Перевод статьи подготовлен в преддверии старта продвинутого курса «Разработчик Python».
Оригинал статьи можно прочитать тут.

Всем привет! В качестве аперитива к профайлеру на Ruby я хотела рассказать о том, как работают уже существующие профайлеры на Ruby и Python. Также это поможет дать ответ на вопрос, который мне задает множество людей: «Как написать профайлер?»
В этой статье мы сфокусируемся на профайлерах процессора (а не, допустим, профайлерах памяти/кучи). Я расскажу о некоторых базовых подходах к написанию профайлера, приведу примеры кода и покажу много примеров популярных профайлеров на Ruby и Python, а также расскажу, как они работают под капотом.
Вероятно, в статье могут быть ошибки (при подготовке к ее написанию, я частично просмотрела код 14 библиотек для профайлинга, и со многими из них я была не знакома до этого момента), так что, пожалуйста, дайте мне знать, если вы их обнаружите.
Есть два основных вида профайлеров процессора – sampling- и tracing-профайлеры.
Tracing-профайлеры записывают каждый вызов функции в вашей программе, в конечном итоге предоставляя отчет. Sampling-профайлеры придерживаются статистического подхода, они записывают стек каждые несколько миллисекунд, создавая отчет на основе этих данных.
Основная причина использовать sampling-профайлер вместо tracing-профайлера – это его легковесность. Делаете вы 20 или 200 снимков в секунду — это не занимает много времени. Такие профайлеры будут очень эффективны, если у вас есть серьезная проблема с производительностью (80% времени тратится на вызов одной медленной функции), поскольку 200 снимков в секунду будет вполне достаточно для определения проблемной функции!
Дальше я приведу общую сводку профайлеров, рассматриваемых в данной статье(отсюда). Я объясню термины, используемые статье (setitimer, rb_add_event_hook, ptrace) немного позже. Интересно, что все профайлеры реализованы с использованием небольшого набора базовых возможностей.
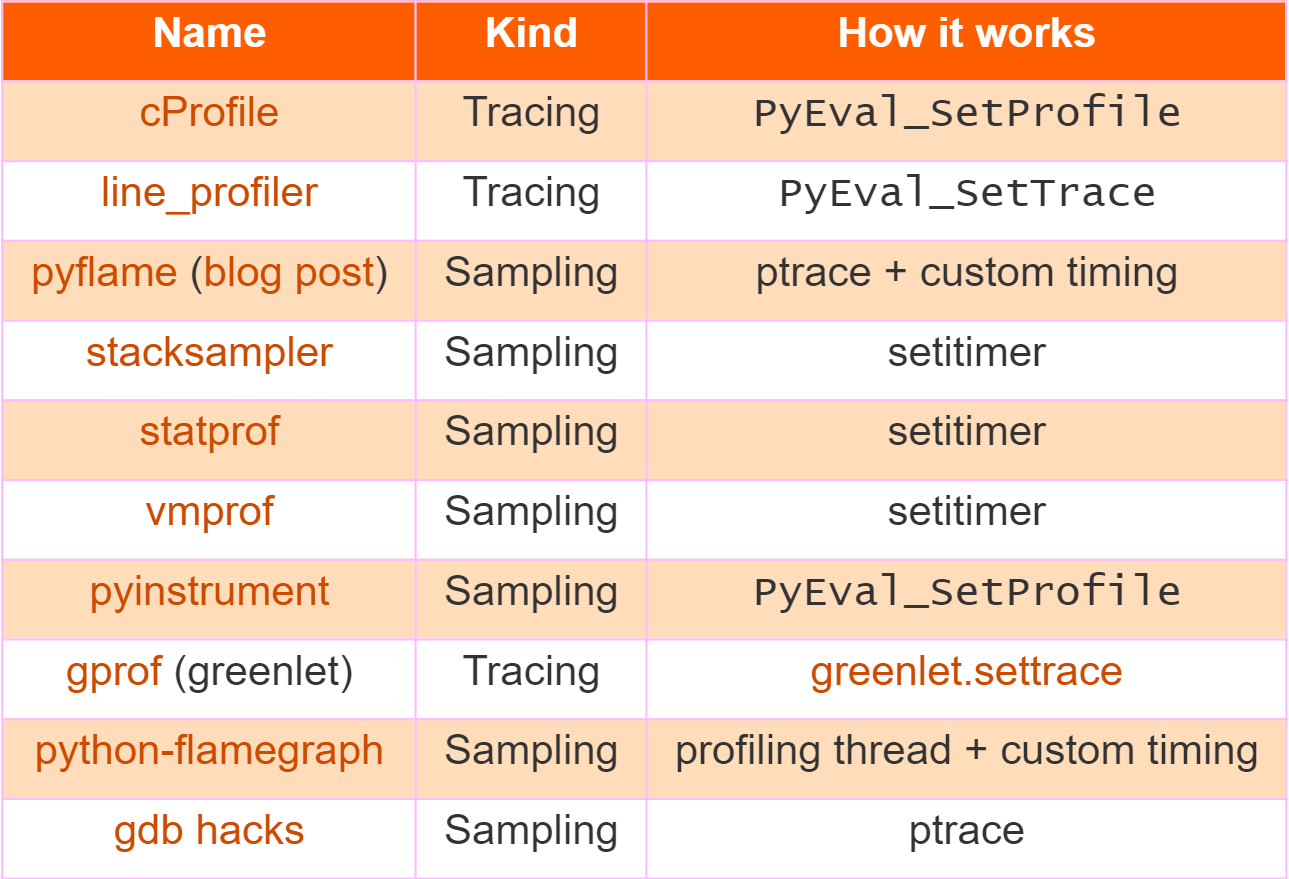
«gdb hacks» не совсем профайлер Python — он ссылается на веб-сайт, рассказывающий о том, как реализовать хакерский профайлер в качестве обертки shell-скрипта вокруг gdb. Речь идет именно о Python, так как новые версии gbd фактически развернут для вас стек Python. Что-то вроде pyflame для бедных.

Почти все эти профайлеры живут внутри вашего процесса
Прежде чем мы начнем разбираться в деталях этих профайлеров, есть одна очень важная вещь – все эти профайлеры, кроме pyflame, запускаются внутри вашего процесса Python/Ruby. Если вы находитесь внутри программы на Python/Ruby, у вас, как правило, имеется простой доступ к стеку. Например, вот простая программа на Python, которая печатает содержимое стека каждого работающего потока:
Вот вывод консоли. Вы видите, что в нем есть имена функций из стека, номера строк, имена файлов – все, что вам может понадобиться, если вы выполняете профилирование.
В Ruby даже проще: вы можете использовать puts caller, чтобы получить стек.
Большинство этих профайлеров являются расширениями С в плане производительности, поэтому они немного отличаются, но такие расширения для программ на Ruby/Python также имеют легкий доступ к стеку вызовов.
Я перечислила все tracing-профайлеры Ruby и Python в таблицах выше: rblineprof, ruby-prof, line_profiler и cProfile. Все они работают схожим образом. Они записывают каждый вызов функции и являются расширениями С для уменьшения оверхеда.
Как они работают? И в Ruby, и в Python вы можете указать коллбэк, который запускается, когда происходят различные события интерпретатора (например, «вызов функции» или «выполнение строки кода»). Когда вызывается коллбэк, он записывает стек для последующего анализа.
Полезно видеть, где именно в коде находятся эти коллбэки, поэтому я сошлюсь на соответствующие строки кода на github.
В Python вы можете настроить коллбэк с помощью
Код:
В Ruby вы можете настроить коллбэк с помощью
Сигнатура
Чем-то похоже на
Код:
Основным недостатком реализованных таким образом tracing-профайлеров является то, что они добавляют фиксированное количество кода для каждого выполняемого вызова функции/строки. Это может заставить вас принимать неправильные решения! Например, если у вас есть две реализации чего-либо — одна с большим количеством вызовов функций, а другая без, которые обычно выполняются за одинаковое время, то первая, с большим количеством вызовов функций, при профилировании будет казаться медленнее.
Чтобы показать наглядно, я создала небольшой файл с именем
Это кажется довольно разумным утверждением – предыдущий пример (который выполняет 3,5 миллиона вызовов функций и больше ничего), очевидно, не является обычной программой на Python, и почти любая другая программа будет иметь меньше оверхеда.
Я не проверяла оверхед
Время поговорить о втором виде профайлеров: sampling-профайлерах!
Большинство sampling-профайлеров Ruby и Python реализованы с использованием системного вызова
Допустим, вы хотите получать снимок стека программы 50 раз в секунду. Сделать это можно следующим образом:
Если вы хотите увидеть практический пример использования
Причина, по которой
Он просто извлекает стек из фрейма и увеличивает количество раз, которое конкретный стек просматривался. Так просто! Так круто!
Давайте рассмотрим все остальные наши профайлеры, которые используют
Важная вещь о
Один ИНТЕРЕСНЫЙ недостаток профайлеров на основе
Существует несколько sampling-профайлеров, которые не используют
Все 3 эти профайлера делают снимки с использованием реального времени.
Я потратила почти все свое время в этом посте на профайлеры, отличные от
Конечно же, все немного сложнее, чем я описала. Я не буду вдаваться в подробности, но Эван Клицке написал много хороших статей об этом в своем блоге:
Больше информации можно найти на eklitzke.org. Все это очень интересные вещи, про которые я собираюсь прочитать более внимательно – возможно,
На этом все на сегодня!
Есть много важных тонкостей, в которые я не вдавалась в этом посте – например, я в основном сказала, что
TDD c pytest и без него. Бесплатный вебинар
Оригинал статьи можно прочитать тут.
Всем привет! В качестве аперитива к профайлеру на Ruby я хотела рассказать о том, как работают уже существующие профайлеры на Ruby и Python. Также это поможет дать ответ на вопрос, который мне задает множество людей: «Как написать профайлер?»
В этой статье мы сфокусируемся на профайлерах процессора (а не, допустим, профайлерах памяти/кучи). Я расскажу о некоторых базовых подходах к написанию профайлера, приведу примеры кода и покажу много примеров популярных профайлеров на Ruby и Python, а также расскажу, как они работают под капотом.
Вероятно, в статье могут быть ошибки (при подготовке к ее написанию, я частично просмотрела код 14 библиотек для профайлинга, и со многими из них я была не знакома до этого момента), так что, пожалуйста, дайте мне знать, если вы их обнаружите.
2 вида профайлеров
Есть два основных вида профайлеров процессора – sampling- и tracing-профайлеры.
Tracing-профайлеры записывают каждый вызов функции в вашей программе, в конечном итоге предоставляя отчет. Sampling-профайлеры придерживаются статистического подхода, они записывают стек каждые несколько миллисекунд, создавая отчет на основе этих данных.
Основная причина использовать sampling-профайлер вместо tracing-профайлера – это его легковесность. Делаете вы 20 или 200 снимков в секунду — это не занимает много времени. Такие профайлеры будут очень эффективны, если у вас есть серьезная проблема с производительностью (80% времени тратится на вызов одной медленной функции), поскольку 200 снимков в секунду будет вполне достаточно для определения проблемной функции!
Профайлеры
Дальше я приведу общую сводку профайлеров, рассматриваемых в данной статье(отсюда). Я объясню термины, используемые статье (setitimer, rb_add_event_hook, ptrace) немного позже. Интересно, что все профайлеры реализованы с использованием небольшого набора базовых возможностей.
Профайлеры Python
«gdb hacks» не совсем профайлер Python — он ссылается на веб-сайт, рассказывающий о том, как реализовать хакерский профайлер в качестве обертки shell-скрипта вокруг gdb. Речь идет именно о Python, так как новые версии gbd фактически развернут для вас стек Python. Что-то вроде pyflame для бедных.
Профайлеры Ruby
Почти все эти профайлеры живут внутри вашего процесса
Прежде чем мы начнем разбираться в деталях этих профайлеров, есть одна очень важная вещь – все эти профайлеры, кроме pyflame, запускаются внутри вашего процесса Python/Ruby. Если вы находитесь внутри программы на Python/Ruby, у вас, как правило, имеется простой доступ к стеку. Например, вот простая программа на Python, которая печатает содержимое стека каждого работающего потока:
import sys import traceback def bar(): foo() def foo(): for _, frame in sys._current_frames().items(): for line in traceback.extract_stack(frame): print line bar()
Вот вывод консоли. Вы видите, что в нем есть имена функций из стека, номера строк, имена файлов – все, что вам может понадобиться, если вы выполняете профилирование.
('test2.py', 12, '<module>', 'bar()') ('test2.py', 5, 'bar', 'foo()') ('test2.py', 9, 'foo', 'for line in traceback.extract_stack(frame):')
В Ruby даже проще: вы можете использовать puts caller, чтобы получить стек.
Большинство этих профайлеров являются расширениями С в плане производительности, поэтому они немного отличаются, но такие расширения для программ на Ruby/Python также имеют легкий доступ к стеку вызовов.
Как работают tracing-профайлеры
Я перечислила все tracing-профайлеры Ruby и Python в таблицах выше: rblineprof, ruby-prof, line_profiler и cProfile. Все они работают схожим образом. Они записывают каждый вызов функции и являются расширениями С для уменьшения оверхеда.
Как они работают? И в Ruby, и в Python вы можете указать коллбэк, который запускается, когда происходят различные события интерпретатора (например, «вызов функции» или «выполнение строки кода»). Когда вызывается коллбэк, он записывает стек для последующего анализа.
Полезно видеть, где именно в коде находятся эти коллбэки, поэтому я сошлюсь на соответствующие строки кода на github.
В Python вы можете настроить коллбэк с помощью
PyEval_SetTrace или PyEval_SetProfile. Это описано в разделе документации Profiling and Tracing по Python. Там сказано: «PyEval_SetTrace похож на PyEval_SetProfile, за исключением того, что функция трассировки получает события с номерами строк».Код:
line_profilerустанавливает свой коллбэк, используяPyEval_SetTrace: см.line_profiler.pyxстрока 157cProfileустанавливает свой коллбэк, используяPyEval_SetProfile: см._lsprof.cстрока 693(cProfile реализован с использованием lsprof)
В Ruby вы можете настроить коллбэк с помощью
rb_add_event_hook. Я не смогла найти никакой документации про это, но вот как это выглядитrb_add_event_hook(prof_event_hook, RUBY_EVENT_CALL | RUBY_EVENT_RETURN | RUBY_EVENT_C_CALL | RUBY_EVENT_C_RETURN | RUBY_EVENT_LINE, self);
Сигнатура
prof_event_hook:static void prof_event_hook(rb_event_flag_t event, VALUE data, VALUE self, ID mid, VALUE klass)
Чем-то похоже на
PyEval_SetTrace в Python, но в более гибкой форме – вы можете выбрать, о каких событиях вы хотите получать уведомления (например, «только вызовы функций»).Код:
ruby-profвызываетrb_add_event_hookздесь:ruby-prof.cстрока 329rblineprofвызываетrb_add_event_hookздесь:rblineprof.cстрока 649
Недостатки tracing-профайлеров
Основным недостатком реализованных таким образом tracing-профайлеров является то, что они добавляют фиксированное количество кода для каждого выполняемого вызова функции/строки. Это может заставить вас принимать неправильные решения! Например, если у вас есть две реализации чего-либо — одна с большим количеством вызовов функций, а другая без, которые обычно выполняются за одинаковое время, то первая, с большим количеством вызовов функций, при профилировании будет казаться медленнее.
Чтобы показать наглядно, я создала небольшой файл с именем
test.py со следующим содержимым и сравнила время выполнения python -mcProfile test.py и python test.py. python. test.py выполнился примерно за 0.6 с, а python -mcProfile test.py – примерно за 1 с. Так что для этого конкретного примера cProfile добавил дополнительные ~ 60% оверхеда.В документацииcProfileсказано:
интерпретируемая природа Python добавляет столько накладных расходов во время выполнения, что детерминированное профилирование имеет тенденцию добавлять небольшую нагрузку на обработку в обычных приложениях
Это кажется довольно разумным утверждением – предыдущий пример (который выполняет 3,5 миллиона вызовов функций и больше ничего), очевидно, не является обычной программой на Python, и почти любая другая программа будет иметь меньше оверхеда.
Я не проверяла оверхед
ruby-prof (tracing-профайлер Ruby), но в его README написано следующее:Большинство программ будет работать примерно вдвое медленнее, в то время как высокорекурсивные программы (такие как тест ряда Фибоначчи) будут работать в три раза медленнее.
Как в основном работают sampling-профайлеры: setitimer
Время поговорить о втором виде профайлеров: sampling-профайлерах!
Большинство sampling-профайлеров Ruby и Python реализованы с использованием системного вызова
setitimer. Что это такое?Допустим, вы хотите получать снимок стека программы 50 раз в секунду. Сделать это можно следующим образом:
- Попросить ядро Linux отправлять вам сигнал каждые 20 миллисекунд (с помощью системного вызова
setitimer); - Зарегистрировать обработчик сигнала для снимка стека при получении сигнала;
- По окончанию профилирования попросить Linux прекратить слать вам сигналы и предоставить результат!
Если вы хотите увидеть практический пример использования
setitimer для реализации sampling-профайлера, я думаю, что stacksampler.py – лучший пример – это полезный, работающий профайлер, и он содержит около 100 строк на Python. И это очень круто!Причина, по которой
stacksampler.py занимает всего 100 строк в Python, заключается в том, что при регистрации функции Python в качестве обработчика сигнала функция передается в текущий стек вашей программы. Поэтому обработчик сигналов stacksampler.py регистрируется очень просто:def _sample(self, signum, frame): stack = [] while frame is not None: stack.append(self._format_frame(frame)) frame = frame.f_back stack = ';'.join(reversed(stack)) self._stack_counts[stack] += 1
Он просто извлекает стек из фрейма и увеличивает количество раз, которое конкретный стек просматривался. Так просто! Так круто!
Давайте рассмотрим все остальные наши профайлеры, которые используют
setitimer, и выясним, где в коде они вызывают setitimer:stackprof(Ruby): вstackprof.cстрока 118perftools.rb(Ruby): в этом патче, который, кажется, применяется, когда gem скомпилирован(?)stacksampler(Python):stacksampler.pyстрока 51statprof(Python):statprof.pyстрока 239vmprof(Python):vmprof_unix.cстрока 294
Важная вещь о
setitimer — вам нужно решить, как считать время. Вы хотите 20 мс реального времени? 20 мс пользовательского процессорного времени? 20 мс пользовательского + системного времени процессора? Если вы внимательно посмотрите на ссылки выше, то заметите, что эти профайлеры на самом деле по-разному используют setitimer – иногда поведение настраивается, а иногда нет. Man-страница setitimer короткая и ее стоит прочитать, чтобы узнать все возможные конфигурации.@mgedmin в твиттере указал на один интересный недостаток использования setitimer. Этот issue и этот issue раскрывают больше деталей.Один ИНТЕРЕСНЫЙ недостаток профайлеров на основе
setitimer – то, что таймеры вызывают сигналы! Сигналы иногда прерывают системные вызовы! Системные вызовы иногда занимают несколько миллисекунд! Если вы делаете снимки слишком часто, то можете заставить программу выполнять системные вызовы бесконечно долго!Sampling-профайлеры, которые не используют setitimer
Существует несколько sampling-профайлеров, которые не используют
setitimer:pyinstrumentиспользуетPyEval_SetProfile(так что это своего рода tracing-профайлер), но он не всегда собирает снимки стека при вызове коллбэка трассировки. Вот код, который выбирает время снимка трассировки стека. Подробнее об этом решении читайте в этом блоге. (в основном:setitimerпозволяет профилировать только основной поток в Python)pyflameпрофилирует код Python снаружи процесса, используя системный вызовptrace. Он использует цикл, где он получает снимки, спит определенное время и снова делает все тоже самое. Вот вызов на ожидание.python-flamegraphиспользует аналогичный подход, когда он запускает новый поток в вашем процессе Python и получает трассировки стека, спит и повторяет все заново. Вот вызов на ожидание.
Все 3 эти профайлера делают снимки с использованием реального времени.
Посты в блоге pyflame
Я потратила почти все свое время в этом посте на профайлеры, отличные от
pyflame, но на самом деле он меня интересует больше всего, поскольку он профилирует вашу программу на Python из отдельного процесса, и именно поэтому я хочу, чтобы мой профайлер Ruby работал аналогично.Конечно же, все немного сложнее, чем я описала. Я не буду вдаваться в подробности, но Эван Клицке написал много хороших статей об этом в своем блоге:
- Pyflame: Uber Engineering’s Ptracing Profiler for Python — введение в pyflame;
- Pyflame Dual Interpreter Mode — о том, как он поддерживает и Python 2 и Python 3 одновременно;
- An Unexpected Python ABI Change — о добавлении поддержки Python 3.6;
- Dumping Multi-Threaded Python Stacks;
- Пакеты Pyflame;
Про интересные проблемы с ptraceи системными вызовами в Python;- Using ptrace for fun and profit, ptrace (продолжение);
Больше информации можно найти на eklitzke.org. Все это очень интересные вещи, про которые я собираюсь прочитать более внимательно – возможно,
ptrace окажется лучше, чем process_vm_readv для реализации профайлера Ruby! У process_vm_readv меньше оверхед, так как он не останавливает процесс, но он также может дать вам некорректный снимок, так как он не останавливает процесс :). В моих экспериментах получение противоречивых снимков не было большой проблемой, но думаю, что здесь я проведу серию экспериментов.На этом все на сегодня!
Есть много важных тонкостей, в которые я не вдавалась в этом посте – например, я в основном сказала, что
vmprof и stacksampler – схожи (это не так — vmprof поддерживает профилирование строк и профилирование функций Python, написанных на C, что, я считаю, делает профайлер более сложным). Но у них есть некоторые одинаковые основные принципы, и поэтому я думаю, что сегодняшний обзор будет хорошей отправной точкой.TDD c pytest и без него. Бесплатный вебинар

