает, что произойдет с 721.

И если мы делаем subtransaction.

Вот у нас 723.
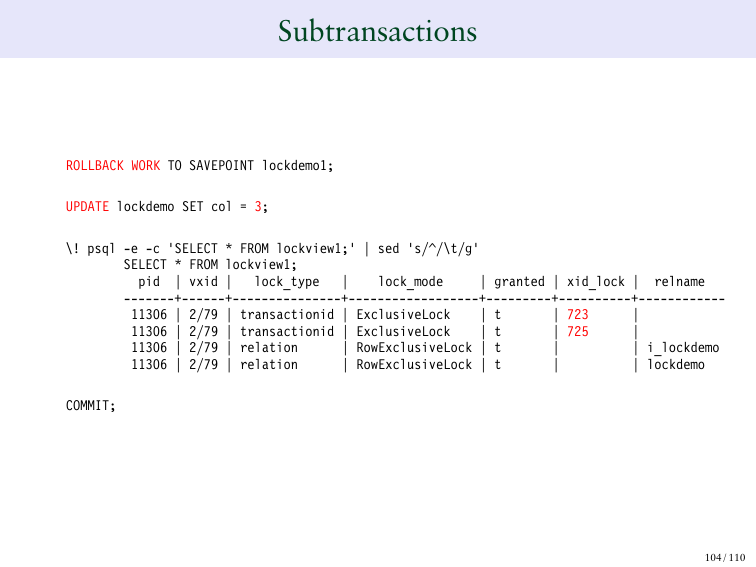
И если мы сохраняем точку и потом ее обновляем, то у нас получается новый транзакционный ID. Это еще один характер поведения, который вам нужно знать. Если мы это возвращаем, то транзакционный ID уходит. 724 уходит. Но теперь у нас появляется 725.
И что я пытаюсь здесь сделать? Я пытаюсь показать вам примеры необычных блокировок, которые вы можете найти: будь то serializable блокировки или SAVEPOINT – это разные виды блокировок, которые будут появляться в таблице блокировок.

Это создание эксплицитных (явных) блокировок, у которых pg_advisory_lock.

И вы видите, что тип блокировки тут числится как advisory. И тут красным написано «advisory». И вы можете одновременно так заблокировать с pg_advisory_unlock.

И завершая я хотел бы вам показать еще одну крышесносную вещь. Я создам еще один вид. Но я соединю таблицу pg_locks с таблицей pg_stat_activity. И зачем я хочу это сделать? Потому что это позволит мне посмотреть и увидеть все текущие сессий и увидеть, каких именно блокировок они ожидают. И это достаточно интересно, когда мы собираем воедино таблицу блокировок и таблицу запросов.

И здесь мы создаем pg_stat_view.

И мы обновляем ряд на один. И здесь мы видим 724. А затем мы обновляем наш ряд до трех. И что вы видите здесь сейчас? Это запросы, т. е. вы видите весь список запросов, которые перечислены в левой колонке. А затем на правой стороне вы можете видеть блокировки и то, что они создают. И это может быть более понятно для вас, чтобы вам не было нужды каждый раз возвращаться к каждой сессии и смотреть – нужно ли к ней присоединиться или нет. За нас это делают.
Еще одна функция, которая очень полезна – это pg_blocking_pids. Вы, наверное, о ней не слышали никогда. Что она делает? Она позволяет нам сказать, что для этой сессии 11740, какие именно ID-процессов она ожидает. И вы можете видеть, что 11740 ожидает 724. И 724 находится на самом верху. А 11306 является вашим ID-процессом. По сути, эта функция идет по вашей таблице блокировок. И я знаю, что это немного сложно, но у вас получается это понимать. По сути, эта функция проходит через эту таблицу блокировок и пытается найти, где этот процесс ID, учитывая те блокировки, которая она ждет. И также пытается вычислить, какой именно процесс ID, у того процесса, который ждет блокировки. Поэтому вы можете запустить эту функцию pg_blocking_pids.
И это бывает очень полезно. Мы это добавили только с версии 9.6, поэтому этой функции всего лишь 5 лет, но она очень и очень полезная. И тоже самое касается второго запроса. Он показывает именно то, что нам надо видеть.

Это то, о чем я хотел с вами поговорить. И как я ожидал, мы использовали все наше время, потому что было такое большое количество слайдов. И слайды доступны для скачивания. Я хотел бы поблагодарить вас за то, что вы были здесь. Я уверен, что вам понравится остаток конференции, большое спасибо!
Вопросы:
Например, если я стараюсь обновить строки, а вторая сессия старается удалить всю таблицу. Насколько я понимаю, что там должно быть что-то вроде intent lock’а. Есть ли такое в Postgres?
Возвращаемся к самому началу. Возможно, вы помните, что когда вы делаете что бы то ни было, например, когда вы делаете SELECT, то мы выдаем AccessShareLock. И это предотвращает удаление таблицы. Поэтому если вы, например, хотите обновить ряд в таблице или удалить ряд, то кто-то не может удалить всю таблицу одновременно с этим, потому что вы держится этот AccessShareLock над всей таблицей и над рядом. И как только вы закончили, они могут это удалить. Но пока вы непосредственно что-то там меняете, они не смогут сделать.
Давайте еще раз. Давайте перейдем к примеру с удалением. И вы видите, как на ряде есть эксклюзивный lock над всей таблицей.
Это будет выглядеть как lock exclusive, правильно?
Да, это похоже на это. Я понимаю, о чем вы говорите. Вы говорите, что, если я выполню SELECT, то у меня будет ShareExclusive, а потом я перевожу это в состояние Row Exclusive, то становится ли это проблемой? Но на удивление это не создает проблему. Это похоже на увеличение степени блокировки, но, по сути, у меня есть lock, который предотвращает удаление. И сейчас, когда я делаю этот замок более мощным, то он все еще предотвращает удаление. Поэтому это не то, чтобы я поднимаюсь вверх. Т. е. он предотвращал это и когда он был на более низком уровне, поэтому, когда я повышаю его уровень, он все еще предотвращает удаление таблицы.
Я понимаю, о чем вы говорите. Здесь нет случая увеличения степени блокировки, где вы пытаетесь отказаться от одной блокировки, чтобы ввести более мощную. Здесь это просто повсеместно увеличивает это предотвращение, поэтому это не вызывает никакого конфликта. Но это хороший вопрос. Большое спасибо, что его задали!
Что нам необходимо делать для того, чтобы избежать ситуации deadlock’а, когда у нас есть много сессий, большое количество пользователей?
Postgres автоматически замечает ситуации deadlock’а. И автоматически будет удалять одну из сессий. Единственный способ, который поможет избежать ситуацию с мертвыми блокировками, если будете блокировать людей в одном и том же порядке. Поэтому, когда вы посмотрите на ваше приложение, то зачастую причина deadlocks… Давайте представим, что я хочу заблокировать две разные вещи. Одно приложение блокирует таблицу 1, а другое приложение блокирует 2, а затем таблицу 1. И самый простой способ избежать deadlocks – это посмотреть на ваше приложение и постараться убедиться в том, что блокировка происходит в одной той же очередности во всех приложениях. И это, как правило, убирает 80 % проблем, потому что самые разные люди пишут эти приложения. И если вы блокируете их в одном и том же порядке, то вы не сталкиваетесь с ситуацией deadlock’а.
Большое спасибо за ваше выступление! Вы говорили о vacuum full и, если я правильно понимаю, то vacuum full деформирует порядок записей в отдельном хранении, поэтому сохраняют текущие записи неизменными. А почему vacuum full берет доступ эксклюзивной блокировки и почему он конфликтует с операциями по записи?
Это хороший вопрос. Причина заключается в том, что vacuum full берет таблицу. И мы, по сути, создаем новую версию таблицы. И таблица будет новой. Получается это будет совершенно новая версия таблицы. И проблема заключается в том, что, когда мы это делаем, мы не хотим, чтобы люди читали это, потому что нам нужно, чтобы они увидели новую таблицу. И поэтому это соединяется с предыдущим вопросом. Если бы мы могли одновременно читать, то мы бы не смогли его переместить и направлять людей на новую таблицу. Нам нужно было бы ожидать, чтобы каждый закончил читать эту таблицу, и поэтому, по сути, это ситуация lock exclusive.
Мы просто говорим, что мы блокируем с самого начала, потому что мы знаем, что в самом конце нам потребуется эксклюзивная блокировка для того, чтобы передвинуть всех на новую копию. Поэтому потенциально мы можем это разрешить. И мы так делаем это с одновременным индексированием. Но это намного сложнее сделать. И это очень сильно относится к вашему предыдущему вопросу про lock exclusive.
Возможно ли добавлять locking timeout в Postgres? В Oracle я могу, например, написать «выбрать на обновление» и ожидать 50 секунд до обновления. Это было хорошо для приложения. Но в Postgres у меня либо нужно это делать сразу и совсем не ждать, либо ждать до какого-то времени.
Да, вы можете выбрать тайм-аут на ваши блокировки, на ваши locks. Вы также можете выдать команду no way, которая будет …, если вы не сможете сразу получить блокировку. Потому либо lock timeout, либо другое, что позволит вам это сделать. Это не делается на синтаксическом уровне. Это делается, как переменная на сервере. Иногда это нельзя использовать.
Вы можете открыть 75 слайд?
Да.
И мой вопрос следующий. Почему оба процесса обновления ожидают 703?
И это замечательный вопрос. Я не понимаю, кстати, почему Postgres это делает. Но когда 703 был создан, он ожидал 702. И когда 704 и 705 появляются, то кажется, что они не знают того, что они ждут, потому что там еще ничего нет. И Postgres это делает так: когда вы не можете получить блокировку, то он пишет «А смысл вас обрабатывать?», потому что вы и так ждете кого-то. Поэтому просто дадим ему повисеть в воздухе, он вообще не обновляет это. Но что произошло здесь? Как только 702 завершил процесс и 703 получил свою блокировку, то система вернулась обратно. И сказала, что теперь у нас есть два человека, которые находятся в ожидании. А затем давайте мы их обновим вместе. И укажем, что оба ожидают.
Я не знаю, почему Postgres так делает. Но есть проблема, которая называется f…. Мне кажется, что это не термин на русском. Это когда все ждут одного замка, даже если есть 20 инстанций, который ждут замка. И вдруг они все просыпаются одновременно. И все начинают пытаться среагировать. Но система делает так, что все ожидают 703. Потому что они все ждут, и мы их сразу всех выстроим в очередь. И если появляется любой другой новый запрос, который был сформирован после этого, например, 707, то там снова будет пустота.
И мне кажется, что это делается для того, чтобы можно было сказать, что на этом этапе 702 ожидает 703, а все те, кто придут после этого, у них не будет никакой записи в этом поле. Но как только первый ожидающий покидает, и все те, кто ожидали в этот момент до обновления, получают тот же самый маркер. И поэтому, мне кажется, это сделано для того, чтобы мы могли обрабатывать по порядку, чтобы они были правильно упорядочены.
Я всегда смотрел на это, как на достаточно странный феномен. Потому что здесь, например, их вообще не перечисляем. Но, мне кажется, каждый раз, когда мы даем новый lock, то мы смотрим на всех тех, кто находится в процессе ожидания. Тогда мы их всех выстраиваем в очередь. А затем любой новый, который приходит, попадает в очередь только тогда, когда следующий человек закончил обрабатываться. Очень хороший вопрос. Спасибо вам большое за вопрос!
Мне кажется, намного логичнее, когда 705 ожидает 704.
Но проблема здесь следующая. Технически вы можете разбудить или тот, или тот. И поэтому мы разбудим тот или другой. Но что происходит в работе системы? Вы видите, как 703 в самом верху заблокировал свой собственный транзакционный ID. Это то, как Postgres работает. И 703 блокируется собственным транзакционным ID, поэтому, если кто-то хочет подождать, то он будет ждать 703. И, по сути, 703 завершает. И только после его завершения какой-то из процессов пробуждается. И мы не знаем, какой именно это процесс будет. Затем мы постепенно все обрабатываем. Но не ясно какой именно процесс пробуждается первым, потому что это может быть любой из этих процессов. По сути, у нас был планировщик, который говорил, что мы теперь можем пробуждать любой из этих процессов. Мы просто выбираем один случайным образом. Поэтому оба из них нужно отметить, потому что мы можем пробуждать любой из них.
И проблема в том, что у нас CP-бесконечность. И поэтому вполне вероятно можем разбудить более поздний. И если, например, мы будем пробуждать более поздний, то будем ожидать того, кто только что получил блокировку, поэтому мы не определяем, кто именно будет пробужден первым. Мы создаем просто такую ситуацию, и система будет их пробуждать в произвольном порядке.
Есть статьи про locks Егора Рогова. Посмотрите, они тоже интересные и полезные. Тема, конечно, жутко сложная. Спасибо большое, Брюс!

