Этот доклад 2016 года, но он все равно полезен для тех кто хочет разобраться как работает TeamCity.
Здравствуйте, очень рад здесь сегодня быть и видеть такой живой интерес к нашему продукту. Я действительно разработчик TeamCity. Я работаю над продуктом более 7 лет. Моя зона ответственности – это поддержка dotnet технологий в TeamCity. Я руковожу dotnet разработкой. Но в том числе я достаточно много общаюсь с пользователями. И делаю всякого вида доклады на конференциях, в том числе тренинги мы делаем для пользователей и помогаем использовать наш продукт правильно, эффективно и т. д.
Сегодня я хочу поделиться опытом использования TeamCity внутри JetBrains и теми подходами, которые мы используем. Я, надеюсь, что вам будет полезно.
У нас обязательно будет сессия вопросов и ответов в конце, поэтому, если вдруг что-то я не освещу, то у вас будет возможность спросить.
Я начну немного издалека. Расскажу про настоящее компании и продукта.

JetBrains сегодня – это офисы в 4-х странах, в том числе у нас есть небольшой офис в Москве, где, кстати, сидят несколько разработчиков TeamCity тоже.
У нас 20 продуктов. Из них 16 персональных и 4 продукта для команды. Это те продукты, которые мы уже анонсировали. Кое-что вариться из того, что мы еще не анонсировали, но через какое-то время тоже будет доступно.
Компания достаточно быстро растет. Количество разработчиков превышает 500 человек, потому что у нас в компании в основном разработчики. У нас минимальное количество людей, которые не занимаются разработкой. Даже те, кто у нас числится менеджером, это тоже обычно разработчик. Даже девчонки на ресепшене сидят и что-то на Javascript делают.
Соответственно, компания очень быстро сейчас растет, особенно в последние 5 лет. И количество сотрудников в разы увеличилось. Очень много продуктов было выпущено.
И активных пользователей только наших персональных продуктов, по-моему, больше 3 000 000 человек в мире, т. е. именно разработчиков. Это достаточно хороший результат, мне кажется. И это число растет постоянно.
Соответственно TeamCity – один из старейших продуктов в компании. В этом году мы выпустили 10-ую версию. Мы выпускаем один мажорный апдейт в течение года и один второстепенный. В мажорном апдейте появляются все новые фичи. Во второстепенном эти фичи доделываются и появляются какие-то менее глобальные фичи.
И еще выпускаем на каждый из этих апдейтов по минимум 5 bugfix апдейтов. И каждый месяц мы что-то релизим. Это либо bugfix апдейт, либо какой-то фич апдейт.
Еще важная особенность TeamCity в том, что саппорт осуществляется командой разработчиков, т. е. у нас, конечно, есть отдельный саппорт, где отвечают инженеры на самые часто задаваемые вопросы, но в основном, если вы обращаетесь в саппорт, то чаще всего вы разговариваете с разработчиками. Соответственно, для вас это хороший уровень компетенции тех, кто отвечает на ваши вопросы. А для нас, для разработчиков, это возможность иметь из первых рук обратную связь про фичи, которые мы зарелизили.

У нас есть внутренняя инсталляция в TeamCity, которая собирает все продукты JetBrains. Вообще, это особенная инсталляция, потому что из нее продукт и вырос.
Все продукты JetBrains появляются и развиваются примерно по одному и тому же сценарию. Мои коллеги, когда разрабатывали эту идею, они столкнулись с тем, что на тот момент ни один инструмент, ни одна build система не удовлетворяла требованиям, которые возникают при разработке сложного java приложения. И было решено сделать свой build сервер. Вот так в JetBrains и появился TeamCity.
Все это время продукт эволюционировал. И во многом эволюционировал как ответ на новые требования нашей увеличивающейся компании. Когда продуктов стало очень много, команд стало очень много, мы сделали иерархию проектов. Когда коллеги стали перелезать активно на использование Git, мы сделали поддержку фич бранчей Git. Т. е. очень многие фичи – это реакция на потребность наших коллег, которые делают сложные продукты для dotnet, java и т. д., поэтому поддержка в TeamCity получается достаточно хорошая.
Вот примерные цифры размера нашей инсталляции. Это я взял нашу статистику:
- У нас более 500 активных проектов.
- В нем около 4 000 активных конфигураций.
- У нас больше 300 build агентов подсоединено к этой одной инсталляции.
- Builds наши в среднем достаточно массивные. Максимальное количество текстов, которое исполняется в одном build – это 53 269.
- В среднем по компании build длится 25 минут. И поток builds достаточно большой, потому что в день происходит около 3 000 коммитов во всей компании. И, соответственно, build-сервис все эти коммиты обрабатывает, запускает builds.
- В среднем 6 000 задач каждый день стартуется.
Т. е. нагрузка на этот внутренний build-сервис достаточно большая. И так или иначе все, что я буду сегодня рассказывать, будет касаться этой инсталляции.

Что конкретно я бы хотел осветить сегодня?
- Во-первых, познакомлю со своим взглядом на базовые понятие TeamCity такие, как конфигурация, проект, шаблон, зависимость, build agents и т. д. Расскажу некоторые детали и особенности использования внутри всех этих понятий.
- Дальше отдельно остановлюсь на очень важной фиче. Это снапшот зависимости. Я расскажу о том, какие есть варианты применения этой фичи. Как показывает практика, пользователи не совсем понимают, зачем это нужно и как правильно использовать эту фичу. Она является краеугольным камнем в TeamCity. И аналогов на рынке нет. И я уделю отдельное время этой фиче.
- Я расскажу о подходах к управлению окружением на build agents, которые мы сейчас используем. Build agents много, их 300 штук. Там разные environment для того, чтобы исполнять тесты наших продуктов. И нужно как-то всем управлять.
- Потом расскажу о том, как TeamCity скелится внутри компании, т. е. в частности в 10-ой версии мы выкатили новую фичу, которая позволяет доставлять еще дополнительный TeamCity сервер, который часть нагрузки с основного сервера на себя снимает.
- Потом коснусь практик администрирования TeamCity.
- И потом расскажу про расширение TeamCity, т. е. про всякие плагины, которые в поставку не входят, но мы внутри компании их используем, и они достаточно полезны нам.
Первые эти два пункта будут в основном полезны разработчикам, build-инженерам, тем, кто не особо касается администрирования самого сервера, но хочет его эффективно и правильно использовать.
Последние четыре пункта будут в том числе полезны проектным администраторам и людям, которые так или иначе вовлечены в администрирование TeamCity.

TeamCity реализует концепцию competition green, т. е. есть основная нода, которая распределяет задачу по вычислению чего-то на второстепенные ноды. Второстепенные ноды – это build agents. Основная нода содержит все данные про конфигурирование этих задач и реагирует на события внешней среды. Т. е. на коммиты version control, на появление артефактов в control репозитории и т. д. И запускает задачу.
Ноды, которые называются, build agents, они репортят на сервер этой задачи и все результаты их исполнения. Соответственно, сервер в том числе поддерживает очередь задач, т. е. если подходящих для исполнения конкретных задач агентов нет, она ставится в очередь и живет там, пока этот агент не появится. Очередь переживает restart, т. е. вы можете выключить сервер и включить обратно, но состояние очереди сохранится.
И в том числе важной особенностью является то, что если в какой-то момент сервер ушел, например, вы производите апгрейд, то агенты переходят в режим накопления данных, которые потом они отправляют на сервер, когда сервер снова поднимется. Таким образом вы можете при апгрейде сервера не потерять ни байта данных, которые должны были пересланы из builds на сервер. А после того, как агенты свои существующие задачи после апгрейда сервера закончат, они получат команду на апгрейд и сами уйдут на апгрейд.
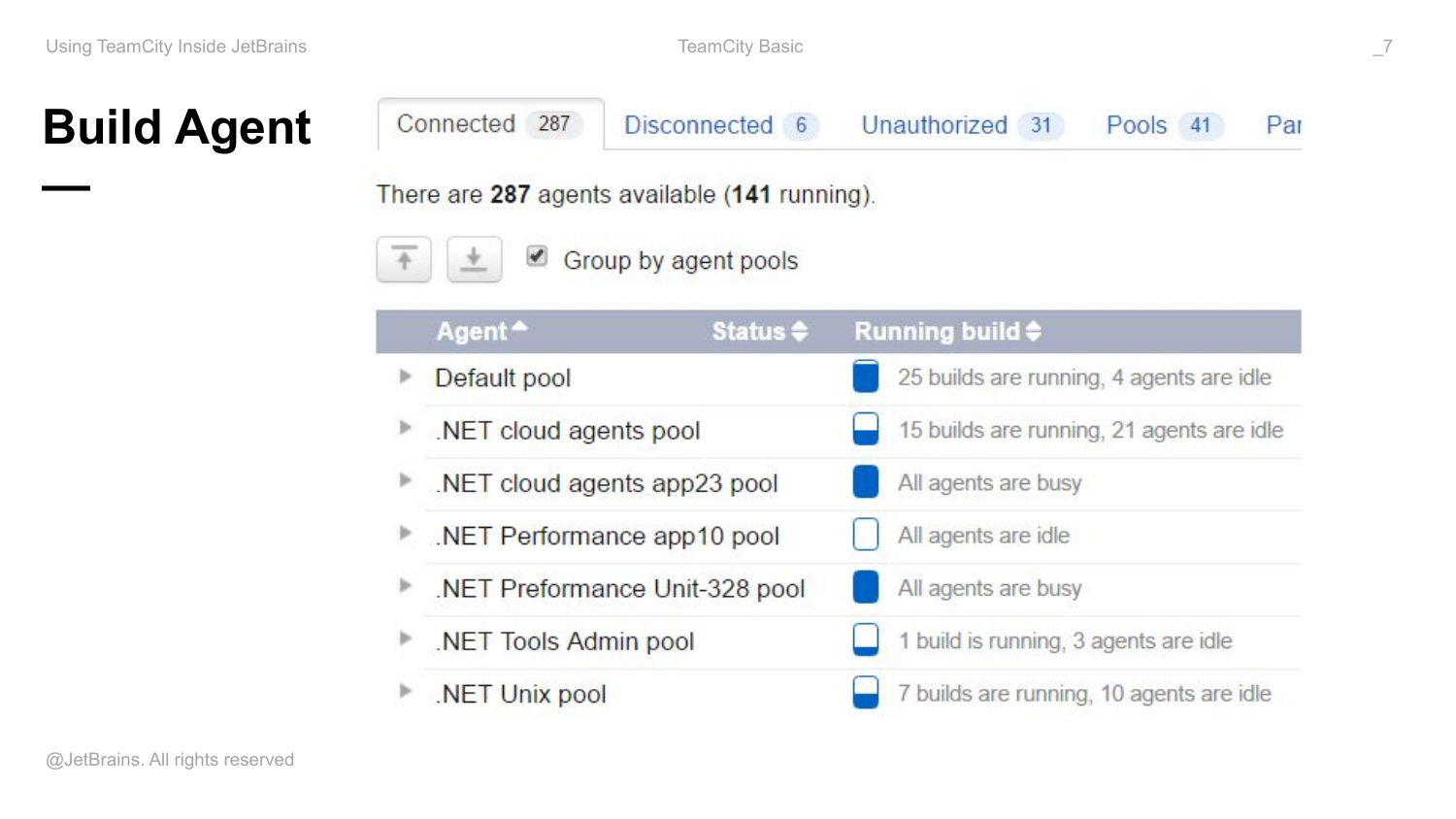
Build Agent – это java-процесс, который запущен как консольное приложение, либо как сервис на какой-то машине. Он умеет принимать задачи по построению, тестированию, деплою и какие угодно задачи от сервера. Умеет репортить обратно ход их исполнения и какие-то артефакты, которые в процессе были сгенерированы и т. д.
Все множество агентов, авторизованных на сервере, делятся по пулам. Пулы очень полезно использовать для того, чтобы доступные ресурсы как-то распределять между командами разработчиков. Т. е. у нас внутри для разных команд есть выделенные свои пулы. И это гарантирует, что если мы в TeamCity запускаем много builds, то это не выест все ресурсы сервера, а выест только в нашем пуле. И время ожидания builds в нашей очереди будет больше, но это никак не зааффектит команду …, либо dotnet команду.

Кроме того, что агент умеет репортить на сервер информацию о задачах, которые он исполняет, агент также рассказывает серверу об окружении, в котором он ранится. Т. е. о том, какие tools стоят в этот момент в операционной системе. Он репортит это через свои конфигурационные параметры. Там поддерживается плагины, т. е. там вы можете написать плагин, который будет репортить с агента какие-то специфичные и нужные для вас tools, если из коробки это все не доступно.
Эти знания про environment на built agents нужны серверу для того, чтобы запускать задачи только на тех нодах, которые совместимо могут выполнить успешно эту задачу.
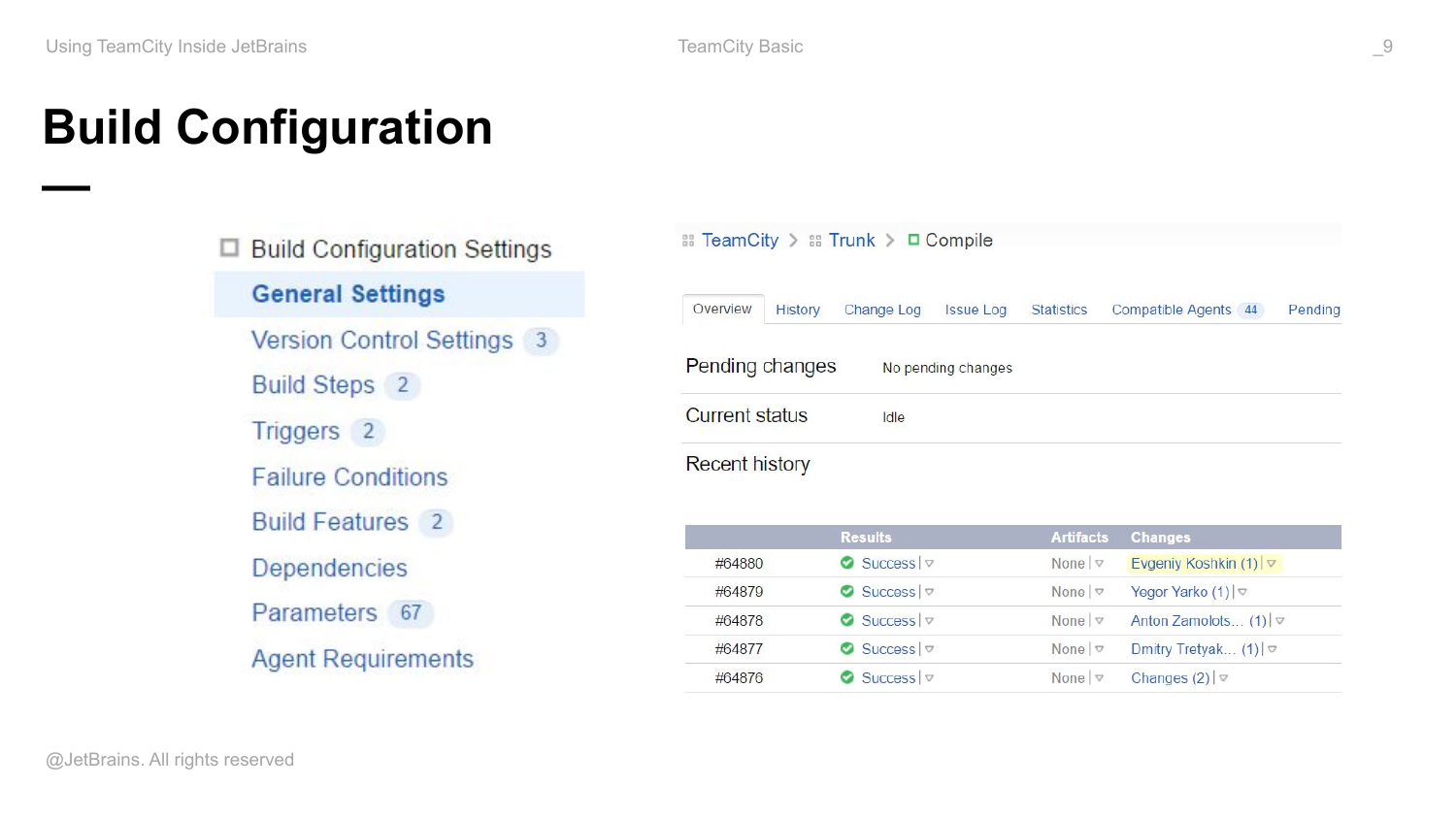
Build configuration – это основная единица конфигурирования TeamCity. По сути, содержит все множество настроек, описывающих ту или иную задачу по сборке. Это, например, список репозиторий, откуда нужно брать исходный код, либо builds скрипты, последовательность шагов, необходимую для сборки критерий запуска задачи, критерий успешности выполнения задачи и требования, например, к агентам, которые эти задачи предоставляют.
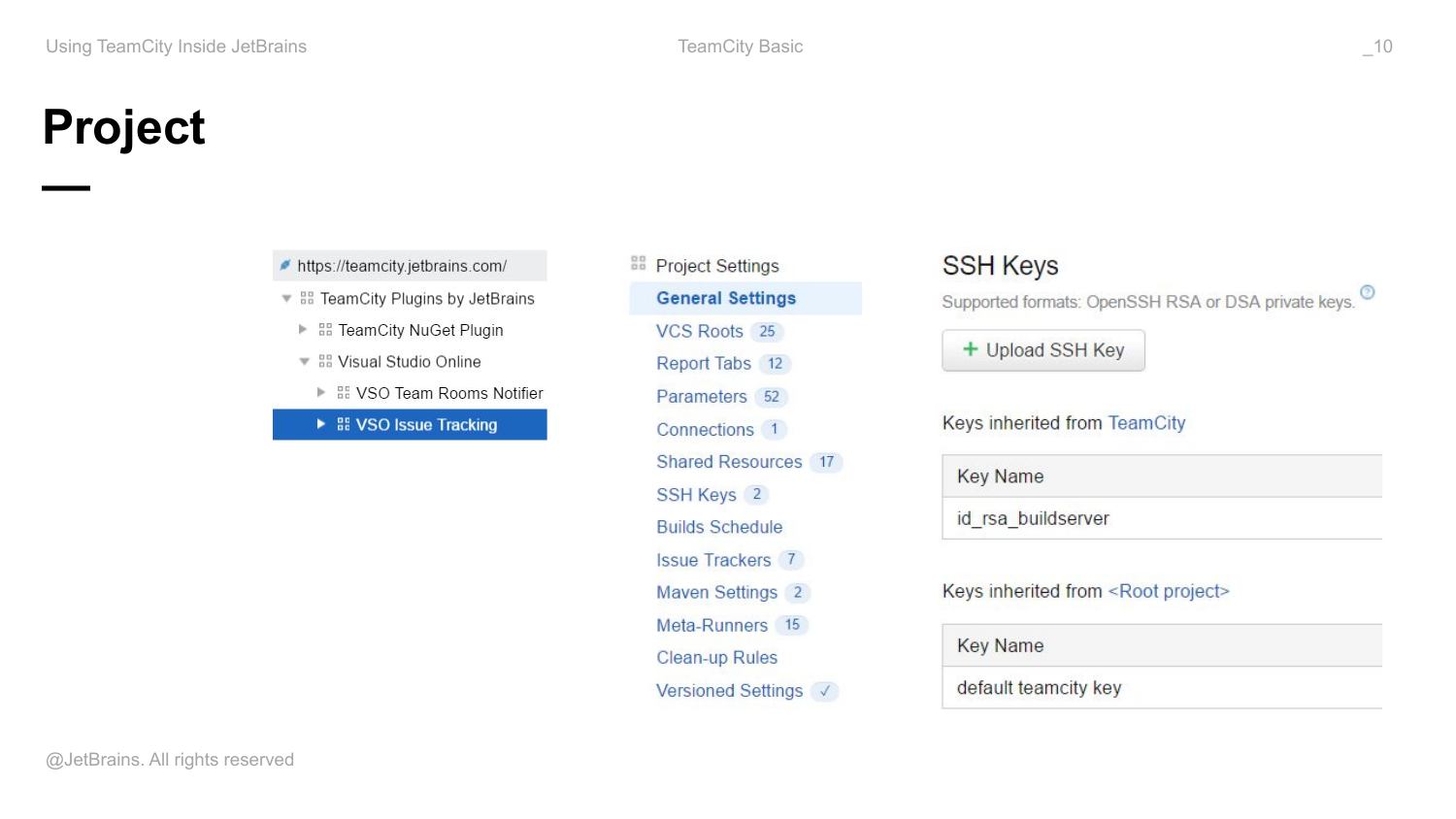
Build configuration объединяется в проекты. Проекты, кроме того, что являются контейнерами для build configuration, они являются контейнерами для других проектов, т. е. проекты могут быть вложенными, они образуют иерархию.
Соответственно, на проектном уровне вы также можете определить некие свойства, которые будут общими для всей конфигурации из этого проекта. Например, включить или выключить сохранение настроек version control, определить SSH ключи, необходимые для работы этих конфигураций, чтобы конфигурации не внутри себя определили эти ключи, а просто использовали их.
Кроме того, проекты образуют иерархию и реализован механизм наследования сущностей внутри проекта, т. е. в каждом проекте вы имеете доступ к сущностям, которые определены в проектах на уровне выше. Таким образом можно осуществлять переиспользование настроек внутри команды или внутри компании.
Еще одно применение проектов – это разграничение прав доступа к тем или иным конфигурациям. К примеру, какие-то конфигурации, связанные с deployment вашего сервиса или приложения в production, можно вынести все эти конфигурации в отдельный проект, дать права на использование и на запуск builds в этом проекте, и на изменение настроек этого проекта только отдельным пользователям. Соответственно, вы сможете ограничить тем самым круг людей, которые могут делать deployment.
Вот этот тренд по перенесению всего в TeamCity на уровень проекта, это глобальный тренд. Он много версий продолжается. И будет продолжаться дальше.
Наша основная задача – сделать так, чтобы при появлении новой команды внутри компании, мы, люди, которые администрируют TeamCity сервер, создали им root’овый проект, назначили кого-то из их команды project admin’ом и потом полностью делегировали ему все дальнейшие задачи по конфигурированию TeamCity. Т. е. мы хотим наши фичи писать так, чтобы при использовании их на уровне проекта, не нужно было делать никаких глобальных админских настроек.
И в частности до 10-ой версии нельзя было, например, авторизовать агентов в свой пул. Даже если у вас был свой собственный пул для своего проекта, у проектного админа не было для этого прав. Нужно было идти к системному админу и просить его авторизовать агенты. В 10-ой версии мы сделали так, что если у вас есть админские права на все проекты, ассоциированные с пулом, то вы сможете сами авторизовать агенты.
Некоторые задачи все еще потребуют от вас взаимодействия с системным админом. Например, все, что связано с пользователями. Т. е. если вы хотите завести нового пользователя в систему, либо сконфигурировать какую-то группу пользователей, для этого пока что придется идти к системному админу. Но мы хотим сделать так в дальнейшем, чтобы люди внутри своих проектов могли создавать свои группы пользователей, т. е. добавлять туда пользователей, авторизовывать и т. д.
Т. е. это такой глобальный тренд, мы постепенно все наши фичи переписываем на такой лад. И это, кстати, один из примеров использования TeamCity внутри JetBrains, потому что, как я уже сказал, этот внутренний instance TeamCity наша команда TeamCity сама администрирует. И поэтому нам отвечать и делать все настройки для всех людей в компании, коих уже больше 500 человек, не хочется. Поэтому мы стараемся делать так, чтобы мы могли делегировать всю эту работу. При этом сделав так, чтобы их настройки никак не аффектили людей из других команд.

Следующая сущность – это зависимости между конфигурациями. Конфигурации могут быть связаны с зависимостями.
Простейший вид зависимости – это артефакт зависимость.
Простейший пример приведу. Если у вас есть приложение, вы используете API какой-то библиотеки в runtime, то, соответственно, чтобы разрешить такую зависимость во время build, вы можете в TeamCity использовать артефакт зависимость между двумя конфигурациями. При этом вы можете использовать последний собранный build библиотеки, т. е. последний успешно собранный, либо какой-то протеганный build. Либо, если вы используете артефакт, то вы можете публиковать артефакты библиотеки в сторонний репозиторий. И потом оттуда его резолвить во время bulid’а приложения.
Второй путь имеет некоторые плюсы. И частности, если вы используете сторонний репозиторий артефактов и не используете напрямую зависимости TeamCity, вы не теряете локальную воспроизводимость builds, что является очень важным свойством. Потому что, если у вас разрешение этой зависимости отражено только в TeamCity в виде зависимости между конфигурациями, локально собрать правильно build вашего приложения на правильную ревизую у вас не получится. Потому что вам нужно будет пойти в TeamCity и понять, какая версия библиотеки в том build использовалась и, соответственно, сделать много ручных действий.
Локальная воспроизводимость builds – это очень важное свойство, которое нужно стараться до последнего не терять. Отказываться от этого, только если есть резкие причины.
Артефакт зависимости вы наверняка используете так или иначе.

Кроме этого есть такая сущность, как шаблон конфигурации. Кроме механизма наследования каких-то свойств через проекты в TeamCity реализован еще один механизм наследования. Это build configuration template.
Стандартным примером является тестирование какого-то приложения на нескольких платформах. В простейшем случае у вас есть конфигурация, которая гоняет тесты. У вас есть какая-то артефакт зависимость на конфигурации, которые собирают артефакты, которые вы тестируете. И есть много build agents с разными машинами. Есть, например, VCS Trigger, который у вас подмонтирован к этой конфигурации. И вы запускаете эти тесты на всех этих машинах. Это рабочий вариант, но идея не очень хорошая.
Почему? Потому что у вас есть тесты, вы таргите несколько платформ, у вас есть одна конфигурация и много build agents, на которых вы запускаетесь.
Общая проблема в том, что у вас в истории builds этой конфигурации будет смешанный статус на разных платформах. Он будет у вас мигать. Т. е. если у вас тесты падают только на Linux, то у вас время от времени build будет то зеленым, то красным. И это плохо. Так делать не стоит. Стоит разделять тесты на разных платформах на разные конфигурации. И чтобы переиспользовать настройки между ними, надо выделять шаблон.

Шаблон, по сути, это тоже конфигурация. Но чем отличается шаблон от конфигурации? Некоторые свойства в нем параметризованы. Т. е. в качестве значений этого свойства используется ссылка на какой-то параметр. Соответственно, создавая новую конфигурацию на базе какого-то шаблона, в дальнейшем, когда у вас появится новая таргет-платформа, вам нужно будет только указать пару параметров и у вас будет новая рабочая конфигурация. А все остальные настройки будут переиспользованы.

И мы дошли до важной сущности – снапшот зависимости. Идея снапшот зависимости достаточно простая. Когда вы говорите, что у вас одна конфигурация зависит по снапшоту от другой конфигурации, то вы говорите, что builds этих двух конфигураций должны собираться консистентно, т. е. относительно одной и той же ревизии, либо снапшота в version control, либо в нескольких репозиториях. Потому что поддерживается даже тот случай, если у вас исходники лежат в одном version control или в одном репозитории, а другие исходники в другом. Т. е. работает даже такой снапшот между разными репозиториями.
Такой тип зависимости дает очень много плюшек. И не все они очевидны.
- Во-первых, с помощью наведения таких зависимостей между конфигурациями вы можете получать в некоторых случаях, в которых раньше не могли, консистентные builds. Т. е. если у вас какое-то приложение или сервис имеют много компонентов, то частенько бывает проблемой сделать какой-то build всей системы, чтобы все его компоненты были консистентные, т. е. собрались относительно какого-то конкретного момента времени и снапшота.
- Использование этой фичи позволяет вам триггерить ваши builds эффективно.
- Кроме этого, версионировать ваши компоненты удобно.
- рименяется при построении build pipeline, т. е. если у вас есть какой-то continuous delivery pipeline, то в TeamCity это все конфигурируется с помощью снапшот зависимости.
- А также это очень помогает, когда вы делаете релизы, потому что есть такая фича, как исторический build, я тоже об этом расскажу.
Теперь давайте разберем по порядку.
Самый простой случай – это консистентность builds.
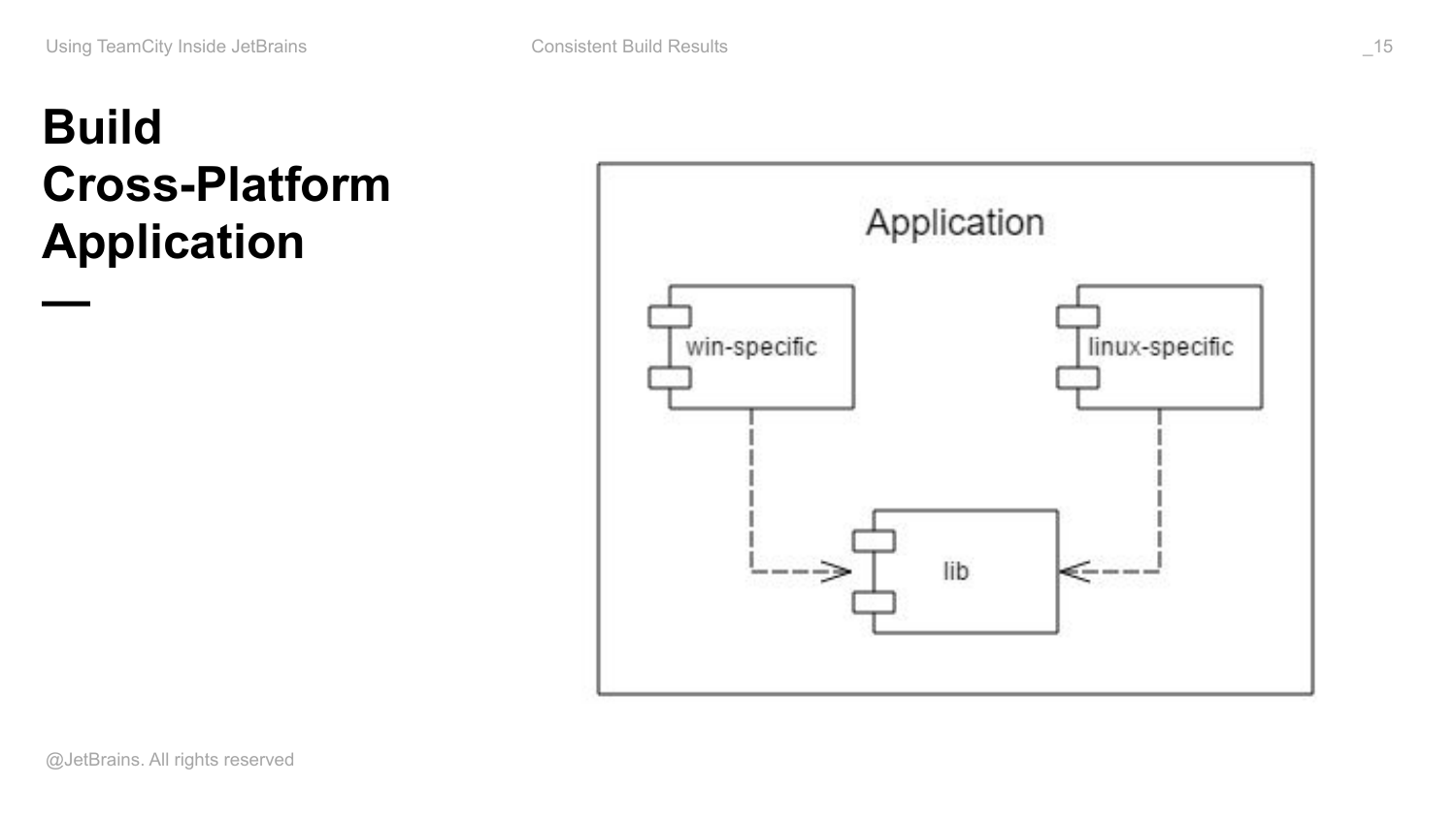
Рассмотрим пример. У нас есть какое-то приложение. Оно кроссплатформенное. Оно содержит какой-то Windows специфичный код, Linux специфичный код и есть какая-то библиотека, которая ранится вне зависимости от платформы.
В runtime Linux и Windows специфичные части используют API этой библиотеки. И приложение содержит в себе все эти компоненты: библиотеку и платформо-зависимые части.
Особенностью такого приложения может являться то, что в рамках одной машины вы такое приложение собрать не можете. Т. е. вы обязательно должны использовать два build agents с Windows и с Linux. И некоторые части системы будут собираться на Windows, некоторые на Linux. В этом случае, когда вы не можете все собрать в рамках одной последовательности шагов, в рамках одного build на одной машине, то у вас здесь могут быть проблемы с консистентностью builds.

Как будет выглядеть простейшая конфигурация? У меня есть build конфигурация, которая компилирует sorts библиотеки и публикует ее как артефакты. Вот эти стрелочки – это артефакт зависимости. У меня есть платформо-зависимые части, которые используют собранные эти артефакты. Они не компилируют код библиотеки сами, они используют это как артефакт. И есть build приложения, который все собирает вместе, строит какой-то пакет и т. д.
Предположим, вы сконфигурировали в TeamCity вот такую схему, т. е. используете только артефакт зависимости. У вас разработчики делают какие-то коммиты, т. е. у вас есть какой-то поток коммитов, соответственно, у вас есть какой-то набор build agents, из которых некоторые совместимы с этими задачами, некоторые с этими и т. д. И может сложится так, что последовательность всех этих builds будет перемешана. Когда вы используете артефакт зависимости, у вас есть последний собранный build, последний успешно собранный build и протеганный build.
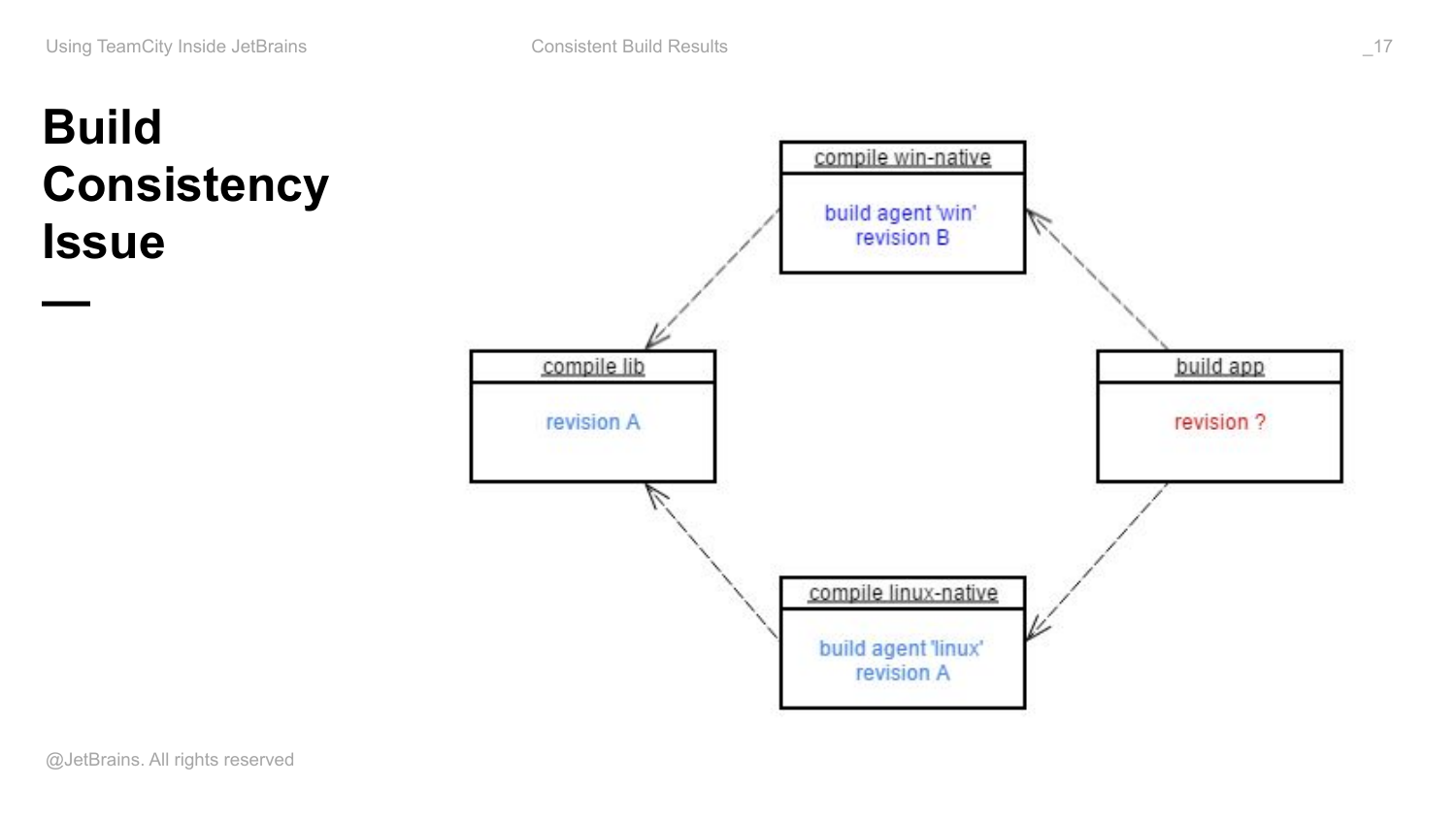
И если у вас было несколько ревизий закоммитчено в репозитории, то какие-то компоненты в конкретный момент времени уже будут собраны относительно A, а какие-то будут собраны относительно ревизии B. И, соответственно, на какой ревизии будет собрано само приложение не очень понятно и какие именно артефакты туда попадут.
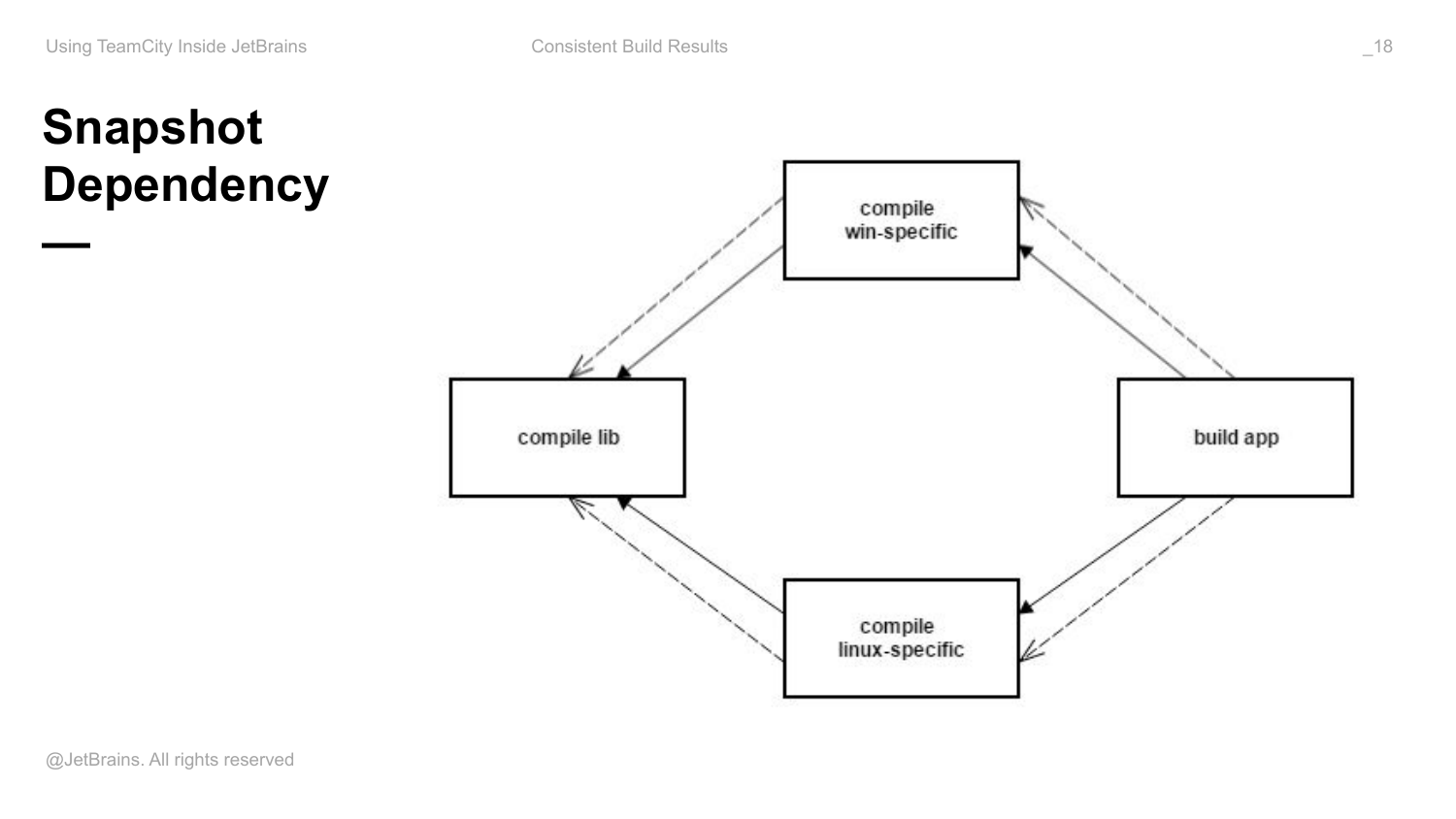
Чтобы избежать этих проблем как раз используются снапшот зависимости. Т. е. вдобавок к артефакт зависимостям, которые говорят о том, что я хочу переиспользовать артефакты из тех builds, вы наводите еще такой же набор эквивалентных снапшот зависимости.
После этого TeamCity вам гарантирует, что builds во всех этих конфигурациях, т. к. они связаны снапшот зависимостями, будут образовывать цепочку builds – build chain. Это такое понятие в TeamCity. И в рамках конкретного build chain вы будете гарантированно иметь консистентное состояние.
Проблема заключается в том, что если вы публикуете свои артефакты и резолвите их из стороннего репозитория, то для вас эта картинка не работает. Потому что TeamCity одновременно знает и про снапшоты, и про артефакт зависимости. И когда он резолвит конкретную версию артефакта, он обращает внимание на снапшот и берет именно правильный артефакт. Если все это публикуете в artifactory, то вы все равно берете либо снапшот, либо какую-то конкретную версию.
Это тот случай, когда выгодно использовать артефакт зависимости внутри TeamCity и не публиковать в сторонний репозиторий артефактов, либо, может быть, дублировать эту публикацию.
На самом деле снапшот зависимость, артефакт зависимость, она не добавляет никакой семантики. TeamCity все равно, что вы там собираете, например, сборка чего-то, выкладка чего-то и т. д. Если вам важно деплоить консистентно несколько компонентов системы, то все тоже самое. Представьте, что у вас здесь не сборка артефактов, а выкладка какого-то набора микро-сервисов на staging или на production. Тогда у вас есть root’овая конфигурация, которая называется deploy все. И она будет зависеть по снапшотам от всех остальных конфигураций. И с помощью этого root’овой ноды вы будете иметь возможность делать все консистентно, все за один раз. И если выкладка одного из компонентов сломалась, то вы сможете ее передеплоить именно снова в консистентное состояние, а не последнее собранное.

Следующий аспект – это как снапшот зависимости позволяет триггерить ваши builds эффективно.

Обычно подход здесь такой. Сначала у меня должна собраться библиотека. Когда она собрана, должен собраться, например, вот этот компонент. Когда он собран, должно собраться само приложение. И обычно это устанавливается как trigger after. Т. е. триггерится, когда build другой конфигурации завершен.
Если у вас есть такой ромбик, то вы получите два build вашего приложения и ни в одном из них не будет нормальной версии артефактов. Чтобы избежать этой ситуации, вы добавляете снапшот зависимости.

И TeamCity предлагает альтернативный подход к триггерингу. Вы вообще не должны думать о том, как зависимость будет исполняться, вы должны думать о результате, т. е. что вы хотите получить. Вы хотите получить build вашего приложения. Там есть какие-то изменения в этом графе. Graf может быть огромным, TeamCity собирается ровно также. У него огромное количество плагинов и огромные графы слева.
Но мы хотим собрать просто build TeamCity. И все что мы делаем, это вешаем только один триггер на root’овую конфигурацию и выставляем там магическую галочку «триггерить build на изменение в снапшот зависимости», которая по умолчанию выключена. И вы вообще дальше ни о чем не думаете. TeamCity за вас определяет в каждый конкретный момент времени builds, какие компоненты должны быть собраны и builds, какие компоненты должны быть пересобраны, потому что одна из зависимостей, например, изменилась.
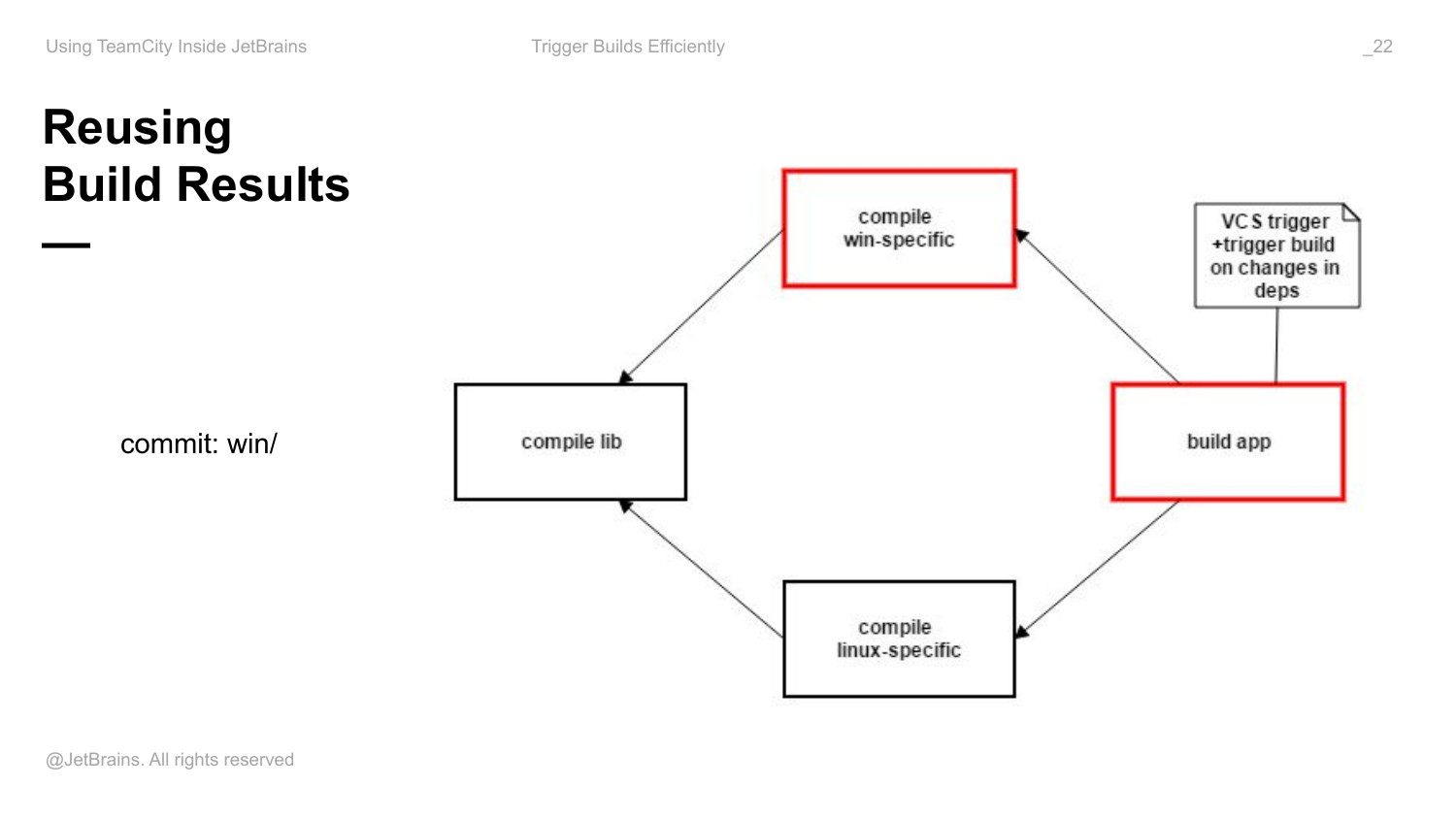
Если в какой-то момент у меня изменился Windows специфичный код, у меня есть триггер только вот здесь, но TeamCity поймет, что весь build chain хочется запускать при таком изменении, значит, этот build будет пересобран. У вас появится новый артефакт этой версии, остальные части системы этими изменениями не были зааффекчены и пересобраны не будут. Так как у вас изменилось один из компонентов приложений, build самого приложения тоже будет пересобран. При этом эти артефакты будут переиспользованы, вы сохраните себе время на build agents, т. е. эти builds вообще запущены не будут.

И наличие этой фичи позволяет нам экономить огромное количество build time у нас внутри.
Это старенький скриншот. Когда build time, который занимал всех агентов на сервере, был 3 558 часов. И каждый день мы на тот момент 870 + 509 часов экономили за счет наличия снапшот зависимости и переиспользования артефактов внутри builds.

Это приводит к тому, что вам нужно покупать меньше build agents, потому что меньшее количество build agents ваши нужны обслуживает, потому что builds переиспользуются.
Почему мы эту фичу не сделали приватной? Потому что мы так не делаем. Все, что мы делаем, мы делаем для себя и для пользователей в том числе.
Manage application components version
Следующая фича, которая доступна с помощью снапшот зависимости – это управление версиями приложения, версиями компонент или микросервисов внутри большого сервиса.

Важным свойством снапшот зависимости и цепочки builds является то, что не только артефакты, которые доступны в рамках этого build chain, составляют общий контекст, но и параметры всех builds составляют общий контекст build chain.
И в рамках этого контекста у вас есть возможность из build одной конфигурации получать доступ к значениям параметров другой конфигурации.
Например, если у вас есть конфигурация A, в котором есть какой-то параметр, у которого значение foo в рамках конкретного build. Если build из конфигурации B в одном chain, т. е. консистентный с этим build, то вы можете в качестве значения параметра B использовать значение, например, вот этого параметра.
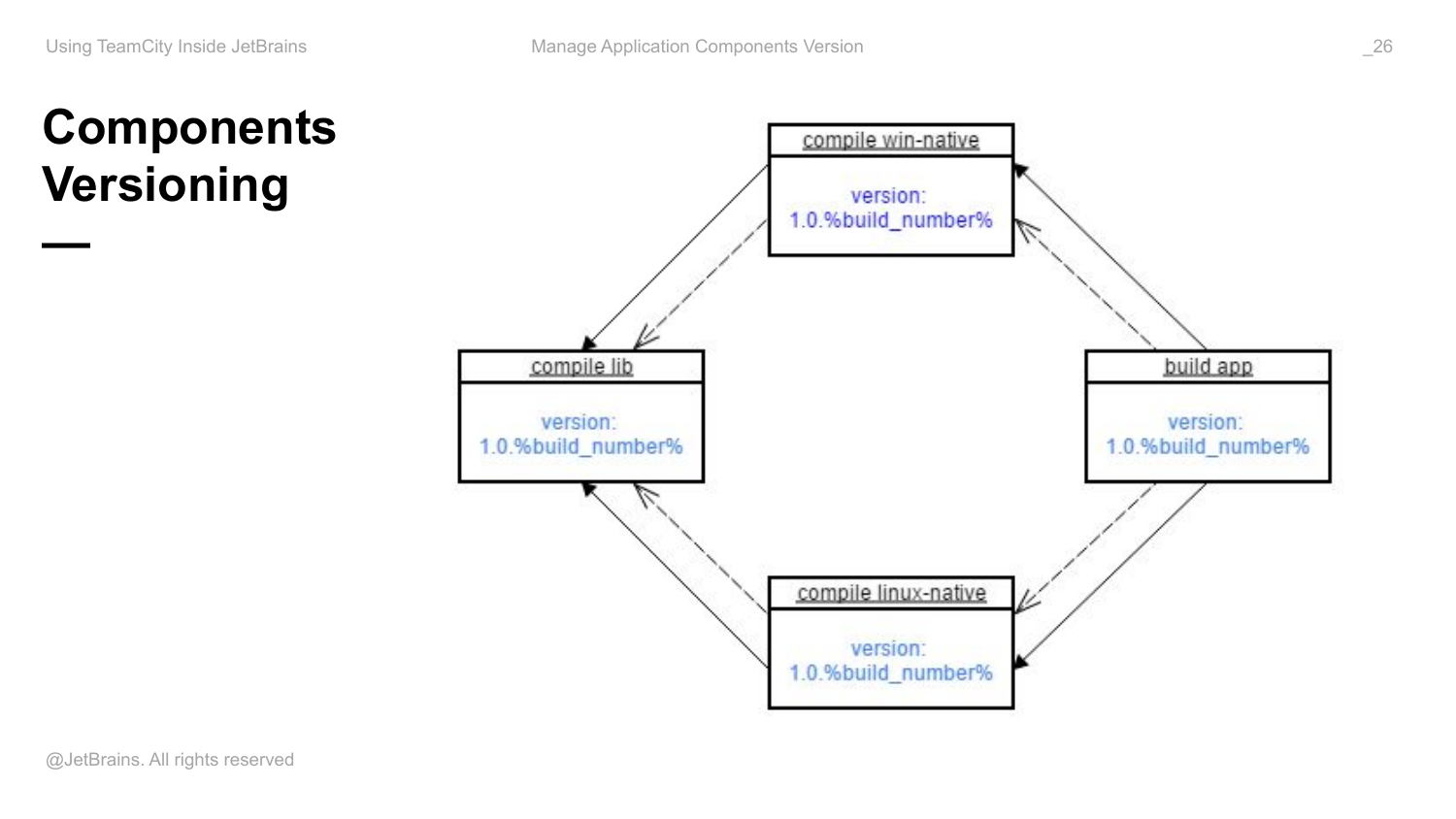
Что это вам дает? Обычно, когда вы говорите о версионировании каких-то компонентов, либо сервисов, то у вас всегда есть какой-то шаблон, в соответствие с которым версия присваивается. И у вас есть какая-то статическая часть, которая обычно захардкожена на уровне build конфигурации. И есть какая-то динамическая часть, которая меняется от build к build. Вот этот синтаксис – процент что-то процент – это ссылка назначения какого-то параметра в TeamCity.
Соответственно, первое, что приходит на ум, если у меня много компонентная система и всем этим компонентам нужно присваивать какую-то версию, это на уровне конфигурации захардкодить такой шаблон. Но тогда у меня будет дублирование. У меня будет 4 места в системе, где у меня этот шаблон будет захардкожен.
Я могу, конечно, наследовать все от какого-то шаблона. Этот шаблон определить на уровне проекта и тоже переиспользовать. Но будет проблема, что если у меня эти builds не исполняются консистентно, т. е. если нет снапшот зависимости, то эта динамическая часть будет не обязательно одинаковой. И получается, что в пакет вашего приложения, возможно, будут попадать компоненты, которые будут иметь разный build number. Потому что build number – это локальный счетчик в рамках каждой конфигурации. И он разный в каждой конфигурации. Если здесь 10 builds прошли, а здесь 11, то здесь будет 11 build number, а здесь 10. И общей версии для всех компонентов не будет.

Как сделать правильно? Я уже сказал, что в рамках build chain у нас есть общий контекст параметров и мы можем ссылаться из параметра одного build на параметр build из другой конфигурации. Мы это можем делать с помощью вот такого синтаксиса.
Расшифровываю. Здесь сказано dependency с такой-то ID и имя property, которую я хочу использовать. Такую подстановку я могу использовать в качестве значения своего параметра. Таким образом, я могу в самой первой исполняемой конфигурации определить параметр version, который будет, например, 1.0.build number, т. е. build number в рамках этой конфигурации. Во всех остальных конфигурациях в качестве версии я буду использовать ссылку на параметр из build из этой конфигурации. Таким образом шаблон у нас определен единственным образом, и мы гарантированно получаем во всех зависимых builds одно и тоже значение версии.
И это все работает не только в read only режиме, т. е. мы не только ссылаться можем на значение параметра и зависимости, мы можем и форсировано выставлять им какие-то значения. Т. е. работает синтаксис revers всем обратным зависимостям, ID которых удовлетворяют какому-то параметру. Т. е. это либо явно указанный ID, либо звездочка. И можем выставить параметр с таким-то именем в какое-то конкретное значение.
Это может быть полезно, когда у вас есть в скриптах, которые собирают каждый из компонентов, например, какой-то параметр. Например, isRelease, который во время компиляции транслируется в код. И таким образом вы потом включаете и выключаете exception, либо еще там что-то делаете. И вы пробрасываете это не через config, а прямо в код это делаете. И, соответственно, у вас зависимостей может быть много и дефолтные значения isRelease в каждой из зависимости могут быть разные.
Но в какой-то момент вы хотите собрать build, чтобы гарантировано все компоненты получили правильное значение этого флажка. И вы стартуете свой build в этой конфигурации, в нашем случае – это build приложения, и говорите «всем зависимостям выставить isRelease true». И вы гарантированно получите правильное значение этого флажка во всех зависимостях. Переиспользованы такие builds не будут, потому что прошлые builds были собраны с другими значениями. У вас будут гарантировано пересобраны все ваши зависимости, но с другой стороны вы получите то, что вы хотите.

Следующий аспект – это немножко про continues delivery.

Представьте, что у вас есть какая-то конфигурация, которая собирает дистрибутив вашего приложения, либо это пакет, который вы в дальнейшем выкладываете на staging, production.
У вас есть какие-то acceptance tests. У вас есть процедура deploy on staging. Она оформлена как build конфигурация. И есть deploy to production.
Обычно, когда такой pipeline конфигурируется, хочется иметь баланс между автоматизацией и ручным управлением. Т. е. какие-то части этого pipeline хочется автоматически запускать, а где-то хочется все-таки ручной привод иметь, т. е. какой-то контроль иметь.
Соответственно, как здесь снапшот зависимость помогает? К примеру, я хочу, чтобы на каждый коммит version control мое приложение собиралось, прогонялись acceptance tests и выкладывалось на staging, но при этом, чтобы в production выкладывалось только то, что я сказал явно руками. Как это можно при помощи снапшот зависимости реализовать?
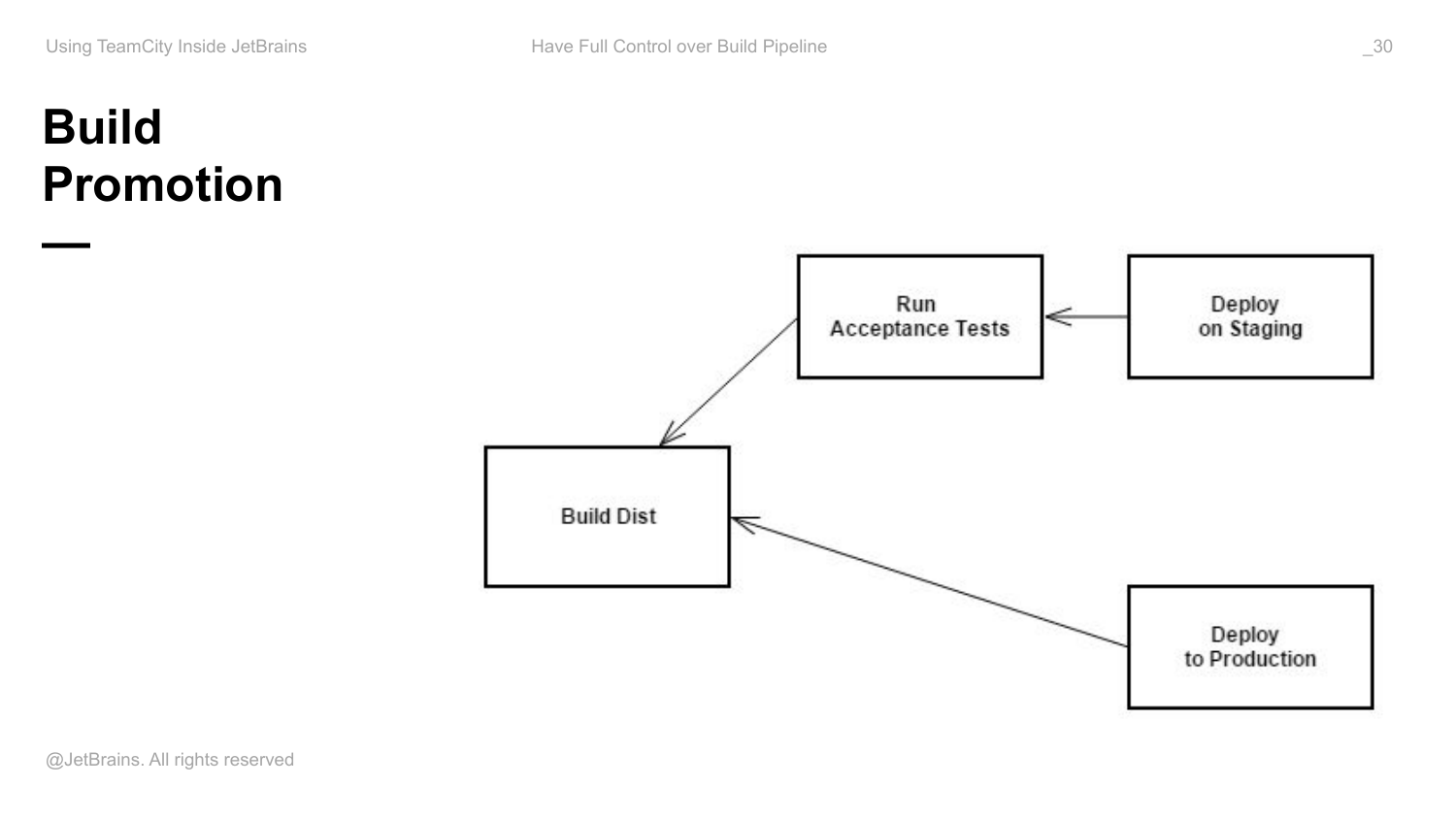
Во-первых, как показано на схеме, я объединяю мои конфигурации снапшот зависимостями, т. е. говорю, что deploy production зависит от build dist. Deploy on staging зависит от acceptance tests. А тесты зависят от build dist, потому что именно этот артефакт они будут в дальнейшем тестировать.
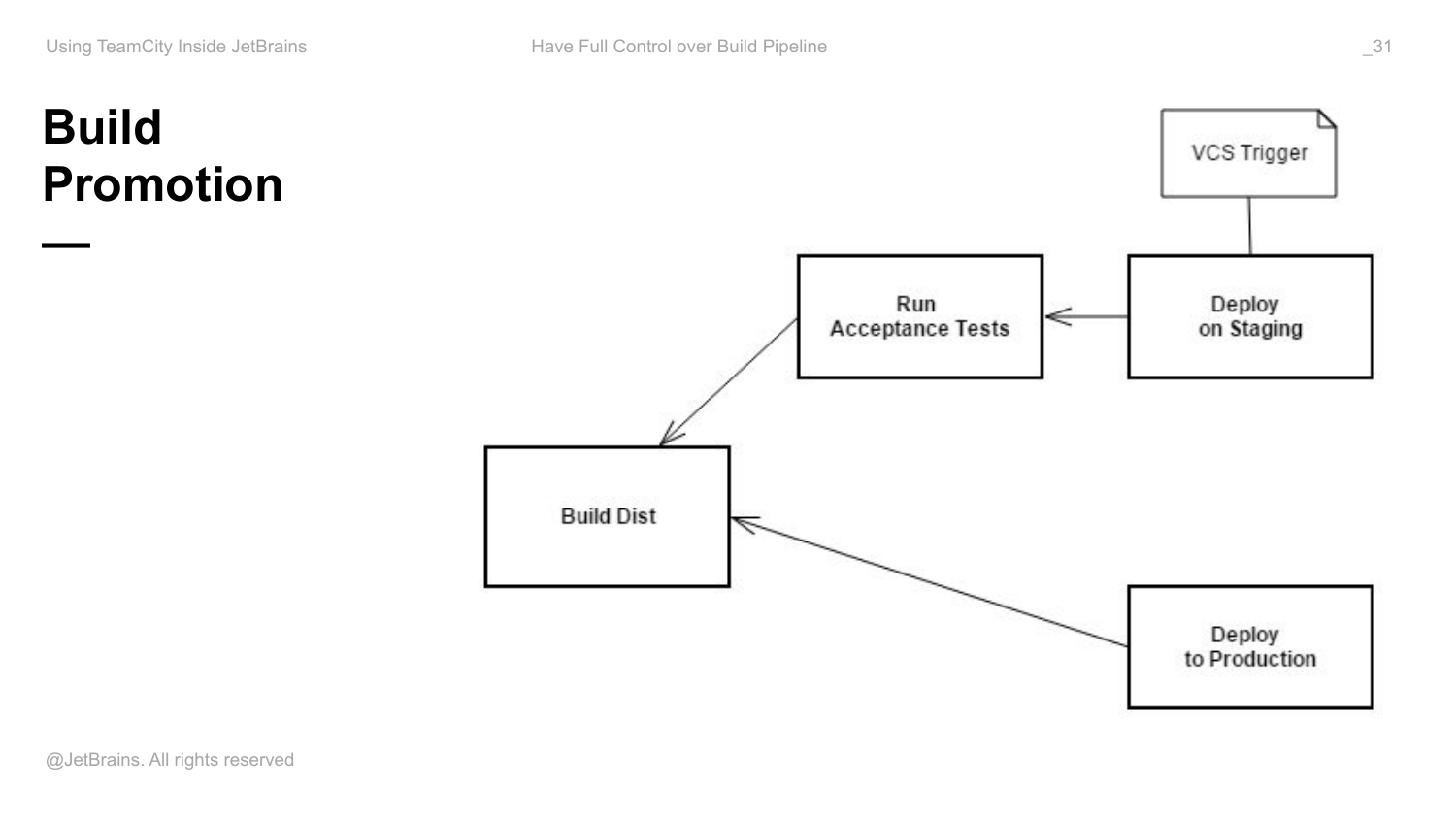
Дальше я добавляю VCS Trigger сюда, т. е. я хочу выкладывать на staging при любом коммите. Сюда я никакой триггер не добавляю, потому что я хочу ручное управление.

Как реализовать это ручное управление? Есть такая фича, которая называется build promotion. Promote – это действия пользователя, которые доступны для конкретного build в этой конфигурации, если есть входящие снапшот зависимости в эту конфигурацию, которые позволяют мне конкретный build дальше протолкнуть по моему pipeline в том направлении, в котором я хочу.
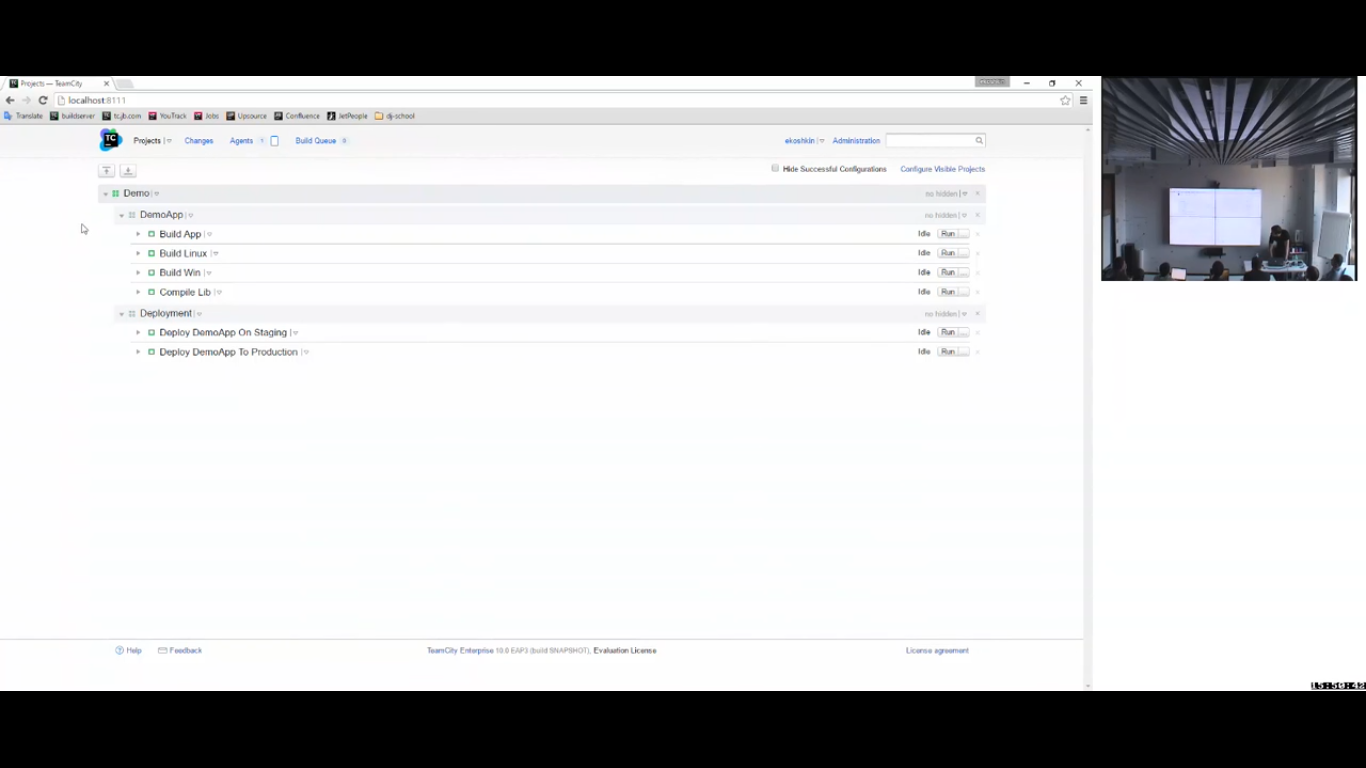
Вот реализована моя схема. Я залогинен под пользователем ekoshkin, который является девелопером. Представьте, что у меня есть команда разработчиков, которая девелопит какое-то приложение, есть команда админов, которая все это дело деплоит.

В моем случае моя root’овая конфигурация – это build app. Есть какой-то build, который был собран. И я хочу его задеплоить. У него есть какие-то зависимости.
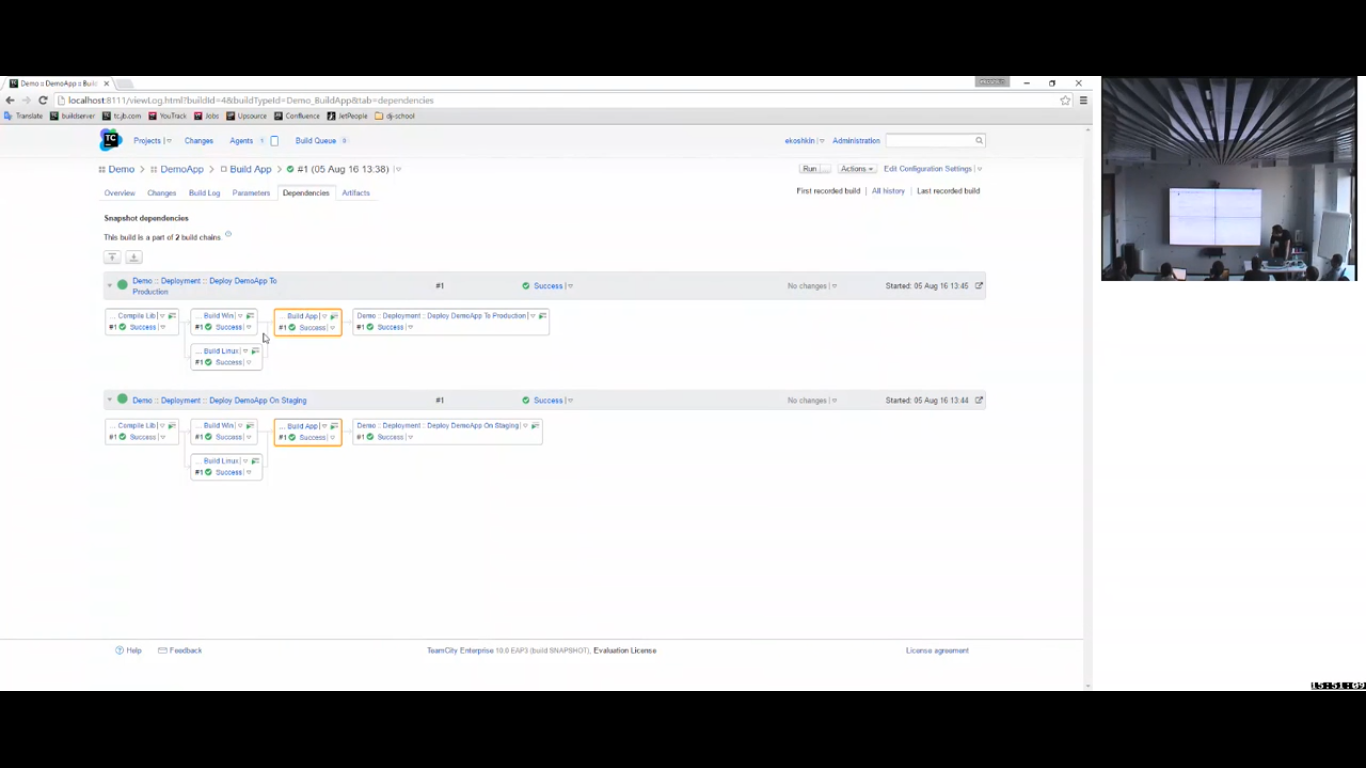
Здесь как раз реализован тот самый ромбик, о котором мы говорили. И я хочу результат этого build куда-то задеплоить.
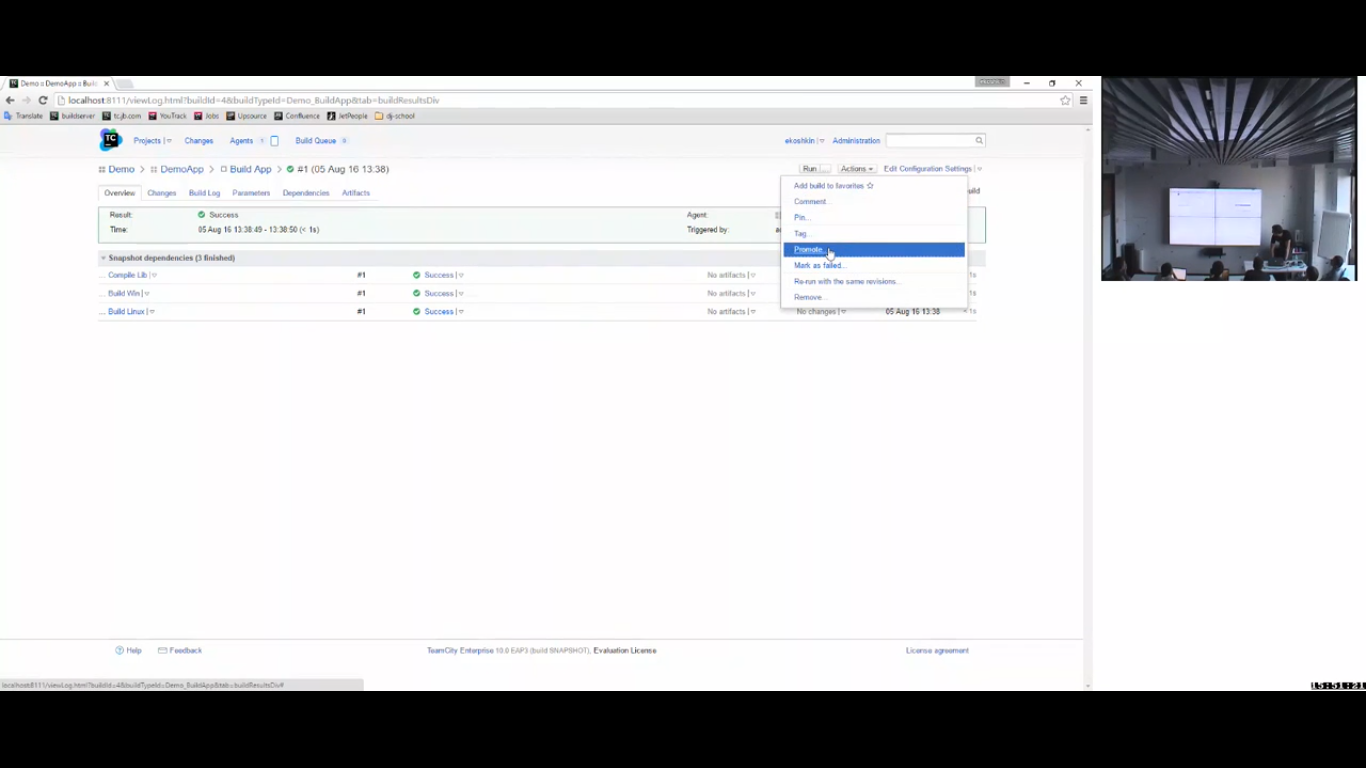
Я иду в action. Это я делаю для конкретного build.

Я запускаю «promote». Мне показывается список входящих снапшот зависимостей, т. е. список конфигурации, которая зависит от меня по снапшоту. И позволяет мне запромоутить build в одну из них.
Соответственно, вот у меня есть две конфигурации, которые деплоят мое приложение в production и на staging. И я могу запустить этот build в одной из этих конфигураций, и эта конфигурация будет использовать именно вот эту версию артефакта, для которого я вызываю «promote». Это снова делается за счет снапшот зависимости, потому что они связаны снапшот зависимостями.
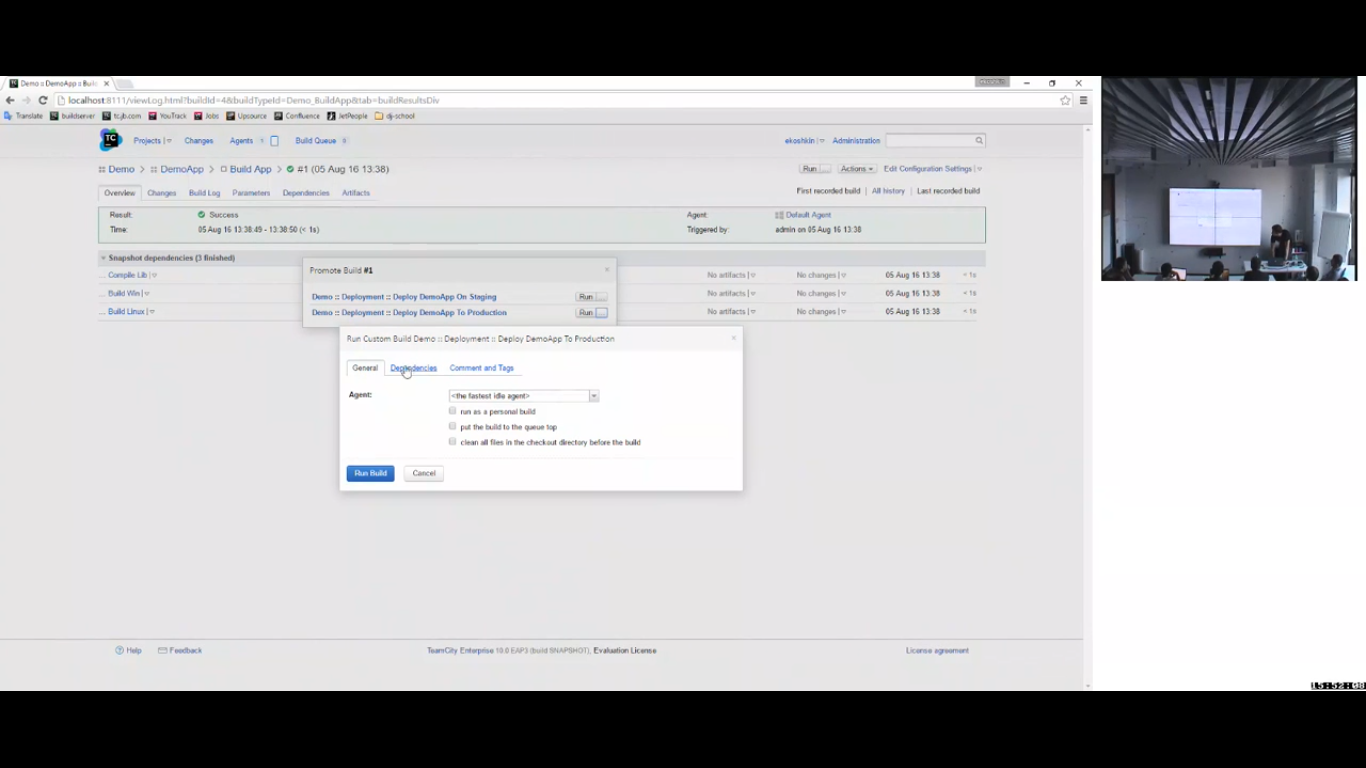
При запуске build я могу что-то кастомизировать, например, т. е. указать какие-то параметры, необходимые для процедуры выкладки и т. д. И после этого build пойдет.
Я вызываю «promote». Запустился build в этой конфигурации в production. Соответственно, у него появился статус. Я могу в этой конфигурации смотреть статус и деплой. В моем случае – это положительные статусы.
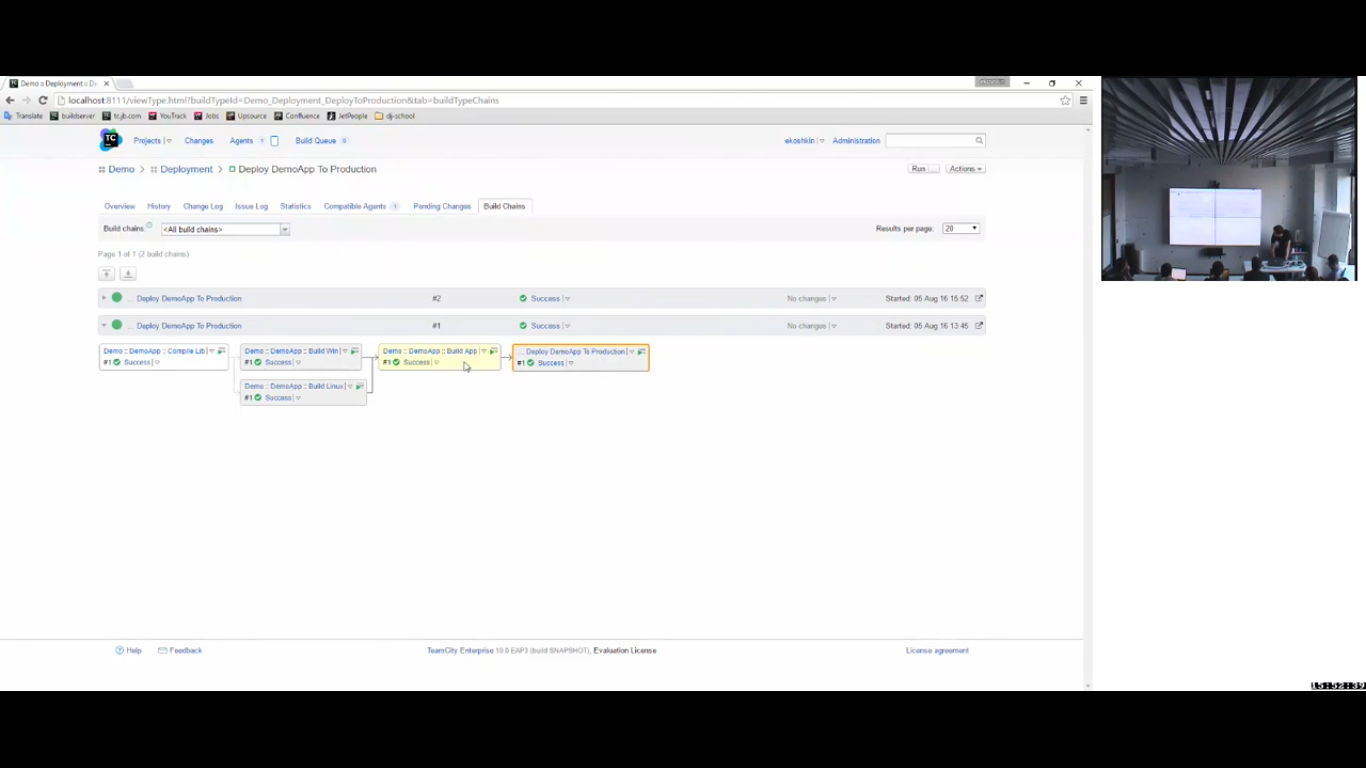
И самое главное, что я потом смогу посмотреть все цепочки build, которые приводили к деплою. И могу видеть все версии, которые в этот момент деплоились, и все версии всех компонентов, которые деплоились, что достаточно полезно.
В чем выгода такого setup?
Я являюсь разработчиком в этом примере и являюсь админом проекта Demoapp, т. е. все, что связано с разработкой моего приложения, я могу как угодно менять. У меня есть права на редактирование чего угодно в приложении. Но при этом, что касается ситуации по deployment, прав у меня нет. Все конфигурации, связанные с deployment, они сосредоточены в отдельном проекте. И на уровне пользовательской группы, в которую я вхожу, у меня эти права забрали. Все, что я могу делать, это только запускать builds, промоутить конкретные артефакты в них.
Таким образом разделена ответственность. С одной стороны, люди, которые являются частью devops команды и являются администраторами в проекте deployment, они могут как угодно менять процедуру сборки. У них, наверное, будет свой пул агентов, ассоциированный с deployment. Там будут какие-то секреты, необходимые для deployment. Например, SSH ключи для доступа к production серверам и т. д. У меня, как у разработчика, доступа к этому не будет. И мой протокол общения с ними – это promote, т. е. promote конкретной версии артефакта, который должен быть выложен. У меня остается право решать, какая версия будет выложена, а у них остается возможность гарантировать, что процедура выкладки будет правильной, безопасной, ее никто менять не будет.
Promote – это ручное действие?
Да, promote – это ручное действие. Если вы хотите в production выкладывать все автоматом, то вы в эту конфигурацию повесьте VCS trigger или любой триггер.
Как управлять переключением между релизом на всех и релизом на первый миллион?
Вы будете делать это через параметр. Скорее всего, у вас будет две конфигурации: деплой на первый миллион, деплой на всех. У них будет общий шаблон, т. е. процедура сборки будет одна и та же, у них будет один параметр. Это на первый миллион, либо не на первый миллион.
Как быть, если хочется выкатывать релиз на первый миллион не в TeamCity, а в другом месте?
Значит что этот коммит/релиз особенный. Коммит/релиз особенный – это значит, что ты какой-то тег выставишь. Альтернативно, чтобы тегов не выставлять я предлагаю такую схему. В конкретном build своего сервиса, который был собран относительно конкретного этого коммита, который никак специально не протегованный, но ты, как разработчик, знаешь, что именно его надо выкладывать.
Как сделать все это для всего, кроме каких-то отдельных коммитов?
Я думаю, что это на уровне веток надо делать. И тогда у этой конфигурации будет несколько историй для разных веток. И будет, что такие фиксы – опасны. И будет мастер. Мастер будет постоянно выкатываться. А если будет что-то такое опасное, то будет отдельная процедура, которая смотрит на отдельную ветку и не мержется это в мастер, пока ты не выкатил и не посмотрел, как это работает. Потому что мне кажется, что в мастере такой коммит не очень хорошо иметь. Нужна процедура, которая смотрит не только на мастер, а еще на какую-то соседнюю ветку, например.
Promote может откатывать?
Promote – это проталкивание по какому-то flow, по направлению в графе задач. Это нужно будет реализовать самому, потому что обратная задача отката – это уже другой вопрос.
Можно ли сделать downgrade при деплое?
Если сама процедура выкатки поддерживает downgrade, тогда да, но это не всегда, потому что у тебя данные могут осесть, если это не в контейнере и есть какой-то state, который сохраняется. И тогда будет проблема. Но это семантика уже конкретного приложения. Такие вещи есть. Например, в TeamCity сделано так. Я говорил о том, что есть мажорный, минорный релизы, есть bugfix апдейты. И у нас есть договоренность, что конвертация данных происходит в мажорных и минорных релизах, т. е. там 10 и 10.1. А когда bagfix апдейты выпускаем, у нас договоренность, что мы поддерживаем downgrade в рамках bugfix апдейтов. Просто мы не пишем конвертеров. Мы пишем, когда все полегло у всех.
Соответственно, если какие-то конверторы мы хотим сделать, мы это восполним в следующем большом релизе, либо как-то обходимся без них, на уровне кода как-то решаем это. У нас так сделано. Но когда вы сервис делаете, то там, по-моему, больше пространств для маневра, чем, когда продукт делаете. Это, наверное, на уровне инфраструктуры делается.

Я еще покажу настройки триггера, на них у меня прав хватает. Соответственно, у меня есть триггер VCS. И стоит галочка «trigger a build on changes in snapshot dependencies», которые не дефолтные.

И куча rules. Add trigger rule и тут есть include, exclude rule по VCS user name, по VCS root, по comment regexp и по file wildcard даже есть. Соответственно, можно инклюдить, эксклюдить и rules может быть несколько. Они могут быть вложенными.

Теперь про исторические builds. Это фича очень полезная, когда вы делаете релизы.
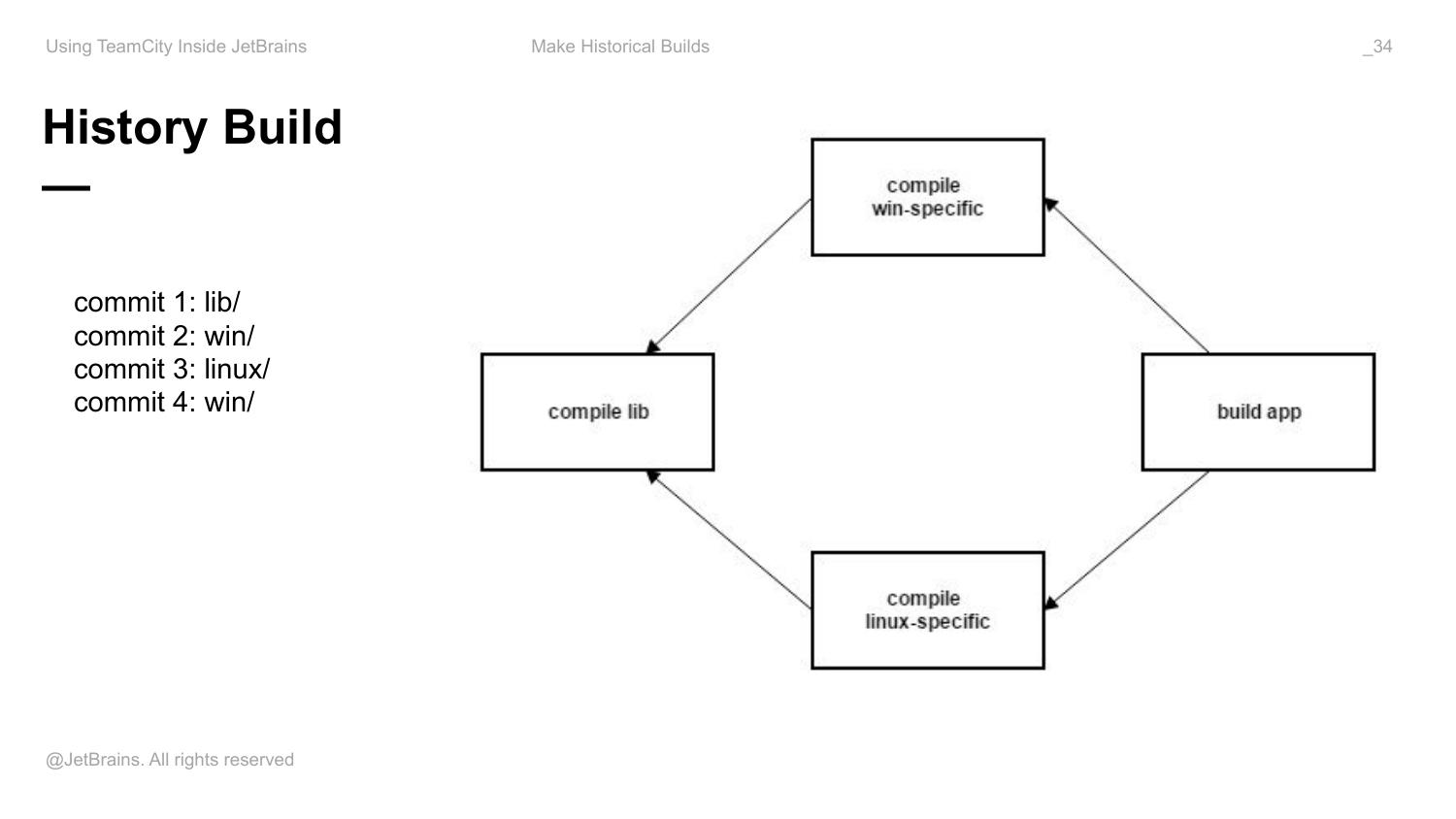
Опять есть наш ромбик, который объединен снапшот зависимостями. И девелоперы делают какие-то коммиты. Пришел коммит в библиотеку, пару коммитов Windows код и какой-то коммит Linux код. И это все происходит перед релизом. Нам надо релизиться как раз, какие-то последние фиксы приходят. У нас есть VCS trigger, поэтому build постоянно запускается.

Собрали какой-то build. Оказалось, что он содержит баг, т. е. там либо тесты какие-то упали, которые не проверили на уровне конкретного компонента, либо тестировщики сказали, что есть проблема.
И на данный момент у нас последний build Linux компонент собран на последнюю ревизию, которая туда пришла. Это коммит 3. В Windows попали 2 коммита и в библиотеку последний коммит попал. И оказалось, что последний коммит 4 принес баг. И если нам собраться вот на это состояние, то все будет хорошо.
Но проблема заключается в том, что на данный момент, у нас в истории вот такой артефакт правильно вообще никогда не собирался, т. е. он собирался на предыдущую ревизию и на последнюю. И он как раз содержит ошибку, а все остальные на правильную ревизию уже собраны.
И хочется так build запустить по-быстрому самого приложения, чтобы как можно быстрее получить новый релизный build, при этому пересобрать вот этот, а эти не трогать.
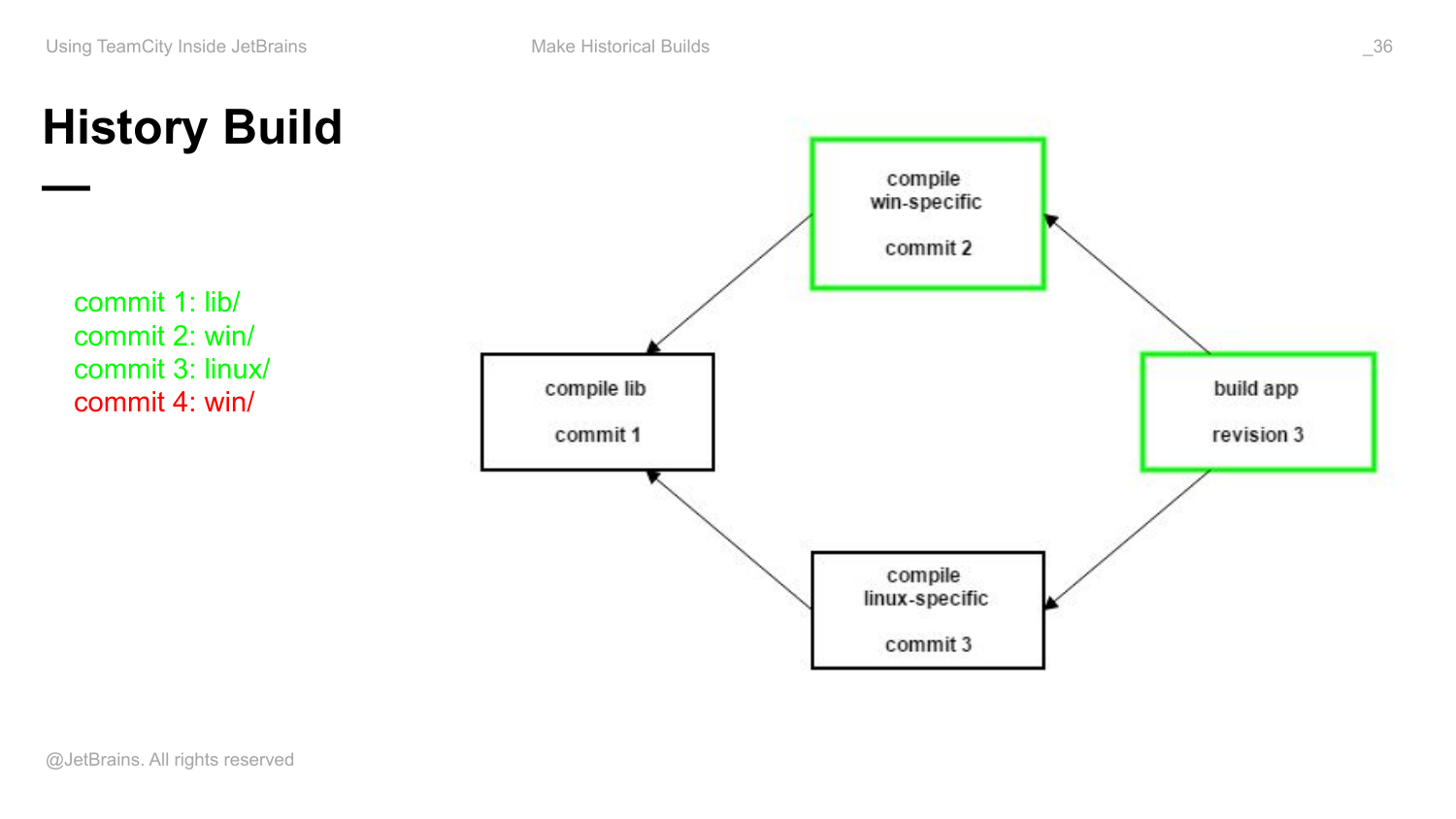
Вот так можно сделать с помощью фичи history build. Вы заходите run custom build этой конфигурации, там у вас будет список changes. И так как у вас все конфигурации объединены снапшот зависимостями, список changes будет списком снапшотов относительно любого, из которых вы можете консистентно собрать все ваше приложение. Вы в нем выберете предыдущую ревизию и запустите build этого приложения на вот эту предыдущую ревизию. Все дальше сделается автоматом, т. е. TeamCity поймет, что относительно этого снапшота вот этот артефакт уже подходящий есть, такого еще собранного не было. Соответственно, он его соберет. И если по каким-то причинам на эту ревизии по каким-то другим chains build был собран, то он тоже будет переиспользован. Возьмет нужный артефакт, пересоберет само приложение, потому что одна из зависимостей изменилась. И используя минимальное количество времени на build agents, т. е. ускоряя feedback системы, вы получаете новый релизный build.
Такая фича появилась. Притом, что очередь полна builds и я показывал, что среднее ожидание build в очереди у нас все еще 1 час, соответственно, хочется как-то быстро релизный build собрать. И наличие такого исторического build позволяет это сделать.
Если вы все публикуете в сторонний репозиторий артефактов, вам придется делать много ручной работы, т. е. для каждого из этих build вам придется вычислить, какая координата этого артефакта была опубликована, какой артефакт был опубликован в каждом из build. И нужно будет сделать какие-то действия вручную, скорее всего.
Как быть, если коммит с багой собержит сторонние зависимости?
Придется написать скрипт. Его можно будет здесь, наверное, запускать. У нас так сделано. У нас есть артефакт скрипт, который девелопер у себя на машине запускает, где именно сторонние библиотеки все резолвятся правильной версии. А дальше все собирается в рамках одной ревизии. У нас большую часть проекта можно собрать на одной машине, но весь TeamCity на одной машине собрать нельзя.
Почему я рисую более заметной стрелочкой снапшот зависимость?
Потому что это более сильная зависимость, чем артефакт зависимость. Артефакт зависимость – это бинарная, по сути, зависимость. Т. е. зависимость от какой-то версии API. А снапшот зависимость – это, по сути, все эти компоненты, которые могут даже лежат в разных репозиториях, но как будто это просто одна рабочая копия. И эту рабочую копию вы можете себе зачекаутить и все собрать. Хотя, может быть, для этого потребуется несколько нод, несколько машин: Mac, Linux, Windows. Т. е. идея такая за всем этим стоит.
Это мы говорили про фичу – исторический build. Такой build, т. к. он последним будет в этой конфигурации, но собран на не последнюю ревизую, он будет помечен как исторический. И будет сказано, что на самом деле эта ревизия более старая по какой-то причине и поэтому называется исторический build.
Основные вещи, например, jobs, slave в Bamboo – все похоже. Я много рассказывал про снапшот зависимости, потому что это действительно такая штука экзотическая. Она только есть в TeamCity. И все эти фичи, которые какими-то костылями решаются обычно, полезны. Как я показал про promotion, но на самом деле у тебя может быть и один компонент, а ручной привод для continuous delivery тоже реализуется с помощью снапшот зависимости, потому что тебе снова нужно что-то консистентное выкладывать.
На слайде 1 снапшот зависимость или 4?
4 снапшота зависимости. И самое главное, что с этими коммитами может быть не последовательная история изменения в какой-то ветке. Это может быть коммиты в разных репозиториях. Потому что TeamCity является таким meta version control. И он делает снапшоты cross-repository. Поэтому вот эта ревизия может прийти в один репозиторий, эти две в другой, эта в третий. И все равно это будет несколько снапшотов.
У меня не самая корневая сломалась, у меня сломалась средняя какая-то зависимость. Но само приложение было зааффечено. TeamCity по времени их синхронизирует. Если это ревизии из одной репозитории, там есть отношение chain partners, потому что направленный граф в Git, но если это между репозиториями, то это TeamCity хранит уже сам. Т. е. он просто знает timestamp каждого коммита и строит свои снапшоты сам, и как-то менеджит.

