
Быть новичком — значит исследовать новые горизонты программирования, шагая в неизвестность, надеясь что где-то там будет лучше.
Думаю что вы согласитесь, зачастую достаточно увлекательно начинать работу над проектом с новой технологией. Проблемы, с которыми вы сталкиваетесь и пытаетесь решить, не всегда просты, хотя являются неотъемлемой частью вашего пути становления гуру.
Так о чём это я. Сегодня я здесь чтобы поделится с вами своим первым опытом создания системы из Hedless CMS, API и блога. В связи с отсутствием достаточного количества подобного материала, особенно русскоязычного, я надеюсь что эта статья поможет вам создать подобную систему самостоятельно, избегая ошибок, которые я совершал.
Я расскажу, как я по блокам собрал систему и что из этого получилось. Я не буду объяснять вводную информацию, но оставлю ссылки на ресурсы, где вы можете узнать больше. Иногда сложно найти русскоязычный источник, но я постараюсь. Кроме того, вы можете посмотреть доклад (на английском) или же прочитать эту статью (ближе всего по смыслу), если не уверены в преимуществах микросервисов над монолитной архитектурой.
Исходный код проекта вместе с пошаговым руководством по пользовательскому интерфейсу и API (рекомендую не читать, пока не закончите статью):
Преамбула
Время от времени, когда я исследую сеть в поисках интересного материала или технологий, невиданных прежде, я могу наткнуться на что-то настолько захватывающее, что из-за лезущих в голову мыслей уснуть ночью становится очень трудно. Следующая ситуация не была исключением.
Год назад я нашел одного очень привлекательного (с точки зрения контента) ютубера. Больше всего в видео блоге Девона Кроуфорда мне нравится то, что он студент, который пытается исследовать и делиться полученным в процессе опытом с другими, создавая «сочные» видео. Он вдохновил меня на изучение новых технологий и даже на создание этого блога.
В серии роликов, которая начинается с этого видео, он рассказывает про процесс построения распределенной системы для управления своими проектами. Реализовать нечто подобное стало следующей ступенью на моем пути становления профессионалом. Около полугода назад у меня наконец-то появилось достаточно времени и навыков, чтобы заняться подобной системой.
Общая структура
Воодушевленный возможностями, я не мог дождаться, чтобы начать работать над новым проектом. Идея состояла в том, чтобы создать Headless (распределенную) CMS, которую я назвал Bluro. Систему я решил дополнить расширенным «Hello world» приложение, блогом «TechOverload» и панелью администрирования для него.
Во-первых, я должен был понять, что должна делать система, после чего определить требуемые компоненты.
Блог может быть простым сайтом, где единственный человек имеет право публиковать и изменять контент. Но в моем варианте все немного сложнее. Любой желающий может прочитать статью. Однако, если он хочет писать, комментировать, подписываться на авторов, тогда он должен создать учетную запись.
Подсумировав вышесказанное, я выписал полный список функций:
- Регистрация, вход, изменение и удаление профиля
- Публикация, сохранение в черновиках, модификация, удаление статей
- Создание, модификация, удаление комментариев
- Возможность подписаться, отписаться от автора
- Создание, чтение, удаление уведомлений
Кроме того, я подумал, что было бы здорово, если модераторы могли управлять контентом в выделенной среде, поэтому я решил реализовать панель администрирования со следующими функциями:
- Просмотр профилей, написание сообщения, которое появится в виде уведомления, удаление профиля пользователя.
- Просмотр, удаление опубликованных статей
- Просмотр, удаление комментариев
Проблема была в том, что я даже не знал с чего начать, кроме того у меня было всего два месяца. Вы можете сказать, что это не проблема для программиста, а скорее типичное состояние. Да, я согласен, за исключением одной маленькой вещи: я мог найти сотни статей, которые объясняют, что означает Headless CMS, но разве что намеки на то, как создать простую версию для начинающих.
Предыдущий значительный скачок в моем уровне веб-разработки был, когда я создал сайт на Python с Django. Я должен сказать, что это дало мне некоторое понимание того, как конечная система должна функционировать.
В конце концов, благодаря куче статей и видео с YouTube, я продвинулся и начал думать об общей структуре приложения.
Если вы посмотрите на диаграмму ниже, то увидите, что архитектура состоит из блоков. Самый верхний блок — это сервер, который ведет вас к соответствующему фронтенду в зависимости от URL (пути, если быть более точным). Оба веб-интерфейса используют компонент бэкенда для получения или сохранения данных.
Эта структура позволяет нам изменять существующие или добавлять новые компоненты, не изменяя потомков, от которых они зависят. В больших масштабах у нас может быть пара человек пишущих пользовательский интерфейс блога, несколько человек на панели администратора и команда, которая работает над бэкэндом.
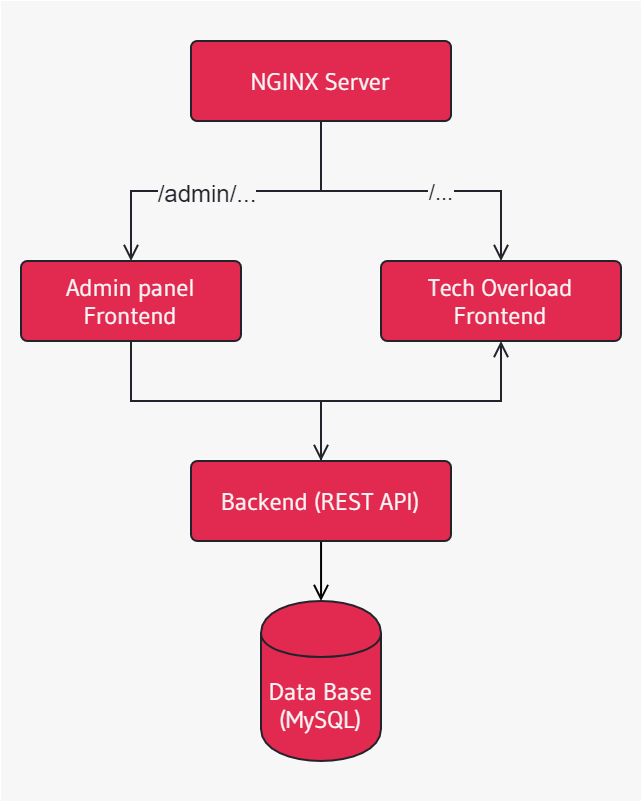
Связь между компонентами осуществляется с помощью API. Бэкэнд-компонент является наиболее сложным, поэтому мы начнем разработку с него.
Поскольку я хотел углубить свой опыт работы с JavaScript, я выбрал NodeJS для бэкэнда и React для фронтендов. Это было бы отличным дополнением к моему портфолио, подумал я тогда.
Разрабатываем Bluro CMS
Headless CMS похожа на обычную, но не имеет уровня представления (UI). Таким образом, она перекладывает задачу отображения графического интерфейса на плечи других компонентов. Вместо этого CMS предоставляет API (REST API в нашем случае, подробнее об этом здесь), чтобы другие могли общаться с ней.
Как вы, возможно, знаете, API — это программная абстракция, проще говоря — место, к которому может подсоединиться программа. Это может быть интерфейс с несколькими функциями, использующимися для соединения одного модуля с другим внутри одной системы, или, как в нашем случае, список URL-адресов, которые мы можем предоставить общественности, чтобы все знали как использовать нашу систему для манипуляции некоторыми данными.
Для того чтобы слушать запросы, нам нужно создать http сервер. Мы обрабатываем каждый полученный запрос, при этом сохраняя и запрашивая нужную информацию из нашей базы данных, после чего мы отправляем ответ.
Частый способ построения такой системы — использование шаблона проектирования MVC (Model View Controller). Таким образом мы разделяем структуру на контроллеры и модели данных (у нас нет представлений).
Создание такой системы не такая простоя задача, ми не хотим переписывать много кода, чтобы заставить ее работать с другим типом приложения, поэтому стоит предоставить возможность изменения частей таким образом, чтобы минимально затрагивать всю систему в общем.
Внедрение дополнительного функционала в нашу CMS требует отделения контроллеров от других компонентов.
Все компоненты, которые не принадлежат бизнес-логике API, составляют ядро нашей CMS. Оно включает в себя сервер, маршрутизатор, файловый менеджер, менеджер конфигураций и небольшие компоненты, облегчающие разработку.
Точно так же мы разбиваем бизнес-логику нашего приложения на модули, которые представляют разные части функциональности.

Приведенная выше диаграмма показывает отношения между наиболее значимыми модулями. Давайте обсудим их.
Main является главным модулем, который загружает систему и другие модули.
ORM
Самый большой и одновременно сложный модуль, являющийся абстракцией между базой данных и другими компонентами — ORM (Object Relational Mapper).
Помните, я говорил, что мы не хотим переписывать много кода, когда решим что-то изменить? Таким образом, чтобы защитить себя от бесчисленных головных болей, мы даем себе в будущем возможность изменить способ хранения данных. Будь то база данных или простые файлы, нам все равно. Все, что нас волнует — это как использовать абстракцию для достижения наших целей.
Центральная сущность модуля — «Модель». Модели дают нам методы для запроса данных, не вдаваясь в детали, такие как написание SQL запросов.
Я знаю, по крайней мере, два способа реализации данного модуля. Первый довольно прост: мы определяем интерфейсы (конечно, в динамически типизированных языках мы можем пропустить этот шаг), представляющие сущности (в случае базы данных это таблицы), с помощью методов которых, мы будем получать доступ к необходимой информации. Затем мы можем написать несколько модулей, каждый из которых реализует интерфейсы, при этом предоставляя новый источник данных. Если использовал этот способ, я бы изменил название нашего абстрактного модуля на что-то вроде «Уровень данных».

Второй более сложный для реализации. Идея состоит в том, чтобы создать единственный класс Model (вместо набора интерфейсов), который наследуется нашими сущностями. Класс Model должен знать только схему нашей базы данных. Он не должен догадываться о том, как получать данные, вместо этого он запрашивает их с помощью другой абстракции.
Опять же таки я не знал как это реализовать, однако к тому времени я работал с несколькими ORM. Поэтому я представлял, как это будет работать на самом высоком уровне абстракции и где я могу подсмотреть реализацию.
Я позволю себе немного отклониться от темы. Не всегда будет возможно найти туториал, объясняющий то что вам нужно, что может раздражать. Но не забывайте о миллионах проектов с открытым исходным кодом. Учитывая такую возможность, вы можете узнать гораздо больше, чем следуя какому-то уроку. Помимо того, что вы можете найти ответы на свои вопросы или обнаружить необычный паттерны, вы можете научиться читать чей-то код, что является важным навыком для программистов. Кто знает, вы можете найти что-то интересное и написать в блоге об этом: ).
Итак, вернемся к делу. Я посмотрел в библиотеку Sequelize и пересмотрел API Django, чтобы имитировать его. Вот как я реализовал ORM.

Самые верхние Entities — это сущности, которые используются для запроса данных из базы (обычно они имеют то же имя, что и таблицы). Класс Model использует QuerySet для фильтрации, сортировки и извлечения данных. В свою очередь, QuerySet зависит от Statement, который предоставляет удобный API для построения запросов. StatementsBuilder — это абстрактный класс, используемый Statement для создания кусочков запроса. Затем у нас есть несколько реализаций, которые вводят определения типов данных и операторов после чего реализуют методы для работы с конкретным диалектом.
Это отличный пример «Паттерна стратегии», хотя не лучший архитектурный подход, поскольку в итоге мы сильно зависим от баз данных.
Я думал, что второй вариант будет лучше, потому что я не видел смысла в использовании простых интерфейсов. Тем не менее я стал мудрее, поэтому рекомендую использовать первый, кроме случаев, когда вы хотите лучше изучить работу ORM.
Вот пример использования моей ORM. Не идеально, но для первой попытки сойдет.
Но мы еще не закончили с нашей прослойкой данных. Есть еще одна концепция, которую я хотел бы обсудить.
Как я уже говорил ранее, мы все еще зависим от базы данных, в частности от схемы. Когда мы меняем схему, мы должны менять наши сущности и наоборот. Итак, я решил внедрить систему миграции, которую заметил в Django.
Каждый раз, когда мы запускаем CMS, система проверяет каждую сущность и создает файл, описывающий изменения. В случае, если сущность была создана, мы добавляем в файл, описание таблицы. В ином случае, если объект изменился, мы добавляем описание различий с предыдущей версией. После этого система применяет изменения, создавая новые таблицы или изменяя уже существующие. Узнать, изменился ли объект, так же просто, как объединить файлы в порядке их создания и проверить различия.
Простейшим примером такой системы является GIT, который отслеживает изменения в ваших файлах, сравнивая их с вашими коммитами.
Вот пример этих файлов. Первый определяет новую сущность, второй вводит изменения.
Server
Чтобы наладить связь с внешним миром, мы должны создать http-сервер. Этот модуль прослушивает запросы, отправляет их на обработку, а затем отправляет ответы. Он использует модуль HTTP, который имеет два класса: Request и Response, расширяющих объекты получаемые сервером.
Requestпомогает получать входящие данные, например, он парсит куки и обрабатывает закодированные формыmultipart / form-data.Responseпомогает структурировать данные, которые будут отправлены обратно. Есть методы для отправки файлов, cookie.
Router
«Маршрутизатор» — это модуль, который помогает нам определять обработчики для конечных точек. Express — простая, но мощная библиотека, реализацию которой я часто подсматривал, в написании своей версии.
Route— определяет контроллер, который будет обрабатывать конечную точку. Контроллер получает запрос, ответ и объект с дополнительной информацией, включая путь и общие параметры. Конечная точка может иметь только один контроллер такого типа.Rule— определяет побочные обработчики, которые обычно вы хотите применить к нескольким конечным точкам. Например, мы можем ввестиauthorizationRule, который проверяет, есть ли у пользователя разрешения. Добавляя это правило, вы закрываете доступ для незарегистрированных пользователей. Конечная точка может определять бесконечное число правил, которые будут применяться в порядке определения.Ruleможет обмениваться данными, сохраняя их в специальном объекте, который будет передан другим контроллерамRuleиRoute.
Ниже вы можете увидеть пример использования модуля. Тут можно найти методы, параметры пути (в фигурных скобках), правила и маршруты.
Расширение системы
Это были основные модули, которые вместе составляют ядро системы. Они предоставляют нам платформу, которую мы можем использовать для создания пользовательского API. В конце концов, это всего лишь пара функций, которые запрашивают данные из базы данных, обрабатывают их, и возвращают ответ.
Хотя мы обсудили все, что вам нужно для создания полноценного API, я не рассказал вам о том, как вы будете расширять систему. Конечно, вы можете опустить эти детали, но когда придет время для новых изменений, у вас могут возникнуть проблемы.
Нам нужен простой способ добавлять новый функционал. Решение — переместить бизнес-логику приложения в модули, которые можно загружать и выгружать по требованию. Для этого я создал Modules Manager, который проверяет наличие модулей, указанных в файле конфигурации, и подключает сущности, правила и контроллеры к компонентам в ядре. Таким образом, вы можете добавлять дополнительные конечные точки с логикой без лишней суеты.
Однако я должен предупредить вас, в моей реализации вы можете найти много нарушений принципов SOLID, которые затрудняют изменение логики. Диаграммы, показанные выше, являются идеализированными с целью упрощения. На самом деле я перепробовал много техник, которые раньше не пробовал, поэтому извиняюсь за беспорядок. Если вы заинтересованны в построении чего-то более сложного, я предлагаю вам узнать больше о чистой архитектуре.
Пример модулей вы можете найти здесь.
Создание API
С готовой системой, разработка API для приложения становится намного проще. Я создал четыре модуля, которые охватывают функциональность, упомянутую ранее. Четыре сущности, которые они представляют, изображены ниже в схеме базы данных.

Auth
Определяет конечные точки, которые позволяют нам создавать учетные записи, входить в систему и управлять информацией профиля: обновлять, удалять, просматривать, подписываться...
Каждый вызов API может быть инициирован разными пользователями, поэтому нам нужен способ идентифицировать их. Итак, мы хотим отправить пользователю некоторые дополнительные данные, которые он будет использовать для авторизации.
Когда пользователь успешно входит в систему, генерируется JWT (JSON Web Token) после чего он отправляется в виде cookie. Токен является закодированным объектом со всем необходимым для идентификации данными. Последующие запросы будут использовать его для авторизации пользователя.
Кроме того, модуль предоставляет два правила:
authRule— правило, применяемое для каждой конечной точки и проверяющее cookie на наличие токена. Если токен действителен, правило сохраняет пользовательские данные в объекте, доступном другим контроллерам.requireAuthorizationRule— правило, которое вы можете применить к конечной точке для защиты от доступа неавторизованных пользователей.
Article
Этот модуль предоставляет конечные точки, которые мы используем для управления статьями. Модуль создает две папки в файловом хранилище, где сохраняются содержимое статей и изображения обложек.
Comment
Дает возможность управлять комментариями.
Notifications
Модуль отвечающий за управление уведомлениями. Он использует
NotificationService для дублирования уведомления на электронную почту.
Вот пример стандартного запроса и ответа от API:
Разработка фронтенда
Чтобы протестировать свою CMS, я решил создать блог, где любой зарегистрированный пользователь имеет возможность поделиться своими мыслями, как я делаю сейчас. Я выбрал React для написания данной части.

Архитектура блога и админ-панели ничем не отличаются от обычных, используемых в реакте. У нас есть «Уровень представления» с нашими компонентами пользовательского интерфейса. React Router загружает страницу в зависимости от пути. Страницы построенные из контейнеров, в котором есть бизнес-логика. Контейнеры, в свою очередь, используют компоненты, которые не имеют бизнес-логики, поэтому могут многократно использоваться.
Для управления состоянием приложения я выбрал Redux с чрезвычайно полезным "плагином" Redux-Saga (мы говорили о тестировании Redux-Saga предыдущий раз). Как вы знаете, в мире Redux у нас есть экшены (Action), которые генерируют объекты с типом действия. Редюсеры (Reducer) ловят эти объекты и изменяет состояние, но мы не можем помещать туда какие-либо побочные эффекты, потому что так будет труднее найти ошибку, редюсеры должны оставаться чистыми.
Итак, что Redux-Saga делает, так это просто дает нам место, где мы можем управлять нашими побочными эффектами. С помощью этого инструмента вы можете создавать сложные потоки в вашем приложении, которые работают асинхронно.
Я использовал Redux-Saga, чтобы наладить связь с Headless CMS. Вот полезные функции, которые помогают делать запросы:
fetchData — это сага, которая использует Fetch API для выполнения запроса. Если запрос занимает больше времени, чем TIMEOUT, мы отменяем его. makeRequest использует предыдущую сагу для запроса некоторых данных, а затем обрабатывает их. Остальные саги используют эти утилиты для получения необходимых данных или выполнения каких-либо действий. Например, здесь вы можете увидеть, как я выполняю открытие статьи:
Блог и админ панель похожи, кроме только пользовательского интерфейса. Ниже я разместил несколько скриншотов с финальной версией пользовательского интерфейса (подробный обзор результатов здесь).

Соединяем все вместе
К этому времени мы говорили о разных блоках нашей системы. Последний шаг — соединить их.
Простая конфигурация для прокси-сервера NGINX:
Используя Docker Compose, я создал контейнеры из которых собрал сервисы. Здесь вы можете найти конфиги со скриптами, которые облегчают развертывание (у меня есть единственная версия сервиса — для разработки).
Если вы хотите создать что-то более захватывающее, советую посмотреть headlesscms.org, где находится список Headless CMS с открытым исходным кодом, которые вы можете использовать в качестве примера.
Спасибо, что уделили мне время, надеюсь мне удалось раскрыть тему в достаточной степени, чтобы помочь кому-то.

