
Приветствую! Сегодня хотелось бы поговорить на одну тему, с которой так или иначе сталкивается любой гейм-дизайнер. И эта тема —
Представьте, у вас в игре есть 100500 видов различных мечей и им всем внезапно потребовалось немного поднять базовый урон. Обычно, в таком случае запрягается старый добрый эксель, а результаты затем вставляются в JSON/XML руками или при помощи регулярок, но это долго, хлопотно и чревато ошибками валидации.
Давайте посмотрим, как для таких целей может подходить Google Spreadsheets и встроенный в него Google Apps Script и можно ли на этом сэкономить время.
Заранее оговорюсь, что речь идет о статике для f2p-игр или игр-сервисов, которым свойственны регулярные обновления механик и пополнение контента, т.е. указанный выше процесс ± постоянен.
Итак, для редактирования тех же мечей вам потребуется выполнить три операции:
- извлечь текущие показатели урона (если у вас нет готовых расчетных таблиц);
- рассчитать обновленные значения в старом добром экселе;
- перенести новые значения в игровые JSON-ы.
До тех пор, пока у вас есть готовый инструмент и он вас устраивает, — все хорошо и можно редактировать так, как привыкли. Но что, если инструмента нет? Или еще хуже, нет самой игры, т.к. она еще только в разработке? В таком случае, помимо редактирования существующих данных вам также требуется решить, где их хранить и какая у них будет структура.
С хранением все еще более-менее понятно и стандартизировано: в большинстве случаев статика — это просто набор отдельных JSON-ов, лежащий где-то в VCS. Бывают, конечно, более экзотические случаи, когда все хранится в реляционной (или не очень) базе, или, что самое страшное, в XML. Но, если вы выбрали их, а не обычный JSON, то скорее всего у вас уже есть весомые на то основания, т.к. производительность и удобство использования этих вариантов весьма сомнительны.
А вот что касается структуры статики и ее редактирования — изменения будут зачастую радикальные и ежедневные. Конечно, в некоторых ситуациях ничто не заменит по эффективности обычный Notepad++ вкупе с регулярками, но нам все же хочется иметь инструмент с более низким порогом входа и удобством для редактирования командой.
В качестве подобного инструмента лично мне подошел банальный и многим известный Google Spreadsheets. Как и у любого инструмента, у него есть свои плюсы и минусы. Попробую рассмотреть их с точки зрения ГД.
| Плюсы | Минусы |
|---|---|
|
|
Для меня плюсы значительно перевешивали минусы, и в связи с этим было решено попробовать найти обходной путь по каждому из представленных минусов.
Что получилось в итоге?
В Google Spreadsheets сделан отдельный документ, в котором есть лист Main, где мы управляем выгрузкой, и остальные листы, по одному на каждый игровой объект.
При этом, чтобы привычный nested JSON уложить в плоскую таблицу, пришлось немного переизобрести велосипед. Допустим, мы имели следующий JSON:
{ "test_craft_01": { "id": "test_craft_01", "tags": [ "base" ], "price": [ {"ident": "wood", "count":100}, {"ident": "iron", "count":30} ], "result": { "type": "item", "id": "sword", "rarity_wgt": { "common": 100, "uncommon": 300 } } }, "test_craft_02": { "id": "test_craft_02", "price": [ {"ident": "sword", "rarity": "uncommon", "count":1} ], "result": { "type": "item", "id": "shield", "rarity_wgt": { "common": 100 } } } }
В таблицах такую структуру можно представить как пару значений “полный путь” — “значение”. Отсюда родился самопальный язык разметки пути, в котором:
- text — это поле или объект
- / — разделитель иерархии
- text[] — массив
- #number — индекс элемента в массиве
Таким образом, в таблицу JSON будет записан следующим образом:

Соответственно, добавление нового объекта такого типа — это еще один столбец в таблице и, если у объекта были какие-то особые поля, — то расширение списка строк с ключами в keypath.
Разделение на root и остальные уровни — это дополнительное удобство в целях использования фильтров в таблице. В остальном работает простое правило: если значение в объекте не пустое, то мы его добавим в JSON и выгрузим.
На случай, если же в JSON будут добавляться новые поля и кто-то ошибется в пути — он проверяется следующей регуляркой на уровне условного форматирования:
=if( LEN( REGEXREPLACE(your_cell_name, "^[a-zA_Z0-9_]+(\[\])*(\/[a-zA_Z0-9_]+(\[\])*|\/\#*[0-9]+(\[\])*)*", ""))>0, true, false)
А теперь о том, как происходит выгрузка. Для этого необходимо перейти на лист Main, выбрать желаемые объекты для выгрузки в столбце #ACTION и…
нажать на Палпатина ( ͡° ͜ʖ ͡°)
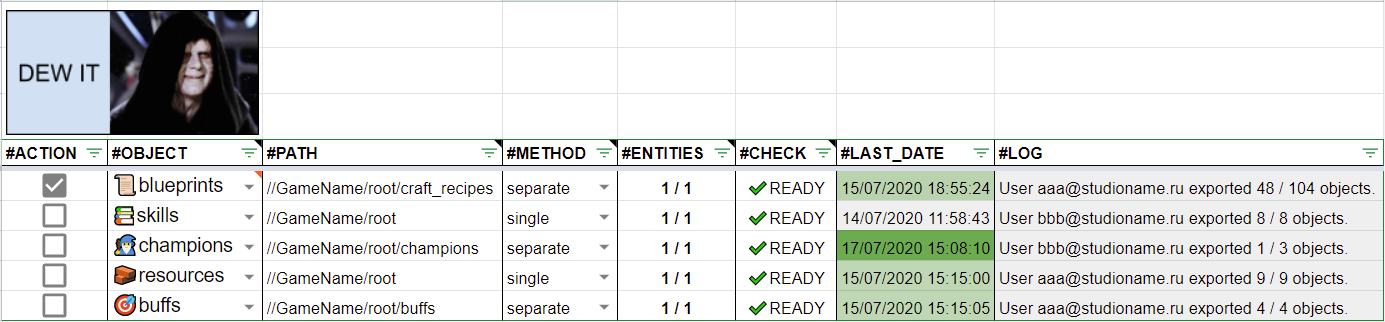
В результате будет запущен скрипт, который возьмет данные с листов, указанных в поле #OBJECT, и выгрузит их в JSON. Путь для выгрузки указан в поле #PATH, а место, куда будет выгружен файл, — это ваш личный Google Drive, привязанный к учетной записи Google, под которой вы просматриваете документ.
Поле #METHOD позволяет настроить, как именно требуется выгрузить JSON:
- Если single — выгружается один файл с названием, равным названию объекта (без эмодзи, конечно же, они тут только для читаемости)
- Если separate — каждый объект с листа будет выгружен в отдельный JSON.
Оставшиеся поля носят больше информационный характер и позволяют понять, сколько сейчас объектов готово к выгрузке и кто их выгружал последним.
При попытке реализовать честный вызов метода экспорта я столкнулся с интересной особенностью спредшитов: повесить вызов функции на картинку — можно, а указать в вызове этой функции аргументы — нельзя. После небольшого периода фрустрации было принято решение продолжить эксперимент с велосипедом и родилась идея разметки самих листов с данными.
Так, например, в таблицах появились якоря ###data### и ###end_data### на листах с данными, по которым определяются области атрибутов для выгрузки.
Исходники
Соответственно, как выглядит сбор JSON-a на уровне кода:
- Берем поле #OBJECT и ищем все данные листа с таким именем
var sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName(name) - Ищем координаты основных якорей, по которым будем фильтровать данные листа (идем по рэнжу как по двумерному массиву, пока не найдем ячейку со значением == тексту якоря)
function GetAnchorCoordsByName(anchor, data){ var coords = { x: 0, y: 0 } for(var row=0; row<data.length; row++){ for(var column=0; column<data[row].length; column++){ if(data[row][column] == anchor){ coords.x = column; coords.y = row; } } } return coords; } - Отрезаем столбцы объектов, которые выгружать не потребуется (для них в строке с якорем ###enable### можно изначально выставить true|false)
function FilterActiveData(data, enabled){ for(var column=enabled.x+1; column<data[enabled.y].length; column++){ if(!data[enabled.y][column]){ for(var row=0; row<data.length; row++){ data[row].splice(column, 1); } column--; } } return data } - Отрезаем строки за пределами якорей ###data### и ###end_data###
function FilterDataByAnchors(data, start, end){ data.splice(end.y) data.splice(0, start.y+1); for(var row=0; row<data.length; row++){ data[row].splice(0,start.x); } return data; } - Забираем данные первого столбца в качестве ключей наших атрибутов
function GetJsonKeys(data){ var keys = []; for(var i=1; i<data.length; i++){ keys.push(data[i][0]) } return keys; } - Пробегаемся по каждому столбцу и создаем на каждый из них по объекту
//На вход получаем отфильтрованные значения. //В случае, если экспорт идет как single-file, - сюда приходят все столбцы с листа. //Иначе - метод вызывается столько раз, сколько будет создано separate JSON-ов function PrepareJsonData(filteredData){ var keys = GetJsonKeys(filteredData) var jsonData = []; for(var i=1; i<filteredData[0].length; i++){ var objValues = GetObjectValues(filteredData, i); var jsonObject = { "objName": filteredData[0][i], "jsonBody": ParseToJson(keys, objValues) } jsonData.push(jsonObject) } return jsonData; } //Упаковываем в JSON конкретный столбец (пары ключ-значение) function ParseToJson(fields, values){ var outputJson = {}; for(var field in fields){ if( IsEmpty(fields[field]) || IsEmpty(values[field]) ){ continue; } var key = fields[field]; var value = values[field]; var jsonObject = AddJsonValueByPath(outputJson, key, value); } return outputJson; } //Добавляем конкретный атрибут в JSON по его полному пути function AddJsonValueByPath(jsonObject, path, value){ if(IsEmpty(value)) return jsonObject; var nodes = PathToArray(path); AddJsonValueRecursive(jsonObject, nodes, value); return jsonObject; } //Разбиваем string с адресом поля на сегменты function PathToArray(path){ if(IsEmpty(path)) return []; return path.split("/"); } //Рекурсивно проверяем, существует ли нода адреса, и если нет - добавляем function AddJsonValueRecursive(jsonObject, nodes, value){ var node = nodes[0]; if(nodes.length > 1){ AddJsonNode(jsonObject, node); var cleanNode = GetCleanNodeName(node); nodes.shift(); AddJsonValueRecursive(jsonObject[cleanNode], nodes, value) } else { var cleanNode = GetCleanNodeName(node); AddJsonValue(jsonObject, node, value); } return jsonObject; } //Добавляем ранее не существовавшую ноду в JSON. Индексы массивов обрабатываются отдельно. function AddJsonNode(jsonObject, node){ if(jsonObject[node] != undefined) return jsonObject; var type = GetNodeType(node); var cleanNode = GetCleanNodeName(node); switch (type){ case "array": if(jsonObject[cleanNode] == undefined) { jsonObject[cleanNode] = [] } break; case "nameless": AddToArrayByIndex(jsonObject, cleanNode); break; default: jsonObject[cleanNode] = {} } return jsonObject; } //Добавляем новый объект в массив по указанному индексу function AddToArrayByIndex(array, index){ if(array[index] != undefined) return array; for(var i=array.length; i<=index; i++){ array.push({}); } return array; } //Заполняем конечный атрибут значением (после того, как проверен полный путь до атрибута) function AddJsonValue(jsonObject, node, value){ var type = GetNodeType(node); var cleanNode = GetCleanNodeName(node); switch (type){ case "array": if(jsonObject[cleanNode] == undefined){ jsonObject[cleanNode] = []; } jsonObject[cleanNode].push(value); break; default: jsonObject[cleanNode] = value; } return jsonObject } //Узнаем тип ноды. //Если object - будем добавлять вложенные ключи по дефолту //Если array - проверяем его наличие и создаем, если его нет //Если nameless - проверяем в массиве выше наличие объекта с соответствующим индексом, и если такого нет - создаем function GetNodeType(key){ var reArray = /\[\]/ var reNameless = /#/; if(key.match(reArray) != null) return "array"; if(key.match(reNameless) != null) return "nameless"; return "object"; } //Вычищаем из имени ноды псевдоразметку для указания конечного значения уже в JSON function GetCleanNodeName(node){ var reArray = /\[\]/; var reNameless = /#/; node = node.replace(reArray,""); if(node.match(reNameless) != null){ node = node.replace(reNameless, ""); node = GetNodeValueIndex(node); } return node } //Извлекаем индекс объекта массива из nameless-объекта function GetNodeValueIndex(node){ var re = /[^0-9]/ if(node.match(re) != undefined){ throw new Error("Nameless value key must be: '#[0-9]+'") } return parseInt(node-1) } - Полученный JSON передаем для создания соответствующего файла в Google Drive
//Основной метод, в который необходимо передать: путь, имя файла (с расширением) и string с данными. function CreateFile(path, filename, data){ var folder = GetFolderByPath(path) var isDuplicateClear = DeleteDuplicates(folder, filename) folder.createFile(filename, data, "application/json") return true; } //Ищем конкретную папку в GoogleDrive по полному пути function GetFolderByPath(path){ var parsedPath = ParsePath(path); var rootFolder = DriveApp.getRootFolder() return RecursiveSearchAndAddFolder(parsedPath, rootFolder); } //Разбиваем полный путь к папке на сегменты function ParsePath(path){ while ( CheckPath(path) ){ var pathArray = path.match(/\w+/g); return pathArray; } return undefined; } //Проверяем валидность переданного на вход пути function CheckPath(path){ var re = /\/\/(\w+\/)+/; if(path.match(re)==null){ throw new Error("File path "+path+" is invalid, it must be: '//.../'"); } return true; } //Если вдруг в папке уже есть файл с таким именем, с которым мы хотим создать файл, - маркируем старый на удаление. //Иначе - получим дублирование файлов, т.к. старый сам не удалится function DeleteDuplicates(folder, filename){ var duplicates = folder.getFilesByName(filename); while ( duplicates.hasNext() ){ duplicates.next().setTrashed(true); } } //Штатной возможности поиска по пути нет, поэтому мы идем от корневого раздела вниз до конечного, ища каждый сегмент пути по имени function RecursiveSearchAndAddFolder(parsedPath, parentFolder){ if(parsedPath.length == 0) return parentFolder; var pathSegment = parsedPath.splice(0,1).toString(); var folder = SearchOrCreateChildByName(parentFolder, pathSegment); return RecursiveSearchAndAddFolder(parsedPath, folder); } //Ищем в parent папку name, и если нет - создаем function SearchOrCreateChildByName(parent, name){ var childFolder = SearchFolderChildByName(parent, name); if(childFolder==undefined){ childFolder = parent.createFolder(name); } return childFolder } //Перебираем итератор файлов в parent на предмет соответствия name на входе function SearchFolderChildByName(parent, name){ var folderIterator = parent.getFolders(); while (folderIterator.hasNext()){ var child = folderIterator.next(); if(child.getName() == name){ return child; } } return undefined; }
Готово! Теперь идем в Google Drive и забираем там свой файлик.
Для чего была нужна возня с файлами в Google Drive, и почему не постить сразу в гит? В основном — только для того, чтобы можно было проверять файлы до того, как они улетели на сервер
Чего нормально решить не удалось: при проведении различных A/B-тестов всегда возникает необходимость создавать отдельные ветки статики, в которых меняется часть данных. Но так как по сути это еще одна копия дикта, мы можем для A/B-теста копировать сам спредшит, поменять данные в нем и уже оттуда выгружать данные для теста.
Заключение
Как в итоге справляется подобное решение? На удивление быстро. При условии того, что большая часть таких работ и так выполняется в спредшитах, — использовать подручный инструмент оказалось наилучшим способом уменьшить время на разработку.
За счет того, что в документе почти не используются формулы, приводящие к каскадным обновлениям, там практически нечему тормозить. Перенос балансовых расчетов из других таблиц теперь вообще занимает минимум времени, т.к. требуется только перейти на нужный лист, выставить фильтры и копировать значения.
Основным бутылочным горлышком производительности становится API Google Drive: поиск и удаление/создание файлов занимает максимальное время, здесь помогает только выгрузка не всех файлов сразу или выгрузка листа не отдельными файлами, а единым JSON-ом.
Надеюсь, подобный клубок извращений будет полезным для тех, кто все еще редактирует JSON-ы руками и регулярками, а также выполняет балансные расчеты статики в Excel вместо Google Spreadsheets.
Ссылки
Пример спредшита-экспортера
Ссылка на проект в Google Apps Script

